As one of the last living dinosaurs on the planet still using text-based email clients, I realized that pine has been replaced by alpine and I upgraded to that. When doing some reading up on the subject, I noticed that there’s another old grumpy guy still using this client. I’m not sure exactly what that says…
Anyway, the upside of this switch is that this client is now distributed under a proper open source license (Apache license 2.0), as that’s what I’ve been getting in my face from mutt users for years when I’ve explained what I use! (I mean the complaint that pine wasn’t proper open source)
The great guys at scan.coverity.com published their Open Source Report 2008 in which they detail findings about source code they’ve monitored and how quality and bug density etc have changed over time since they started scanning over 250 popular open source projects. curl is one of the projects included.
Some highlights from the report:
curl is mentioned as one of the (few) projects that fixed all defects identified by coverity
from their start, the average defect frequency has gone down from one defect per 3333 lines of code to one defect per 4000 lines
they find no support to backup the old belief that there’s a correlation between function length and bug count
the average function length is 66 lines
And the top-5 most frequently detected defects are:
We have a sort of symbiosis between the curl project and the PHP project, at least we in the curl project get a lot of people learning about curl the first time when they hack PHP. This happens to the extent that to a lot of people, curl is but the name of a PHP extension.
So while we can thank the PHP project for referring us a bunch of users that might not otherwise have found us, there is also quite some “friction” or perhaps better called “disagreements” between our projects and how we (don’t) interact.
name
CURL vs libcurl vs cURL. We only ever use the funny casing cURL when referring to the cURL project. The cURL project produces curl and libcurl. curl is a command line tool and libcurl is a file transfer library.
The PHP team provides and distributes an extension they call CURL which is a libcurl binding for PHP. This naming causes a great deal of confusion to PHP users who go to the curl site only to find that it isn’t at all devoted to (just) the PHP extension but instead there’s mostly a lot of other curl stuff there!
I’ve discussed this naming issue with the PHP team on several occasions but they don’t agree with me that this causes confusion, and even if it would cause confusion they seem to be of the opinion that it doesn’t matter since the PHP users should find all their info about CURL and related matters on the PHP site and thus it doesn’t matter what the curl site shows or not. (Or something similar to that, I really don’t mean to put words into their mouths so you better ask them about this to get their real and unaltered view – see my link to an old conversation for some info.)
I tend to call it PHP/CURL just to make sure it is clear that we’re talking about the binding. This of course also confuse users since that’s not what it is called in the PHP documentation…
irony
PHP themselves recognize the problem of related projects borrowing the name, so they forbid derivate projects to include “PHP” in their names. Clearly stated in paragraph 4 of their license.
versions
The binary build of PHP for windows have libcurl built in statically with the curl extension code, so people can’t easily replace the libcurl version used by PHP. And in general, Windows people using open source are much less likely to ever build anything on their own in my experience.
PHP 5.2.6 was released on May 1st 2008 still has libcurl 7.16.0 built into the Windows version. That libcurl version was released in October 2006 and right now we have released eight (8) releases after that one. All of them including many bug fixes. This is more than slightly annoying.
support
This isn’t anyone’s fault but… there really aren’t many PHP people who are involved or care about the libcurl binding so those who have PHP/CURL problems tend to ask questions on the curl-and-php mailing list and in the #curl IRC channel but there aren’t any PHP insiders around in those areas to answer PHP questions…
development
Is it just my imagination or isn’t there a lot of PHP users that have asked for the same features in the PHP libcurl binding for a long time by now, but really very few actually step forward and make a difference? So these features remain unfixed and not added. This is even “just” a binding, nothing of the really hard work is done in the binding itself… It might just be me and my head, but the ratio for doers/plain users in the PHP world seems to be exceptionally low in comparison to many other open source areas I see. Of course this is tainted by me only really seing the PHP/CURL side of the PHP world.
future
I have no reason to expect anything to change, nor do I know how I can make anything of this change on my own so I assume things will just continue working exactly like this in the future as well…
There’s one thing the GNU project has done wrong (and thus the followers of it, like the Debian Linux distribution and others) and it is with their stupid preference to not provide proper man pages but instead insist that the user runs “info [whatever]”. In Debian you also very often have to install a separate doc package to get those info files, and I fail to see the logic in providing tools and libs etc without the proper docs. (and in fact in many cases the info page shows the man page until you get that proper package installed!)
