 Roughly a week ago, on August 19, cdn77.com announced that they are the “first CDN to publicly offer HTTP/2 support for all customers, without ‘beta’ limitations”. They followed up just hours later with a demo site showing off how HTTP/2 might perform side by side with a HTTP/1.1 example. And yes, the big competitor CDNs are not yet offering HTTP/2 support it seems.
Roughly a week ago, on August 19, cdn77.com announced that they are the “first CDN to publicly offer HTTP/2 support for all customers, without ‘beta’ limitations”. They followed up just hours later with a demo site showing off how HTTP/2 might perform side by side with a HTTP/1.1 example. And yes, the big competitor CDNs are not yet offering HTTP/2 support it seems.
Their demo site initially got critized for not being realistic and for showing HTTP/2 to be way better in comparison that what a real life scenario would be more likely to look like, and it was also subsequently updated fairly quickly. It is useful to compare with the similarly designed previously existing demo sites hosted by Akamai and the Go project.
 cdn77’s offering is built on nginx’s alpha patch for HTTP/2 that was anounced just two weeks ago. I believe nginx’s full release is still planned to happen by the end of this year.
cdn77’s offering is built on nginx’s alpha patch for HTTP/2 that was anounced just two weeks ago. I believe nginx’s full release is still planned to happen by the end of this year.
I’ve talked with cdn77’s Jakub Straka and their lead developer Honza about their HTTP/2 efforts, and since I suspect there are a few others in my audience who’re also similarly curious I’m offering this interview-style posting here, intertwined with my own comments and thoughts. It is not just a big ad for this company, but since they’re early players on this field I figure their view and comments on this are worth reading!
I’ve been in touch with more than one person who’ve expressed their surprise and awe over the fact that they’re using this early patch for nginx to run in production. So I had to ask them about that. Below, their comments are all prefixed with CDN77 and shown using italics.
nginx
CDN77: “Yes, we are running the alpha patch, which is basically a slightly modified SPDY. In the past we have been in touch with the Nginx team and exchanged tips and ideas, the same way we plan to work on the alpha patch in the future.
We’re actually pretty careful when deploying new and potentially unstable packages into production. We have separate servers for http2 and we are monitoring them 24/7 for any exceptions. We also have dedicated developers who debug any issues we are facing with these machines. We would never jeopardize the stability of our current network.”
I’m not an expert on neither server-side HTTP/2 nor nginx in particular , but I think I read somewhere that the nginx HTTP/2 patch removes the SPDY support in favor of the new protocol.
CDN77: “You are right. HTTP/2 patch rewrites SPDY into the HTTP/2, so the SPDY is no longer supported after applying the patch. Since we have HTTP/2 running on separate servers, we still have SPDY support on the rest of the network.”
Did the team at cdn77 at all consider using something else than nginx for HTTP/2, like the promising newcomer h2o?
CDN77: “Not at all. Nginx is a clear choice for us. Its architecture and modularity is awesome. It is also very reliable and it has a pretty long history.”
On scale
Can you share some of the biggest hurdles you had to overcome to deploy HTTP/2 on this scale with nginx?
CDN77: “Since nobody has tried the patch in such a scale ever before, we had to make sure it will hold even under pressure and needed to create a load heavy testing environment. We used servers from our partner company 10gbps.io and their 10G uplinks to create intensive ghost traffic. Also, it was important to make sure that supporting tools and applications are HTTP/2 ready – not all of them were. We needed to adjust the way we monitor and control servers in few cases.”
There are a few bugs in Nginx that appear mainly in association with the longer-lived connections. They cause issues with the application layer and consume more resources. To be able to accommodate HTTP/2 and still keep necessary network redundancies, we needed to upgrade our network significantly.”
I read this as an indication that the nginx patch isn’t perfected just yet rather than signifying that http2 is special. Perhaps also that http2 connections might use a larger footprint in nginx than good old http1 connections do.
