I attended FOSDEM 2023 and over the two days of conference I gave away well over a thousand curl stickers. Every last curl sticker I had in my possession.
What does a curl maintainer do when he runs out of curl stickers? He restocks.
5400 stickes and 200 coasters arrived in a box.
Many stickers.
Two new sticker designs in a limited edition.
Getting stickers
Right now, the only way to get your hands on a set of these fine quality stickers is to meet me. Attend a talk that I do or a conference that I visit.
I might do another attempt at distributing stickers at a later point, but the last time did leave some scars I still haven’t gotten over!
My desktop computer is my trusted work machine that I do the majority of all my (curl) development on. When the 15th computer I’ve owned through the times was ten years old the time was ripe to bump things up a notch.
Requirements
I don’t do games (as in: never) and I don’t do any other 3D stuff. I just need my two 4K monitors to display my desktops and browser windows fine.
In my ordinary days I compile C code and I run tests. CPU and memory will be used to build and test faster and to be able to run separate VM runtimes in parallel without problems. I rarely even build very large or complicated software projects. (The days of building Firefox are long gone…)
Ideally, this upgrade will last for a long time again so I’ve tried to push it a little to increase those chances.
New machine
This new baby is (of course) built from components and I’ve relied heavily on advice, research and help by my brother Björn for this.
CPU
I’m a sucker for maximum single-thread performance. Lots of things I do still run in single-threaded in a single core so I think this is good for me.
The Intel Core i7-13700K at 3.4 GHz is benchmarked at a CPU Mark that is over 7 times faster than the CPU of my old machine. 16 cores, Socket 1700 Raptor Lake. “13th gen”
On cpubenchmark.net, this model is currently ranked 4th among all current CPUs in single-thread performance.
CPU Cooling
I think I’m not alone in having past happy experiences with Noctua. This time I use the Noctua NH-U12A, which I have gotten reports does a good job for this CPU.
Motherboard
Something to host the CPU that just does the job. MSI PRO B660M-A DDR4 is a small board, but I don’t need anything more.
Turned out to require a little dance to make it accept my CPU since the BIOS it shipped with did not support it, so we had to insert an older CPU first just in order to upgrade the BIOS to make it boot with the intended CPU!
Graphics
My plan is to start trying out the built-in Intel video capabilities. Nothing extra. Lots of space in the box!
Memory
I don’t think I’ve experienced a situation when I have run out of my memory in my current 32GB setup, so my original plan was to go with 64GB in this new machine. However it turned out that the motherboard does not work with all four slots using my 3600MHz memories at full speed and I decided it is better to start out with 32 really fast gigabytes than 64GB at 2100MHz (which was the alternative)!
RGB-LEDs on the memory modules is apparently a thing now.
Should be >50% faster than my old memory.
Storage
I am not a data hoarder. On the disks in my current machine I use just a few hundred gigabytes. 2 TB will give me sufficient space to play with for a while. My old machine had a 3 TB spinning disk so this is less room than before, but I don’t expect that to be a problem. This storage is speced doing 14 times faster reads than my previous SSD.
The Kolink Enclave / 600W / 80+ Gold is nothing special. A modular and cheap alternative that my preferred supplier happened to offer. Again, I will not run any power hungry graphics cards.
Case
Me and friends have been happy with Fractal Design cases in the past and a friend of mine mentioned that he recently purchased this model and is very happy, so I went with the Fractal Design Define 7 Compact / Solid.
Internals with motherboard and CPU cooler in place. Not a lot of extra things in this…
This is a big case for a what is otherwise a very small computer (need). Partly because of the recommendation but also partly because that my preferred supplier did not offer any smaller Fractal Design case at the moment. At least there will be lots of air in the box.
This case looks almost identical to my old case which will make my machine upgrade at least physically impossible to detect in my home office once installed.
Front interface from left to right: Reset button, Audio I/O, 1x USB 3.1 Gen 2 Type-C, Power button, 2x USB 2.0, 2x USB 3.0,
Speed comparisons
Here’s how the new beast compares to the old box when doing a few of my regular every day tasks.
Building stuff
On a typical curl debug build of mine, identical setups. Run-time in seconds on the new machine vs the old.
Task
Old
New
build curl with make -sj
13.1
2.7
autoreconf -fi
13.2
5.6
configure
19.3
10.1
build in curl’s test directory
30.1
7.6
run the first 200 curl tests with valgrind
331
194
Downloading 100 GB from http://localhost to /dev/null with curl. Old: 2248MB/sec. New: 4281MB/sec.