Man pages may not be the best format in the world for docs, but I rather have a proper man page for all commands and then I’ll go html online for extended information. Info is just plain annoying and we should bury it. The sooner the better!
And yes, it is not a coincidence that no project I’m actively driving as a proper contributor are producing any Info documents…
Less is more it is said, and I can certainly subscribe to the reverse: more means less. The two primary open source projects I spend time in have been growing the last years, in source code contributions, but also in amount of users and in amount of contributors. I see the similar effects on myself and on my own role in both Rockbox and curl: I do more and more coordination, planning, admin work, talk (chatting on IRC, responding to mails etc) and “guidance” than actual coding work. My code/non-code work ratio has decreased massively.
This is not complaint, just an observation!
It makes sense to me that early on in a project, and until there’s enough momentum to get the project to more or less drive itself, it is important with a driving core that pushes the project forward. That makes sure every little peace fits together and gets the proper attention to make it a good product and project. As time goes by, more and more people get that knowledge, that ability and the amount of people that drive the project forward increases.
So being an “elderly” in both these projects, I’m more of an advisor, talker, tinker, admin, than a lead programmer now. This is at least most notable in Rockbox, since we have 80 committers now and I think at least 50 of them are active.
I probably spend roughly the same amount of time: somewhere around 2-3 hours/day on my open source projects.
Of course, in my particular case exactly now, I’ve also just recently ramped up my working hours and find myself trying to get accustomed to this life with full-time work, a two-kids-and-wife family and several time-consuming spare time projects. It takes a great deal of juggling and less sleeping.
Nothing is forever so I’m certain my situation will change over time. I’m determined to continue hacking in both projects. And my juggling skills will improve…
I find it noteworthy that the FSF runs a campaign they call playogg in which they detail the importance and stuff why people should avoid non-free formats and instead use Ogg Vorbis in preference to mp3 for example.
Yet, they document a number of alternatives for Mac users, for Windows users etc on the front page, but there’s not a single word of advice for people with portable music players. Then again, it is very hard for people to find free software alternatives to their portable music players and FSF being so very anti-closed source this makes me wonder why there’s no mention of Rockbox, ipodlinux or even sansalinux to be found?
The only place with this info that I could find when following links from their site, was about three clicks away on xiph.org’s PortablePlayers wiki page but the majority of the stuff mentioned there is non-free…!
Personally, I’m not convinced when I see TI speak of Open Source since I’m fully aware of their history and I even believe that this brand new “open” platform still requires TI’s restricted-but-free compiler for the DSP. Of course it is more open than many other platforms, but I dislike when someone tries to sound all fine and dandy while at the same time they’re trying to hide some of their better cards behind their back.
A truly open platform would not give TI an advantage. It would offer anyone wanting to do anything with it the same chance. This platform does not. After all, having it built around one of SoC flagships should be enough for them and should be a motivator for them to make this as successful (and thus as open) as possible.
I think it is sad that Neuros repeatedly does this kind of statements. Their original “open source” player was never open source (to any degree). Their OSD player is largely open source but huge chunks of it is not. Now they try to announce even more openness for an entire platform and yet again they fail to actually deliver a truly open product. Neuros shall forever be known as the company who seems to want to do right, but always fails to in the end nonetheless.
Update: Joe replied on the list to my question about the DSP tool(s) and it certainly sounds as if TI may in fact release a more open tool and/or even a gcc port!? If that turns out true it will of course squash most of my complaints here!
On March 20th 1998 curl 4 was released. It was the first curl release ever even if already at version 4 since we kept the version number from the previous projects we did before curl – using other names. We started it all with having the tool named httpget (which was an existing small tool written by Rafael Sagula), soon changed name to urlget to end up with curl – all renames happening due to shifting features and focus.
Like many other projects, this started because of an itch. I wanted to get currency rates off the internet to allow an IRC bot to be able to provide an “exchange service” for users with accurate up-to-date rates. I thought the existing projects I found all did too much or did the wrong thing. That bot and service is now gone since long.
curl has been a truly portable project from day 1, and the first windows build was already urlget 2.1 (pre-curl). autoconf support for the build process was added in October 1998.
Unfortunately I don’t have the original release 4 tarball left anymore, the closest one I have is curl 4.8 (dated August 31 1998). curl 4.8 is about 3400 lines of code. Today we’re totaling in well over 100K source lines, so it has grown over 30 times!
