The dash-dash-libcurl is the sometimes missed curl gem that you might want to know about and occasionally maybe even use.
How do I convert
There is a very common pattern in curl land: a user who is writing an application using language L first does something successfully with the curl command line tool and then the person wants to convert that command line into the program they are writing.
How do you convert this curl command line into a transfer using programming language XYZ?
Language bindings
There is a huge amount of available bindings for libcurl. Bindings, as in adjustments and glue code for languages to use libcurl for Internet transfers so that they do not have to write the application in C.
At a recent count I found more than 60 libcurl bindings. They allow authors of virtually any programming language to do internet transfers using the powers of libcurl.
Most of these bindings are “thin” and follow the same style of the original C API: You create a handle for which you set options and then you do the transfer. This way they are fairly easy to keep up to date with the always-changing and always-improving libcurl releases.
Say hi to --libcurl
Most curl command line options are mapped one-to-one to an underlying libcurl option so for some time I tried to help users by explaining what they map to. Until one day I realized that
Hey! curl itself already has this mapping in source code, it just needs a way to show it to users!
How would it best output this mapping?
The --libcurl command line option was added to curl already back in 2007 and has been part of the tool since version 7.16.1.
Show this command line as libcurl code
It is really easy to use too.
Create a complicated curl command line that does what you need it to do.
Append --libcurl example.c to the command line and run it again.
Inspect your newly generated file example.c for how you could write your application to do the same thing with libcurl.
If you want to use a libcurl binding rather than the C API, like perhaps write your code in Python or PHP, you need to convert the example code into your programming language but much thanks to the options keeping their names across the different bindings it is usually a trivial task.
Example
The simplest possible command line:
curl curl.se
It gets HTTP from the site “curl.se”. If you try it, you will not see anything because it just replies with a redirect to the HTTPS version of the page. But ignoring that, you can convert that action into a libcurl program like this:
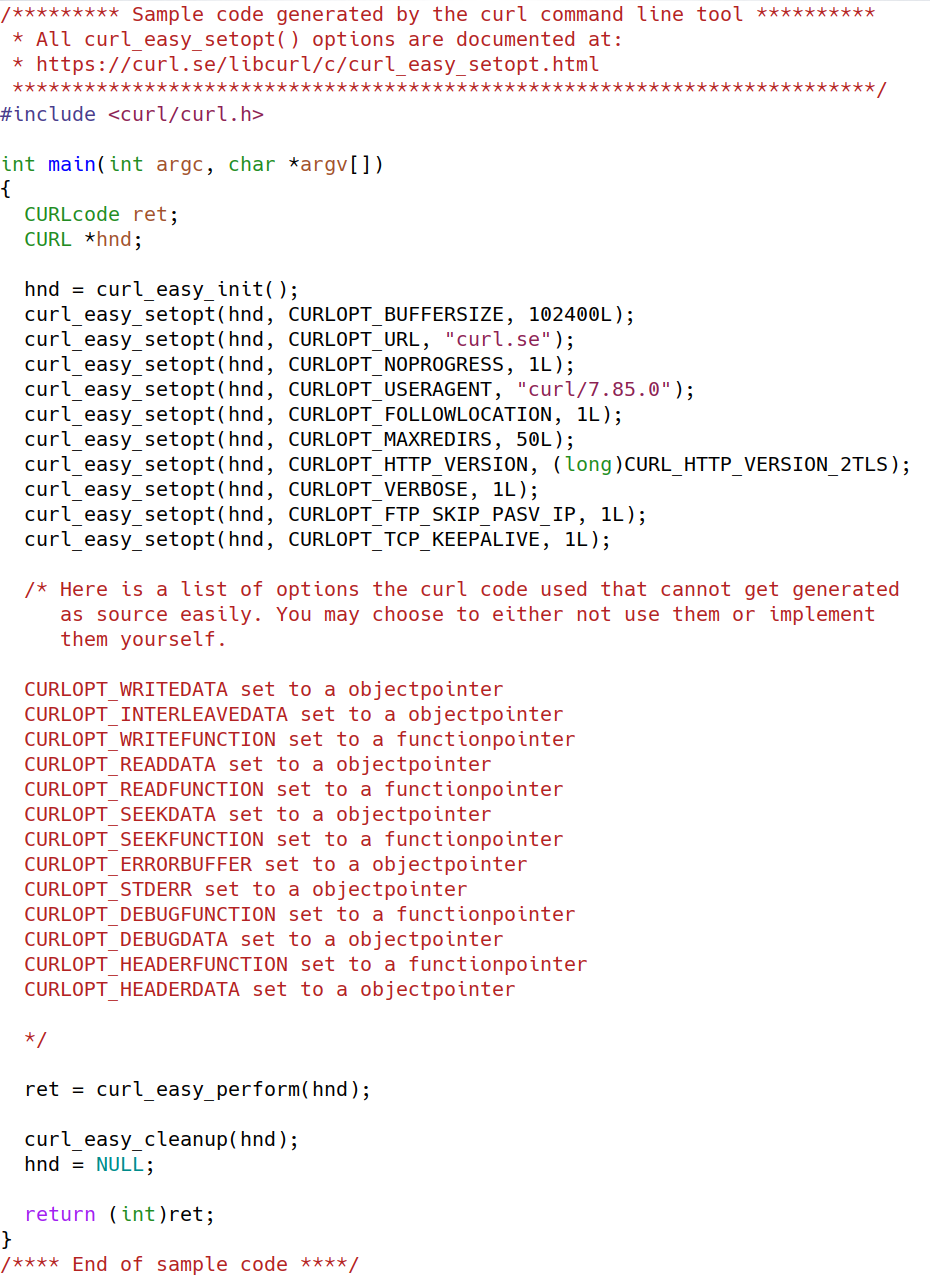
curl curl.se --libcurl code.c
The newly created file code.c now contains a program that you can compile :
gcc -o getit code.c -lcurl
and then run
./getit
You might want your program to rather follow the redirect? Maybe even show debug output? Let’s rerun the command line and get a code update:
Now, if you rebuild your program and run it again, it shows you the front page HTML of the curl website on stdout.
The code
The exact code my curl version 7.85.0 produced in the command line above is shown below.
You see several options that are commented out. Those were used by the command line tool but there is no easy or convenient way to show their use in the example. Often you can start out by just skipping those .
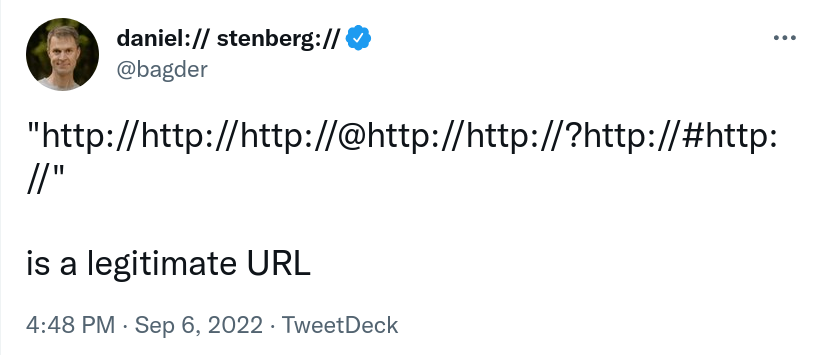
As it took off, got an amazing attention and I received many different comments and replies, I felt a need to elaborate a little. To add some meat to this.
Is this string really a legitimate URL? What is a URL? How is it parsed?
http – the scheme of the URL. This speaks HTTP. The “://” separates the scheme from the following authority part (that’s basically everything up to the path).
http – the user name up to the first colon
//http:// – the password up to the at-sign (@)
http: – the host name, with a trailing colon. The colon is a port number separator, but a missing number will be treated by curl as the default number. Browsers also treat missing port numbers like this. The default port number for the http scheme is 80.
//http:// – the path. Multiple leading slashes are fine, and so is using a colon in the path. It ends at the question mark separator (?).
http:// – the query part. To the right of the question mark, but before the hash (#).
http:// – the fragment, also known as “anchor”. Everything to the right of the hash sign (#).
To use this URL with curl and serve it on your localhost try this command line:
The curl parser has been around for decades already and do not break existing scripts and applications is one of our core principles. Thus, some of the choices in the URL parser we did a long time ago and we stand by them, even if they might be slightly questionable standards wise. As if any standard meant much here.
The curl parser started its life as lenient as it could possibly be. While it has been made stricter over the years, traces of the original design still shows. In addition to that, we have also felt that we have been forced to make adaptions to the parser to make it work with real world URLs thrown at it. URLs that maybe once was not deemed fine, but that have become “fine” because they are accepted in other tools and perhaps primarily in browsers.
