

Disclaimer: I work for wolfSSL but I don’t speak for wolfSSL. I state my own opinions and I try to be as honest and transparent as possible. As always.
QUIC API
Back in the summer of 2020 I blogged about QUIC support coming in wolfSSL. That work never actually took off, primarily I believe because the team kept busy with other projects and tasks that had more customer focus and interest and yeah, there was not really any noticeable customer demand for QUIC with wolfSSL.
Time passed.
On July 21 2022, Stefan Eissing submitted his work on introducing a QUIC API and after reviews and updates, it was merged into the wolfSSL master branch on August 9th.
The QUIC API is planned to appear “for real” in a coming wolfSSL release version. Until then, we can play with what is available in git.
Let me be clear here: the good people at wolfSSL has not decided to write a full QUIC implementation, because that would be insane when so many good alternatives are already being worked on. This is just a set of new functions to allow wolfSSL to be used as TLS component when a QUIC stack is created.
Having QUIC support in wolfSSL is just one (but important) step along the way as it makes it possible to use wolfSSL to build a QUIC implementation but there are some more steps needed to turn this baby into full HTTP/3.
ngtcp2
Luckily, ngtcp2 exists and it is an established QUIC implementation that was written to be TLS agnostic from the beginning. This “only” needs adaptions provided to make sure it can be built and used with wolSSL as the TLS provider.
Stefan brought wolfSSL support to ngtcp2 in this PR. Merged on August 13th.
nghttp3
nghttp3 is the HTTP/3 library that uses ngtcp2 for QUIC, so once ngtcp2 supports wolfSSL we can use nghttp3 to do HTTP/3.
curl
curl can (as one of the available options) get built to use nghttp3 for HTTP/3, and if we just make sure we use an underlying ngtcp2 built to use a wolfSSL version with QUIC support, we can now do proper curl HTTP/3 transfers powered by wolfSSL.
Stefan made it possible to build curl with the wolfSSL+ngtcp2 combo in this PR. Merged on August 15th.
Available HTTP/3 components
With this new ecosystem addition, the chart of HTTP/3 components for curl did not get any easier to parse!
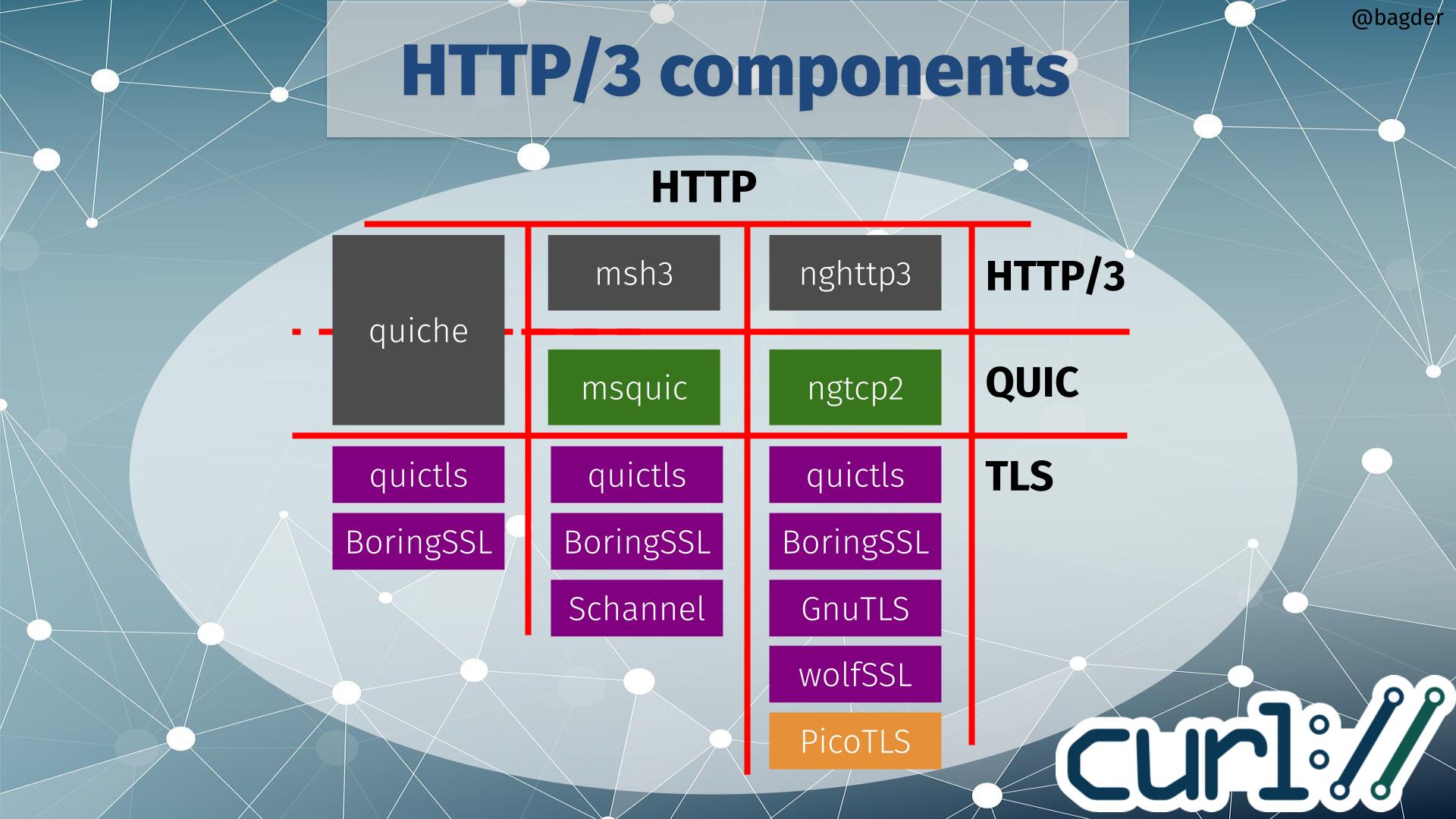
If you start by selecting which HTTP/3 library (or maybe I should call it HTTP/3 vertical) to use when building, there are three available options to go with: quiche, msh3 or nghttp3. Depending on that choice, the QUIC library is given. quiche does QUIC as well, but the two other HTTP/3 libraries use dedicated QUIC libraries (msquic and ngtcp2 respectively).