I had no big plans for curl nor did I think very much about the future of the project. I just added the features I and my fellow contributors wanted to have for the moment. That’s actually pretty much how the project has continued to work. We don’t have many long-term plans for what to do with it, we mostly look just inches ahead of our noses and act accordingly.
During the version 6 period (Sep 1999 – Mar 2000) we learned that curl was getting popular, was useful and worked rather well, so the work on providing a libcurl started. We wanted to offer other applications the ability to use curl’s file transfer powers. Version 7.1 was released in August 2000 and thus libcurl was officially born.
curl and libcurl remained being a rather low-key project, I just work on it on my spare time and there are no full-time developers paid to work on this project – apart from some occasional sub-projects now and then that have been sponsored by companies and organizations. (See later on for an example.)
Slowly but surely more and more people started using libcurl and contributed with bug reports and patches. When the project turned 5 years in 2003 I collected all the names of all contributors so far and I reached the number 270. I found the number very high and I was mostly kidding when I said I hoped we would double that amount by the time we celebrate our tenth anniversary. Of course we’ve more than doubled that amount today when we have more than 620 named contributors so far – and continuously adding new ones with every release.
During this journey of a decade, I’ve remained the lead developer and project leader but we’re now some 10 developers with commit access (that also use it) and I try to be open and responsive in order to attract more developers to come aboard, to listen to their advice and ideas and to be sensitive on what our users want from us.
In 2005 I was lucky enough to get a grant from the Swedish IIS organization for the purpose of developing a new event-based API for libcurl to better deal with very large amount of connections, the problem so nicely called c10k.
In the days when our humble project turns 10, I spend about two hours spare time per day on the project and it is my primary hobby, we make 5-6 releases per year, we get about 7000 unique visitors on the web site a normal day, about one million curl packages are downloaded per year – from our servers.
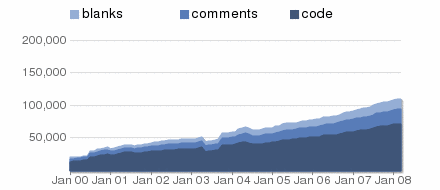
Today, libcurl is feature-rich, portable, very widely used, very fast, well supported and there are no signs of stagnation in release nor development pace. In fact, looking at the source-code growth over the last couple of years we can see a pretty stable and continuous growth:
Just as I never looked ahead and planned for the future much in the past, I don’t do that now either so I really don’t know and can’t tell what the future will hold for us. We’ll just continue to develop the world’s best client-side file transfer library, to make it even more solid for the foreseeable future, to make it do the things users and developers out there think it should do. Possibly that involves adding support for more protocols, removing some of the less popular ones or simply by enhancing how we support the existing ones.
Join the mailing lists and join us for the next ten years to come!
In hard techy interesting terms: they plan to upgrade to Texas Instruments Davinci 6446 chipset, which is a 300MHz ARM9 with a C64x DSP core embedded. Pretty much like the existing DM320 one, but it seems with a great deal of more horse power under the hood. Given their specs paper, it will support a lot of formats and at least partially up to HD resolutions. It’ll also support internal harddrive and offer 256MB RAM and 256MB internal NAND flash.
Personally I don’t care that much as I don’t even have analogue TV and don’t download/have many movies to watch and my existing DVB-T box has fine recording abilities and my DVD is good enough for my kids to repeatedly watch the same animated films over and over and over…
Oh btw, if this sounds like your kind of backyard and other things combine well, Neuros is hiring Linux developers for what I believe is this hardware.
(sorry for the crappy quality of the pic but I nicked it from the PDF)
It is yet again time to pause the add-new-features-craze in order to settle down and fix a few more remaining bugs before we go ship another curl and libcurl release in the beginning of April.
So at March 20 we hold back and only fix bugs for about 2 weeks until we release curl and libcurl 7.18.1.
The only currently mentioned flaw in TODO-RELEASE to fix before this release is the claimed race condition in win32 gethostbyname_thread but since the reporter doesn’t respond anymore and we can’t repeat the problem it is deemed to just be buried and forgotten.
Other problems currently mentioned on the mailing list is a POST problem with digest and read callbacks and a mysterious bad progress callbacks for uploads, but none of them seem very serious and thus terribly important to get fixed in case they should turn out hard-to-fix.
Yes, I picked the date on purpose as that is the magic date in this project. Especially this year.