Jakub mentioned they see average “performance savings” in the order of 20 to 60 percent depending on sites and contents with the switch to h2, but their traffic amounts haven’t been that large yet:
CDN77: “So far, only a fraction of the traffic is running via HTTP/2, but that is understandable since we launched the support few days ago. On the first day, only about 0.45% of the traffic was HTTP/2 and a big part of this was our own demo site. Over the weekend, we saw impressive adoption rate and the total HTTP/2 traffic accounts for more than 0.8% now, all that with the portion of our own traffic in this dropping dramatically. We expect to be pushing around 1.2% – 1.5% of total traffic over HTTP/2 till the end of this week.”
Understandably, it is ramping up. Still, Firefox telemetry is showing at least 10% of the total traffic over HTTP/2 already.
Future of HTTPS and HTTP/2?
W hile I’m talking to a CDN operator, I figured I should poll their view on HTTPS going forward! Will the fact that all browsers only support h2 over HTTPS push more of your customers and your traffic in general over to HTTP, you think?
hile I’m talking to a CDN operator, I figured I should poll their view on HTTPS going forward! Will the fact that all browsers only support h2 over HTTPS push more of your customers and your traffic in general over to HTTP, you think?
CDN77: “This is not easy to predict. There is encryption overhead, but HTTP/2 comes with header compression and it is binary. So at this single point, the advantages and disadvantages zero out. Also, the use of HTTPS is rising rapidly even on the older protocol, so we don’t consider this an issue at all.”
