
I find that many web minded people working client-side or even server-side have neglected to learn the subtle details of the redirects of today. Here’s my attempt at writing another text about it that the ones who should read it still won’t.
Nothing here, go there!
The “redirect” is a fundamental part of the HTTP protocol. The concept was present and is documented already in the first spec (RFC 1945), published in 1996, and it has remained well used ever since.
A redirect is exactly what it sounds like. It is the s erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.
erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.
But not all redirects are alike. How permanent is the redirect? What request method should the client use in the next request?
All redirects also need to send back a Location: header with the new URI to ask for, which can be absolute or relative.
Permanent or Temporary
Is the redirect meant to last or just remain for now? If you want a GET to resource A permanently redirect users to resource B with another GET, send back a 301. It also means that the user-agent (browser) is meant to cache this and keep going to the new URI from now on when the original URI is requested.
The temporary alternative is 302. Right now the server wants the client to send a GET request to B, but it shouldn’t cache this but keep trying the original URI when directed to it.
Note that both 301 and 302 will make browsers do a GET in the next request, which possibly means changing method if it started with a POST (and only if POST). This changing of the HTTP method to GET for 301 and 302 responses is said to be “for historical reasons”, but that’s still what browsers do so most of the public web will behave this way.
In practice, the 303 code is very similar to 302. It will not be cached and it will make the client issue a GET in the next request. The differences between a 302 and 303 are subtle, but 303 seems to be more designed for an “indirect response” to the original request rather than just a redirect.
These three codes were the only redirect codes in the HTTP/1.0 spec.
GET or POST?
All three of these response codes, 301 and 302/303, will assume that the client sends a GET to get the new URI, even if the client might’ve sent a POST in the first request. This is very important, at least if you do something that doesn’t use GET.
If the server instead wants to redirect the client to a new URI and wants it to send the same method in the second request as it did in the first, like if it first sent POST it’d like it to send POST again in the next request, the server would use different response codes.
To tell the client “the URI you sent a POST to, is permanently redirected to B where you should instead send your POST now and in the future”, the server responds with a 308. And to complicate matters, the 308 code is only recently defined (the spec was published in June 2014) so older clients may not treat it correctly! If so, then the only response code left for you is…
The (older) response code to tell a client to send a POST also in the next request but temporarily is 307. This redirect will not be cached by the client though so it’ll again post to A if requested to. The 307 code was introduced in HTTP/1.1.
Oh, and redirects work the exact same way in HTTP/2 as they do in HTTP/1.1.
The helpful table version
| Permanent | Temporary | |
|---|---|---|
| Switch to GET | 301 | 302 and 303 |
| Keep original method | 308 | 307 |
It’s a gap!
Yes. The 304, 305, and 306 codes are not used for redirects at all.
What about other HTTP methods?
They don’t change methods! This table above is only for changing from POST to GET, other methods will not change.
curl and redirects
I couldn’t write a text like this without spicing it up with some curl details!
First, curl and libcurl don’t follow redirects by default. You need to ask curl to do it with -L (or –location) or libcurl with CURLOPT_FOLLOWLOCATION.
It turns out that there are web services out there in the world that want a POST sent, are responding with HTTP redirects that use a 301, 302 or 303 response code and still want the HTTP client to send the next request as a POST. As explained above, browsers won’t do that and neither will curl – by default.
Since these setups exist, and they’re actually not terribly rare, curl offers options to alter its behavior.
You can tell curl to not change the POST request method to GET after a 30x response by using the dedicated options for that:
–post301, –post302 and –post303. If you are instead writing a libcurl based application, you control that behavior with the CURLOPT_POSTREDIR option.
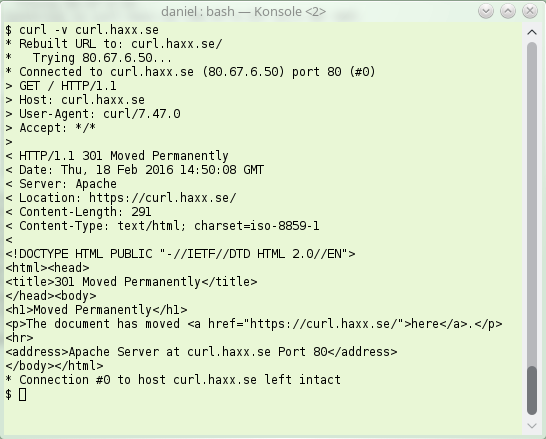
Here’s how a simple HTTP/1.1 redirect can look like. Note the 301, this is “permanent”:




 We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer
We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer 
