Tim Westermann is the creator who makes, sells and distributes these beauties. My only involvement has been to help Tim with the textual content on them.
There is no money going to me or the curl project as part of this setup. But you might become a better curl user while saving your desk at the same time.
I have a set myself. I love them. Note that they are printed on both sides – with different content.
They do not only look like PCBs, they are high-quality printed circuit boards (PCBs).
Dimensions: 10 cm x 10 cm [3.94″ x 3.94″] Thickness: 1.6mm [0.04″] Weight: 30g
On November 16 2023, I will do a multi-hour tutorial video on how to use libcurl. How to master it. As a follow-up to my previous video class called mastering the curl command line (at 13,000+ views right now).
This event will run as a live-stream webinar combination. You can opt to join via zoom or twitch. Zoom users can ask questions using voice, twitch viewers can do the same using the chat. For attending via Zoom you need to register, for twitch you can just show up.
It starts at 18:00 CET (09:00 PST, 17:00 UTC)
This session is part one of the planned two-part series. The amount of content is simply too much for me to deliver in a single sitting with intact quality. The second part will happen the following Monday, on November 20. Same time.
Both sessions will be recorded and will be made available for browsing after the fact.
At the time of me putting this blog post up the presentation and therefore agenda is not complete. I have also not yet figured out exactly how to do the split between the two episodes. Below you will find the planned topics that will be covered over the two episodes. Details will of course change in the final presentation.
The idea is that very little about developing with libcurl should be left out. This is the most thorough, most advanced, most in-depth libcurl video you ever saw. And it will be shock-full with source code examples. All examples that are shown in the video, are also provided stand-alone for easy browsing, copy and paste and later reading in a dedicated mastering libcurl GitHub repository.
Thank you everyone who has helped out in making curl into what it is today.
We make an effort to note the names of and say thanks to every single individual who ever reported bugs, fixed problems, ran tests, wrote code, polished the website, spell-fixed documentation, assisted debug sessions, helped interpret protocol standards, reported security problems or co-authored code etc.
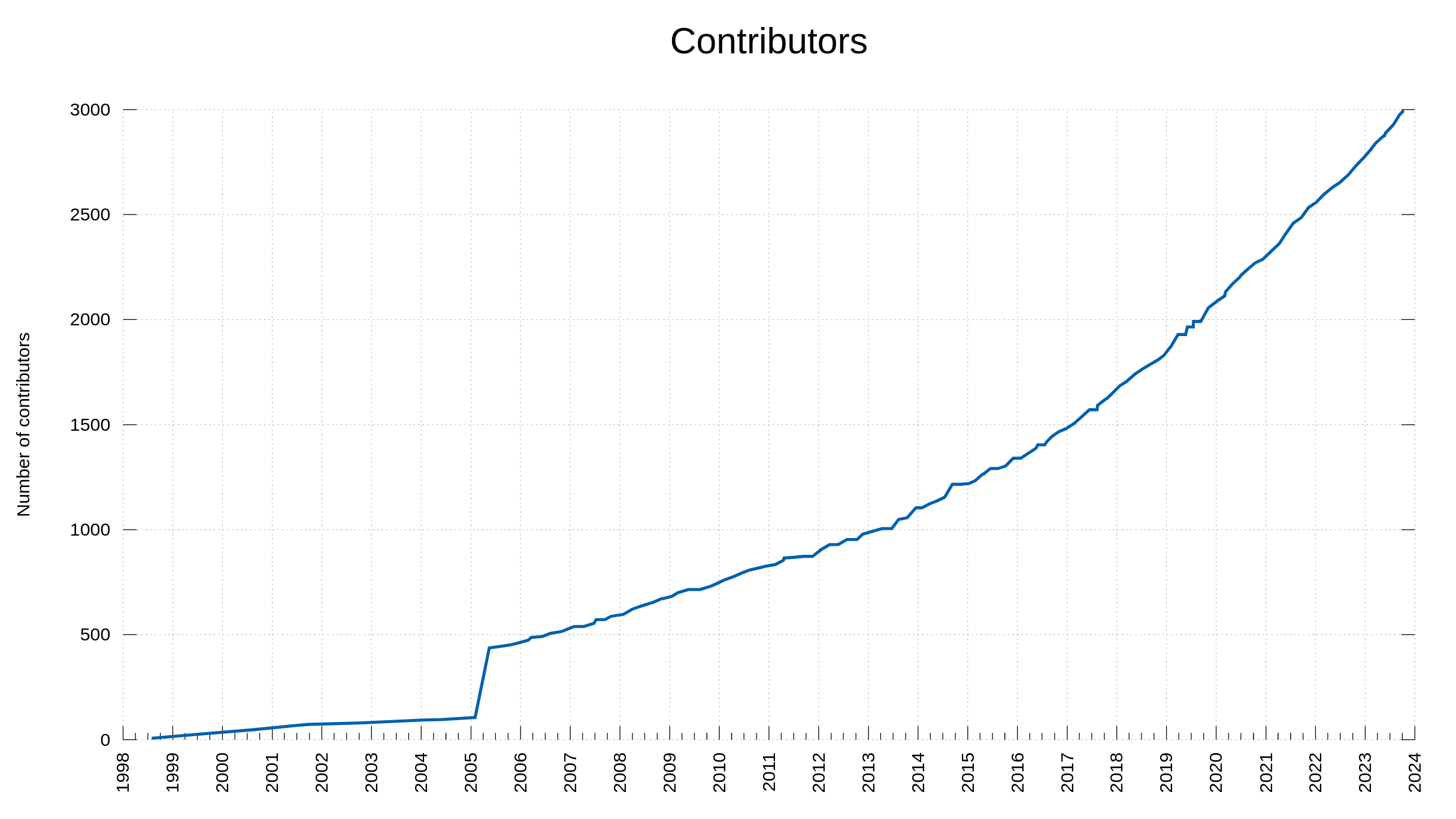
In 2005 I decided to go back through the project history and make sure all names that had been involved up to that point in time would also be mentioned in the THANKS file. This is the reason for the visible bump in the graph.
