We keep track of bugfixes done to curl. All bugfixes ever done. A while back I also went back and populated the lists with details from all the releases to the pre-cursors of curl: httpget and urlget. All and every change made since November 1996.
The bugfixes are all listed on the curl changelog page. The bugfix counter can be found on the release log page.
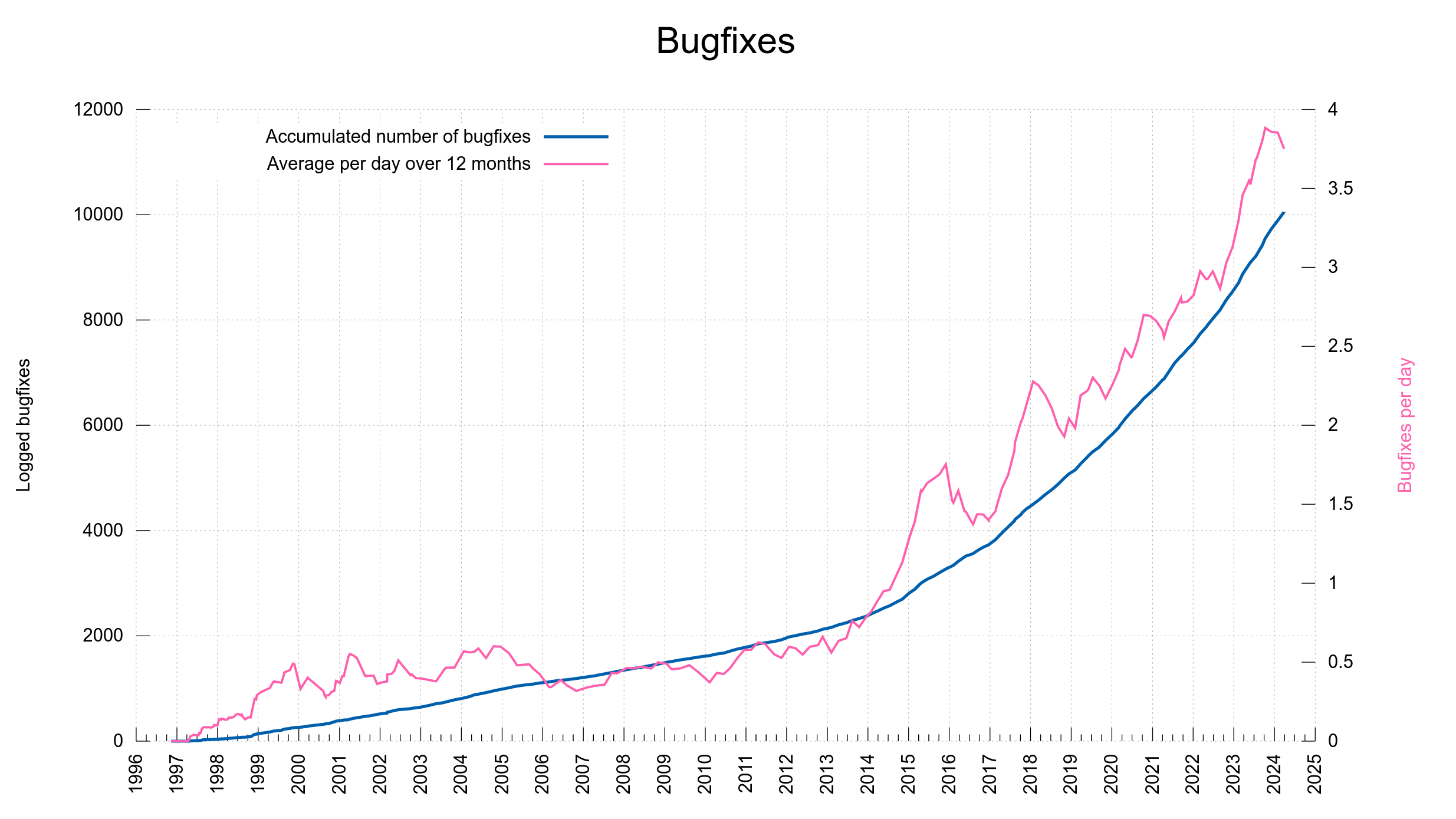
The rate of bugfixes has been increasing over the years. I think in terms of actual bugs being squashed and fixes being merged, but also partly because we have gotten much better at keeping meticulous logs and do better release notes.
