A few hours ago I ended my webinar on how to get your code contribution merged into curl. Here’s the video of it:
Here are the slides.

curl and/or libcurl related
A few hours ago I ended my webinar on how to get your code contribution merged into curl. Here’s the video of it:
Here are the slides.
The curl test suite fires up a whole bunch of test servers for the various supported protocols, and then command lines using curl or libcurl-using dedicated test apps are run against those servers to make sure curl is acting exactly as it is supposed to.

The curl test suite was introduced back in the year 2000 and has of course grown and been developed substantially since then.
Each test server is invoked and handles a specific protocol or set of protocols, so to make sure curl’s 24 transfer protocols are tested, a lot of test server instances are spun up. The test servers normally don’t shut down after each individual test but instead keep running in case there are more tests for that protocol for speedier operations. When all tests are completed, all the test servers are shut down again.
The protocols curl communicates with are all done over TCP or UDP, and therefore each test server needs to listen to a dedicated port so that the tests can be invoked and curl can use the protocols correctly.
We started the test suite once by using port number 8990 as a default “base port”, and then each subsequent server it invokes gets the next port number. A full round can use up to 30 or so ports.
The script needed to know what port number to use so that it could invoke the tests to use the correct port number. But port numbers are both a scarce resource and a resource that can only be used by one server at a time, so if you would simultaneously invoke the curl test suite a second time on the same machine, it would cause havoc since it would attempt to use the same port numbers again.
Not to mention that when various users run the test suite on their machines, on servers or in CI jobs, just assuming or hoping that we could use a range of 30 fixed port numbers is error-prone and it would occasionally cause us trouble.
A few months ago, in April 2020, I started the work on changing how the curl test suite uses port numbers for its test servers. Each used test server would instead get fired up on a totally random port number, and then feed back that number to the test script that then would use the actually used port number to run the tests against.
It took some rearranging of internal logic to make sure things still worked and that the comparison of the generated protocol etc still would work. Then it was “just” a matter of converting over all test servers to this new dynamic concept and made sure that there was no old-style assumptions lingering around in the test cases.
Some of the more tricky changes for this new paradigm was the protocol parts that use the port number in data where curl base64 encodes the chunk and sends it to the server.
The final fixed port number in the curl test suite was removed when we merged PR 5783 on August 7 2020. Now, every test in curl that needs a port number uses a dynamic port number.
Now we can run “make test” from multiple shells on the same machine in parallel without problems.
It can allow us to improve the test suite further and maybe for example run multiple tests in parallel in order to reduce the total execution time. It will avoid future port collisions. A small, but very good step forward.
Yay.
Image by Gerd Altmann from Pixabay
When: Aug 13, 2020 10:00 AM Pacific Time (US and Canada) (17:00 UTC)
Length: 30 minutes
Abstract: curl is a wildly popular and well-used open source tool and library, and is the result of more than 2,200 named contributors helping out. Over 800 individuals wrote at least one commit so far.
In this presentation, curl’s lead developer Daniel Stenberg talks about how any developer can proceed in order to get their first code contribution submitted and ultimately landed in the curl git repository. Approach to code and commits, style, editing, pull-requests, using github etc. After you’ve seen this, you’ll know how to easily submit your improvement to curl and potentially end up running in ten billion installations world-wide.
Register in advance for this webinar:
https://us02web.zoom.us/webinar/register/WN_poAshmaRT0S02J7hNduE7g
--path-as-is is a boolean option that was added in curl 7.42.0.
I hope it isn’t a surprise to you that curl works on URLs. It’s one of the fundamental pillars of curl. The “URLs” curl work with are actually called “URIs” in the IETF specs and the primary specification for them is RFC 3986. (But also: my URL is not your URL…)
A URL can be split up into several different components, which is typically done by the “URL parser” in a program like curl. For example , we can identify a scheme, a host name and a path.
When a program is given a URL, and the program has identified the path part of that URL – it is supposed to “Remove Dot Segments” (to use the wording from RFC 3986) before that path is used.
Let me show you this with an example to make it clear. Ponder that you pass this URL to curl: "https://example.org/hello/../to/../your/../file". Those funny dot-dot sequences in there is traditional directory traversal speak for “one directory up”, while a single "./" means in the same directory.
