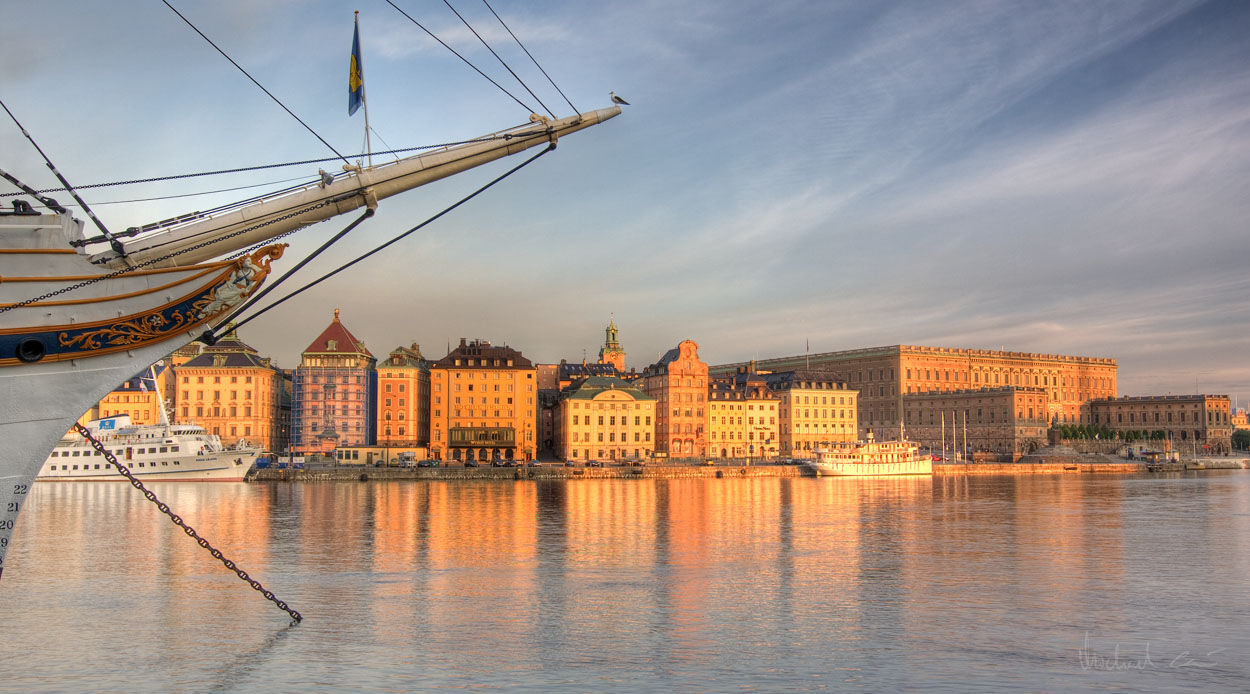At times when I’ve gone out (yes it happens), faced an audience and talked about my primary spare time project curl, I’ve said a few times in the past that we have one billion users.
Users?

