TLS 1.3 has been in development for quite some time by now, and a lot of TLS libraries already support it to some extent. At varying draft levels.
curl and libcurl has supported an explicit option to select TLS 1.3 since curl 7.52.0 (December 2016) and assuming you build curl to use a TLS library with support, you’ve been able to use TLS 1.3 with curl since at least then. The support has gradually been expanded to cover more and more libraries since then.
Today, curl and libcurl support speaking TLS 1.3 if you build it to use one of these fine TLS libraries of a recent enough version:
OpenSSL
BoringSSL
libressl
NSS
WolfSSL
Secure Transport (on iOS 11 or later, and macOS 10.13 or later)
Do you remember this exact day, twenty years ago? March 20, 1998. What exactly happened that day? I’ll tell you what I did then.
First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.
I was 27 years old and I worked full-time as a software engineer, mostly with embedded systems. I had already been developing software as a profession for several years then. At this moment in time I was involved as a consultant in a (rather boring) project for Ericsson Telecom ETX, in Nacka Strand in the south eastern general Stockholm area.
At some point during that Friday (I don’t remember the details, but presumably it happened during the late evening), I packaged up the source code of the URL transfer tool we were working on and uploaded it to my personal web site to share it with the world. It was the first release ever of the project under the new name: curl. The tool was already supporting HTTP, FTP and GOPHER – including uploads for the two first protocols.
It would take more than a year after this day until we started hosting the curl project on its own dedicated web site. curl.haxx.nu went live in August 1999, and it was changed again to curl.haxx.se in June the following year, a URL and name we’ve kept since.
(this is the first curl logo we used, made in 1998 by Henrik Hellerstedt)
In my flat in Solna (just north of Stockholm, Sweden) I already then spent a lot of spare time, mostly late nights, in front of my computer. Back then, an Intel Pentium 120Mhz based desktop PC with a huge 19″ Nokia CRT monitor, on which I dialed up to my work’s modem pool to access the Internet and to log in to the Unix machines there on which I did a lot of the early curl development. On SunOS, Solaris and Linux.
In Stockholm, that Friday started out with sub-zero degrees Celsius but the temperature climbed up to a few positive degrees during the day and there was no snow on the ground. Pretty standard March weather in Stockholm. This is usually a period when the light is slowly coming back (winters are really dark here) but the temperatures remind us that spring still isn’t quite here.
curl 4.0 was just a little more than 2000 lines of C code. It featured 23 command line options. curl 4.0 introduced support for the FTP PORT command and now it could do ftp uploads that append to the remote file. The version number was bumped up from the 3.12 which was the last version number used by the tool under the old name, urlget.
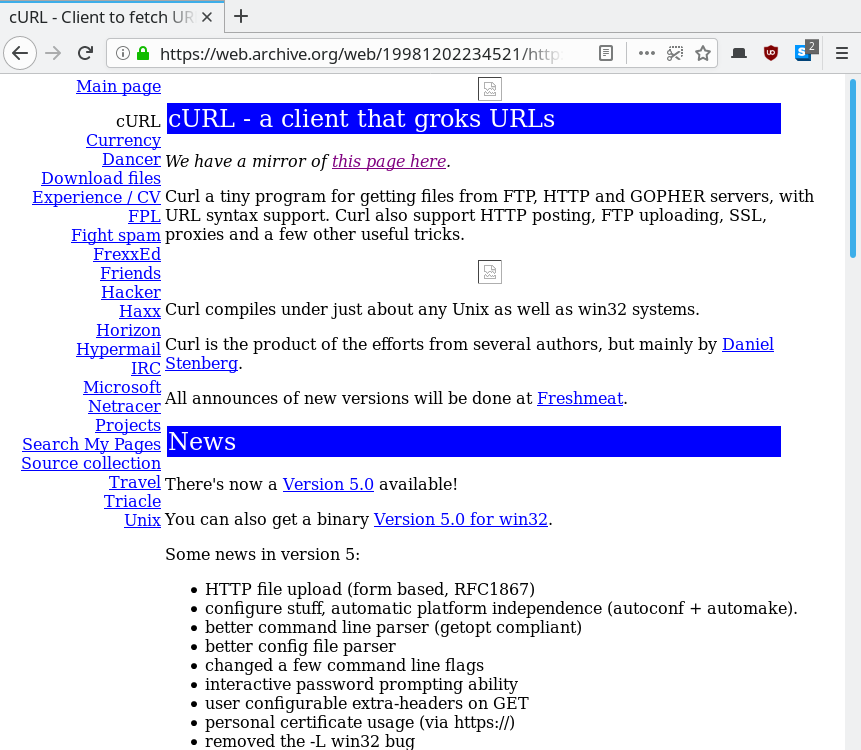
This is what the web site looked like in December 1998, the oldest capture I could find. Extracted from archive.org so unfortunately two graphical elements are missing!