RFC 3986 says these sequences should be removed, so curl will iterate and remove them accordingly. A sequence like "word/../" will effectively evaluate to nothing. The example URL above will be massaged into the final version: "https://example.org/file" and so curl will ask the server for just /file.
Seen as pure HTTP 1.1, the result of the command line used without --path-as-is:
GET /file HTTP/1.1
Host: example.org
user-agent: curl/7.71.0
accept: */*
Same command line, with --path-as-is:
GET /hello/../to/../your/../file HTTP/1.1
Host: example.org
user-agent: curl/7.71.1
accept: */*
HTTP servers have over the years been found to have errors and mistakes in how they handle paths and a common way to exploit such flaws has been to pass on exactly this kind of dot-dot sequences to servers.
The very minute curl started removing these sequences (as the spec tells us) security researcher objected and asked for ways to tell curl to not do this. Enter --path-as-is. Use this option to make curl send the path exactly as provided in the URL, without removing any dot segments.
Other curl options that allow you to customize HTTP request details include --header, --request and --request-target.
Previous options of the week.
--silent (-s) existed in curl already in the first ever version released: 4.0.
I’ve always enjoyed the principles of Unix command line tool philosophy and I’ve tried to stay true to them in the design and implementation of the curl command line tool: everything is a pipe, don’t “speak” more than necessary by default.
As a result of the latter guideline, curl features the --verbose option if you prefer it to talk and explain more about what’s going on. By default – when everything is fine – it doesn’t speak much extra.
To show users that something is happening during a command line invoke that takes a long time, we added a “progress meter” display. But since you can also ask curl to output text or data in the terminal, curl has logic to automatically switch off the progress meter display to avoid content output to get mixed with it.
Of course we very quickly figured out that there are also other use cases where the progress meter was annoying so we needed to offer a way to shut it off. To keep silent! --silent was the obvious choice for option name and -s was conveniently still available.
The other thing that curl “speaks” by default is the error message. If curl fails to perform the transfer or operation as asked to, it will output a single line message about it when it is done, and then return an error code.
When we added an option called --silent to make curl be truly silent, we also made it hush the error message. curl still returns an error code, so shell scripts and similar environments that invoke curl can still detect errors perfectly fine. Just possibly slightly less human friendly.
In May 1999, the tool was just fourteen months old, we added --show-error (-S) for users that wanted to curl to be quiet in general but still wanted to see the error message in case it failed. The -Ss combination has been commonly used ever since.
Over time we’ve made the tool more complex and we’ve felt that it needs some more informational output in some cases. For example, when you use --retry, curl will say something that it will try again etc. The reason is of course that --verbose is really verbose so its not really the way to ask for such little extra helpful info.
Not too long ago, we ended up with a new situation where the --silent option is a bit too silent since it also disables the text for retry etc so what if you just want to shut off the progress meter?
--no-progress-meter was added for that, which thus is a modern replacement for --silent in many cases.
The webinar from June 30, now on video. The slides are here.
This is a follow-up patch release a mere week after the grand 7.71.0 release. While we added a few minor regressions in that release, one of them were significant enough to make us decide to fix and ship an update sooner rather than later. I’ll elaborate below.
Every early patch release we do is a minor failure in our process as it means we shipped annoying/serious bugs. That of course tells us that we didn’t test all features and areas good enough before the release. I apologize.
the 193rd release
0 changes
7 days (total: 8,139)
18 bug fixes (total: 6,227)
32 commits (total: 25,943)
0 new public libcurl function (total: 82)
0 new curl_easy_setopt() option (total: 277)
0 new curl command line option (total: 232)
16 contributors, 8 new (total: 2,210)
5 authors, 2 new (total: 805)
0 security fixes (total: 94)
0 USD paid in Bug Bounties
compare cert blob when finding a connection to reuse – when specifying the client cert to libcurl as a “blob”, it needs to compare that when it subsequently wants to reuse a connection, as curl already does when specifying the certificate with a file name.
curl_easy_escape: zero length input should return a zero length output – a regression when I switched over the logic to use the new dynbuf API: I inadvertently modified behavior for escaping an empty string which then broke applications. Now verified with a new test.
set the correct URL in pushed HTTP/2 transfers – the CURLINFO_EFFECTIVE_URL variable previously didn’t work for pushed streams. They would all just claim to be the parent stream’s URL.
fix HTTP proxy auth with blank password – another dynbuf conversion regression that now is verified with a new test. curl would pass in “(nil)” instead of a blank string (“”).
terminology: call them null-terminated strings – after discussions and an informal twitter poll, we’ve rephrased all documentation for libcurl to use the phrase “null-terminated strings” and nothing else.
allow user + password to contain “control codes” for HTTP(S) – previously byte values below 32 would maybe work but not always. Someone with a newline in the user name reported a problem. It can be noted that those kind of characters will not work in the credentials for most other protocols curl supports.