Things did not work out the way we had planned. The 7.88.0 release that was supposed to be the last curl version 7 release contained a nasty bug that made us decide that we better ship an update once that is fixed. This is the update. The second final version 7 release.
Release presentation
Numbers
the 214th release 0 changes 5 days (total: 9,103) 25 bug-fixes (total: 8,690) 32 commits (total: 29,853) 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 0 new curl command line option (total: 250) 19 contributors, 7 new (total: 2,819) 10 authors, 1 new (total: 1,120) 0 security fixes (total: 135)
Bugfixes
As this is a rushed patch-release, there is only a small set of bugfixes merged in this cycle. The following notable bugs were fixed.
http2 multiplexed data corruption
The main bug that triggered the patch release. In some circumstances , when data was delivered as a HTTP/2 multiplexed stream, curl would get it wrong and cause the saved data to be corrupt. It would get the wrong data from the internal buffer.
This was not a new bug, but recent changes made it more likely to trigger.
make connect timeouts use full duration
In some cases curl would only allow half the given timeout period when doing connects.
runtests: fix “uninitialized value $port”
Running the test suite with verbose mode enabled, it would error out with this message. Since a short while back, we consider warnings in the test script fatal so this then aborts all the tests.
tests: make sure gnuserv-tls has SRP support before using it
The test suite uses gnuserv-tls to verify SRP authentication. It will only use this tool if found at startup, but due to recent changes in the GnuTLS project that ships this tool, it now builds with SRP disabled by default and thus can’t be used for this test. Now, the test script also checks that it actually supports SRP before trying to use it.
setopt: allow HTTP3 when HTTP2 is not defined
A regression made it impossible to ask for HTTP/3 if the build did not also support HTTP/2.
socketpair: allow EWOULDBLOCK when reading the pair check bytes
The fix in 7.88.0 turned out to cause occasional hiccups (on Windows at least) and this is a follow-up improvement for the verification of the socketpair emulation. When we create the pair and verify that it works, we must make sure that the code handles EWOULDBLOCK correctly.
Welcome to the final and last release in the series seven. The next release is planned and intended to become version 8.
Numbers
the 213th release 5 changes 56 days (total: 9,098) 173 bug-fixes (total: 8,665) 250 commits (total: 29,821) 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 1 new curl command line option (total: 250) 78 contributors, 41 new (total: 2,812) 42 authors, 18 new (total: 1,119) 3 security fixes (total: 135)
Release presentation
Security
This time we bring you three security fixes. All of them covering cases for which we have had problems reported and fixed before, but these are new subtle variations.
While we count over 140 individual bugfixes merged for this release, here follows a curated subset of some of the more interesting ones.
http/3 happy eyeballs
When asking for HTTP/3, curl will now also try older HTTP versions with a slight delay so that if HTTP/3 does not work, it might still succeed with and use an older version.
An application can now set drastically larger download buffers. For high speed/localhost transfers of some protocols this might sometimes make a difference.
curl: output warning at –verbose output for debug-enabled version
To help users realize when they use a debug build of curl, it now outputs a warning at the top of the --verbose output. We strongly discourage users to ship or use such builds in production.
websocket: multiple bugfixes
WebSocket support remains an experimental feature in curl but it is getting better. Several smaller and bigger bugs were squashed. Please continue to try it and report any problems and we can probably consider removing the experimental label soon.
dict: URL decode the entire path always
If you used a DICT URL it would sometimes do wrong as it previously only URL decoded parts of the path when using it. Now it correctly decodes the entire thing.
URL-encode/decode much faster
The libcurl functions for doing these conversions were sped up significantly. In the order of 3x and 7x.
haxproxy: send before TLS handhshake
The haproxy details are now properly sent before the TLS handshake takes place.
HTTP/[23]: continue upload when state.drain is set
Fixes a stalling problem when data is being uploaded and downloaded at the same time.
http2: aggregate small SETTINGS/PRIO/WIN_UPDATE frames
Optimizes outgoing frames for HTTP/2 into doing more in fewer sends.
openssl: store the CA after first send (ClientHello)
By changing the order of things, curl is better off spending CPU cycles while waiting for the server’s response and thereby making the entire handshake process complete faster.
curl: repair –rate
A regression in 7.87.0 made this feature completely broken. Now back on track again.
