One positive thing among many others at this version of the HTTP Workshop (day one, day two) is the fact that there have been several new faces showing up here. People who have not previously attended any HTTP Workshops. Getting fresh blood into the mix is great. A chance to maybe lower the average age of the attendees also feels welcome.
This half day was the final session for this time. Three topics were dealt with.
Do you speak HTTP? Getting your HTTP implementation to do right according to the specification can be a challenge. There is a whole range of existing tests for various areas of HTTP but there might still be a place to add HTTP semantic tests in particular for servers. Discussions brought about reflections around testing, doing tests, test formats, other tests, test infrastructure and more. I think the general sense was that yes it would be great. At least if someone else makes it happen…
Workshop feedback and thoughts. What is a good cadence for future events, how long should the events be etc. This is probably the maximum amount of attendees we can handle using the same setup. This event was clearly better than several of the past ones in terms of diversity, but I will second our “workshop maestro” in that it could improve further still. We also discussed whether do-arranging together with IETF is good or bad, should it then be before or after IETF?
I think the consensus said that making it biannual event is good. The reasoning for keeping the event in Europe has been because a larger share of the European attendees come from smaller companies compared to the non-Europeans which to a larger degree come from larger companies that might have it easier to pay for longer trips.
My personal take
The HTTP Workshop is a one-of-a-kind event. At these events everything is about and around HTTP with an information density level that is super high. We get to learn how things actually work for people or that do not work. And that we are not alone in whatever struggles or HTTP challenges we have.
Networking with other doers here and absorbing every protocol detail being expressed, gives food for thoughts and lessons to take advantage from in years to come when we for sure are going to take HTTP transfers further. This is in many ways a kind of brain fertilizer event.
Did I mention I enjoyed it? I will certainly try to attend the next one.
In an office building close to the Waterloo station in London, around 40 persons again sat down at this giant table forming a big square that made it possible for us all to see each other. One by one there were brief presentations done with follow-up discussions. The discussions often reiterated old truths, brought up related topics and sometimes went deep down into the weeds about teeny weeny details of the involved protocol specs. The way we love it.
The people around the table represent Ericsson, Google, Microsoft, Apple, Meta, Akamai, Cloudflare, Fastly, Mozilla, Varnish. Caddy, Nginx, Haproxy, Tomcat, Adobe and curl and probably a few more I forget now. One could say with some level of certainty that a large portion of every day HTTP traffic in the world is managed by things managed by people present here.
This morning we all actually understood that the south entrance is actually the east one (yeah, that’s a so called internal joke) and most of us were sitting down, eager and prepared when the day started at 9:30 am.
Capsule. The capsule protocol (RFC 9297) is a way to, put simply, send UDP packets/datagrams over old style HTTP/1 or HTTP/2 proxies.
Cookies. With the 6265bis effort well on its way to ship as an updated RFC, there is an effort and intent to take yet another stab at improving and refreshing the cookie spec situation. In particular to better split off browser management and API related stuff from the more network-oriented over-the-wire details. You know yours truly never ceases an opportunity to voice his opinion on cookies… I approve of this attempt as well, as I think increasing clarity and improving the specification situation can’t but to help improve things.
Declarative web push. There’s an ongoing effort to improve web push – not to be confused with server push, so that it can be done easier and without needing JavaScript to manage it in the client side.
Reverse HTTP. There are origins who want to contact their CDNs without having to listening on any ports/sockets and still be able to provide content. That’s one of the use cases for Reverse HTTP and we got to learn details from internet drafts done on the topics for the last fifteen years and why it might still be a worthwhile effort and why the use cases still exist. But is there an enough demand to put it into HTTP?
Server Stack Detection. A discussion around how someone can detect the origin of the server stack of any given HTTP server implementation. Should there be a better way? What is the downside of introducing what would basically be the server version of the user-agent header field? Lots of productive discussions on how to avoid recreating problems of the past but in a reversed way.
MoQ: What is it and why is it not just HTTP/3? Was an educational session about the ongoing work done in this working group that is wrongly named and would appreciate more input from the general protocol community.
New HTTP stack. A description of the journey of a full HTTP stack rewrite: how components can be chained together and in which order and a follow-up discussion about if this should be included in documentation and if so in which way etc. Lessons included that the spec is one thing, the Internet is another. Maybe not an entirely new revelation.
Multiplexing in the year 2024. There are details in HTTP/2 multiplexing that does not really work, there are assumptions that are now hard to change. To introduce new protocols and features in the modern HTTP stack, things need to be done for both HTTP/2 and HTTP/3 that are similar but still different and it forces additional work and pain.
What if we create a way to do multiplexing over TCP, so called “over streams”, so that the HTTP/3 fallback over TCP could still be done using HTTP/3 framing. This would allow future new protocols to remain HTTP/3-only and just make the transport be either QUIC+UDP or Streams-over TCP+TLS. This triggered a lot of discussions, mostly positive and forward-looking but also a lot of concerns raised about additional work and yet another protocols component to write and implement that then needs to be supported until the end of times because things never truly go away completely.
I think this sounds like a fun challenge! Count me in.
End of day two. I need a beer or two to digest this.
For the sixth time, this informal group of HTTP implementers and related “interested parties” unite in a room over a couple of days doing a HTTP Workshop. Nine years since that first event in Münster, Germany.
If you are someone like me, obsessed with networking and HTTP in particular this is certainly the place to be. Talking and discussing past lessons, coming changes and protocol dreams in several days with like-minded people is a blast. The people on these events are friends that I don’t always get to hang out with too often. Many of the attendees here have been involved in this community for a long time and have attended all or most of the past workshops as well. I have fortunately been able to attend all of them so far.
This time we are in London.
Let me tell you a little about the topics of day one – without spilling the beans about exactly who said what or what the company they came from. (I will add links to the presentations later once I know where to link to.)
Make Cleartext HTTP harder. The first discussion point of the day. While we have made HTTPS easier over recent years it can only take us so far. What if we considered means to make HTTP harder to use as the next level efforts to further reduce its use over the internet. The HSTS preload list is only growing. Should we instead convert it into a HSTS exclude list that can shrink over time? This triggered a looong a discussion in the group which brought back a lot of old arguments and reasoning from days I thought we had left behind long ago.
HTTP 2/3 abuses. A prominent implementer of a HTTP proxy/load balancer walked us through a whole series of different HTTP/2 and HTTP/3 protocols details that attackers can have been exploiting in recent years, with details about what can be done to mitigate such attacks. It made several other implementers mention how they take similar precautions and some other general discussions around the topics of what can be considered normal use of the protocol and what is not.
Idle connections & mobile: beneficial or harmful. 0-RTT instead of idle connections. There is a non-negligible cost associate with keeping connections alive for clients running on mobile phones. Would it be possible to instead move forward into a world when they are not kept alive but instead closed and 0-RTT opened again next time they are needed? Again the room woke up to a long discussion about the benefits and problems with doing this – which if it would be possible probably would save a lot of battery time on the average mobile phones.
QUIC pacing. We learned that it is very important for servers to implement decent QUIC pacing as it can increase performance up to 20 times compared to no pacing at all. What about using the flow control properly? What about changing the default buffer sizes for UDP sockets in the Linux kernel to something similar to TCP sockets in order to help the default case to perform better?
HTTP prioritization for product performance. The HTTP/2 way of doing prioritization was deemed a failure and too complicated a long time ago but in this presentation we were taught that there are definitely use cases and scenarios where the regular HTTP/3 priority setup is helpful and improves performs. Examples and descriptions for a popular and well used client were shown.
Allowing HTTP clients to use stale DNS data. What if HTTP clients would use stale data instead of having to wait for the DNS resolver response as a means to avoid having to wait a whole RTT to get the date that in a fair amount of the cases is the same as the stale data. Again a long discussion around TTLs for DNS queries and the fact that some clients are already doing this, in more or less explicit ways.
QUIC cache DSR. As the last talk of the the afternoon we got in the details of Direct Server Response for QUIC and how this can improve performance and problems and challenges involved with this. It then indirectly took us into a long sub-thread talking about HTTP caching, Vary headers and what could and should be done to improve things going forward. There seems to be an understanding that it would be good to improve the current situation but it is not entirely clear to this author exactly what that would entail.
When we then took a walk through the streets of London, only to have an awesome dinner during which we could all conclude that HTTP still is not ready. There is still work to be done. There are challenges left to overcome.
Time for another checkup. Where are we right now with HTTP/3 support in curl for users?
