(I wrote about this topic in my weekly email this week. This is the blog version, somewhat extended.)
Easy to read
Two contributing factors that make code hard to read are function length and function complexity. To keep source code easy to read, understand and debug we should strive towards keeping functions short and simple. Nothing ground-breaking in that conclusion.
I know, it sounds really simple and straight forward but in a living project that goes on for decades, code develops, moves and grows over time. What started out small and simple risk gradually turning into something else.
This of course because there are so many more factors involved that need to be given focus as well. Like security, bugfixes, performance, food on the table and getting more people involved.
Graphs graphs graphs
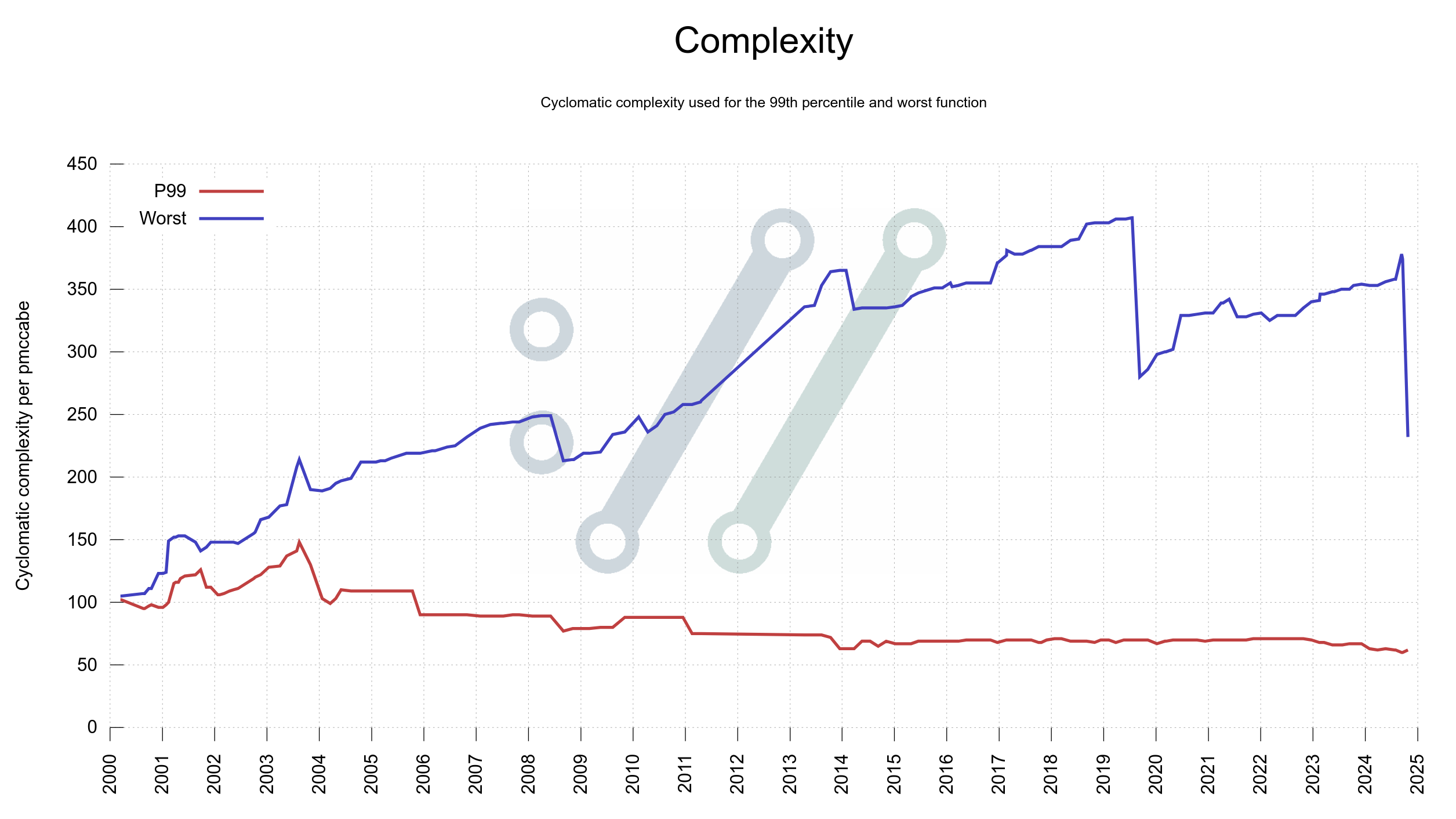
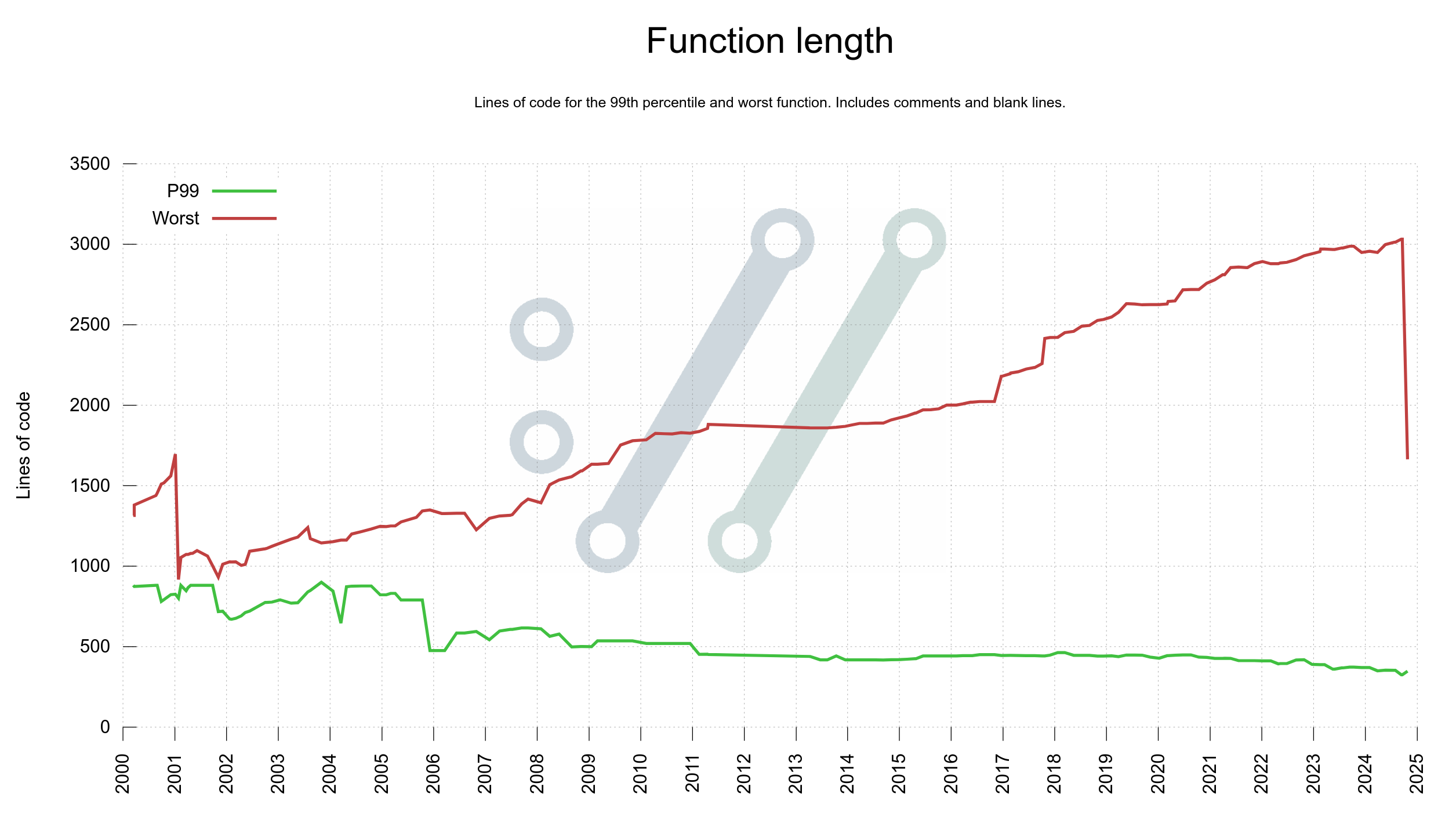
Last week I added two more graphs to the curl dashboard showing function complexity and function length growth in curl code over the decades: one plot for the worst function and one plot for the 99th percentile in each graph. For both graphs, the 99th percentile plots shrink gradually over time but the worst offenders grow. This means that there are a few functions that with attention could improve readability and code maintainability but that in general things are under control.
