curl is a command line tool and library for doing Internet data transfers. It has been around for a loooong time (over 23 years) but there is still a flood of new things being added to it and development being made, to take it further and to keep it relevant today and in the future.
I’m the lead developer and head maintainer of the curl project.
How do we decide what goes into curl? And perhaps more importantly, what does not get accepted into curl?
Let’s look how this works in the curl factory.
Stick to our principles
curl has come this far by being reliable, trusted and familiar. We don’t rock the boat: curl does Internet transfers specified as URLs and it doesn’t parse or understand the content it transfers. That goes for libcurl too.
Whatever we add should stick to these constraints and core principles, at least. Then of course there are more things to consider.
A shortlist of things I personally want to see
I personally usually have a shortlist of a few features I personally want to work on in the coming months and maybe half year. Items I can grab when other things are slow or if I need a change or fun thing to work on a rainy day. These items are laid out in the ROADMAP document – which also tends to be updated a little too infrequently…
There’s also the TODO document that lists things we consider could be good to do and KNOWN_BUGS that lists known shortcomings we want to address.
Sponsored works have priority
I’m the lead developer of the curl project but I also offer commercial support and curl services to allow me to work on curl full-time. This means that paying customers can get a “priority lane” into landing new features or bug-fixes in future releases of curl. They still need to suit the project though, we don’t abandon our principles even for money. (Contact me to learn how I can help you get your proposed changes done!)
Keep up with where the world goes
All changes and improvements that help curl keep up with and follow where the Internet protocol community is moving, are considered good and necessary changes. The curl project has always been on the front-lines of protocols and that is where we want to remain. It takes a serious effort.
Asking the community
Every year around the May time frame we do a “user survey” that we try to get as many users as possible to respond to. It asks about user patterns, what’s missing and how things are working.
The results from that work provide good feedback on areas to improve and help us identify features our community think curl lacks etc. (The 2020 survey analysis)
Even outside of the annual survey, discussions on the mailing list is a good way for getting direct feedback on questions and ideas and users very often bring up their ideas and suggestions using those channels.
Ideas are easy, code is harder
Actually implementing and providing a feature is a lot harder than just providing an idea. We almost drown among all the good ideas people propose we might or could do one day. What someone might think is a great idea may therefore still not be implemented very soon. Because of the complexity of implementing it or because of lack of time or energy etc.
But at the same time: oftentimes, someone needs to bring the idea or crack the suggestion for it to happen.
It needs to exist to be considered
Related to the previous section. Code and changes that exist, that are provided are of course much more likely to actually end up in curl than abstract ideas. If a pull-request comes to curl and the change adheres to our standards and meet the requirements mentioned in this post, then the chances are very good that it will be accepted and merged.
As I am currently the only one working on curl professionally (ie I get paid to do it). I can rarely count on or assume work submissions from other team members. They usually show up more or less by surprise, which of course is awesome in itself but also makes such work and features very hard to plan for ahead of time. Sometimes people bring new features. Then we deal with them!
Half-baked is not good enough
A decent amount of all pull requests submitted to the project never get merged because they aren’t good enough and the person who submitted them doesn’t respond to feedback and improvement requests properly so that they never become good enough. Things like documentation and tests are typically just as important as the functionality itself.
Pull requests that are abandoned by the author can of course also get taken over by someone else but it cannot be expected or relied upon. A person giving up on the pull request is also a strong sign to the rest of us that obviously the desire to get that specific change landed wasn’t that big and that tells us something.
We don’t accept and merge partial changes that for example lack a crucial part like tests or documentation because we’ve learned the hard way many times over the years that it is just too common that the author then vanishes before completing the work – forcing others to do that work or we have to rip the change out again.
Standards and in-use are preferred properties
At times people suggest we support new protocols or experiments for new things. While that can be considered fun and useful, we typically want both the protocol and the associated URL syntax to already be in use and be somewhat established and preferably even standardized and properly documented in specifications. One of the fundamental core ideas with URLs is that they should mean the same thing for more than one application.
When no compass needle exists, maintain existing direction
Most changes are in line with what we already do and how the products work so no major considerations are necessary. Only once in a while do we get requests or suggestions that actually challenge the direction or forces us to consider what is the right and the wrong way.
If the reason and motivation provided is valid and holds up, then we might agree and go in that direction, If we don’t, we discuss the topic and see if we perhaps can change someone’s mind or “wiggle” the concepts and ideas to see whether we can change the suggestion or perhaps see it from n a different angle to reconsider. Sometimes we just have to decline and say no: that’s not something we think is in line with curl.
Who decides if its fine?
curl is not a democracy, we don’t vote about decisions or what to accept etc.
curl is also not a strict dictatorship where a single leader dictates all truths and facts from above for all subjects to accept and obey.