Reverted the implementation of “wait using winsock events” – another regression that apparently wasn’t tested good enough before it landed and we take the opportunity here to move back to the solution we have before. This change will probably take another round and aim to get landed in a better shape in a future.
ngtcp2: sync with current master – interestingly enough, the ngtcp2 project managed to yet again update their API exactly this week between these two curl releases. This means curl 7.71.1 can be built against the latest ngtcp2 code to speak QUIC and HTTP/3.
In parallel with that ngtcp2 sync, I also ran into a new problem with BoringSSL’s master branch that is fixed now. Timely for us, as we can now also boast with having the quiche backend in sync and speaking HTTP/3 fine with the latest and most up-to-date software.
We have not updated the release schedule. This means we will have almost three weeks for merging new features coming up then four weeks of bug-fixing only until we ship another release on August 19 2020. And on and on we go.
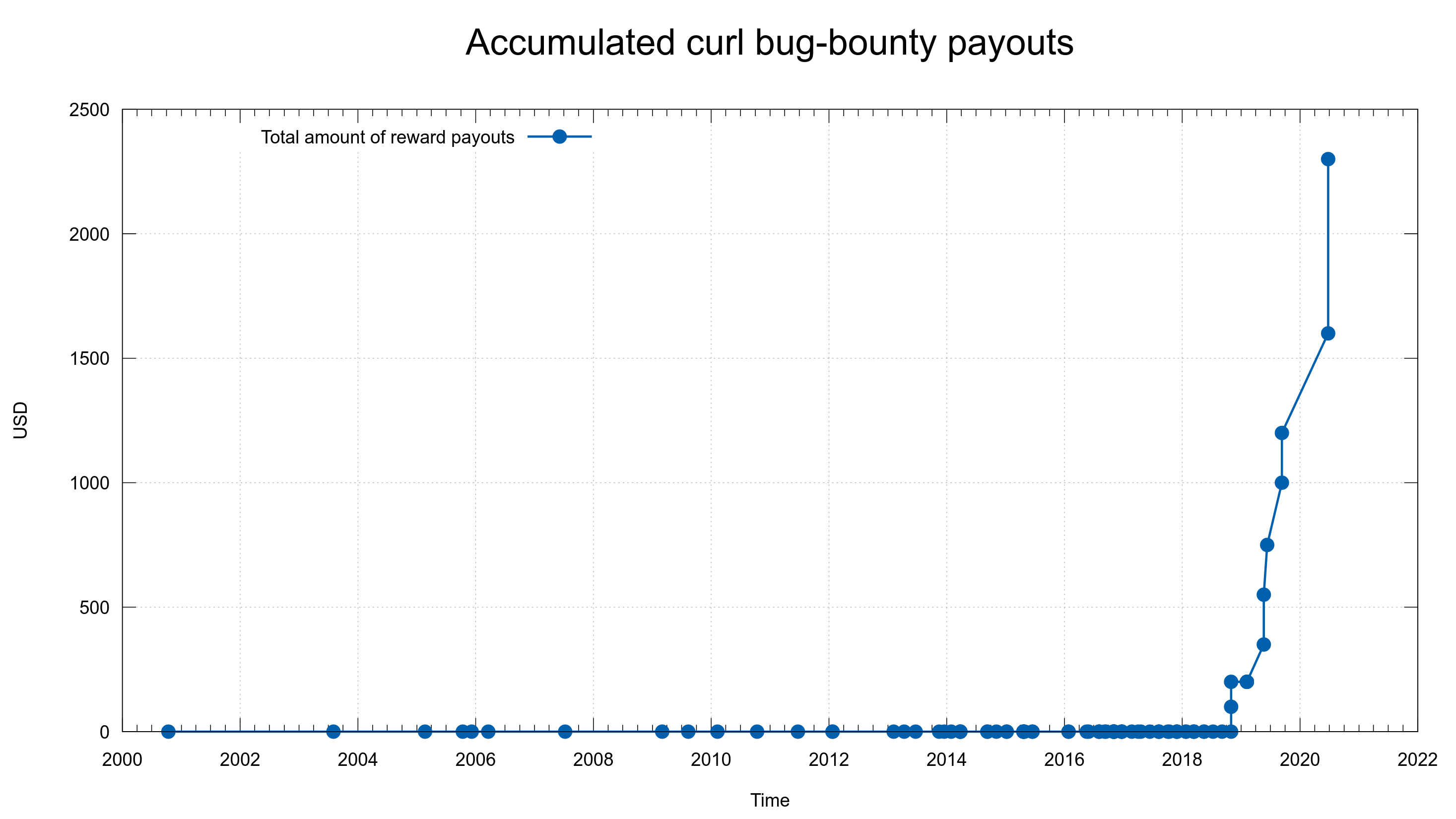
A while ago I tweeted the good news that we’ve handed over our largest single monetary reward yet in the curl bug-bounty program: 700 USD. We announced this security problem in association with the curl 7.71.0 release the other day.
