We cut the release cycle short and decided to ship this release now rather than later because of the heap overflow issue we found.
Release presentation
Numbers
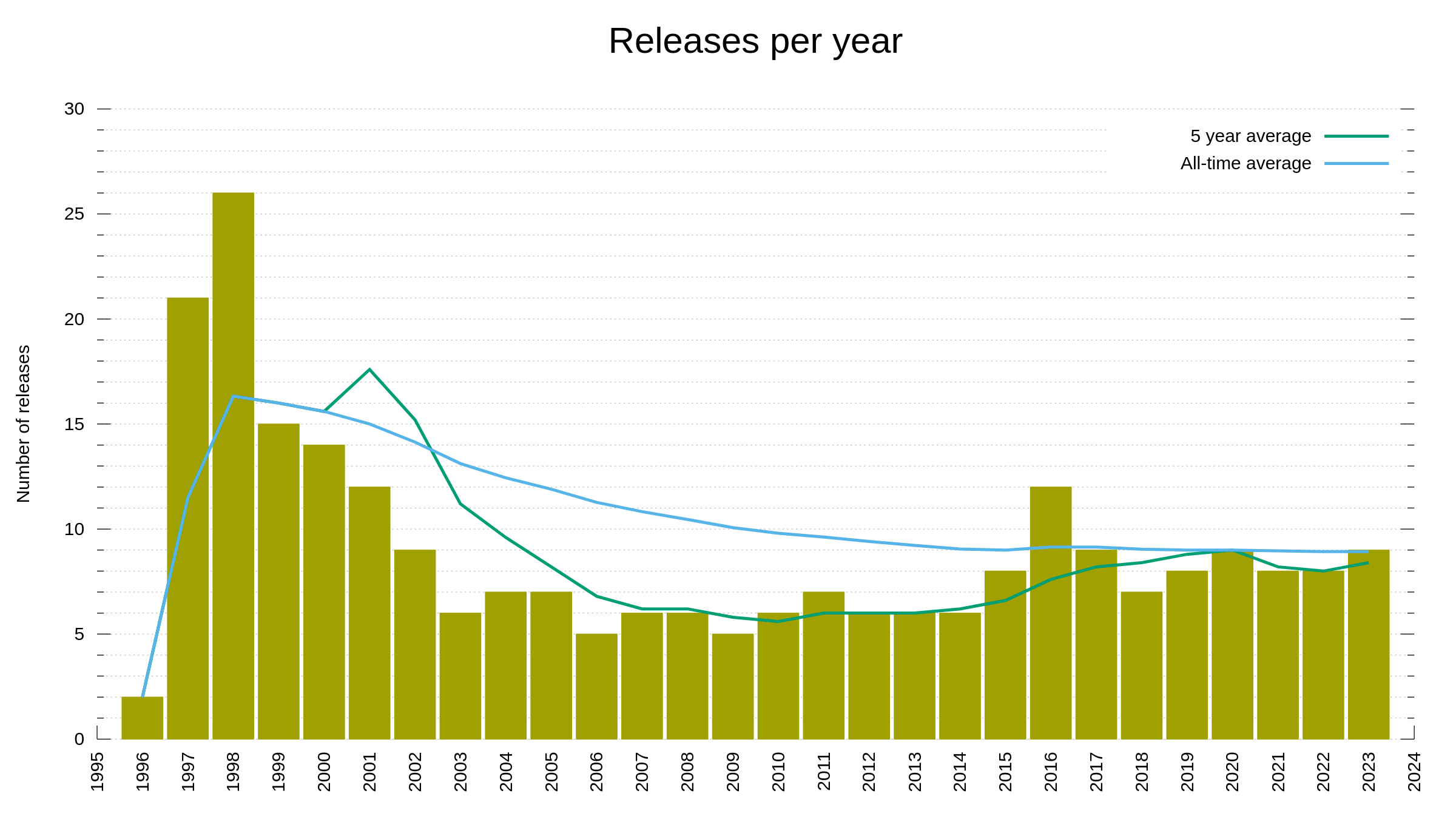
the 252nd release
3 changes
28 days (total: 9,336)
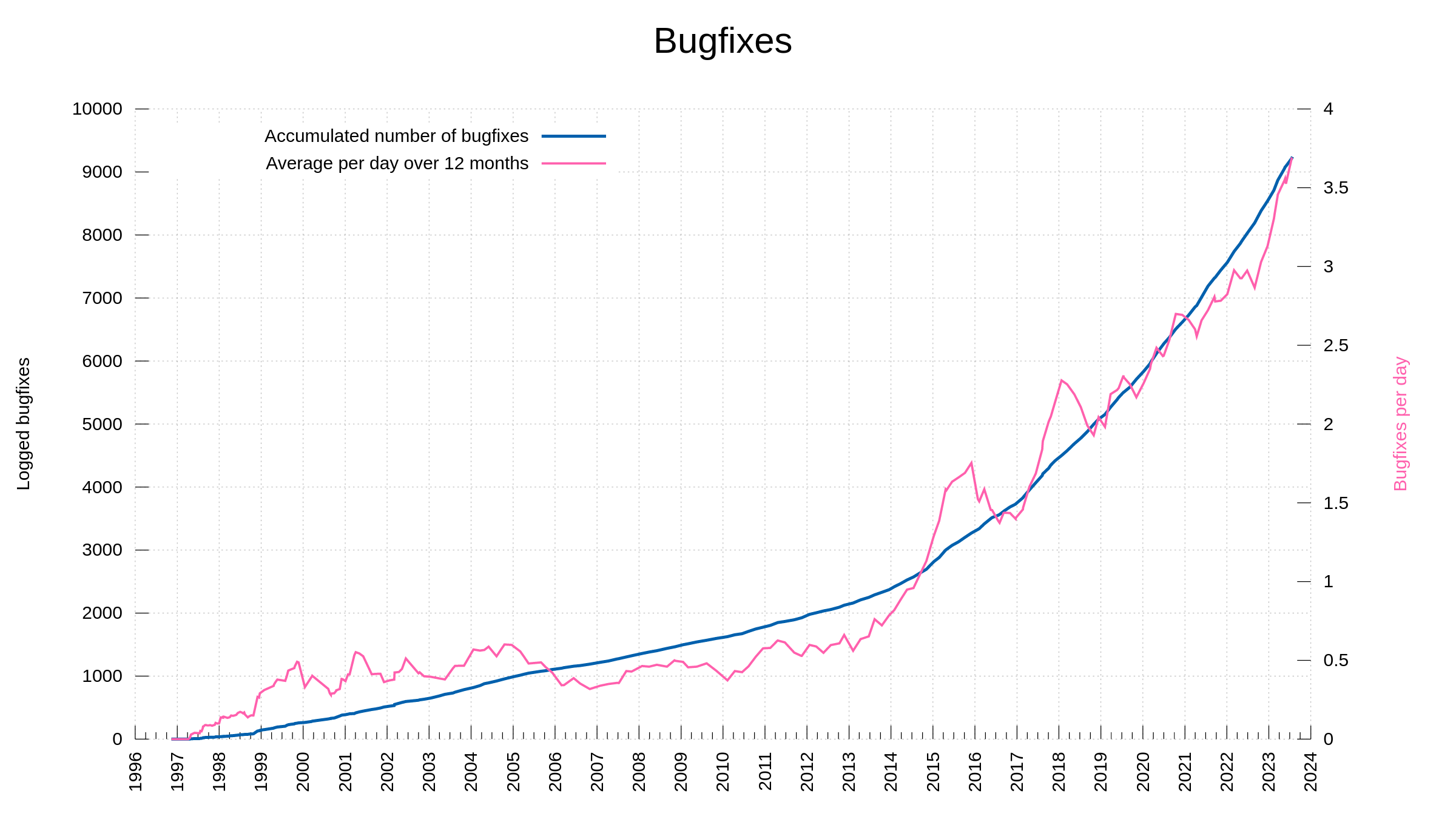
136 bug-fixes (total: 9,551)
216 commits (total: 31,158)
1 new public libcurl function (total: 93)
0 new curl_easy_setopt() option (total: 303)
1 new curl command line option (total: 258)
46 contributors, 20 new (total: 2,996)
21 authors, 7 new (total: 1,200)
2 security fixes (total: 148)
Security
SOCKS5 heap buffer overflow (HIGH)
(CVE-2023-38545) This flaw makes curl overflow a heap based buffer in the SOCKS5 proxy handshake.