One of the main points for me with graphing the project from as many angles as possible is to unveil things like this. Areas that might need attention, and then keep a check on these areas going forward. Details like these are otherwise rather subtle and not easily detected when manually browsing around.
It has been said that whatever measurement you use to track engineering progress, that will then become the goal for what engineers work towards. I hope to combat this by measuring (and graphing) as many angles as possible of the curl project. To help push us in the right direction in as many different areas as possible.
Improve
I took it upon myself to improve the situation: to reduce the size of the largest function in the code base and to simplify the most complex one. Incidentally they were different functions: the largest function was the big switch handling curl_easy_setopt options, and the most complex one was the main curl tool function setting up a single transfer.
These two functions had simply just slowly and consistently been growing over time, in size and complexity. No one’s “fault” really and not with any specific plan or intention. The graph helped me decide to act and the pmccabe tool helped me identify them. We can of course argue about the specific method or number that pmccabe presents for complexity, but I think it at least is pretty good at actually identifying the correct functions and the exact particular score it sets is not terribly important.
Both pull-requests became > 2000 modified lines monsters, but they also had immediate and distinct effects on the graphs; which ideally should mean that the code readability is now a little better than before, making the functions easier to improve and work with going forward
Complexity
The single worst function in production code had gotten quite complex. I spent a work day on the case and look at the drop on the right edge of the graph below, made after my fix landed. Most of the job was to properly split the function into several smaller ones that made sense.
The single worst offender at this particular time was the function in the curl tool that sets up a single transfer job.
There are still some pretty complex ones remaining. Room for further improvements no doubt.
Function length
The worst offenders in terms of function size in curl have been of two kinds: state machines with many states and functions handling big switches for options.
In this particular case, this was the big function handling curl_easy_setopt(), and as we have over three hundred options having them all handled in a single function made it very big. The new setup splits that handling up into multiple smaller functions, one for each kind of input.
The largest one is now at over 1,500 lines. Still on the too large side of things but way better than before.
Going forward
Yes, I am a graphaholic and I seem to keep finding new ways to illustrate project status and development using plots on timelines. I am also most likely the biggest consumer of these graphs as I monitor them daily to make sure I have full control of how we are in the project, in every imaginable aspect.
I intend to try to continue simplifying a few more of the functions in the pmccabe toplist.
Let’s see what the graph shows in another three years.
The transition from Ubuntu 22 to 24 for ubuntu-latest on GitHub actions started recently with the associated version bumps of a lot of applications. As expected.
One of the version bumps is for clang: it now uses clang 18 by default. clang 18 introduced some changes that turned out to be relevant for me and other curl developers. Yeah, surely for some others as well.
clang and gcc
In my daily developer life I just typically use gcc for building local stuff – mostly out of old habits. I rebuild and test curl dozens of times every day. In my normal work process I use a couple of different build combinations that enable a lot of third party dependencies and I almost always build curl and libcurl with debug enabled and only statically. It is a debug-friendly setup.
Of course I also have clang installed so that I can try out building with it when I want to, and I have a large set of alternative config setups that I use when I have a particular reason to check or debug such a build.
CI to the rescue
There are literally many millions of build combinations of curl, and we do some of the most important ones automatically for every pull request and commit in the source repository. They help us avoid regressions. Currently we do almost two hundred different jobs.
Two of those CI jobs build curl using clang and enable some sanitizers: address, memory, undefined and signed-integer-overflow and use those builds to run through the test suite to help us verify that everything still looks fine.
Since it gets done in the CI for every change, I don’t have to run it myself locally very often. We have thus been using the default clang version shipped in Ubuntu 22.04 for this for quite some time now.
Undefined behavior sanitizer
When the clang version for the Ubuntu jobs on GitHub was bumped up to version 18, the undefined behavior sanitizer job suddenly found plenty of new problems in curl.