It was far from an immediate success. An old note mentions how curl 4.8 (released the summer of 1998) was downloaded more than 300 times from the site. In August 1999, we counted 1300 weekly visits on the web site. It took time to get people to discover curl and make it into the tool users wanted. By September 1999 curl had already grown to 15K lines of code
In August 2000 we shipped the first version of libcurl: all the networking transfer powers of curl in a library, ready to be used by your applications. PHP was one of the absolutely first users of libcurl and that certainly helped to drive the early use.
A year later, in August 2001, when Apple started shipping curl by default in Mac OS X 10.1 curl was already widely available in Linux and BSD package collections.
By June 2002, we counted 13000 weekly visits on the site and we had grown to 35K lines of code. And it would not stop there…
Twenty years is both nothing at all and at the same time what feels like an eternity. Just three weeks before curl 4.0 shipped, Mozilla was founded. Google wasn’t founded until six months after. This was long before Facebook or Twitter had even been considered. Certainly a different era. Even the term open source was coined just a month prior to this curl release.
Growth factors over 20 years in the project:
Supported protocols: 7.67x
Command line options: 9x
Lines of code: 75x
Contributors: 100x
Weekly web site visitors: 1,400x
End users using (something that runs) the code: 4,000,000x Stickers with the curl logo: infinity
Twenty years since the first ever curl release. Of course, it took time to make that first release too so the work is older. curl is the third name or incarnation of the project that I first got involved with already in late 1996…
That’s the thought that ran through my head when I read the email I had just received.
GAAAAAAAAAAAAH
You know the feeling when the realization hits you that you did something really stupid? And you did it hours ago and people already noticed so its too late to pretend it didn’t happen or try to cover it up and whistle innocently. Nope, none of those options were available anymore. The truth was out there.
I had messed up royally.
What triggered this sudden journey of emotions and sharp sense of pain in my soul, was an email I received at 10:18, Friday March 9 2018. The encrypted email pointed out to me in clear terms that there was information available publicly on the curl web site about the security vulnerabilities that we intended to announce in association with the next curl release, on March 21. (The person who emailed me is a member of a group that was informed by me about these issues ahead of time.)
In the curl project, we never reveal nor show any information about known security flaws until we ship fixes for them and publish their corresponding security advisories that explain the flaws, the risks, the fixes and work-arounds in detail. This of course in the name of keeping users safe. We don’t want bad guys to learn about problems and flaws until we also offer fixes for them. That is, unless you screw up like me.
It took me a few minutes until I paused my work I was doing at the moment and actually read the email, but once I did I acted immediately and at 10:24 I had reverted the change on the web site and purged the URL from the CDN so the information was no longer publicly visible there.
The entire curl web site is however kept in a public git repository, so while the sensitive information was no longer immediately notable on the site, it was still out of the bag and there was just no taking it back. Not to mention that we don’t know how many people that already updated their git clones etc.
I pushed the particular file containing the “extra information” to the web site’s git repository at 01:26 CET the same early morning and since the web site updates itself in a cronjob every 20 minutes we know the information became available just after 01:40. At which time I had already gone to bed.
The sensitive information was displayed on the site for 8 hours and 44 minutes. The security page table showed these lines at the top:
#
Vulnerability
Date
First
Last
CVE
CWE
78
RTSP RTP buffer over-read
February 20, 2018
7.20.0
7.58.0
CVE-2018-1000122
CWE-126: Buffer Over-read
77
LDAP NULL pointer dereference
March 06, 2018
7.21.0
7.58.0
CVE-2018-1000121
CWE-476: NULL Pointer Dereference
76
FTP path trickery leads to NIL byte out of bounds write
March 21, 2018
7.12.3
7.58.0
CVE-2018-1000120
CWE-122: Heap-based Buffer Overflow
I only revealed the names of the flaws and their corresponding CWE (Common Weakness Enumeration) numbers, the full advisories were thankfully not exposed, the links to them were broken. (Oh, and the date column shows the dates we got the reports, not the date of the fixed release which is the intention.) We still fear that the names alone plus the CWE descriptions might be enough for intelligent attackers to figure out the rest.
