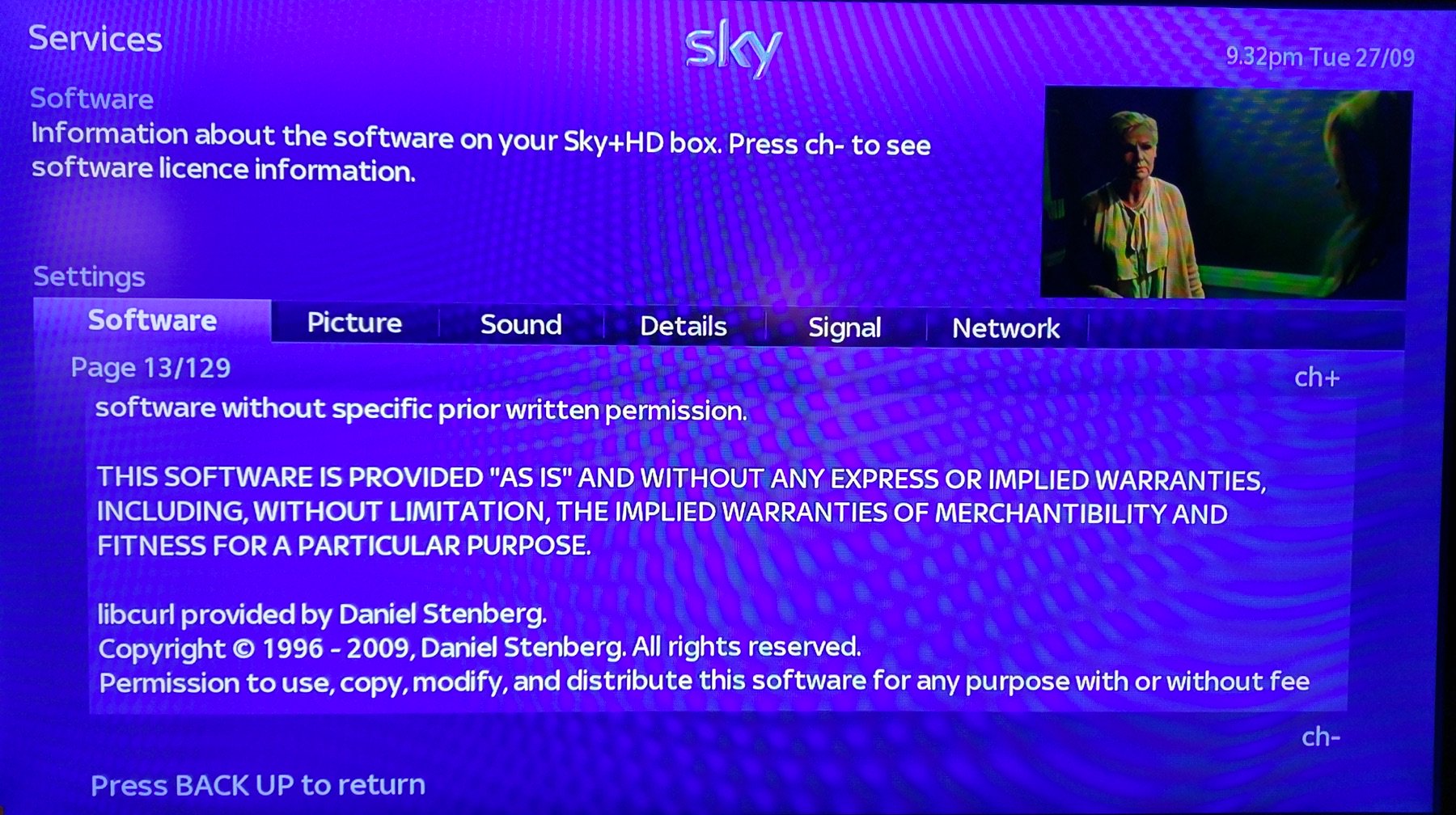
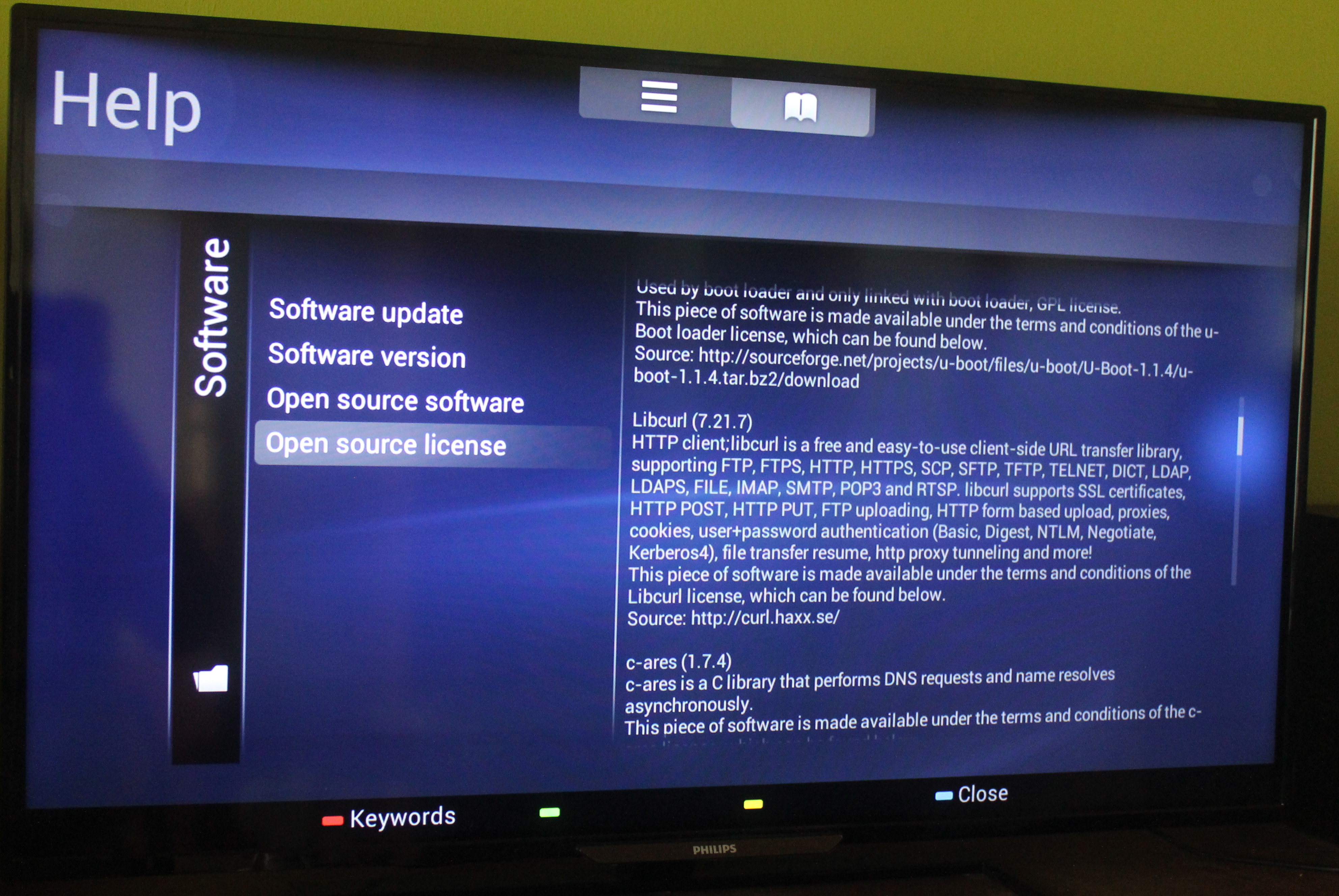
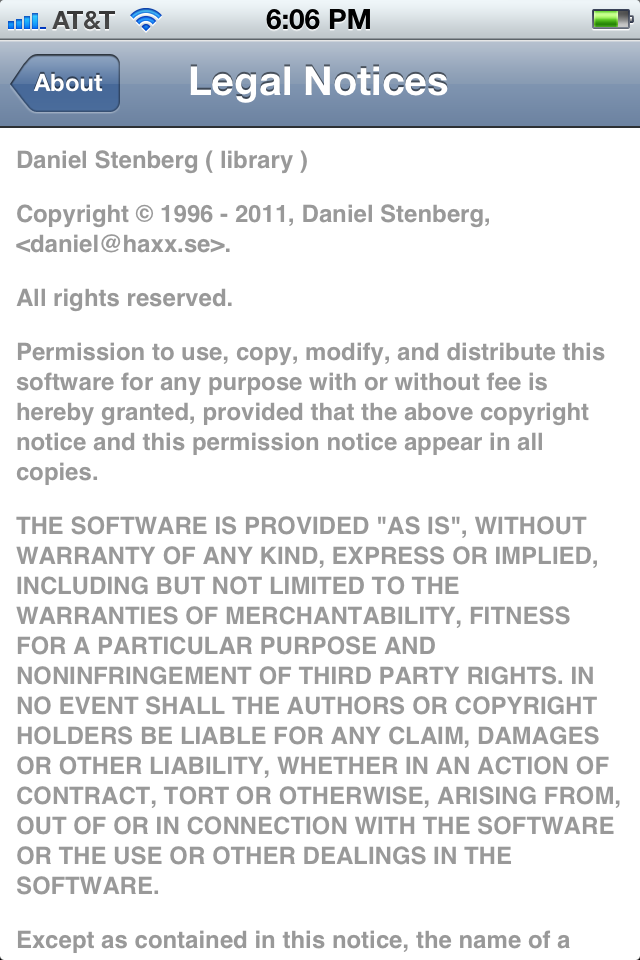
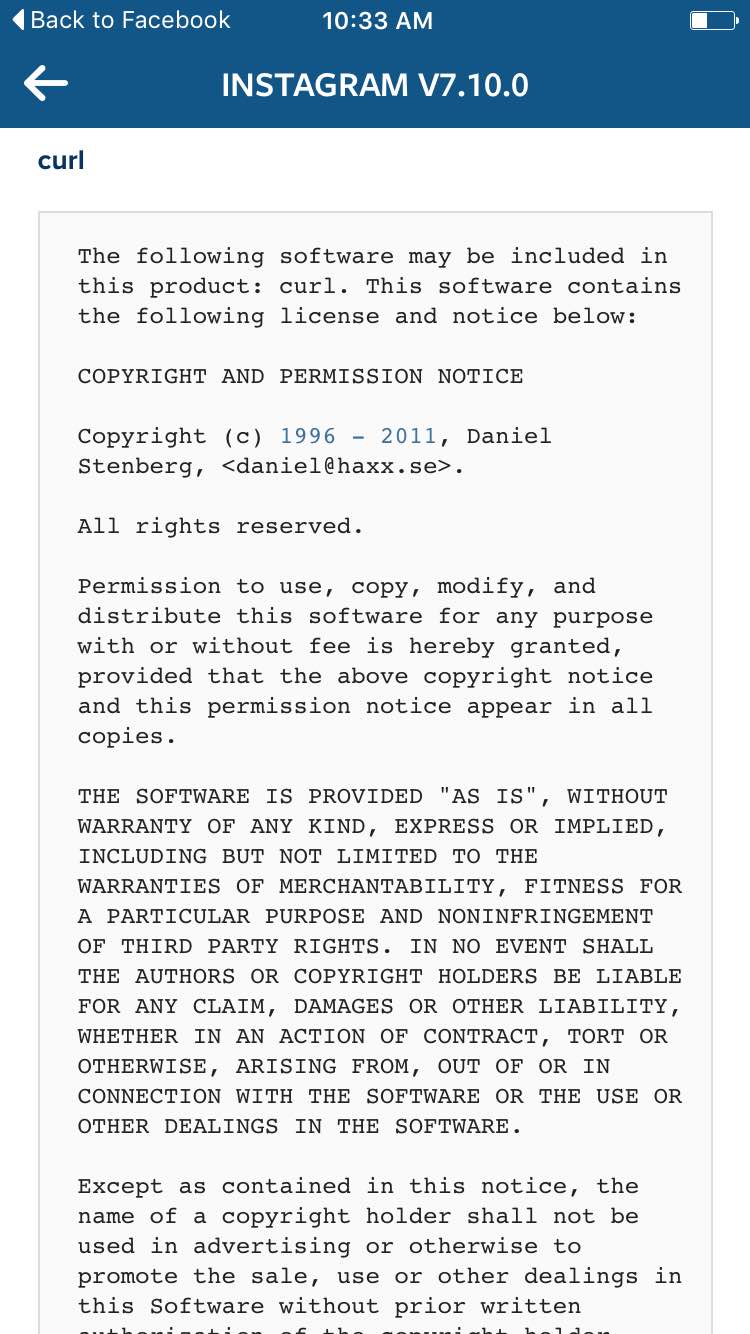
