For many years we’ve had this outstanding idea to add a new API to libcurl that would offer applications easy access to HTTP response headers.
Applications could already retrieve the headers using existing methods but that requires them to write a callback and to a certain amount of parsing and “understanding” HTTP that we always felt was a little unfortunate, a bit error-prone on the behalf of the applications and perhaps also a thing that forced a lot of applications out there having to write the same kind of extra function logic.
If libcurl provides this functionality, it would remove a lot of (duplicated) code from a lot of applications.
Designing the API
We started this process a while ago when I first wrote down a basic approach to an API for this and sent it off to the curl-library mailing list for feedback and critique.
/* first take */
char *curl_easy_header(CURL *easy,
const char *name);
The conversation that followed that first plea for help, made me realize that my first proposal had been far too basic and it wouldn’t at all work to satisfy the needs and use cases we could think of for this API.
Try again
I went back to mull over what I’ve learned and update my design proposal, trying to take the feedback into account in the best possible way. A few weeks later, I returned with a “proposal v2” and again I asked for comments and opinions on what I had put together.
/* second shot */
CURLHcode curl_easy_header(CURL *easy,
const char *name,
size_t index,
struct curl_header **h);
As I had already adjusted the API from feedback the first time around, the feedback this time was perhaps not calling for as big changes or radical differences as they did the first time around. I could adapt my proposal to what people asked and suggested. We arrived at something that seemed like a pretty solid API for offering HTTP headers to applications.
Let’s do this
As the API proposal feedback settled down and the interface felt good and sensible, I decided it was time for me to write up a first implementation so that we can offer code to people to give everyone a chance to try out the API in real life as well. There’s one thing to give feedback on a “paper product”, actually being able to use it and try it in an application is way better. I dove in.
The final take
When the code worked to the level that I started to be able to extract the first headers with the API, it proved to that we needed to adjust the API a little more, so I did. I then ran into more questions and thoughts about specifics that we hadn’t yet dealt with or nailed proper in the discussions up to that point and I took some questions back to the curl community. This became an iterative process and we smoothed out questions about how access different header “sources” as well as how to deal with multiple headers and “request sequences”. All supported now.
/* final version */
CURLHcode curl_easy_header(CURL *easy,
const char *name,
size_t index,
unsigned int origin,
int request,
struct curl_header **h);Multiple headers
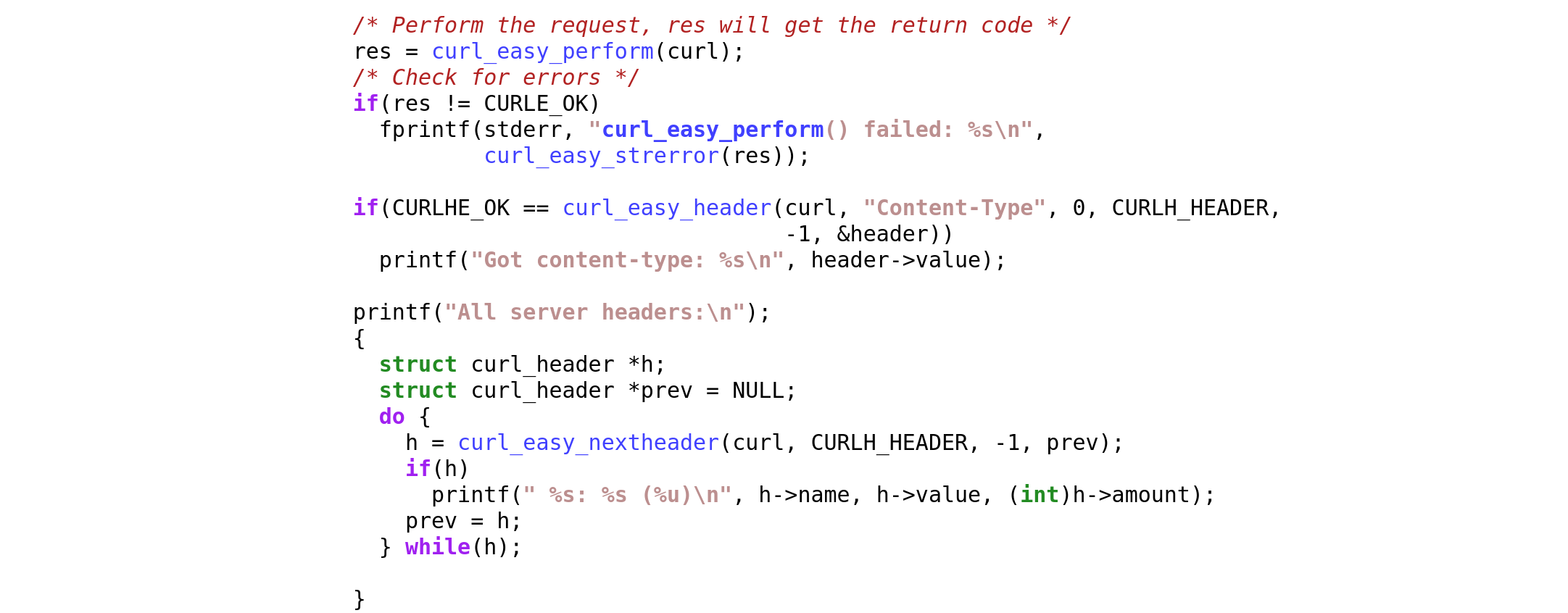
This API allows applications to extract all headers from a previous transfer. It can get one or many headers when there are duplicated ones, like Set-Cookie: commonly arrive as.
Sources
The application can ask for “normal” headers, for trailers (that arrive after the body), headers associated with the CONNECT request (if such a one was performed), pseudo headers (that might arrive when HTTP/2 and HTTP/3 is used) or headers associated with a HTTP 1xx “intermediate” response.
Multiple responses
The libcurl APIs typically work on transfers, which means that a single transfer may end up doing multiple transfers, multiple HTTP requests. Primarily when redirects are followed but it can also be due to other reasons. This header API therefore allows the caller to extract headers from the entire “chain” of requests a previous transfer was made with.
EXPERIMENTAL
This API is initially merged (in this commit) labeled “experimental” to be included in the upcoming 7.83.0 release. The experimental label means a few different things to us:
- The API is disabled by default in the build and you need to explicitly ask for it with
--enable-headers-apiwhen you run configure - There are no ABI and API promises for these functions yet. We might change the functions based on feedback before we remove the label.
- We strongly discourage anyone from shipping experimentally labeled functions in production.
- We rely on people to enable and test this and provide feedback, to give us confidence enough to remove the experimental label as soon as possible.
We use the experimental “route” to lower the bar for merging new stuff, so that we get some extra chances to fix up mistakes before the rules and API are carved in stone and we are set to support that for a life time.
This setup relies on users actually trying out the experimental stuff as otherwise it isn’t method for improving the API, it will only delay the introduction of it to the general public. And it risks becoming be less good.
Documentation
The two new functions have detailed man pages: curl_easy_header and curl_easy_nextheader. If there is anything missing on unclear in there, let us know!
I have also created an initial example source snippet showing header API use. See headerapi.c.
This API deserves its own little section in the everything curl book, but I think I will wait for it to get landed “for real” before I work on adding that.