A bugfix can be a single letter typo fix in a document, a spell-fix in a source code comment or it can fix a serious security vulnerability. From high to low, from important to a small subtle detail. The counter does not value, it is just a counter.
When we shipped the recent curl version, 8.6.0, the counter said 9,888 shipped bugfixes. The other day, when 8.7.0 and 8.7.1 shipped, the counter was upped to surpass 10,000 and now says: 10,051.
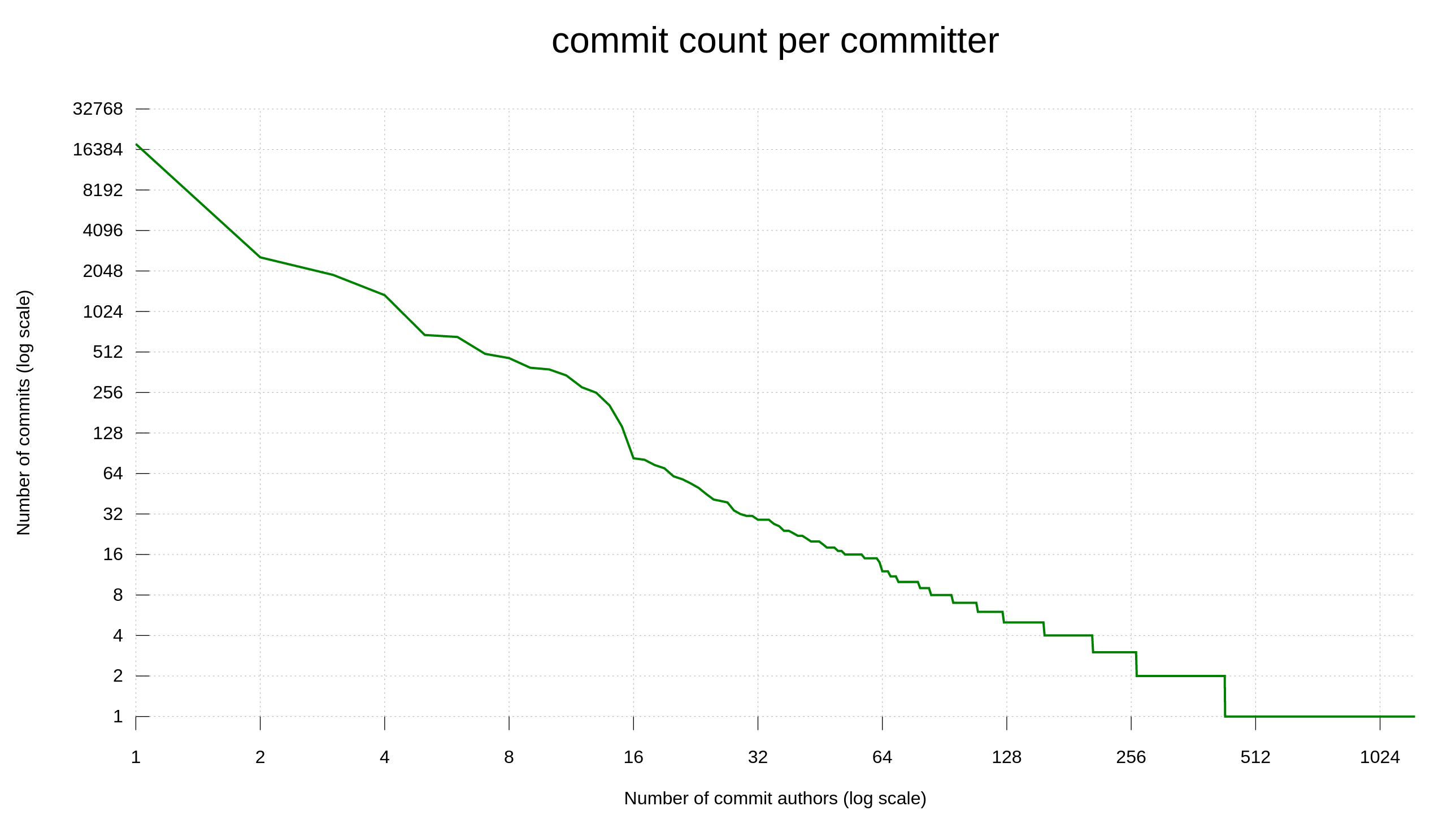
These bugfixes happened thanks to 3,134 contributors, out of which 1,252 persons have authored commits merged into the curl source repository.