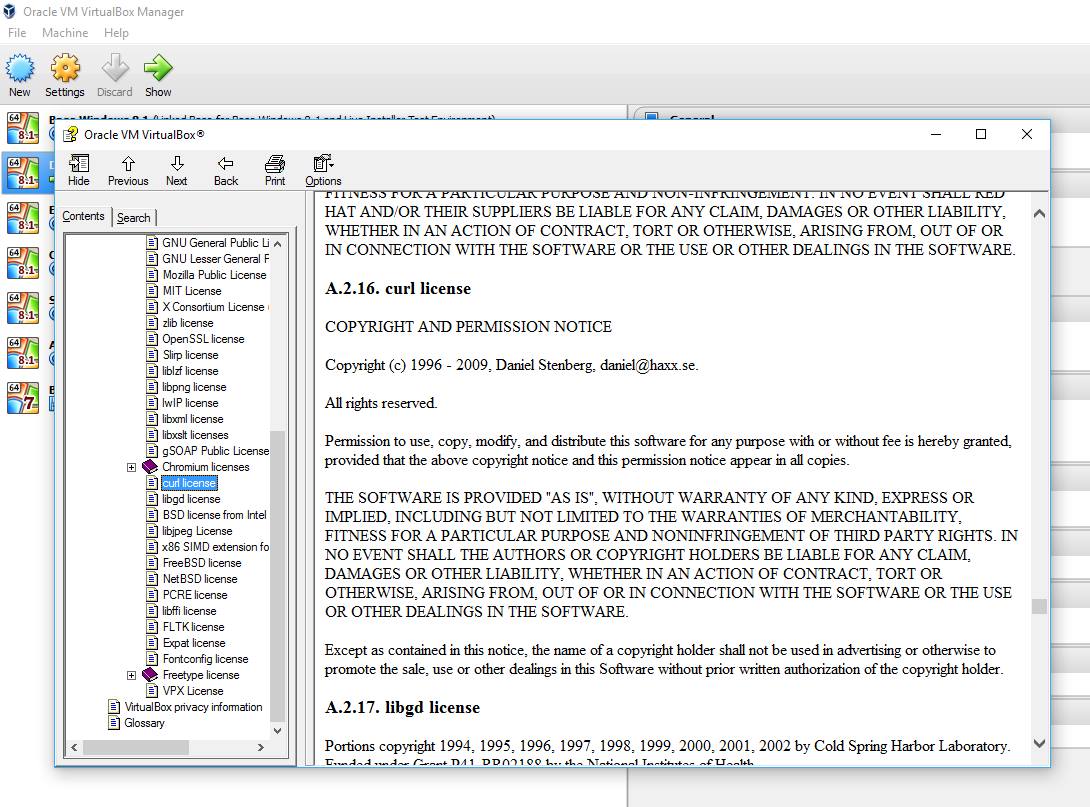
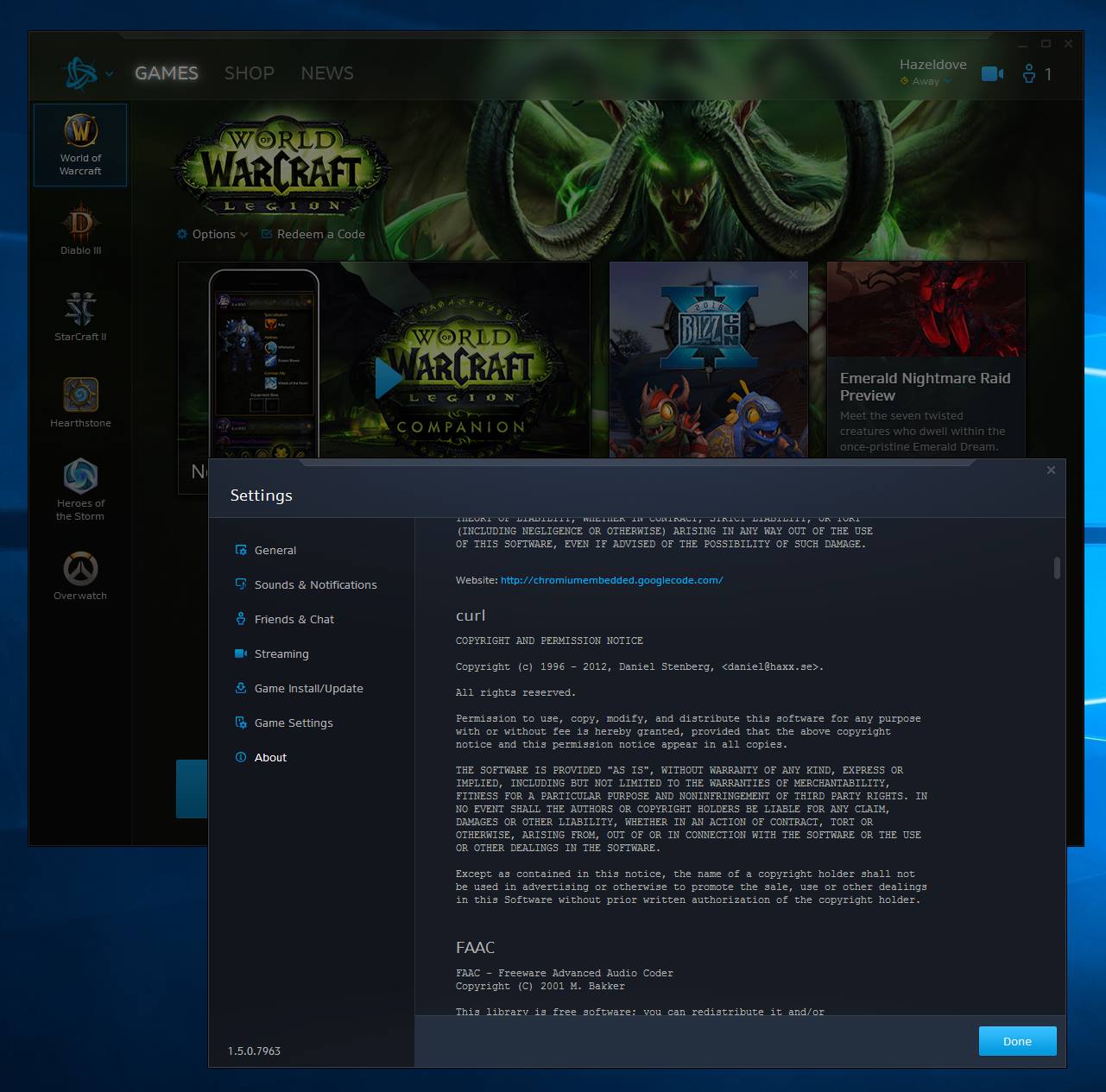
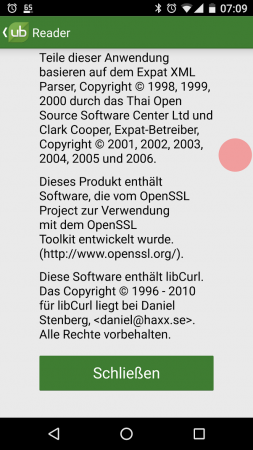
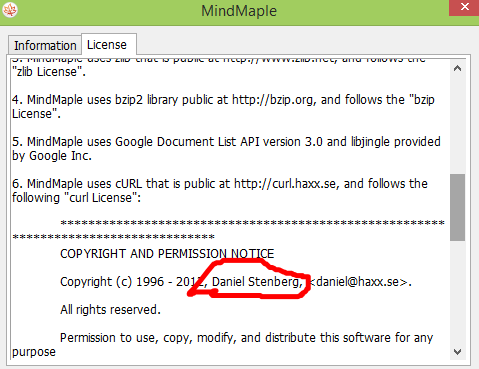