There is the URI (not URL!) definition from IETF RFC 3986, there is the WHATWG URL Specification that browsers (try to) adhere to and there are numerous different implementations of parsers being more or less strict when following one or both of the above mentioned specifications.
You will find that when you scrutinize them into the details, hardly any two URL parsers agree on every little character.
Therefore, if you throw the above mentioned URL on any random URL parser they may reject it (like the Twitter parser didn’t seem to think it was a URL) or they might come to a different conclusion about the different parts than curl does. In fact, it is likely that they will not do exactly as curl does.
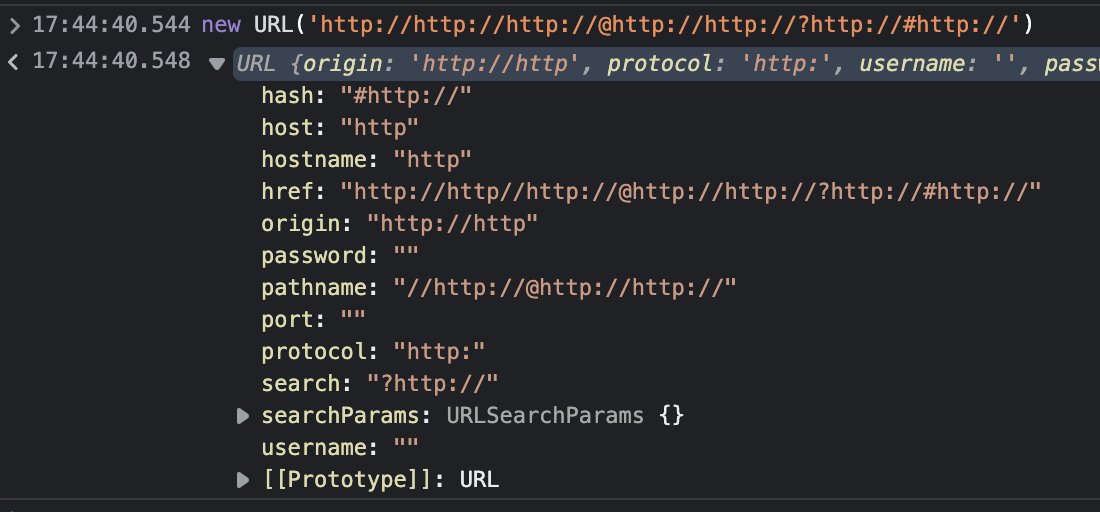
Python’s urllib
April King threw it at Python’s urllib. A valid URL! While it accepted it as a URL, it split it differently:
(the second colon from the left is removed, everything else is the same)
… but still considered it a valid URL and showed the contents from my web server.
Chrome behaved exactly the same. A valid URL according to it, and a rewrite of the URL like Firefox does.
RFC 3986
Some commenters mentioned that the unencoded “unreserved” letters in the authority part make it not RFC 3986 compliant. Section 3.2 says:
The authority component is preceded by a double slash ("//") and is terminated by the next slash ("/"), question mark ("?"), or number sign ("#") character, or by the end of the URI.
Meaning that the password should have its slashes URL-encoded as %2f to make it valid. At least. So maybe not a valid URL?
Update: it actually still qualifies as “valid”, it just is parsed a little differently than how curl does it. I do not think there is any question that curl’s interpretation is not matching RFC 3986.
It made it 7 characters longer for no obvious extra fun
It is harder to prove working by serving your own content as you would need curl -k or similar to make the host name ‘https’ be OK vs the name used in the actual server you would target.
The URL Buffalo buffalo
A surprisingly large number of people thought it reminded them of the old buffalo buffalo thing.
This is a tale of cookies, Internet code and a CVE. It goes back a long time so please take a seat, lean back and follow along.
The scene is of course curl, the internet transfer tool and library I work on.
1998
In October 1998 we shipped curl 4.9. In 1998. Few people had heard of curl or used it back then. This was a few months before the curl website would announce that curl achieved 300 downloads of a new release. curl was still small in every meaning of the word at that time.
curl 4.9 was the first release that shipped with the “cookie engine”. curl could then receive HTTP cookies, parse them, understand them and send back cookies properly in subsequent requests. Like the browsers did. I wrote the bigger part of the curl code for managing cookies.
In 1998, the only specification that existed and described how cookies worked was a very brief document that Netscape used to host called cookie_spec. I keep a copy of that document around for curious readers. It really does not document things very well and it leaves out enormous amounts information that you had to figure out by inspecting other clients.
The cookie code I implemented than was based on that documentation and what the browsers seemed to do at the time. It seemed to work with numerous server implementations. People found good use for the feature.
2000s
This decade passed with a few separate efforts in the IETF to create cookie specifications but they all failed. The authors of these early cookie specs probably thought they could create standards and the world would magically adapt to them, but this did not work. Cookies are somewhat special in the regard that they are implemented by so many different authors, code bases and websites that fundamentally changing the way they work in a “decree from above” like that is difficult if not downright impossible.
RFC 6265
Finally, in 2011 there was a cookie rfc published! This time with the reversed approach: it primarily documented and clarified how cookies were actually already being used.
I was there and I helped it get made by proving my views and opinions. I did not agree to everything that the spec includes (you can find blog posts about some of those details), but finally having a proper spec was still a huge improvement to the previous state of the world.
Double syntax
What did not bother me much at the time, but has been giving me a bad rash ever since, is the peculiar way the spec is written: it provides one field syntax for how servers should send cookies, and a different one for what syntax clients should accept for cookies.
Two syntax for the same cookies.
This has at least two immediate downsides:
It is hard to read the spec as it is very easy to to fall over one of those and assume that syntax is valid for your use case and accidentally get the wrong role’s description.
The syntax defining how to send cookie is not really relevant as the clients are the ones that decide if they should receive and handle the cookies. The existing large cookie parsers (== browsers) are all fairly liberal in what they accept so nobody notices nor cares about if the servers don’t follow the stricter syntax in the spec.
RFC 6265bis
Since a few years back, there is ongoing work in IETF on revising and updating the cookie spec of 2011. Things have evolved and some extensions to cookies have been put into use in the world and deserves to be included in the spec. If you would to implement code today that manage cookies, the old RFC is certainly not enough anymore. This cookie spec update work is called 6265bis.
The issue about the double syntax from above is still to be resolved in the document, but I faced unexpectedly tough resistance when I recently shared my options and thoughts about that spec peculiarity.
It can be noted that fundamentally, cookies still work the same way as they did back in 1998. There are added nuances and knobs sure, but the basic principles have remained. And will so even in the cookie spec update.
One of oddities of cookies is that they don’t work on origins like most other web features do.
HTTP Request tunneling
While cookies have evolved slowly over time, the HTTP specs have also been updated and refreshed a few times over the decades, but perhaps even more importantly the HTTP server implementations have implemented stricter parsing policies as they have (together with the rest of the world) that being liberal in what you accept (Postel’s law) easily lead to disasters. Like the dreaded and repeated HTTP request tunneling/smuggling attacks have showed us.
To combat this kind of attack, and probably to reduce the risk of other issues as well, HTTP servers started to reject incoming HTTP requests early if they appear “illegal” or malformed. Block them already at the door and not letting obvious crap in. In particular this goes for control codes in requests. If you try to send a request to a reasonably new HTTP server today that contains a control code, chances are very high that the server will reject the request and just return a 400 response code.
With control code I mean a byte value between 1 and 31 (excluding 9 which is TAB)
The well known HTTP server Apache httpd has this behavior enabled by default since 2.4.25, shipped in December 2016. Modern nginx versions seem to do this as well, but I have not investigated since exactly when.
Cookies for other hosts
If cookies were designed today for the first time, they certainly would be made different.
A website that sets cookies sends cookies to the client. For each cookie it sends, it sets a number of properties for the cookie. In particular it sets matching parameters for when the cookie should be sent back again by the client.
One of these cookie parameters set for a cookie is the domain that need to match for the client to send it. A server that is called www.example.com can set a cookie for the entire example.com domain, meaning that the cookie will then be sent by the client also when visiting second.example.com. Servers can set cookies for “sibling sites!
Eventually the two paths merged
The cookie code added to curl in 1998 was quite liberal in what content it accepted and while it was of course adjusted and polished over the years, it was working and it was compatible with real world websites.
The main driver for changes in that area of the code has always been to make sure that curl works like and interoperates with other cookie-using agents out in the wild.
CVE-2022-35252
In the end of June 2022 we received a report of a suspected security problem in curl, that would later result in our publication of CVE-2022-35252.
