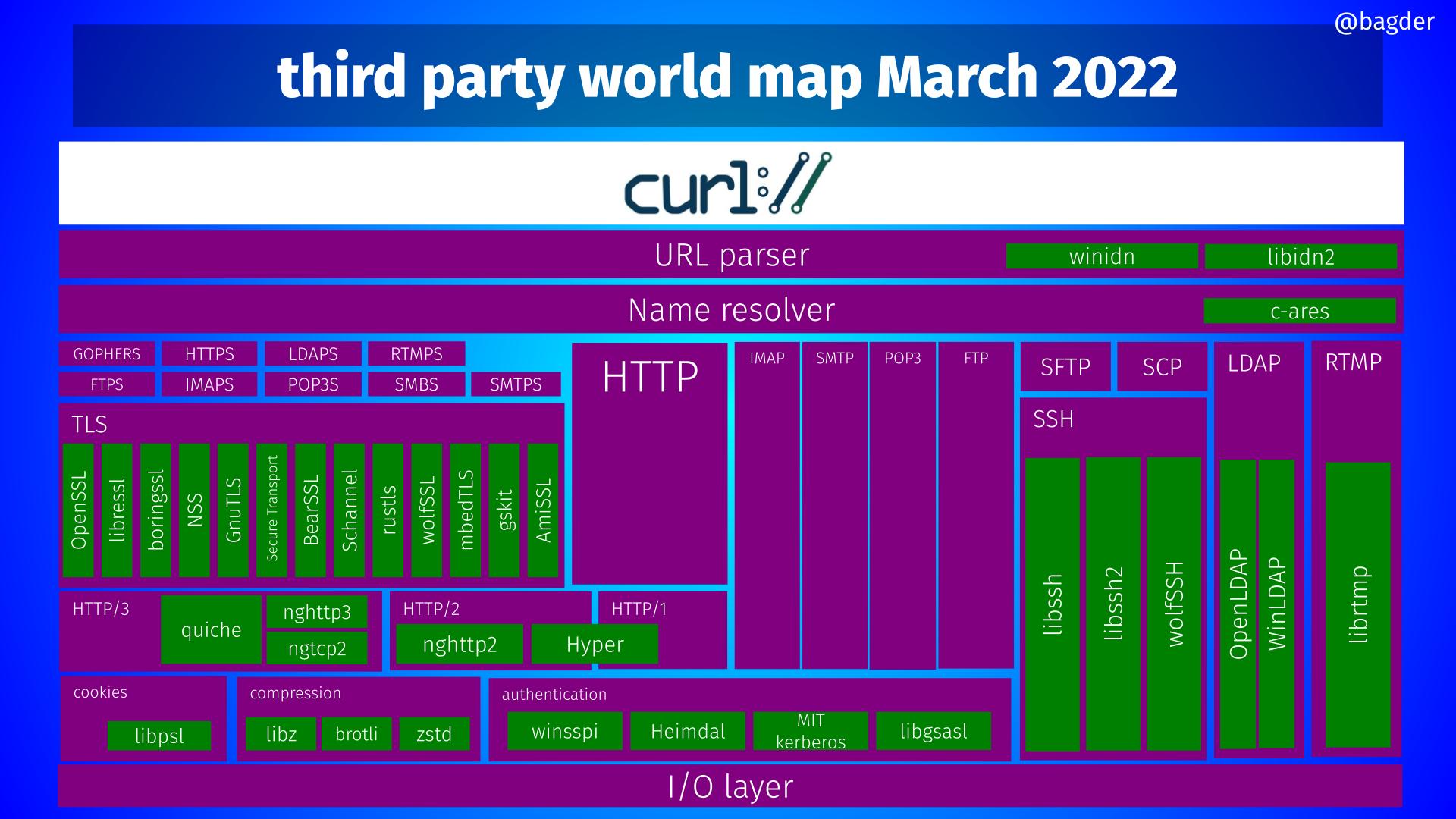
One of the toughest jobs I have, is to assess if a reported security problem is indeed an actual security vulnerability or “just” a bug. Let me take you through a recent case to give you an insight…
Some background