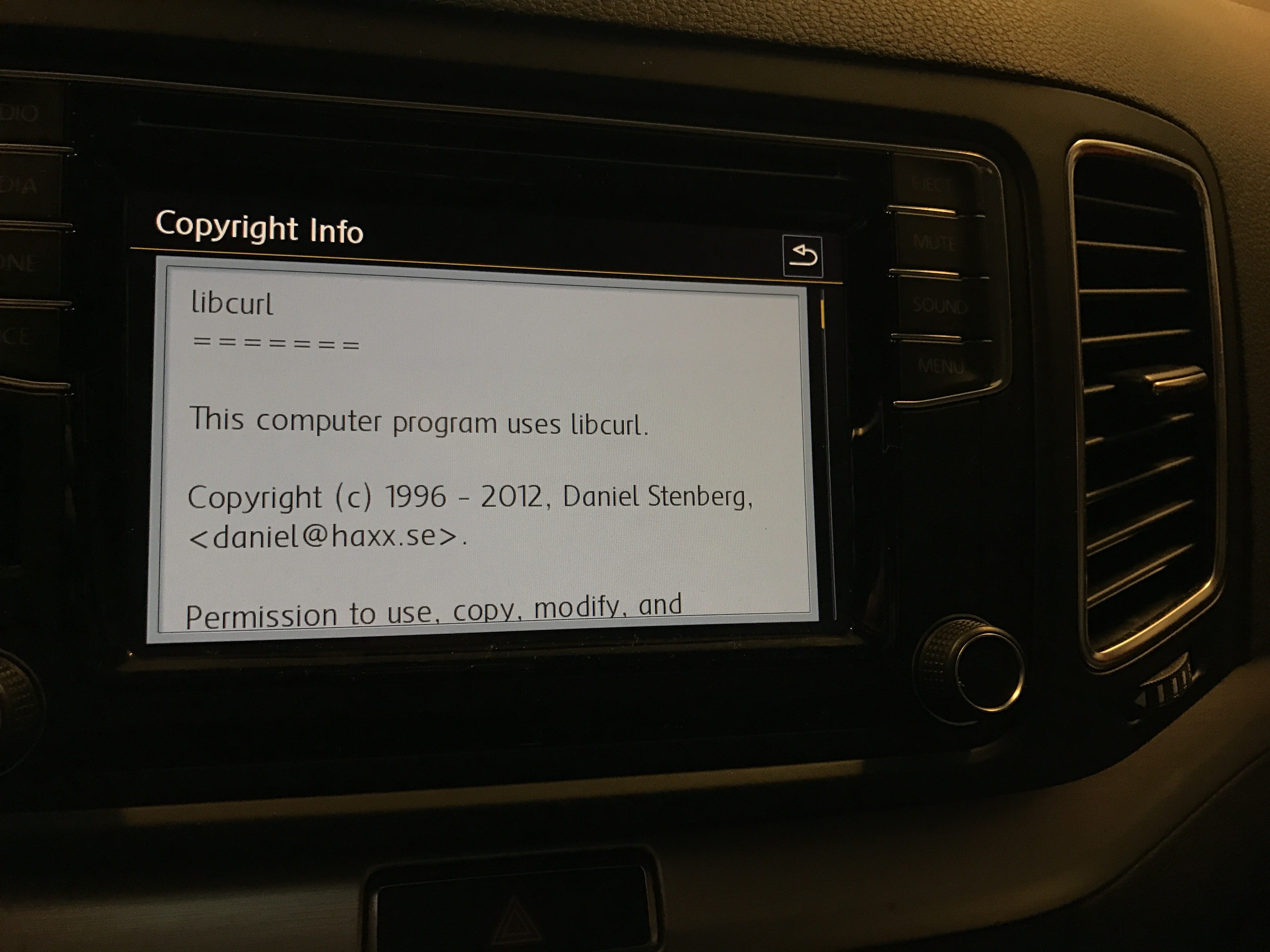
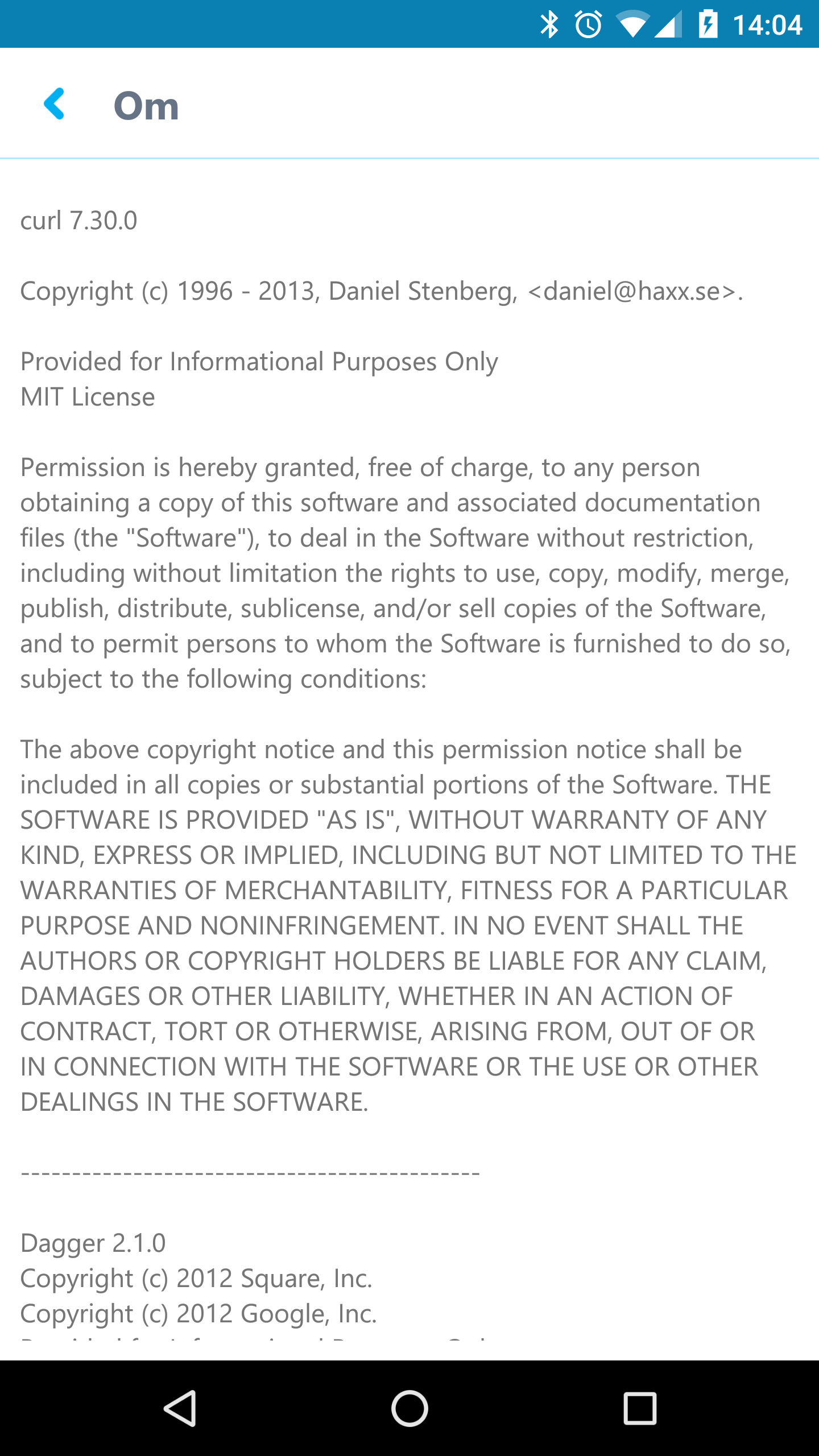
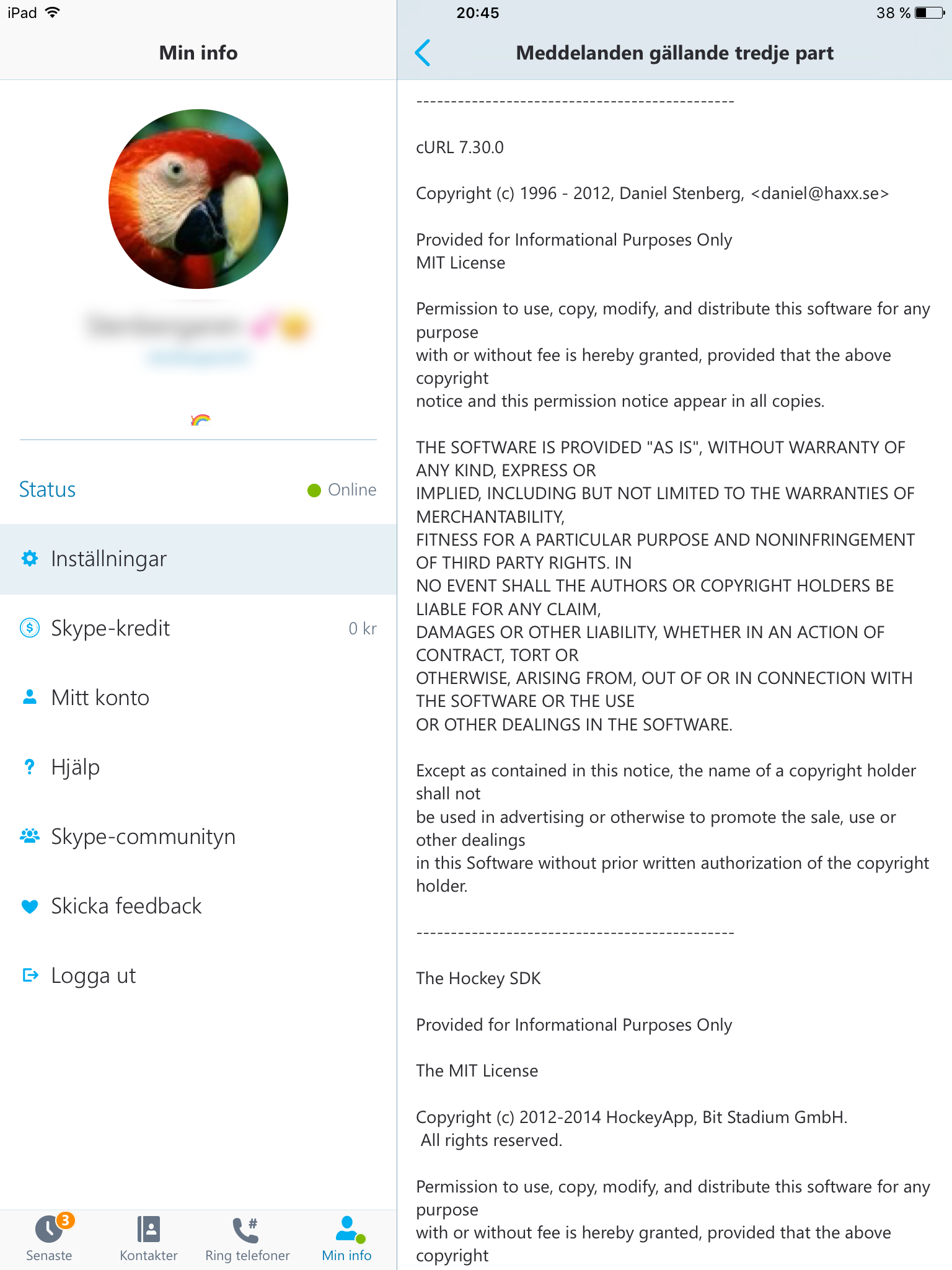
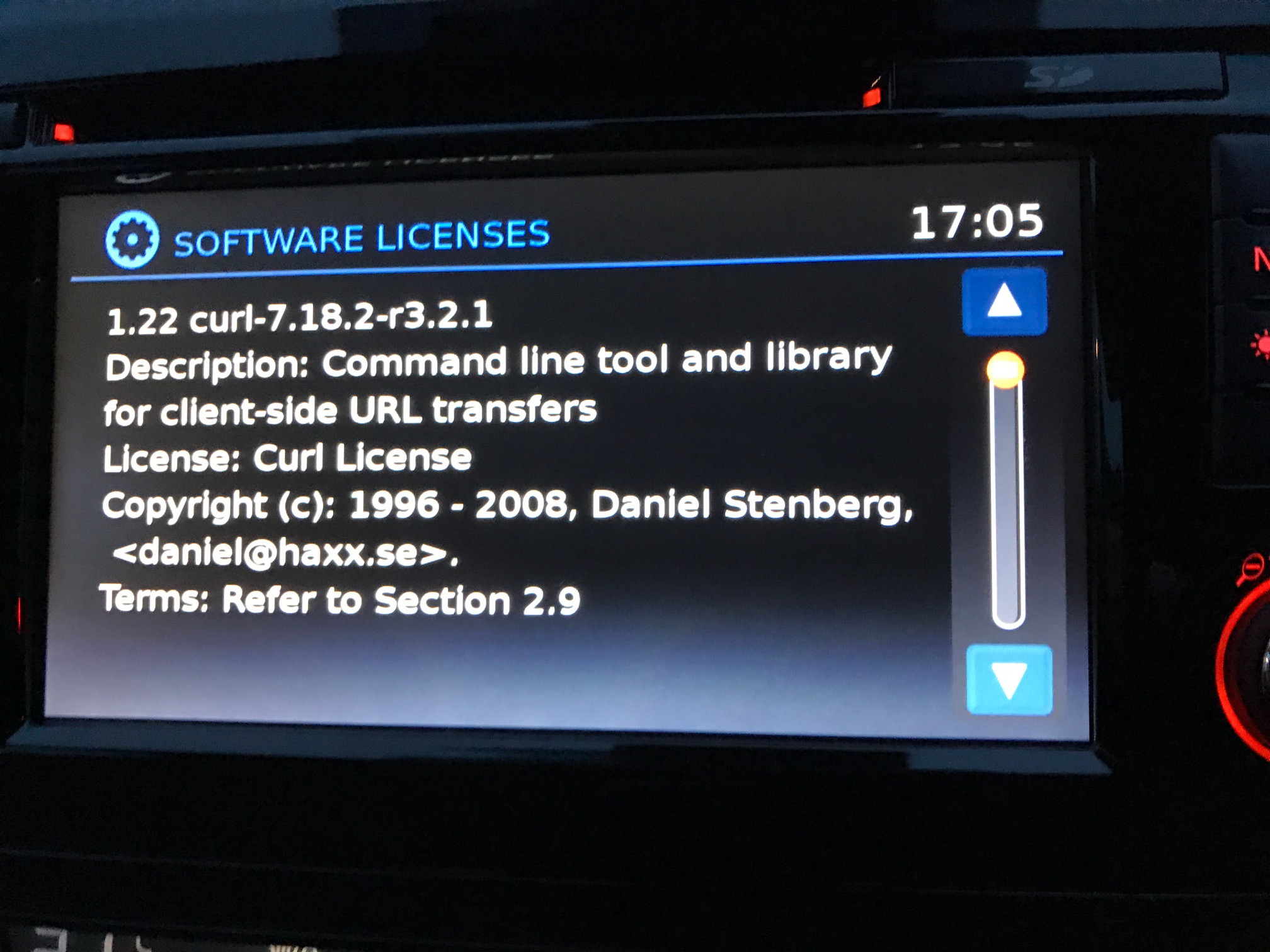
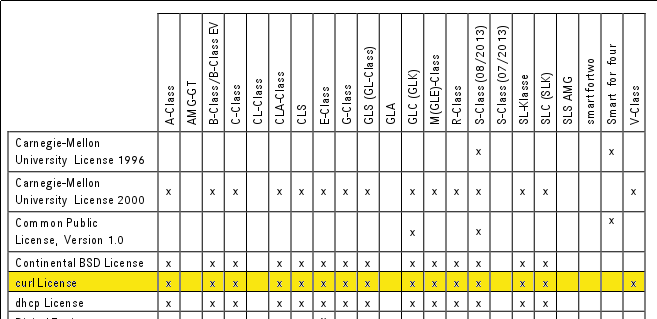