In code that had been running without problems for a long time (decades in some cases) on countless systems and on almost every imaginable architecture. Unexpected.
Picky function prototypes
Here is the reason:
The sanitizer now keeps track of exactly how a function pointer prototype is declared and verifies that the function actually called via that pointer is using an identical prototype.
This is generally probably a good idea and a sound sanity check for most programs but since the checker insists on identical prototypes, I believe it goes beyond what is undefined behavior – I believe some discrepancies are handled just fine. For example a signed vs unsigned pointer or void vs char pointers. I am however not a compiler developer and neither am I an expert in the C language specifications so maybe I am wrong.
Example
A function pointer defined to call a function that returns a void and gets a single char pointer input
char *data = "string"; name = (name_func)target; name(data);
In libcurl we set function pointers (callbacks) via a setopt() style function, which cannot validate the pointer at compile time.
When the code example above is tested with the undefined behavior sanitizer and its -fsanitize=function check (I believe), it complains about the mismatching prototypes between the pointer and the actually called function.
How this became annoying
For the example above, the sanitizer report is most welcome, even if I think it goes beyond what is actually undefined behavior. It helps us clean up the code.
For libcurl, we have a CURL * type returned for a handle from curl_easy_init(). This handle is used as an input argument to multiple functions and it is also used as an input argument to several callbacks an application can tell libcurl to call, etc.
This made us get a more descriptive pointer for the type when we build libcurl. For convenience.
The function pointer is defined internally for libcurl as a struct pointer, but outside in the application land as a void pointer. This works great.
Until this new sanitizer check. Now it complaints loudly because the prototypes for the function called does not match the prototype for the function pointer. The struct vs the void pointers. The sanitizer stores and uses “resolved” typedefs in its checks, not the name of the types visible in code.
The fix
Since we can’t have build breakage in the CI jobs, I fixed this.
We are back to how we did it in the past. With a plain
typedef void CURL;
… even when we build libcurl. To make sure the pointer and the final function have the same prototypes. To hush up the undefined behavior sanitizer.
This is now in master and how the code in the pending curl 8.11.0 release will look.
Disabling the check is not enough
While we could disable this particular check in our CI jobs, that would not suffice since we want everyone to be able to run these tools against curl without any warnings or errors.
We also want application authors in general who use libcurl to be able to similarly run this sanitizer against their tools to not get error reports like this.
Is this a clang issue?
Maybe. I just can’t see how this could happen by mistake, and since it is a feature that has existed for quite a while now already I have not bothered to submit an issue or have any argument or discussion with the clang team. I have simply accepted that this is the way they want to play this and adapt accordingly.
A historic footnote
In 2016 I wanted to change the type universally to just
typedef struct Curl_easy CURL;
… as I thought we could do that without breaking neither API nor ABI. I still believe I was right, but the change still caused an “uproar” among some users who had already built code and done things based on the assumption that it was and would always remain a void pointer. Changing the type thus caused build errors at places to a level that made us retract that change and revert back to the #ifdef version showed above.
And now we had to retract even the #ifdef and thus we are back to the pre 2016 way.
Post-publish update
It has been pointed out to me that the way the C standard is phrased, this tool seems to be correct. More discussions around that can be found in a long OpenSSL issue from last year.
tldr: the curl bug-bounty has been an astounding success so far.
We started the current curl bug-bounty setup in April 2019. We have thus run it for five and a half years give or take.
In the beginning we awarded researchers just a few hundred USD per issue because we did not know where it would go and as we used money from the curl fund (donated money) we wanted to make sure we could afford it.
Since a few years back, the money part of the bug-bounty is sponsored by the Internet Bug Bounty, meaning that the curl project actually earns money for every flaw as we get 20% of the IBB money for each bounty paid.
While the exact award amounts per report vary over time, they are roughly 500 USD for a low severity issue, 2,500 USD for a Medium and almost 5,000 USD for a High severity one.
To this day, we have paid out 84,260 USD to security researchers as rewards for their findings, distributed over 69 separate CVEs. 1,220 USD on average.
Counters
In this period we have received 477 reports, which is about 6 per month on average.