Since then, we add the names of all the helpers. We say thanks and give credits in commit messages and we have scripts to help us collect them and mention them as contributors. We probably miss occasional ones but I hope and believe that most of all the awesome people that ever helped us are recorded accordingly and given credit.
We are nothing without out dear contributors.
Today, this list of people we are thankful for, reached 3,000 entries when Alex Klyubin’s pull request was merged. (The list of names on the website is synced every once in a while so it actually typically shows slightly fewer people than we have logged in git.)
The team behind curl. 3,000 persons over almost 27 years.
We reached 2,000 contributors less than four years ago, in October 2019, so we have added about 250 new names per year to this list the last four years.
We reached 1,000 contributors in March 2013, meaning from then it took about 6.5 years to get the next 1,000. Roughly 150 new names per year.
The first 1,000 took over 16 years to reach.
You too can see it quite clearly in the graph above as well: the rate of which we get new contributors to help out in the project is increasing.
curl has existed for 9338 days. That equals one new contributor every 3.1 days for over 25 years, on average.
Non-code or code alike
It is oftentimes said that Open Source projects in general have a hard time to properly recognize and appreciate non-code contributions. In the curl project, we try hard to not differentiate between help and help.
If a person helps out to take the curl project further, even if just by a little, we say thank you very much and add their name to the list. We need and are grateful for code and non-code contributions alike. One of the most important parts of the curl project is the documentation, and that is clearly not code.
About the contributors
We cannot say much about the contributors because in an effort to lower the bars and reduce friction, we also do not ask them about details. We only know the name they provide the help under, which could be a pseudonym and in some cases clearly are nicknames. We do not know where in the world they originate from or which company they work for, we can’t tell their gender, skin color, religion or other human “properties”. And we don’t care much about those specifics. Our job is to bring curl forward.
This said: there is a risk that we have added the same contributors twice or more, if they have helped out using several different names. That is just not something we can detect or avoid. Unless the contributor themself informs us.
There is also a risk that some of the persons that contributed to curl are not nice people or that they work for reprehensible organizations. We focus on the quality of their submissions and if they hide who they are, we will never know if they actually are animal-hurting nazis hiding behind pseudonyms.
(Lack of) Diversity
As far as I can tell, we have a lousy contributor diversity. I am pretty sure the majority of all help come from old white middle-class western men. Like myself.
I cannot fully know this for sure because I only actually know a small fraction of all the contributors, but out of the ones I have met this is true and I believe I have met or at least communicated with the ones who have done the vast majority of all the changes.
I would much rather see us have many more contributors from other parts of the world, female, and with non-christian backgrounds, but I cannot control who comes to us. I can only do my best to take care of all and appreciate every contribution without discrimination.
Commit authors
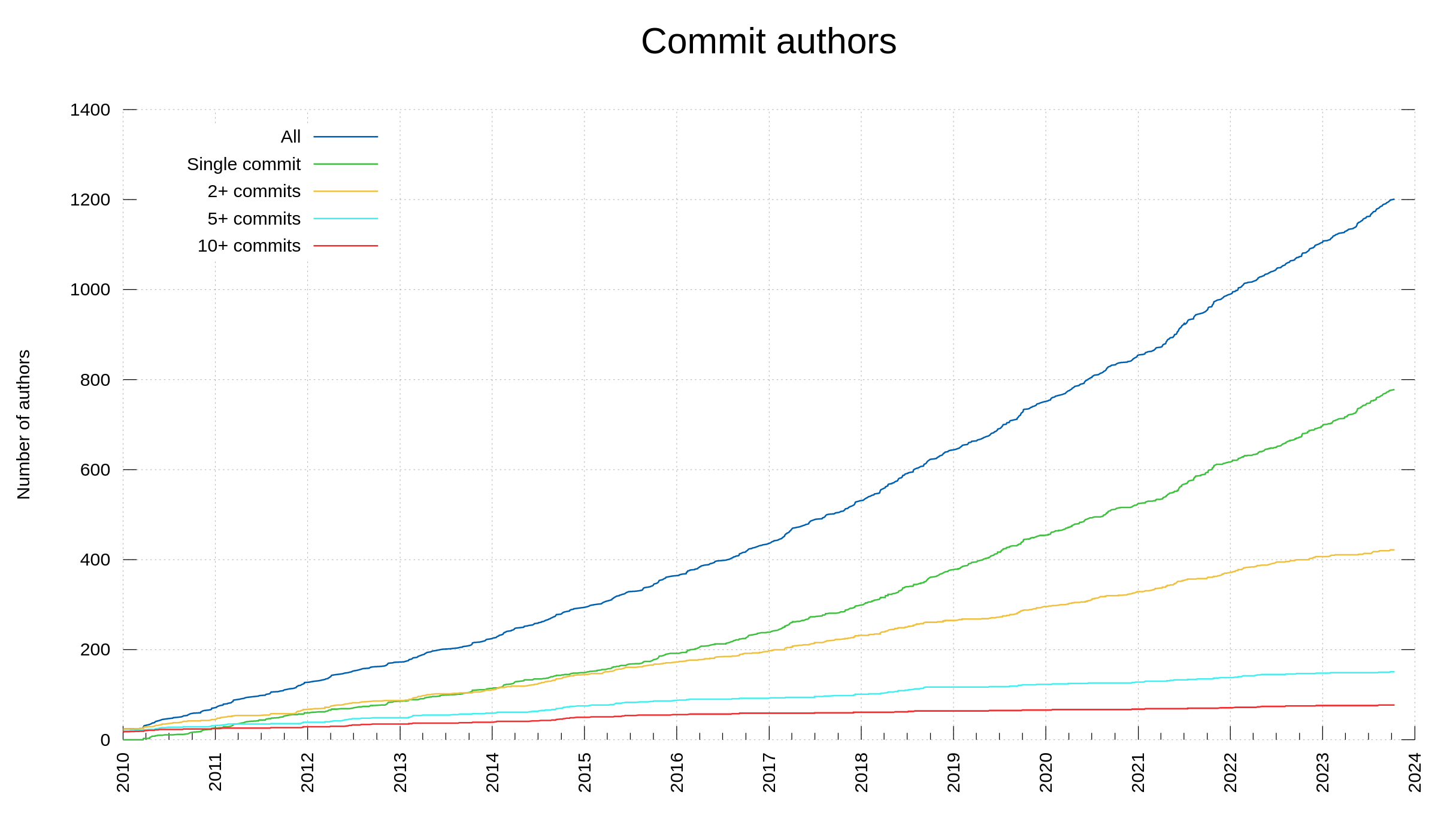
This day when we reach 3,000 contributors, we also count 1,201 commit authors. Persons with their names as authors of at least one commit in the curl source repository. 40% of the contributors are committers. Almost 65% of the committers only ever committed once.
3,000 visualized
