In 2011 I started to send “pre-notifications” about pending curl security vulnerabilities to the distros mailing list (back then it was still called linux-distros).
For several years we also asked them for CVE IDs for the new vulnerabilities that we were about to publish to the world. By notifying the distros ahead of time, the idea is that they get a little head-start to fix their curl packages so that at the day when we publish the vulnerabilities to the world, they can already provide curl upgrades.
The gap from us announcing a flaw until they offer curl upgrades could ideally be made a minimum.
The distros list’s rules forbid us to tell them more than 10 days before the planned release day. They call this an embargo as they are expected to not tell anyone who is not a mailing list member about these flaws.
During the last twelve plus years, I have told them about almost 130 pending curl vulnerabilities like this up until today.
Secrets are hard
For an open source project that has all its processes and test infrastructure public and open there are several challenges with how to deal with secrets, such as vulnerabilities and their corresponding fixes.
We recently updated our security process in the curl project: we have noticed that we have previously – several times – landed fixes to security problems that were defective and in some cases did not even fix the reported problem correctly. I believe one reason for this is that we had this policy to make the fix into a (public) pull-request no earlier than 48 hours before the pending release. 48 hours is enough to make all the tests and CI verify the fix, but it is a very short time window for the community to react or be able to test and find any problems with the fixes before the release goes out.
As an attempt to do better we have tweaked our policy. If a reported security problem is deemed to be of severity low or severity medium, we will instead allow and rather push for turning the fix into a public pull-request much earlier. We will however not mention the security aspect of the fix in the public communication about the pull-request, but only talk about the bugfix aspect.
This will allow us to merge fixes earlier in the release cycle. To give the bugfixes more time to mature and ripe in the repository before the pending release. It should increase the chances that we can do follow-up fixes and truly make it a good correction by the time we do the next release. Hopefully it leads to better releases with fewer regressions.
Of course the risk with this is that a malicious user somewhere finds out about a vulnerability this way, earlier than 48 hours before a release, and therefore gets an extended time window to perform nefarious actions. That is also why we limit this method to severity low and medium issues, as the ones rated more serious are deemed too dangerous to risk.
Policy vs policy
The week before we were about to ship the curl 8.0.0 release, I emailed the distros mailing list again like I have done so many times before and told them about the upcoming six(!) vulnerabilities we were about to reveal to the world.
This time turned out to be different.
Because of our updated policy where the fixes were already committed in a public git repository, the distros mailing list’s policy says that if there is a public commit they consider the issue to be public and thus they refuse to accept any embargo.
What they call embargo I of course call heads-up time.
I argue that while the fixes are public, the actual vulnerabilities and the security issues those fixes rectify are not. It takes a serious effort and pretty good insights to just detect that one or more of the commits for the pending release are done because of a security problem and then even more so if you want to convert that suspicion into an actual attack vector.
They maintain that while they could make an exception for me/us this time, this is an exception and their policy says this is not acceptable for embargos.
If we make commits public before telling distros, we may not “ask for an embargo”.
So we won’t tell
I thought we were doing this for their benefit. I was under the impression that we actually helped distributors of open source operating systems by telling them ahead of time what was going to ship very soon that they might want to get a head-start on so that their users stay protected.
I have been told in very clear terms that they do not want to be notified about vulnerabilities ahead of time if the commits are public.
I have informed them that I will not tell them anymore until they change their minds because I think our updated security process can make our releases better and I think improving curl and making better releases is more important than telling distros ahead of time.
I cannot understand how this stubbornness makes anything better for them. For me, it takes away some amount of work so I will manage just fine. For curl users “in the wild”, this will probably mean that they will get security-patched curl releases from their distros a little slower in the future.
We rarely see curl vulnerabilities rated higher than medium so this means we will effectively stop emailing distros about pending flaws. We are still allowed to tell them about more criticality scored vulnerabilities but I must confess I feel less inclined to do that than I used to.
