Simply because it is so hard to find this resource by googling it. Here’s the official HTTP/3 logo hosted:
https://github.com/httpwg/wg-materials/tree/gh-pages/badge/http3

Internet. Networking.
Simply because it is so hard to find this resource by googling it. Here’s the official HTTP/3 logo hosted:
https://github.com/httpwg/wg-materials/tree/gh-pages/badge/http3
We have started the work on extending wolfSSL to provide the necessary API calls to power QUIC and HTTP/3 implementations!
The TLS library known as wolfSSL is already very often a top choice when users are looking for a small and yet very fast TLS stack that supports all the latest protocol features; including TLS 1.3 support – open source with commercial support available.
As manufacturers of IoT devices and other systems with memory, CPU and footprint constraints are looking forward to following the Internet development and switching over to upcoming QUIC and HTTP/3 protocols, wolfSSL is here to help users take that step.
In case you have forgot, here’s a schematic view of HTTPS stacks, old vs new. On the right side you can see HTTP/3, QUIC and the little TLS 1.3 box there within QUIC.

There are no plans to write a full QUIC stack. There are already plenty of those. We’re talking about adjustments and extensions of the existing TLS library API set to make sure wolfSSL can be used as the TLS component in a QUIC stack.
One of the leading QUIC stacks and so far the only one I know of that does this, ngtcp2 is written to be TLS library agnostic and allows different TLS libraries to be plugged in as different backends. I believe it makes perfect sense to make such a plugin for wolfSSL to be a sensible step as soon as there’s code to try out.

A neat effect of that, would be that once wolfSSL works as a backend to ngtcp2, it should be possible to do full-fledged HTTP/3 transfers using curl powered by ngtcp2+wolfSSL. Contact us with other ideas for QUIC stacks you would like us to test wolfSSL with!
We expect wolfSSL to be the first FIPS-based implementation to add support for QUIC. I hear this is valuable to a number of users.
This work begins now and this is just a blog post of our intentions. We and I will of course love to get your feedback on this and whatever else that is related. We’re also interested to get in touch with people and companies who want to be early testers of our implementation. You know where to find us!
I can promise you that the more interest we can sense to exist for this effort, the sooner we will see the first code to test out.
It seems likely that we’re not going to support any older TLS drafts for QUIC than draft-29.

I want curl to be on the very bleeding edge of protocol development to aid the Internet protocol development community to test out protocols early and to work out kinks in the protocols and server implementations using curl’s vast set of tools and switches.
For this, curl supported HTTP/2 really early on and helped shaping the protocol and testing out servers.
For this reason, curl supports HTTP/3 already since August 2019. A convenient and well-known client that you can then use to poke on your brand new HTTP/3 servers too and we can work on getting all the rough edges smoothed out before the protocol is reaching its final state.
One of the many challenges QUIC and HTTP/3 have is that with a new transport protocol comes entirely new paradigms. With new paradigms like this, we need improved or perhaps even new tools to help us understand the network flows back and forth, to make sure we all have a common understanding of the protocols and to make sure we implement our end-points correctly.
QUIC only exists as an encrypted-only protocol, meaning that we can no longer easily monitor and passively investigate network traffic like before, QUIC also encrypts more of the protocol than TCP + TLS do, leaving even less for an outsider to see.
The current QUIC analyzer tool lineup gives us two options.
We all of course love Wireshark and if you get a very recent version, you’ll be able to decrypt and view QUIC network data.
With curl, and a few other clients, you can ask to get the necessary TLS secrets exported at run-time with the SSLKEYLOGFILE environment variable. You’ll then be able to see every bit in every packet. This way to extract secrets works with QUIC as well as with the traditional TCP+TLS based protocols.
