I’m a firm believer in the old unix mantra of letting each tool do its job and do it well, and pass on the rest of the work to the next tool. I’ve always stated that curl should remain this way and that it should remain within its defined walls and not try to do everything.
But time passes and more and more ideas are thrown up in the air, or in some cases directly at me, and the list of things that we could do but don’t due to this philosophical limit of remaining focused has grown. It currently includes at least:
metalink support
recursive HTML downloads
recursive/wildcard FTP transfers
bittorrent support
automatic proxy configuration
simultaneous/parallel download support
Educated readers of course immediately detect that this list (if implemented) would make a tool that basically does what wget already does (and a lot more) and I’ve explicitly said for a decade that curl is not a wget clone. Maybe it is time for us (me?) to reevaluate that sentiment – at least in some sense.
I don’t want to sacrifice the concepts that have worked so fine for curl under so many years, so I’m still firmly against stuffing all this into curl (or libcurl). That simply will not happen with me at the wheel.
A much more interesting alternative would be to instead start working on a second tool within the curl project: murl. A tool that does basically everything that curl already does, but also opens the doors for adding just about everything else we can cram in and that is still related to data transfers. That would include, but not be restricted to, all the fancy stuff mentioned in the list above!
No the name murl is not set in stone, nor is this whole idea anything but plain and early thoughts thrown out at this point so it may or may not actually take off. It will probably depend on if I get support and help from fellow hackers to get started and moving along.
It’s been a while since we had this discussion so I figure it is about time to re-iterate it and this time I thought I’d do a little blog post to put the lights on my stand-point regarding this issue:
I’ve had this discussion at length with Anthony Bryan (the main man behind the metalink format) privately in the past and I’ve bounced back a lot of feedback on the actual XML format to him and I believe some of that were taken into account and changed the format. Of course this was before it “settled” and started to get adopted. I think metalink is a great idea and the file format is (the last time I checked it out, I can’t seem to find the docs now) mostly making sense.
I have little to no understanding for the idea that libcurl should add support for this natively. metalink is just an XML format that sets up resources for an application to where and how it can download files, and libcurl does indeed support most of the protocols that such URLs can use. libcurl is a data transfer library that is oriented around a given URL and the URL in question has a 1:1 relationship to what protocol it is and it is always content-agnostic.
metalink is application layer, not transport. Adding metalink to libcurl would mean that all of a sudden libcurl would transfer a file and actually parse the (XML!) contents of that file and then get (possibly) multiple streams using multiple protocols based on what that parsing gave. It is just so many new things and violations against key libcurl concepts that I cannot see this done.
Metalink isn’t even a standard so we would then more or less open the gates for further random efforts to introduce similar ideas and whatnot and where would we draw the line? Currently I think we have a pretty solid border drawn in the sand and we don’t cross that line (on purpose).
And frankly, there is only one and one reason only (mentioned and that I can think of) for libcurl to support this feature and I that is because libcurl is already widely adopted it would be easier for metalink to conquer the world by sneaking in the back-door with libcurl as then a large amount of applications would support it with no additional efforts at all. But sorry, I don’t think that’s a good enough reason to break or change these important key concepts/limits of libcurl. (Actually, I think it is a bit foolish to think that adding metalink to libcurl would make all these applications automatically support metalink as there would be several arguments against that too.)
As I’ve said before, I think one of our biggest challenges in this project is to limit what libcurl does, to not allow it to grow in all directions, to keep the scope and to maintain focus.
A metalink file transfer library could be made as a layer on top of libcurl, and I think that is the only logical and sensible way.
Adding metalink support to the curl tool however, seems like a good idea to me…
On March 20th 1998 curl 4 was released. It was the first curl release ever even if already at version 4 since we kept the version number from the previous projects we did before curl – using other names. We started it all with having the tool named httpget (which was an existing small tool written by Rafael Sagula), soon changed name to urlget to end up with curl – all renames happening due to shifting features and focus.
Like many other projects, this started because of an itch. I wanted to get currency rates off the internet to allow an IRC bot to be able to provide an “exchange service” for users with accurate up-to-date rates. I thought the existing projects I found all did too much or did the wrong thing. That bot and service is now gone since long.
curl has been a truly portable project from day 1, and the first windows build was already urlget 2.1 (pre-curl). autoconf support for the build process was added in October 1998.
Unfortunately I don’t have the original release 4 tarball left anymore, the closest one I have is curl 4.8 (dated August 31 1998). curl 4.8 is about 3400 lines of code. Today we’re totaling in well over 100K source lines, so it has grown over 30 times!
I had no big plans for curl nor did I think very much about the future of the project. I just added the features I and my fellow contributors wanted to have for the moment. That’s actually pretty much how the project has continued to work. We don’t have many long-term plans for what to do with it, we mostly look just inches ahead of our noses and act accordingly.
During the version 6 period (Sep 1999 – Mar 2000) we learned that curl was getting popular, was useful and worked rather well, so the work on providing a libcurl started. We wanted to offer other applications the ability to use curl’s file transfer powers. Version 7.1 was released in August 2000 and thus libcurl was officially born.
curl and libcurl remained being a rather low-key project, I just work on it on my spare time and there are no full-time developers paid to work on this project – apart from some occasional sub-projects now and then that have been sponsored by companies and organizations. (See later on for an example.)
Slowly but surely more and more people started using libcurl and contributed with bug reports and patches. When the project turned 5 years in 2003 I collected all the names of all contributors so far and I reached the number 270. I found the number very high and I was mostly kidding when I said I hoped we would double that amount by the time we celebrate our tenth anniversary. Of course we’ve more than doubled that amount today when we have more than 620 named contributors so far – and continuously adding new ones with every release.
During this journey of a decade, I’ve remained the lead developer and project leader but we’re now some 10 developers with commit access (that also use it) and I try to be open and responsive in order to attract more developers to come aboard, to listen to their advice and ideas and to be sensitive on what our users want from us.
In 2005 I was lucky enough to get a grant from the Swedish IIS organization for the purpose of developing a new event-based API for libcurl to better deal with very large amount of connections, the problem so nicely called c10k.
In the days when our humble project turns 10, I spend about two hours spare time per day on the project and it is my primary hobby, we make 5-6 releases per year, we get about 7000 unique visitors on the web site a normal day, about one million curl packages are downloaded per year – from our servers.
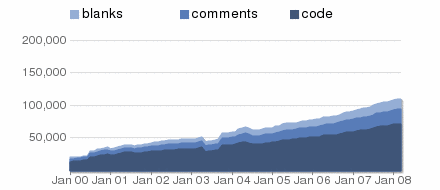
Today, libcurl is feature-rich, portable, very widely used, very fast, well supported and there are no signs of stagnation in release nor development pace. In fact, looking at the source-code growth over the last couple of years we can see a pretty stable and continuous growth:
Just as I never looked ahead and planned for the future much in the past, I don’t do that now either so I really don’t know and can’t tell what the future will hold for us. We’ll just continue to develop the world’s best client-side file transfer library, to make it even more solid for the foreseeable future, to make it do the things users and developers out there think it should do. Possibly that involves adding support for more protocols, removing some of the less popular ones or simply by enhancing how we support the existing ones.
Join the mailing lists and join us for the next ten years to come!
yassl is a (in comparison) small SSL/TLS library that libcurl can be built to use instead of using one of the other SSL/TLS libraries libcurl supports (OpenSSL, GnuTLS, NSS and QSSL). However, yassl differs somewhat from the others in the way that it provides an OpenSSL-emulating API layer so that in libcurl we pretty much use exactly the same code for OpenSSL as we do for yassl.
yassl claimed this libcurl support for several years ago and indeed libcurl builds fine with it and you can even do some basic SSL operations with it, but the emulation is just not good enough to let the curl test suite go through so lots of stuff breaks when libcurl is built with yassl.
I did this same test 15 months ago and it had roughly the same problems then.
As far as I know, the other three main libraries are much more stable (the QSSL/QsoSSL library is only available on the AS/400 platform and thus I don’t personally know much about how it performs) and thus they remain the libraries I recommend users to select from if they want something that’s proven working.
I did my share of Java bashing just a short while ago, so it is a bit ironic that just days afterwards the topic of the java binding for libcurl resurfaced, and now it seems both Günter and Patrick (libcurl hacker dudes) are working to get it in shape to actually again end up in a useful state.
What I find a bit annoying with this situation, is that I’m using Debian unstable and I’m dist-upgrading fairly frequently to be able to run on the bleeding edge and yet I don’t have the equivalent NSS version Fedora has and what’s perhaps worse is: I don’t even know how to get it and build my own local version! Is Fedora using their own patched version of this (rhetorical question as I’m quite sure they are)? Is it possible to get that version or patch so that I can build it and test on my non- Fedora development machine(s) ?
So, even though it really isn’t my problem or my issue to deal with, I couldn’t even try out his problem on my own!
Readers of my blog or my site or almost whatever on the internet where my name would appear should know that two of my primary open source involvements are in the curl and the Rockbox projects.
Therefore I felt great pleasure yesterday when both of these worlds collided!
While investigating the internals of the SanDisk Sansa Connect mp3 player for the Rockbox project, fellow Robert Keevil discovered that it actually includes… libcurl! (actually, he discovered this before but I only realized it yesterday)