OK, as this is open source I’m talking about, I can’t actually count my users and what really constitutes “a user” anyway?
If the same human runs multiple copies of curl (in different devices and applications), is that human then counted once or many times? If a single developer writes an application that uses libcurl and that application is used by millions of humans, is that one user or are they millions of curl users?
What about pure machine “users”? In the subway in one of the world’s largest cities, there’s an automated curl transfer being done for every person passing the ticket check point. Yet I don’t think we can count the passing (and unknowing) passengers as curl users…
I’ve had a few people approach me to object to my “curl has one billion users” statement. Surely not one in every seven humans on earth are writing curl command lines! We’re engineers and we’re picky with the definitions.
Because of this, I’m trying to stop talking about “number of users”. That’s not a proper metric for a project whose primary product is a library that is used by applications or within devices. I’m instead trying to assess the number of humans that are using services, tools or devices that are powered by curl. Fun challenge, right?
Who isn’t using?
 I’ve tried to imagine of what kind of person that would not have or use any piece of hardware or applications that include curl during a typical day. I certainly can’t properly imagine all humans in this vast globe and how they all live their lives, but I quite honestly think that most internet connected humans in the world own or use something that runs my code. Especially if we include people who use online services that use curl.
I’ve tried to imagine of what kind of person that would not have or use any piece of hardware or applications that include curl during a typical day. I certainly can’t properly imagine all humans in this vast globe and how they all live their lives, but I quite honestly think that most internet connected humans in the world own or use something that runs my code. Especially if we include people who use online services that use curl.
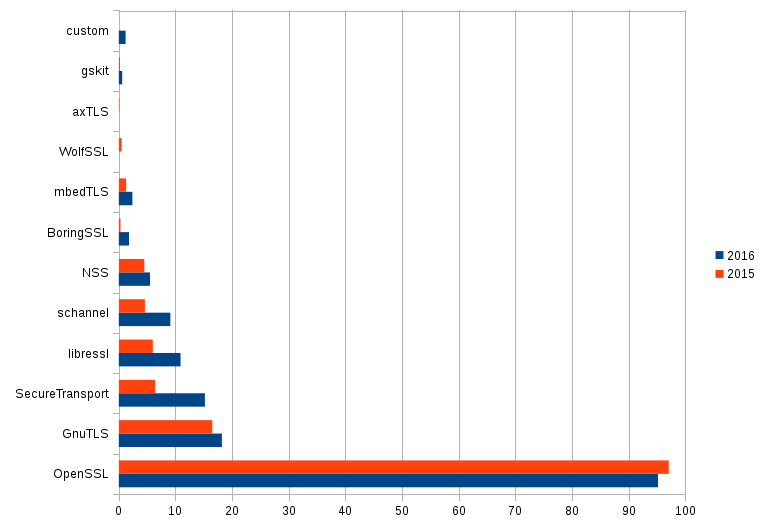
curl is used in basically all modern TVs, a large percentage of all car infotainment systems, routers, printers, set top boxes, mobile phones and apps on them, tablets, video games, audio equipment, Blu-ray players, hundreds of applications, even in fridges and more. Apple alone have said they have one billion active devices, devices that use curl! Facebook uses curl extensively and they have 1.5 billion users every month. libcurl is commonly used by PHP sites and PHP empowers no less than 82% of the sites w3techs.com has figured out what they run (out of the 10 million most visited sites in the world).
There are about 3 billion internet users worldwide. I seriously believe that most of those use something that is running curl, every day. Where Internet is less used, so is of course curl.
Every human in the connected world, use something powered by curl every day
Frigging Amazing
It is an amazing feeling when I stop and really think about it. When I pause to let it sink in properly. My efforts and code have spread to almost every little corner of the connected world. What an amazing feat and of course I didn’t think it would reach even close to this level. I still have hard time fully absorbing it! What a collaborative success story, because I could never have gotten close to this without the help from others and the community we have around the project.
But it isn’t something I think about much or that make me act very different in my every day life. I still work on the bug reports we get, respond to emails and polish off rough corners here and there as we go forward and keep releasing new curl releases every 8 weeks. Like we’ve done for years. Like I expect us and me to continue doing for the foreseeable future.
It is also a bit scary at times to think of the massive impact it could have if or when a really terrible security flaw is discovered in curl. We’ve had our fair share of security vulnerabilities so far through our history, but we’ve so far been spared from the really terrible ones.
So I’m rich, right?

If I ever start to describe something like this to “ordinary people” (and trust me, I only very rarely try that), questions about money is never far away. Like how come I give it away free and the inevitable “what if everyone using curl would’ve paid you just a cent, then…“.
I’m sure I don’t need to tell you this, but I’ll do it anyway: I give away curl for free as open source and that is a primary reason why it has reached to the point where it is today. It has made people want to help out and bring the features that made it attractive and it has made companies willing to use and trust it. Hadn’t it been open source, it would’ve died off already in the 90s. Forgotten and ignored. And someone else would’ve made the open source version and instead filled the void a curlless world would produce.

 The HTTP Workshop 2016 will take place in Stockholm starting tomorrow Monday, as I’ve mentioned before. Today we’ll start off slowly by having a few pre workshop drinks and say hello to old and new friends.
The HTTP Workshop 2016 will take place in Stockholm starting tomorrow Monday, as I’ve mentioned before. Today we’ll start off slowly by having a few pre workshop drinks and say hello to old and new friends.