73 of the reports (15.4%) were confirmed and treated as valid security vulnerabilities that ended up CVEs. This also means that we get roughly one valid security report per month on average. Only 3 of these security problems were rated severity High, the rest were Low or Medium. None of them reached the worst level: Critical.
92 of of the reports (19.4%) were confirmed legitimate bugs but not security problems.
311 of the reports (65.3%) were Not Applicable. They were not bugs and not security problems. See below for more on this category.
1 of the reports is still being assessed as I write this.
Tightening the screws
Security is top priority for us but we also continue to develop curl at a high pace. We merge code into the repository at a frequency of more than four bugfixes per day on average over the last couple of years. When we tighten the screws in this project in order to avoid future problems and to mitigate the risks that we add new ones, we need to do it using policies and concepts that still allow us to move fast and be agile.
First response
We have an ambition to always have a first response posted within 24 hours. Over these first 477 reports, we have had a medium response time on under one hour and we have never missed our 24 hour goal. I am personally a little amazed by this feat.
Time to triage
The medium time from filed report until the curl security team has determined and concluded with some confidence that the problem is a security problem is 36 hours.
Assessing
Assessing a (good) report is hard and usually involves a lot of work: reading up on protocols details, reading code, trying different reproducer builds/scripts and bouncing back and forth with the reporters and the security team.
Acknowledging that it is a security problem is only one step. The adjacent one that is at least equally difficult is to then figuring out the severity. How serious is this flaw? A normal pattern is of course that the researcher considers the problem to be several degrees worse than the curl security team does so it can take a great deal of reasoning to reach an agreement. Sometimes we even decree a certain severity against the will of the researcher.
The team
There is a curl security team that works on and with security reports. The awesome people in this group are:
Max Dymond, Dan Fandrich, Daniel Gustafsson, James Fuller, Viktor Szakats, Stefan Eissing and myself.
They are all long-time curl maintainers. Knowledgeable, skilled, trusted.
Report quality
65.3% of the incoming reports are deemed not even a bug.
These reports can be all sorts of different things of course. When promising people money for their reports, there is no surprise that we get a fair share of luck-seekers trying to earn a few bucks the easy route.
Some reporters run scanners against the code, the mail server or the curl website and insist some findings are bounty worthy. The curl bug-bounty does not cover infrastructure, only the products, so they are not covered no matter what.
A surprisingly large amount of the bad reports are on various kinds of “information exposure” on the website – which is often ironic since the entire website already is available in a public git repository and the information exposed is hardly secret.
Reporting scanner results on code without applying your own thinking and confirming that the findings are indeed correct – and actual security problems – is rarely a good idea. That also goes for when asking AIs for finding problems.
Dismissing
Typically, the worse the report is, the quicker it is to dismiss. That is also why having this large share of rubbish is usually not a problem: we normally get rid of them with just a few minutes work spent.
The better crap we get, the worse the problem gets. An AI or a person that writes a long and good-looking report arguing for their sake can take a long time to analyze, asses and eventually debunk.
Since security problems are top priority in the project, getting too much good crap can to some degree cause a denial of service in the project as we need to halt other activities while we take care of the incoming reports.
We run our bug-bounty program on Hackerone, which has a reputation system for reporters. When we close reports as N/A, they get a reputation cut. This works as a mild deterrence for submitting low quality reports. Of course it also sometimes gives the reporter a reason to argue with us and insist we should rather close it as informative which does not come with a reputation penalty.
The good findings
I would claim that it is pretty hard to find a security problem in curl these days, but since we still average in maybe twelve per year recently they certainly still exist.
The valid reports today tend to happen because either a user accidentally did something that made them look, research and unveil something troublesome, or in the more common case: they have put in some real effort into research.
In the latter cases, we see researchers run their own custom fuzzers on parts of the code that our own fuzzers have not exercised as well, we see them check for code patterns that have led to problems before or in other projects and we also see researchers get inspiration by previous reports and fixes to see if perhaps there were gaps left.
The best curl security problem finders today understand the underlying involved protocols, the curl architecture, the source code and they look for inconsistencies between them all, as such might cause security problems.