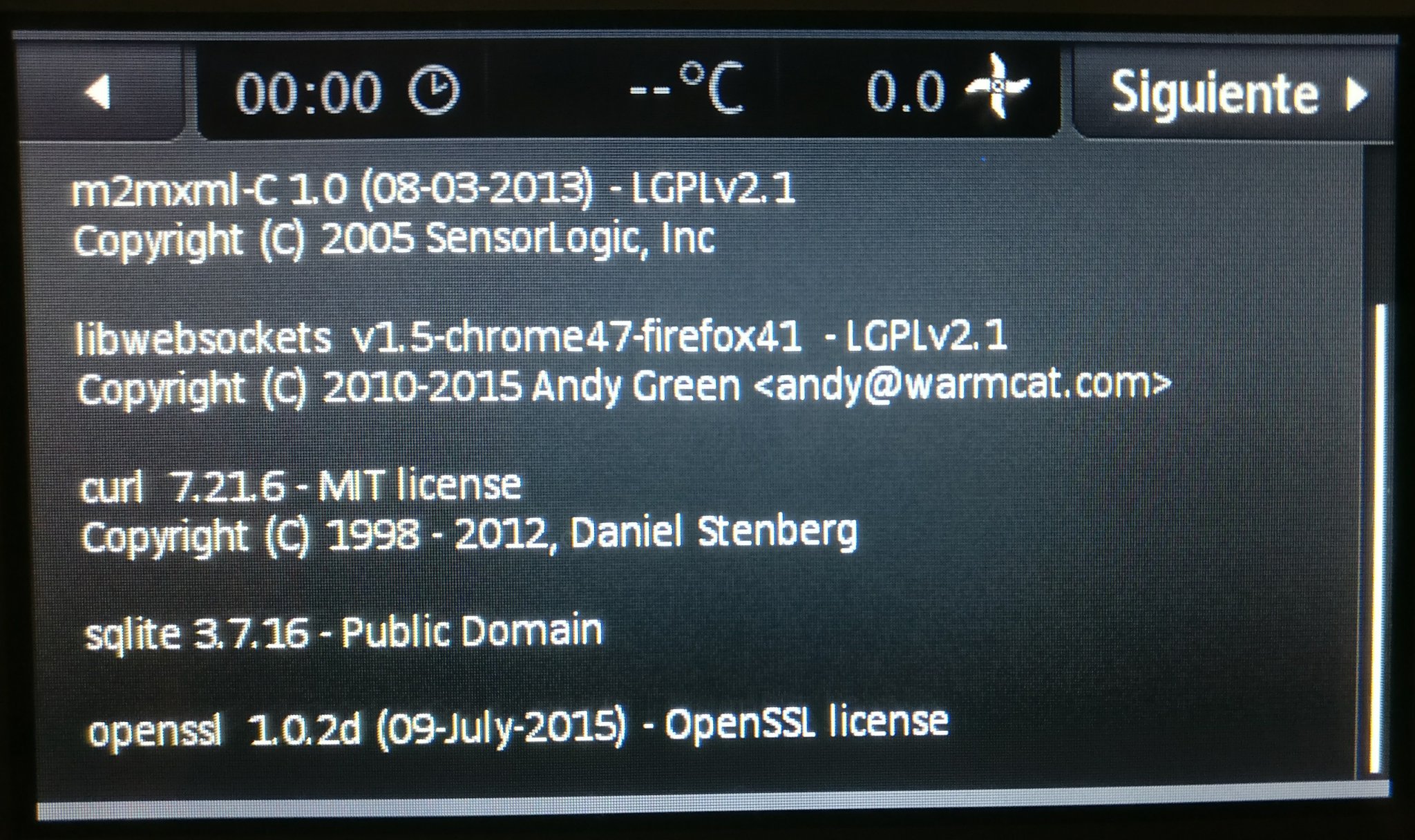
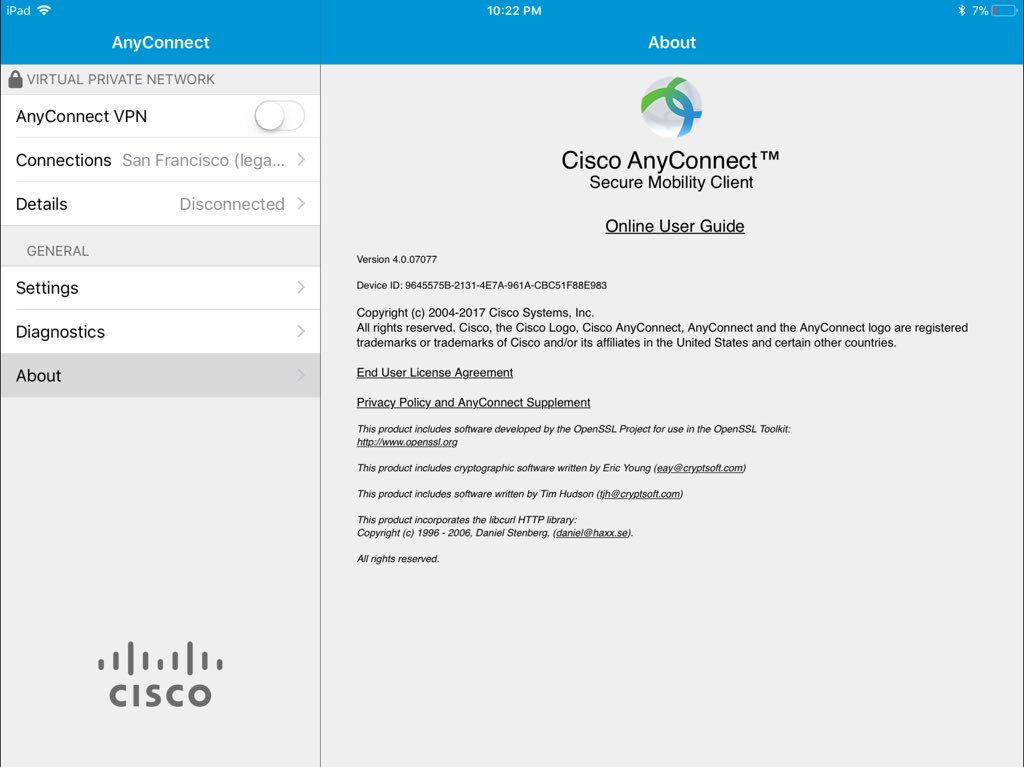
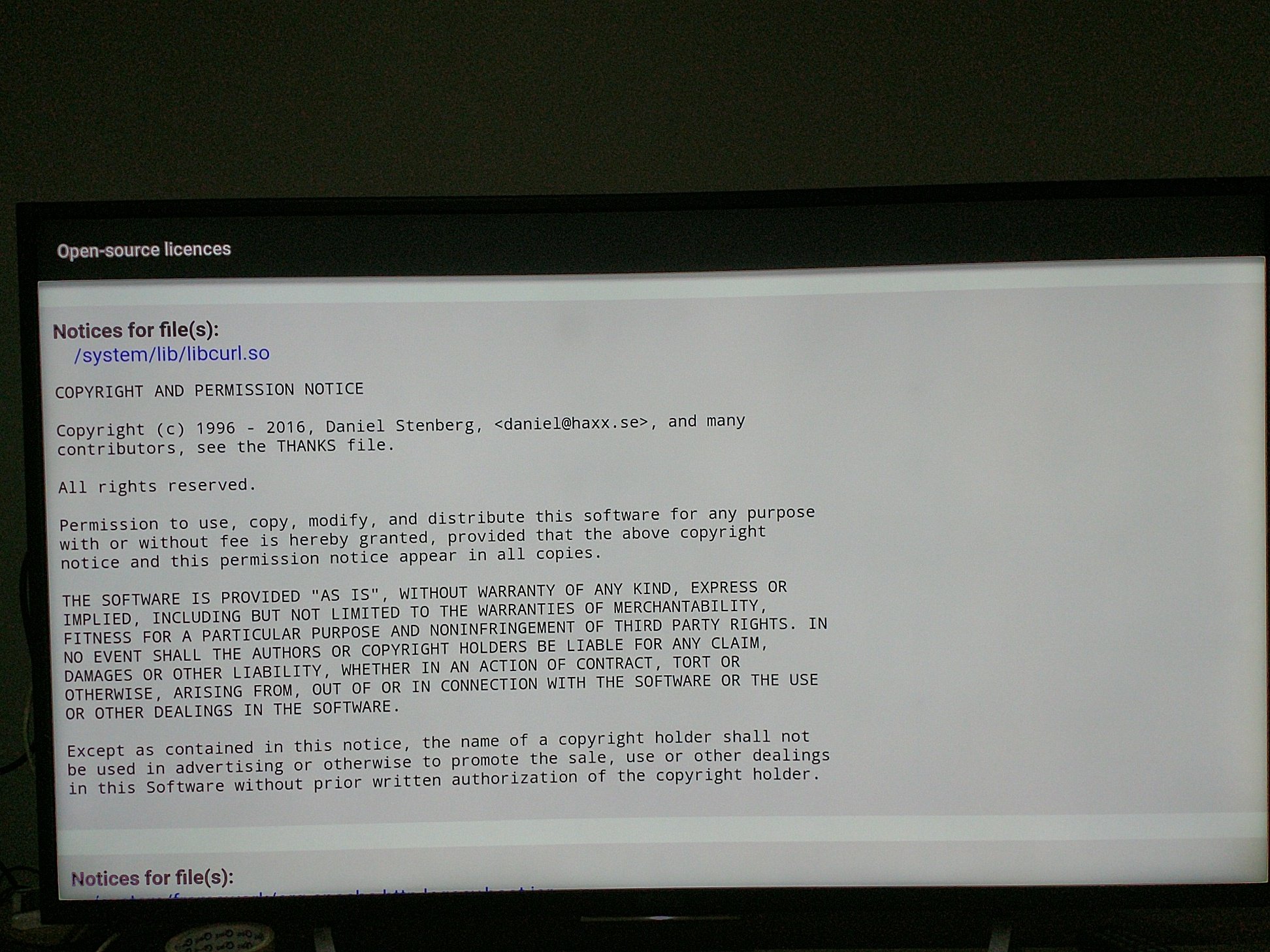
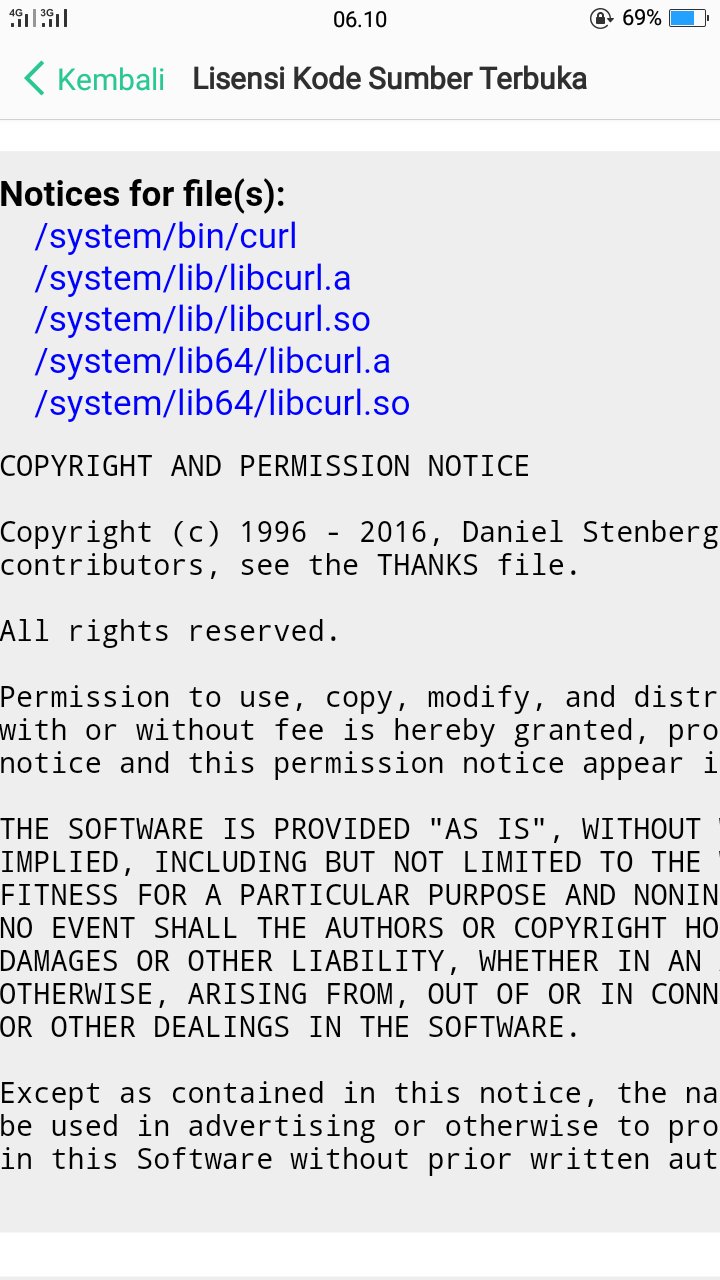