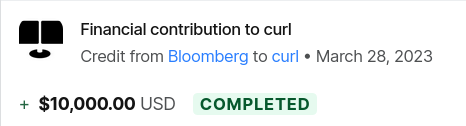
Hi curl admins, Alyssa here from the Bloomberg Open Source Program Office. I wanted to let you know that curl was selected as a winner in our inaugural FOSS Contributor Fund! We wanted to let you know of the results before we transferred funds via Open Source Collective. Can you confirm you’ve received this message? Again, we’re super excited to support your work and excited that you were selected in our inaugural vote! Please let us know if we can be of any further support. All best, Alyssa.
The quote above was received by the curl team on March 27, 2023 and…
Open Collective
All curl funds are held by Open Collective, as the curl project is not a legal entity and cannot hold on to money or any assets at all really on its own.
Bloomberg’s donation was directed directly to Open Collective and below is a screenshot from there:
Screenshot from curl’s fund at Open Collective
Grateful
We are of course grateful for this generous donation and we will make sure that we spend this money on activities that bring the project forward. A pledge we do for all money ever donated to us. We are determined to live up to the highest expectations of excellency that our awesome sponsors and donors might have on us. Now and in the future.
On the behalf of the curl project: Thank you Bloomberg!
Every once in a while someone brings up the topic of code coverage in relation to curl. What portion of the code is actually exercised when running the tests?
Honestly, we don’t know. We can’t figure it out. We are not trying to figure it out. We have to live with this.
We used to get a number
A few years back we actually did a build and a test run in our CI setup that used one of those cloud services that would monitor the code coverage and warn if we would commit something that drastically reduced coverage.
This had significant drawbacks:
First, the service was unstable which made it occasionally sound the horns because we had gone down to 0% coverage and that is bad.
Secondly, it made parts of the audience actually believe that what was reported by that service for a single build and a single test run was the final and accurate code coverage number. It was far from it.
We ended up ditching that job as it did very little good but some amount of harm.
Different build combinations – and platforms
Code coverage is typically the number of lines of code that were executed as a share out of the total amount of possible lines (lines that were compiled and used in the build, not lines of code that were not included in the complete source). Since curl offers literally many million build combinations, an evaluated code coverage number can only apply to that specific build combination. When using that exact setup and running a particular set of tests on a fixed platform.
Just getting the coverage rate off one of these builds is easy enough but is hardly representing the true number as we run tests on many build combinations doing many different tests.
Can’t do it all in a single test run
We run many different tests and some of the tests we limit and split up into several different specific CI jobs since they are very slow and by doing a smaller portion of the jobs in separate CI jobs, we allow them to run in parallel and thus complete faster. That is super complicated from a code coverage point of view as we would have to merge coverage data between numerous independent and isolated build runs, possibly running on different services, to get a number approaching the truth.
We don’t even try to do this.
Not the panacea
Eventually, even if we would be able to get a unified number from a hundred different builds and test runs spread over many platforms, what would it tell us?
libcurl has literally over 300 run-time options that can be used in combinations. Running through the code with a few different option combinations could theoretically reach almost complete code coverage and yet only test a fraction of the possibilities.
But yes: it would help us identify source code lines that are never executed when the tests run and it would be very useful.
Instead
We rely on manual (and more error-prone) methods of identifying what parts of the code we need to add more tests for. This is hard, and generally the best way to find weak spots is when someone reports a bug or a regression as that usually means that there was a lack of tests for that area that allowed the problem to sneak in undetected.
Of course we also need to make sure that all new features and functions get test cases added in parallel.
This is a rather weak system but we have not managed to make a better one yet.
Right. I said in the 8.0.0 blog post that it might be a good release. It was. Apart form the little bug that caused it to crash in several test cases.
So now we shipped curl 8.0.1, which is almost identical apart from a single commit that was reverted.
Exactly why this was not discovered in our tests and CI jobs before the release we have yet to figure out, but it is certainly more than just a little disturbing.
This a major version number bump but without any ground-breaking changes or fireworks. We decided it was about time to reset the minor number down to more a manageable level and doing it exactly on curl’s 25th birthday made it extra fun. There is no API nor ABI break in this version.
This is likely the best curl release we ever made.
curl supports communicating using the TELNET protocol and as a part of this it offers users to pass on user name and “telnet options” for the server negotiation.