The top image of this blog post is a photo from FOSDEM a few years back when I did a presentation in front of a packed room with some 1,400 attendees. The largest room at FOSDEM is said to fit 1415 persons. So not even two such giant rooms would be enough to hold all the curl contributors if it would have been possible to get them all in one place…
You too?
You too can be a curl contributor. We are friendly. It is not hard. There is lots to do. Your contributions can end up getting used by literally billions of humans.
In association with the release of curl 8.4.0, we publish a security advisory and all the details for CVE-2023-38545. This problem is the worst security problem found in curl in a long time. We set it to severity HIGH.
While the advisory contains all the necessary details. I figured I would use a few additional words and expand the explanations for anyone who cares to understand how this flaw works and how it happened.
SOCKS5 is a proxy protocol. It is a rather simple protocol for setting up network communication via a dedicated “middle man”. The protocol is for example typically used when setting up communication to get done over Tor but also for accessing Internet from within organizations and companies.
SOCKS5 has two different host name resolver modes. Either the client resolves the host name locally and passes on the destination as a resolved address, or the client passes on the entire host name to the proxy and lets the proxy itself resolve the host remotely.
In early 2020 I assigned myself an old long-standing curl issue: to convert the function that connects to a SOCKS5 proxy from a blocking call into a non-blocking state machine. This is for example much noticeable when an application performs a large amount of parallel transfers that all go over SOCKS5.
On February 14 2020 I landed the main commit for this change in master. It shipped in 7.69.0 as the first release featuring this enhancement. And by extension also the first release vulnerable to CVE-2023-38545.
A less wise decision
The state machine is called repeatedly when there is more network data to work on until it is done: when the connection is established.
This boolean variable holds information about whether curl should resolve the host or just pass on the name to the proxy. This assignment is done at the top and thus for every invocation while the state machine is running.
The state machine starts in the INIT state, in which the main bug for today’s story time lies. The flaw is inherited from the function from before it was turned into a state-machine.
SOCKS5 allows the host name field to be up to 255 bytes long, meaning a SOCKS5 proxy cannot resolve a longer host name. On finding a too long host name. the curl code makes the bad decision to instead switch over to local resolve mode. It sets the local variable for that purpose to TRUE. (This condition is a leftover from code added ages ago. I think it was downright wrong to switch mode like this, since the user asked for remote resolve curl should stick to that or fail. It is not even likely to work to just switch, even in “good” situations.)
The state machine then switches state and continues.
The issue triggers
If the state machine cannot continue because it has no more data to work with, like if the SOCKS5 server is not fast enough, it returns. It gets called again when there is data available to continue working on. Moments later.
But now, look at the local variable socks5_resolve_local at the top of the function again. It again gets set to a value depending on proxy mode – not remembering the changed value because of the too long host name. Now it again holds a value that says the proxy should resolve the name remotely. But the name is too long…
curl builds a protocol frame in a memory buffer, and it copies the destination to that buffer. Since the code wrongly thinks it should pass on the host name, even though the host name is too long to fit, the memory copy can overflow the allocated target buffer. Of course depending on the length of the host name and the size of the target buffer.