Someone responded to me and wanted this clarified: we award 700 USD to someone for reporting a curl bug that potentially affects users on virtually every computer system out there – while Apple just days earlier awarded a researcher 100,000 USD for an Apple-specific security flaw.
The difference in “amplitude” is notable.
I think first we should start with appreciating that we have a bug-bounty program at all! Most open source projects don’t, and we didn’t have any program like this for the first twenty or so years. Our program is just getting started and we’re getting up to speed.
How can we in the curl project hand out any money at all? We get donations from companies and individuals. This is the only source of funds we have. We can only give away rewards if we have enough donations in our fund.
When we started the bug-bounty, we also rather recently had started to get donations (to our Open Collective fund) and we were careful to not promise higher amounts than we would be able to pay, as we couldn’t be sure how many problems people would report and exactly how it would take off.
Over time it has gradually become clear that we’re getting donations at a level and frequency that far surpasses what we’re handing out as bug-bounty rewards. As a direct result of that, we’ve agreed in the the curl security team to increase the amounts.
For all security reports we get now that end up in a confirmed security advisory, we will increase the handed out award amount – until we reach a level we feel we can be proud of and stand for. I think that level should be more than 1,000 USD even for the lowest graded issues – and maybe ten times that amount for an issue graded “high”. We will however never get even within a few magnitudes of what the giants can offer.
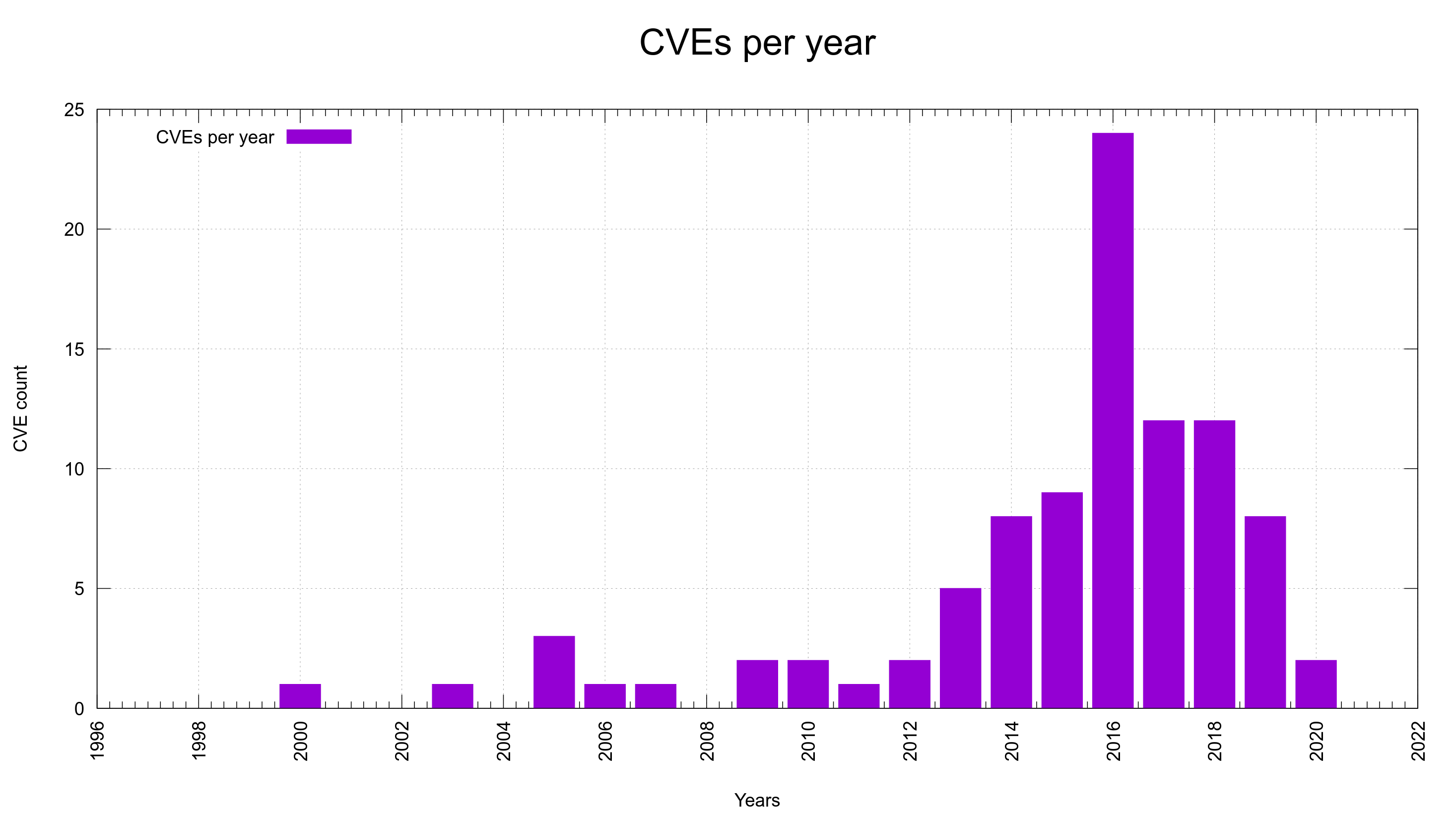
The graph with number of reported CVEs per year shows that we started to get a serious number of reports in 2013 (5 reports) and it also seems to show that we’ve passed the peak. I’m not sure we have enough enough data and evidence to back this up, but I’m convinced we do a lot of things much better in the project now that should help to keep the amount of reports down going forward. In a few years when we look back we can see if I was right.
We’re at mid year 2020 now with only two reports so far, which if we keep this rate will make this the best CVE-year after 2012. This, while we offer more money than ever for reported issues and we have a larger amount of code than ever to find problems in.
One company suggests that they will chip in and pay for an increased curl bug bounty if the problem affects their use case, but for some reason the problems just never seem to affect them and I’ve pretty much stopped bothering to even ask them.
curl is shipped with a large number of operating systems and in a large number of applications but yet not even the large volume users participate in the curl bug bounty program but leave it to us (and they rarely even donate). Perhaps you can report curl security issues to them and have a chance of a higher reward?
You would possibly imagine that these companies should be keen on helping us out to indirectly secure users of their operating systems and applications, but no. We’re an open source project. They can use our products for free and they do, and our products improve their end products. But if there’s a problem in our stuff, that issue is ours to sort out and fix and those companies can then subsequently upgrade to the corrected version…
This is not a complaint, just an observation. I personally appreciate the freedom this gives us.
Help us review code. Report bugs. Report all security related problems you can find or suspect exists. Get your company to sponsor us. Write awesome pull requests that improve curl and the way it does things. Use curl and libcurl in your programs and projects. Buy commercial curl support from the best and only provider of commercial curl support.

Welcome to the “prose version” of the curl 7.71.0 change log. There’s just been eight short weeks since I last blogged abut a curl release but here we are again and there’s quite a lot to say about this new one.
the 192nd release
4 changes
56 days (total: 8,132)
136 bug fixes (total: 6,209)
244 commits (total: 25,911)
0 new public libcurl function (total: 82)
7 new curl_easy_setopt() option (total: 277)
1 new curl command line option (total: 232)
59 contributors, 33 new (total: 2,202)
33 authors, 17 new (total: 803)
2 security fixes (total: 94)
1,100 USD paid in Bug Bounties
This is a nasty bug in user credential handling when doing authentication and HTTP redirects, which can lead to a part pf the password being prepended to the host name when doing name resolving, thus leaking it over the network and to the DNS server.