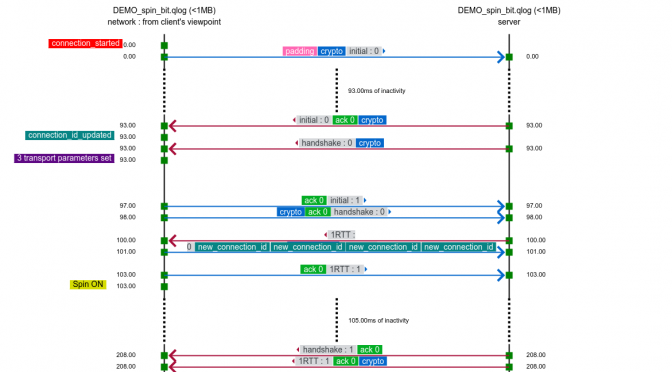
The qvis/qlog site. If you find the Wireshark network view a little bit too low level and leaving a lot for you to understand and draw conclusions from, the next-level tool here is the common QUIC logging format called qlog. This is an agreed-upon common standard to log QUIC traffic, which the accompanying qvis web based visualizer tool that lets you upload your logs and get visualizations generated. This becomes extra powerful if you have logs from both ends!
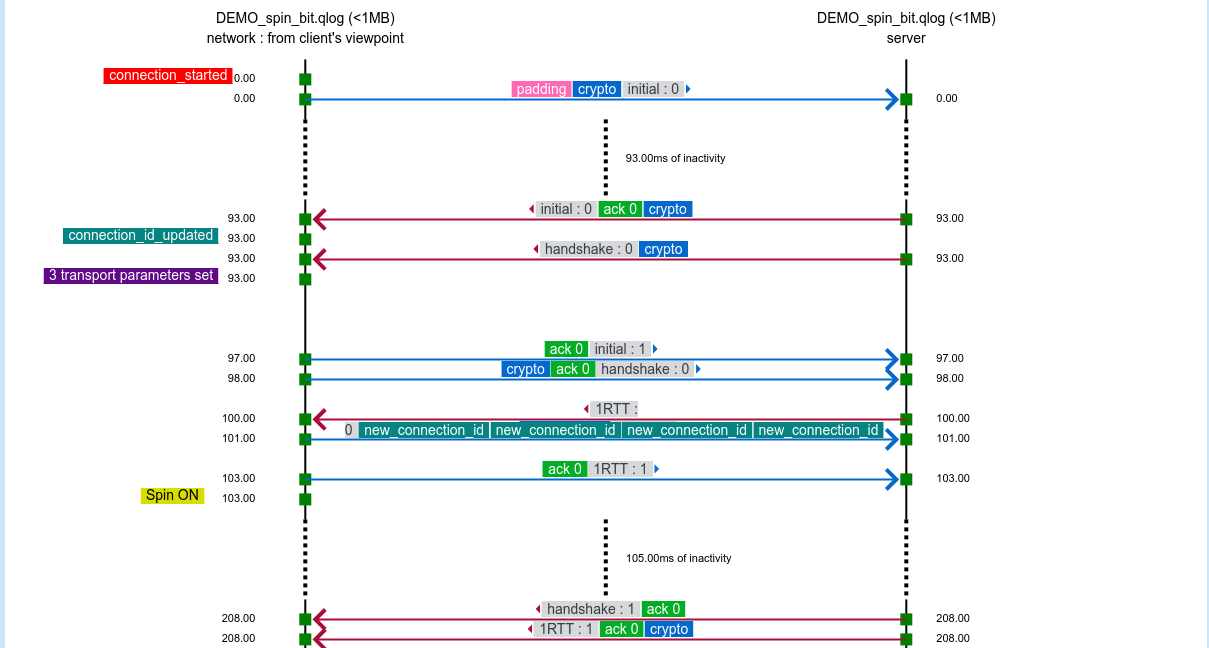
Starting with this commit (landed in the git master branch on May 7, 2020), all curl builds that support HTTP/3 – independent of what backend you pick – can be told to output qlogs.
Enable qlogging in curl by setting the new standard environment variable QLOGDIR to point to a directory in which you want qlogs to be generated. When you run curl then, you’ll get files creates in there named as [hex digits].log, where the hex digits is the “SCID” (Source Connection Identifier).
qlog and qvis are spear-headed by Robin Marx. qlogging for curl with Quiche was pushed for by Lucas Pardue and Alessandro Ghedini. In the ngtcp2 camp, Tatsuhiro Tsujikawa made it very easy for me to switch it on in curl.
The top image is snapped from the demo sample on the qvis web site.
FTP is going out of style.
The Chrome team has previously announced that they are deprecating and removing support for FTP.
Mozilla also announced their plan for the deprecation of FTP in Firefox.
Both browsers have paused or conditioned their efforts to not take the final steps during the Covid-19 outbreak, but they will continue and the outcome is given: FTP support in browsers is going away. Soon.
curl supported both uploads and downloads with FTP already in its first release in March 1998. Which of course was many years before either of those browsers mentioned above even existed!
In the curl project, we work super hard and tirelessly to maintain backwards compatibility and not break existing scripts and behaviors.
For these reasons, curl will not drop FTP support. If you have legacy systems running FTP, curl will continue to have your back and perform as snappy and as reliably as ever.
FTP is a protocol that is quirky to use over the modern Internet mostly due to its use of two separate TCP connections. It is unencrypted in its default version and the secured version, FTPS, was never supported by browsers. Not to mention that the encrypted version has its own slew of issues when used through NATs etc.
To put it short: FTP has its issues and quirks.
FTP use in general is decreasing and that is also why the browsers feel that they can take this move: it will only negatively affect a very minuscule portion of their users.
FTP is however still used in places. In the 2019 curl user survey, more than 29% of the users said they’d use curl to transfer FTP within the last two years. There’s clearly a long tail of legacy FTP systems out there. Maybe not so much on the public Internet anymore – but in use nevertheless.
SFTP could have become a viable replacement for FTP in these cases, but in practice we’ve moved into a world where HTTPS replaces everything where browsers are used.
FOSDEM 2020 is over for this time and I had an awesome time in Brussels once again.

I brought a huge collection of stickers this year and I kept going back to the wolfSSL stand to refill the stash and it kept being emptied almost as fast. Hundreds of curl stickers were given away! The photo on the right shows my “sticker bag” as it looked before I left Sweden.
Lesson for next year: bring a larger amount of stickers! If you missed out on curl stickers, get in touch and I’ll do my best to satisfy your needs.
“HTTP/3 for everyone” was my single talk this FOSDEM. Just two days before the talk, I landed updated commits in curl’s git master branch for doing HTTP/3 up-to-date with the latest draft (-25). Very timely and I got to update the slide mentioning this.
As I talked HTTP/3 already last year in the Mozilla devroom, I also made sure to go through the slides I used then to compare and make sure I wouldn’t do too much of the same talk. But lots of things have changed and most of the content is updated and different this time around. Last year, literally hundreds of people were lining up outside wanting to get into room when the doors were closed. This year, I talked in the room Janson, which features 1415 seats. The biggest one on campus. It was pack full!
It is kind of an adrenaline rush to stand in front of such a wall of people. At one time in my talk I paused for a brief moment and then I felt I could almost hear the complete silence when a huge amount of attentive faces captured what I had to say.



I got a lot of positive feedback on the presentation. I also thought that my decision to not even try to take question in the big room was a correct and I ended up talking and discussing details behind the scene for a good while after my talk was done. Really fun!
The video is also available from the FOSDEM site in webm and mp4 formats.
If you want the slides only, run over to slideshare and view them.
By late 2019, there’s an estimated amount of ten billion curl installations in the world. Of course this is a rough estimate and depends on how you count etc.
There are several billion mobile phones and tablets and a large share of those have multiple installations of curl. Then there all the Windows 10 machines, web sites, all macs, hundreds of millions of cars, possibly a billion or so games, maybe half a billion TVs, games consoles and more.

In the high end of volume users, we have at least two that I know of are doing around one million requests/sec on average (and I’m not even sure they are the top users, they just happen to be users I know do high volumes) but in the low end there will certainly be a huge amount of installations that barely ever do any requests at all.
If there are two users that I know are doing one million requests/sec, chances are there are more and there might be a few doing more than a million and certainly many that do less but still many.
Among many of the named and sometimes high profiled apps and users I know use curl, I very rarely know exactly for what purpose they use curl. Also, some use curl to do very many small requests and some will use it to do a few but very large transfers.
Additionally, and this really complicates the ability to do any good estimates, I suppose a number of curl users are doing transfers that aren’t typically considered to be part of “the Internet”. Like when curl is used for doing HTTP requests for every single subway passenger passing ticket gates in the London underground, I don’t think they can be counted as Internet transfers even though they use internet protocols.
According to some data, there is today around 4.388 billion “Internet users” (page 39) and the world wide average time spent “on the Internet” is said to be 6 hours 42 minutes (page 50). I think these numbers seem credible and reasonable.
According to broadbandchoices, an average hour of “web browsing” spends about 25MB. According to databox.com, an average visit to a web site is 2-3 minutes. httparchive.org says the median page needs 74 HTTP requests to render.
So what do users do with their 6 hours and 42 minutes “online time” and how much of it is spent in a browser? I’ve tried to find statistics for this but failed.
@chuttenc (of Mozilla) stepped up and helped me out with getting stats from Firefox users. Based on stats from users that used Firefox on the day of October 1, 2019 and actually used their browser that day, they did 2847 requests per client as median with the median download amount 18808 kilobytes. Of that single day of use.
I don’t have any particular reason to think that other browsers, other days or users of other browsers are very different than Firefox users of that single day. Let’s count with 3,000 requests and 20MB per day. Interestingly, that makes the average data size per request a mere 6.7 kilobytes.
A median desktop web page total size is 1939KB right now according to httparchive.org (and the mobile ones are just slightly smaller so the difference isn’t too important here).
Based on the median weight per site from httparchive, this would imply that a median browser user visits the equivalent of 15 typical sites per day (30MB/1.939MB).
If each user spends 3 minutes per site, that’s still just 45 minutes of browsing per day. Out of the 6 hours 42 minutes. 11% of Internet time is browser time.
3000 requests x 4388000000 internet users, makes 13,164,000,000,000 requests per day. That’s 13.1 trillion HTTP requests per day.
The world’s web users make about 152.4 million HTTP requests per second.
(I think this is counting too high because I find it unlikely that all internet users on the globe use their browsers this much every day.)
The equivalent math to figure out today’s daily data amounts transferred by browsers makes it 4388000000 x 30MB = 131,640,000,000 megabytes/day. 1,523,611 megabytes per second. 1.5 TB/sec.
30MB/day equals a little under one GB/month per person. Feels about right.
The curl users with the highest request frequencies known to me (*) are racing away at one million requests/second on average, but how many requests do the others actually do? It’s really impossible to say. Let’s play the guessing game!
First, it feels reasonable to assume that these two users that I know of are not alone in doing high frequency transfers with curl. Purely based on probability, it seems reasonable to assume that the top-20 something users together will issue at least 10 million requests/second.
Looking at the users that aren’t in that very top. Is it reasonable to assume that each such installed curl instance makes a request every 10 minutes on average? Maybe it’s one per every 100 minutes? Or is it 10 per minute? There are some extremely high volume and high frequency users but there’s definitely a very long tail of installations basically never doing anything… The grim truth is that we simply cannot know and there’s no way to even get a ballpark figure. We need to guess.
Let’s toy with the idea that every single curl instance on average makes a transfer, a request, every tenth minute. That makes 10 x 10^9 / 600 = 16.7 million transfers per second in addition to the top users’ ten million. Let’s say 26 million requests per second. The browsers of the world do 152 million per second.
If each of those curl requests transfer 50Kb of data (arbitrarily picked out of thin air because again we can’t reasonably find or calculate this number), they make up (26,000,000 x 50 ) 1.3 TB/sec. That’s 85% of the data volume all the browsers in the world transfer.
The world wide browser market share distribution according to statcounter.com is currently: Chrome at 64%, Safari at 16.3% and Firefox at 4.5%.
This simple-minded estimate would imply that maybe, perhaps, possibly, curl transfers more data an average day than any single individual browser flavor does. Combined, the browsers transfer more.
Sure, or call them estimates. I’m doing them to the best of my ability. If you have data, reasoning or evidence to back up modifications my numbers or calculations that you can provide, nobody would be happier than me! I will of course update this post if that happens!
(*) = I don’t name these users since I’ve been given glimpses of their usage statistics informally and I’ve been asked to not make their numbers public. I hold my promise by not revealing who they are.
Thanks to chuttenc for the Firefox numbers, as mentioned above, and thanks also to Jan Wildeboer for helping me dig up stats links used in this post.

In the afternoon of August 5 2019, I successfully made curl request a document over HTTP/3, retrieve it and then exit cleanly again.
(It got a 404 response code, two HTTP headers and 10 bytes of content so the actual response was certainly less thrilling to me than the fact that it actually delivered that response over HTTP version 3 over QUIC.)
The components necessary for this to work, if you want to play along at home, are reasonably up-to-date git clones of curl itself and the HTTP/3 library called quiche (and of course quiche’s dependencies too, like boringssl), then apply pull-request 4193 (build everything accordingly) and run a command line like:
curl --http3-direct https://quic.tech:8443
The host name used here (“quic.tech”) is a server run by friends at Cloudflare and it is there for testing and interop purposes and at the time of this test it ran QUIC draft-22 and HTTP/3.
The command line option --http3-direct tells curl to attempt HTTP/3 immediately, which includes using QUIC instead of TCP to the host name and port number – by default you should of course expect a HTTPS:// URL to use TCP + TLS.
The official way to bootstrap into HTTP/3 from HTTP/1 or HTTP/2 is via the server announcing it’s ability to speak HTTP/3 by returning an Alt-Svc: header saying so. curl supports this method as well, it just needs it to be explicitly enabled at build-time since that also is still an experimental feature.
To use alt-svc instead, you do it like this:
curl --alt-svc altcache https://quic.tech:8443
The alt-svc method won’t “take” on the first shot though since it needs to first connect over HTTP/2 (or HTTP/1) to get the alt-svc header and store that information in the “altcache” file, but if you then invoke it again and use the same alt-svc cache curl will know to use HTTP/3 then!
Be aware that I just made this tiny GET request work. The code is not cleaned up, there are gaps in functionality, we’re missing error checks, we don’t have tests and chances are the internals will change quite a lot going forward as we polish this.
You’re of course still more than welcome to join in, play with it, report bugs or submit pull requests! If you help out, we can make curl’s HTTP/3 support better and getting there sooner than otherwise.
curl currently supports two different QUIC/HTTP3 backends, ngtcp2 and quiche. Only the latter currently works this good though. I hope we can get up to speed with the ngtcp2 one too soon.
quiche uses and requires boringssl to be used while ngtcp2 is TLS library independent and will allow us to support QUIC and HTTP/3 with more TLS libraries going forward. Unfortunately it also makes it more complicated to use…
The official OpenSSL doesn’t offer APIs for QUIC. QUIC uses TLS 1.3 but in a way it was never used before when done over TCP so basically all TLS libraries have had to add APIs and do some adjustments to work for QUIC. The ngtcp2 team offers a patched version of OpenSSL that offers such an API so that OpenSSL be used.
Neither the QUIC nor the HTTP/3 protocols are entirely done and ready yet. We’re using the protocols as they are defined in the 22nd version of the protocol documents. They will probably change a little more before they get carved in stone and become the final RFC that they are on their way to.
The command line options mentioned above of course have their corresponding options for libcurl using apps as well.
Set the right bit with CURLOPT_H3 to get direct connect with QUIC and control how to do alt-svc using libcurl with CURLOPT_ALTSVC and CURLOPT_ALTSVC_CTRL.
All of these marked EXPERIMENTAL still, so they might still change somewhat before they become stabilized.
Starting on August 8, the option is just --http3 and you ask libcurl to use HTTP/3 directly with CURLOPT_HTTP_VERSION.
The first curl release ever saw the light of day on March 20, 1998 and already then, curl could transfer any amount of URLs given on the command line. It would iterate over the entire list and transfer them one by one.
Not even 22 years later, we introduce the ability for the curl command line tool to do parallel transfers! Instead of doing all the provided URLs one by one and only start the next one once the previous has been completed, curl can now be told to do all of them, or at least many of them, at the same time!
This has the potential to drastically decrease the amount of time it takes to complete an operation that involves multiple URLs.
Doing transfers concurrently instead of serially of course changes behavior and thus this is not something that will be done by default. You as the user need to explicitly ask for this to be done, and you do this with the new –parallel option, which also as a short-hand in a single-letter version: -Z (that’s the upper case letter Z).
To avoid totally overloading the servers when many URLs are provided or just that curl runs out of sockets it can keep open at the same time, it limits the parallelism. By default curl will only try up to 50 transfers concurrently, so if there are more transfers given to curl those will wait to get started once one of the first transfers are completed. The new –parallel-max command line option can be used to change the concurrency limit.
Is different in this mode. The new progress meter that will show up for parallel transfers is one output for all transfers.
When doing many simultaneous transfers, how do you figure out how they all did individually, like from your script? That’s still to be figured out and implemented.
This functionality makes curl do URLs in parallel. It will still not download the same URL using multiple parallel transfers the way some other tools do. That might be something to implement and offer in a future fine tuning of this feature.
This is a new command line feature that uses the fact that libcurl can already do this just fine. Thanks to libcurl being a powerful transfer library that curl uses, enabling this feature was “only” a matter of making sure libcurl was used in a different way than before. This parallel change is entirely in the command line tool code.
This change has landed in curl’s git repository already (since b8894085000) and is scheduled to ship in curl 7.66.0 on September 11, 2019.
I hope and expect us to keep improving parallel transfers further and we welcome all the help we can get!
The 2019 HTTP Workshop ended today. In total over the years, we have now done 12 workshop days up to now. This day was not a full day and we spent it on only two major topics that both triggered long discussions involving large parts of the room.

Mike West kicked off the morning with his cookies are bad presentation.
One out of every thousand cookie header values is 10K or larger in size and even at the 50% percentile, the size is 480 bytes. They’re a disaster on so many levels. The additional features that have been added during the last decade are still mostly unused. Mike suggests that maybe the only way forward is to introduce a replacement that avoids the issues, and over longer remove cookies from the web: HTTP state tokens.
A lot of people in the room had opinions and thoughts on this. I don’t think people in general have a strong love for cookies and the way they currently work, but the how-to-replace-them question still triggered lots of concerns about issues from routing performance on the server side to the changed nature of the mechanisms that won’t encourage web developers to move over. Just adding a new mechanism without seeing the old one actually getting removed might not be a win.
We should possibly “worsen” the cookie experience over time to encourage switch over. To cap allowed sizes, limit use to only over HTTPS, reduce lifetimes etc, but even just that will take effort and require that the primary cookie consumers (browsers) have a strong will to hurt some amount of existing users/sites.
(Related: Mike is also one of the authors of the RFC6265bis draft in progress – a future refreshed cookie spec.)
Mike Bishop did an excellent presentation of HTTP/3 for HTTP people that possibly haven’t kept up fully with the developments in the QUIC working group. From a plain HTTP view, HTTP/3 is very similar feature-wise to HTTP/2 but of course sent over a completely different transport layer. (The HTTP/3 draft.)
Most of the questions and discussions that followed were rather related to the transport, to QUIC. Its encryption, it being UDP, DOS prevention, it being “CPU hungry” etc. Deploying HTTP/3 might be a challenge for successful client side implementation, but that’s just nothing compared the totally new thing that will be necessary server-side. Web developers should largely not even have to care…
One tidbit that was mentioned is that in current Firefox telemetry, it shows about 0.84% of all requests negotiates TLS 1.3 early data (with about 12.9% using TLS 1.3)
Thought-worthy quote of the day comes from Willy: “everything is a buffer”
There’s no next workshop planned but there might still very well be another one arranged in the future. The most suitable interval for this series isn’t really determined and there might be reasons to try tweaking the format to maybe change who will attend etc.
The fact that almost half the attendees this time were newcomers was certainly good for the community but that not a single attendee traveled here from Asia was less good.
Thanks to the organizers, the program committee who set this up so nicely and the awesome sponsors!
Yesterday we plowed through a large and varied selection of HTTP topics in the Workshop. Today we continued. At 9:30 we were all in that room again. Day two.
Martin Thomson talked about his “hx” proposal and how to refer to future responses in HTTP APIs. He ended up basically concluding that “This is too complicated, I think I’m going to abandon this” and instead threw in a follow-up proposal he called “Reverse Javascript” that would be a way for a client to pass on a script for the server to execute! The room exploded in questions, objections and “improvements” to this idea. There are also apparently a pile of prior art in similar vein to draw inspiration from.
With the audience warmed up like this, Anne van Kasteren took us back to reality with an old favorite topic in the HTTP Workshop: websockets. Not a lot of love for websockets in the room… but this was the first of several discussions during the day where a desire or quest for bidirectional HTTP streams was made obvious.
Woo Xie did a presentation with help from Alan Frindell about Extending h2 for Bidirectional Messaging and how they propose a HTTP/2 extension that adds a new frame to create a bidirectional stream that lets them do messaging over HTTP/2 fine. The following discussion was slightly positive but also contained alternative suggestions and references to some of the many similar drafts for bidirectional and p2p connections over http2 that have been done in the past.