Due to lack of proper input scrubbing and without it being the documented functionality, curl would pass on user name and telnet options to the server as provided. This could allow users to pass in carefully crafted content that pass on content or do option negotiation without the application intending to do so. In particular if an application for example allows users to provide the data or parts of the data.
curl supports SFTP transfers. curl’s SFTP implementation offers a special feature in the path component of URLs: a tilde (~) character as the first path element in the path to denotes a path relative to the user’s home directory. This is supported because of wording in the once proposed to-become RFC draft that was to dictate how SFTP URLs work.
Due to a bug, the handling of the tilde in SFTP path did however not only replace it when it is used stand-alone as the first path element but also wrongly when used as a mere prefix in the first element.
Using a path like /~2/foo when accessing a server using the user dan (with home directory /home/dan) would then quite surprisingly access the file /home/dan2/foo.
This can be taken advantage of to circumvent filtering or worse.
libcurl would reuse a previously created FTP connection even when one or more options had been changed that could have made the effective user a very different one, thus leading to the doing the second transfer with wrong credentials.
libcurl keeps previously used connections in a connection pool for subsequent transfers to reuse if one of them matches the setup. However, several FTP settings were left out from the configuration match checks, making them match too easily. The settings in questions are CURLOPT_FTP_ACCOUNT, CURLOPT_FTP_ALTERNATIVE_TO_USER, CURLOPT_FTP_SSL_CCC and CURLOPT_USE_SSL level.
CVE-2023-27536: GSS delegation too eager connection re-use
libcurl would reuse a previously created connection even when the GSS delegation (CURLOPT_GSSAPI_DELEGATION) option had been changed that could have changed the user’s permissions in a second transfer.
libcurl keeps previously used connections in a connection pool for subsequent transfers to reuse if one of them matches the setup. However, this GSS delegation setting was left out from the configuration match checks, making them match too easily, affecting krb5/kerberos/negotiate/GSSAPI transfers.
libcurl supports sharing HSTS data between separate “handles”. This sharing was introduced without considerations for do this sharing across separate threads but there was no indication of this fact in the documentation.
Due to missing mutexes or thread locks, two threads sharing the same HSTS data could end up doing a double-free or use-after-free.
libcurl would reuse a previously created connection even when an SSH related option had been changed that should have prohibited reuse.
libcurl keeps previously used connections in a connection pool for subsequent transfers to reuse if one of them matches the setup. However, two SSH settings were left out from the configuration match checks, making them match too easily.
Changes
There is only one actual “change” in this release. This is the first curl release to drop support for building on a systems that lack a working 64 bit data type. curl now requires that ‘long long‘ or an equivalent exists.
Bugfixes
This release cycle was half the length of a regular one but yet we managed to merge an impressive amount of bugfixes. Below I highlight a few that I think deserve a special mention.
build: drop the use of XC_AMEND_DISTCLEAN
A strange description but this change removed an old autotools macro that made configure sometimes “balloon” Makefiles to several gigabytes.
connect: fix time_connect and time_appconnect timer statistics
A regression after the new happy eyeball h2/h3 connect approach was introduced.
curl.1: list all “global options”
Command line options that survive the use of --next are called “global options” and the man page now lists all of them for easier identification.
To accomplish this, there is a new metadata “tag” for this purpose to mark the global options in their corresponding docs files.
ftp: active mode with SSL, add the filter
Regression: FTPS in active mode did not setup the data connection correctly.
replaced sscanf() in several parsers
From 24 occurrences of sscanf() calls in the code in the previous release, down to just 4 left.
headers: make curl_easy_header and nextheader return different buffers
http2 bugfixes
error handling during parallel operations
fix http2 prior knowledge when reusing connections
RST and GOAWAY better recognize partial transfers
avoid upload busy loop
http: don’t send 100-continue for short PUT requests
Now aligns with and behaves more similarly to how curl has treated POST for a long time.
http: fix unix domain socket use in https connects
A regression.
multi: make multi_perform ignore/unignore signals less often
When iterating over a potentially long list of individual transfers to “take care of”, we can avoid many ignore + unignore sequences by retaining the previous state when possible.
multi: remove PENDING + MSGSENT handles from the main linked list
To speed up the handling of large amounts of easy handles added to a multi handle that are either pending or already completed, those easy handles are now moved out of the main linked list to separate queues.
rand: use arc4random as fallback when available
Makes curl built without a TLS library get better random, assuming the platform supports it.
urlapi: ‘%’ is illegal in host names
The URL parser would wrongly accept a stand-alone percent as part of a host name. It remains accepted for percent-encoded host names and as separator between an IPv6 address and a zone id.
urlapi: parse IPv6 literals without ENABLE_IPV6
To make the URL parser behavior more consistent, it can now parse and deal with IPv6 addresses perfectly fine and the same way even if IPv6 connectivity does not actually work.
binding to an interface with host name using c-ares
Time flies when you are having fun. Today is curl‘s 25th birthday.