This bug was reported and we fixed it in public – and then someone else pointed out the security angle of it! Just shows my lack of imagination. As a result, even though this was a bug already reported – and fixed – and therefor technically not subject for a bug bounty, we decide to still reward the reporter, just maybe not with the full amount this would otherwise had received. We awarded the reporter 400 USD.
When curl -J is used it doesn’t work together with -i and there’s a check that prevents it from getting used. The check was flawed and could be circumvented, which the effect that a server that provides a file name in a Content-Disposition: header could overwrite a local file, since the check for an existing local file was done in the code for receiving a body – as -i wasn’t supposed to work… We awarded the reporter 700 USD.
We’re counting four “changes” this release.
CURLSSLOPT_NATIVE_CA – this is a new (experimental) flag that allows libcurl on Windows, built to use OpenSSL to use the Windows native CA store when verifying server certificates. See CURLOPT_SSL_OPTIONS. This option is marked experimental as we didn’t decide in time exactly how this new ability should relate to the existing CA store path options, so if you have opinions on this you know we’re interested!
CURLOPT-BLOBs – a new series of certificate related options have been added to libcurl. They all take blobs as arguments, which are basically just a memory area with a given size. These new options add the ability to provide certificates to libcurl entirely in memory without using files. See for example CURLOPT_SSLCERT_BLOB.
CURLOPT_PROXY_ISSUERCERT – turns out we were missing the proxy version of CURLOPT_ISSUERCERT so this completed the set. The proxy version is used for HTTPS-proxy connections.
--retry-all-errors is the new blunt tool of retries. It tells curl to retry the transfer for all and any error that might occur. For the cases where just --retry isn’t enough and you know it should work and retrying can get it through.
This is yet another release with over a hundred and thirty different bug-fixes. Of course all of them have their own little story to tell but I need to filter a bit to be able to do this blog post. Here are my collected favorites, in no particular order…
There are more changes coming and some PR are already pending waiting for the feature window to open. Next release is likely to become version 7.72.0 and have some new features. Stay tuned!
--connect-timeout [seconds] was added in curl 7.7 and has no short option version. The number of seconds for this option can (since 7.32.0) be specified using decimals, like 2.345.
curl shipped with support for the -m option already from the start. That limits the total time a user allows the entire curl operation to spend.
However, if you’re about to do a large file transfer and you don’t know how fast the network will be so how do you know how long time to allow the operation to take? In a lot of of situations, you then end up basically adding a huge margin. Like:
This operation usually takes 10 minutes, but what if everything is super overloaded at the time, let’s allow it 120 minutes to complete.
Nothing really wrong with that, but sometimes you end up noticing that something in the network or the remote server just dropped the packets and the connection wouldn’t even complete the TCP handshake within the given time allowance.
If you want your shell script to loop and try again on errors, spending 120 minutes for every lap makes it a very slow operation. Maybe there’s a better way?
To help combat this problem, the --connect-timeout is a way to “stage” the timeout. This option sets the maximum time curl is allowed to spend on setting up the connection. That involves resolving the host name, connecting TCP and doing the TLS handshake. If curl hasn’t reached its “established connection” state before the connect timeout limit has been reached, the transfer will be aborted and an error is returned.
This way, you can for example allow the connect procedure to take no more than 21 seconds, but then allow the rest of the transfer to go on for a total of 120 minutes if the transfer just happens to be terribly slow.
Like this:
curl --connect-timeout 21 --max-time 7200 https://example.com
You can even set the connection timeout to be less than a second (with the exception of some special builds that aren’t very common) with the use of decimals.
Require the connection to be established within 650 milliseconds:
curl --connect-timeout 0.650 https://example.com
Just note that DNS, TCP and the local network conditions etc at the moment you run this command line may vary greatly, so maybe restricting the connection time a lot will have the effect that it sometimes aborts a connection a little too easily. Just beware.
If you prefer a way to detect and abort transfers that stall after a while (but maybe long before the maximum timeout is reached), you might want to look into using –limit-speed.
Also, if a connection goes down to zero bytes/second for a period of time, as in it doesn’t send any data at all, and you still want your connection and transfer to survive that, you might want to make sure that you have your –keepalive-time set correctly.