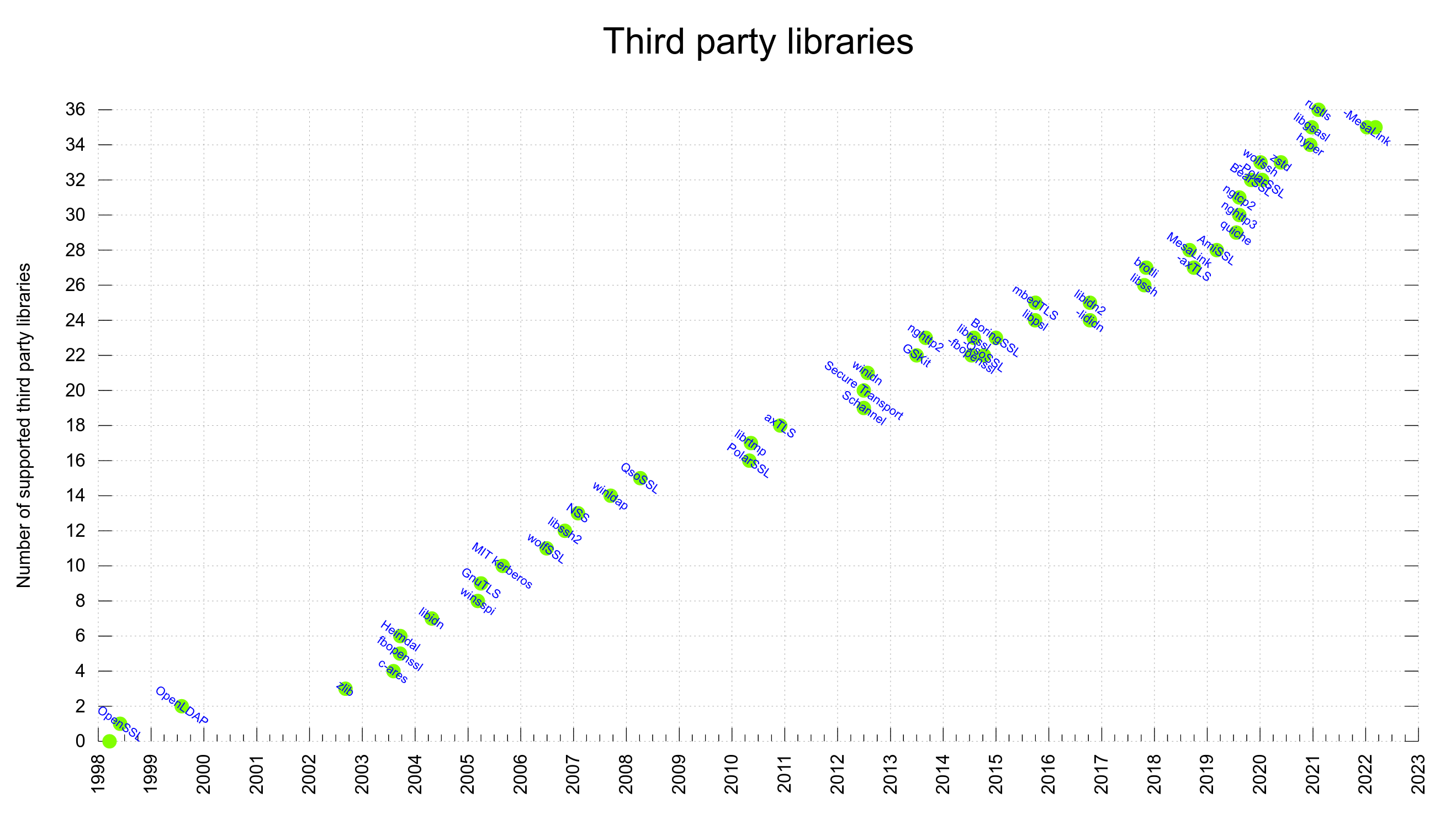
curl is 24 years old and so far in our history we have registered 111 security vulnerabilities in curl. I’ve sided with the “security vulnerability” side in reported issues 111 times. I’ve taken the opposite stance many more times.
