With the new EU legislation Cyber Resiliency Act (CRA), there are new responsibilities and requirements put on manufacturers of digital products and services in Europe.
Going forward these manufacturers must be able to know and report the exact contents of their software, called a Software Bill of Material (SBOM) and they have requirements to check for vulnerabilities in those components etc. This implies that they need to have full control and knowledge about all of their Open Source components in their stack. (See the CRA Hub for a good resource on CRA for Open Source people.)
As a maintainer of a software component that is widely used, I have been curious to see how this will materialize for us. Today I got a first glimpse of what I can only guess will happen more going forward.
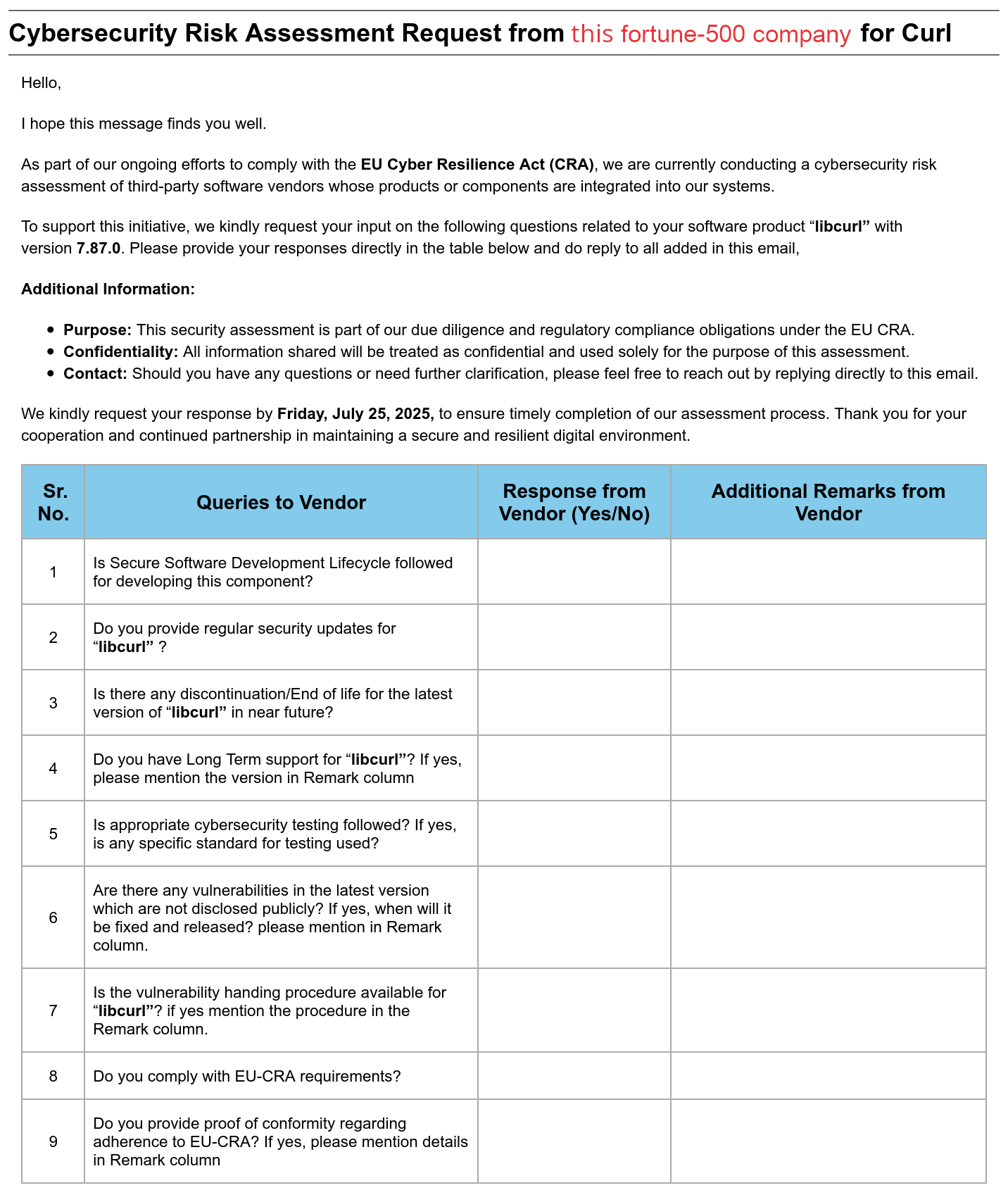
This multi-billion-dollar Fortune-500 company that I have no contract with and with which I have had no previous communication, sent me this email asking for a lot of curl information. A slightly redacted version is shown below.
Now that my curiosity has been satisfied a little bit I instead await the future and long to see how many more of these that will come. And how they will respond to my replies.
CRA_request_counter = 1;
The request
Hello,
I hope this message finds you well.
As part of our ongoing efforts to comply with the EU Cyber Resilience Act (CRA), we are currently conducting a cybersecurity risk assessment of third-party software vendors whose products or components are integrated into our systems.
To support this initiative, we kindly request your input on the following questions related to your software product “libcurl” with version 7.87.0. Please provide your responses directly in the table below and do reply to all added in this email,
Additional Information:
Purpose: This security assessment is part of our due diligence and regulatory compliance obligations under the EU CRA.
Confidentiality: All information shared will be treated as confidential and used solely for the purpose of this assessment.
Contact: Should you have any questions or need further clarification, please feel free to reach out by replying directly to this email.
We kindly request your response by Friday, July 25, 2025, to ensure timely completion of our assessment process. Thank you for your cooperation and continued partnership in maintaining a secure and resilient digital environment.
My reaction and response
I am not their vendor without having a more formal relationship established and I am certainly not going to spend a few hours of my spare time gathering a lot of information for them for free for their commercial benefit.
They “kindly” want me to respond within two weeks.
Their use of double quotes around “libcurl” feels odd, and they claim to be using a version that is now more than 2.5 years old.
Most if not all of the information they are asking for is already publicly and openly accessible and readable. I suspect they want the information in this more formal way to make it appear more reliable or trustworthy perhaps. Or maybe it just follows their processes better.
I will be happy to answer all curl and libcurl related questions and assist you with this inquiry as soon as we have a support contract setup. You can get the process started immediately by emailing support@wolfssl.com.
Thanks, I’m looking forward to future cooperation.
/ Daniel
I will let you know if they take me up on my offer .
The screenshot
This snapshot of how it looked also shows the actual nine-question form table.
Email screenshot
Why the company name is redacted
I’m looking forward to eventually do business with this company, I don’t want them to feel targeted or “ridiculed”. I also suspect that there will be many more emails like this going forward. The company name is not the interesting part of this story.
This is an intersection of two of my obsessions: graphs and vulnerability data for the curl project.
In order to track and follow every imaginable angle of development, progression and (possible) improvements in the curl project we track and log lots of metadata.