I think curl’s situation is symptomatic for a lot of other HTTP tools and libraries. HTTP/3 has been and continues to be a much tougher deployment journey than HTTP/2 was.
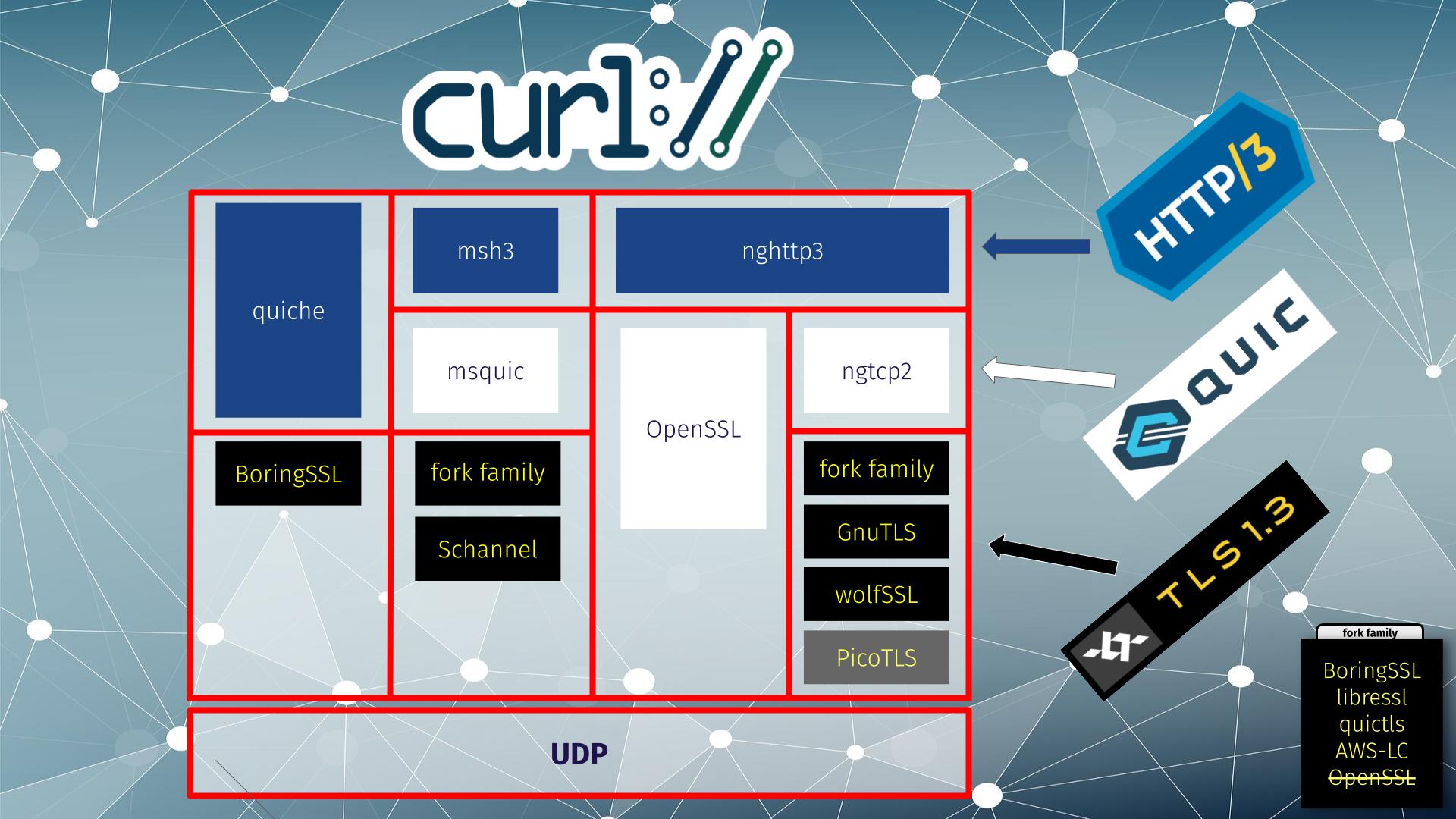
curl supports four alternative HTTP/3 solutions
You can enable HTTP/3 for curl using one of these four different approaches. We provide multiple different ones to let “the market” decide and to allow different solutions to “compete” with each other so that users eventually can get the best one. The one they prefer. That saves us from the hard problem of trying to pick a winner early in the race.
More details about the four different approaches follow below.
Why is curl not using HTTP/3 already?
It already does if you build it yourself with the right set of third party libraries. Also, the curl for windows binaries provided by the curl project supports HTTP/3.
For Linux and other distributions and operating system packagers, a big challenge remains that the most widely used TLS library (OpenSSL) does not offer the widely accepted QUIC API that most other TLS libraries provide. (Remember that HTTP/3 uses QUIC which uses TLS 1.3 internally.) This lack of API prevents existing QUIC libraries to work with OpenSSL as their TLS solution forcing everyone who want to use a QUIC library to use another TLS library – because curl does not easily allows itself to get built using multiple TLS libraries . Having a separate TLS library for QUIC than for other TLS based protocols is not supported.
Debian tries an experiment to enable HTTP/3 in their shipped version of curl by switching to GnuTLS (and building with ngtcp2 + nghttp3).
HTTP/3 backends
To get curl to speak HTTP/3 there are three different components that need to be provided, apart from the adjustments in the curl code itself:
TLS 1.3 support for QUIC
A QUIC protocol library
An HTTP/3 protocol library
Illustrated
Below, you can see the four different HTTP/3 solutions supported by curl in different columns. All except the right-most solution are considered experimental.
HTTP/3 backend support in curl, June 2024
From left to right:
the quiche library does both QUIC and HTTP/3 and it works with BoringSSL for TLS
msh3 is an HTTP/3 library that uses mquic for QUIC and either a fork family or Schannel for TLS
nghttp3 is an HTTP/3 library that in this setup uses OpenSSL‘s QUIC stack, which does both QUIC and TLS
nghttp3 for HTTP/3 using ngtcp2 for QUIC can use a range of different TLS libraries: fork family, GnuTLS and wolfSSL. (picotls is supported too, but curl itself does not support picotls for other TLS use)
ngtcp2 is ahead
ngtcp2 + nghttp3 was the first QUIC and HTTP/3 combination that shipped non-beta versions that work solidly with curl, and that is the primary reason it is the solution we recommend.
The flexibility in TLS solutions in that vertical is also attractive as this allows users a wide range of different libraries to select from. Unfortunately, OpenSSL has decided to not participate in that game so this setup needs another TLS library.
OpenSSL QUIC
OpenSSL 3.2 introduced a QUIC stack implementation that is not “beta”. As the second solution curl can use. In OpenSSL 3.3 they improved it further. Since early 2024 curl can get built and use this library for HTTP/3 as explained above.
However, the API OpenSSL provide for doing transfers is lacking. It lacks vital functionality that makes it inefficient and basically forces curl to sometimes busy-loop to figure out what to do next. This fact, and perhaps additional problems, make the OpenSSL QUIC implementation significantly slower than the competition. Another reason to advise users to maybe use another solution.
We keep communicating with the OpenSSL team about what we think needs to happen and what they need to provide in their API so that we can do QUIC efficiently. We hope they will improve their API going forward.