Target buffer
The allocated memory area curl uses to build the protocol frame in to send to the proxy, is the same as the regular download buffer. It is simply reused for this purpose before the transfer starts. The download buffer is 16kB by default but can also be set to use a different size at the request of the application. The curl tool sets the buffer size to 100kB. The minimum accepted size is 1024 bytes.
If the buffer size is set smaller than 65541 bytes this overflow is possible. The smaller the size, the larger the possible overflow.
Host name length
A host name in a URL has no real size limit, but libcurl’s URL parser refuses to accept names longer than 65535 bytes. DNS only accepts host names up 253 bytes. So, a legitimate name that is longer than 253 bytes is unusual. A real name that is longer than 1024 is virtually unheard of.
Thus it pretty much requires a malicious actor to feed a super-long host name into this equation to trigger this flaw. To use it in an attack. The name needs to be longer than the target buffer to make the memory copy overwrite heap memory.
Host name contents
The host name field of a URL can only contain a subset of octets. A range of byte values are plain invalid and would cause the URL parser to reject it. If libcurl is built to use an IDN library, that one might also reject invalid host names. This bug can therefore only trigger if the right set of bytes are used in the host name.
Attack
An attacker that controls an HTTPS server that a libcurl using client accesses over a SOCKS5 proxy (using the proxy-resolver-mode) can make it return a crafted redirect to the application via a HTTP 30x response.
Such a 30x redirect would then contain a Location: header in the style of:
… where the host name is longer than 16kB and up to 64kB
If the libcurl using client has automatic redirect-following enabled, and the SOCKS5 proxy is “slow enough” to trigger the local variable bug, it will copy the crafted host name into the too small allocated buffer and into the adjacent heap memory.
A heap buffer overflow has then occurred.
The fix
curl should not switch mode from remote resolve to local resolve due to too long host name. It should rather return an error and starting in curl 8.4.0, it does.
We now also have a dedicated test case for this scenario.
Credits
This issue was reported, analyzed and patched by Jay Satiro.
This is the largest curl bug-bounty paid to date: 4,660 USD (plus 1,165 USD to the curl project, as per IBB policy)
Classic related Dilbert strip. The original URL seems to no longer be available.
Rewrite it?
Yes, this family of flaws would have been impossible if curl had been written in a memory-safe language instead of C, but porting curl to another language is not on the agenda. I am sure the news about this vulnerability will trigger a new flood of questions about and calls for that and I can sigh, roll my eyes and try to answer this again.
The only approach in that direction I consider viable and sensible is to:
allow, use and support more dependencies written in memory-safe languages and
potentially and gradually replace parts of curl piecemeal, like with the introduction of hyper.
Such development is however currently happening in a near glacial speed and shows with painful clarity the challenges involved. curl will remain written in C for the foreseeable future.
Everyone not happy about this are of course welcome to roll up their sleeves and get working.
Including the latest two CVEs reported for curl 8.4.0, the accumulated total says that 41% of the security vulnerabilities ever found in curl would likely not have happened should we have used a memory-safe language. But also: the rust language was not even a possibility for practical use for this purpose during the time in which we introduced maybe the first 80% of the C related problems.
It burns in my soul
Reading the code now it is impossible not to see the bug. Yes, it truly aches having to accept the fact that I did this mistake without noticing and that the flaw then remained undiscovered in code for 1315 days. I apologize. I am but a human.
It could have been detected with a better set of tests. We repeatedly run several static code analyzers on the code and none of them have spotted any problems in this function.
In hindsight, shipping a heap overflow in code installed in over twenty billion instances is not an experience I would recommend.
Behind the scenes
To learn how this flaw was reported and we worked on the issue before it was made public. Go check the Hackerone report.
On Scott Adams
I use his “I’m going to write myself a minivan”-strip above because it’s a classic. Adams himself has turned out to be a questionable person with questionable opinions and I do not condone or agree with what he says.
(CVE-2023-38546) This flaw allows an attacker to insert cookies at will into a running program using libcurl, if the specific series of conditions are met and the cookies are put in a file called “none” in the application’s current directory.
Changes
IPFS protocols via HTTP gateway
The curl tool now supports IPFS URLs via gateway. I emphasize that it is the tool because this support is not libcurl. The URL needs to be a correct IPFS URL but curl only works with it if you provide an IPFS gateway, it has no actual native IPFS implementation. You want to read the new IPFS section on the curl website for details.
This is new and very simply function added to the libcurl API: it returns all the easy handles that were previously added to it.
dropped support for legacy mingw.org toolchain
The legacy mingw version is deprecated and by dropping support for this we can simplify code a little.