In order to educate and inform users about past vulnerabilities, but also as a means for the project team to find patterns and learn from past mistakes, we extract and document every detail.
Do we improve?
The grand question. Let’s get back to this a little later. Let’s first walk through some of the latest additions to the collection of graphs on the curl dashboard.
The here data is mostly based on the 167 published curl vulnerabilities to date.
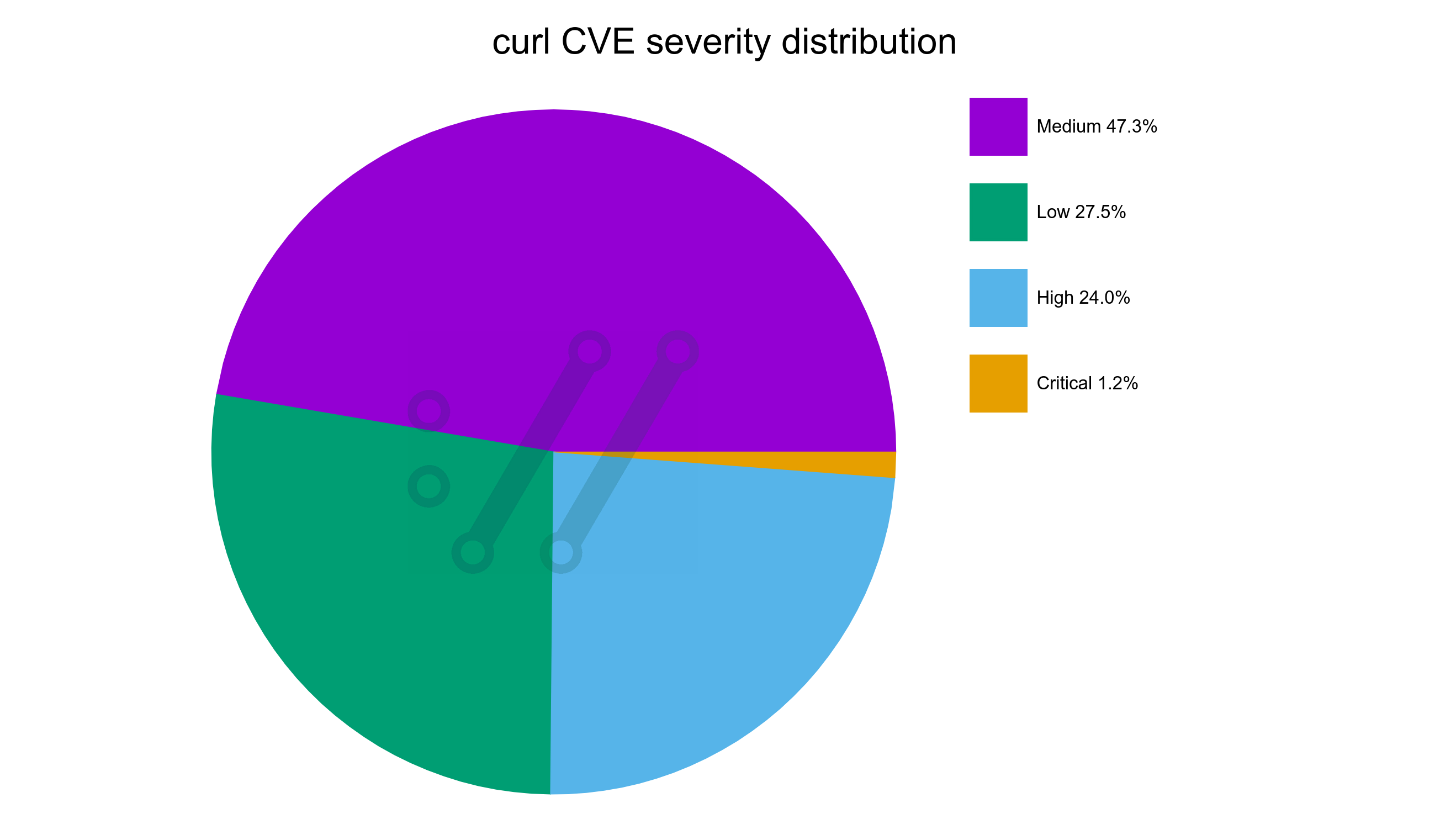
vulnerability severity distribution
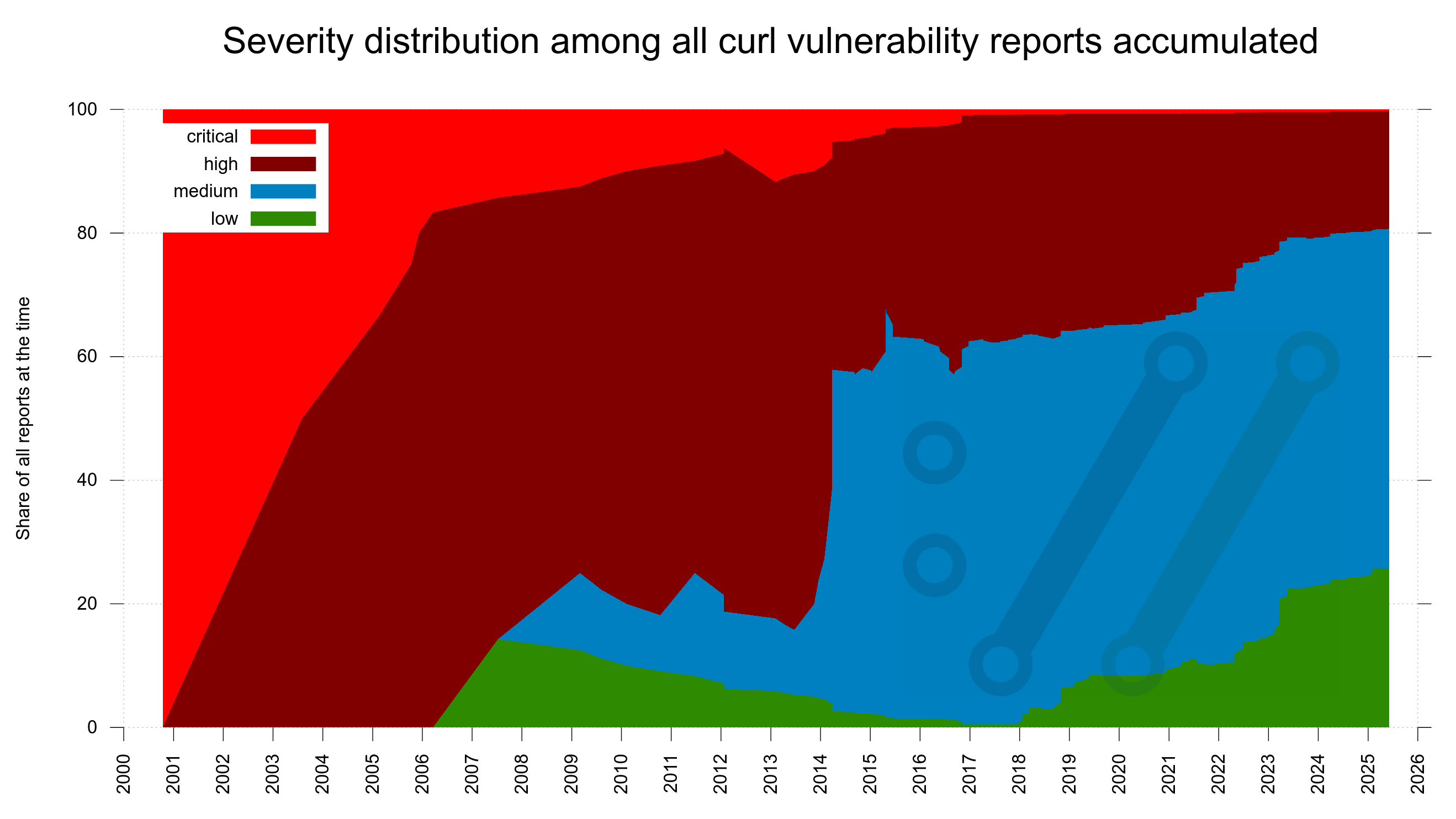
Twenty years ago, we got very few vulnerability reports. The ones we got were only for the most serious problems and lots of the smaller problems were just silently fixed without being considered anything else than bugs.