In general, from a CDN perspective and as someone who just deployed this on a fairly large scale, what’s your general perception of what http2 means going forward?
CDN77: “We believe that this is a huge step forward in how we distribute content online and as a CDN company, we are especially excited as it concerns the very core of our business. From the new features, we have great expectations about cache invalidation that is being discussed right now.”
Thanks to Jakub, Honza and Tomáš of cdn77 for providing answers and info. We live in exciting times.

 The HTTP Workshop was much appreciated by the attendees and it is now about to be repeated. In the summer of 2016, the HTTP Workshop is again taking place in Europe, but this time as a three-day event slightly further up north: in the capital of Sweden and my home town: Stockholm. During 25-27 July 2016, we intend to again dig in deep.
The HTTP Workshop was much appreciated by the attendees and it is now about to be repeated. In the summer of 2016, the HTTP Workshop is again taking place in Europe, but this time as a three-day event slightly further up north: in the capital of Sweden and my home town: Stockholm. During 25-27 July 2016, we intend to again dig in deep.
 erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.
erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.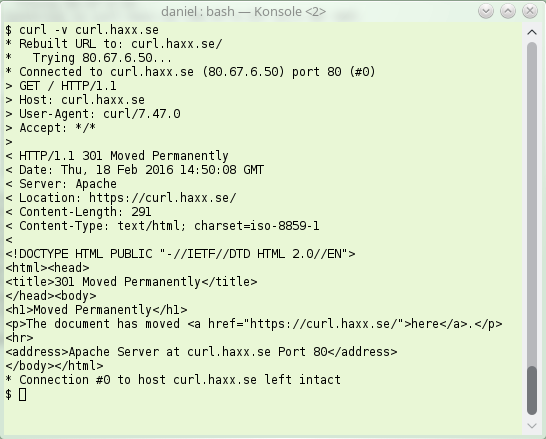


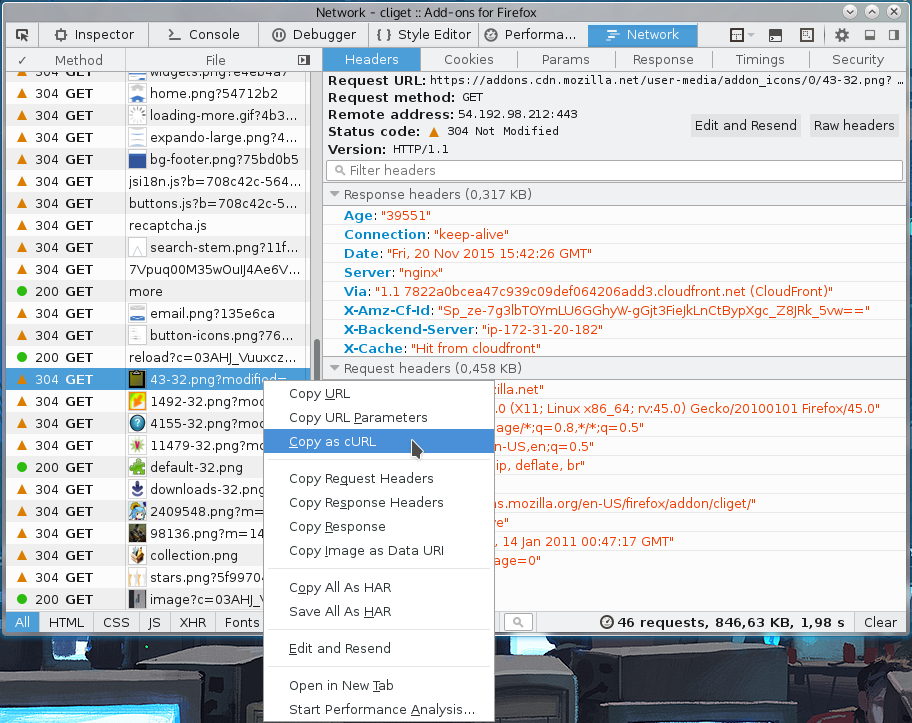
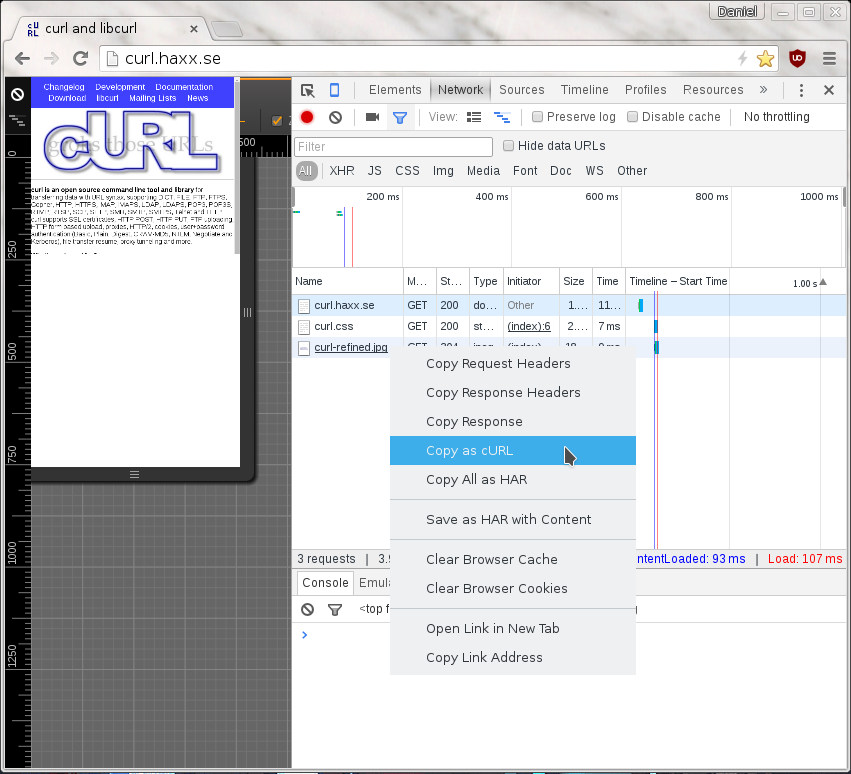


 We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer
We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer 