Welcome to another release, seven weeks since we did the patch release 7.71.1. This time we add a few new subtle features so the minor number is bumped yet again. Details below.
Release presentation video
Numbers
the 194th release
3 changes
49 days (total: 8,188)
100 bug fixes (total: 6,327)
134 commits (total: 26,077)
0 new public libcurl function (total: 82)
0 new curl_easy_setopt() option (total: 277)
0 new curl command line option (total: 232)
52 contributors, 29 new (total: 2,239)
30 authors, 14 new (total: 819)
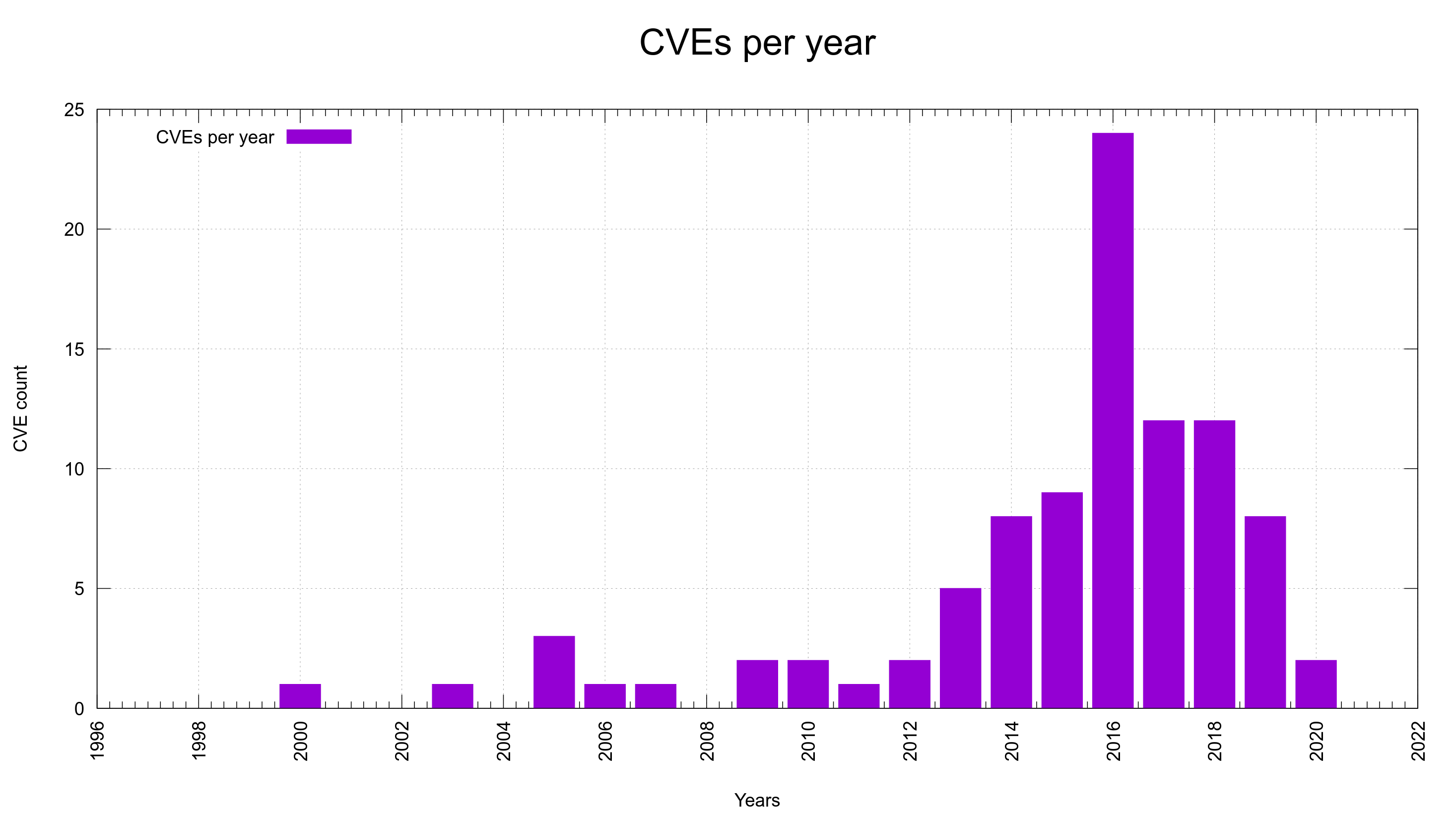
1 security fix (total: 95)
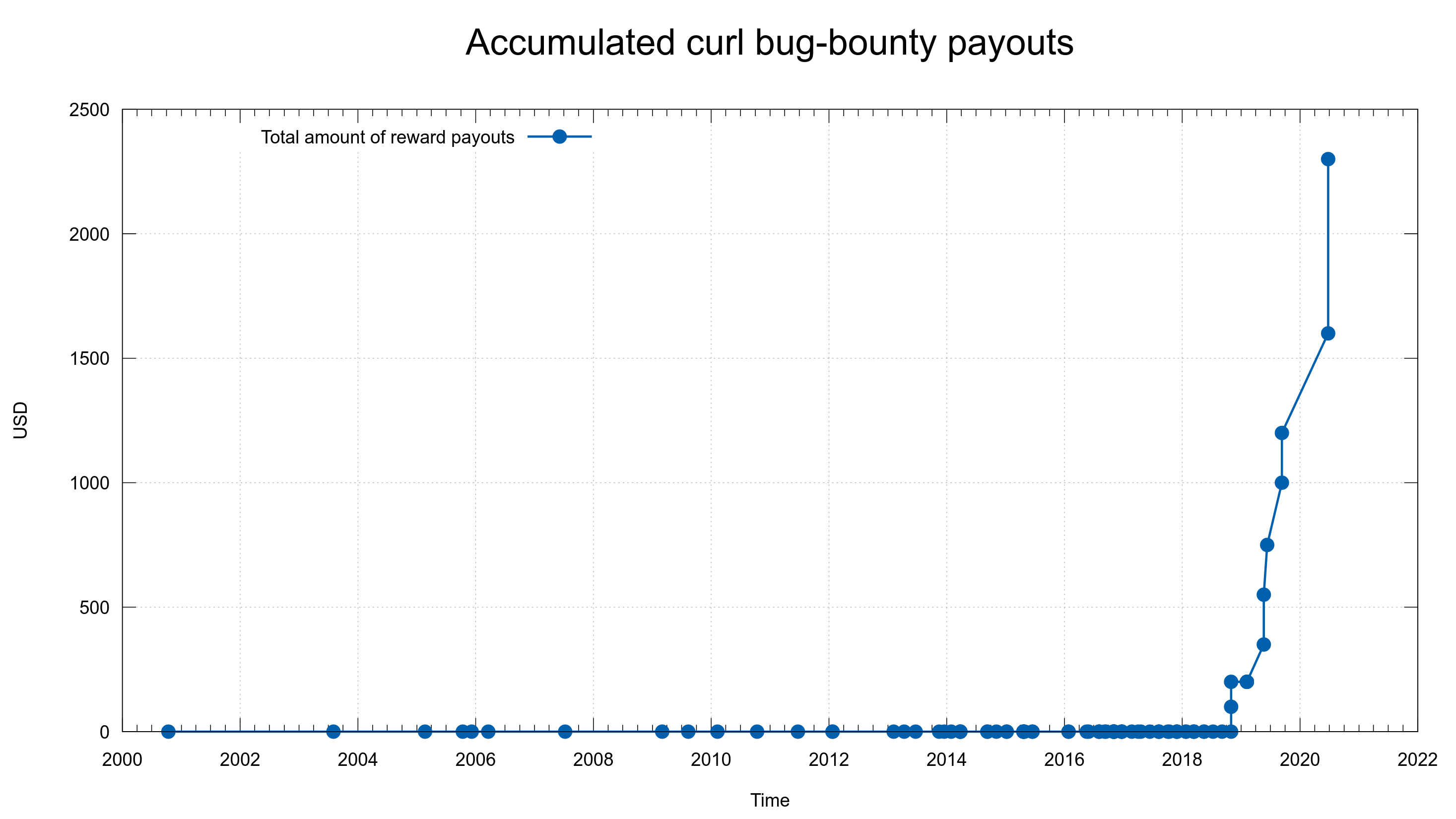
500 USD paid in Bug Bounties (total: 2,800 USD)
Security
CVE-2020-8132: “libcurl: wrong connect-only connection”. This a rather obscure issue that we’ve graded severity Low. There’s a risk that an application that’s using libcurl to do connect-only connections (ie not doing the full transfer with libcurl, just using it to setup the connection) accidentally sends or reads data over the wrong connection, as libcurl could mix them up internally in rare circumstances.