Over time, security awareness has become more widespread and nowadays many more problems are reported. Because people are more vigilant, more people are looking and problems are now more often considered security problems. In recent years also because we offer monetary rewards.
This development is clearly visible in this new graph showing the severity distribution among all confirmed curl vulnerabilities through time. It starts out with the first report being a critical one, adding only high severity ones for a few years until the first low appears in 2006. Today, we can see that almost half of all reports so far has been graded medium severity. The dates in the X-axis are when the reports were submitted to us.
Severity distribution among all curl vulnerability reports accumulated
curl CVE severity distribution July 2025
Severity distribution in code
One of the tricky details with security reports is that they tend to identify a problem that has existed in code already for quite some time. For a really long time even in many cases. How long you may ask? I know I did.
I created a graph to illustrate this data already years ago, but it was a little quirky and hard to figure out. What you learn after a while trying to illustrate data over time as a graph, is sometimes you need to try a few different ways and layouts before it eventually “speaks” to you. This is one of those cases.
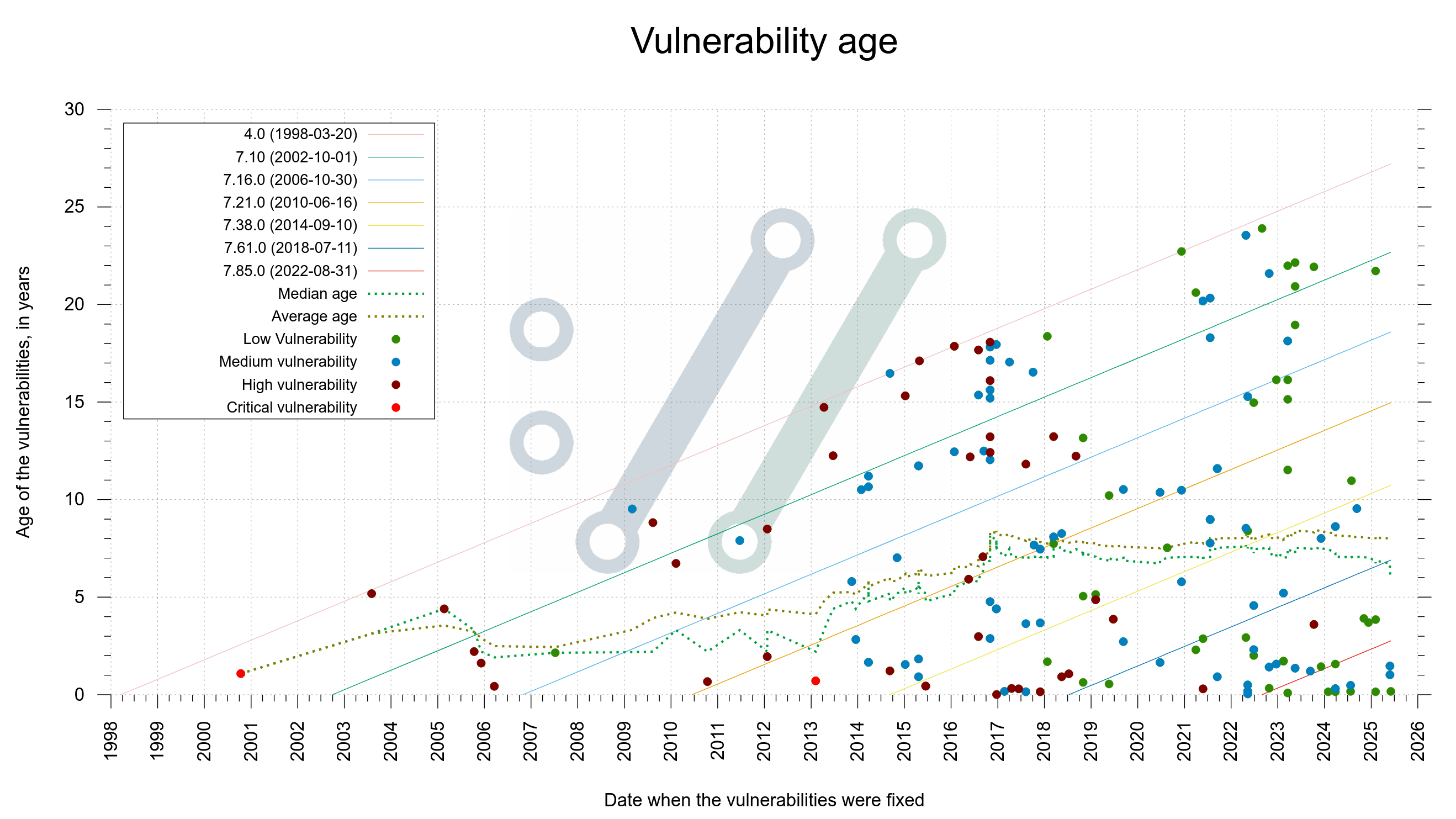
For every confirmed vulnerability report we receive, we backtrack and figure out exactly which the first release was that shipped the vulnerability. For the last decades we also identify the exact commit that brought it and of course the exact commit that fixed it. This way, we know the exact age of every vulnerability we ever had.
Hold on to something now, because here comes an information dense graph if there ever was one.
There is a dot in the graph for every known vulnerability
The X-axis is the date the vulnerability was fixed
The Y-axis is the number of years the flaw existed in code before we fixed it
The color of each dot indicates the severity level of the vulnerability (see the legend)
To guide the viewer, there is also a few diagonal lines. They show the release dates of a number of curl versions. I’ll explain below how they help.