Lucas Pardue and Nick Jones did a presentation about HTTP/2 Priorities, based a lot of research previously done and reported by Pat Meenan. Lucas took us through the history of how the priorities ended up like this, their current state and numbers and also the chaos and something about a possible future, the h3 way of doing prio and mr Meenan’s proposed HTTP/3 prio.
Nick’s second half of the presentation then took us through Cloudflare’s Edge Driven HTTP/2 Prioritisation work/experiments and he showed how they could really improve how prioritization works in nginx by making sure the data is written to the socket as late as possible. This was backed up by audience references to the TAPS guidelines on the topic and a general recollection that reducing the number connections is still a good idea and should be a goal! Server buffering is hard.
Asbjørn Ulsberg presented his case for a new request header: prefer-push. When used, the server can respond to the request with a series of pushed resources and thus save several round-rips. This triggered sympathy in the room but also suggestions of alternative approaches.
Alan Frindell presented Partial POST Replay. It’s a rather elaborate scheme that makes their loadbalancers detect when a POST to one of their servers can’t be fulfilled and they instead replay that POST to another backend server. While Alan promised to deliver a draft for this, the general discussion was brought up again about POST and its “replayability”.
Willy Tarreau followed up with a very similar topic: Retrying failed POSTs. In this this context RFC 2310 – The Safe Response Header Field was mentioned and that perhaps something like this could be considered for requests? The discussion certainly had similarities and overlaps with the SEARCH/POST discussion of yesterday.
Mike West talked about Fetch Metadata Request Headers which is a set of request headers explaining for servers where and what for what purpose requests are made by browsers. He also took us through a brief explained of Origin Policy, meant to become a central “resource” for a manifest that describes properties of the origin.
Mark Nottingham presented Structured Headers (draft). This is a new way of specifying and parsing HTTP headers that will make the lives of most HTTP implementers easier in the future. (Parts of the presentation was also spent debugging/triaging the most weird symptoms seen when his Keynote installation was acting up!) It also triggered a smaller side discussion on what kind of approaches that could be taken for HPACK and QPACK to improve the compression ratio for headers.
Anne van Kesteren talked Web-compatible header value parsers, standardizing on how to parse headers not covered by structured headers.
Yoav Weiss described the current status of client hints (draft). This is shipped by Chrome already and he wanted more implementers to use it and tell how its working.
Roberto Peon presented an idea for doing “Partialy-Reliable HTTP” and after his talk and a discussion he concluded they will implement it, play around and come back and tell us what they’ve learned.
Mark Nottingham talked about HTTP for CDNs. He has this fancy-looking test suite in progress that checks how things are working and what is being supported and there are two drafts in progress: the cache response header and the proxy status header field.
Willy Tarreau talked about a race problem he ran into with closing HTTP/2 streams and he explained how he worked around it with a trailing ping frame and suggested that maybe more users might suffer from this problem.
The oxygen level in the room was certainly not on an optimal level at this point but that didn’t stop us. We knew we had a few more topics to get through and we all wanted to get to the boat ride of the evening on time. So…
Hooman Beheshti polled the room to get a feel for what people think about Early hints. Are people still on board? Turns out it is mostly appreciated but not supported by any browser and a discussion and explainer session followed as to why this is and what general problems there are in supporting 1xx headers in browsers. It is striking that most of us HTTP people in the room don’t know how browsers work! Here I could mention that Cory said something about the craziness of this, but I forget his exact words and I blame the fact that they were expressed to me on a boat. Or perhaps that the time is already approaching 1am the night after this fully packed day.
Good follow-up reads from that discussion is Yoav’s blog post A Tale of Four Caches and Jake Archibalds’s HTTP/2 Push is tougher than I thought.
As the final conversation of the day, Anne van Kesteren talked about Response Sources and the different ways a browser can do requests and get responses.
HAproxy had the excellent taste of sponsoring this awesome boat ride on the Amsterdam canals for us at the end of the day

Thanks again to Cory Benfield for feeding me his notes of the day to help me keep things straight. All mistakes are mine. But if you tell me about them, I will try to correct the text!