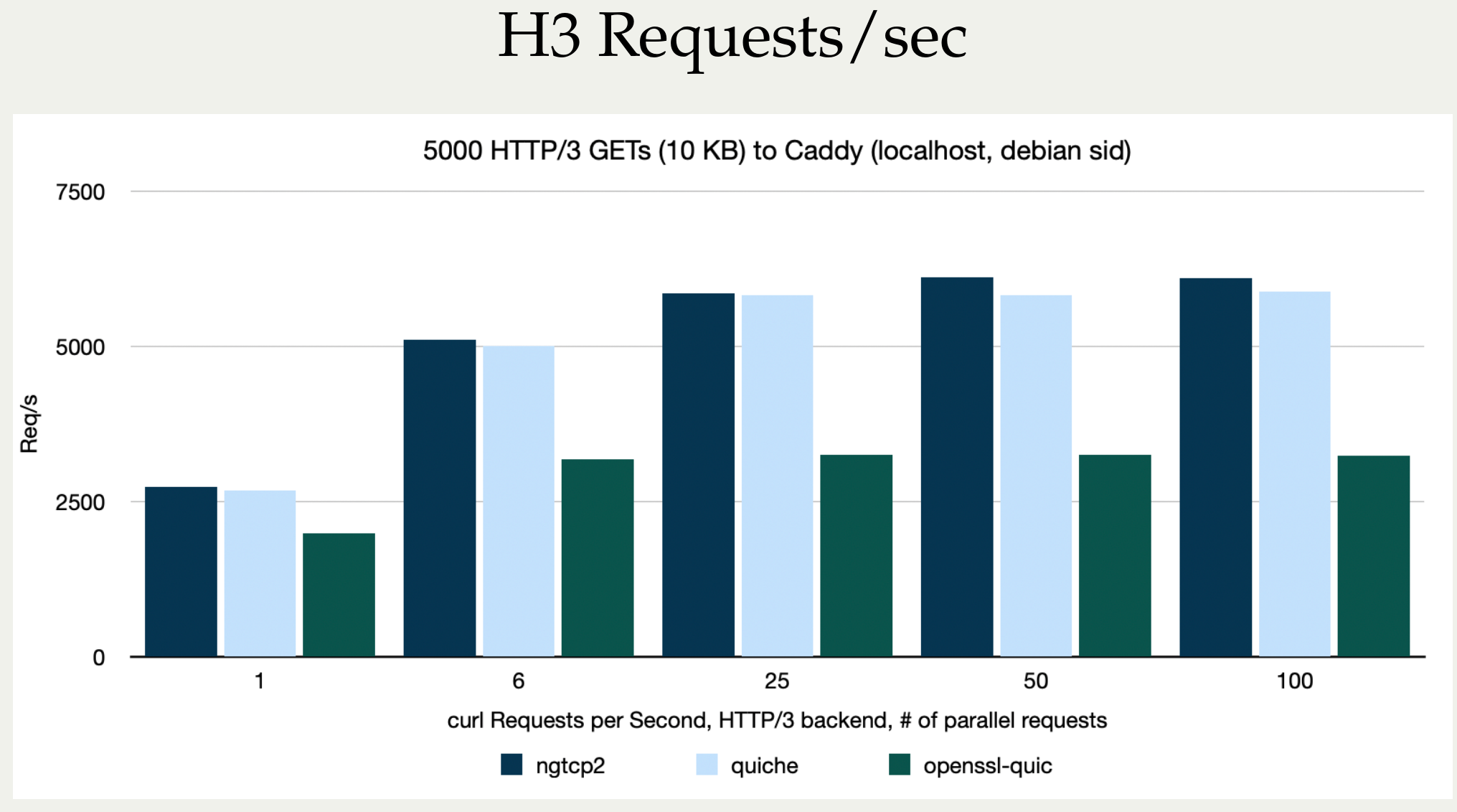
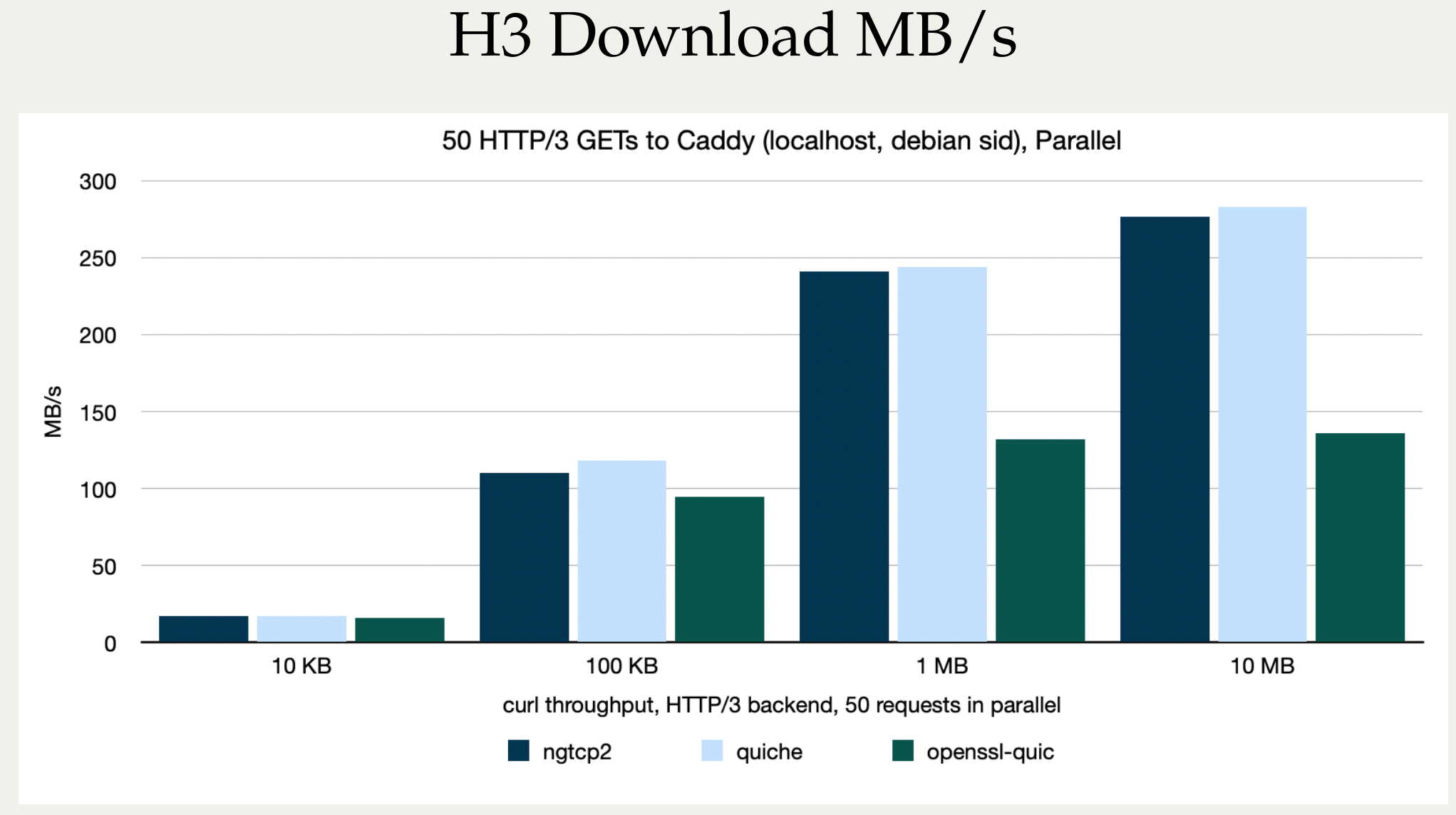
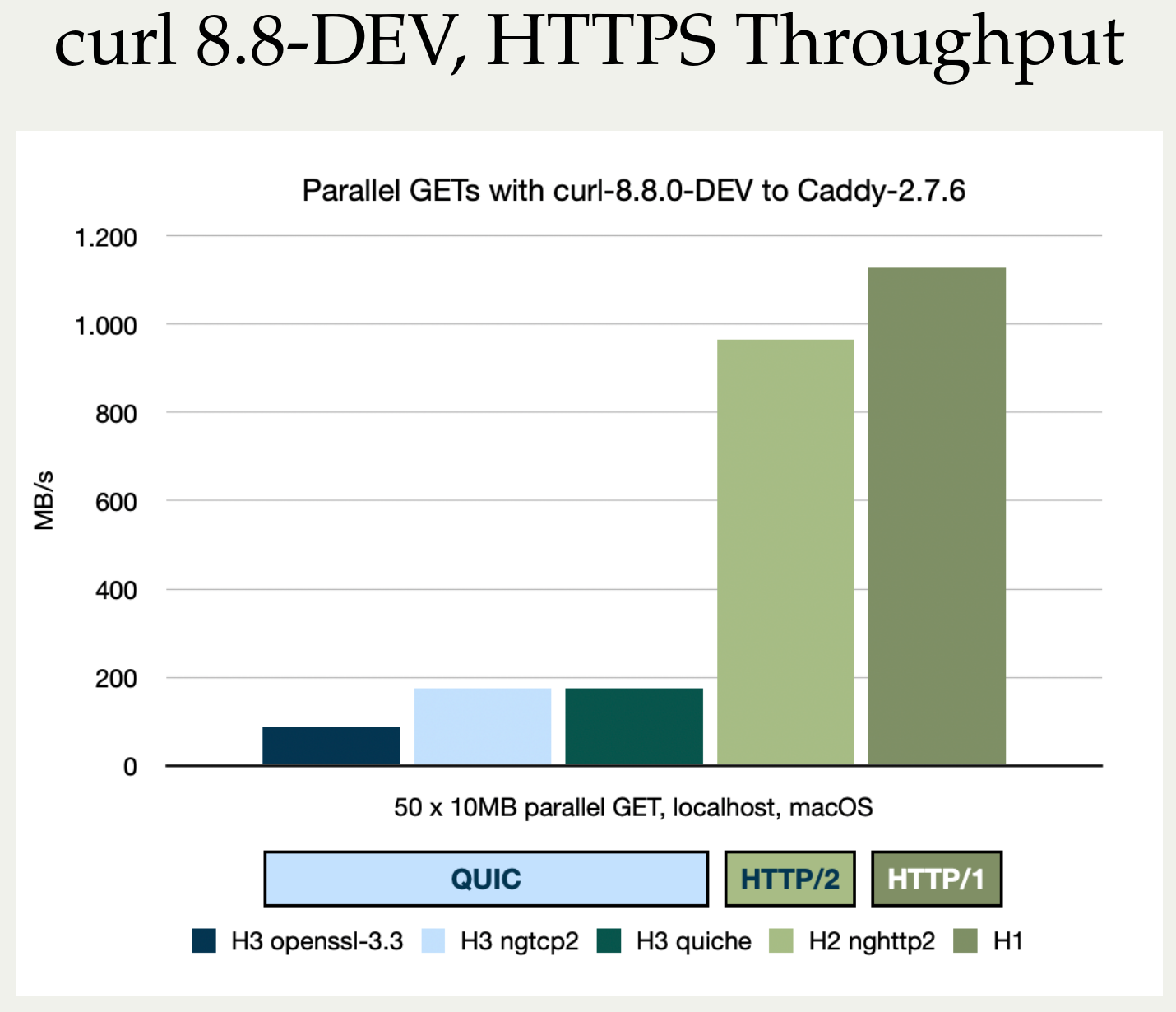
Stefan Eissing produced nice comparisons graph that I have borrowed from his Performance presentation (from curl up 2024. Stefan also blogged about h3 performance in curl earlier.). It compares three HTTP/3 curl backends against each other. (It does not include msh3 because it does not work good enough in curl.)