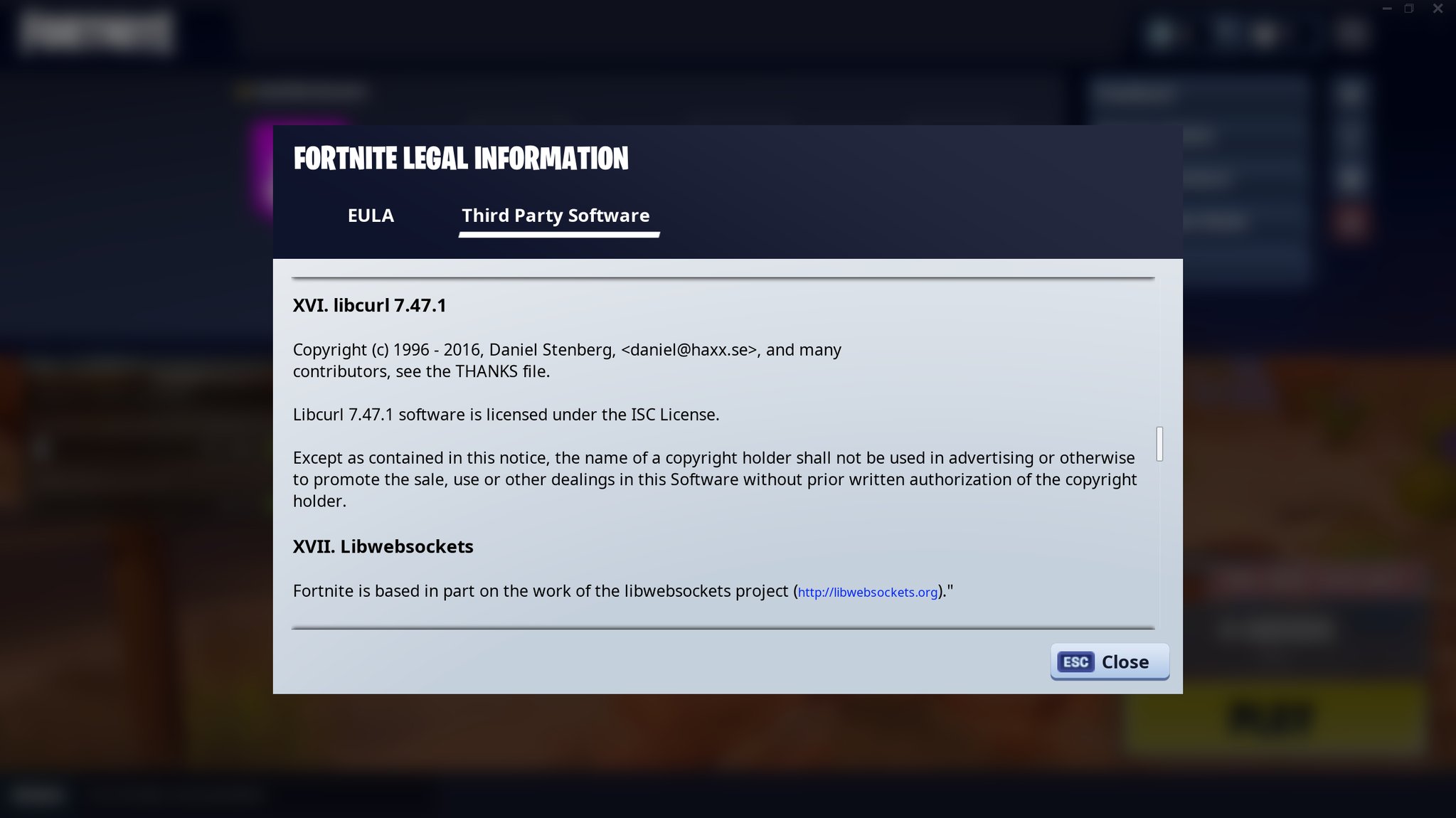
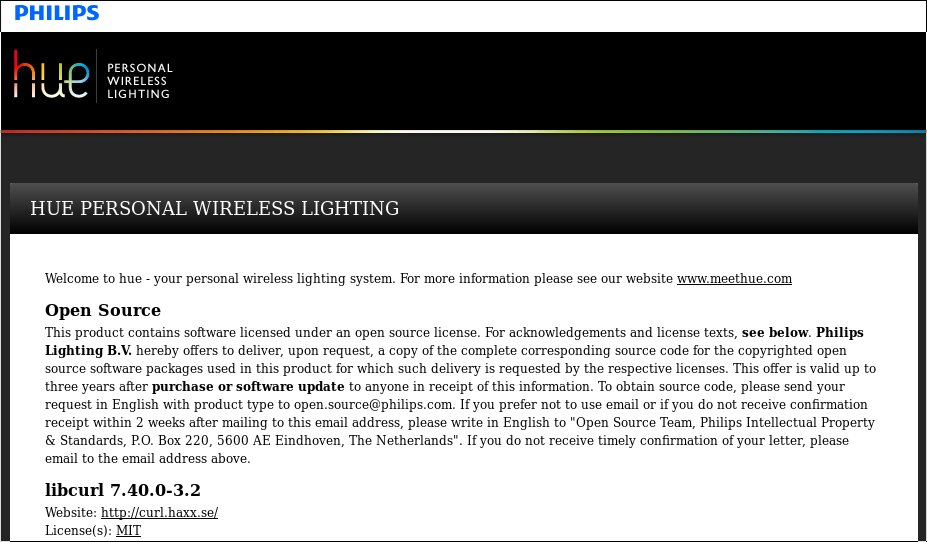
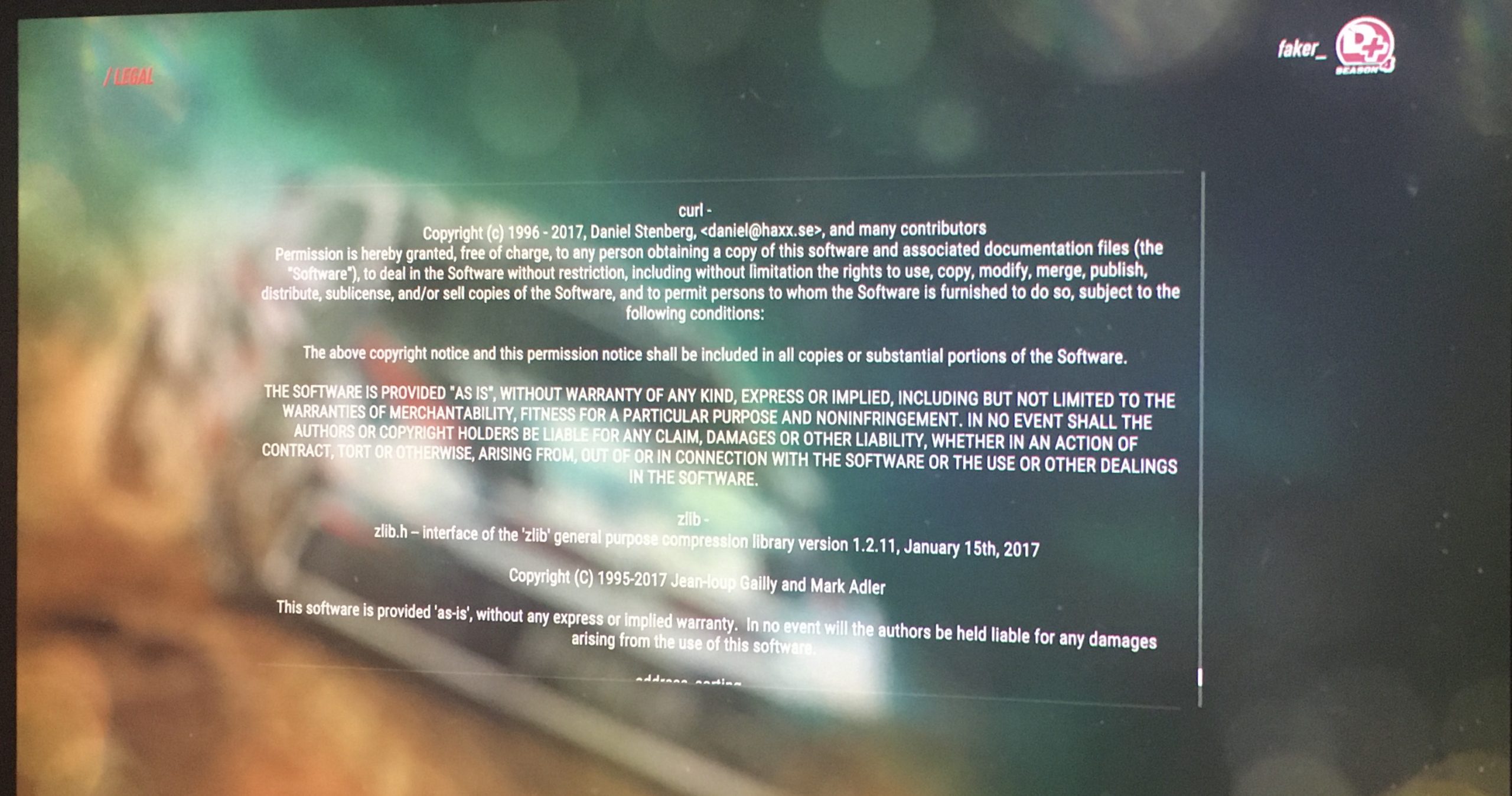
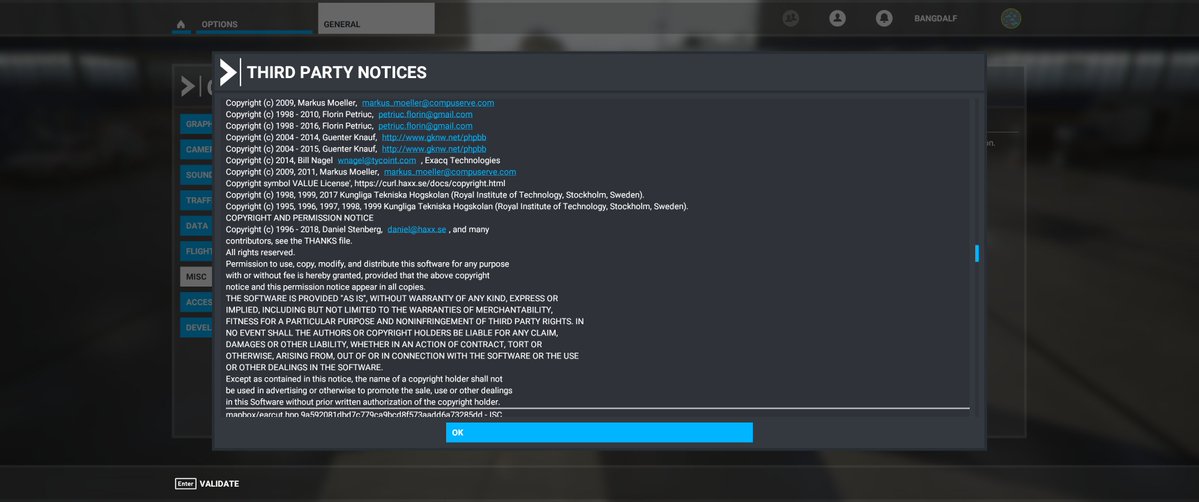