Now, look at the graph here and I’ll continue below.
Vulnerability age
Yes, you are reading it right. If you count the dots above the twenty year line, you realize that no less than twelve of the flaws existed in code that long before found and fixed. Above the fifteen year line is almost too many to even count.
If you check how many dots that are close to the the “4.0” diagonal line, it shows how many bugs that have been found throughout the decades that were introduced in code not long after the initial curl release. The other diagonal lines help us see around which particular versions other bugs were introduced.
The green dotted median line we see bouncing around is drawn where there are exactly as many older reports as there are newer. It has hovered around seven years for several recent years but has fallen down to about six recently. Probably too early to tell if this is indeed a long-term evolution or just a temporary blip.
The average age is even higher, about eight years.
You can spot a cluster of fixed issues in 2016. It remains the year with most number of vulnerabilities reported and fixed in curl: 24. Partly because of a security audit.
A key take-away here is that vulnerabilities linger a long time before found. It means that whatever we change in code today, we cannot see the exact effect on vulnerability frequency until many years into the future. We can’t even know exactly how long time we need to tell for sure.
Current knowledge, applied to old data
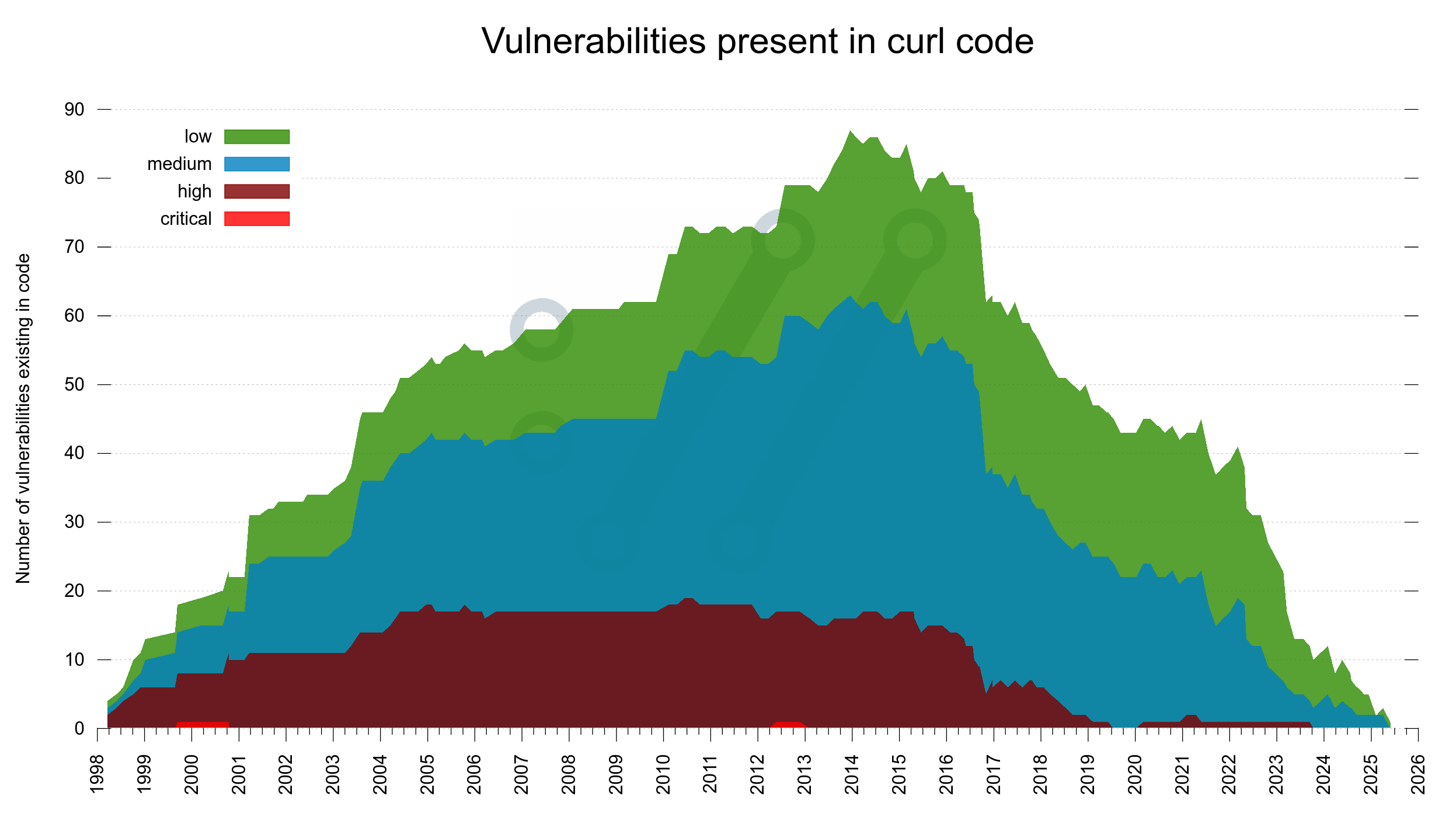
The older the projects gets, the more we learn about mistakes we did in the past. The more we realize that some of the past releases were quite riddled with vulnerabilities. Something nobody knew back then.
For every release ever made from the first curl release in 1998 we increase a counter for every vulnerability we now know was present. Make it a different color depending on vulnerability severity.