HTTP/2 much faster multiplexed transfers
By improving the handling of multiple concurrent streams over a single connection, curl now performs such transfers much faster than before. Sometimes an almost 3x speedup.
noproxy: support for space-separated names is deprecated
The parser that parses the “noproxy” string accepts plain space (without comma) as separators, while hardly any other tool or library does. This matters because it can be set in an environment variable. This accepted space-only separation is now marked as deprecated.
nss: implement data_pending method
The NSS backend was improved to work better for cases when the socket has been drained of data and only the NSS internal buffers has it, which could lead to curl getting stalled or losing data. Note: NSS support is marked for removal later in 2023.
socketpair: allow localhost MITM sniffers
curl has an internal socketpair emulation function for Windows. The way it worked did not allow MITM sniffers, but instead return error if such a thing was detected. It turns out too many users run tools on Windows that do this, so we have changed the logic to accept their presence and use.
tests-httpd: infra to run curl against an apache httpd
An entirely new line of tests that opens up new ways to test and verify our HTTP implementations in ways we could not do before. It uses pytest and an apache httpd server with special test modules.
curl: fix hiding of command line secrets
A regression.
curl: fix error code on bad URL
If you would use an invalid URL for upload, curl would erroneously report the problem as “out of memory” which unsurprisingly greatly confused users.
curl is actually something which is critical, especially to our data management system. It is being used very widely across NASA.
Dr Steve Crawford
2020
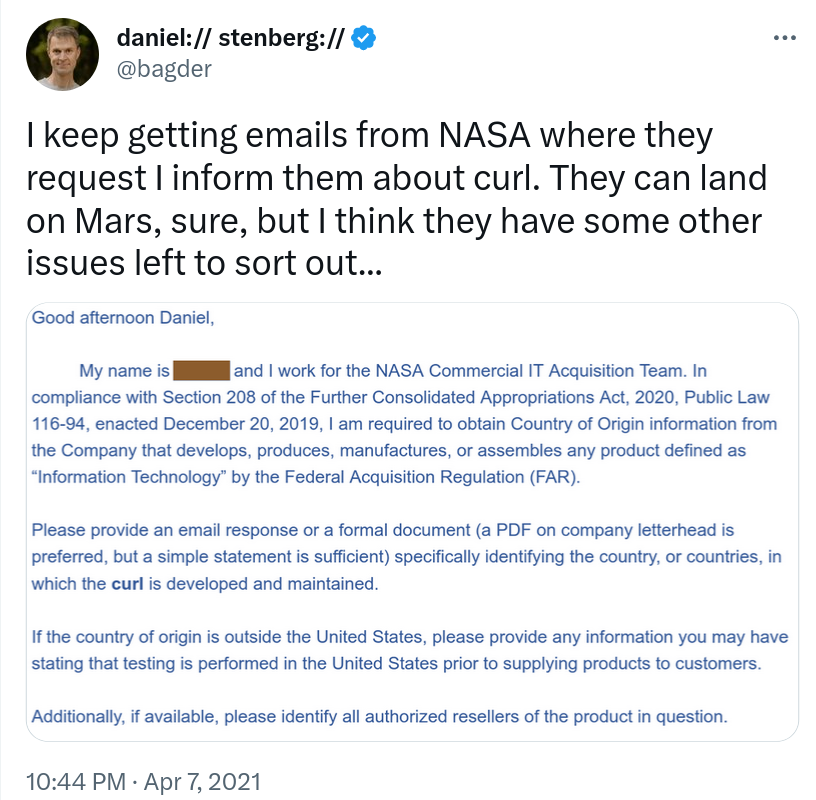
Back in 2020 I started getting emails from NASA asking for details and specifics about curl’s origins and in particular about where contributors to the project works, and I first replied eagerly trying to be helpful, but over time I kept receiving very similar emails from other NASA departments.
2021
It puzzled me, and out of frustration I posted this tweet in April 2021. A tweet that received a lot of attention and more than 3,000 likes.
2023
In a closing keynote at the FOSDEM 2023 conference, Dr. Steve Crawford did a talk titled NASA and Open Source Software (video, slides).
Some 24 minutes in, on slide 28, Dr Crawford shows a screenshot of the above tweet and talks about NASA’s use of curl, and says that piece I quoted at the top.