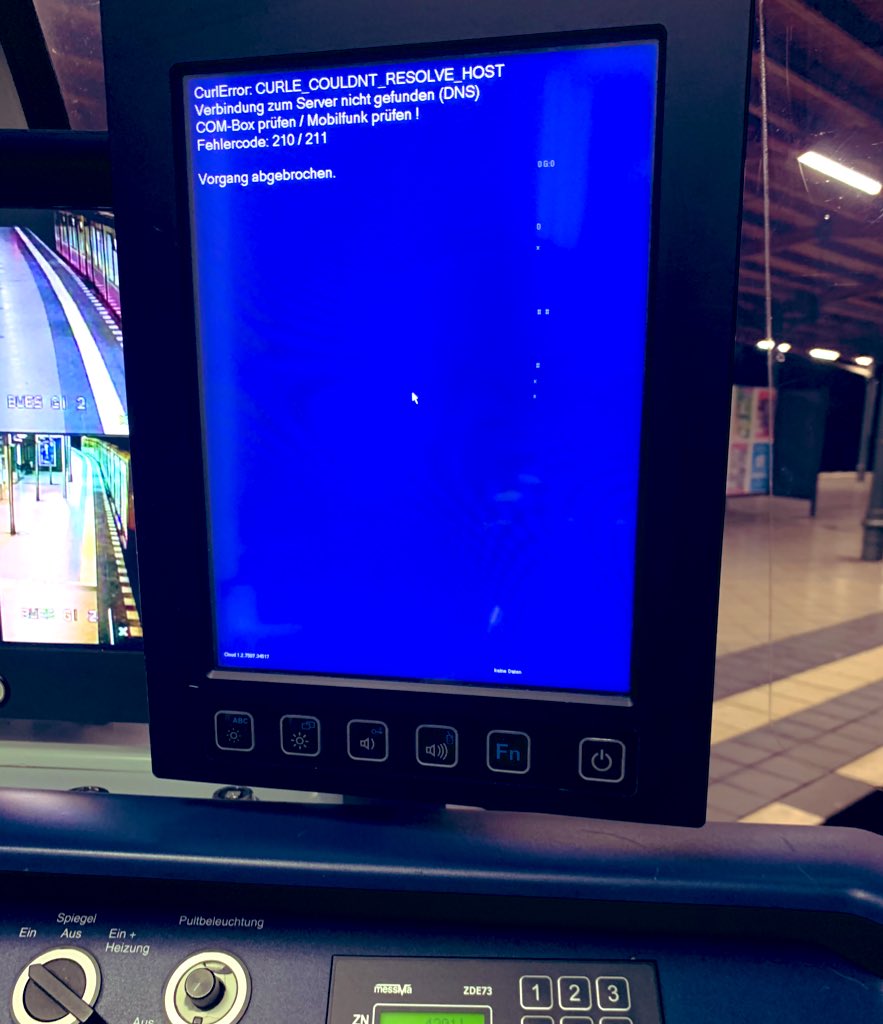
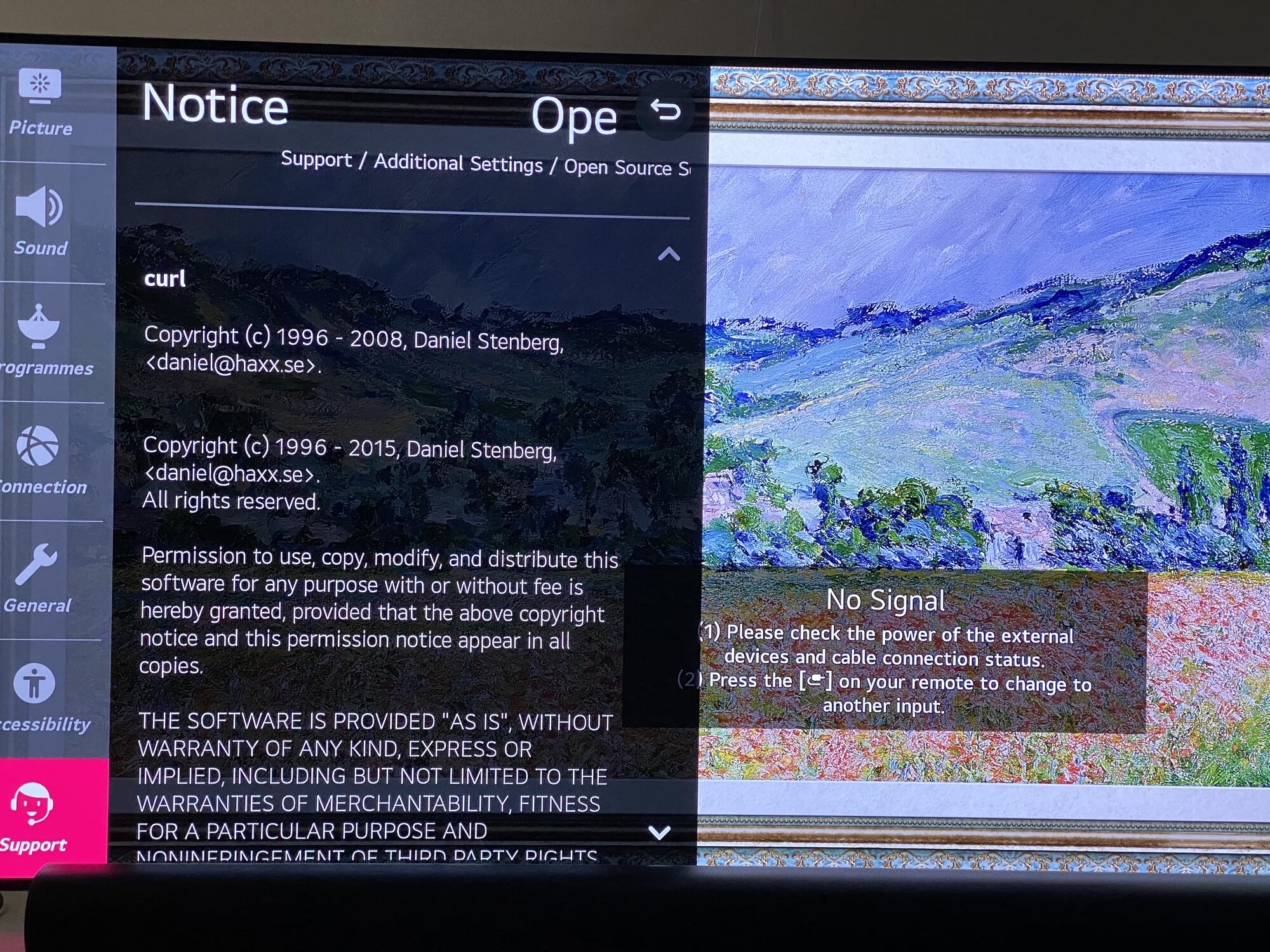
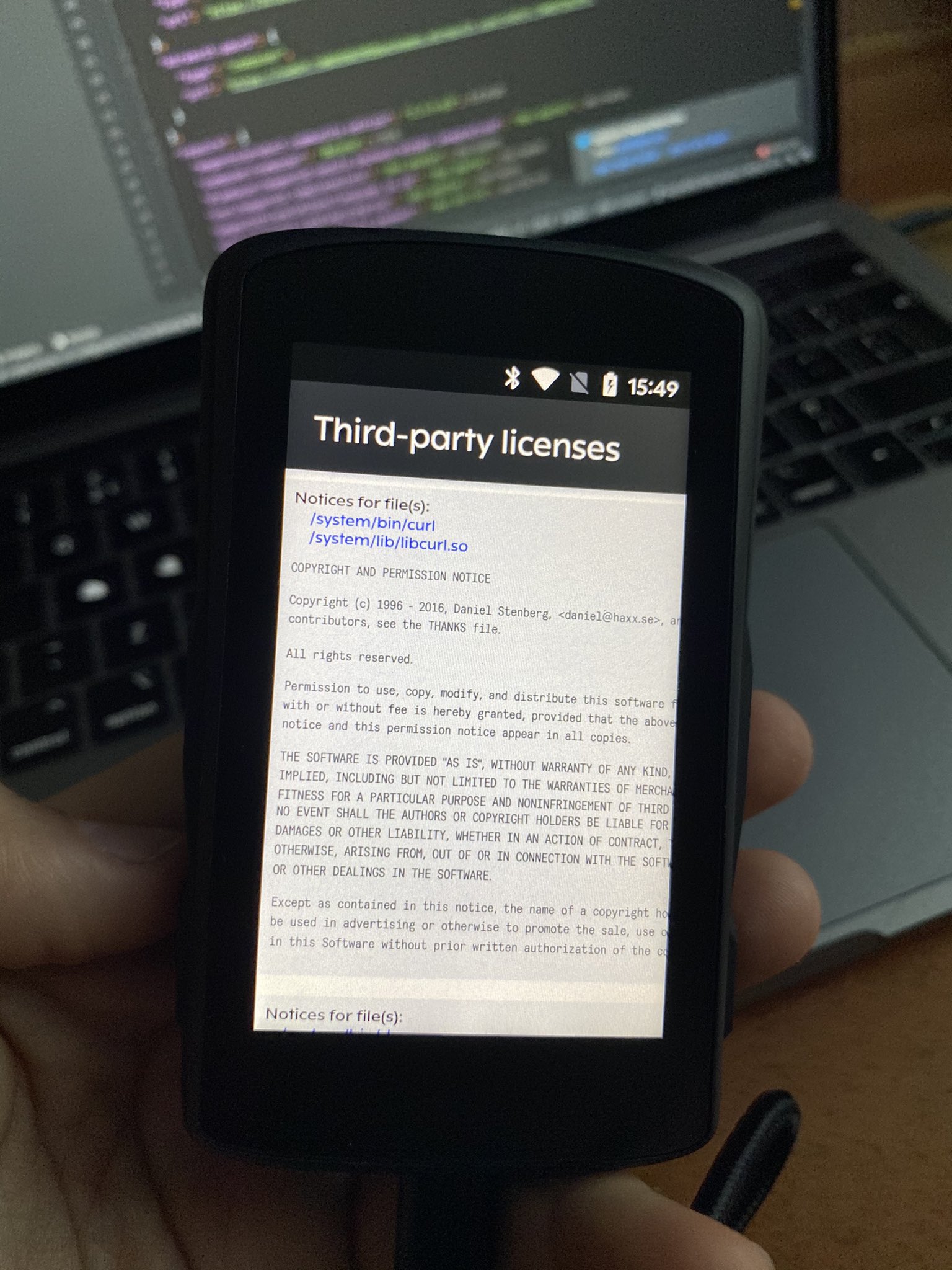
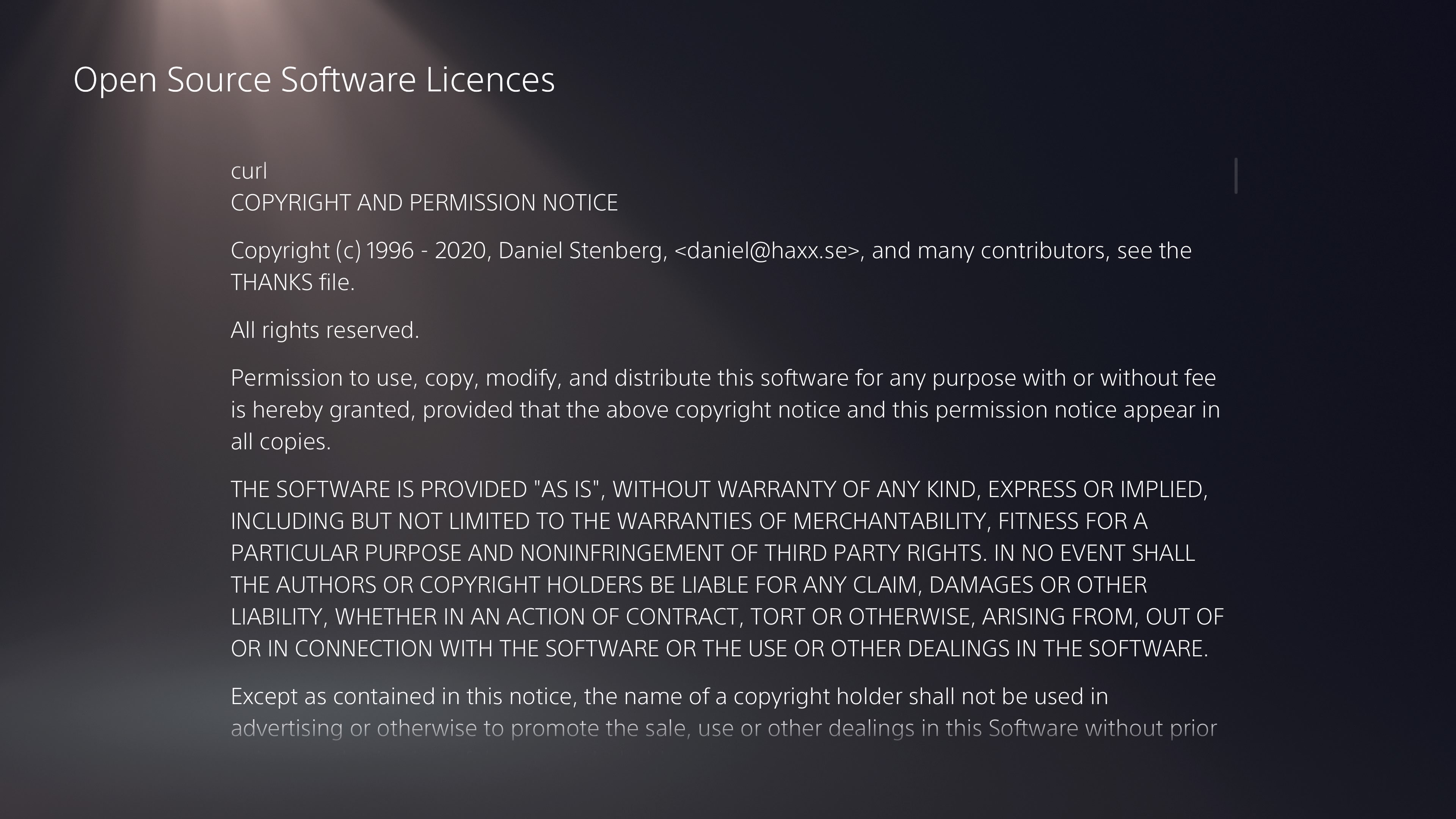