As it turned out, the old cookie code from 1998 accepted cookies that contained control codes. The control codes could be part of the name or the the content just fine, and if the user enabled the “cookie engine” curl would store those cookies and send them back in subsequent requests.
Example of a cookie curl would happily accept:
Set-Cookie: name^a=content^b; domain=.example.com
The ^a and ^b represent control codes, byte code one and two. Since the domain can mark the cookie for another host, as mentioned above, this cookie would get included for requests to all hosts within that domain.
When curl sends a cookie like that to a HTTP server, it would include a header field like this in its outgoing request:
Cookie: name^a=content^b
400
… to which a default configure Apache httpd and other servers will respond 400. For a script or an application that received theses cookies, further requests will be denied for as long as the cookies keep getting sent. A denial of service.
What does the spec say?
The client side part of RFC 6265, section 5.2 is not easy to decipher and figuring out that a client should discard cookies with control cookies requires deep studies of the document. There is in fact no mention of “control codes” or this byte range in the spec. I suppose I am just a bad spec reader.
Browsers
It is actually easier to spot what the popular browsers do since their source codes are easily available, and it turns out of course that both Chrome and Firefox already ignore incoming cookies that contain any of the bytes
%01-%08 / %0b-%0c / %0e-%1f / %7f
The range does not include %09, which is TAB and %0a / %0d which are line endings.
The fix
The curl fix was not too surprisingly and quite simply to refuse cookie fields that contain one or more of those banned byte values. As they are not accepted by the browser’s already, the risk that any legitimate site are using them for any benign purpose is very slim and I deem this change to be nearly risk-free.
The age of the bug
The vulnerable code has been in curl versions since version 4.9 which makes it exactly 8,729 days (23.9 years) until the shipped version 7.85.0 that fixed it. It also means that we introduced the bug on project day 201 and fixed it on day 8,930.
The code was not problematic when it shipped and it was not problematic during a huge portion of the time it has been used by a large amount of users.
It become problematic when HTTP servers started to refuse HTTP requests they suspected could be malicious. The way this code turned into a denial of service was therefore more or less just collateral damage. An unfortunate side effect.
Maybe the bug was born first when RFC 6265 was published. Maybe it was born when the first widely used HTTP server started to reject these requests.
Project record
8,729 days is a new project record age for a CVE to have been present in the code until found. It is still the forth CVE that were lingering around for over 8,000 days until found.
Credits
Thanks to Stefan Eissing for digging up historic Apache details.
Every human has a unique fingerprint. With only an impression of a person’s fingertip, it is possible to follow the lead back to the single specific individual wearing that unique pattern.
TLS fingerprints
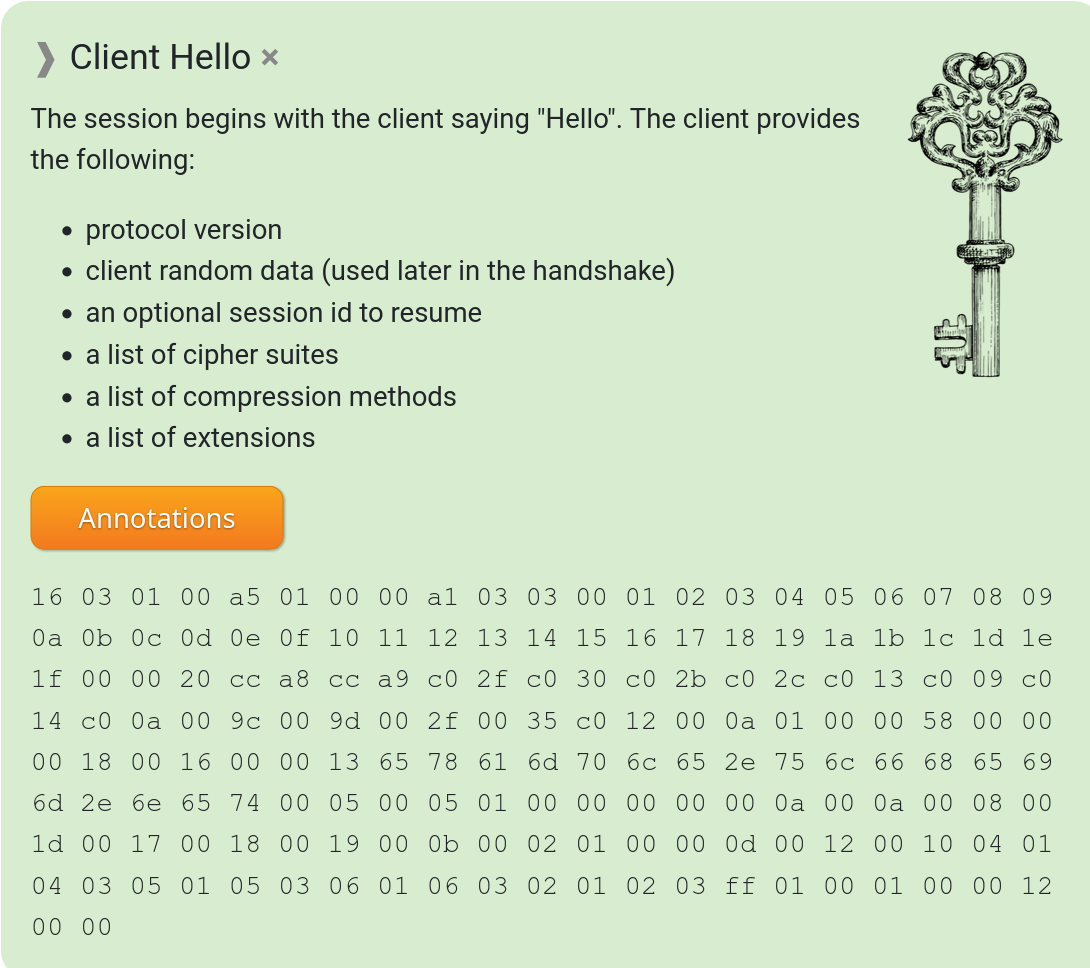
The phrase TLS fingerprint is of course in this spirit. A pattern in a TLS handshake that allows an involved party to tell or at least guess with a certain level of accuracy what client software that performed it – purely based on how exactly the TLS magic is done. There are numerous different ways and variations a client can perform a TLS handshake and still be standards compliant. There is a long list of extensions that can vary in content, the order of the list of extensions, the ciphers to accept, the allowed TLS versions, steps performed, the order and sequence of those steps and more.
When a network client connects to a remote site and makes a TLS handshake with the server, the server can basically add up all those details and make an educated guess exactly which client that connects to it. One method to do it is called JA3 and produces a 32 digit hexadecimal number as output. (The three creators of this algorithm all have JA as their initials!)
In use out there
I have recently talked with customers and users who have faced servers that refused them access when they connected to sites using curl, but allowed them access to the site when they instead use one of the popular browsers – or if curl was tweaked to look like one of those browsers. It might be a trend in the making. There might be more sites out there now that reject clients that produce the wrong fingerprint then there used to be.
Why
Presumably there are many reasons why servers want to limit access to a subset of clients, but I think the general idea is that they want to prevent “illegitimate” user agents from accessing their sites.
For example, I have seen online market sites use this method in an what I have perceived as an attempt to block bots and web scrapers. Or they do it to block malware or other hostile clients that scour their website.
How
There’s this JA3 page that shows lots of implementations for many services that can figure out clients’ TLS fingerprints and act on them. And there’s nothing that says you have to do it with JA3. There’s likely to be numerous other ways and algorithms as well.
There are also companies that offer commercial services to filter off mismatching clients from your site. This is real business.
A TLS Client hello message has lots of info.
Other fingerprinting
In the earlier days of the web, web sites used more basic ways to detect and filter out bots and non-browser user clients. The original and much simpler way is to check the User-Agent: field that HTTP clients pass on, but has also sometimes been extended to check the order of the sent HTTP headers and in some cases, servers have used elaborate JavaScript schemes in order to try to “smoke out” the clients that don’t seem to act like full-fledged browsers.
If the clients use HTTP/2, that too allows for more details to fingerprint.
As the web has transitioned over to almost exclusively use HTTPS, it has severely increased the ways a server can fingerprint clients, and at the same time made it harder for non-browser clients to look exactly like browsers.
Allow list or block list
Sites that use TLS fingerprints to allow access, of course do not want too many false positives. They want to allow all “normal” browser-based visitors, even if they use a little older versions and also if they use somewhat older or less common operating systems.
This means that they either have to work hard to get an extensive list of acceptable hashes in an accept list or they add known non-desired clients in a block list. I would imagine that if you go the accept list route, that’s how companies can sell this services as that is maintenance intensive work.