Depending on which QUIC solution you use, there is a limited selection of TLS libraries to use. The image above shows TLS libraries that curl also supports for other protocols, meaning that if you pick one of those you can still use that curl build to for example do HTTPS for HTTP version 1 or 2.
TLS options
If you instead rather pick TLS library first, only quictls and BoringSSL are supported by all QUIC libraries (quictls is an OpenSSL fork with a BoringSSL-like QUIC API patched in). If you rather build curl to use Schannel (that’s the native Windows TLS API), GnuTLS or wolfSSL you have also indirectly chosen which QUIC and HTTP/3 libraries to use.
Picotls
ngtcp2 supports Picotls shown in orange in the image above because that is a TLS 1.3-only library that is not supported for other TLS operations within curl. If you build curl and opt to go with a ngtcp2 build using Picotls for QUIC, you would need to have use an second TLS library for other TLS-using protocols. This is possible, but is rarely what users prefer.
No OpenSSL option
It should probably be especially highlighted that the plain vanilla OpenSSL is not an available option. Primarily because they decided that the already created API was not good enough for them so they will instead work on implementing their own QUIC library to be released at some point in the future. That also implies that if we want to build curl to do HTTP/3 with OpenSSL in the future, we probably need to add support for a forth QUIC library – and someone would also have to write a HTTP/3 library to use OpenSSL for QUIC.
Why wolfSSL adding QUIC is good for HTTP/3
People in general want to build applications and infrastructure using released, official and supported libraries and the sad truth is that there is a clear shortage in such TLS libraries with QUIC support.
In your typical current Linux distribution, quictls and BoringSSL are usually not viable options. The first since it is an OpenSSL fork not many even ship as a package and the second because it is done by Google for Google and they don’t do releases and generally care little for outside-Google users.
For the situations where those two TLS options are out of the game, the image above shows you the grim reality: your HTTP/3 options are limited. On Windows you can go with msh3 since it can use Schannel there, but on non-Windows you can only use ngtcp2/nghttp3 and before this wolfSSL support the only TLS option was GnuTLS.
For many embedded solutions, or even FIPS requirements, wolfSSL is now the only viable option for doing HTTP/3 with curl.













{kind=link}