Bounty hunters
The 69 bug bounty payouts so far have been done to 27 separate individuals. Five reporters have been rewarded for more than two issues each. The true curl security researcher heroes:
Reports
Name
Rewarded
25
Harry Sintonen
29,620 USD
8
Hiroki Kurosawa
9,800 USD
4
Axel Chong
7,680 USD
4
Patrick Monnerat
7,300 USD
3
z2_
4,080 USD
Top-5 curl bounty hunters
We are extremely fortunate to have this skilled set of people tracking down and highlighting our worst mistakes.
Harry of course sticks out in the top with his 25 rewarded curl security reports. More than three times the amount the number two has.
(Before you think the math is wrong: a few reports have been filed that ended up as valid CVEs but for which the reporters have declined getting a monetary reward.)
My advice
I think the curl bug-bounty is an absolute and undisputed success. I believe it is a key part in our mission to keep our users safe and secure.
If you consider kicking off a bug-bounty for your project here’s my little checklist:
Do your software engineering proper. Run all the tools, tests, checks, analyzers, scanners, fuzzers you can and make sure they are at zero reported defects. To avoid a raging herd of reports when you open the gates.
Start out with conservative bounty amounts to get a lay of the land, then raise them as you go.
Own all security problems for your project. Whoever reports them and however they appear, you assess, evaluate, research and fix them. You write and publish the complete and original security advisory.
Make sure you have a team. Even the best maintainers need sleep and occasional vacation days. Security is hard and having good people around to bounce problems with is priceless.
Close/reject crap reports as quickly as possible to prevent them from wasting team time and energy.
Always fix security problems with haste. Never let them linger around.
Transparency. Make as much as possible open and public once the CVEs are out, so that your processes, communications, methods are visible. This builds trust and allows for feedback and iterative improvements of the process.
Future
I think we will continue to receive valid security reports going forward, simply because we keep developing at a high pace and we change and add a lot of source code every year.
The trend in recent years have been more security reports, but the ratio of low/medium vs high/critical has sky-rocketed. The issues reported these days tend to be less sever than they were in the past.
My explanation for this is primarily that we have more people looking harder for problems now than in the past. Due to mitigations and past reports we introduce really bad security problems at a lower frequency than before.
From: Microsoft
Subject: Congratulations on your Microsoft MVP award
You’ve been accepted to the Microsoft MVP program
Daniel Stenberg,
We’re pleased to welcome you to the Microsoft Most Valuable Professionals (MVP) program in recognition of your outstanding contributions to the community in following technical area/s:
C++
It was not a total surprise since I was nominated to this program earlier this year and I actually did the necessary steps of manually filling in tedious forms. The program has lofty words about wanting to recognize efforts like mine, but when filling in the form there is no recognition for Open Source or other of my areas of expertise. Since I had to claim at least two areas to advance in the forms, I claimed to be an expert on “C++” and “web”. Those items were basically the only two available options that weren’t plain Microsoft technologies. I at least know about C++ and web. Obviously the program people did not think I qualified for “web”.
In the form I only listed and referred to my Open Source work to back up my claims. I am of course not at all an expert in C++, but I do know my way around C. I suspect the people over there don’t care about the difference.
My take on this is that they accepted me in the category that was closest to what I primarily work with, and that my protocol work is probably not the “web” they think of.
What good will this do me?
I honestly have no idea and I don’t have any expectations. I don’t think it can do me much harm anyway.
I figure ideally it can get me more contacts and reach to people that has knowledge about things that can help me in my Open Source work – in particular with Windows related queries and problems.
I don’t feel too special or unique as this an award given to thousands of people, and in little Sweden alone there are like a hundred people awarded. But I still feel honored!
The glass trophy/plaque, with my workplace in the background.
Update March 13 2025
Nope, this program was just a flood of Microsoft flogging their own technologies and products. I’m leaving the program again. There was nothing here for me. No Open Source, no protocols, no Internet technologies.
Hi Daniel,
Thank you for your feedback. We regret that it didn't work out as hoped. We will now begin the process of retiring you from the MVP Program.
On Monday this week, I did a talk at the Nordic Software Security Summit conference in Stockholm Sweden. I titled it CVEMITRECVSSNVDCNAOSS WTF with the subtitle “Keeping the world from Burning”.