This journey started with httpget. The first ever release of httpget 0.1 that was made public happened on November 11 1996. Today, that is exactly 10,000 days ago.
We only have git commits stored from late 1999, but that counter is almost at 32,000 now. Making a little less than every third commit ever done a logged bugfix.
How I do the release notes
This is highly scripted task.
It starts with: every commit of the RELEASE-NOTES file in git that makes it up-to-date needs to use the single word “synced” as commit message. The commit that syncs it.
Further, I have an alias in my ~/.gitconfig file that says:
[alias]
latest = log @^{/RELEASE-NOTES:.synced}..
This allows me to invoke git latest to get a list of the latest changes done in the repository since I most recently synced the RELEASE-NOTES.
Sync
When that list starts to grow, typically roughly every four to ten days something, I invoke the release-notes.pl script we have in the curl git repository. This scripts gets all the changes since the most previous sync and inserts them into the RELEASE-NOTES file, complete with a correct reference to the associated GitHub issue or pull-request.
The actual bullet point text it inserts comes from the first line of the corresponding commit message. The links comes from parsing commit messages and finding keywords and links according to how the project dictates how they should be used. This is one reason why it is important to do good commit messages following the correct style in the project. It makes the release notes job easier and the results better.
The script does not know what’s a change, what’s a bugfix or what’s not even worthy of mentioning. It just adds all changes to top the list of changes (and includes a convenient separator so that it is easy to spot the newly added ones) and the next step for me is then to manually go over the list and delete the ones that aren’t intended to be mentioned there and move the few changes into the correct section of the release notes.
I run release-notes.pl cleanup which then sorts the lists alphabetically and removes dangling references (which are leftovers from the lines I removed).
Contributors
We keep track, try to say thanks to and give credit to every contributor that helps out in the project. No matter the size of the contribution. When someone has reported a bug. the reporter is credited in the commit message of the bugfix. We also give credit to co-authors and people assisting in solving the issues etc. To make sure we mention and give credit to the contributors and keep track of them beyond what git itself does.
We can also add names manually to the release notes file, like if we had forgotten to mention them in a commit message. Then I run the contributors.sh script. It reads the list of names currently in the RELEASE-NOTES and then scans all the git changes since the previous sync and generates an updated list of all git authors, committers and everyone else who are credited, and it outputs an updated list (and contributor counter). That updated list is then pasted into RELEASE-NOTES.
In recent years, in a normal eight week release cycle, we typically feature 60 to 80 named contributors in this file. Of course, top contributors in the project tend to get mentioned in just about every release notes file, as they just have to help out and contribute once every 56 days to appear there.
On release days, we update the docs/THANKS file (using the contrithanks.sh script) where all contributors who ever helped out are mentioned and saved for the future. That list of people is also made visible on the thanks page on the curl website.
Counters
At the top of the release notes we have a few counters displayed. It looks similar to:
Public curl releases: 255 Command line options: 258 curl_easy_setopt() options: 304 Public functions in libcurl: 93 Contributors: 3119
After the list of contributors have been pasted into the current release notes, I invoke the delta script, which shows a lot of curl git repository statistics since the most previous release tag. That input includes the numbers shown in the release notes top, so if they are different now I update the release notes accordingly with the updated data. Most frequently, the contributor counter has been bumped.
Commit
- included the lists of bugfixes and changes
- updated contributors
- updated the counters
The RELEASE-NOTES file is then committed to git using “synced” as commit message. Until it is time to sync it again.
Because of this work, we can offer the pending release notes on the website, as it is the work in progress file with the changes we have already logged that is targeted to be included in the next release.
Release
Of course, on release days I make sure to do a final update so that all the last changes get into the file before release as then the file ends up in the release tarball, that is locked, signed and stored the archives.
After a release, I just manually erase the lists from the file and clear the list of names and commit. Then we start rebuilding it again with new stuff in the new release cycle.