

The preferred method of providing changes to the curl project, be it source code, documentation or web site contents, is by submitting a pull-request. A “PR”. On the curl repository on GitHub.
When a proposed curl change, bugfix or improvement is submitted as a PR on GitHub, it gets built, checked, tested and verified in countless ways and a few hundred developers get a notification about it.
The first thing I do every morning and the last thing I do every night before I go to bed, is eyeing through the list of open PRs, and especially the ones with recent activities. I of course also get back to them during the day if there is activity that might need my attention – not to mention that I also personally submit by own PRs to curl at an average rate of a few per day.
You can rightly say that my day and my work with curl is extremely PR centered. And by extension, also extremely git and GitHub focused.
Merging the work
When all the CI checks run green and all review comments and concerns have been addressed, the PR has become ripe for merge.
As a general rule, we always work in the master branch as the current development branch that is destined to become the next release when the time comes. An approved PR thus gets merged into the master branch and pushed there. We keep the git history linear and clean, meaning we do merge + rebase before pushing.
Commit messages
One of the key properties of a git commit, is the commit message. The text that describes the particular change in the repository.
In the curl project we have a standard style or template for how to write these messages. This makes them consistent and helps making them useful and get populated with informational meta-data that future versions of ourselves might appreciate when we look back at the changes decades into the future.
The PR review UI on GitHub unfortunately totally ignores commit messages, which means that we cannot comment on them or insist or check that users write them in our preferred style. Arguably, it is also just quicker and easier not to do that and instead just gently brush up the message in the commit locally before the commit is pushed.
Adding correct fixes #xxx and closes #xxx information to the message also helps making sure GitHub closes the associated issues/pull-requests and allows us to map git repository commits with GitHub activities at will – like when running statistic scripts etc.
This strictness and way of working makes it impossible to use the “merge” button in the GitHub UI since we simply cannot ensure that the commit is good enough with it. The button is however not possible to remove from the UI with any settings. We just prohibit its use.
They appear as “closed this in”
This way of working makes most PRs appear as “closed this in #[commit hash]” in the GitHub UI instead of saying “merged by” that same hash. Because in GitHub’s view, the PR was not merged.

GitHub could fix this with a merges keyword, which has been suggested since forever, but clearly they do not see this as a problem.
