Welcome to another curl release, 7 weeks since the previous one.
Release presentation
Numbers
the 204th release
6 changes
49 days (total: 8,636)
117 bug-fixes (total: 7,397)
198 commits (total: 27,866)
1 new public libcurl function (total: 86)
4 new curl_easy_setopt() option (total: 294)
1 new curl command line option (total: 243)
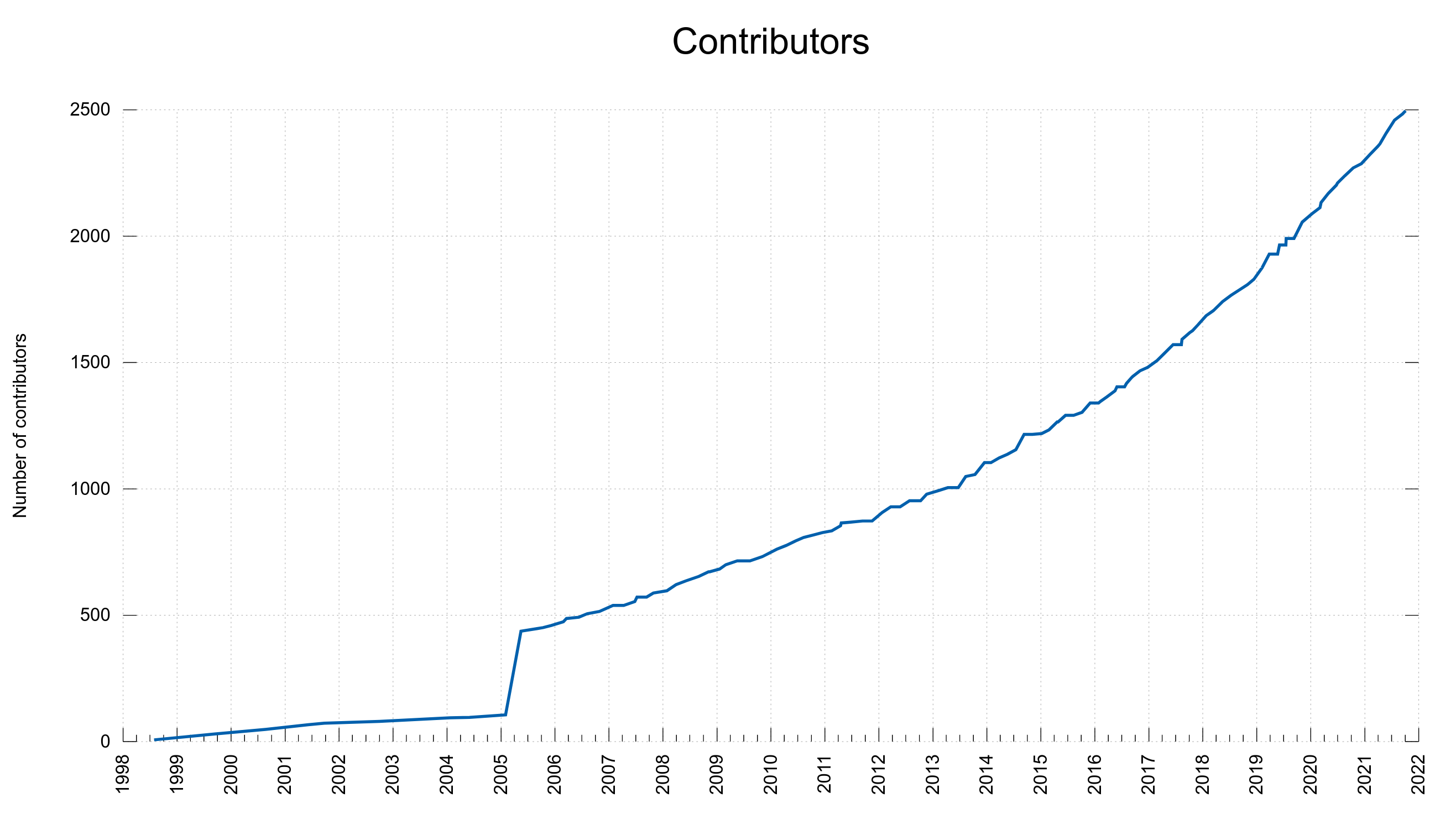
78 contributors, 44 new (total: 2,533)
50 authors, 28 new (total: 976)
0 security fixes (total: 111)
0 USD paid in Bug Bounties (total: 16,900 USD)
Changes
CURLOPT_MAXLIFETIME_CONN
This new option provides yet another knob for applications to control and limit connection reuse. Using this option, the application sets an upper limit that specifies that connections may not be older than this when being reused. It can for example be used to make sure connections don’t “get stuck” on one single specific load-balancer for extended periods of time.