The talk was well received and I think it added something to the conversation. Almost every other talk during the rest of the conference that I saw referred back to it.
Since the talk was not recorded (no talks were at this event), I intend to do the presentation again – from home. This time live-streamed and recorded.
This happens on:
Monday September 30, 2024 14:00 UTC (16:00 CEST)
The stream happens on Twitch where I as always am curlhacker. Join the chatroom, ask questions, have a good time. There will of course be room for a Q&A.
No registration. No fee. Just show up.
At the conference, I did the presentation in under thirty minutes. This version might go on a few more minutes.
Abstract
The abstract I provided for this talk to the conference says:
Bogus CVEs, know-better organizations, conflicting databases, AI hallucinations, inflated severity scoring, security scanners, Jia Tan. As the lead developer in the curl project, Daniel describes some of the challenges involved and what you need to do to stay on top of security when working in a high profile Open Source project running in some twenty billion instances. The talk will be involving many examples from real life.
Differences
Since this is a second run of a talk I already did and I have no script, it will not be identical. I will also try to polish some minor details that I felt could need some brush-ups.
I decided to bump the minor version number again because there is a new option: --qtrim.
This is the old --trim option made simpler and specialized for query components only. When we added originally --trim, the idea was that it would be similar to --set and --get and be able to trim different components – but over time we have realized that the only component the trimming operation really makes sense for is query.
Hence, now we have the query trim option and the old trim option is deprecated. The old option still works but is not advertised in the --help output.
Manpage
The trurl manpage now features a section describing the different URL components, how they work and some specific options that affect them. With examples.
The manpage has almost doubled in size compared to 0.15.1 and the nroff version is now over 800 lines long. All in the name of making sure every option and feature is understood properly.
Bugfixes
query normalization. When a name/value pair had a blank string on either side of the equals character, trurl messed it up.
user/password/options/fragment normalization. trurl now normalizes all these fields if provided.
lowercase %-encoding. In some instances trurl was not consistently using lowercase hexadecimal in its output.
Tests
I looked for white spots in the test suite: untested options and option combinations, and have worked to fill those voids. This release has around thirty new test cases and trurl is now verified using more than two hundred tests.
Welcome to this follow-up patch release, just a week after we shipped 8.10.0. A bunch of bugfixes.
Numbers
the 261th release 0 changes 7 days (total: 9,679) 24 bugfixes (total: 10,828) 50 commits (total: 33,259) 0 new public libcurl function (total: 94) 0 new curl_easy_setopt() option (total: 306) 0 new curl command line option (total: 265) 19 contributors, 7 new (total: 3,246) 9 authors, 1 new (total: 1,303) 0 security fixes (total: 158)
Download the new curl release from curl.se as always.
Release presentation
Bugfixes
These are the perhaps most important ones fixed this time:
fix configure –with-ca-embed. It could otherwise sometimes lead to an empty bundled CA store.
cmake: ensure CURL_USE_OPENSSL/USE_OPENSSL_QUIC are set in sync
cmake: fix MSH3 to appear on the feature list
runtests: accecpt ‘quictls’ as OpenSSL compatible. It would previously skip a few tests that are marked OpenSSL specific.
connect: store connection info when really done
fix FTP CRLF line endings for ASCII transfer regression. Perhaps most notably this problem was seen on directory listings, which are done using ASCII mode.
fix HTTP/2 end-of-stream handling when uploading data from stdin
http: make max-filesize check not count ignored bodies. Like in the case where a URL is redirected to a second place, the first URL might still provide a body that curl ignores.
fix AF_INET6 use outside of USE_IPV6. Made the build fail on systems without IPv6 support.
check that the multi handle is valid in curl_multi_assign. Perhaps not exactly libcurl’s responsibility, but we found at least one application that did this after the 8.10.0 upgrade.
on QUIC connects, keep on trying on draining server
request: correctly reset the eos_sent flag. When doing multiple HTTP/2 uploads using the same handle – this caused problems for git.
transfer: fix sendrecv() without interim poll. An optimization that optimized a little too much… Most commonly this problem was seen with PHP programs that often (but unwisely) skip the polling.
rustls: fixed minor logic bug in default cipher selection
rustls: support strong CSRNG data. Now every curl build using TLS ensures use of strong random numbers.
trurl is slowing growing up and maturing. This is a minor patch release following up the previous one done just a few weeks ago, fixing a few annoying bugs only.