As a direct result of me having revealed information about these three security vulnerabilities, we decided to change the release date of the pending release curl 7.59.0 to happen one week sooner than previously planned. To reduce the time bad actors would be able to abuse this information for malicious purposes.
How exactly did it happen?
When approaching a release day, I always create local git branches called next-release in both the source and the web site git repositories. In the web site’s next-release branch I add the security advisories we’re working on and I add/update meta-data about these vulnerabilities etc. I prepare things in that branch that should go public on the release moment.
We’ve added CWE numbers to our vulnerabilities for the first time (we are now required to provide them when we ask for CVEs). Figuring out these numbers for the new issues made me think that I should also go back and add relevant CWE numbers to our old vulnerabilities as well and I started to go back to old issues and one by one dig up which numbers to use.
After having worked on that for a while, for some of the issues it is really tricky to figure out which CWE to use, I realized the time was rather late.
– I better get to bed and get some sleep so that I can get some work done tomorrow as well.
Then I realized I had been editing the old advisory documents while still being in the checked out next-release branch. Oops, that was a mistake. I thus wanted to check out the master branch again to push the update from there. git then pointed out that the vuln.pm file couldn’t get moved over because of reasons. (I forget the exact message but it it happened because I had already committed changes to the file in the new branch that weren’t present in the master branch.)
So, as I wanted to get to bed and not fight my tools, I saved the current (edited) file in a different name, checked out the old file version from git again, changed branch and moved the renamed file back to vuln.pm again (without a single thought that this file now contained three lines too many that should only be present in the next-release branch), committed all the edited files and pushed them all to the remote git repository… boom.
You’d think I would…
know how to use git correctly
know how to push what to public repos
not try to do things like this at 01:26 in the morning
(*) = changes are things that don’t fix existing functionality but actually add something new to curl/libcurl. New features mostly.
The new things time probably won’t be considered as earth shattering but still a bunch of useful stuff:
–proxy-pinnedpubkey
The ability to specified a public key pinning has been around for a while for regular servers, and libcurl has had the ability to pin proxies’ keys as well. This change makes sure that users of the command line tool also gets that ability. Make sure your HTTPS proxy isn’t MITMed!
CURLOPT_TIMEVALUE_LARGE
Part of our effort to cleanup our use of ‘long’ variables internally to make sure we don’t have year-2038 problems, this new option was added.
CURLOPT_RESOLVE
This popular libcurl option that allows applications to populate curl’s DNS cache with custom IP addresses for host names were improved and now you can add multiple addresses for host names. This allows transfers using this to even more work like as if it used normal name resolves.
CURLOPT_HAPPY_EYEBALLS_TIMEOUT_MS
As a true HTTP swiss-army knife tool and library, you can toggle and tweak almost all aspects, timers and options that are used. This libcurl option has a new corresponding curl command line option, and allows the user to set the timeout time for how long after the initial (IPv6) connect call is done until the second (IPv4) connect is invoked in the happy eyeballs connect procedure. The default is 200 milliseconds.
Bug fixes!
As usual we fixed things all over. Big and small. Some of the ones that I think stuck out a little were the fix for building with OpenSSL 0.9.7 (because you’d think that portion of users should be extinct by now) and the fix to make configure correctly detect OpenSSL 1.1.1 (there are beta releases out there).
Some application authors will appreciate that libcurl now for the most part detects if it gets called from within one of its own callbacks and returns an error about it. This is mostly to save these users from themselves as doing this would already previously risk damaging things. There are some functions that are still allowed to get called from within callbacks.
Subject: Warumfrage
Schönen guten Tag
Ich habe auf meinem Navi aus meinem Auto einen Riesentext wo unter anderem Ihre Mailadresse zu sehen ist?
Können Sie mich schlau machen was es damit auf sich hat ?
… which translated into English says:
I have a huge text on my sat nav in my car where, among other things, your email address can be seen?