Users of alternative and niche browsers are sometimes also victims in this scheme if they stand out enough.
Altering the fingerprint
The TLS fingerprints have the interesting feature compared to human fingertip prints, that they are the result of a set of deliberate actions and not just a pattern you are born to wear. They are therefore a lot easier to change.
With curl version C using TLS library T of version V, the TLS fingerprint is a function that involves C, T and V. And the options O set by curl. By changing one or more of those variables, you are likely to alter the TLS fingerprint.
Match a browser exactly
To be most certain that no site will reject your curl request because of its TLS fingerprint, you would alter the print to look exactly like the one of a popular browser. You can suspect that most sites want their regular human browser-using visitors to be able to access them.
To make curl look exactly like a browser you also likely need to do more than just change C, O, T and V from the section above. You also need to make sure that the TLS library you use produces its lists of extensions and ciphers in exactly the same order etc. This may require that you alter options and maybe even source code.
curl-impersonate
This is a custom build of curl that can impersonate the four major browsers: Chrome, Edge, Safari & Firefox. curl-impersonateperforms TLS and HTTP handshakes that are identical to that of a real browser.
curl-impersonate is a modified curl build and the project also provides docker images and more to help users to use it easily.
I cannot say right now if any of the changes done for curl-impersonate will get merged into the upstream curl project, but it will also depend on what users want and how the use of TLS fingerprinting spread or changes going forward.
Program a browser
Another popular way to work around this kind of blocking is to simply program a browser to do the job. Either a headless browser or with tools like Selenium. Since these methods make the TLS handshake using a browser “engine”, they are unlikely to get blocked by these filters.
Cat and mouse
Servers add more hurdles to attempt to block unwanted clients.
Clients change to keep up with the servers and to still access the sites in spite of what the server admins want.
Future
As early as only a few years ago I had never heard of any site that blocked clients because of their TLS handshake. Through recent years I have seen it happen and the use of it seems to have increased. I don’t know of any way to measure if this is actually true or just my feeling.
I cannot rule out that we are going to see this more going forward, even if I also believe that the work on circumventing these fingerprinting filters is just getting started. If the circumvention grows and becomes easy enough, maybe it will stifle servers from adding these filters as they will not be effective anyway?
Let us come back to this topic in a few years and see where it went.
Welcome to a new curl release, the result of a slightly extend release cycle this time.
Release presentation
Numbers
the 210th release 3 changes 65 days (total: 8,930) 165 bug-fixes (total: 8,145) 230 commits (total: 29,017) 0 new public libcurl function (total: 88) 2 new curl_easy_setopt() option (total: 299) 0 new curl command line option (total: 248) 79 contributors, 38 new (total: 2,690) 44 authors, 22 new (total: 1,065) 1 security fixes (total: 126) Bug Bounties total: 40,900 USD
Security
We have yet another CVE to disclose.
control code in cookie denial of service
CVE-2022-35252 allows a server to send cookies to curl that contain ASCII control codes. When such cookies subsequently are sent back to a server, they will cause 400 responses from servers that downright refuse such requests. Severity: low. Reward: 480 USD.
Changes
This release counts three changes. They are:
schannel backend supports TLS 1.3
For everyone who uses this backend (which include everyone who uses the curl that Microsoft bundles with Windows) this is great news: now you too can finally use TLS 1.3 with curl. Assuming that you use a new enough version of Windows 10/11 that has the feature present. Let’s hope Microsoft updates the bundled version soon.
These are two new options meant to replace and be used instead of the options with the same names without the “_STR” extension.
While working on support for new future protocols for libcurl to deal with, we realized that the old options were filled up and there was no way we could safely extend them with additional entries. These new functions instead work on text input and have no limit in number of protocols they can be made to support.
This was yet again a cycle packed with bugfixes. Here are some of my favorites:
asyn-thread: fix socket leak on OOM
Doing proper and complete memory cleanup even when we exist due to out of memory is sometimes difficult. I found and fixed this very old bug.
cmdline-opts/gen.pl: improve performance
The script that generates the curl.1 man page from all its sub components was improved and now typically executes several times faster then before. curl developers all over rejoice.
configure: if asked to use TLS, fail if no TLS lib was detected
Previously, the configure would instead just silently switch off TLS support which was not always easy to spot and would lead to users going further before they eventually realize this.
configure: introduce CURL_SIZEOF
The configure macro that checks for size of variable types was rewritten. It was the only piece left in the source tree that had the mention of GPL left. The license did not affect the product source code or the built outputs, but it caused questions and therefore some friction we could easily avoid by me completely writing away the need for the license mention.
close the happy eyeballs loser connection when using QUIC
A silly memory-leak when doing HTTP/3 connections on dual-stack machines.
treat a blank domain in Set-Cookie: as non-existing
Another one of those rarely used and tiny little details about following what the spec says.
configure: check whether atomics can link
This, and several other smaller fixes together improved the atomics support in curl quite a lot since the previous version. We conditionally use this C11 feature if present to make the library initialization function thread-safe without requiring a separate library for it.
digest: fix memory leak, fix not quoted ‘opaque’
There were several fixes and cleanups done in the digest department this time around.
remove examples/curlx.c
Another “victim” of the new license awareness in the project. This example was the only file present in the repository using this special license, and since it was also a bit convoluted example we decided it did not really have to be included.
resolve *.localhost to 127.0.0.1/::1
curl is now slightly more compliant with RFC 6761, follows in the browsers’ footsteps and resolves all host names in the “.localhost” domain to the fixed localhost addresses.
enable obs-folded multiline headers for hyper
curl built with hyper now also supports “folded” HTTP/1 headers.
libssh2:+libssh make atime/mtime date overflow return error
Coverity had an update in August and immediately pointed out these two long-standing bugs – in two separate SSH backends – related to time stamps and 32 bits.
curl_multi_remove_handle closes CONNECT_ONLY transfer
When an applications sets the CONNECT_ONLY option for a transfer within a multi stack, that connection was not properly closed until the whole multi handle was closed even if the associated easy handle was terminated. This lead to connections being kept around unnecessarily long (and wasting resources).
use pipe instead of socketpair on apple platforms
Apparently those platform likes to close socketpairs when the application is pushed into the background, while pipes survive the same happening… This is a change that might be preferred for other platforms as well going forward.
use larger dns hash table for multi interface
The hash table used for the DNS cache is now made larger for the multi interface than when created to be used by the easy interface, as it simply is more likely to be used by many host names then and then it performs better like this.
reject URLs with host names longer than 65535 bytes
URLs actually have no actual maximum size in any spec and neither does the host name within one, but the maximum length of a DNS name is 253 characters. Assuming you can resolve the name without DNS, another length limit is the SNI field in TLS that is an unsigned 16 bit number: 65535 bytes. This implies that clients cannot connect to any SNI-using TLS protocol with a longer name. Instead of checking for that limit in many places, it is now done early.
reduce size of several struct fields
As part of the repeated iterative work of making sure the structs are kept as small as possible, we have again reduced the size of numerous struct fields and rearranged the order somewhat to save memory.
Next
The next release is planned to ship on October 25, 2022.