Occasional users of course get surprised or even puzzled by us closing the PR “instead of merging”, because that is what it looks like. When it really is not.
Ultimately, I consider the state and contents of our git repository and history more important than how the PRs appear on GitHub so I stick to our way of working.
Signed commits
As a little side-note, I of course also always GPG sign my commits so you can verify on GitHub and with git that my commits are genuinely done by me.
Stats
To give you an idea of the issue and pull request frequency and management in curl (the source code repository). Snapshots from the curl dashboard from August 8, 2022.
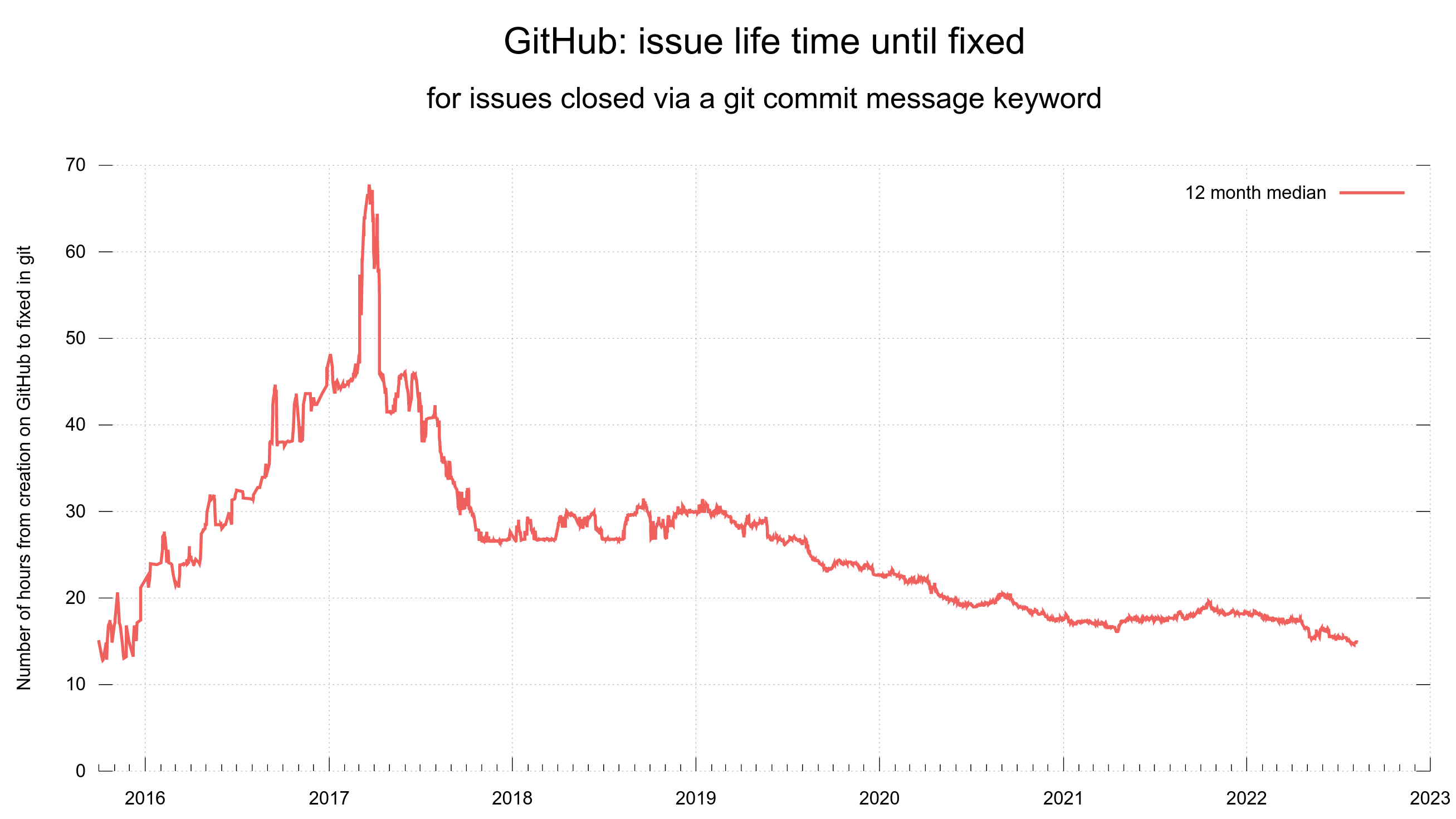
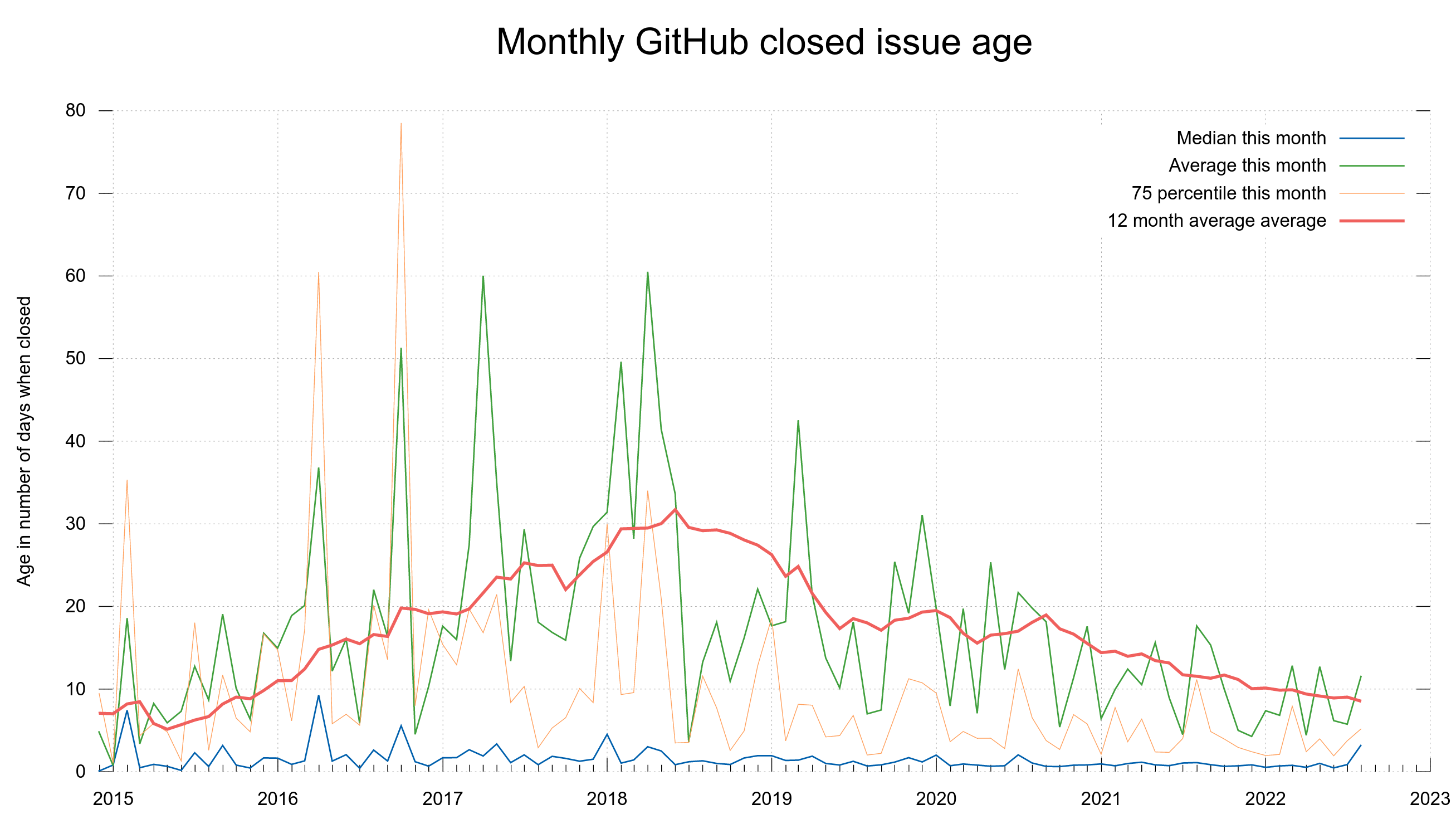

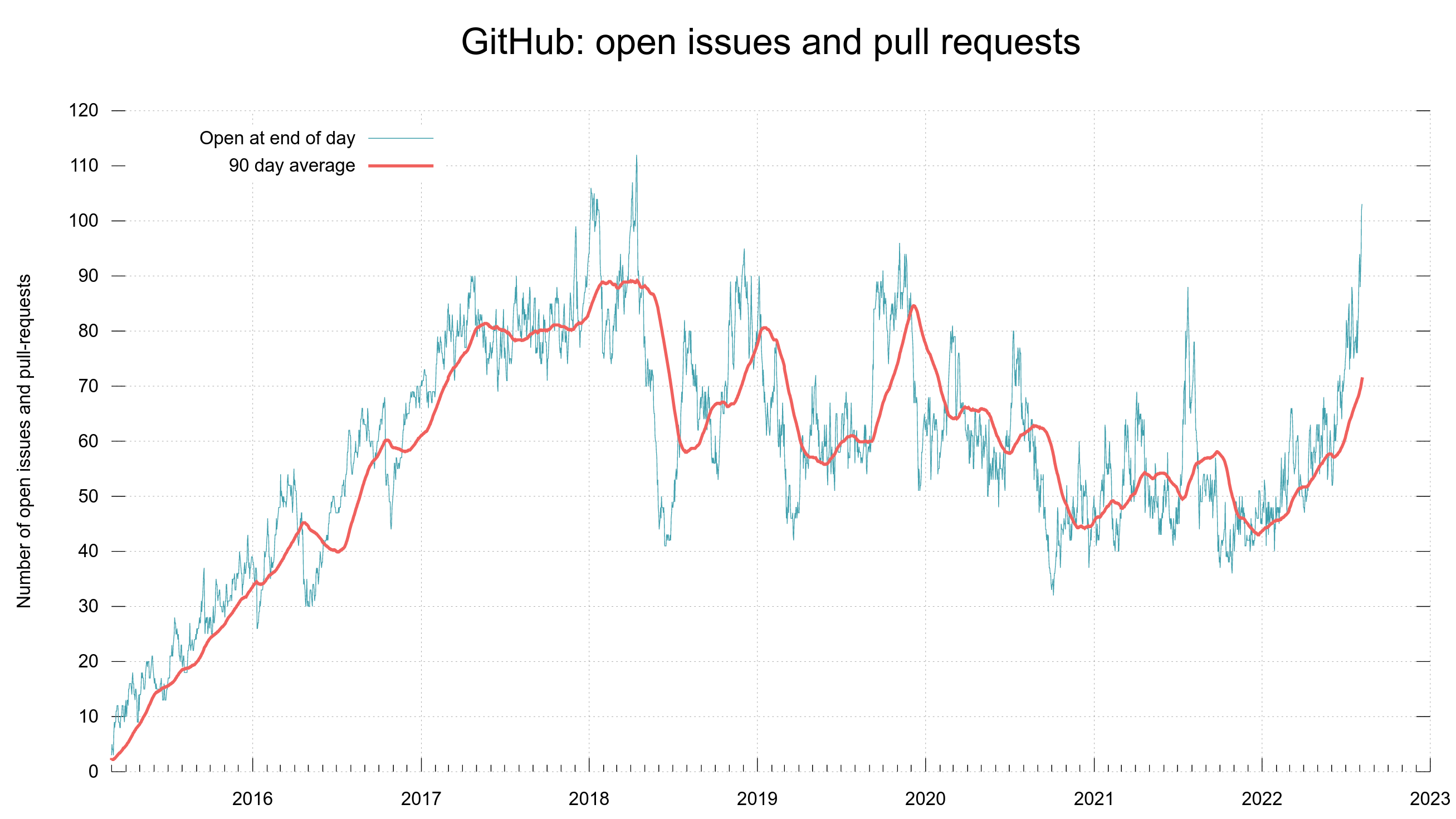
Update
Several people have mentioned to me after I posted this article that I could squash and edit the commits and force-push the work back to the user’s branch used for the PR before using the “merge” button or auto-merge feature of GitHub.
Sure, I could do it that way, but I think that is an even worse solution and a poor work-around. It is very intrusive method that would make me force-push in every user’s PR branch and I am certain a certain amount of users will be surprised by that and some even downright upset because it removes/overwrites their work. For the sake of working around a GitHub quirk. Nope, I will not do that.











{kind=link}