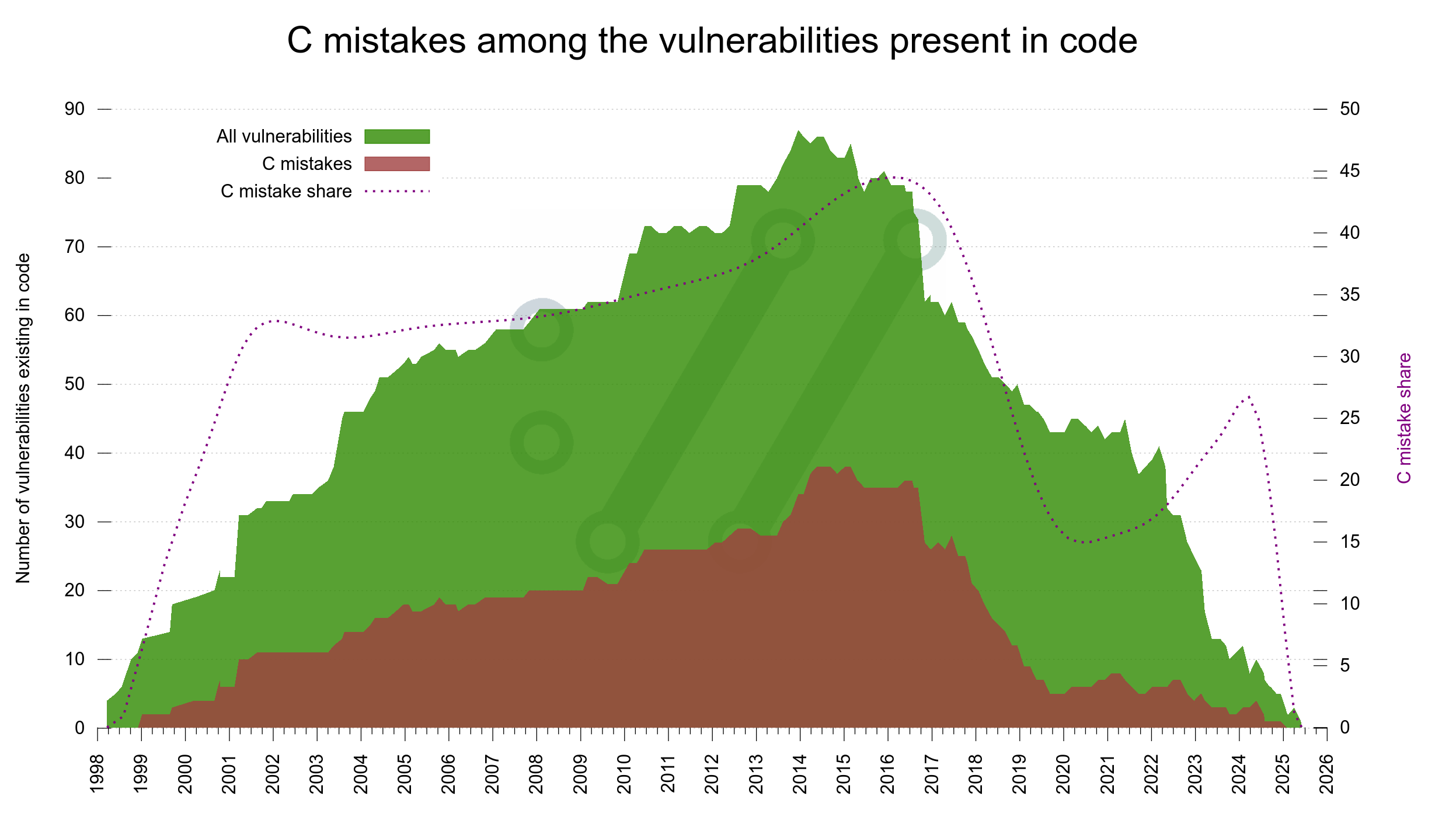
If we lay all this out in a graph, it becomes an interesting “mountain range” style look. In the end of 2013, we shipped a release that contained no less than (what we now know were) 87 security problems.
Vulnerabilities present in curl code
In this image we can spot that around 2017, the amount of high severity flaws present in the code decreased and they have been almost extinct since 2019. We also see how the two critical flaws thankfully only existed for brief periods.
However. Recalling that the median time for a vulnerability to exist before getting reported is six years, we know that there is a high probability that at least the rightmost 6-10 years of the graph is going to look differently when we redraw this same graph 6-10 years into the future. We simply don’t know how different it will be.
Did we do anything different in the project starting 2017? I have not been able to find any major distinct thing that stands out. We still only had a dozen CI builds but we started fuzzing curl that year. Maybe that is the change that is now visible?
C mistakes
curl is written in C and C is not a memory-safe language. People keep suggesting that we should rewrite it in other languages. In jest and for real. (Spoiler: we won’t rewrite it in any language.)
To get a feel for how much the language itself impacts our set of vulnerabilities, we analyze every flaw and assess if it is likely to have been avoided had we not used C. By manual review. This helps us satisfy our curiosity. Let me be clear that the mistakes are still ours and not because of the language. They are our mistakes that the language did not stop or prevent.
To also get a feel for how or if this mistake rate changes over time, I decided to use the same mountain layout as the previous graph: iterate over all releases and this time count the vulnerabilities they had and instead separate them only between C mistakes and not C mistakes. In the graph the amount of C mistakes is shown in a red-brown nuance.
C mistakes among the vulnerabilities present in code
The dotted line shows the share of the total that is C mistakes, and the Y axis for that is on the right side.
Again, since it takes six years to get half of the reports, we must take at least the rightmost side of the graph as temporary as it will be changed going forward.
The trend looks like we are reducing the share of C bugs though. I don’t think there is anything that suggests that such bugs would be harder to detect than others (quite the opposite actually) so even if we know the graph will change, we can probably say with some certainty that the C mistake rate has indeed been reduced the last six seven years? (See also writing C for curl on how we work consciously on this.)
Do we improve?
I think (hope?) we are, even if the graphs are still not reliably showing this. We can come back here in 2030 or so and verify. It would be annoying if we weren’t.
We do much more testing than ever: more test cases, more CI jobs with more build combinations, using more and better analyzer tools. Combined with concerned efforts to make us write better code that helps us reduce mistakes.
I’m pleased to announce that once again I have collected the results, generated the graphs and pondered over conclusions to make after the annual curl user survey.
I don’t think I spoil it too much if I say that there aren’t too many drastic news in this edition. I summed up ten key findings from it, but they are all more or less expected:
Linux is the primary curl platform
HTTPS and HTTP remain the most used protocols
Windows 11 is the most used Windows version people run curl on
32 bit x86 is used by just 7% of the users running curl on Windows
all supported protocols are used by at least some users
OpenSSL remain the most used TLS backend
libssh2 is the most used SSH backend
85% of respondents scored curl 5 out of 5 for “security handling”
Mastodon is a popular communication channel, and is wanted more
The median used curl version is just one version away from the latest
On the process
Knowing that it is quite a bit of work, it took me a while just to get started this time – but when I finally did I decided to go about it a little different this year.
This time, the twelfth time I faced this task, I converted the job into a programming challenge. I took it upon me to generate all graphs with gnuplot and write the entire document using markdown (and write suitable glue code for everything necessary in between). This way, it should be easier to reuse large portions of the logic and framework for future years and it also helped me generate all the graphs in more consistent and streamlined way.
The final report could then eventually be rendered into single page HTML and PDF versions with pandoc; using 100% Open Source and completely avoiding the use of any word processor or similar. Pretty nice.
As a bonus, this document format makes it super flexible and easy should we need to correct any mistakes and generate updated follow-up versions etc in a very clean way. Just like any other release.
It also struck me that we never actually created a single good place on the curl website for the survey. I thus created such a section on the site and made sure it features links to all the previous survey reports I have created over the years.
That new website section is what this blog post now points to for the 2025 analysis. Should thus also make it easier for any curious readers to find the old documents.
curl supports getting built with eleven different TLS libraries. Six of these libraries are OpenSSL or forks of OpenSSL. Allow me to give you a glimpse of their differences, similarities and some insights into what it takes to support them all.
SSLeay
It all started with SSLeay. This was the first SSL library I found out to exist and we added the first HTTPS support to curl using this library in the spring of 1998. Apparently the SSLeay project was started already back in 1995.
This was back in the days we still only had SSL; TLS would come later.