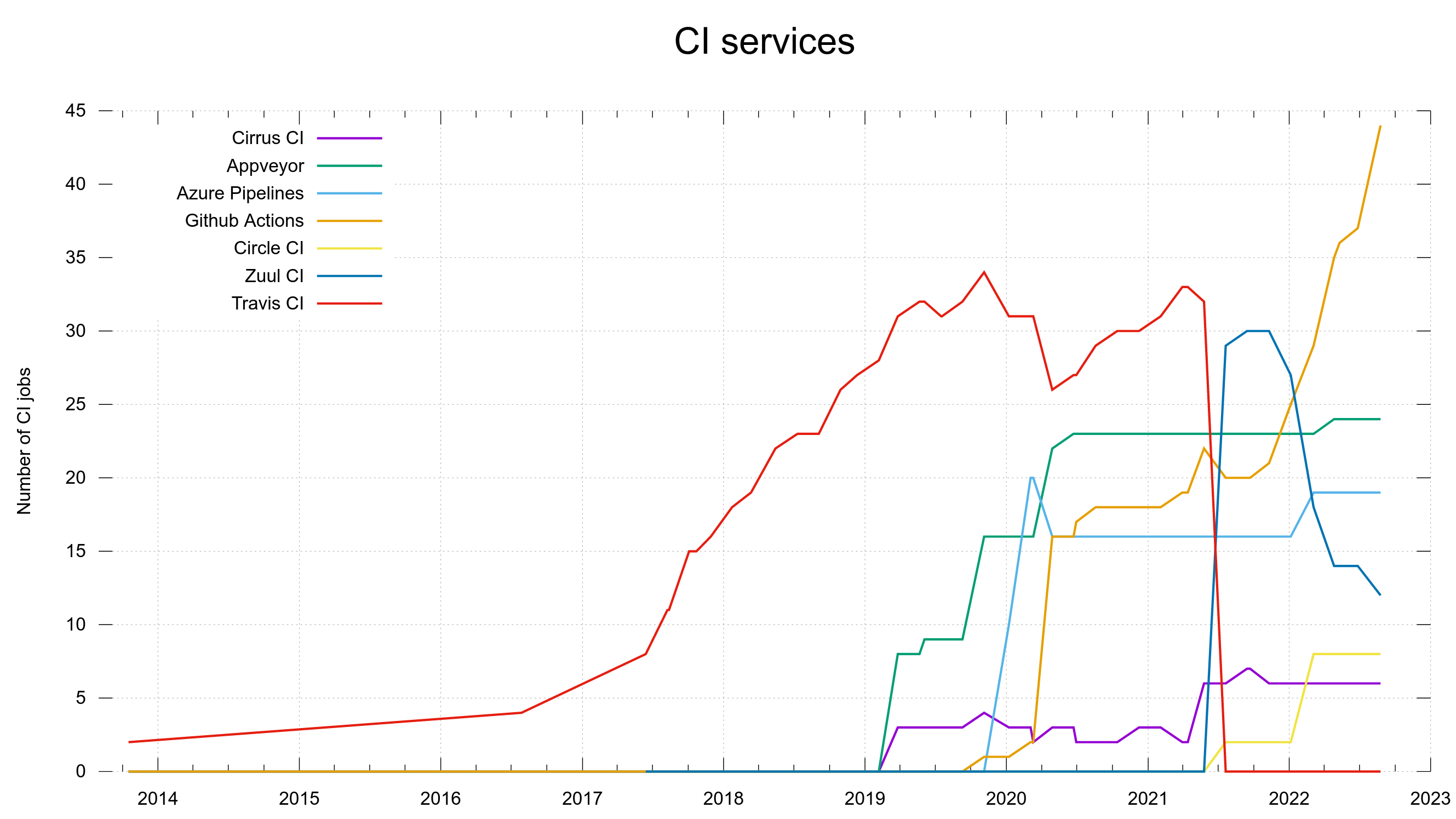
A little over a year ago, we ditched Travis CI as a service to use for the curl project.
Up until that day, it had been our preferred and favored CI service for many years. At most, we ran 34 CI jobs on it, for every pull-request and commit. It was the service that we leaned on when we transitioned the curl project into a CI-heavy user. Our use of CI really took off 2017 and has been increasing ever since.
A clean cut
We abruptly cut off over 30 jobs from the service just one day. At the time, that was a third of all our CI. The CI jobs that we rely on to verify our work and to keep things working and stable in the project.
More CI services
At the time of the amputation, we run 99 CI jobs distributed over 5 services, so even with one of them cut off we still ran jobs on AppVeyor, Azure Pipelines, GitHub Actions and Cirrus CI. We were not completely stranded.
New friends
Luckily for us, when one solution goes sour there are often alternatives out there that we can move over to and continue our never-ending path forward.
In our case, friendly people helped moving over almost all ex-Travis jobs to the (for us) new service Zuul CI. In July 2021, we had 29 jobs on it. We also added Circle CI to the mix and started running jobs there.
In July 2021 – a month after the cut – we counted 96 running jobs (a few old jobs were just dropped as we reconsidered their value). While the work involved a lot of adjusting scripts, pulling hair over yaml files and more, it did not cause any significant service loss over an extended period. We managed pretty good.
There was no noticeable glitch in quality or backed up “guilt” in the project because of the transition and small period of lesser CI either. Thanks to the other services still running, we were still in a good shape.
Why all the services
In the end of August 2022 we still use 6 different CI services and we now run 113 CI jobs on them, for every push to master and to pull-requests.
There are primarily three reasons why we still use a variety of services.
load balancing: we get more parallelism by running jobs on many services as they all have a limited parallelism per service.
We also get less problems when one of the services has some glitch or downtime, as then we still work with the others. The not all eggs in the same basket thing.
The various services also have different features, offer different platforms and work slightly differently which for several jobs make them necessary to run on a specific service, or rather they cannot run on most of the other services.
It does not end
Over the year since the amputation, we have learned that our new friend Zuul CI has turned out to not work quite as reliable and convenient as we would like it. Since a few months back, we are now gradually moving away from this service. Slowly moving over jobs from there to run on one the other five instead.
Over time, our new most preferred CI service has turned out to be GitHub Actions. At the latest count, it now run 44 CI jobs for us. We still have 12 jobs on Zuul targeted for transition.
Our use of different CI services over time in the curl project
Services come and go. We have different ideas and our requirements and ambitions change. I am sure we will continue to service-jump when needed. It is just a natural development. A part of a software development life.
On flakiness
A big challenge and hurdle with our CI setup remains: to maintain the builds and keep them stable and functioning. With over a hundred jobs running on six services and our code and test suite being portable and things being networked and running on many platforms, it is job that we quite often fail at. It has turned out mighty difficult to avoid that at least a few of the jobs are constantly red, “permafailing”, at any single moment.
If this is stuff you like to tinker with, we could use your help!
In June of 2022 we intended to run the curl up 2022 curl conference in person, in California.
Unfortunately, I had the bad taste of catching covid exactly when I was about to use my new US visa for the first time, so I had to remain at home and because of that we cancelled the whole event.
Try again
Now we try again. The curl up 2022 take 2 will be an all-virtual event that is going to be a long Zoom-session with a number of presentations and discussion slots. Feel free to join in for what you want and stay away from the sessions that don’t interest you. We will make our best to keep the schedule, and the agenda will be available ahead of time for you to plan your attendance around.
On September 15, 2022 we will start the show at 15:00 CEST and we have a program that is a full day. Join when you want, leave, come back. You decide.
The Agenda is almost complete. The presentations will be done live or be provided prerecorded. The prerecorded talks will still be discussed and have Q&As live afterwards.
Speak!
There is still room left to add some speakers. If you use curl/libcurl somewhere and want to tell us about things you’ve learned and things libcurl devs should learn, come do it! Or anything else that is related to curl or Internet transfers. Big or small – even just 5 minutes works!
This is a day for sharing info, spreading knowledge and having fun.
Attend!
Yeah, sign up and come hang out with us and watch a range of curl related talks. I think you will learn things and I think it will be a lot of fun.
The curl up hours spelled out in different time zones:
PDT 6:00 – 15:00 (US west coast)
EDT 9:00 – 18:00 (US east coast)
UTC 13:00 – 22:00
CEST 15:00 – 00:00 (central Europe)
IST 18:30 – 03:30 (India)
CST 21:00 – 06:00 (China)
JST 22:00 – 07:00 (Japan)
AEST 23:00 – 08:00 (Sidney, Autralia)
NZST 01:00 – 09:00 (New Zealand) (This is on the 16th)
I get this question fairly often. How would the projects I run manage if I took off? And really, the primary project people think of then is of course curl.
How would the curl project manage if I took a forever vacation starting now?
Of course I don’t know that. We can’t really know for sure until the day comes (in the distant future) when I actually do this. Then you can come back to this post and see how well I anticipated what would happen.
Let me be clear: I do not have any plans to leave the curl project or in any way stop my work on it, neither in the short nor long term. I hope to play this game for a long time still. I am living the dream after all.
Busfactor
Traditionally we talk about the busfactor in various projects as a way to see how many key people a particular project has. The idea being that if there is only one, the project would effectively die if that single person goes away. A busfactor of one is considered bad.
The less morbid name sometimes used for this number is the holiday factor.
There is also the eternal difficult religious question of how to calculate the busfactor, but let’s ignore that today.
I would maybe argue differently
The theory of the busfactor is the idea that the main contributors of a project are irreplaceable and that the lack of other more active involvement are because of a lack of knowledge or ability or something.
It very well might be. A challenge is that there is no way to tell. It could also be that because one or more of the top active developers do a good enough job, the others do not see a need or a reason for them to step up, join in and work. They can very well keep lingering in the background because everything seems to work well enough from their perspective. And if things work well enough in project X, surely lots of people can then rather find interesting work elsewhere. Perhaps in project Y that may not work as well.
