This whole family of functions, fopen, fread, fwrite, fgets, fclose and more are defined in the C standard since C89. You can’t really call yourself a C programmer without knowing them and probably even using them in at least a few places.
The charm with these is that they’re standard, they’re easy to use and they’re available everywhere where there’s a C compiler.
A basic example that just reads a file from disk and writes it to stdout could look like this:
FILE *file;
file = fopen("hello.txt", "r");
if(file) {
char buffer [256];
while(1) {
size_t rc = fread(buffer, sizeof(buffer),
1, file);
if(rc > 0)
fwrite(buffer, rc, 1, stdout);
else
break;
}
fclose(file);
}
Imagine you’d like to switch this example, or one of your actual real world programs that use the fopen() family of functions to read or write files, and instead read and write files from and to the Internet instead using your favorite Internet protocols. How would you do that without having to change your code a lot and do a major refactoring job?
Enter fcurl
I’ve started to work on a library that provides a look-alike API with matching functions and behaviors, but that allows fopen() to instead specify a URL instead of a file name. I call it fcurl. (Much inspired by the libcurl example fopen.c, which I wrote the first version of already back in 2002!)
It is of course open source and is powered by libcurl.
The project is in its early infancy. I think it would be interesting to try it out and I’ve mentioned the idea to a few people that have shown interest. I really can’t make this happen all on my own anyway so while I’ve created a first embryo, it will take some time before it gets truly useful. Help from others would be greatly appreciated of course.
Using this API, a version of the above example that instead reads data from a HTTPS site instead of a local file could look like:
FCURL *file;
file = fcurl_open("https://daniel.haxx.se/",
"r");
if(file) {
char buffer [256];
while(1) {
size_t rc = fcurl_read(buffer,
sizeof(buffer), 1,
file);
if(rc > 0)
fwrite(buffer, rc, 1, stdout);
else
break;
}
fcurl_close(file);
}
And it could even actually also read a local file using the file:// sheme.
Drop-in replacement
The idea here is to make the alternative functions have new names but as far as possible accept the same input arguments, return the same return codes and so on.
If we do it right, you could possibly even convert an existing program with just a set of #defines at the top without even having to change the code!
Something like this:
#define FILE FCURL #define fopen(x,y) fcurl_open(x, y) #define fclose(x) fcurl_close(x)
I think it is worth considering a way to provide an official macro set like that for those who’d like to switch easily (?) and quickly.
Fun things to consider
1. for non-scheme input, use normal fopen?
An interesting take is probably to make fcurl_open() treat input specified without a “scheme://” to be a local file, and then passed to fopen() instead under the hood. That would then enable even more code to switch to fcurl since all the existing use cases with local file names would just continue to work.
2. LD_PRELOAD
An interesting area of deeper research around this could be to provide a way to LD_PRELOAD replacements for the functions so that not even any source code would need be changed and already built existing binaries could be given this functionality.
3. fopencookie
There’s also the GNU libc’s fopencookie concept to figure out if that is something for fcurl to support/use. BSD and OS X have something similar called funopen.
4. merge in official libcurl
If this turns out useful, appreciated and good. We could consider moving the API in under the curl project’s umbrella and possibly eventually even making it part of the actual libcurl. But hey, we’re far away from that and I’m not saying that is even the best idea…
Your input is valuable
Please file issues or pull-requests. Let’s see where we can take this!



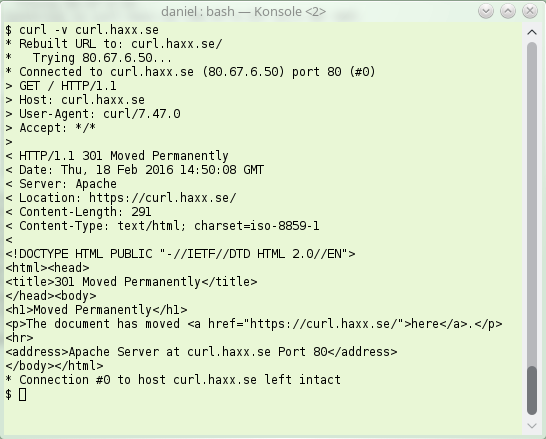
 erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.
erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.