OpenSSL
This project was created (forked) from the ashes of SSLeay in late 1998 and curl supported it already from its start. SSLeay was abandoned.
OpenSSL always had a quirky, inconsistent and extremely large API set (a good chunk of that was inherited from SSLeay), that is further complicated by documentation that is sparse at best and leaves a lot to the users’ imagination and skill to dig through source code to get the last details answered (still today in 2025). In curl we keep getting occasional problems reported with how we use this library even decades in. Presumably this is the same for every OpenSSL user out there.
The OpenSSL project is often criticized for having dropped the ball on performance since they went to version 3 a few years back. They have also been slow and/or unwilling at adopt new TLS technologies like for QUIC and ECH.
In spite of all this, OpenSSL has become a dominant TLS library especially in Open Source.
LibreSSL
Back in the days of Heartbleed, the LibreSSL forked off and became its own. They trimmed off things they think didn’t belong in the library, they created their own TLS library API and a few years in, Apple ships curl on macOS using LibreSSL. They have some local patches on their build to make it behave differently than others.
LibreSSL was late to offer QUIC, they don’t support SSLKEYLOGFILE, ECH and generally seem to be even slower than OpenSSL to implement new things these days.
curl has worked perfectly with LibreSSL since it was created.
BoringSSL
Forked off by Google in the Heartbleed days. Done by Google for Google without any public releases they have cleaned up the prototypes and variable types a lot, and were leading the QUIC API push. In general, most new TLS inventions have since been implemented and supported by BoringSSL before the other forks.
Google uses this in Android and other places.
curl has worked perfectly with BoringSSL since it was created.
AmiSSL
A fork or flavor of OpenSSL done for the sole purpose of making it build and run properly on AmigaOS. I don’t know much about it but included it here for completeness. It seems to be more or less a port of OpenSSL for Amiga.
curl works with AmiSSL when built for AmigaOS.
QuicTLS
As OpenSSL dragged their feet and refused to provide the QUIC API the other forks did back in the early 2020s (for reasons I have yet to see anyone explain), Microsoft and Akamai forked OpenSSL and produced QuicTLS which has since tried to be a light-weight fork that mostly just adds the QUIC API in the same style BoringSSL and LibreSSL support it. Light-weight in the meaning that they were tracking upstream closely and did not intend to deviate from that in other ways than the QUIC API.
With OpenSSL3.5 they finally shipped a QUIC API that is different than the QUIC API the forks (including QuicTLS) provide. I believe this triggered QuicTLS to reconsider their direction going forward but we are still waiting to see exactly how. (Edit: see below for a comment from Rich Salz about this.)
curl has worked perfectly with QuicTLS since it was created.
AWS-LC
This is a fork off BoringSSL maintained by Amazon. As opposed to BoringSSL, they do actual (frequent) releases and therefore seem like a project even non-Amazon users could actually use and rely on – even though their stated purpose for existing is to maintain a secure libcrypto that is compatible with software and applications used at AWS. Strikingly, they maintain more than “just” libcrypto though.
The API AWS-LC offers is not identical to BoringSSL’s.
curl works perfectly with AWS-LC since early 2023.
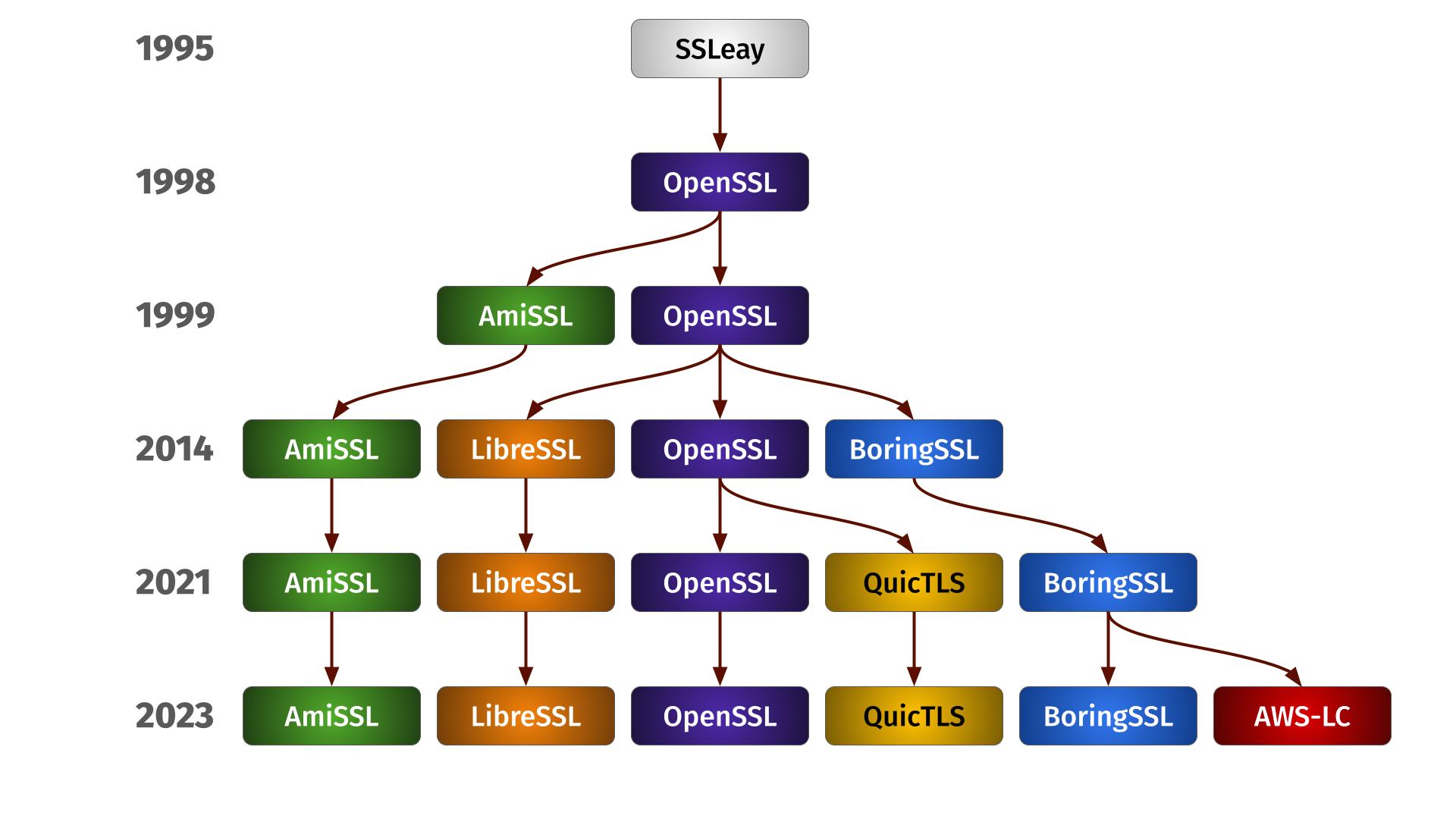
Family Tree
The OpenSSL fork family tree
The family life
Each of these six different forks has its own specifics, APIs and features that also change and varies over their different versions. We remain supporting these six forks for now as people still seem to use them and maintenance is manageable.