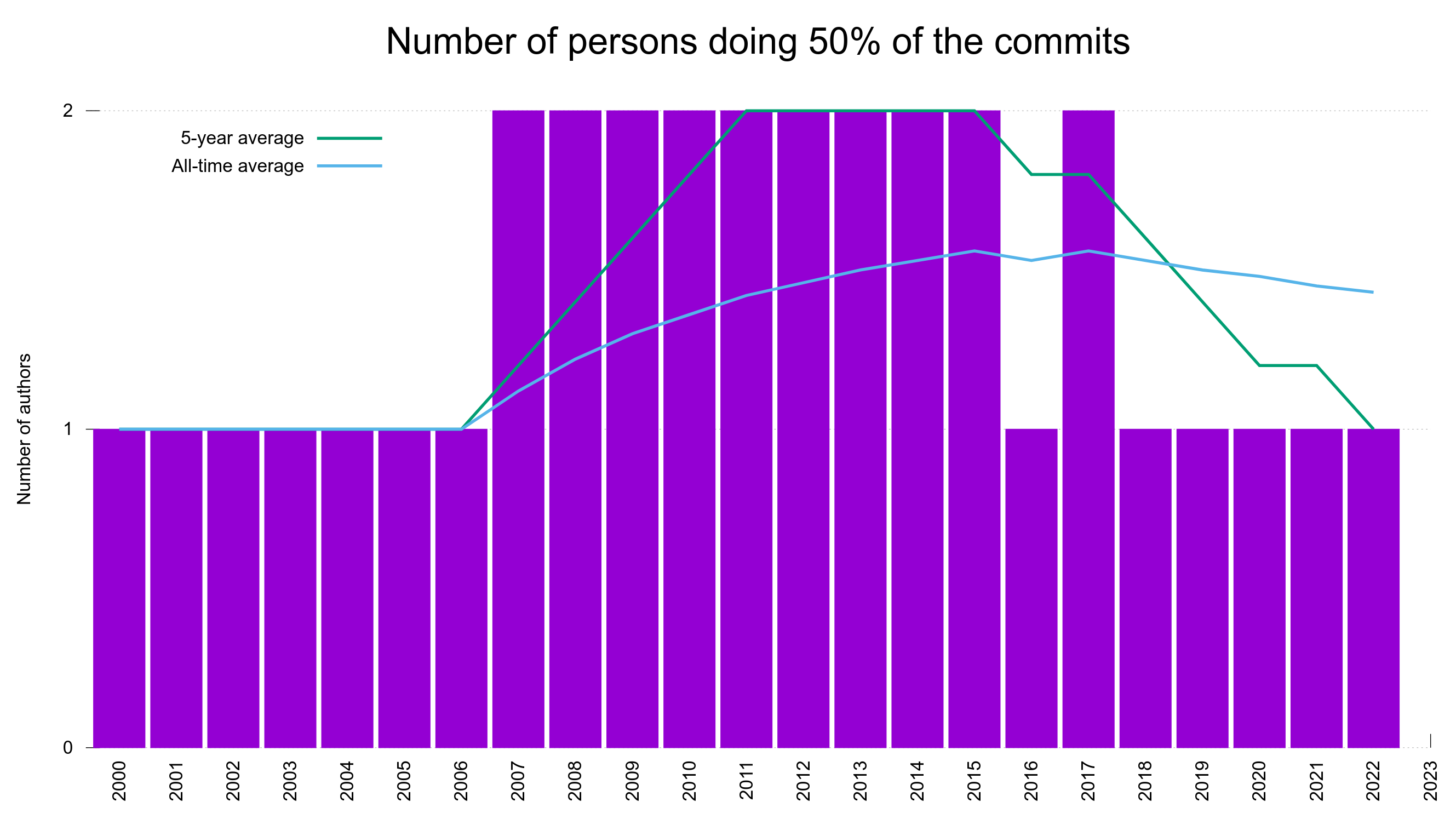
I prefer to think and I actually believe that curl is a project in this second category. It runs pretty well, even if I do a really large chunk of the work in the project. I am not sure curl actually counts as a busfactor one project, but the exact number is not important me. At least I regularly do more than 50% of the commits on an average year.
Graph for the curl source code repository
A safety net
I think an important part of the job for me in the project is to make sure that everything is documented. The code of course, the APIs, the way we build things, how to run tests, how to write tests etc. But also some of the softer things: how we do releases, what the different roles are the project, how we decide merging features, how we work on security issues, how did the project start, how do we want contributions and much much more.
This is the safety net for the day I vanish.
There are no secrets, no hidden handshakes and no surprises. No procedures or ways of working that is not written down and shared with the team.
If you know me and my work in curl, you know that I work fiercely on documentation.
Maybe there is only a single bus driver, but there are wannabe potential drivers following along that can take over the wheel should the seat become empty.
Contingency
There is no designated crown prince/princess or heir who inherits the throne after me. I don’t think that is a valuable thing to even discuss. I am convinced that when the day comes, someone will step up to do what is necessary. If the project is still relevant and in use. Heck, it could even be a great chance to change the way the project is run…
Unless of course the project has already ran out of its use by then, and then it doesn’t matter if someone steps up or not.
Most (95%) of the copyrights in the project are mine. But I have decided to ship the code under a liberal license, so while successors cannot change the copyright situation easily, there should be very little or no reason for doing that.
The keys
If I vanish, the only vital thing you (the successors) will really miss to run and manage the curl project exactly as I have done, is the keys to the building. The passwords and the logins to the various machines and services we use that I can login to, to manage whatever I need to for the project.
If I vanish willingly, I will of course properly hand these over to someone who is willing to step up and take the responsibility. If I instead suddenly get abducted by aliens with no chance for a smooth transition, I have systems setup so that people left behind know what to do and can get access to them.
Recently I have received curious questions from users, customers and bystanders.
Can you explain the seemingly increased CVE activity in curl over like the last year or so?
(data and stats for this post comes mostly from the curl dashboard)
Pointless but related poll I ran on Twitter
Frequency
In 2022 we have already had 14 CVEs reported so far, and we will announce the 15th when we release curl 7.85.0 at the end of August. Going into September 2022, there have been a total of 18 reported CVEs in the last 12 months.
During the whole of 2021 we had 13 CVEs reported – and already that was a large amount and the most CVEs in a single year since 2016.
There has clearly been an increased CVE issue rate in curl as of late.
Finding and fixing problems is good
While every reported security problem stings my ego and makes my soul hurt since it was yet another mistake I feel I should have found or not made in the first place, the key take away is still that it is good that they are found and reported so that they can be fixed properly. Ideally, we also learn something from each such report and make it less likely that we ever introduce that (kind of) problem again.
That might be the absolutely hardest task around each CVE. To figure out what went wrong, detect a pattern and then lock it down. It’s almost amusing how all bugs look a like a one-off mistake with nothing to learn from…
Ironically, the only way we know people are looking really hard at curl security is when someone reports security problems. If there was no reports at all, can we really be sure that people are scrutinizing the code the way we want?
Who is counting?
Counting the amount of CVEs and giving that a meaning, or even comparing the number between projects, is futile and a bad idea. The number does not say much and comparing two projects this way is impossible and will not tell you anything. Every project is unique.
Just counting CVEs disregards the fact that they all have severity levels. Are they a dozen “severity low” or are they a handful of critical ones? Even if you take severity into account, they might have gotten entirely different severity for virtually the same error, or vice versa.
Further, some projects attract more scrutinize and investigation because they are considered more worthwhile targets. Or perhaps they just pay researchers more for their findings. Projects that don’t get the same amount of focus will naturally get fewer security problems reported for them, which does not necessarily mean that they have fewer problems.
Incentives
The curl bug-bounty really works as an incentive as we do reward security researchers a sizable amount of money for every confirmed security flaw they report. Recently, we have handed over 2,400 USD for each Medium-severity security problem.
In addition to that, finding and getting credited for finding a flaw in a widespread product such as curl is also seen as an extra “feather in the hat” for a lot of security-minded bug hunters.
Over the last year alone, we have paid about 30,000 USD in bug bounty rewards to security researchers, summing up a total of over 40,000 USD since the program started.
Accumulated bug-bounty rewards for curl CVEs over time
Who’s looking?
We have been fortunate to have received the attention of some very skilled, patient and knowledgeable individuals. To find security problems in modern curl, the best bug hunters both know the ins and outs of the curl project source code itself while at the same time they know the protocols curl speaks to a deep level. That’s how you can find mismatches that shouldn’t be there and that could lead to security problems.
The 15 reports we have received in 2022 so far (including the pending one) have been reported by just four individuals. Two of them did one each, the other two did 87% of the reporting. Harry Sintonen alone reported 60% of them.
Hardly any curl security problems are found with source code analyzers or even fuzzers these days. Those low hanging fruits have already been picked.