As you can see below, in several test setups OpenSSL is only achieving roughly half the performance of the other backends in both requests per second and raw transfer speed. This is on a localhost, so basically CPU bound transfers.
HTTP/3 backend performance in curl compared, requests/second
HTTP/3 backend performance in curl compared, megabytes/second
I believe OpenSSL needs to work on their QUIC performance in addition to providing an improved API.
quiche and msh3
quiche is still labeled beta and is only using BoringSSL which makes it harder to use in a lot of situations.
msh3 does not work at all right now in curl after a refactor a while ago.
HTTP/3 is a CPU hog
This is not news to anyone following protocol development. I have been repeating this over and over in every HTTP/3 presentation I have done – and I have done a few by now, but I think it is worth repeating and I also think Stefan’s graphs for this show the situation in a crystal clear way.
HTTP/3 is slow in terms of transfer performance when you are CPU bound. In most cases of course, users are not CPU bound because typically networks are the bottlenecks and instead the limited bandwidth to the remote site is what limits the speed on a particular transfer.
HTTP/3 is typically faster to completing a handshake, thanks to QUIC, so a HTTP/3 transfer can often get the first byte transmitted sooner than any other HTTP version (over TLS) can.
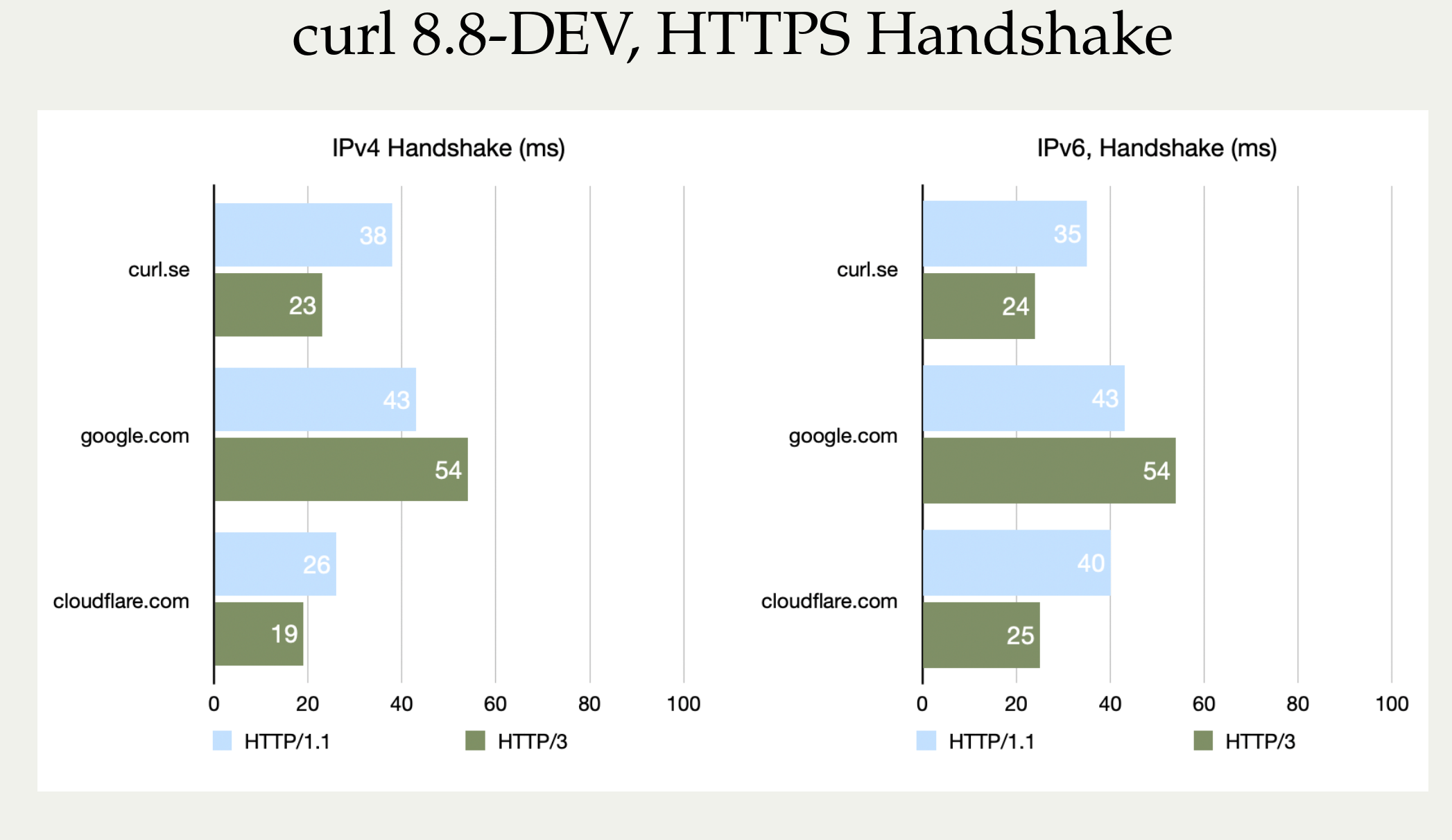
To show how this looks with more of Stefan’s pictures, let’s first show the faster handshakes from his machine somewhere in Germany. These tests were using a curl 8.8.0-DEV build, from a while before curl 8.8.0 was released.
HTTP/3 vs HTTP/1.1 handshake performance in curl compared
Nope, we cannot explain why google.com actually turned out worse with HTTP/3. It can be added that curl.se is hosted by Fastly’s CDN, so this is really comparing curl against three different CDN vendors’ implementations.
HTTP/3 vs HTTP/2 vs HTTP/1.1 throughput performance in curl compared
Again: these are CPU bound transfers so what this image really shows is the enormous amounts of extra CPU work that is required to push these transfers through. As long as you are not CPU bound, your transfers should of course run at the same speeds as they do with the older HTTP versions.
These comparisons show curl’s treatment of these protocols as they are not generic protocol comparisons (if such are even possible). We cannot rule out that curl might have some issues or weird solutions in the code that could explain part of this. I personally suspect that while we certainly always have areas for improvement remaining, I don’t think we have any significant performance blockers lurking. We cannot be sure though.
OpenSSL-QUIC stands out here as well, in the not so attractive end.
