I have this tradition of mentioning occasional network related quirks on Windows on my blog so here we go again.
This round started with a bug report that said
curl is slow to connect to localhost on Windows
It is also demonstrably true. The person runs a web service on a local IPv4 port (and nothing on the IPv6 port), and it takes over 200 milliseconds to connect to it. You would expect it to take no less than a number of microseconds, as it does on just about all other systems out there.
The command
curl http://localhost:4567
Connecting
Buckle up, this is getting worse. But first, let’s take a look at this exact use case and what happens.
The hostname localhost first resolves to ::1 and 127.0.0.1 by curl. curl actually resolves this name “hardcoded”, so it does this extremely fast. Hardcoded meaning that it does not actually use DNS or any resolver functionality. It provides this result “fixed” for this hostname.
When curl has both IPv6 and IPv4 addresses to connect to and the host supports both IP families, it will first start the IPv6 attempt(s) and only if it did not succeed to connect over IPv6 after two hundred millisecond does it start the IPv4 attempts. This way of connecting is called Happy Eyeballs and is the de-facto and recommended way to connect to servers in a dual-stack since years back.
On all systems except Windows, where the IPv6 TCP connect attempt sends a SYN to a TCP port where nothing is listening, it gets a RST back immediately and returns failure. ECONNREFUSED is the most likely outcome of that.
On all systems except Windows, curl then immediately switches over to the IPv4 connect attempt instead that in modern systems succeeds within a small fraction of a millisecond. The failed IPv6 attempt is not noticeable to a user.
A TCP reminder
This is how a working TCP connect can be visualized like:
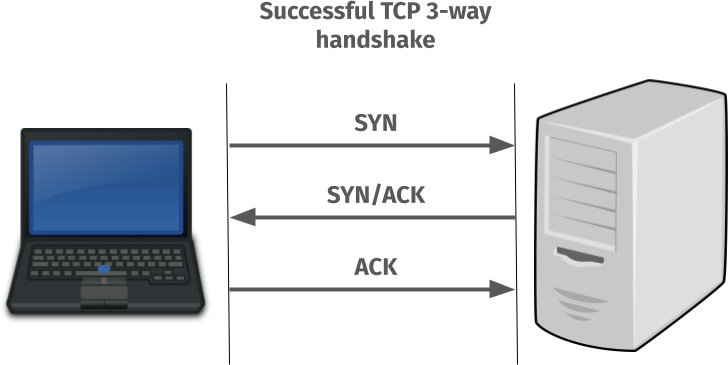
But when the TCP port in the server has no listener it actually performs like this
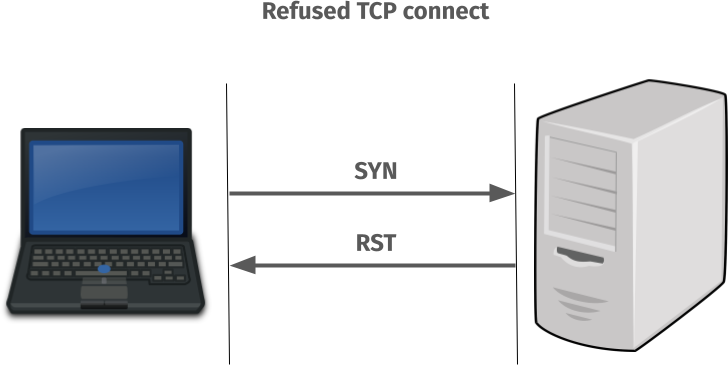
Connect failures on Windows
On Windows however, the story is different.
When the TCP SYN is sent to the port where nothing is listening and an RST is sent back to tell the client so, the client TCP stack does not return an error immediately.
Instead it decides that maybe the problem is transient and it will magically fix itself in the near future. It then waits a little and then keeps sending new SYN packets to see if the problem perhaps has fixed itself – until a maximum retry value is reached (set in the registry, this value defaults to 3 extra times).
Done on localhost, this retry-SYN process can easily take a few seconds and when done over a network, it can take even more seconds.
Since this behavior makes the leading IPv6 attempt not possible to fail within 200 milliseconds even when nothing is listening on that port, connecting to any service that is IPv4-only but has an IPv6 address by default delays curl’s connect success by two hundred milliseconds. On Windows.
Of course this does not only hurt curl. This is likely to delay connect attempts for countless applications and services for Windows users.
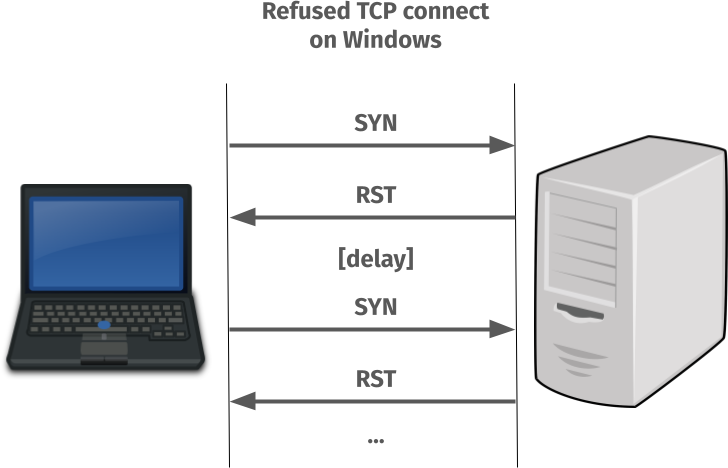
Non-responding is different
I want to emphasize that there is a big difference when trying to connect to a host where the SYN packet is simply not answered. When the server is not responding. Because then it could be a case of the packet gotten lost on the way so then the TCP stack has to resend the SYN again a couple of times (after a delay) to see if it maybe works this time.
IPv4 and IPv6 alike
I want to stress that this is not an issue tied to IPv6 or IPv4. The TCP stack seems to treat connect attempts done over either exactly the same. The reason I even mention the IP versions is because how this behavior works counter to Happy Eyeballs in the case where nothing listens to the IPv6 port.
Is resending SYN after RST “right” ?
According to this exhaustive resource I found on explaining this Windows TCP behavior, this is not in violation of RFC 793. One of the early TCP specifications from 1981.
It is surprising to users because no one else does it like this. I have not found any other systems or TCP stacks that behave this way.
Fixing?
There is no way for curl to figure out that this happens under the hood so we cannot just adjust the code to error out early on Windows as it does everywhere else.
Workarounds
There is a registry key in Windows called TcpMaxConnectRetransmissions that apparently can be tweaked to change this behavior. Of course it changes this for all applications so it is probably not wise to do this without a lot of extra verification that nothing breaks.
The two hundred millisecond Happy Eyeballs delay that curl exhibits can be mitigated by forcibly setting –happy-eyballs-timeout-ms to zero.
If you know the service is not using IPv6, you can tell curl to connect using IPv4 only, which then avoids trying and wasting time on the IPv6 sinkhole: –ipv4.
Without changing the registry and trying to connect to any random server out there where nothing is listening to the requested port, there is no decent workaround. You just have to accept that where other systems can return failure within a few milliseconds, Windows can waste multiple seconds.
Windows version
This behavior has been verified quite recently on modern Windows versions.