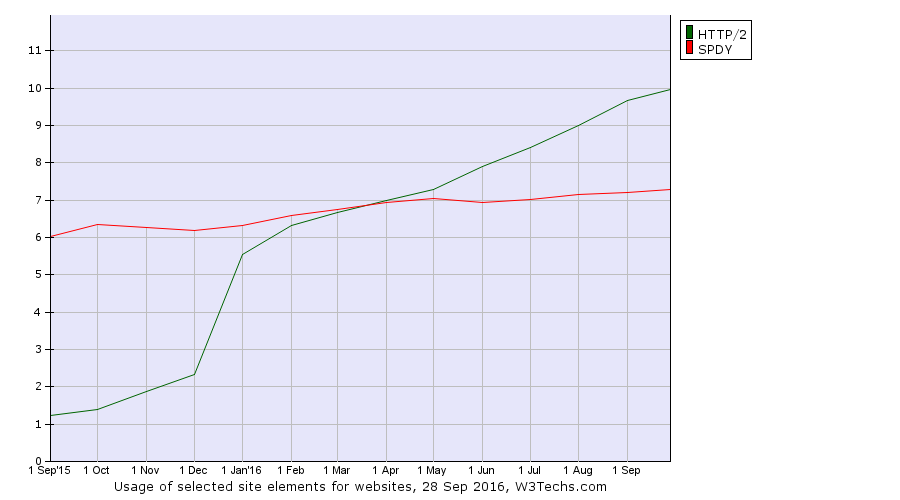
 The protocol HTTP/2 as defined in the draft-17 was approved by the IESG and is being implemented and deployed widely on the Internet today, even before it has turned up as an actual RFC. Back in February, already upwards 5% or maybe even more of the web traffic was using HTTP/2.
The protocol HTTP/2 as defined in the draft-17 was approved by the IESG and is being implemented and deployed widely on the Internet today, even before it has turned up as an actual RFC. Back in February, already upwards 5% or maybe even more of the web traffic was using HTTP/2.
My prediction: We’ll see >10% usage by the end of the year, possibly as much as 20-30% a little depending on how fast some of the major and most popular platforms will switch (Facebook, Instagram, Tumblr, Yahoo and others). In 2016 we might see HTTP/2 serve a majority of all HTTP requests – done by browsers at least.
Counted how? Yeah the second I mention a rate I know you guys will start throwing me hard questions like exactly what do I mean. What is Internet and how would I count this? Let me express it loosely: the share of HTTP requests (by volume of requests, not by bandwidth of data and not just counting browsers). I don’t know how to measure it and we can debate the numbers in December and I guess we can all end up being right depending on what we think is the right way to count!
Who am I to tell? I’m just a person deeply interested in protocols and HTTP/2, so I’ve been involved in the HTTP work group for years and I also work on several HTTP/2 implementations. You can guess as well as I, but this just happens to be my blog!
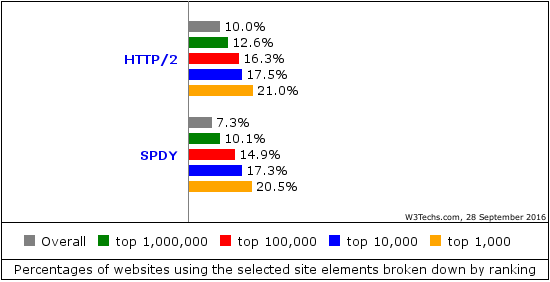
The HTTP/2 Implementations wiki page currently lists 36 different implementations. Let’s take a closer look at the current situation and prospects in some areas.
Browsers
Firefox and Chome have solid support since a while back. Just use a recent version and you’re good.
Internet Explorer has been shown in a tech preview that spoke HTTP/2 fine. So, run that or wait for it to ship in a public version soon.
There are no news about this from Apple regarding support in Safari. Give up on them and switch over to a browser that keeps up!
Other browsers? Ask them what they do, or replace them with a browser that supports HTTP/2 already.
My estimate: By the end of 2015 the leading browsers with a market share way over 50% combined will support HTTP/2.
Server software
Apache HTTPd is still the most popular web server software on the planet. mod_h2 is a recent module for it that can speak HTTP/2 – still in “alpha” state. Give it time and help out in other ways and it will pay off.
Nginx has told the world they’ll ship HTTP/2 support by the end of 2015.
IIS was showing off HTTP/2 in the Windows 10 tech preview.
H2O is a newcomer on the market with focus on performance and they ship with HTTP/2 support since a while back already.
nghttp2 offers a HTTP/2 => HTTP/1.1 proxy (and lots more) to front your old server with and can then help you deploy HTTP/2 at once.
Apache Traffic Server supports HTTP/2 fine. Will show up in a release soon.
Also, netty, jetty and others are already on board.
HTTPS initiatives like Let’s Encrypt, helps to make it even easier to deploy and run HTTPS on your own sites which will smooth the way for HTTP/2 deployments on smaller sites as well. Getting sites onto the TLS train will remain a hurdle and will be perhaps the single biggest obstacle to get even more adoption.
My estimate: By the end of 2015 the leading HTTP server products with a market share of more than 80% of the server market will support HTTP/2.