We support all of them using the same single source code with an ever-growing #ifdef maze, and we verify builds using the forks in CI – albeit only with a limited set of recent versions.
Over time, the forks seem to be slowly drifting apart more and more. I don’t think it has yet become a concern, but we are of course monitoring the situation and might at some point have to do some internal refactors to cater for this.
Future
I can’t foresee what is going to happen. If history is a lesson, we seem to rather go towards more forks rather than fewer, but every reader of this blog post of course now ponders over how much duplicated efforts are spent on all these forks and the implied inefficiencies of that. On the libraries themselves but also on users such as curl.
In the curl project we have a long tradition of supporting a range of different third party libraries that provide similar functionality. The person who builds curl needs to decide which of the backends they want to use out of the provided alternatives. For example when selecting which TLS library to use.
This is a fundamental and appreciated design principle of curl. It allows different users to make different choices and priorities depending on their use cases.
Up until May 2025, curl has supported thirteen different TLS libraries. They differ in features, footprint, speed and licenses.
Raising the bar
We implicitly tell the user that you can use one of the libraries from this list to get good curl functionality. The libraries we support have met our approval. They passed the tests. They are okay.
As we support a large number of them, we can raise the bar and gradually increase the requirements we set for them to remain approved. For the good of our users. To make sure that the ones we support truly are good quality choices to build upon – ideally for years to come.
TLS 1.3
The latest TLS version is called TLS 1.3 and the corresponding RFC 8443 was published in August 2018, almost seven years ago. While there are no known major problems or security issues with the predecessor version 1.2, a modern TLS library that has not yet implemented and provide support for TLS 1.3 is a laggard. It is behind.
We take this opportunity to raise the bar and say that starting June 2025, curl only supports TLS libraries that supports TLS 1.3 (in their modern versions). The first curl release shipping with this change is the pending 8.15.0 release, scheduled for mid July 2025.
This move has been announced, planned and repeatedly communicated for over a year. It should not come as a surprise, even if I have no doubt that this will be considered a such by some.
This makes sure that users and applications that decide to lean on curl are more future-proof. We no longer recommend using one of the laggards.
Removed
This action affects these two specific TLS backends:
BearSSL
Secure Transport
BearSSL
This embedded and small footprint focused library is probably best replaced by wolfSSL or mbedTLS.
Secure Transport
This is a native library in Apple operating systems that has been deprecated by Apple themselves for a long time. There is no obvious native replacement for this, but we probably recommend either wolfSSL or an OpenSSL fork. Apple themselves have used libreSSL for their curl builds for a long time.
The main feature user might miss from Secure Transport that is not yet provided by any other backend, is the ability to use the native CA store on the Apple operating systems – iOS, macOS etc. We expect this feature to get implemented for other TLS backends soon.
Network framework
On Apple operating systems, there is a successor to Secure Transport: the Network framework. This is however much more than just a TLS layer and because of their design decisions and API architecture it is totally unsuitable for curl’s purposes. It does not expose/use sockets properly and the only way to use it would be to hand over things like connecting, name resolving and parts of the protocol management to it, which is totally unacceptable and would be a recipe for disaster. It is therefore highly unlikely that curl will again have support for a native TLS library on Apple operating systems.
Eleven remaining TLS backends in curl
In the order we added them.
OpenSSL
GnuTLS
wolfSSL
SChannel
libressl – an OpenSSL fork
BoringSSL – an OpenSSL fork
mbedTLS
AmiSSL – an OpenSSL fork
rustls
quictls – an OpenSSL fork
AWS-LC – an OpenSSL fork
Eight removed TLS backends
With these two new removals, the set of TLS libraries we have removed support for over the years are, in the order we removed them:
QsoSSL
axTLS
PolarSSL
MesaLink
NSS
gskit
BearSSL
Secure Transport
Going forward
Currently we have no plans for removing support for any other TLS backends, but we will of course reserve ourselves the right to do so when we feel the need, for the good of the project and our users.
We similarly have no plans to add support for any additional TLS libraries, but if someone would bring such work to the project for one of the few remaining quality TLS libraries that exist that curl does not already support, then we would most probably welcome such an effort.
The curl project is an independent Open Source project. Our ambition is to do internet transfers right and securely with the features “people” want. But how do we know if we do this successfully or not?
Possibly one rough way to measure if users are happy would be to know if the number of users go up or down.
How do we know?
Number of users
We don’t actually know how many users we have – which devices, tools and services that are powered by our code. We don’t know how many users install curl. We also don’t know how many install it and then immediately uninstall it again because there is something about it they don’t like.
Most of our users install curl and libcurl from a distribution, unless they already had it installed there from the beginning without them having to do anything. They don’t download anything from us. Most users likely never visit our website for any purpose.
No telemetry nor logs
We cannot do and will never try to do any kind of telemetry in the command line tool or library, so there is no automated way we can actually know how much any of them are used unless we are told explicitly.
We can search the web, guess and ask around.
Tarball downloads
We can estimate how many people download the curl release tarballs from the website every month, but that is a nearly useless number without meaning. What does over a million downloads per month mean in this context? Presumably a fair share of these are just repeated CI jobs.
A single download of a curl tarball be used to build curl for a long time, for countless products and get installed in several billions of devices or never get used anywhere. Or somewhere in between. We will never know.
GitHub
Our GitHub repository has a certain amount of stars. This number does not mean anything as just a random subset of developers ever see it, and just some of those decide to do the rather meaningless act of staring it. The git repository has been forked on GitHub several thousand times but that’s an almost equally pointless number.
We can get stats for how often our source code git repository is cloned, but then again that number probably gets heavily skewed as CI use of it goes up and down.
Binary downloads
We offer curl for Windows binaries but since we run a website entirely without logs, those downloads are bundled with the tarballs in our rough stats. We only know how many objects in the 1M-10M size range are downloaded over a period of time. Besides, Windows ships with curl bundled so most Windows users never download anything from us.
We provide curl containers and since they are hosted by others, we can get some “pull” numbers. They mostly tell us people use the containers – but growing and shrinking trends don’t help us much as we don’t know who or why.
Ecosystems
Because how libcurl is a fairly low-level C library, it is usually left outside of all ecosystems. With most infrastructure tooling for listing, counting and tracking dependencies etc, libcurl is simply left out and invisible. As if it is not actually used. Presumably just assumed to be part of the operating system or something.
These tools are typically done for Python, Node, Java, Rust, Perl, etc ecosystems where dependencies are easy to track via their package systems. Therefore, we cannot easily check how many projects or products that depend on libcurl with these tools. Because that number would be strangely low.