The curl project started out very humbly as a small renamed URL transfer tool that almost nobody knew about for the first few years. It scratched a personal itch of mine,
Me back then
I made that first curl release and I’ve packaged every single release since. The day I did that first curl release I was 27 years old and I worked as a software engineer for Frontec Tekniksystem, where I mostly did contract development on embedded systems for larger Swedish product development companies. For a few years in the late 90s I would for example do quite a few projects at and for the telecom giant Ericsson.
I have enjoyed programming and development ever since I got my first computer in the mid 80s. In the 1990s I had already established a daily schedule where I stayed up late when my better half went to bed at night, and I spent another hour or two on my spare time development. This is basically how I have manged to find time to devote to my projects the first few decades. Less sleep. Less other things.
Gradually and always improving
The concept behind curl development has always been to gradually and iteratively improve all aspects of it. Keep behavior, but enhance the code, add test cases, improve the documentation. Over and over, year after year. It never stops. As the timeline below helps showing.
Similarly, there was no sudden specific moment when suddenly curl became popular and the number of users skyrocketed. Instead, the number of users and the popularity of the tool and library has gradually and continuously grown. In 1998 there were few users. By 2010 there were hundreds of millions.
We really have no idea exactly how many users or installations of libcurl there are now. It is easy to estimate that it runs in way more than ten billion installations purely based on the fact that there are 7 billion smart phones and 1 billion tablets in the world , and we know that each of them run at least one, but likely many more curl installs.
Before curl
My internet transfer journey started in late 1996 when I downloaded httpget 0.1 to automatically download currency rates daily to make my currency exchange converter work correctly for my IRC bot. httpget had some flaws so I sent back fixes, but Rafael, the author, quickly decided I could rather take over maintenance of the thing. So I did.
I added support for GOPHER, change named of the project, added FTP support and then in early 1998 I started adding FTP upload support as well…
1998
The original curl logo.
On March 20 1998, curl 4.0 was released and it was already 2,200 lines of code on its birthday because it was built on the projects previously named httpget and urlget. It then supported three protocols: HTTP, GOPHER and FTP and featured 24 glorious command line options.
The first release of curl was not that special event since I had been shipping httpget and urlget releases for over a year already, so while this was a new name it was also “just another release” as I had done many times already.
We would add HTTPS and TELNET support already the first curl year, which also introduced the first ever curl man page. curl started out GPL licensed but I switched to MPL already within that first calendar year 1998.
The first SSL support was powered by SSLeay. The project that in late 1998 would transition over into becoming OpenSSL.
In August 1998, we added curl on the open source directory site freshmeat.net.
The first curl web page was published at http://www.fts.frontec.se/~dast. (the oldest version archived by the wayback machine is from December 1998)
In November 1998 I added a note to the website about the mind-blowing success as the latest release had been downloaded 300 times! Success and popularity were far from instant.
Screenshot from the curl website of November 1998
During this first year, we shipped 20 curl releases. We have never repeated that feat again.
1999
We created the first configure script, added support for cookies and appeared as a package in Debian Linux.
The curl website moved to http://curl.haxx.nu.
We added support for DICT, LDAP and FILE through the year. Now supporting 8 protocols.
In the last days of 1999 we imported the curl code to the cool new service called Sourceforge. All further commit counts in curl starts with this import. December 29, 1999.
2000
Privately, I switched jobs early 2000 but continued doing embedded contract development during my days.
The rules for the TLD .se changed and we moved the curl website to curl.haxx.se.
I got married.
In August 2000, we shipped curl 7.1 and things changed. This release introduced the library we decided to call libcurl because we couldn’t come up with a better name. At this point the project were at 17,200 lines of code.