I was at the FOSDEM 2023 conference, but unfortunately I had to skip the last hour of presentations so I had just left the campus when this talk was held.
It would have been a blast to have been present in the room at that time. Now I instead got an avalanche of messages from friends and acquaintances who notified me about this talk and mention of me, which was of course also fun.
Takeaway
I’m glad NASA is aware of some of their problems and that they listen. It is a comfort that my text was taken with the right attitude. It also feels good that I used the correct tone in that Tweet: I figure it is rarely someone’s actual desire to appear clumsy or bureaucratic, but organizations and companies can easily get trapped in processes that still make them act that way.
Credit
As a celebration of NASA, the top image is taken by NASA’s James Webb Space Telescope’s Near-Infrared Camera (NIRCam) and features the central region of the Chamaeleon I dark molecular cloud, which resides 630 light years away.
Lots of people walked around the conference this year with sarcastic or otherwise amusing messages scrolling or blinking on them.
GitHub Social
When a few people at the GitHub Social event on the Saturday evening showed up wearing those badges, this triggered Martin Woodward (VP of DevRel for GitHub) who hosted the event, and he brought out his e-ink programmable badge from GitHub Universe and with a big smile on his face he showed off how cool it was and some of the functionality it holds. Combined with the story behind how he made this happen. Good stuff!
The red led badge immediately felt boring in comparison and in particular my friend Linus expressed his desire to get one. Martin explained how they had a few of them as prizes for the lottery of the evening. You would get one chance to win for every “hash collision” you could find – we all had gotten a hash code each on a sticker when we entered the place. Linus took off and searched for collisions with a frenzy, trying to maximize his chances.
Hash collisions
My fancy t-shirt front of the evening, showing my hash in the top left.
It was a fun and sufficiently nerdy social game that made us talk and mingle around a bit among the other fellow open source maintainers in the room and soon enough we found occasional collisions. I think I ended up finding three, Linus found six. Every time we wrote our names on a piece of paper and put it in a big container.
Socializing, beers, pizza and then eventually the time had come. No more collisions, time to see who had won.
Prizes
GitHub handed out many different prizes apart from the badges: GitHub pro subscriptions, hats and a huge GitHub Led logo.
I got the honors of picking the first five prizes: the pro subscriptions. Out of the five folded papers one of them had my name on it! Me already being a GitHub star (which offers that, and Martin knowing this), my name was instead replaced by another ticket. Still, I had apparently managed to pull my own name out of the hundreds of lottery tickets!
The badges
When the time come to pick the winners for the five badges, someone else fished up five tickets from the box and they were handed over to Martin to who read them, one by one.
Daniel Stenberg – I had won again! What are the odds? It was most hilarious, but then Martin continued, he read another name and then when he unfolded a ticket he looked a little surprised and said a little wondering another Stenberg? Yes, my brother Björn who was also present there then also won of those fun badges. What were the odds of that?!
Linus did not win one.
Linus, Björn and me are friends since over thirty years back (we are haxx.se) and since now two of us had won badges and the person who wanted it the most did not win, we of course could not resist to tease and taunt Linus plenty about it. What are friends for after all?
Leveling up
I knew how much Linus wanted one of these, so while I considered giving him mine, I first did a careful check with Martin. Did he possibly have an extra spare one that I could perhaps get my hands on for Linus?
He probably did. Over at his hotel he might have an extra. He even very graciously offered me that one like the champ he is.
Knowing that this possibility was in the pipeline, we could level up the taunting even more and really rub it in on Linus. Me and Björn thought it was mightily fun. You can probably say we were badgering him.
A midnight image
The GitHub event ended, we all walked out into the Brussels night, aiming to get some sleep to endure another intense FOSDEM full day the following Sunday. At 00:55 Martin messaged me this picture:
Sunday morning
Of course we reminded Linus already at breakfast how some of us actually have these cool badges and then maybe a few more times the following hours. We also shared the secret with other friends so the surrounding had a better understanding of what was going on.
In the meantime, I secretly coordinated a badge drop-off. My personal hero Martin delivered a box for Linus with this badge, I could pick it up and while pausing our badge-teasing, I could hand over the cardboard box to him with his GitHub handle on a sticker.
Here’s one for you
That expression. It took a few seconds for what just happened to sink in, before Linus realized exactly what had been going on since last night.
Priceless.