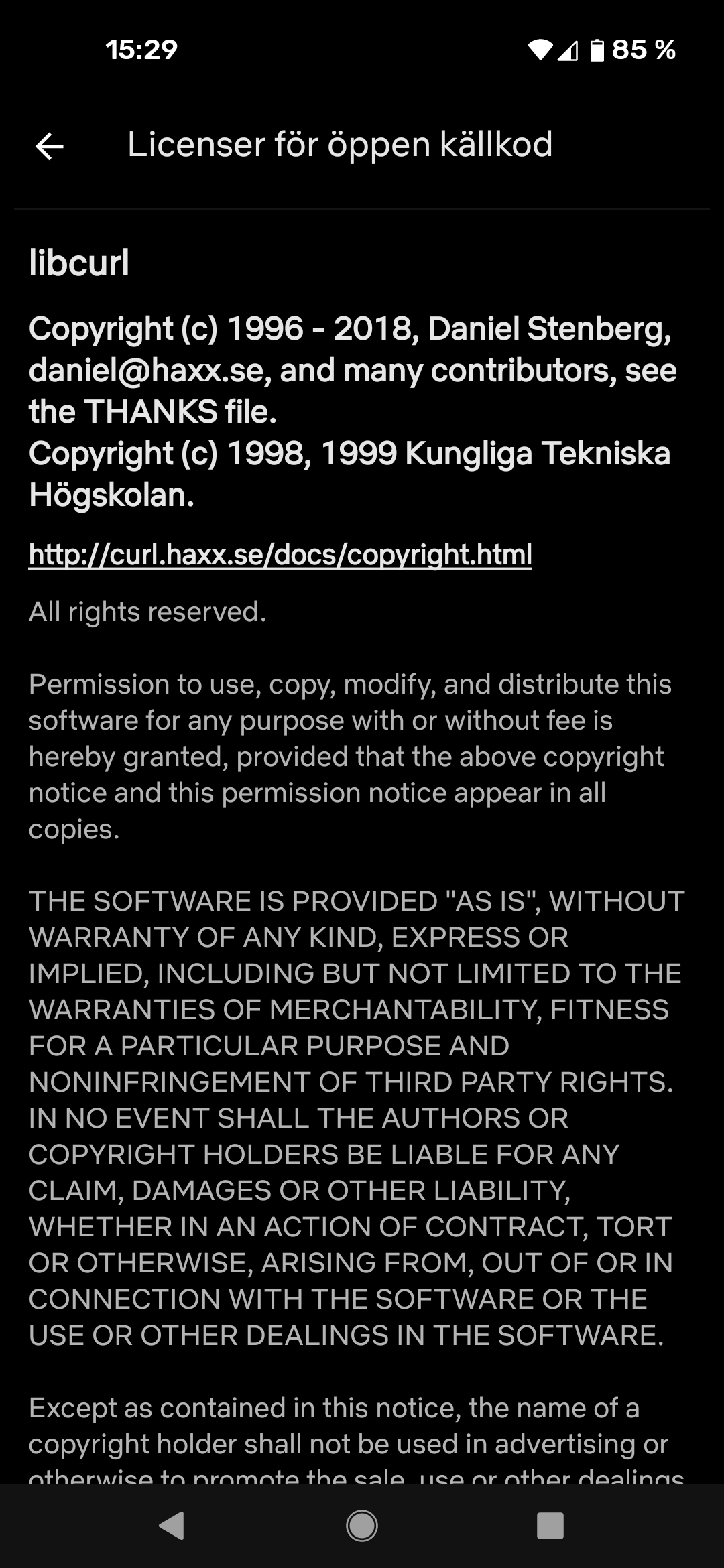
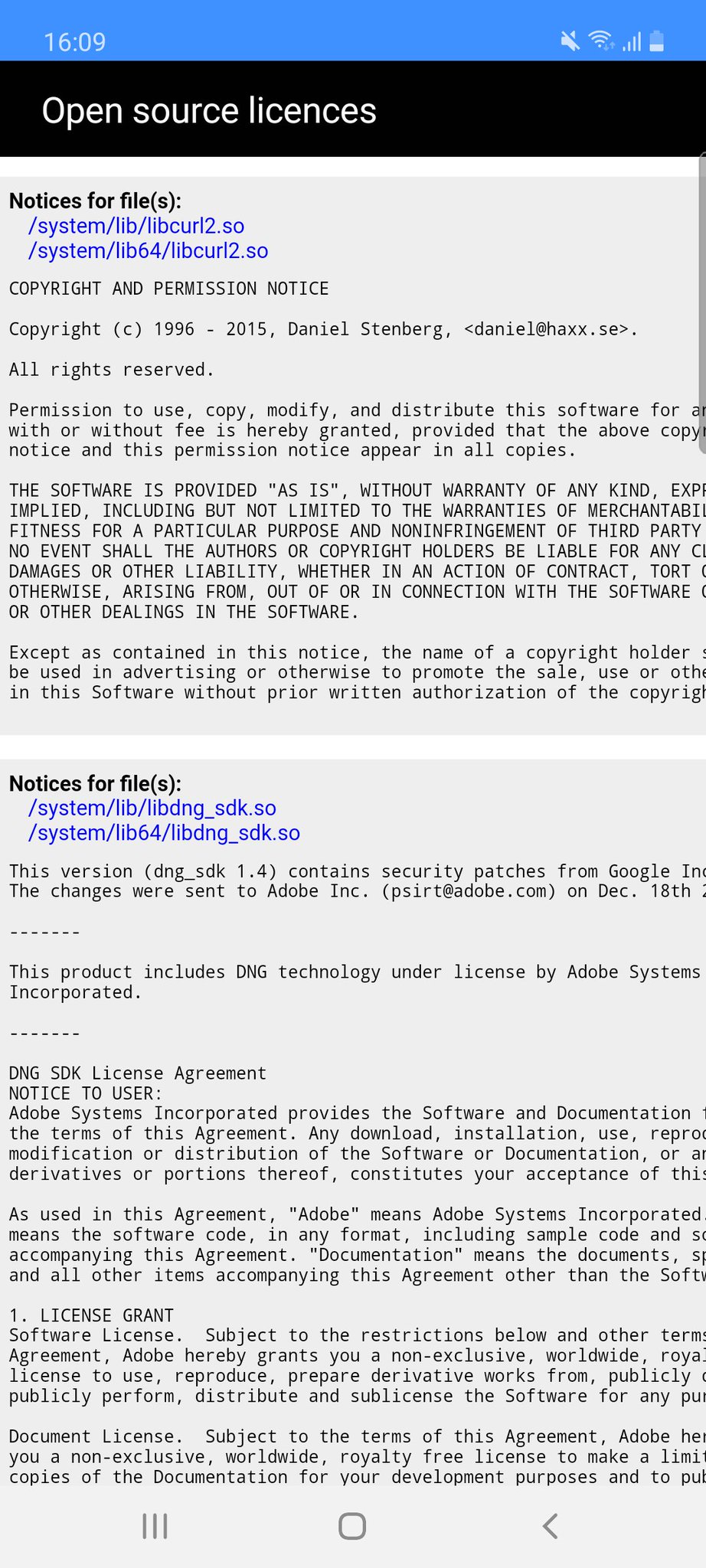
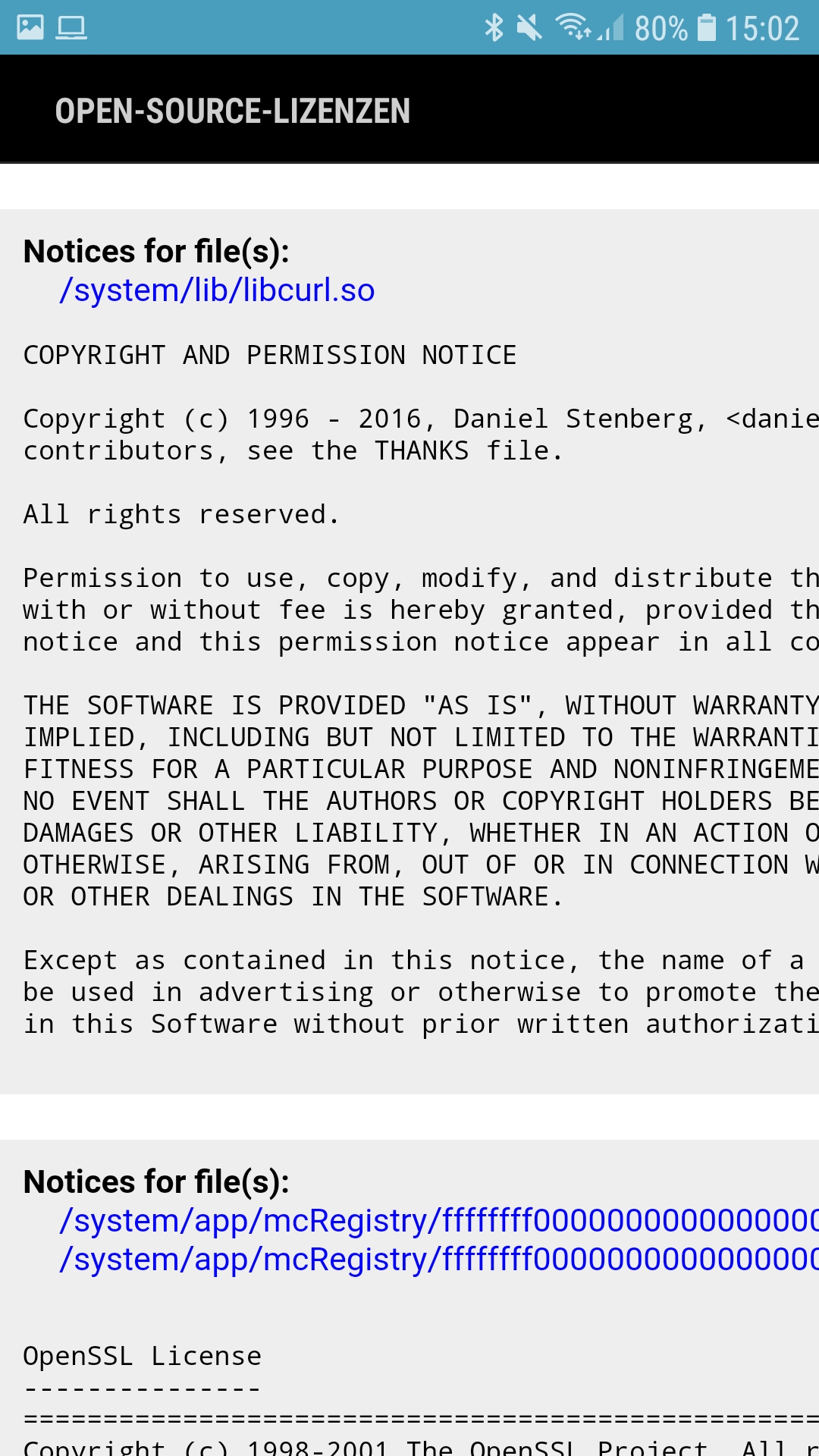
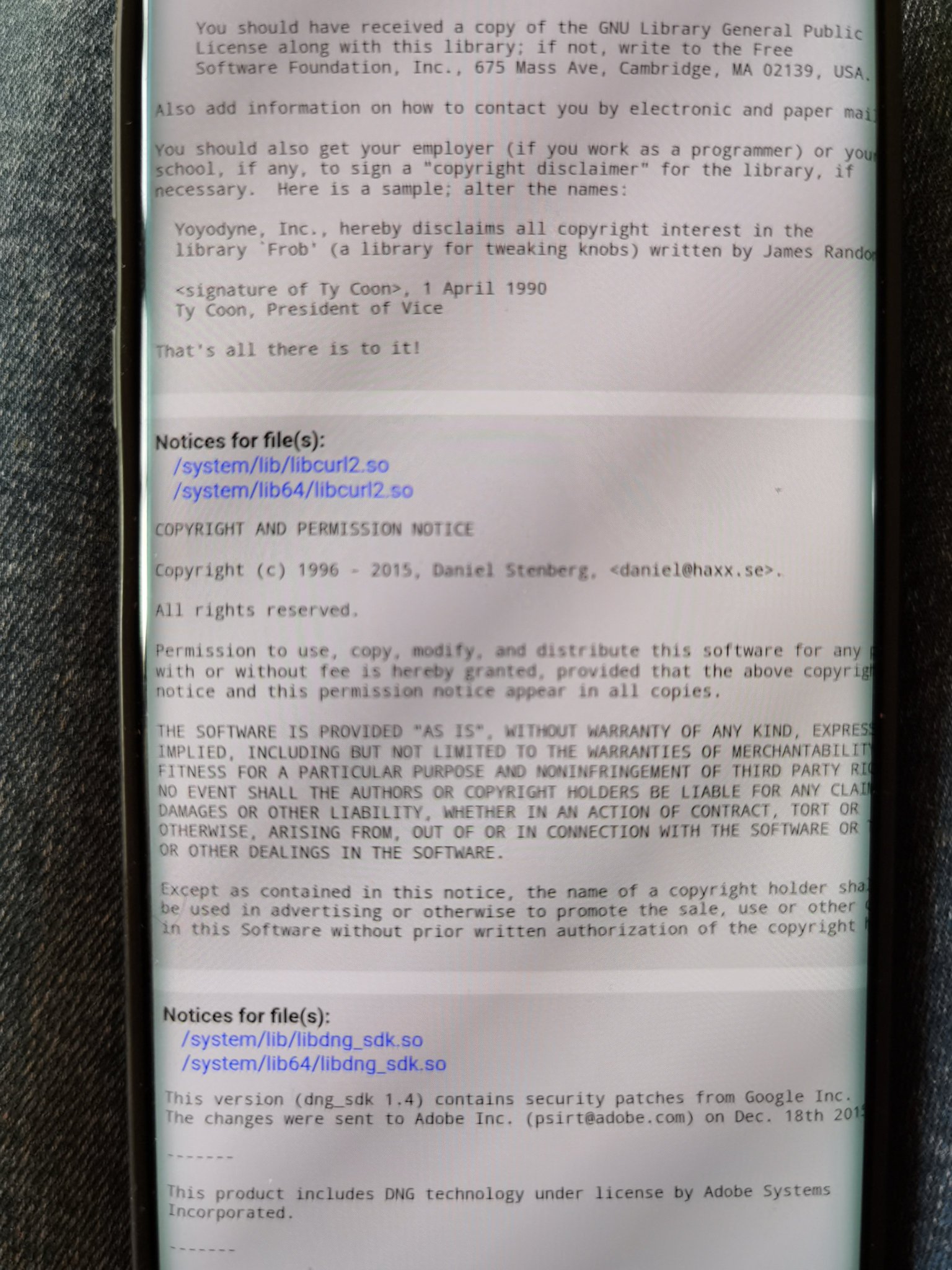
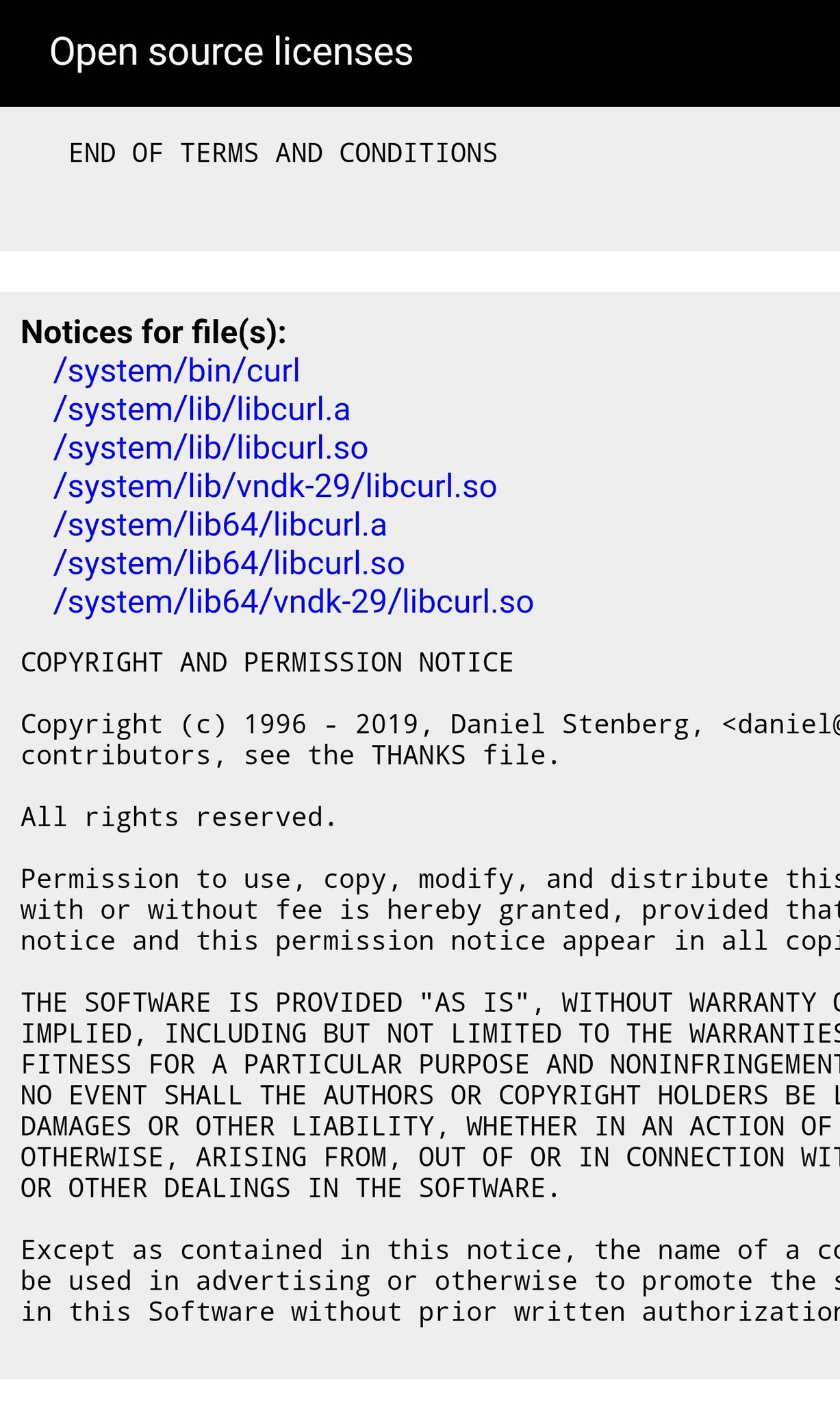