Over the last two years, we have received 129 reports about suspected security problems and less than 15% of them (17) were eventually deemed actual security vulnerabilities. In the other 112 cases, we ended up concluding that the report was not pointing out a curl security problem. In many of those 112 cases, it was far from easy to end up with that decision and in several instances the reporter disagreed with us. (But sure, in the majority of the cases we could fairly quickly conclude that the reports were completely bonkers.)
The reporter’s view
Many times, the reporter that reports a security bug over on Hackerone has spent a significant amount of time and effort to find it, research it, reproduce it and report it. The reporter thinks it is a security problem and there’s a promised not totally insignificant monetary reward for such problems. Not to mention that a found and reported vulnerability in curl might count as something of a feat and a “feather in the hat” for a security researcher. The reporter has an investment in this work and a strong desire to have their reported issue classified as a security vulnerability.
The project’s view
If the reported problem is a security problem then we must consider it as that and immediately work on fixing the issue to reduce the risk of users getting hurt, and to inform all users about the risk and ask them to upgrade or otherwise mitigate and take precautions against the risks.
Most reported security issues are not immediately obvious. At least not in my eyes. I usually need to object, discuss, question and massage the data for a while in order to land on how we should best view the issue. I’m a skeptic by nature and I need to be convinced before I accept it.
Labeling something a “security vulnerability” if it indeed is not, is rather hurting users and the entire community rather than helping it. We must not cry wolf for a problem that cannot hurt users or that in practical terms is impossible to occur. Or maybe it is a problem that users are already expected to deal with. Or a result of an explicit or implicit application choice rather than a mistake done by us.
But we must not ignore actual security problems!
This latest MQTT problem
On March 24, 2022 we got a new report filed over on hackerone with the title Denial of Service vulnerability in curl when parsing MQTT server response.
Here’s (roughly) what the issue is about:
- A bug in current libcurl makes it misbehave under certain conditions. When the MQTT connection gets closed mid message, libcurl refuses to acknowledge that and thinks the connection is still alive. Easily triggered by a malicious server.
- libcurl considers the connection readable non-stop
- Reading from the connection brings no more data
- Busy-looping in the event-loop. Goto 2
The loop stops only once it reaches the set timeout, the progress callback can stop it and the speed-limit options will stop it if the right conditions are met.
By default, none of those options are set for a transfer and therefore, by default this makes an endless busy-loop.
At the same time…
A transfer can always stall and take a very long time to complete. A server can basically always just stop delivering more data, making the transfer take an infinite amount of time to complete. Applications that have not set any options to stop such a transfer risk doing a transfer that never ends. An endless transfer.
Also: if libcurl makes a transfer over a really fast network, such as localhost or using a super fast local network, then it might also reach the same level of busy-loop due to never having to wait for data. Albeit for a limited amount of time – until the transfer is complete. This busy-loop is highly unlikely to actually starve out any important threads in a system.
Yes, a closed connection is a much “cheaper” attack from server’s point of view than maintaining a long-living connection, but the cost of the attack is not a factor here.
Where in this grey area do we land?
This is difficult one.
I can see the point of the reporter, but I can also see how this flaw will basically not hurt any existing curl user. Where is our responsibility here?
I ended up concluding that this issue not a security vulnerability. The reporter disagreed.
It is a terribly annoying bug for sure. But the only applications that are seriously affected by it, are the ones that already allow an endless transfer.
The bug-fix was instead submitted as a normal pull-request: PR 8644, targeted to be fixed and included in the pending curl 7.83.0 release.
We publicize the reports after the fact
We make all (non-rubbish) previously reported hackerone issues public, whether they ended up being a vulnerability or not. To give everyone involved time to object or redact sensitive details, the publication date is usually within a month after the issue was closed.
By making the reports public, we allow everyone interested enough the ability and chance to check out and follow past discussions and deliberations for going the directions we did. The idea is primarily to be completely open about the reported issues and how we classify them, to show that we are not hiding anything and it also provides a chance for us to get more feedback from the surrounding and from security people who might disagree with previous analyses.
Security is hard.