We rewarded 500 USD to the reporter of this security flaw.
Features
This is the first curl release that supports zstd compression. zstd is a yet another way to compressed content data over HTTP and if curl supports it, it can then automatically decompress it on the fly. zstd is designed to compress better and faster than gzip and if I understand the numbers shown, it is less CPU intensive than brotli. In pure practical terms, curl will ask for this compression in addition to the other supported algorithms if you tell curl you want compressed content. zstd is still not widely supported by browsers.
For clients that supports HTTP/2 and server push, libcurl now allows the controlling callback (“should this server push be accepted?”) to return an error code that will tear down the entire connection.
There’s a new option for curl_easy_getinfo called CURLINFO_EFFECTIVE_METHOD that lets the application ask libcurl what the most resent request method used was. This is relevant in case you’ve allowed libcurl to follow redirects for a POST where it might have changed the method as a result of what particular HTTP response the server responded with.
Bug-fixes
Here are a collection of bug-fixes I think stood out a little extra in this cycle.
cmake: fix windows xp build
I just love the fact that someone actually tried to build curl for Windows XP, noticed it failed in doing so and provided the fix to make it work again…
curl: improve the existing file check with -J
There were some minor mistakes in the code that checks if the file you get when you use -J already existed. That logic has now been tightened. Presumably not a single person ever actually had an actual problem with that before either, but…
ftp: don’t do ssl_shutdown instead of ssl_close
We landed an FTPS regression in 7.71.1 where we accidentally did the wrong function call when closing down the data connection. It could make consecutive FTPS transfers terribly slow.
http2: repair trailer handling
We had another regression reported where HTTP trailers when using HTTP/2 really didn’t work. Obviously not a terribly well-used feature…
http2: close the http2 connection when no more requests may be sent
Another little HTTP/2 polish: make sure that connections that have received a GOAWAY is marked for closure so that it gets closed sooner rather than later as no new streams can be created on it anyway!
multi_remove_handle: close unused connect-only connections
“connect-only connections” are those where the application asks libcurl to just connect to the site and not actually perform any request or transfer. Previously when that was done, the connection would remain in the multi handle until it was closed and it couldn’t be reused. Starting now, when the easy handle that “owns” the connection is removed from the multi handle the associated connect-only connection will be closed and removed. This is just sensible.
ngtcp2: adapt to changes
ngtcp2 is a QUIC library and is used in one of the backends curl supports for HTTP/3. HTTP/3 in curl is still marked experimental and we aim at keeping the latest curl code work with the latest QUIC libraries – since they’re both still “pre-beta” versions and don’t do releases yet. So, if you find that the HTTP/3 build fails, make sure you use the latest git commits of all the h3 components!
quiche: handle calling disconnect twice
If curl would call the QUIC disconnect function twice, using the quiche backend, it would crash hard. Would happen if you tried to connect to a host that didn’t listen to the UDP port at all for example…
setopt: unset NOBODY switches to GET if still HEAD
We recently fixed a bug for storing the HTTP method internally and due to refactored code, the behavior of unsetting the CURLOPT_NOBODY option changed slightly. There was never any promise as to what exactly that would do – but apparently several users had already drawn conclusions and written applications based on that. We’ve now adapted somewhat to that presumption on undocumented behavior by documenting better what it should do and by putting back some code to back it up…
http2: move retrycount from connect struct to easy handle
Yet another HTTP/2 fix. In a recent release we fixed a problem that materialized when libcurl received a GOAWAY on a stream for a HTTP/2 connection, and it would then instead try a new connection to issue the request over and that too would get a GOAWAY. libcurl will do these retry attempts up to 5 times but due to a mistake, the counter was stored wrongly and was cleared when each new connection was made…
url: fix CURLU and location following
libcurl supports two ways of setting the URL to work with. The good old string to the entire URL and the option CURLOPT_CURLU where you provide the handle to an already parsed URL. The latter is of course a much newer option and it turns out that libcurl didn’t properly handle redirects when the URL was set with this latter option!
Coming up
There are already several Pull Requests waiting in line to get merged that add new features and functionality. We expect the next release to become 7.73.0 and ship on October 14, 2020. Fingers crossed.