We care, we act
Our average response time for security reports sent to the curl project has been less than two hours during 2022, for the 56 reports received so far.
We give each report a thorough investigation and we spend a serious amount of time and effort to really make sure we understand all the angles of the claim, that it really is a security problem, that we produce the best possible fix for it and not the least: that we produce a mighty fine advisory for the issue that explains it to the world with detail and accuracy.
Less than 8% of the submissions we get are eventually confirmed actual security problems.
As a general rule all security problems we confirm, are fixed in the pending next release. The only acceptable exception would be if the report arrives just a day or two from the next release date.
We work hard to make curl more secure and to use more ways of writing secure code and tools to detect mistakes than ever, to minimize the risk for introducing security flaws.
Judge a project on how it acts
Since you cannot judge a project by the number of CVEs that come out of it, what you should instead pay more focus on when you assess the health of a software project is how it acts when security problems are reported.
Most problems are still very old
In the curl project we make a habit of tracing back and figuring out exactly in which release each and every security problem was once introduced. Often the exact commit. (Usually that commit was authored by me, but let’s not linger on that fact now.)
One fun thing this allows us to do, is to see how long time the offending code has been present in releases. The period during which all the eyeballs that presumably glanced over the code missed the fact that there was a security bug in there.
On average, curl security problems have been present an extended period of time before there are found and reported.
On average for all CVEs: 2,867 days
The average time bugs were present for CVEs reported during the last 12 months is a whopping 3,245 days. This is very close to nine years.
How many people read the code in those nine years?
The people who find security bugs do not know nor do they care about the age of a source code line when they dig up the problems. The fact that the bugs are usually old could be an indication that we introduced more security bugs in the past than we do now.
Finding vs introducing
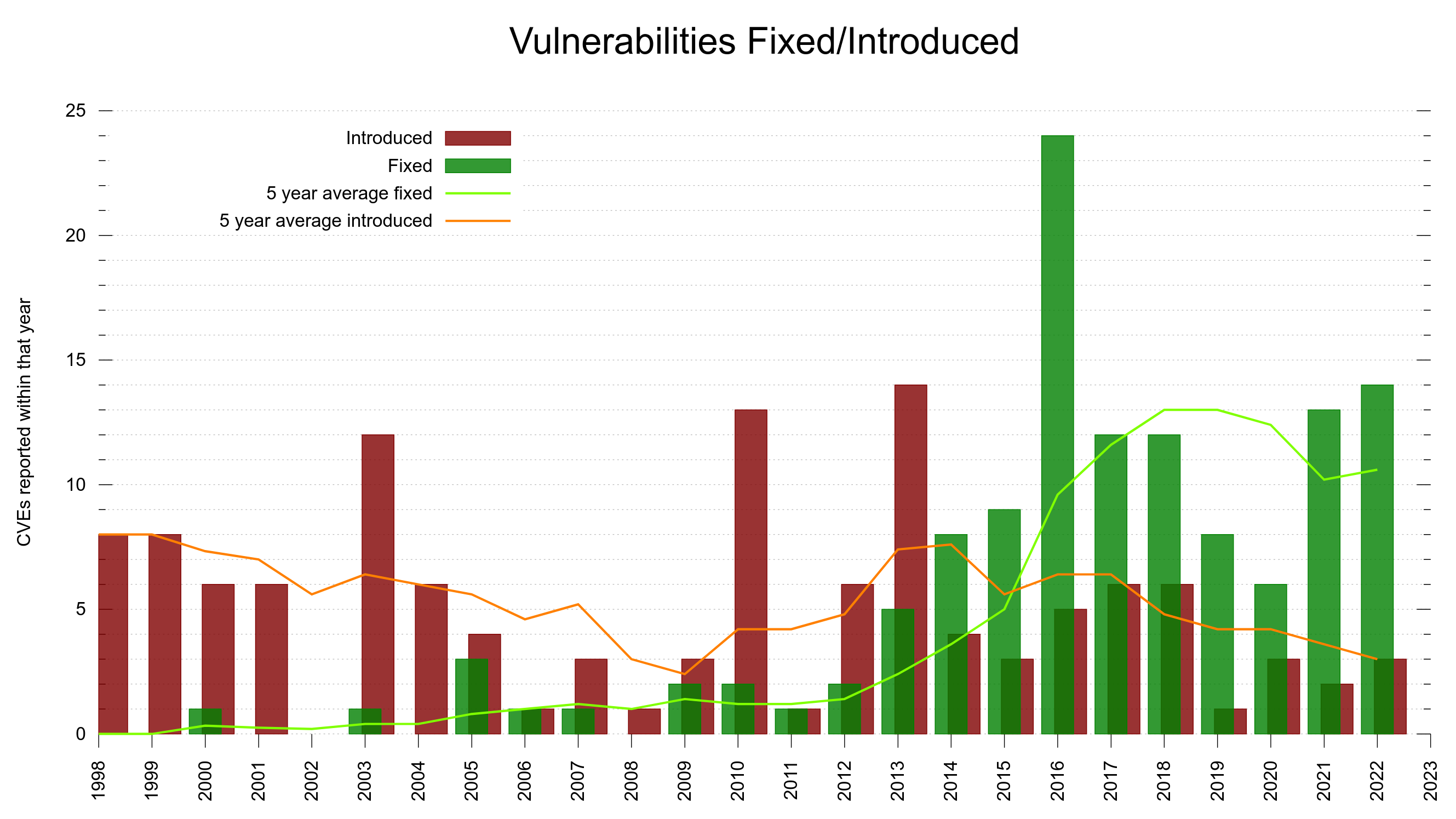
Enough about finding issues for a moment. Let’s talk about introducing security problems. I already mentioned we track down exactly when security flaws were introduced. We know.
All CVEs in curl, green are found, red are introduced
With this, we can look at the trend and see if we are improving over time.
The project has existed for almost 25 years, which means that if we introduce problems spread out evenly over time, we would have added 4% of them every year. About 5 CVE problems are introduced per year on average. So, being above or below 5 introduced makes us above or below an average year.
Bugs are probably not introduced as a product of time, but more as a product of number of lines of code or perhaps as a ratio of the commits.
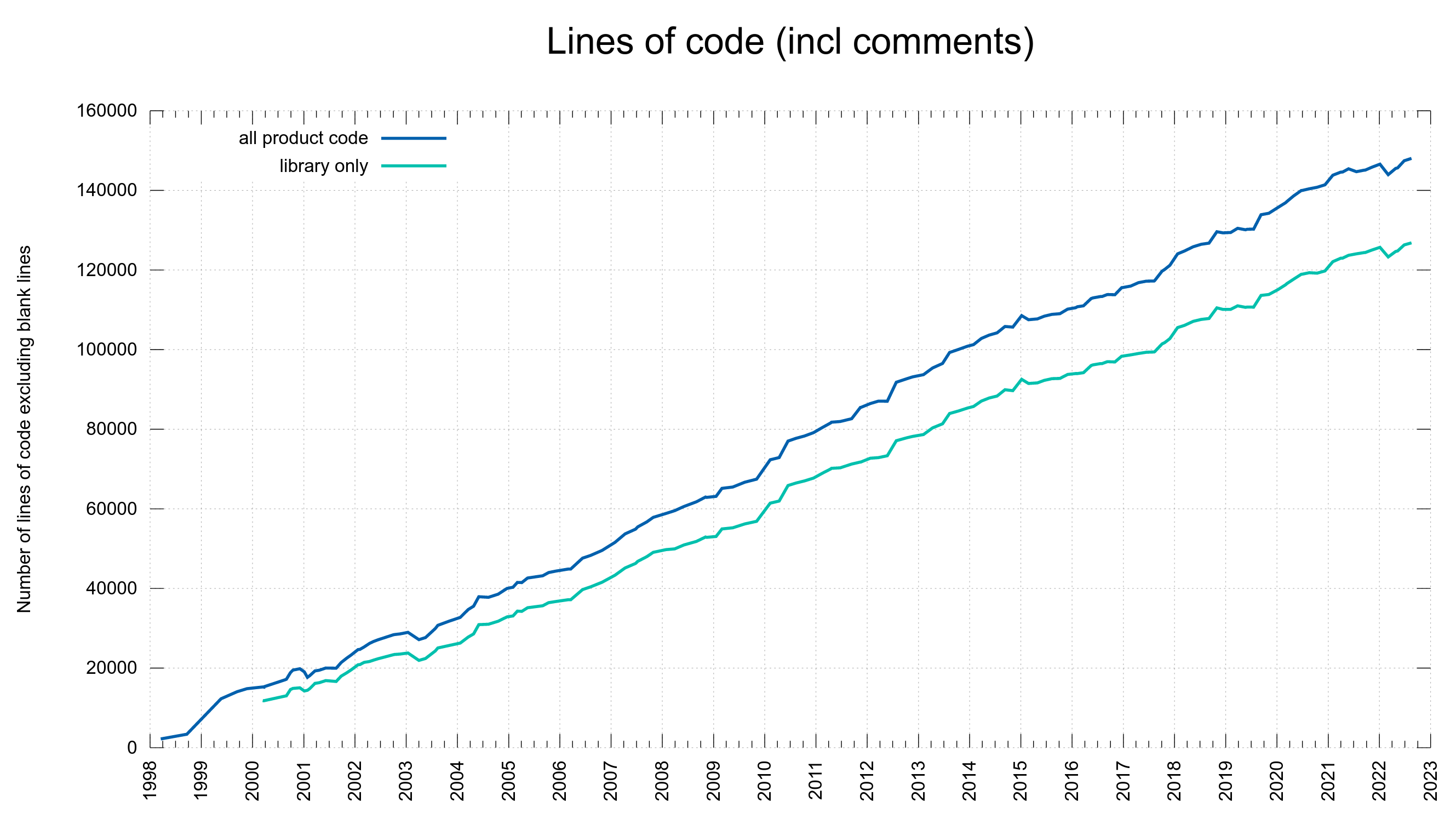
75% of the CVE errors were introduced before March 2014 – and yet the code base “only” had 102,000 lines of code at the end of that period. At that time, we had done 61% of the git commits (17684). One CVE per 189 commits.