See also my separate detailed explainer about CVE-2023-38545.
cookie injection with none file (LOW)
(CVE-2023-38546) This flaw allows an attacker to insert cookies at will into a running program using libcurl, if the specific series of conditions are met and the cookies are put in a file called “none” in the application’s current directory.
Changes
IPFS protocols via HTTP gateway
The curl tool now supports IPFS URLs via gateway. I emphasize that it is the tool because this support is not libcurl. The URL needs to be a correct IPFS URL but curl only works with it if you provide an IPFS gateway, it has no actual native IPFS implementation. You want to read the new IPFS section on the curl website for details.
curl_multi_get_handles()
This is new and very simply function added to the libcurl API: it returns all the easy handles that were previously added to it.
dropped support for legacy mingw.org toolchain
The legacy mingw version is deprecated and by dropping support for this we can simplify code a little.
Bugfixes
Some of the things we fixed in this release are…
made cmake more aligned with configure
Numerous smaller and larger fixes went in this cycle to make sure the cmake and configure configs are more aligned and create more similar default builds.
expire the timeout when trying next IP
Iterating over IP addresses when connecting could accidentally do delays, making the process take longer time than necessary.
remove unnecessary cookie struct fields
curl now keeps much less data in memory per cookie
update curl man page references
All curl man pages got their references updated and they are now verified and checked in tests to remain accurate and well formatted.
use per-request counter to check too large http headers
The check that prevents too large accumulated HTTP response headers actually used the wrong counter so it kicked in too early.
aws-sigv4: fix sorting with empty parts
Getting this authentication method to work in all cases turns out to be a real adventure and in this release we fix yet some minor issues.
let the max file size option stop too big transfers
Up until now, the maximum file size option only works on stopping transfers before it even began if libcurl knew the file size was too big. Starting now, it will also stop ongoing transfers if they reach the maximum limit. This should help users avoid unwanted surprises.
lib: use wrapper for curl_mime_data fseek callback
Rewinding files when doing multipart formbased transfers on 32 bit ARM using the legacy libcurl curl_formadd API did not work because of data size incompatibilities. It took some work to find and understand as it still worked fine on x86 32 bit for example!
libssh: cap SFTP packet size sent
The libssh library mostly passes on the data with the same size libcurl passes to it, it turns out. That is not compatible with the SFTP protocol so in order to make libcurl work better, it now caps how much data it can send in a single libssh send call. It probably makes SFTP uploads much slower.
misc: better random boundary separators
The mime boundaries used for multipart formposts now use more random bits than before. Up from 64 to 130 bits. It now produces strings using alphanumerical characters instead of just hex.
quic: set ciphers/curves like for TLS
The same style of support for setting TLS 1.3 ciphers and curves as for regular TLS were added to the QUIC code.
http2: retry on GOAWAY
Improved handling of GOAWAY when wanting to use use connection and then move on to use another.
fall back to http/https proxy env-variable if ws/wss not set
When using one of the WebSocket schemes, curl will now fall back and try the http_proxy and https_proxy environment variables if ws_proxy or wss_proxy is not set.
accept –expand on file names too
The variable --expand functionality did not work for command line options that accept file names, such as --output. It does now.
Next
We have synced the coming release cycles on this release. The next one is thus planned to happen in exactly eight weeks time. On December 6, 2023.