Proxies
Squid works on HTTP/2 support.
HAproxy? I haven’t gotten a straight answer from that team, but Willy Tarreau has been actively participating in the HTTP/2 work all the time so I expect them to have work in progress.
While very critical to the protocol, PHK of the Varnish project has said that Varnish will support it if it gets traction.
My estimate: By the end of 2015, the leading proxy software projects will start to have or are already shipping HTTP/2 support.
Services
Google (including Youtube and other sites in the Google family) and Twitter have ran HTTP/2 enabled for months already.
Lots of existing services offer SPDY today and I would imagine most of them are considering and pondering on how to switch to HTTP/2 as Chrome has already announced them going to drop SPDY during 2016 and Firefox will also abandon SPDY at some point.
My estimate: By the end of 2015 lots of the top sites of the world will be serving HTTP/2 or will be working on doing it.
Content Delivery Networks
Akamai plans to ship HTTP/2 by the end of the year. Cloudflare have stated that they “will support HTTP/2 once NGINX with it becomes available“.
Amazon has not given any response publicly that I can find for when they will support HTTP/2 on their services.
Not a totally bright situation but I also believe (or hope) that as soon as one or two of the bigger CDN players start to offer HTTP/2 the others might feel a bigger pressure to follow suit.
Non-browser clients
curl and libcurl support HTTP/2 since months back, and the HTTP/2 implementations page lists available implementations for just about all major languages now. Like node-http2 for javascript, http2-perl, http2 for Go, Hyper for Python, OkHttp for Java, http-2 for Ruby and more. If you do HTTP today, you should be able to switch over to HTTP/2 relatively easy.
More?
I’m sure I’ve forgotten a few obvious points but I might update this as we go as soon as my dear readers point out my faults and mistakes!
How long is HTTP/1.1 going to be around?
My estimate: HTTP 1.1 will be around for many years to come. There is going to be a double-digit percentage share of the existing sites on the Internet (and who knows how many that aren’t even accessible from the Internet) for the foreseeable future. For technical reasons, for philosophical reasons and for good old we’ll-never-touch-it-again reasons.
The survey
Finally, I asked friends on twitter, G+ and Facebook what they think the HTTP/2 share would be by the end of 2015 with the help of a little poll. This does of course not make it into any sound or statistically safe number but is still just a collection of what a set of random people guessed. A quick poll to get a rough feel. This is how the 64 responses I received were distributed:

Evidently, if you take a median out of these results you can see that the middle point is between 5-10 and 10-15. I’ll make it easy and say that the poll showed a group estimate on 10%. Ten percent of the total HTTP traffic to be HTTP/2 at the end of 2015.
I didn’t vote here but I would’ve checked the 15-20 choice, thus a fair bit over the median but only slightly into the top quarter..
In plain numbers this was the distribution of the guesses:
| 0-5% |
29.1% (19)
|
| 5-10% |
21.8% (13)
|
| 10-15% |
14.5% (10)
|
| 15-20% |
10.9% (7)
|
| 20-25% |
9.1% (6)
|
| 25-30% |
3.6% (2)
|
| 30-40% |
3.6% (3)
|
| 40-50% |
3.6% (2)
|
| more than 50% |
3.6% (2)
|






 Initially on Windows only
Initially on Windows only

 On November 28, the HTTPbis group within the IETF published the
On November 28, the HTTPbis group within the IETF published the