15% of the security problems were introduced during the last five years and now we are at 148,000 lines of code. Finding needles in a growing haystack. With more code than ever before, we introduce bugs at a lower-than average rate. One CVE per 352 commits. This probably is also related to the ever-growing number of tests and CI jobs that help us detect more problems before we merge them.
Number of lines of code. Includes comments, excludes blank lines
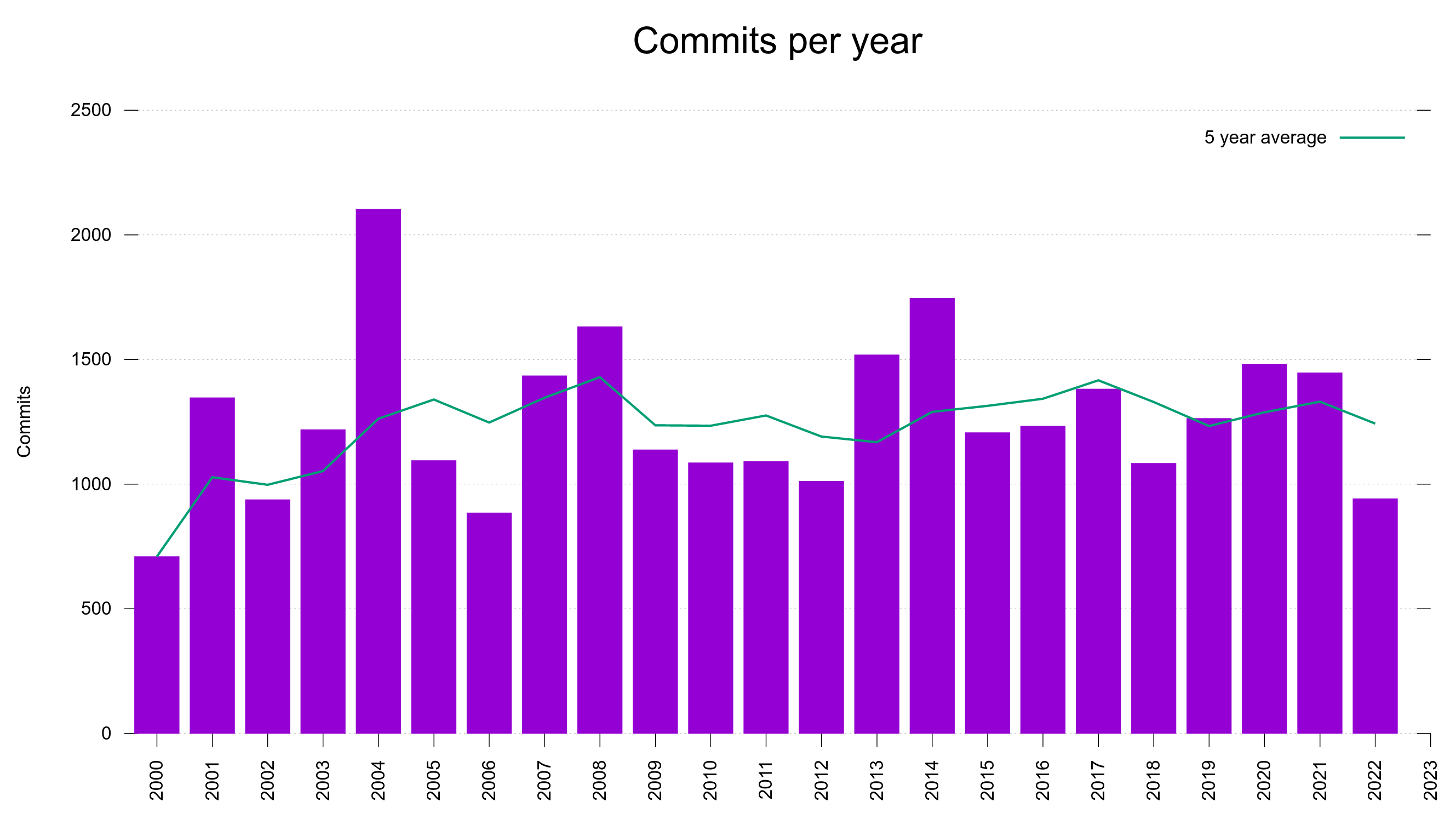
The commit rate has remained between 1,100 and 1,700 commits per year since 2007 with ups and downs but no obvious growing or declining trend.
Number of commits per year
Harry Sintonen
Harry reported a large amount of the recent curl CVEs as mentioned above, and is credited for a total of 17 reported curl CVEs – no one else is even close to that track record. I figured it is apt to ask him about the curl situation of today, to make sure this is not just me hallucinating things up. What do you think is the reason for the increased number of CVEs in curl in 2022?
Harry replied:
The news of good bounties being paid likely has been attracting more researchers to look at curl.
I did put considerable effort in doing code reviews. I’m sure some other people put in a lot of effort too.
When a certain before unseen type of vulnerability is found, it will attract people to look at the code as a whole for similar or surrounding issues. This quite often results in new, similar CVEs bundling up. This is kind of a clustering effect.
It’s worth mentioning, I think, that even though there has been more CVEs found recently, they have been found (well most of them at least) as part of the bug bounty program and get handled in a controlled manner. While it would be even better to have no vulnerabilities at all, finding and handling them in controlled manner is the 2nd best option.
This might be escaping a random observer who just looks at the recent amount of CVEs and goes “oh this is really bad – something must have gone wrong!”. Some of the issues are rather old and were only found now due to the increased attention.
Conclusion
We introduce CVE problems at a slower rate now than we did in the past even though we have gotten problems reported at a higher than usual frequency recently.
The way I see it, we are good. I suppose the future will tell if I am right.
With just a month left until its seventh birthday, everything curl has now surpassed this amazing milestone. The book now contains more than 100,000 words. Distributed over 883 sections. All written in glorious markdown.
Two years ago when we celebrated its 5th birthday, it was still this measly thin “pamphlet” of 72,000 words. It has grown by almost 40% over the last two years.
The average word length in the book is now 5.25 characters and all this is spread out over 14,900 lines (in the source markdowns).
63 individuals have had their commits merged. I have great help from people to polish off weird language and wrong English.
My ambition with this book remains the same: to document everything there is to tell about curl and libcurl from every aspect. Code, use, development, project, background, future, philosophy and more.
CI
News from the last year for everything curl is that we have several CI jobs now that verify new contributions to make sure we don’t degrade too much. They check that:
we avoid some words (contractions and some other things) – basically my most common mistakes
spellcheck
markdown heading level sanity check
The spellcheck part can of course be a bit tedious for such a technical document but I realized that since I am such a sloppy writer I need that check. This has really reduced the inflow of PRs with spelling fixes.
These CI jobs makes the quality of the book much better even though it is a highly moving target.
Keeping up
As curl is a constantly evolving project that adds new features and changes things every now and then, there is also a constant stream of new things to add or update in the book.
Since I also want the book to work for readers that may very well run curl versions from several years ago, we need to keep that in mind and make sure to keep “old behavior” and details around for a while.