The libcurl API was inspired by how fopen() works and returns just an opaque handle, and how ioctl() can be used to set options.
Creating a library out of curl was an idea I had almost from the beginning, as I’ve already before that point realized the power a good library can bring to applications.
Users found the library useful and increased the curl uptake. One of the first early adopters of libcurl was the PHP language, which decided to use libcurl as their default HTTP/URL transfer engine.
We created the first test suite.
2001
We changed the license and offered curl under the new curl license (effectively MIT) as well as MPL. The idea to slightly modify the curl license was a crazy one, but the reason for that has been forgotten.
We added support for HTTP/1.1 and IPv6.
In June, the THANKS file counted 67 named contributors. This is a team effort. We surpassed 1,100 total commits in March and in July curl was 20,000 lines of code.
Apple started bundling curl with Mac OS X when curl 7.7.2 shipped in Mac OS X 10.1.
2002
The test suite contained 79 test cases.
We dropped the MPL option. We would never again play the license change game.
We added support for gzip compression over HTTP and learned how to use SOCKS proxies.
2003
The curl “autobuild” system was introduced: volunteers run scripts on their machines that download, build and run the curl tests frequently and email back the results to our central server for reporting and analyses. Long before modern CI systems made these things so much easier.
We added support for Digest, NTLM and Negotiate authentication for HTTP.
In August we offered 40 individual man pages.
Support for FTPS was added, protocol number 9.
My first child, Agnes, was born.
I forked the ares project and started the c-ares project to provide and maintain a library for doing asynchronous name resolves – for curl and others. This project has since then also become fairly popular and widely used.
2004
At the beginning of 2003, curl was 32,700 lines of code.
We made curl support “large files”, which back then meant supporting files larger than 2 and 4 gigabytes.
We implemented support for IDN, International Domain Names.
2005
GnuTLS become the second supported TLS library. Users could now select which TLS library they wanted their build to use.
Thanks to a grant from the Swedish “Internetfonden”, I took a leave of absence from work and could implement the first version of the multi_socket() API to allow applications to do more parallel transfers faster.
git was created and they quickly adopted curl for their HTTP(S) transfers.
TFTP became the 10th protocol curl supports.
2006
We decided to drop support for “third party FTP transfers” which made us bump the SONAME because of the modified ABI. The most recent such bump. It triggered some arguments. We learned how tough bumping the SONAME can be to users.
The wolfSSL precursor called cyassl became the third SSL library curl supported.
We added support for HTTP/1.1 Pipelining and in the later half of the year I accepted a contract development work for Adobe and added support for SCP and SFTP.
As part of the SCP and SFTP work, I took a rather big step into and would later become maintainer of the libssh2 project. This project is also pretty widely used.
I had a second child, my son Rex.
2007
Now at 51,500 lines of code we added support for a fourth SSL library: NSS
We added support for LDAPS and the first port to OS/400 was merged.
For curl 7.16.1 we added support for --libcurl. Possibly my single favorite curl command line option. Generate libcurl-using source code repeating the command line transfer.
In April, curl had 348 test cases.
2008
By now the command line tool had grown to feature 126 command line options. A 5x growth during curl’s ten first years.
In March we surpassed 10,000 commits.
I joined the httpbis working group mailing list and started slowly to actively participate within the IETF and the work on the HTTP protocol.
Solaris ships curl and libcurl. The Adobe flash player on Linux uses libcurl.
In September the total count of curl contributors reached 654.
We introduced support for building curl with cmake. A decision that is still being discussed and questioned if it actually helps us. To make the loop complete, cmake itself uses libcurl.
In July the IETF 75 meeting was held in Stockholm, my home town, and this was the first time I got to physically meet several of my personal protocol heroes that created and kept working on the HTTP protocol: Mark, Roy, Larry, Julian etc.
In August, I quit my job to work for my own company Haxx, but still doing contracted development. Mostly doing embedded Linux by then.
Thanks to yet another contract, I introduced support for IMAP(S), SMTP(S) and POP3(S) to curl, bumping the number of supported protocols to 19.
We switched version control system from CVS to git and at the same time we switched hosting from Sourceforge to GitHub. From this point on we track authorship of commits correctly and appropriately, something that was much harder to do with CVS.