An e-ink programmable badge
The badge tech itself is a 296 x 128 pixels e-ink display powered by an FP2040 (Raspberry Pi) Dual Arm Cortex M0+ running at up to 133Mhz. Easily programmable too.
If you want one, pimoroni sells these beauties. (I have no relation with them.)
They call this the badger 2040, which is particularly fun since I use the nickname bagder since a long time, on GitHub and elsewhere. A badger badge for bagder.
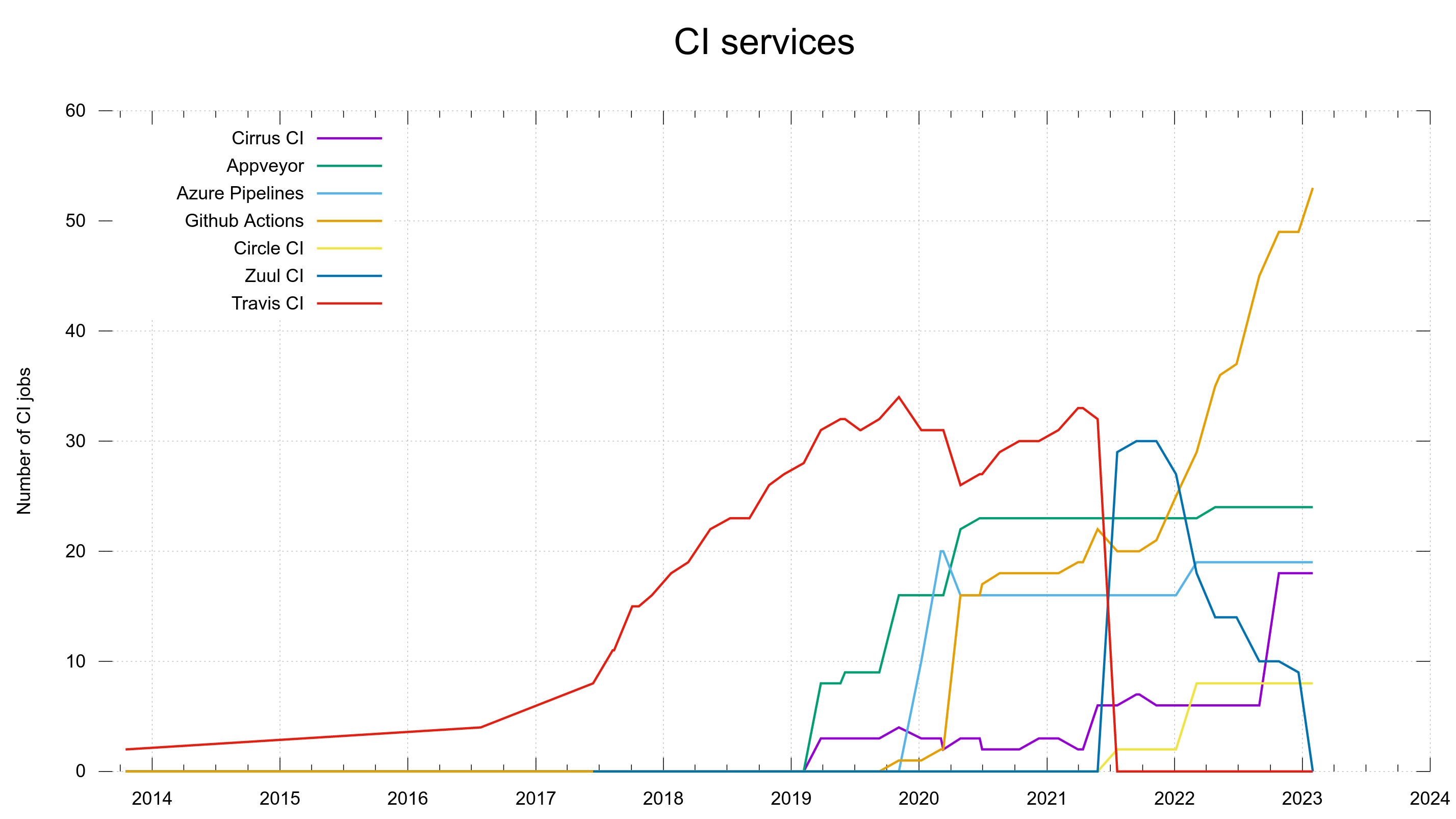
In the beginning and for many years, the curl project used no CI services at all. It instead used a distributed build and test systems where volunteers ran machines that pulled the latest code repeatedly, built curl, ran the tests and reported back the results to a central server.