Bugfixes
Some of the things we fixed in this release are…
made cmake more aligned with configure
Numerous smaller and larger fixes went in this cycle to make sure the cmake and configure configs are more aligned and create more similar default builds.
expire the timeout when trying next IP
Iterating over IP addresses when connecting could accidentally do delays, making the process take longer time than necessary.
remove unnecessary cookie struct fields
curl now keeps much less data in memory per cookie
update curl man page references
All curl man pages got their references updated and they are now verified and checked in tests to remain accurate and well formatted.
use per-request counter to check too large http headers
The check that prevents too large accumulated HTTP response headers actually used the wrong counter so it kicked in too early.
aws-sigv4: fix sorting with empty parts
Getting this authentication method to work in all cases turns out to be a real adventure and in this release we fix yet some minor issues.
let the max file size option stop too big transfers
Up until now, the maximum file size option only works on stopping transfers before it even began if libcurl knew the file size was too big. Starting now, it will also stop ongoing transfers if they reach the maximum limit. This should help users avoid unwanted surprises.
lib: use wrapper for curl_mime_data fseek callback
Rewinding files when doing multipart formbased transfers on 32 bit ARM using the legacy libcurl curl_formadd API did not work because of data size incompatibilities. It took some work to find and understand as it still worked fine on x86 32 bit for example!
libssh: cap SFTP packet size sent
The libssh library mostly passes on the data with the same size libcurl passes to it, it turns out. That is not compatible with the SFTP protocol so in order to make libcurl work better, it now caps how much data it can send in a single libssh send call. It probably makes SFTP uploads much slower.
misc: better random boundary separators
The mime boundaries used for multipart formposts now use more random bits than before. Up from 64 to 130 bits. It now produces strings using alphanumerical characters instead of just hex.
quic: set ciphers/curves like for TLS
The same style of support for setting TLS 1.3 ciphers and curves as for regular TLS were added to the QUIC code.
http2: retry on GOAWAY
Improved handling of GOAWAY when wanting to use use connection and then move on to use another.
fall back to http/https proxy env-variable if ws/wss not set
When using one of the WebSocket schemes, curl will now fall back and try the http_proxy and https_proxy environment variables if ws_proxy or wss_proxy is not set.
accept –expand on file names too
The variable --expand functionality did not work for command line options that accept file names, such as --output. It does now.
Next
We have synced the coming release cycles on this release. The next one is thus planned to happen in exactly eight weeks time. On December 6, 2023.
The number of security fixes is adjusted due to the recently rejected CVE-2023-32001
Security
We publish a security advisory in association with today’s release.
HTTP headers eat all memory
[CVE-2023-38039] When curl retrieves an HTTP response, it stores the incoming headers so that they can be accessed later via the libcurl headers API.
However, curl did not have a limit in how many or how large headers it would accept in a response, allowing a malicious server to stream an endless series of headers and eventually cause curl to run out of heap memory.
Changes
curl: make %output{} in -w specify a file to write to
The super handy option –write-out become even more convenient now as it can redirect its output into a specific file and not just stdout and stderr.
curl: add “variable” support
The new variable concept now only lets users use environment variables on config files but also opens up for new ways to use curl command lines effectively.
remove gskit support
The gskit TLS library is no longer a provided option when building curl.
remove NSS support
The NSS TLS library is no longer a provided option when building curl. curl still supports building with twelve different TLS libraries even after the removal of these two.
configure –disable-bindlocal builds curl without local binding support
As a next step in the gradual movement to allow more and more features to get enabled/disabled at build time, the time came to the bindlocal function, which is the feature that binds the local end of a connection. Primarily intended for tiny-curl purposes when you aim for a minimal footprint build.
make tracing available in non-debug builds
Starting now, libcurl offers curl_global_trace and curl offers –trace-config to ask for what specific details to include in the verbose logging output. This is a way for a non-debug build to provide more protocol level details from transfers in ways that were previously not possible. Allows for users to report bugs better and provide more insights from real-world problematic scenarios.
CURLOPT_MAXREDIRS defaults to 30
As a precaution, we change the default from unlimited to 30.
CURLU_PUNY2IDN – convert punycode to IDN
The URL API gets the ability to convert to an International Domain Name when given a punycode version. Previously it could only do the conversion in the other direction.
wolfssl: support loading system CA certificates
curl built with wolfSSL now can use the “native CA” option which then makes it possible to use the native CA store on several platforms instead of using a separately provided external file.
Bugfixes
More than 160 bugfixes are logged for this release, but here are a few selected highlights.
accept and parse IPv6 addresses in alt-svc response headers
Previously curl would not parse and accept such hosts.
c-ares: reduce timeout to 2000ms
The default c-ares DNS timeout is set to the same time that c-ares itself has changed to in their next pending release.
make CURLOPT_HAPROXY_CLIENT_IP set the source IP
It was wrongly set as destination instead of source.
cmake: ten separate improvements
Numerous smaller and larger fixes that made the cmake build of curl several notches better.
stop halving the remaining connect timeout when less than 600 ms left
When curl connects to a host that resolves to multiple IP addresses, it allows half the timeout time for the current IP before it moves on to attempt the next IP in the list. That “halving” is now stopped when there is less than 600 milliseconds left to reduce problems with too short times.
docs: rewrite to present tense
Most of the curl documentation now says “this option does this” instead of “this option will do this”
escape all dashes (ASCII minus) to avoid Unicode hyphens in curl.1 man page
It turns out the curl man page as generated previously, would make the man command use a Unicode hyphen instead of ASCII minus when displayed. This broke copy and paste and it made it impossible to properly search for minus/dash when viewing the man page.
accept leading whitespace on first HTTP response header
curl is now less strict if the first HTTP/1 response header starts with space or tab, thus looking like it is a “fold” when it not. Other commonly used tools/browsers accept this kind of bad syntax and so does curl now.
avoid too early HTTP/2 connection re-use/multiplexing
When doing lots of parallel transfers curl might need to create a second connection when the first reaches its maximum number of streams. In that situation, curl would try to multiplex on that new connection too early, already before it was properly setup and be ready for use, leading to transfer errors.