We’re somewhere in between. We discuss and try to find consensus of what and how to do things. The persons who bring the code or experience the actual problems of course will have more to say. Experienced and long-term maintainers’ opinions have more weight in discussions and they’re free and allowed to merge pull-requests they think are good.
I retain the right to veto stuff, but I very rarely exercise that right.
curl is still a small project. You’ll notice that you’ll quickly recognize the same handful of maintainers in all pull-requests and long tail of others chipping in here and there. There’s no massive crowd anywhere. That’s also the explanation why sometimes your pull-requests might not get reviewed instantly but you must rather wait for a while until you get someone’s attention.
If you’re curious to learn how the project is governed in more detail, then check out the governance docs.
How to land code in curl
I’ve done a previous presentation on how to work with the project get your code landed in curl. Check it out!
Your feedback helps!
Listening to what users want, miss and think are needed when going forward is very important to us. Even if it sometimes is hard to react immediately and often we have to bounce things a little back and forth before they can become “curl material”. So, please don’t expect us to immediately implement what you suggest, but please don’t let that stop you from bringing your grand ideas.
And bring your code. We love your code.







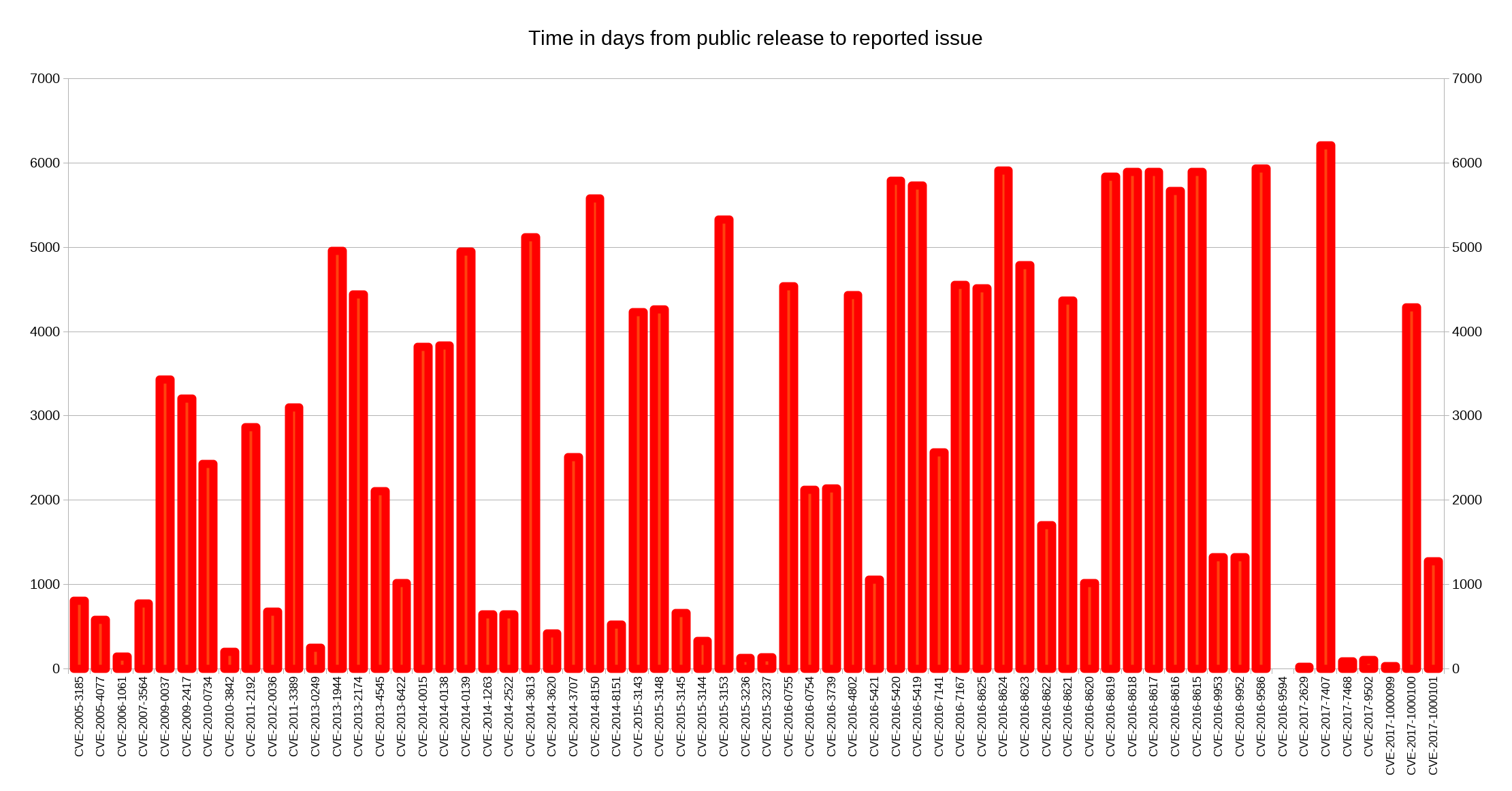
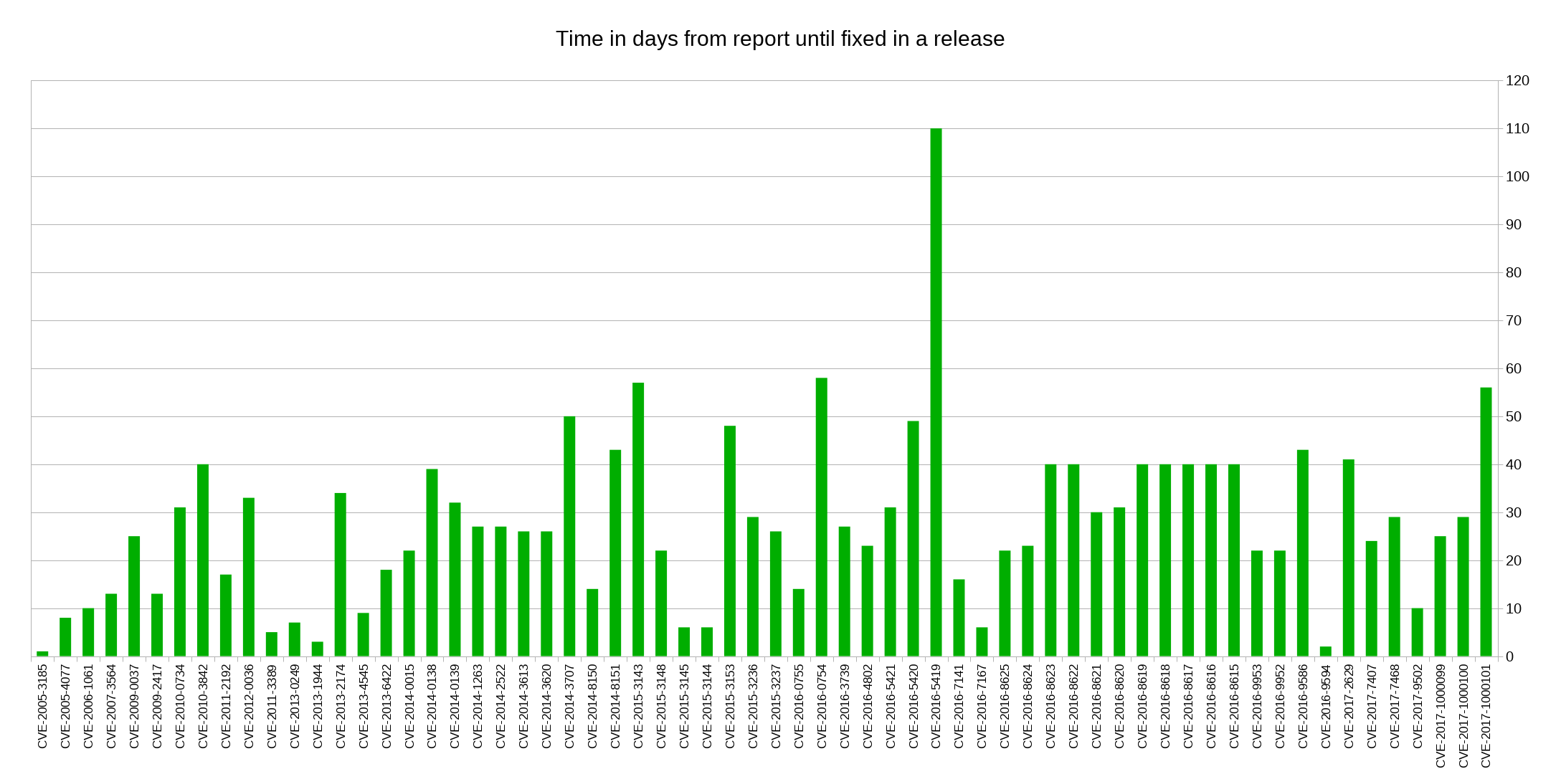
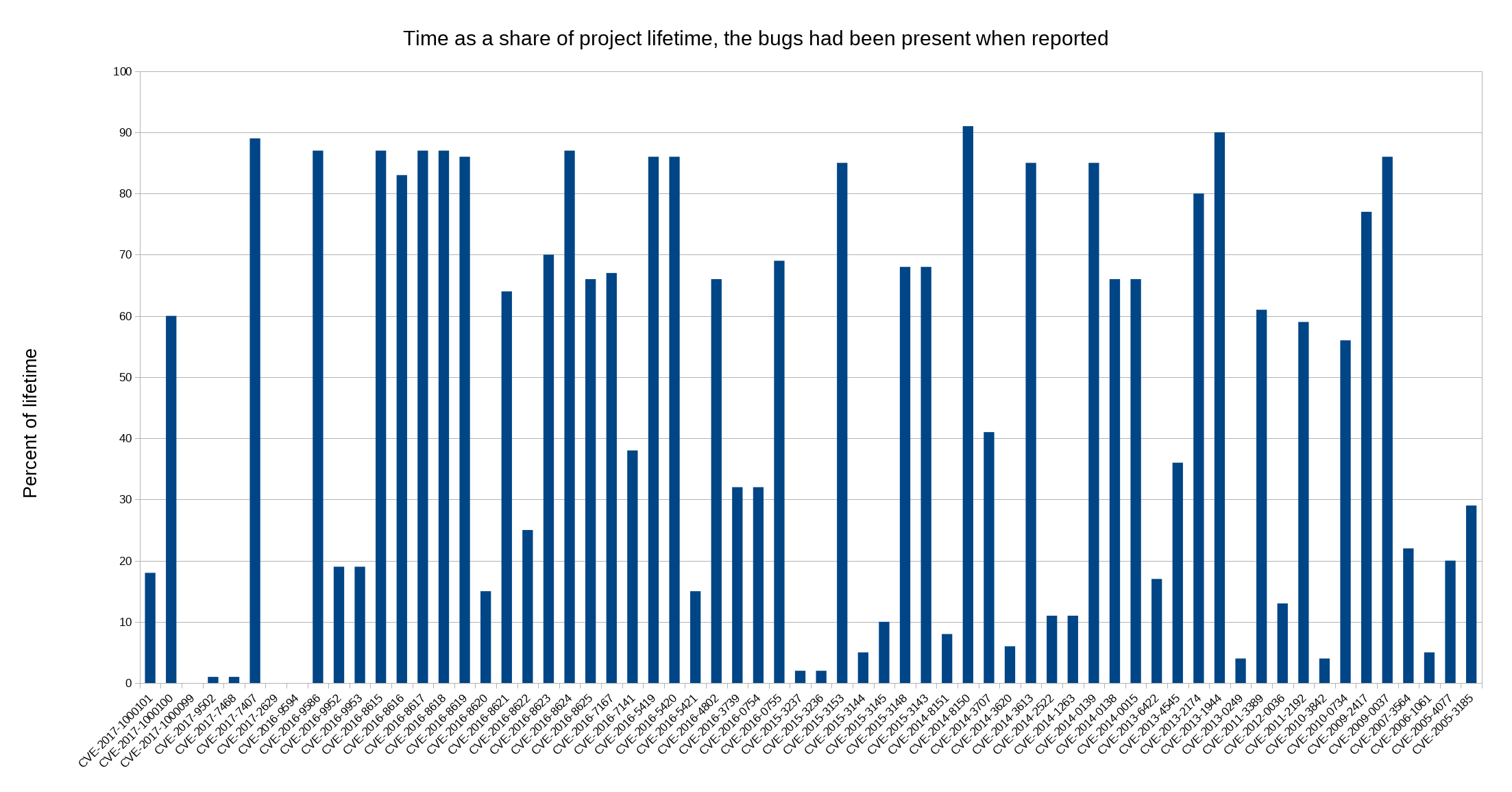
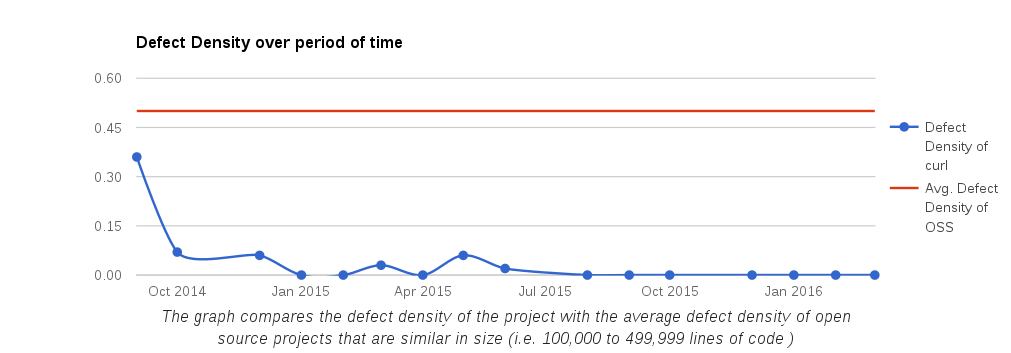
 I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in