One
In 2013, the year curl turned 15, we created our first CI jobs on Travis CI. With only a single CI service life was easy for a few years.
Two, three
This single service had a limited feature set and in particular a limited set of supported platforms. To also do automatic testing on FreeBSD and Windows we had to use two additional services because Travis did not support them. Now they were three, early 2019. Cirrus CI and AppVeyor.
Four
When we use free services, we need to live with the limitations of what the good providers offer for free or at low cost. In the case of CI services, they tend to reduce CPU time and parallelisms for users of the free tier and so did Travis.
When the number of CI jobs on Travis surpassed 30, and we had already gotten a small performance boost just because of their good will, we created the next few new CI jobs on GitHub Actions instead to increase the parallelism for no extra money. If I recall things correctly, the macOS support was also much better on GitHub since it was rather limited on Travis.
GitHub later graciously bumped our service level for even more power and parallelism. Increased parallelism, not the least thanks to the use of several independent CI services, made sure that the complete set of CI jobs would still complete within a reasonable time.
Five
When working on extending and improving our Windows CI testing in late 2019, our previous Windows CI provider AppVeyor was not good enough so we opted to add jobs on Azure Pipelines. This was also because GitHub Actions could not run the images we have and wanted to use for this purpose.
Redundancy
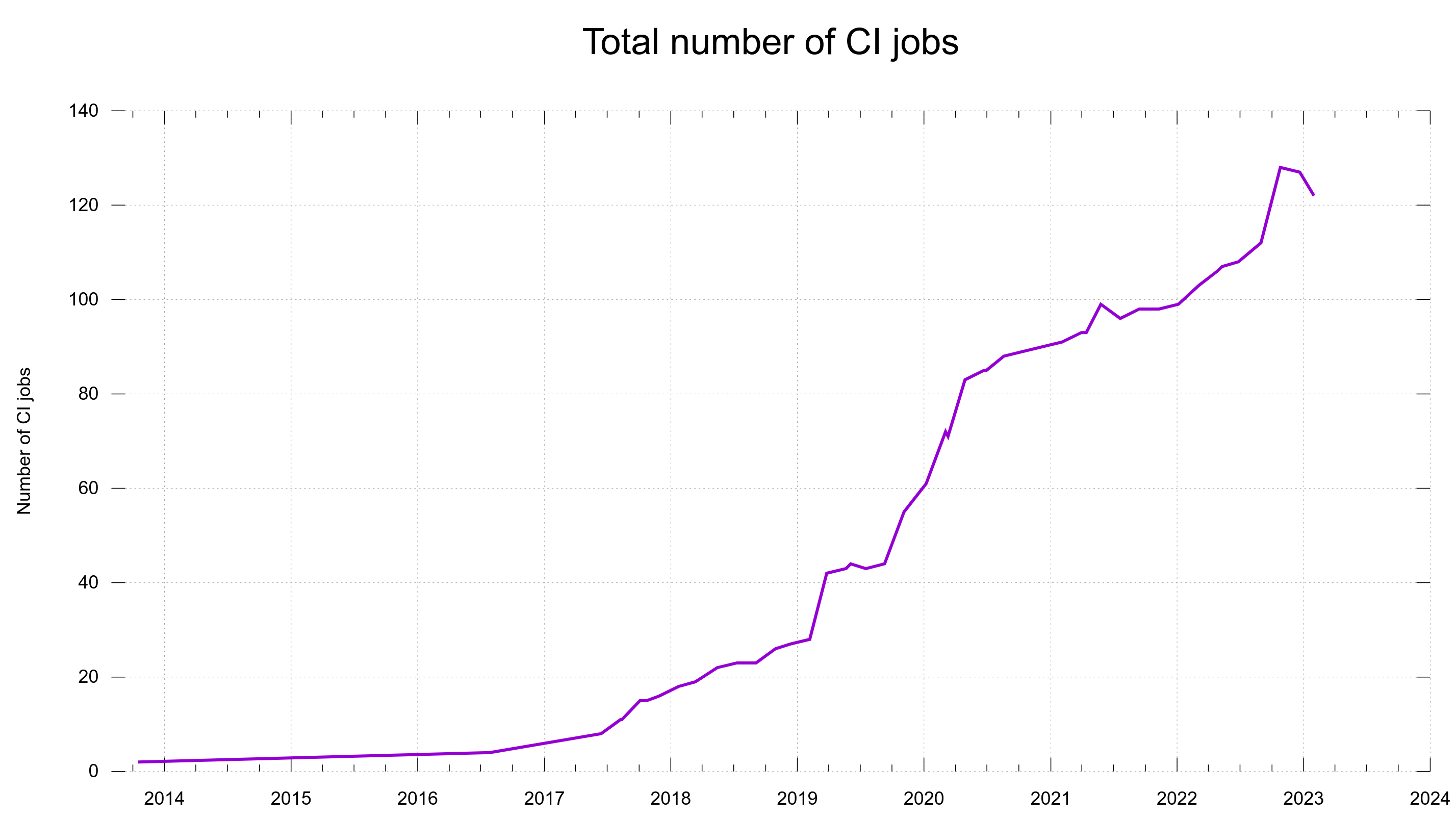
When we entered the year 2020 we were at 60 CI jobs and having them run on several different CI services often turned out useful when one of them acted up: at least a lot of other jobs would still work and help us assess and verify proposed changes. No all eggs in the same basket problem.