HTTP/3 deployments
w3techs, Mozilla and Cloudflare data all agree that somewhere around 28-30% of the web traffic is HTTP/3 right now. This is a higher rate than HTTP/1.1 for browser traffic.
An interesting detail about this 30% traffic share is that all the big players and CDNs (Google, Facebook, Cloudflare, Akamai, Fastly, Amazon etc) run HTTP/3, and I would guess that they combined normally have a much higher share of all the web traffic than 30%. Meaning that there is a significant amount of browser web traffic that could use HTTP/3 but still does not. Unfortunately I don’t have the means to figure out explanations for this.
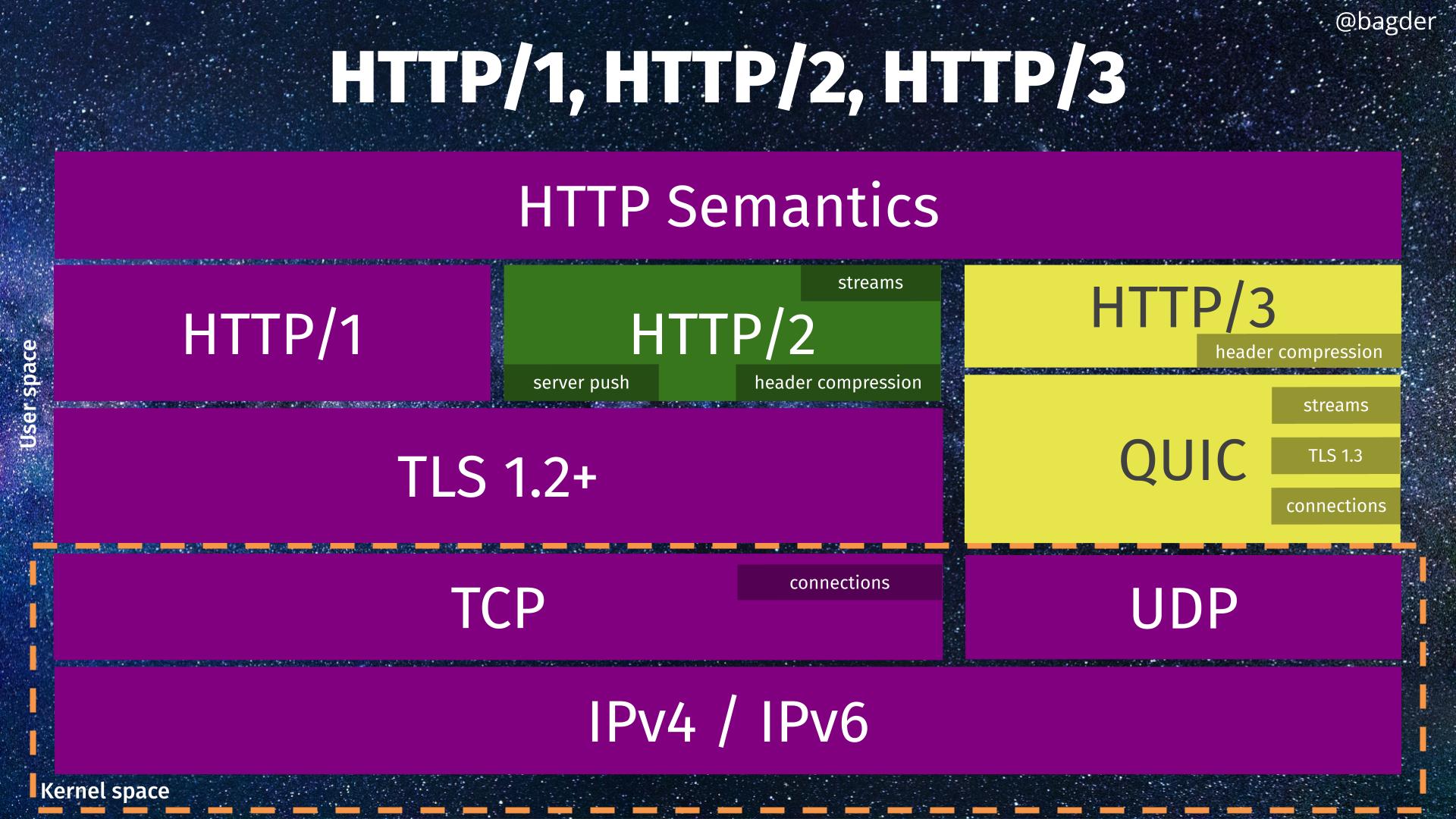
HTTPS stack overview
In case you need a reminder, here is how an HTTPS stack works.
trurl is a tool in a similar spirit of tr but for URLs. Here, tr stands for translate or transpose.
trurl is a small command line tool that parses and manipulates URLs, designed to help shell script authors everywhere.
URLs are tricky to parse and there are numerous security problems in software because of this. trurl wants to help soften this problem by taking away the need for script and command line authors everywhere to re-invent the wheel over and over.
trurl uses libcurl’s URL parser and will thus parse and understand URLs exactly the same as curl the command line tool does – making it the perfect companion tool.
I created trurl on March 31, 2023.
Some command line examples
Given just a URL (even without scheme), it will parse it and output a normalized version:
$ trurl ex%61mple.com/
http://example.com/
The above command will guess on a http:// scheme when none was provided. The guess has basic heuristics, like for example FTP server host names often starts with ftp:
$ trurl ftp.ex%61mple.com/
ftp://ftp.example.com/
A user can output selected components of a provided URL. Like if you only want to extract the path or the query components from it.:
trurl can read URLs to work on off a file or from stdin, and works on them in a streaming fashion suitable for filters etc.
$ cat many-urls.yxy | trurl --url-file -
...
More or different
trurl was born just a few days ago, this is what we have made it do so far. There is a high probability that it will change further going forward before it settles on exactly how things ideally should work.
It also means that we are extra open for and welcoming to feedback, ideas and pull-requests. With some luck, this could become a new everyday tool for all of us.
Starting this week, you can subscribe to my weekly report and receive it as an email. This is the brief weekly summary of my past week that I have been writing and making available for over a year already. It sums up what I have been doing recently and what I plan to do next.
Topics in the reports typically involve a lot of curl, libcurl, HTTP, protocols, standards, networking and related open source stuff.
By subscribing to this by email, you will receive a ping and get it in your inbox as soon as it it exists. This saves you from reloading the weekly report web page or risk missing my updates on social media.
Follow what happens in the projects I run and participate in. Keep up with the latest developments in all the open source and network related stuff that occupy my every day life.
Why email?
I was already sending this report over email to some receivers, so I figured I could just invite everyone who wants to receive it the same way. Depending on how people take this, I might decide to rather only do this over email going forward.
Your feedback will help me decide on how this plays out.
The weekly report emails are archived, so you can go back and check them after the fact as well.
Every human has a unique fingerprint. With only an impression of a person’s fingertip, it is possible to follow the lead back to the single specific individual wearing that unique pattern.
TLS fingerprints
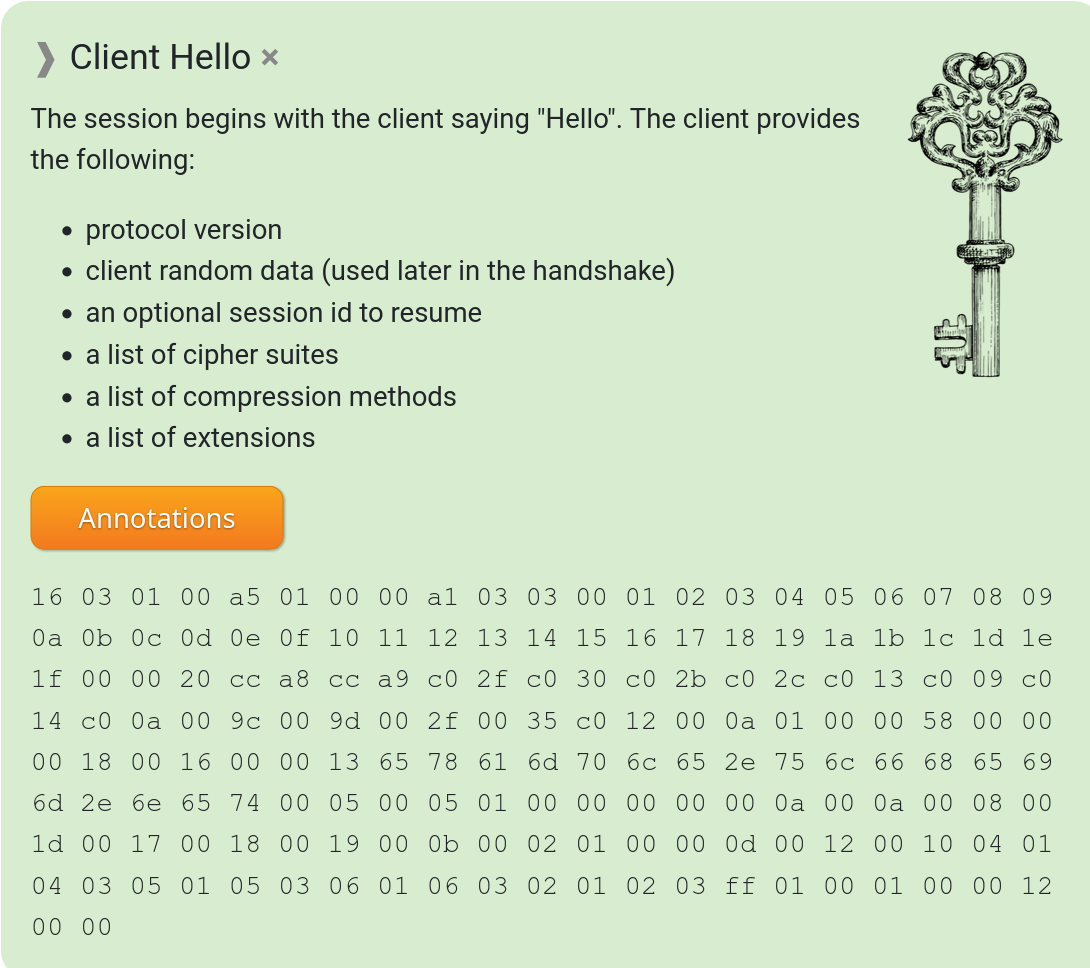
The phrase TLS fingerprint is of course in this spirit. A pattern in a TLS handshake that allows an involved party to tell or at least guess with a certain level of accuracy what client software that performed it – purely based on how exactly the TLS magic is done. There are numerous different ways and variations a client can perform a TLS handshake and still be standards compliant. There is a long list of extensions that can vary in content, the order of the list of extensions, the ciphers to accept, the allowed TLS versions, steps performed, the order and sequence of those steps and more.
When a network client connects to a remote site and makes a TLS handshake with the server, the server can basically add up all those details and make an educated guess exactly which client that connects to it. One method to do it is called JA3 and produces a 32 digit hexadecimal number as output. (The three creators of this algorithm all have JA as their initials!)
In use out there
I have recently talked with customers and users who have faced servers that refused them access when they connected to sites using curl, but allowed them access to the site when they instead use one of the popular browsers – or if curl was tweaked to look like one of those browsers. It might be a trend in the making. There might be more sites out there now that reject clients that produce the wrong fingerprint then there used to be.
Why
Presumably there are many reasons why servers want to limit access to a subset of clients, but I think the general idea is that they want to prevent “illegitimate” user agents from accessing their sites.
For example, I have seen online market sites use this method in an what I have perceived as an attempt to block bots and web scrapers. Or they do it to block malware or other hostile clients that scour their website.
How
There’s this JA3 page that shows lots of implementations for many services that can figure out clients’ TLS fingerprints and act on them. And there’s nothing that says you have to do it with JA3. There’s likely to be numerous other ways and algorithms as well.
There are also companies that offer commercial services to filter off mismatching clients from your site. This is real business.
A TLS Client hello message has lots of info.
Other fingerprinting
In the earlier days of the web, web sites used more basic ways to detect and filter out bots and non-browser user clients. The original and much simpler way is to check the User-Agent: field that HTTP clients pass on, but has also sometimes been extended to check the order of the sent HTTP headers and in some cases, servers have used elaborate JavaScript schemes in order to try to “smoke out” the clients that don’t seem to act like full-fledged browsers.
If the clients use HTTP/2, that too allows for more details to fingerprint.
As the web has transitioned over to almost exclusively use HTTPS, it has severely increased the ways a server can fingerprint clients, and at the same time made it harder for non-browser clients to look exactly like browsers.
Allow list or block list
Sites that use TLS fingerprints to allow access, of course do not want too many false positives. They want to allow all “normal” browser-based visitors, even if they use a little older versions and also if they use somewhat older or less common operating systems.
This means that they either have to work hard to get an extensive list of acceptable hashes in an accept list or they add known non-desired clients in a block list. I would imagine that if you go the accept list route, that’s how companies can sell this services as that is maintenance intensive work.
Users of alternative and niche browsers are sometimes also victims in this scheme if they stand out enough.
Altering the fingerprint
The TLS fingerprints have the interesting feature compared to human fingertip prints, that they are the result of a set of deliberate actions and not just a pattern you are born to wear. They are therefore a lot easier to change.
With curl version C using TLS library T of version V, the TLS fingerprint is a function that involves C, T and V. And the options O set by curl. By changing one or more of those variables, you are likely to alter the TLS fingerprint.
Match a browser exactly
To be most certain that no site will reject your curl request because of its TLS fingerprint, you would alter the print to look exactly like the one of a popular browser. You can suspect that most sites want their regular human browser-using visitors to be able to access them.
To make curl look exactly like a browser you also likely need to do more than just change C, O, T and V from the section above. You also need to make sure that the TLS library you use produces its lists of extensions and ciphers in exactly the same order etc. This may require that you alter options and maybe even source code.
curl-impersonate
This is a custom build of curl that can impersonate the four major browsers: Chrome, Edge, Safari & Firefox. curl-impersonateperforms TLS and HTTP handshakes that are identical to that of a real browser.
curl-impersonate is a modified curl build and the project also provides docker images and more to help users to use it easily.
I cannot say right now if any of the changes done for curl-impersonate will get merged into the upstream curl project, but it will also depend on what users want and how the use of TLS fingerprinting spread or changes going forward.
Program a browser
Another popular way to work around this kind of blocking is to simply program a browser to do the job. Either a headless browser or with tools like Selenium. Since these methods make the TLS handshake using a browser “engine”, they are unlikely to get blocked by these filters.
Cat and mouse
Servers add more hurdles to attempt to block unwanted clients.
Clients change to keep up with the servers and to still access the sites in spite of what the server admins want.
Future
As early as only a few years ago I had never heard of any site that blocked clients because of their TLS handshake. Through recent years I have seen it happen and the use of it seems to have increased. I don’t know of any way to measure if this is actually true or just my feeling.
I cannot rule out that we are going to see this more going forward, even if I also believe that the work on circumventing these fingerprinting filters is just getting started. If the circumvention grows and becomes easy enough, maybe it will stifle servers from adding these filters as they will not be effective anyway?
Let us come back to this topic in a few years and see where it went.
The first mention of QUIC on this blog was back when I posted about the HTTP workshop of July 2015. Today, this blog is readable over the protocol QUIC subsequently would turn into. (Strictly speaking, it turned into QUIC + HTTP/3 but let’s not be too literal now.)
The other day Fastly announced that all their customers now can enable HTTP/3, and since this blog and the curl site are graciously running on the Fastly network I went ahead and enabled the protocol.
Within minutes and with almost no mistakes, I could load content over HTTP/3 using curl or browsers. Wooosh.
The name HTTP/3 wasn’t adopted until late 2018, and the RFC has still not been published yet. Some of the specifications for QUIC have however.
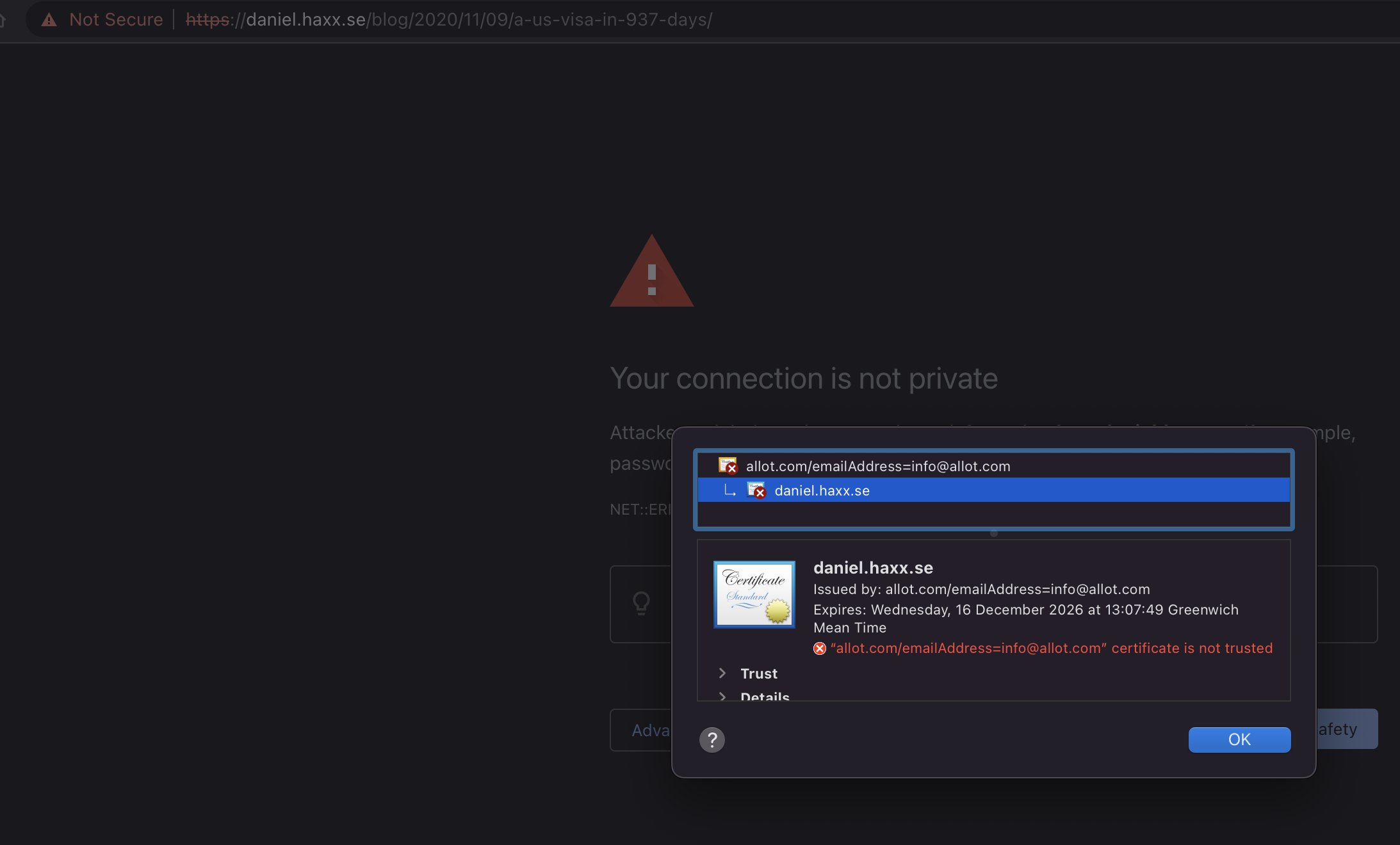
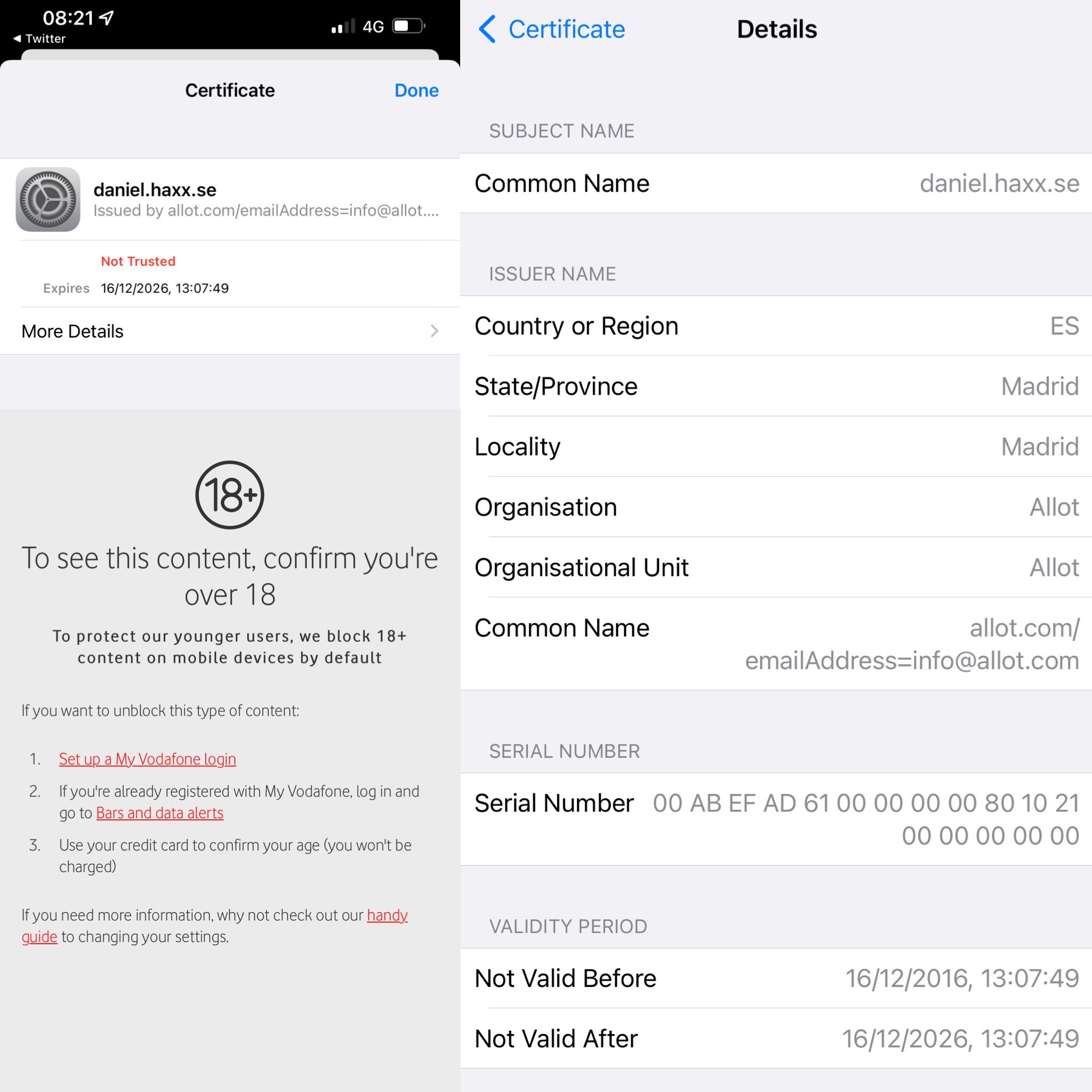
Vodafone UK has taken it on themselves to make the world better by marking this website (daniel.haxx.se) “adult content”. I suppose in order to protect the children.
It was first reported to me on May 2, with this screenshot from a Vodafone customer:
And later followed up with some more details from another user in this screenshot
Customers can opt out of this “protection” and then apparently Vodafone will no longer block my site.
How
I was graciously given more logs (my copy) showing DNS resolves and curl command line invokes.
It shows that this filter is for this specific host name only, not for the entire haxx.se domain.
It also shows that the DNS resolves are unaffected as they returned the expected Fastly IP addresses just fine. I suspect they have equipment that inspects outgoing traffic that catches this TLS connection based on the SNI field.
As the log shows, they then make their server do a TLS handshake in which they respond with a certificate that has daniel.haxx.se in the CN field.
The curl verbose output shows this:
* SSL connection using TLSv1.2 / ECDHE-ECDSA-CHACHA20-POLY1305
* ALPN, server did not agree to a protocol
* Server certificate:
* subject: CN=daniel.haxx.se
* start date: Dec 16 13:07:49 2016 GMT
* expire date: Dec 16 13:07:49 2026 GMT
* issuer: C=ES; ST=Madrid; L=Madrid; O=Allot; OU=Allot; CN=allot.com/emailAddress=info@allot.com
* SSL certificate verify result: self signed certificate in certificate chain (19), continuing anyway.
> HEAD / HTTP/1.1
> Host: daniel.haxx.se
> User-Agent: curl/7.79.1
> Accept: */*
>
The allot.com clue is the technology they use for this filtering. To quote their website, you can “protect citizens” with it.
I am not unique, clearly this has also hit other website owners. I have no idea if there is any way to appeal against this classification or something, but if you are a Vodafone UK customer, I would be happy if you did and maybe linked me to a public issue about it.
Update
I was pointed to the page where you can request to unblock specific sites so I have done that now (at 12:00 May 2).
Update on May 3
My unblock request for daniel.haxx.se is apparently “on hold” according to the web site.
I got an email from an anonymous (self-proclaimed) insider who says he works at Allot, the company doing this filtering for Vodafone. In this email, he says
Most likely, Vodafone is using their parental control a threat protection module which works based on a DNS resolving.
and then
After the business logic decides to block the website, it tells the DNS server to reply with a custom IP to a server that always shows a block page, because how HTTPS works, there is no way to trick it, either with Self-signed certificate, or using a signed certificate for a different domain, hence the warning.
What is weird here is that this explanation does not quite match what I have seen the logs provided to me. They showed this filtering clearly not being DNS based – since the DNS resolves got the exact same IP address a non-filtered resolver does.
Someone on Vodafone UK could of course easily test this by simply using a different DNS server, like 1.1.1.1 or 8.8.8.8.
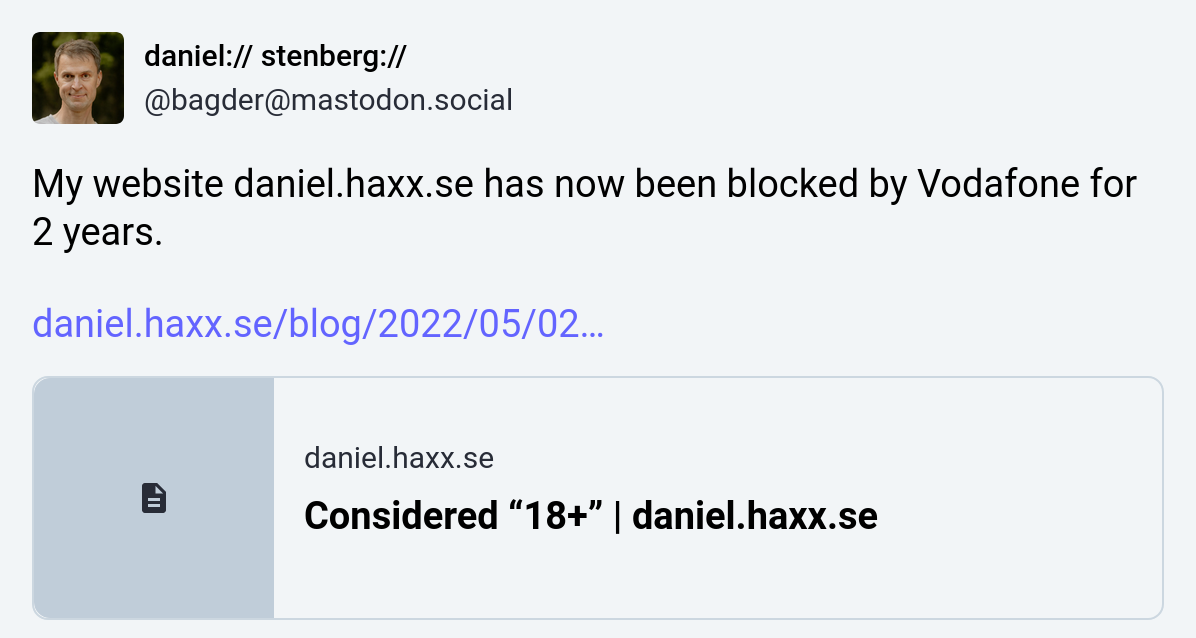
Two years later the situation was the same and I wrote about it on Mastodon:
Just hours later I was emailed by a person who explained they are employed by Vodafone and they forwarded my post internally. The blocking should thereby be gone. The original block was wrongly applied and then my unblocking request from two years ago “never reached the responsible team”.
When you use the name localhost in a URL, what does it mean? Where does the network traffic go when you ask curl to download http://localhost ?
Is “localhost” just a name like any other or do you think it infers speaking to your local host on a loopback address?
Previously
curl http://localhost
The name was “resolved” using the standard resolver mechanism into one or more IP addresses and then curl connected to the first one that works and gets the data from there.
The (default) resolving phase there involves asking the getaddrinfo() function about the name. In many systems, it will return the IP address(es) specified in /etc/hosts for the name. In some systems things are a bit more unusually setup and causes a DNS query get sent out over the network to answer the question.
In other words: localhost was not really special and using this name in a URL worked just like any other name in curl. In most cases in most systems it would resolve to 127.0.0.1 and ::1 just fine, but in some cases it would mean something completely different. Often as a complete surprise to the user…
Starting now
curl http://localhost
Starting in commit 1a0ebf6632f8, to be released in curl 7.78.0, curl now treats the host name “localhost” specially and will use an internal “hard-coded” set of addresses for it – the ones we typically use for the loopback device: 127.0.0.1 and ::1. It cannot be modified by /etc/hosts and it cannot be accidentally or deliberately tricked by DNS resolves. localhost will now always resolve to a local address!
Does that kind of mistakes or modifications really happen? Yes they do. We’ve seen it and you can find other projects report it as well.
Who knows, it might even be a few microseconds faster than doing the “full” resolve call.
(You can still build curl without IPv6 support at will and on systems without support, for which the ::1 address of course will not be provided for localhost.)
Specs say we can
The RFC 6761 is titled Special-Use Domain Names and in its section 6.3 it especially allows or even encourages this:
Users are free to use localhost names as they would any other domain names. Users may assume that IPv4 and IPv6 address queries for localhost names will always resolve to the respective IP loopback address.
Followed by
Name resolution APIs and libraries SHOULD recognize localhost names as special and SHOULD always return the IP loopback address for address queries and negative responses for all other query types. Name resolution APIs SHOULD NOT send queries for localhost names to their configured caching DNS server(s).
Mike West at Google also once filed an I-D with even stronger wording suggesting we should always let localhost be local. That wasn’t ever turned into an RFC though but shows a mindset.
(Some) Browsers do it
Chrome has been special-casing localhost this way since 2017, as can be seen in this commit and I think we can safely assume that the other browsers built on their foundation also do this.
Firefox landed their corresponding change during the fall of 2020, as recorded in this bugzilla entry.
Safari (on macOS at least) does however not do this. It rather follows what /etc/hosts says (and presumably DNS of not present in there). I’ve not found any official position on the matter, but I found this source code comment indicating that localhost resolving might change at some point:
Since some time back, Windows already resolves “localhost” internally and it is not present in their /etc/hosts alternative. I believe it is more of a hybrid solution though as I believe you can put localhost into that file and then have that custom address get used for the name.
Secure over http://localhost
When we know for sure that http://localhost is indeed a secure context (that’s a browser term I’m borrowing, sorry), we can follow the example of the browsers and for example curl should be able to start considering cookies with the “secure” property to be dealt with over this host even when done over plain HTTP. Previously, secure in that regard has always just meant HTTPS.
This change in cookie handling has not happened in curl yet, but with localhost being truly local, it seems like an improvement we can proceed with.
Can you still trick curl?
When I mentioned this change proposal on twitter two of the most common questions in response were
can’t you still trick curl by routing 127.0.0.1 somewhere else
can you still use --resolve to “move” localhost?
The answers to both questions are yes.
You can of course commit the most hideous hacks to your system and reroute traffic to 127.0.0.1 somewhere else if you really wanted to. But I’ve never seen or heard of anyone doing it, and it certainly will not be done by mistake. But then you can also just rebuild your curl/libcurl and insert another address than the default as “hardcoded” and it’ll behave even weirder. It’s all just software, we can make it do anything.
The --resolve option is this magic thing to redirect curl operations from the given host to another custom address. It also works for localhost, since curl will check the cache before the internal resolve and --resolve populates the DNS cache with the given entries. (Provided to applications via the CURLOPT_RESOLVE option.)
What will break?
With enough number of users, every single little modification or even improvement is likely to trigger something unexpected and undesired on at least one system somewhere. I don’t think this change is an exception. I fully expect this to cause someone to shake their fist in the sky.
However, I believe there are fairly good ways to make to restore even the most complicated use cases even after this change, even if it might take some hands on to update the script or application. I still believe this change is a general improvement for the vast majority of use cases and users. That’s also why I haven’t provided any knob or option to toggle off this behavior.
Credits
The top photo was taken by me (the symbolism being that there’s a path to take somewhere but we don’t really know where it leads or which one is the right to take…). This curl change was written by me. Mike West provided me the Chrome localhost change URL. Valentin Gosu gave me the Firefox bugzilla link.