Users
I try to avoid talking about number of users because for curl and libcurl I can’t really tell what a user is. curl is used directly by users, sure, but it is also used in countless scripts that run without a user directly running it.
libcurl is used many magnitudes more than the curl tool, and that is a component built-in into devices, tools and services that often operate independent of users being present.
Installations
I tend to make my (wild) guesses on number of (lib)curl installations even though that is also highly error-prone.
I don’t know even nearly all the tools, games, devices and services that use libcurl because most of them never tell me or anyone else. They don’t have to. If we find out while searching the web or someone points us to a credit mention then we know. Otherwise we don’t.
I don’t know how many of those libcurl using applications exist in the world. New versions come, old versions die.
The largest volume libcurl users are most probably the mobile phones: libcurl is part of the operating systems in Apple’s iOS and in both Google’s and Samsung’s default Android setup. Probably in a few of the other popular Androids as well.
Since the libcurl API is not exposed by the mobile phone operating systems, a large amount of mobile phone applications subsequently build their own libcurl and ship with their apps, on both iOS and Android. This way, a single mobile phone can easily contain a dozen different libcurl installations, depending on exactly what set of apps that are used.
There is an estimated seven billion smart phones and one billion tablets in the world. Do they all have five applications on average that bundle libcurl? Who knows. If they do, that makes roughly eight billion times six installations.
Also misleading
Staring on and focusing that outrageously large number is also complicated and may not be a particularly good indicator that we are on the right path. So ten or perhaps forty-eight billion libcurl installations are controlled and done by basically just a handful of applications and companies. Should some of them switch over to an alternative the number would dwindle immediately. And similarly if we get twice that amount of new users but on low volume installations (compared to smart phones everything is low volume), the total number of installations won’t really change, but we may have more satisfied users.
Maybe the best indicator of us keeping on the right track is the number of different users or applications that are using libcurl and then we would count Android, iOS and the mobile YouTube application as three. Of course we have no means to even guess how many different users there are. That’s again also a very time-specific question as maybe there are a few new since yesterday and tomorrow a few existing users may ditch libcurl for something else.
We just don’t know and we can’t tell. With no expectations of this to change.
Success
In many ways this is of course a success beyond our wildest dreams and a luxury position many projects only dream of. Don’t read this blog post as a complaint in any way. It just describes a challenge and reality.
The old fashioned way
With no way to automatically or even half-decently guess how we are doing, we instead do it the old way. We rely on users to tell us what they think. We work on issues, we respond to questions and we do an annual survey. We try to be open for feedback and listen in how people and users want modern internet transfers done.
We make an effort to ship quality products and run a tight ship. To score top scores in all and every way you can evaluate a software project and our products.
Hopefully this will keep us on the right track. Let me know if you ever think we veer off.
This is a patch-release done only a week since the previous version with no changes merged only bugfixes. Because some of the regressions in 8.14.0 were a little too annoying to leave unattended for a full cycle.
Release presentation
Numbers
the 268th release 0 changes 7 days (total: 9,938) 35 bugfixes (total: 12,049) 48 commits (total: 35,238) 0 new public libcurl function (total: 96) 0 new curl_easy_setopt() option (total: 308) 0 new curl command line option (total: 269) 20 contributors, 4 new (total: 3,431) 9 authors, 1 new (total: 1,376) 1 security fix (total: 167)
Security
CVE-2025-5399: WebSocket endless loop. A malicious WebSocket server can send a particularly crafted packet which makes libcurl get trapped in an endless busy-loop. Severity LOW.
The time has come for you to once again do your curl community duty. Run over and fill in the curl user survey and tell us about how you use curl etc. This is the only proper way we get user feedback on a wide scale so please use this opportunity to tell us what you really think.
This is the 12th time the survey runs. It is generally similar to last year’s but with some details updated and refreshed.
The survey stays up for fourteen days. Tell your friends.
On the completely impossible situation of blocking the Tor .onion TLD to avoid leaks, but at the same time not block it to make users able to do what they want.
dot-onion leaks
The onion TLD is a Tor specific domain that does not mean much to the world outside of Tor. If you try to resolve one of the domains in there with a normal resolver, you will get told that the domain does not exist.
If you ask your ISP’s resolver for such a hostname, you also advertise your intentions to speak with that domain to a sizeable portion of the Internet. DNS is inherently commonly insecure and has a habit of getting almost broadcast to lots of different actors. A user on this IP address intends to interact with this .onion site.
It is thus of utter importance for Tor users to never use the normal DNS system for resolving .onion names.
Remedy: refuse them
To help preventing DNS leaks as mentioned above, Tor people engaged with the IETF and the cooperation ultimately ended up with the publication of RFC 7686: The “.onion” Special-Use Domain Name. Published in 2015.
This document details how libraries and software should approach handling of this special domain. It basically says that software should to a large degree refuse to resolve such hostnames.
Eight years later the issue was still lingering in that document and curl had still not done anything about it, when Matt Jolly emerged from the shadows and brought a PR that finally implemented the filtering the RFC says we should do. Merged into curl on March 30, 2023. Shipped in the curl 8.1.0 release that shipped in May 17, 2023. Two years ago.
Since that release, curl users would not accidentally leak their .onion use.
A curl user that uses Tor would obviously use a SOCKS proxy to access the Tor network like they always have and then curl would let the Tor server do the name resolving as that is the entity here that knows about Tor and the dot onion domain etc.
That’s the thing with using a proxy like this. A network client like curl can hand the full host name to the proxy server and let that do the resolving magic instead of it being done by the client. It avoids leaking names to local name resolvers.
Controversy
It did not take long after curl started support the RFC that Tor themselves had pushed for, when Tor users with creative network setups realized and had opinions.
A proposal appeared to provide an override of the filter based on an environment variable for users who have a setup where the normal name resolver is already protected somehow and is known to be okay. Environment variables make for horrible APIs and the discussion did not end up in any particular consensus for other solutions so this suggestion did not make it through into code.
This issue has subsequently popped up a few more times when users have had some issues, but no fix or solution has been merged. curl remains blocking this domain. Usually people realize that when using the SOCKS proxy correctly, the domain name works as expected and that has then been the end of the discussions.
oniux
This week the Tor project announced a new product of their: oniux: a command-line utility providing Tor network isolation for third-party applications using Linux namespaces.
On their introductory web page explaining this new tool they even show it off using a curl command line:
(I decided to shorten the hostname here for illustration purposes.)
Wait a second, isn’t that a .onion hostname in that URL? Now what does curl do with .onion host names since that release two years ago?
Correct: that illustrated command line only works with old curl versions from before we implemented support for RFC 7686. From before we tried to do in curl what Tor indirectly suggested we should do. So now, when we try to do the right thing, curl does not work with this new tool Tor themselves launched!
At least we can’t say we get do live a dull life.
Hey this doesn’t work!
No really? Tell us all about it. Of course there was immediately an issue submitted against curl for this, quite rightfully. That tool was quite clearly made for a use case like this.









{kind=link}