Services come and go
Redundancy also helps soften the blow when a service goes away. If you are in the race long enough, all services will go away or go sour eventually. This includes CI services.
In 2021, Travis CI changed their policies and suddenly we could not keep using them unless we paid up a few K USD per year and we would rather avoid that.
We had to move the 30+ CI jobs from Travis to something else. Thanks to a generous offer, volunteers showed up and helped transition the Travis jobs over to a new service: Zuul CI. It softened the repercussions from the “jump” and the CI jobs kept helping us ship quality code.
Five, Six
To manage the Travis CI eviction, Zuul took over most of the curl CI jobs and a few of them were added on Circle CI, which then appeared as CI service number six. Primarily because of their at the time early and convenient support for arm.
Zuul CI
We were grateful for the help we got to move over to Zuul from Travis, but soon it became apparent to us that Zuul CI is more “crude” than some of the other services and it left us wanting more. It’s UI is way less sophisticated, to the level that it is almost difficult for a casual PR submitted to read and understand build errors. Also, it was slightly buggy, which could result in Zuul jobs not showing up in the GitHub UI at all or simply failing to trigger the new jobs. When the responses from the Zuul side to our problems were somewhere between slow to non-existent I felt with had no other choice but to transition away from this service as well.
The change took its time. At the end of 2021 we had 30 CI jobs on Zuul, and just days ago in late January 2023, we removed the final curl jobs from it.
Five
We use five services now and we could possibly consolidate down to four if we really wanted to, but I see no reason to do that now when things are working and huffing along.
GitHub Actions have really taken off as our primary CI service and now runs almost half of the entire set. Thanks to it being convenient, well integrated, well documented and us having good parallelism on it.
We do what we need
Whatever is good for the project we will consider doing. We have gotten to this point with this set of CI services because they help the project. If someone proposes a change that improve things and that change reduces the number of CI services, then we might go that way next. Or maybe we add one? We have not planned what comes next.
What we run in CI
We build curl and run tests with numerous different build configurations on several architectures on different operating systems. With and without debug enabled. With and without using valgrind. Most builds also run checksrc , which verifies source code style.
We run dedicated jobs that do “deeper” testing, such as building with address and undefined behavior-analyzers and running the complete curl test suite in “torture mode”.
We run markdown and man page spell checkers
We run English prose checking (using proselint) of markdown files
We run static code analyzers and fuzzers
We confirm the copyright and license situation of all files in git
We verify links within markdowns
We have a few “bot services” that can set the “hacktoberfest-accepted” label, and a labeler service that tries to automatically set proper categories for pull requests.
We verify that the release tarball looks right and works when generated from the current set of files in git
… and probably a few other things I have forgot now
Of course we have graphs
These graphs were screenshotted from the dashboard on February 1st, 2023.
The total number of CI jobs done for each PR and commit, over time
Number of CI jobs running on which CI service, over time
CI job distribution over platforms
Future
Whatever helps the project and whatever someone offers to help us make that happen, we might do. That may mean using more services, it might mean using less.
The important part is that these services are used to improve and strengthen the curl project and the products we ship.