We introduced the checksrc script that verifies that source code adheres to the curl code style. Started out simple, has improved and been made stricter over time.
Added support for Schannel and Secure Transport for TLS.
When I did an attempt at a vanity count of number of curl users, I ended up estimating they were 550 million. This was one of the earlier realizations of mine that man, curl is everywhere!
During the entire year of 2012, there were 67 commit authors.
2013
Added support for GSKit, a TLS library mostly used on OS/400. The 10th supported TLS library.
In April the number of contributors had surpassed 1,000 and we reached over 800 test cases.
We refactored the internals to make sure everything is done non-blocking and what we call “use multi internally” so that the easy interface is just a wrapper for a multi transfer.
The initial attempts at HTTP/2 support were merged (powered by the great nghttp2 library) as well as support for doing connects using the Happy Eyeballs approach.
We created our first two CI jobs.
2014
I started working for Mozilla in the Firefox networking team, remotely from my house in Sweden. For the first time in my career, I would actually work primarily with networking and HTTP etc with a significant overlap with what curl is and does. Up until this point, the two sides of my life had been strangely separated. Mozilla allowed me to spend some work hours on curl.
At 161 command line options and 20 reported CVEs.
59 man pages exploded into 270 man pages in July when every libcurl option got its own separate page.
We added support for the libressl OpenSSL fork and removed support for QsoSSL. Still at 10 supported TLS libraries.
In September, there was 105,000 lines of code.
Added support for SMB(S). 24 protocols.
2015
Added support for BoringSSL and mbedTLS.
We introduced support for doing proper multiplexed transfers using HTTP/2. A pretty drastic paradigm change in the architecture when suddenly multiple transfers would share a single connection. Lots of refactors and it took a while until HTTP/2 support got stable.
It followed by our first support for HTTP/2 server push.
We switched over to the GitHub working model completely, using its issue tracker and doing pull-requests.
The first HTTP/2 RFC was published in May. I like to think I contributed a little bit to the working group effort behind it.
My HTTP/2 work this year was in part sponsored by Netflix and it was a dance to make that happen while still employed by and working for Mozilla.
curl got support for building with and using multiple TLS libraries and doing the choice of which to use at start-up.
Fastly reached out and graciously and generously started hosting the curl website as well as my personal website. This help putting the end to previous instabilities when blog posts got too popular for my site to hold up and it made the curl site snappier for more people around the globe. They have remained faithful sponsors of the project ever since.
In the spring of 2017, we had our first ever physical developers conference, curl up, as twenty something curl fans and developers went to Nuremberg, Germany to spend a weekend doing nothing but curl stuff.
In June I was denied traveling to the US. This would subsequently take me on a prolonged and painful adventure trying to get a US visa.
The first SSLKEYLOGFILE support landed, we introduced the new MIME API and support for brotli compression.
The curl project was adopted into the OSS-Fuzz project, which immediately started to point out mistakes in our code. They have kept fuzzing curl nonstop since then.
In October, I was awarded the Polhem Prize. Sweden’s oldest and probably most prestigious engineering award. This prize was established and has been awarded since 1876. A genuine gold medal, handed over to me by no other than his majesty the king of Sweden. The medal even has my name engraved.
2018
Added support for DNS over HTTPS and the new URL API was introduced to allow applications to parse URLs the exact same way curl does it.
We introduced support for a second SSH library, so now SCP and SFTP could be powered by libssh in addition to the already supported libssh2 library.
We added support for MesaLink but dropped support for AxTLS. At 12 TLS libraries.
129,000 lines of code. Reached 10,000 stars on GitHub.
To accept a donation it was requested we create an account with Open Collective, and so we did. It has since been a good channel for the project to receive donations and sponsorships.
In November 2018 it was decided that the HTTP-over-QUIC protocol should officially become HTTP/3.
At 27 CI jobs at the end of the year. Running over 1200 test cases.
We introduced our first curl bug bounty program and we have effectively had a bug bounty running since. In association with hackerone. We have paid almost 50,000 USD in reward money for 45 vulnerabilities (up to Feb 2023).
Added support for AmiSSL and BearSSL: at 14 libraries.