Can you tell me what this is all about?
I replied (in English) to the question, explained how I’m the main author of curl and how his navigation system is probably using this. I then asked what product or car he saw my email in and if he could send me a picture of my email being there.
He responded quickly and his very brief answer only says it is a Toyota Verso from 2015. So I put an image of such a car on the top of this post.
tldr: we’ve made curl handle dates beyond 2038 better on systems with 32 bit longs.
libcurl is very portable and is built and used on virtually all current widely used operating systems that run on 32bit or larger architectures (and on a fair amount of not so widely used ones as well).
This offers some challenges. Keeping the code stellar and working on as many platforms as possible at the same time is hard work.
How long is a long?
The C variable type “long” has existed since the dawn of time and used to be 32 bit big already back in the days most systems were 32 bits. With the introduction of 64 bit systems in the 1990s, something went wrong and when most operating systems went with 64 bit longs, some took the odd route and stuck with a 32 bit long… The windows world even chose to not support “long long” for 64 bit types but instead it insists on calling them “__int64”!
(Thankfully, ints have at least remained 32 bit!)
Two less clever API decisions
Back in the days when humans still lived in caves, we decided for the libcurl API to use ‘long’ for a whole range of function arguments. In hindsight, that was naive and not too bright. (I say “we” to make it less obvious that it of course is mostly me who’s to blame for this.)
Another less clever design idea was to use vararg functions to set (all) options. This is convenient in the way we have one function to set a huge amount of different option, but it is also quirky and error-prone because when you pass on a numeric expression in C it typically gets sent as an ‘int’ unless you tell it otherwise. So on systems with differently sized ints vs longs, it is destined to cause some mistakes that, thanks to use of varargs, the compiler can’t really help us detect! (We actually have a gcc-only hack that provides type-checking even for the varargs functions, but it is not portable.)
libcurl has both an option to pass time to libcurl using a long (CURLOPT_TIMEVALUE) and an option to extract a time from libcurl using a long (CURLINFO_FILETIME).
We stick to using our “not too bright” API for stability and compatibility. We deem it to be even more work and trouble for us and our users to change to another API rather than to work and live with the existing downsides.
Time may exist after 2038
There’s also this movement to transition the time_t variable type from 32 to 64 bit. time_t of course being the preferred type for C and C++ programs to store timestamps in. It is the number of seconds since January 1st, 1970. Sometimes called the unix epoch. A signed 32 bit time_t can be used to store timestamps with second accuracy from roughly 1903 to 2038. As more and more things will start to refer to dates after 2038, this is of course becoming a problem. We need to move to 64 bit time_t all over.
We’re now less than 20 years away from the signed 32bit tip-over point: 03:14:07 UTC, 19 January 2038.
To complicate matters even more, there are odd systems out there with unsigned time_t variables. Such systems then cannot easily refer to dates before 1970, but can instead hold dates up to the year 2106 even with just 32 bits. Oh and there are some systems with 64 bit long that feature a 32 bit time_t, and 32 bit systems with 64 bit time_t!
Most modern systems today have 64 bit time_t – including win64, and 64 bit time_t can handle dates up to about year 292,471,210,647.
int – long – time_t
We cannot move data between ints and longs in the code and assume it doesn’t overflow
We can’t move data losslessly between ints and time_t
We must not move data between long and time_t
Recently we’ve been working on making sure we live up to these three rules in libcurl. One could say it was about time! (pun intended)
In particular number (3) has required us to add new entry points to the API so that even 32 bit long systems can set/read 64 bit time. Starting in libcurl 7.59.0, applications can pass 64 bit times to libcurl with CURLOPT_TIMEVALUE_LARGE and extract 64 bit times with CURLINFO_FILETIME_T. For compatibility reasons, the old versions will of course be kept around but newer applications should really consider the new options.
We also recently did an overhaul of our time and date parser (externally accessible as curl_getdate() ) which we learned erroneously used a ‘long’ in the calculation which made it not work proper beyond 2038 on systems with 32 bit longs. This fix will also ship in 7.59.0 (planned release date: March 21, 2018).
If you find anything in curl that doesn’t deal with times after 2038 correctly, please file a bug!
The other day we noticed some curl test case failures, that only happened on macos and not on Linux. Curious!