The query parameter normalization introduced in 0.15 did not properly handle query pairs when one of the sides of the ‘=’ was blank.
Make the generated manpage “source” to use the version number, not the title – which should be plain trurl.
A minuscule escaping mistake in the manual markdown made the output render wrongly.
Only install the manpage for ‘make install’ if there really is a manpage present – since it is generated and bundled in the release tarball it is not necessary present when users build their own
Future
I have this feeling that we still have use cases and combinations that we don’t have tested in the test suite so we probably need to do a few more minor or patch releases until we are ready to bump this baby to 1.0.
the 260th release 18 changes 42 days (total: 9,672) 245 bugfixes (total: 10,804) 461 commits (total: 33,209) 0 new public libcurl function (total: 94) 0 new curl_easy_setopt() option (total: 306) 2 new curl command line option (total: 265) 57 contributors, 28 new (total: 3,239) 27 authors, 14 new (total: 1,302) 1 security fixes (total: 158)
Download the new curl release from curl.se as always.
Release presentation
Security
CVE-2024-8096: OCSP stapling bypass with GnuTLS When curl is told to use the Certificate Status Request TLS extension, often referred to as OCSP stapling, to verify that the server certificate is valid, it might fail to detect some OCSP problems and instead wrongly consider the response as fine.
support for setting TLS version and ciphers for Rustls
stop offering ALPN http/1.1 for http2-prior-knowledge
support for sslcert/sslkey blob options for wolfSSL
release tarball 100% reproducible. We also provide verify-release a convenient shell script allowing anyone and everyone to easily verify curl release tarballs.
Bugfixes
See the full changelog for the complete list. Here follows my favorite subset:
build: add poll() detection for cross-builds
cmake: 40+ bugfixes
configure: fail if PSL is not disabled but not found
runtests: remove “has_textaware”
curl: find curlrc in XDG_CONFIG_HOME without leading dot
curl: make the progress bar detect terminal width changes
curl: bump maximum post data size in memory to 16GB
bearssl/mbedtls/rustls/wolfssl: fix setting tls version
gnutls/wolfssl: improve error message when certificate fails
gnutls: send all data
openssl: certinfo errors now fail correctly
sectransp: fix setting tls version
x509asn1: raise size limit for x509 certification information
ftp: always offer line end conversions
ftp: fix pollset for listening
http2: improved upload eos handling
idn: support non-UTF-8 input under AppleIDN
ngtcp2: use NGHTTP3 prefix instead of NGTCP2 for errors in h3 callbacks
pop3: fix multi-line responses
managen: fix superfluous leading blank line in quoted sections. Nicer HTML version of the manpages.
managen: in man output, remove the leading space from examples
managen: wordwrap long example lines in ASCII output. Nicer curl --manual and -h output.
manpage: ensure a maximum width for the text version.
connect: always prefer ipv6 in IP eyeballing
aws_sigv4: fix canon order for headers with same prefix
cf-socket: prevent KEEPALIVE_FACTOR being set to 1000 for Windows
rand: only provide weak random when needed
sigpipe: init the struct so that first apply ignores
Date: September 5, 2024 Time: 17:00 UTC (19:00 CEST, 10:00 PDT)
Everyone uses curl, the Swiss army knife of Internet transfers. While this tool has performed transfers and provided and a solid set of command line options for decades, new ones are added over time.
This talk goes through and focuses on some of the most powerful and interesting additions to curl done in recent years. The perhaps lesser known curl tricks that might enrich your command lines, extend your “tool belt” and make you more productive. Also trurl, the recently created companion tool for URL manipulations you maybe did not yet realize you need.
This presentation might just help you curl better.
The presentation will be followed by a Q&A session for all your curl questions.
You can select which one to view/attend. On the Zoom call, you will be able to ask questions via voice and on both you can ask questions via text/chat.
The Zoom version must be signed-up for to attend. The Twitch version you can just show up to.