http/http2/http3: fix sending large requests
Logic for all supported HTTP versions had (different) issues in handling sending very large requests.
aws-sigv4: canonicalize the query
Using aws-sigv4 authentication would fail if the query part was not manually crafted to be correct: sorted, uppercase %-encoding and all the name/value pairs alpha-sorted. Now curl does this itself.
make aws-sigv4 not require TLS to be used
The –aws-sigv4 option no longer requires an HTTPS:// URL to be used.
lib: move mimepost data from ->req.p.http to ->state
The moving of internal data from one struct to another made data survive between two requests and thus fixed a bug involving redirects with MIMEPOST that needed to rewind.
use PF_INET6 family lookups when CURL_IPRESOLVE_V6 is set
Turns out curl would still resolve both IPv4 and IPv6 names even if ipv6-only connections were being requested, thus getting some extra names in vein.
system.h: add CURL_OFF_T definitions on HP-UX with HP aCC
Starting now, curl builds properly on more HP-UX machines.
tests: update cookie expiry dates to far in the future
curl’s test suite now runs fine even when executed in a year after 2038.
tool_filetime: make -z work with file dates before 1970
The -z option can get the file date off a local file and use that in a HTTP time condition request, but if the file was older than January 1 1970 it would act wrongly.
transfer: also stop the sending on closed connection
When curl sent off a HTTP/1 request and the connection was closed before the sending was complete, curl could end up not detecting that and ending the transfer correctly.
don’t set TIMER_STARTTRANSFER on first send
Adjustments were made to make this timestamp work as actually documented.
make zoneid duplicated in curl_url_dup
This dup function did not correctly duplicate the zone id from the source handle, making it an incomplete duplicate.
quic: don’t set SNI if hostname is an IP address
curl would wrongly populate the SNI field with the IP address when doing QUIC connections to such.
Next
This is a dot-zero release. If there are any important enough regressions shipped in this version, we will do a follow-up release within shortly. Report all and any problems you spot.
On August 26 I posted details here on my blog about the bogus curl issue CVE-2020-19909. Luckily, it got a lot of attention and triggered discussions widely. Maybe I helped shed light on the brittleness of this system. This was not a unique instance and it was not the first time it happened. This has been going on for years.
Some people did in discussions following my blog post insist that a signed long overflow is undefined behavior in C and since it truly is undefined all bets are off so this could be a security issue.
I am not a fan of philosophical thought exercises around vulnerabilities. They are distractions from the real matters and I find them rather pointless. It is easy to test how this flaw plays out on numerous platforms using numerous compilers. It’s not a security problem on any of them. Even if the retry time would go down to 0, it is not a DOS to do multiple internet transfers next to each other. If it would be, then a browser makes a DOS every time you visit a website – and curl does it when you give it two URLs on the same command line. Unexpected behavior and a silly bug, yes. Security flaw: no.
Not to even mention that no person or script actually would use such numbers on the command line that trigger the bug. This is the bug that never triggered for anyone who did not deliberately try to make it happen.
Who gets to report a CVE
A CVE Id is basically just a bug tracker identifier. You can ask for a number for a problem you found, and by the nature of this you don’t even have to present many details when you ask for it. You are however supposed to provide them when the issue goes public. CVE-2020-19909 certainly failed this latter step. You could perhaps ask why MITRE even allows for CVEs to get published at all if there isn’t more information available.
When you request a CVE Id, there are a few hundred distributed CVE number authorities (CNAs) you can get the number from.
CNA
A CNA can (apparently) require to be consulted if the ask is in regards to their scope. To their products.
I have initiated work on having curl become a CNA; to take responsibility for all CVEs that concern curl or libcurl. I personally think it is rather problematic that this basically is the only available means to prevent this level of crap, but I still intend to attempt this route.
Lots of other Open Source projects (Apache, OpenSSL, Python, etc) already are CNAs, many of them presumably because they realized these things much faster than me. I suspect curl is a smaller shop than most of the existing CNAs, but I don’t think size matters here.
It does of course add administration and work for us which is unfortunate, because that time and energy could be spent on more productive activities, but it still feels like a reasonable thing to try. Hopefully this can also help combat inflated severity levels.
MITRE: Reject 2020-19909 please
The main care-taker of the CVE database is MITRE. They provide a means for anyone to ask for updates to already published CVEs. I submitted my request for rejection using their online form, explaining that this issue is not a security problem and thus should be removed again. With all the info I had, including a link to my blog post.
They denied my request.
Their motivation? The exact quote:
After review there are multiple perspectives on whether the issue information is helpful to consumers of the CVE List, our current preference is in the direction of keeping the CVE ID assignment. There is a valid weakness (integer overflow) that can lead to a valid security impact (denial of service, based on retrying network traffic much more often than is documented/requested).
This is signed CVE Assignment Team, no identifiable human involved.
It is not a Denial of Service. It’s blatant scaremongering and it helps absolutely no one to say that it is.
NVD: Rescore 2020-19909 please
NVD maintains some sort of database and index with all the CVE Ids. They score them and as you may remember, they decided this non-issue is a 9.8 out of 10 severity.
The same evening I learned about this CVE I contacted NVD (nvd@nist.gov), pointed out this silliness and asked them to act on it.