The failures were detected in our unit test 1307, when testing a particular internal pattern matching function (Curl_fnmatch). Both targets run almost identical code but somehow they ended up with different results! Test cases acting differently on different platforms isn’t an extremely rare situation, but in this case it is just a pattern matching function and there’s really nothing timing dependent or anything that I thought could explain different behaviors. It piqued my interest, so I dug in.
The isalnum() return value
Eventually I figured out that the libc function isalnum(), when it got the 8 input value hexadecimal c3 (decimal 195), would return true on the macos machine and false on the box running Linux with glibc!
int value = isalnum(0xc3);
Setting LANG=C before running the test on macos made its isalnum() return false. The input became c3 because the test program has an UTF-8 encoded character in it and the function works on bytes, not “characters”.
Or in the words of the opengroup.org documentation:
The isalnum() function shall test whether c is a character of class alpha or digit in the program’s current locale.
It’s all documented – of course. It was just me not really considering the impact of this.
Avoiding this
I don’t like different behaviors on different platforms given the same input. I don’t like having string functions in curl act differently depending on locale, mostly because curl and libcurl can very well be used with many different locales and I prefer having a stable fixed behavior that we can document and stand by. Also, the libcurl functionality has never been documented to vary due to locale so it would be a surprise (bug!) to users anyway.
We’ve now introduced a private version of isalnum() and the rest of the ctype family of functions for curl. Hopefully this will make the tests more stable now. And make our functions work more similar and independent of locale.
We have just opened up the registration site for curl up 2018, the annual curl developers meeting that this year takes place in Stockholm, Sweden, over the weekend April 14-15. There’s a limited number of seats available, so if you want to join in the fun it might be a good idea to decide early on.
Also, to get into the proper curl up spirit, here’s the curl quiz we ran last year. I hope to run something similar again this year, but of course with a different set of questions.
curl 7.58.0 is the 172nd curl release and it contains, among other things, 82 bug fixes thanks to 54 contributors (22 new). All this done with 131 commits in 56 days.
The bug fix rate is slightly lower than in the last few releases, which I tribute mostly to me having been away on vacation for a month during this release cycle. I retain my position as “committer of the Month” and January 2018 is my 29th consecutive month where I’ve done most commits in the curl source code repository. In total, almost 58% of the commits have been done by me (if we limit the count to all commits done since 2014, I’m at 43%). We now count a total of 545 unique commit authors and 1,685 contributors.
Introducing the pluggable SSH backend, and libssh is now the new alternative SSH backend to libssh2 that has been supported since late 2006. This change alone brought thousands of new lines of code.
Tell configure to use it with –with-libssh and you’re all set!
The libssh backend work was done by Nikos Mavrogiannopoulos, Tomas Mraz, Stanislav Zidek, Robert Kolcun and Andreas Schneider.
Security
Yet again we announce security issues that we’ve found and fixed. Two of them to be exact:
curl features an alternative progress bar. When you invoke it with -# or the longer version –progress-bar, curl will show the transfer progress using a single “bar” on the screen instead of the default meter that shows a lot of data like amount of data, transfer speeds and times.
The alternative progress bar works great when the amount of data to transfer is known since then it can actually know how large part of the transfer that is done etc. If the amount of data is unknown – which is not a super rare situation – the progress bar output instead used to output one ‘#’ per kilobyte of data so that it would still show something. That could then end up filling up the screen and more if you did a large transfer.
Starting in curl 7.58.0 (to be released on January 24, 2018), this latter progress bar layout is modified. If the total size is unknown, it will now instead display a small space ship flying across the line, back and forth – and it will only move as long as there is data being transferred. If it stalls, the little ship stops.
“Over” the space ship there are four nonsensical flying hashes (‘#’) that are simply moving across the line on a sine wave, following each other. They move independently of there being data transferred or not.
It can then end up looking similar to this:
Pointless
There’s no real “meaning” behind this new progress bar output mode. I wanted it to
only use a single line, even in the no-total size known case
somehow indicate when there’s no data flying (ie space ship stops)
make it slightly more interesting to watch than just one # per kilobyte
Since this new bar has just landed and this is the first time we ship a release with it, I wouldn’t be surprised if we end up polishing it further later on.
Can you tell I started out my programming life as a demo programmer on the Commodore 64? 🙂



 First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.
First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.