We merged initial support for HTTP/3, powered by the quiche library, and a little later also with a second library: ngtcp2. Because why not do many backends?
We started offering curl in an “official” docker image.
2020
The curl tool got parallel transfer powers, the ability to output data in JSON format with -w and the scary --help output was cleaned up and arranged better into subcategories.
In March, for curl 7.69.0, I started doing release video presentations, live-streamed.
The 212th curl release was done in December. Issue 10,000 was created on GitHub.
2023
At the start of the year: 155,100 lines of code. 486 man pages. 1560 test cases. 2,771 contributors. 1,105 commit authors. 132 CVEs. 122 CI jobs. 29,733 commits. 48,580 USD rewarded in bug-bounties. 249 command line options. 28 protocols. 13 TLS libraries. 3 SSH libraries. 3 HTTP/3 libraries.
Introduce support for HTTP/3 with fall-back to older versions, making it less error-prone to use it.
On March 13 we surpassed 30,000 commits.
On March 20, we release curl 8.0.0. Exactly 25 years since the first curl release.
Staying relevant
Over the last 25 years we have all stopped using and forgotten lots of software, tools and services. Things come and go. Everything has its time and lots of projects simply do not keep up and gets replaced by something else at some point.
I like to think that curl is still a highly relevant software project with lots of users and use cases. I want to think that this is partly because we maintain it intensely and with both care and love. We make it do what users want it to do. Keep up, keep current, run the latest versions, support the latest security measures, be the project you would like to use and participate. Lead by example.
My life is forever curl tinted
Taking curl this far and being able to work full time on my hobby project is a dream come real. curl is a huge part of my life.
Me, on vacation in Portugal in 2019.
This said, curl is a team effort and it would never have taken off or become anything real without all our awesome contributors. People will call me “the curl guy” and some will say that it is “my” project, but everyone who has ever been close to the project knows that we are many more in the team than just me.
25 years
That day found httpget I was 26 years old. I was 27 by the time I shipped curl. I turned 52 last November.
I’ve worked on curl longer than I’ve worked for any company. None of my kids are this old. 25 years ago I did not live in my house yet. 25 years ago Google didn’t exist and neither did Firefox.
Many current curl users were not even born when I started working on it.
Beyond twenty-five
I feel obligated to add this section because people will ask.
I don’t know what the future holds. I was never good at predictions or forecasts and frankly I always try to avoid reading tea leaves. I hope to stay active in the project and to continue working with client-side internet transfers for as long as it is fun and people want to use the results of my work.
Will I be around in the project in another 25 years? Will curl still be relevant then? I don’t know. Let’s find out!
Consider muting yourself when you join, but feel encouraged to leave the camera on. Click the link above to get the time for your location. It is within this weird period between the US has switched to daylight saving time while Europe has not yet switched.
Bowmore. 25 years old.
If it works out, I will do a presentation walking over the bigger changes done over the years while sipping on the 25 year old single malt I have arranged for the occasion. With the ability for everyone to ask questions or otherwise contribute.
The meeting might be recorded and made available for watching after the fact.
The actual links needed to join or watch the celebrations will be added to this blog post closer to the event start.
When a security vulnerability has been found and confirmed in curl, we request a CVE Id for the issue. This is a global unique identifier for this specific problem. We request the ID from our CVE Numbering Authority (CNA), Hackerone, which once we make the issue public will publish all details about it to MITRE, which hosts the central database.
In the curl project we have until today requested CVE Ids for and provided information about 135 vulnerabilities spread out over twenty-five years.
A CVE identifier affects a specific product (or set of products), and the problem affects the product from a version until a fixed version. And then there is a severity. How bad is the problem?
CVSS score
The Common Vulnerability Scoring System (CVSS) is a way to grade severity on a scale from zero to ten. You typically use a CVSS calculator, fill in the info as good as you can and voilá, out comes a score.
The ranges have corresponding names:
Name
Range
Low
lower 4
Medium
4.0-6.9
High
7.0-8.9
Critical
9 or higher
CVSS is a shitty system
Anyone who ever gets a problem reported for their project and tries to assess and set a CVSS score will immediately realize what an imperfect, simplified and one-dimensional concept this is.
