First: performance is tricky and bechmarking even more so. I will talk some numbers in this post but of course they are what I have measured for my specific tests on my machine. Your numbers for your test cases will be different.
Over the last six months or so, curl has undergone a number of refactors and architectural cleanups. The primary motivations for this have been to improve the HTTP/3 support and to offer HTTP/2 over proxy, but also to generally improve the code, its maintainability and its readability.
A main change is the connection filters I already blogged about, but while working on this a lot of other optimizations and “quirk removals” have been performed. Most of this work done by Stefan Eissing.
So how do all these changes reflect on raw transfer metrics?
Parallelism with TLS
This test case uses a single TCP connection and makes 50 parallel transfers, each being 100 megabytes. The transfer uses HTTP/2 and TLS to a server running on the same host. All done in a single thread in the client.
As a baseline version, I selected curl 7.86.0, which was released in October 2022. The last curl release we shipped before Stefan’s refactor work started. Should work as a suitable before/after comparison.
For this test I built curl and made it use OpenSSL 3.0.8 for TLS and nghttp2 1.52.0 for HTTP/2. The server side is apache2 2.4.57-2, a plain standard installation in my Debian unstable.
python3 tests/http/scorecard.py --httpd h2
On my fairly fast machine, curl on current master completes this test at 2450 MB/sec.
Running the exact same parallel test, built with the same OpenSSL version (and cipher config) and the same nghttp2 version, 7.86.0 transfers those 50 streams at 1040 MB/sec. A 2.36 times speedup!
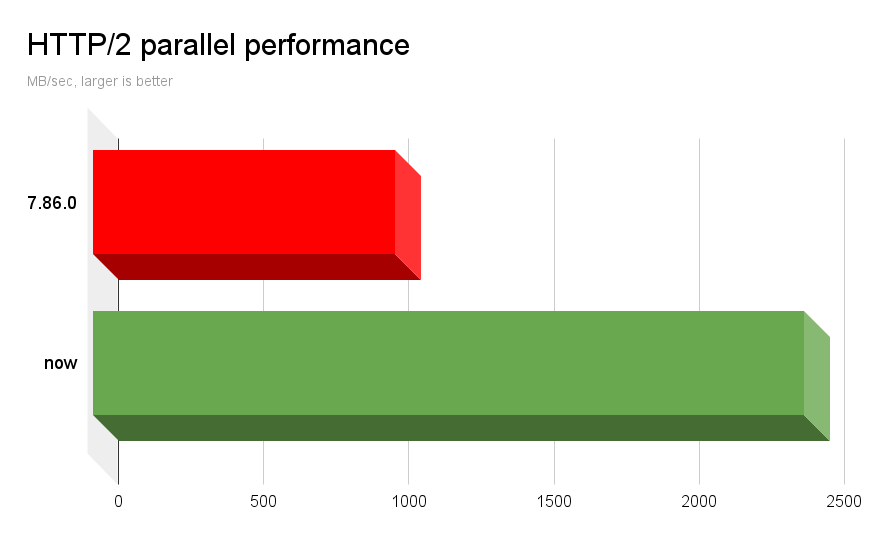
We still have further ideas on how we can streamline the receiving of data on multiplexed transfers. Future versions might be able to squeeze out even more.
Raw unencrypted HTTP/1
This test simply uses the libcurl multi API to do 5 parallel HTTP/1 transfers – in the same thread. They will then use one connection each and again download from the local apache2 installation. Each file is 100GB so it transfers 500GB and measures how fast it can complete the entire operation.
Running this test program linking with curl 7.86.0 reaches 11320 MB/sec on the same host as before.
Running the exact same program, just pointing out to my 8.1.0-DEV library, the program reports a rather amazing 18104 MB/sec. An 1.6 times improvement.
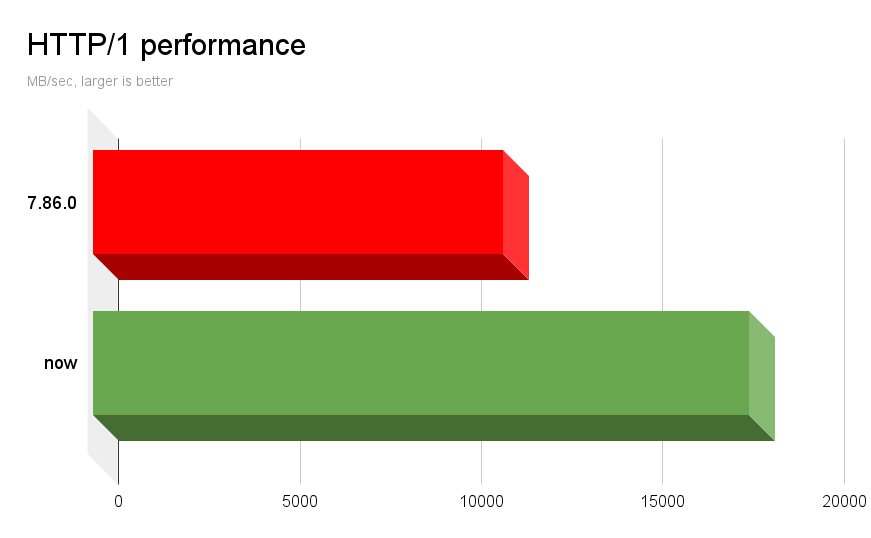
This difference actually surprised us, because we knew we had some leeway in the HTTP/2 department to “clean up” but I was not aware that we had this much margin to further enhance plain HTTP/1 transfers. We are also not entirely sure what change that made this significant bump possible.
It should probably also be noted that this big gain is in particular when doing them in parallel. If I do a single file transfer with the same program, current libcurl does 3900 MB/sec vs the old at 3700 MB/sec. Clearly the bigger enhancements lie in doing multiple transfers and internal transfer-switching.
Does it matter?
I believe it does. By doing transfers faster, we are more effective and therefor libcurl uses less energy for the same thing than previously. In a world with 20+ billion libcurl installations, every little performance tweak has the opportunity to make a huge dent at scale.
If there are 100 million internet transfers done with curl every day, and we make each transfer take 0.1 second less we save 10 million CPU seconds. That equals 115 days of CPU time saved.
The competition
I have not tried to find out how competitors and alternative Internet transfers libraries perform for the same kind of work loads. Primarily because I don’t think it matters too much, but also because doing fair performance comparisons is really hard and no matter how hard I would try I would be severely biased anyway. I leave that exercise to someone else.