A few days later they responded. From the National Vulnerability Database Team, no identifiable human.
First, they of course think their initial score was a fair assessment:
At the time of analysis, information for this CVE record was particularly sparse. Per NVD policy, if any information is lacking, unclear or conflicts between sources, the NVD policy is to represent the worst-case scenario. The NVD takes this conservative approach to avoid under reporting the possible severity of a given vulnerability.
Meaning: when they don’t know, they make up the worst possible scenario. That is literally what they say and how they act. Panic by default.
However, at this time there are more information sources and clarifications provided that make amendment of the CVSS vector string appropriate. We will break down the various amendments for transparency and to assist in confirmation of the appropriateness of these changes by you or a member of your team.
Meaning: their messed up system requires us to react and provide additional information to them to trigger a reassessment and them updating the score. To lower the panic level.
NVD themselves will not remove any CVE. As long as MITRE says it is a genuine issue, NVD shows it.
Rescore
As a rejection of the CVE was denied, the secondary goal would be to lower NVD’s severity score as much as possible.
The NVD response helped me understand how their research into and analyses of issues are performed.
Their email highlighted three specific items in the CVSS score and how they could maybe re-evaluate them to a lower setting. How do they base and motivate that? Providing links to specific reddit discussions for details of the CVE-2020-19909 problems. Postings done by the ordinary set of pseudonymous persons. Don’t get me wrong, some of those posts are excellent and clearly written by skilled and knowledgeable persons. It just seems a bit… arbitrary.
I did not participate in those discussions and neither did any curl core contributor to my knowledge. There are simply no domain experts involved there.
No reading or pointing to code. No discussions on data input and what changing retry delays mean and not a single word on UB. No mention on why no or a short delay would imply DOS.
Eventually, their proposed updated CVSS ends up with a new score of…
3.3
To be honest, I find CVSS calculations exhausting and I did not care to evaluate their proposal very closely. Again, this is not a security problem.
If you concur with the assessment above based on publicly available information this would change the vector string as follows:
I have not personally checked the scoring very closely. I do not agree with the premise that this is a security problem. It is bad, wrong and hostile to insist that non-issues are security problems. It is counter-productive for the entire industry.
As they set it to 3.3 it at least takes the edge off this silliness and I feel a little bit better. They now also link to my blog post from their CVE-2020-19909 info page, which I think is grand of them.
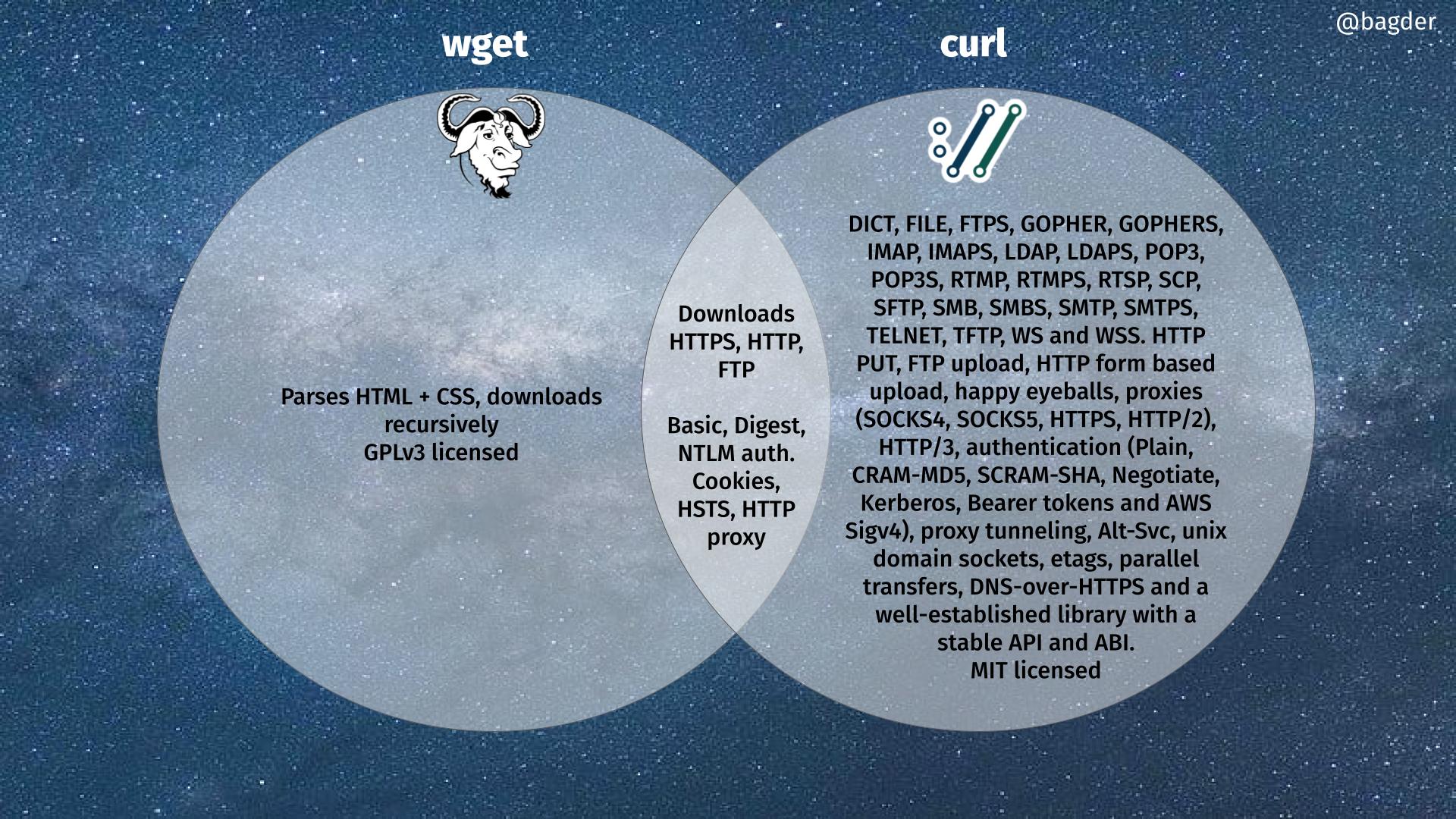
In my view, wget is not a curl competitor. It is a companion tool that has a feature overlap with curl.