The CVSS score leaves out several very important factors like how widespread the affected platform is, how common the affected configuration is and yet it is still very subjective as you need to assess as and mark different things as None, Low, Medium or High.
The same bug is therefore likely to end up with different CVSS scores depending on who fills in the form – even when the persons are familiar with the product and the error in question.
curl severity
In the curl project we decided to abandon CVSS years ago because of its inherent problems. Instead we use only the four severity names: Low, Medium, High, and Critical and we work out the severity together in the curl security team as we work on the vulnerability. We make sure we understand the problem, the risks, its prevalence and more. We take all factors into account and then we set a severity level we think helps the world understand it.
All security vulnerabilities are vulnerabilities and therefore security risks, even the ones set to severity Low, but having the correct severity is still important in messaging and for the rest of the world to get a better picture of howserious the issue is. Getting the right severity is important.
NVD
Let me introduce yet another player in this game. The National Vulnerability Database (NVD). (And no, it’s not “national” really).
NVD hosts a database of vulnerabilities. All CVEs that are submitted to MITRE are sucked in into NVD’s database. NVD says it “performs analysis on CVEs that have been published to the CVE Dictionary“.
That last sentence is probably important.
NVD imports CVEs into their database and they in turn offer other databases to import vulnerabilities from them. One large and known user of the NVD database is this I mentioned in a recent blog post: GitHub Security Advisory Database (GHSA DB) .
GHSA DB
This GitHub thing an ambitious database that subsequently hosts a lot of vulnerabilities that people and projects reported themselves in addition to them importing information about all vulnerabilities ever published with CVE Ids.
This creates a huge database that in theory should contain just about every software vulnerability ever reported in the public. Pretty cool.
Enter reality
NVD, in their great wisdom, rescores the CVSS score for CVE Ids they import into their database! (It’s not clear how or why, but they seem to not do it for all issues).
NVD decides they know better than the project that set the severity level for the issue, enters their own answers in the CVSS calculator and eventually sets that new score on the CVEs they import.
NVD clearly thinks they need to do this and that they improve the state of the CVEs by this practice, but the end result is close to scaremongering.
Result
Because NVD sets their own severity level and they have some sort of “worst case” approach, virtually all issues that NVD sets severity for is graded worse or much worse when they do it than how we set the severity levels.
Let’s take an example: CVE-2022-42915: HTTP proxy double-free. We deemed this a medium severity. It was not made higher partly because of the very limited time-window between the two frees, making it harder to take advantage of.
Yes, it makes you wonder what magic insights and knowledge the person/bots on NVD possessed when they did this.
Scaremongering
The different severity levels should not matter too much but people find those inflated ones and they believe them. Users also find the discrepancies, get confused and won’t know what to believe or whom to trust. After all, NVD is trust-inducing brand. People think they know their stuff and if they say critical and the curl project says medium, what are we expected to think?
I claim that NVD overstate their severity levels and there unnecessarily scares readers and make them think issues are worse and more dangerous than they actually are.
The fact that GitHub now imports all CVE data from NVD makes these severity levels get transported, shown and believed as they are now also shown in the GHSA DB.
Look how many critical issues there are!
Not exactly GitHub’s fault
This NVD habit of re-scoring is an old existing habit and I just recently learned it. GitHub’s displaying the severity levels highlighted it for me, especially since users out there seem to trust and use this GitHub database.
I have talked to humans on the GitHub database team and I push for them to ignore or filter out the severity levels as set by NVD, if possible. But me being just a single complaining maintainer I do not expect this to have much of an effect. I would urge NVD to stop this insanity if I had any way to.
Hackerone glitches?
(Updated after first post). It turns out that some CVEs that we have filed from the curl project that uses our CNA hackerone have been submitted to MITRE without any severity level or CVSS score at all. For such issues, I of course understand why someone would put their own score on the issue because then our originally set score/severity is not passed on. Then the “blame” is instead shifted to Hackerone. I have contacted them about it.
Dispute a CVSS
NVD provides a way to dispute their rescores, but that’s just an open free-text form. I have use that form to request that NVD stop rescoring all curl issues. Although I honestly think they should rather stop all rescoring and only do that in the rare occasions where the original score or severity is obviously wrong.
I cannot dispute the severity levels at GitHub. They show the NVD levels.