CURLOPT_PREREQFUNCTION
This new callback gets called immediately before the request is started (= “Pre req”). Gives the application a heads up and some details about what is just about to start.
libssh2: SHA256 fingerprint support
This is a bump up from the previous MD5 version. Make sure that curl connections to the correct host with a cryptographically strong fingerprint check.
curl_url_strerror()
When a URL API function returns an error it does so using a CURLUcode type. Now there’s a function to convert this error code into an error message.
support UNC paths in file: URLs on Windows
The URL parser now understands UNC paths when parsing URLs on Windows.
allow setting of groups/curves with wolfSSL
The wolfSSL backend now allows setting of specific curves for TLS 1.3 connections, which allows users to use post quantum algorithms if wolfSSL is built to support them!
Bug-fixes
This is another release with more than one hundred individual bug-fixes, and here are a selected few I think might be worth highlighting.
more hyper work
I’ve done numerous small improvements in this cycle to take the hyper backend closer to become a solid member of the curl backend family.
print curl --help descriptions aligned right
When listing available options with --help or -h, the list is now showing the descriptions right-aligned which makes the output more easy-to-read in my opinion. Illustration:

store remote IP address for QUIC connections too
HTTP/3 uses QUIC and with this bug fixed, the %{remote_ip} variable for --write-out works there as well – as you’d expect. This fixes the underlying CURLINFO_PRIMARY_IP option.
reject HTTP response codes < 100
The HTTP response parser no longer accepts response code numbers below 100 as a legitimate protocol. The HTTP protocol has never specified any such code so this should not cause any problems. Lots of other HTTP clients already enforce this requirement too.
do not wait for writable socket if there’s no remote HTTP/2 window
If curl runs out of remote HTTP/2 window for a stream while uploading, ie the other end says it can’t receive any data right now, curl would still wait for the socket to be writable which would cause really bad busy-loops.
get libssh2 version at runtime
curl now asks libssh2 for its version string in runtime instead of showing the version that was used back when the curl binary was built, as it might very well be upgraded dynamically after the build!
require all man pages to use the same section headers in the same order
We tighten the bolts even more to make the libcurl documentation consistent. Now all libcurl man pages have to feature the same set of headers in the same order to not cause test failure. This includes a required example section. We also added an extra check to detect a common backslash-wrong-formatting mistake that we’ve previously done several times in man page examples.
NTLM: use DES_set_key_unchecked with OpenSSL
Turns out that the code that is implemented to use OpenSSL for doing NTLM authentication was using a function call that returns error if a “bad” key is used. NTLM v1 being a very weak algorithm in general makes it very easy to end up calling the function with such a weak key and then the NTLM authentication failed…
openssl: if verifypeer is not requested, skip the CA loading
If peer verification is disabled for a transfer when curl is built to use OpenSSL or one of its forks, curl will now completely skip the loading of the CA cert bundle. It was basically only used for being able to show in the verbose output if there was a match or not – that was then ignored anyway – and by skipping the load step the TLS handshake will use less memory and CPU resources.
urlapi: URL decode percent-encoded host names
The URL parser did not accept percent encoded host names. Now it does. Note however that libcurl will not by default percent-encode the host name when extracting a URL for the purpose of keeping IDN names working. It’s a little complicated.
ngtcp2: use QUIC TLS RFC9001
We switch over to use the “real” QUIC identifier when setting up connections instead of using the identifier made for a previous draft version of the protocol. curl still asks h3-29 for HTTP/3 since that RFC has still not shipped, but includes h3 as well – since it turns out some servers assume plain h3 when the final QUIC v1 version is used for transport.
a failed etag save now only fails that transfer
Specifying a file name to save etags in will from now on only fail those transfers using that file. If you specify more transfers that use another file or not use etags at all, those transfers can still get done.
Added test case for checksrc!
The custom tool we use for checking code style compliance, checksrc, has become quite advanced and now checks for a lot of source code details, and when we once again improved it in this release cycle we also added a test case for the tool itself to make sure it maintains its functionality even when we keep improving it going forward!
Next
The next release is planned for January 5, 2022. We have several changes queued up as pull requests already so I’d say it is likely that it then will become version 7.81.0.
Support?
I offer commercial support and curl related contracting for you and your company!