Use the tool that does the job.
Getting the job done is the key. If that means using wget instead of curl, then that is good and I don’t mind. Why would I?
To illustrate the technical differences (and some similarities) between curl and wget, I made the following Venn diagram. Click the image to get the full resolution version.
The curl-wget Venn diagram
I have contributed code to wget. Several wget maintainers have contributed to curl. We are all friends.
If you think there is a problem or omission in the diagram, let me know and I can do updates.
This is a story consisting of several little building blocks and they occurred spread out in time and in different places. It is a story that shows with clarity how our current system with CVE Ids and lots of power given to NVD is a completely broken system.
CVE-2020-19909
On August 25 2023, we got an email to the curl-library mailing list from Samuel Henrique that informed us that “someone” had recently created a CVE, a security vulnerability identification number and report really, for a curl problem.
I wanted to let you know that there's a recent curl CVE published and it doesn't look like it was acknowledged by the curl authors since it's not mentioned in the curl website: CVE-2020-19909
We can’t tell who filed it. We just know that it is now there.
We own our curl issues
In the curl project we work hard and fierce on security and we always work with security researchers who report problems. We file our own CVEs, we document them and we make sure to tell the world about them. We list over 140 of them with every imaginable detail about them provided. We aim at providing gold-level documentation for everything and that includes our past security vulnerabilities.
That someone else suddenly has submitted a CVE for curl is a surprise. We have not been told about this and we would really have liked to. Now there is a new CVE out there reporting a curl issue and we have no details to say about it on the website. Not good.
I bet curl users soon would like to know the details about this.
Wait 2020?
The new CVE has an ID containing 2020 and that is weird. When you register a CVE you typically get it with the year you request it. Unless you get an ID for an old problem of the past. Is that what they did?
Sources seem to indicate that this was published just days ago.
Integer overflow vulnerability in tool_operate.c in curl 7.65.2 via crafted value as the retry delay.
And then the craziest statement of the year. They grade it a 9.8 CRITICAL issue. With 10 as a maximum, this is close to the worst case possible, right?
The code
Let’s pause NVD in their panic state for a moment because I immediately recognized this description. Brief as it is.
I spend a lot of time in the curl security team receiving reports, reviewing reports, reviewing source code, assessing claims and figuring out curl security issues. I had seen this claim before!
On July 27, 2019, a Jason Lee file an issue on hackerone, where he reported that there was an integer overflow problem in curl’s --retry-delay command line option. The option accepts number of seconds and then internally converts to milliseconds by multiplying the value by 1000. The option sets how long time curl should wait until it makes a retry if the previous transfer failed with a transient error.
This means that on a 64 bit machine, if you write
curl --retry-delay 18446744073709552 ...
The number will overflow the math and instead of waiting until the end of the universe, it might retry again within the next few seconds. The above example apparently made it 384 seconds instead. On Windows, which uses 32 bit longs, you can get the problem already by asking for more than two million seconds (roughly 25 days).
A bug, sure. Security problem? No. I told Jason that in 2019 and then we closed the security report. I then filed a pull-request and fixed the bug. Credits to Jason for the report. We moved on. The fix was shipped in curl 7.66.0, released in September 2019.
Grading issues
In previous desperate attempts from me to reason with NVD and stop their scaremongering and their grossly inflating the severity level of issues, they have insisted that they take in all publicly available data about the problem and make an assessment.
It was obvious already before that NVD really does not try very hard to actually understand or figure out the problem they grade. In this case it is quite impossible for me to understand how they could come up with this severity level. It’s like they saw “integer overflow” and figure that wow, yeah that is the most horrible flaw we can imagine, but clearly nobody at NVD engaged their brains nor looked at the “vulnerable” code or the patch that fixed the bug. Anyone that looks can see that this is not a security problem.
The issue listed by NVD even links to my pull request I mention above. There is no doubt that it is the exact same bug they refer to.
Spreading like a virus
NVD hosts a CVE database and there is an entire world and eco system now that pulls the records from them.
NVD now has this CVE-2020-19909 entry in there, rated 9.8 CRITICAL and now this disinformation spreads across the world. Now when we search for this CVE number we find numerous sites that repeats the same data. “This is a 9.8 CRITICAL problem in curl” – when it is not.
I will object
I learned about this slap in my face just a few hours ago (and I write this past Friday midnight), but I intend to do what I can to reject this CVE.