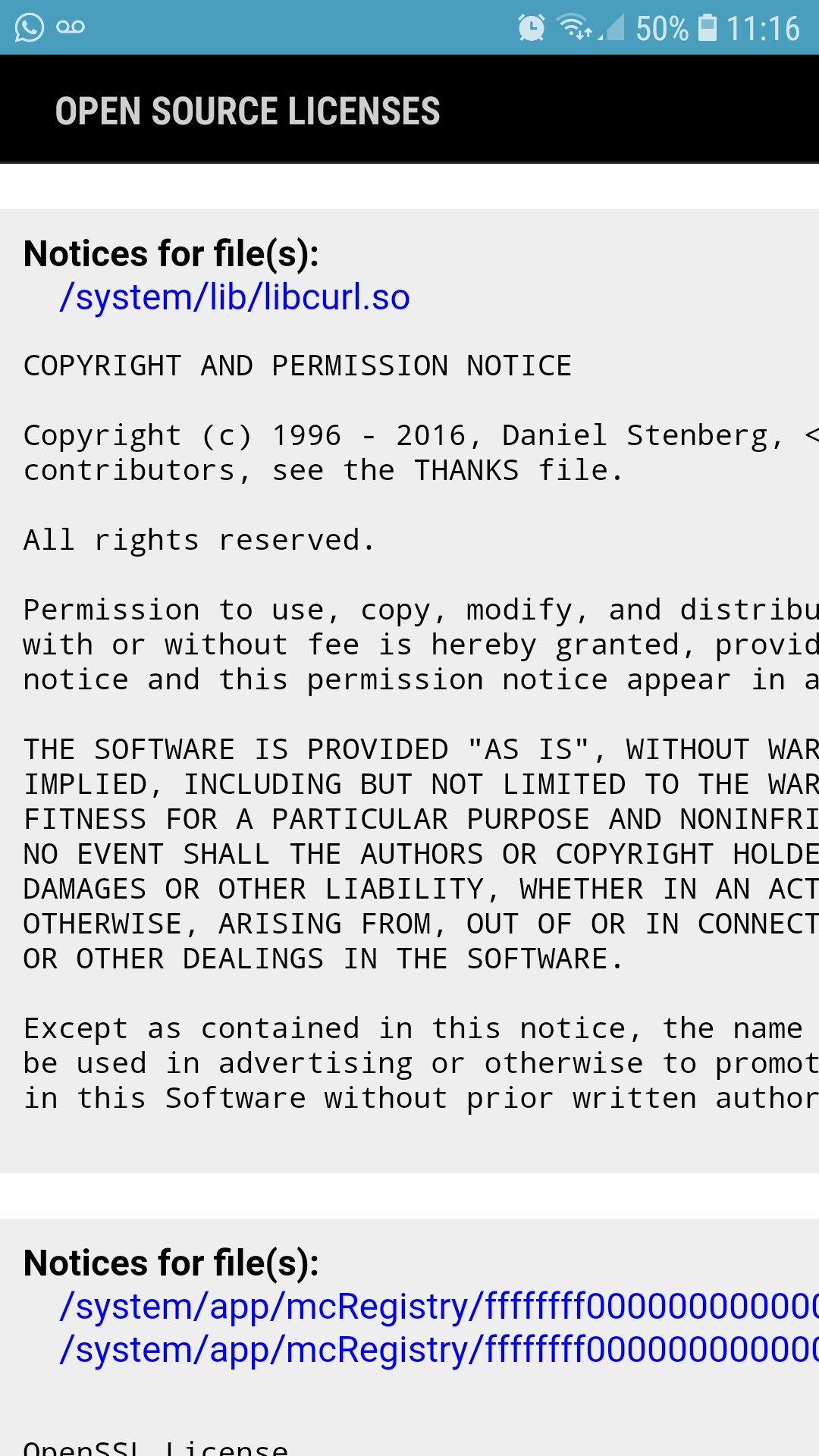
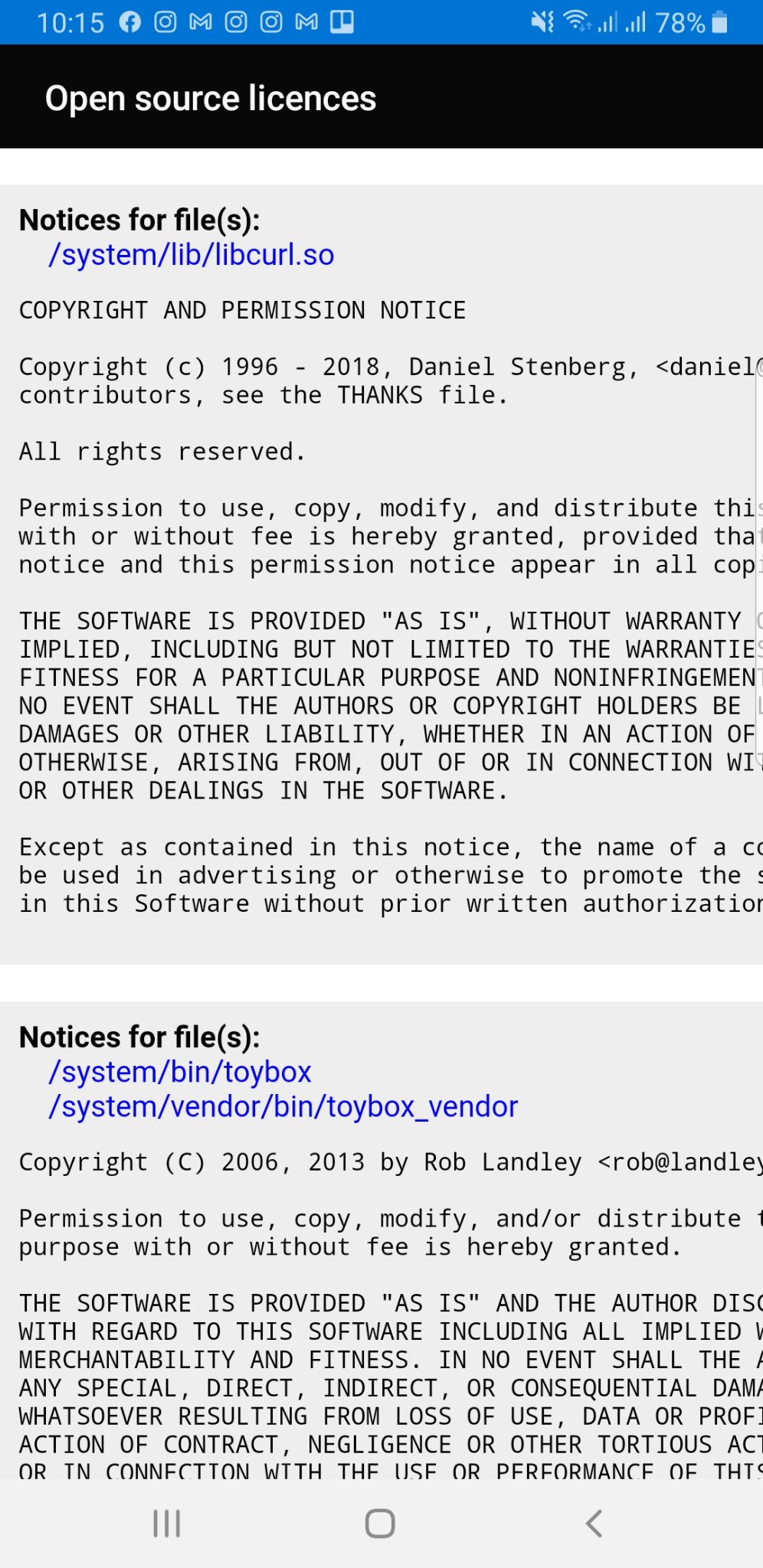
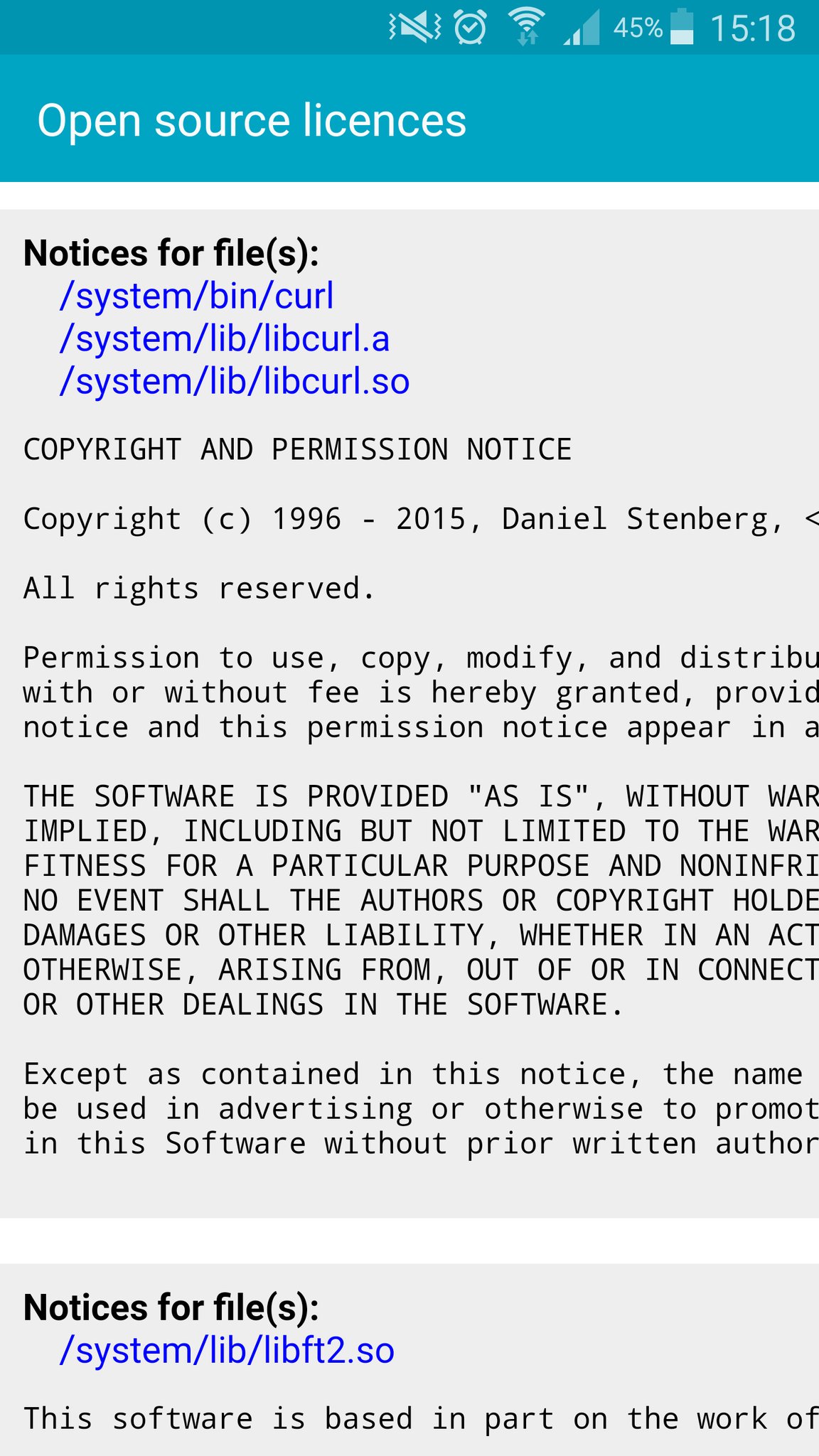
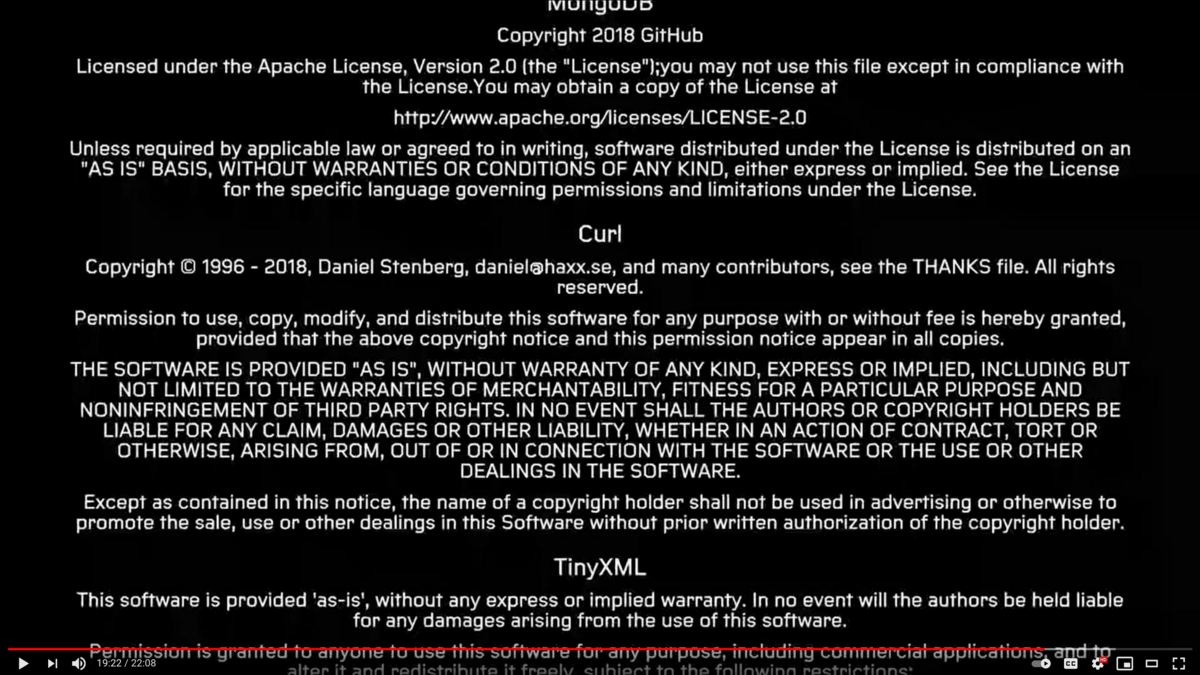
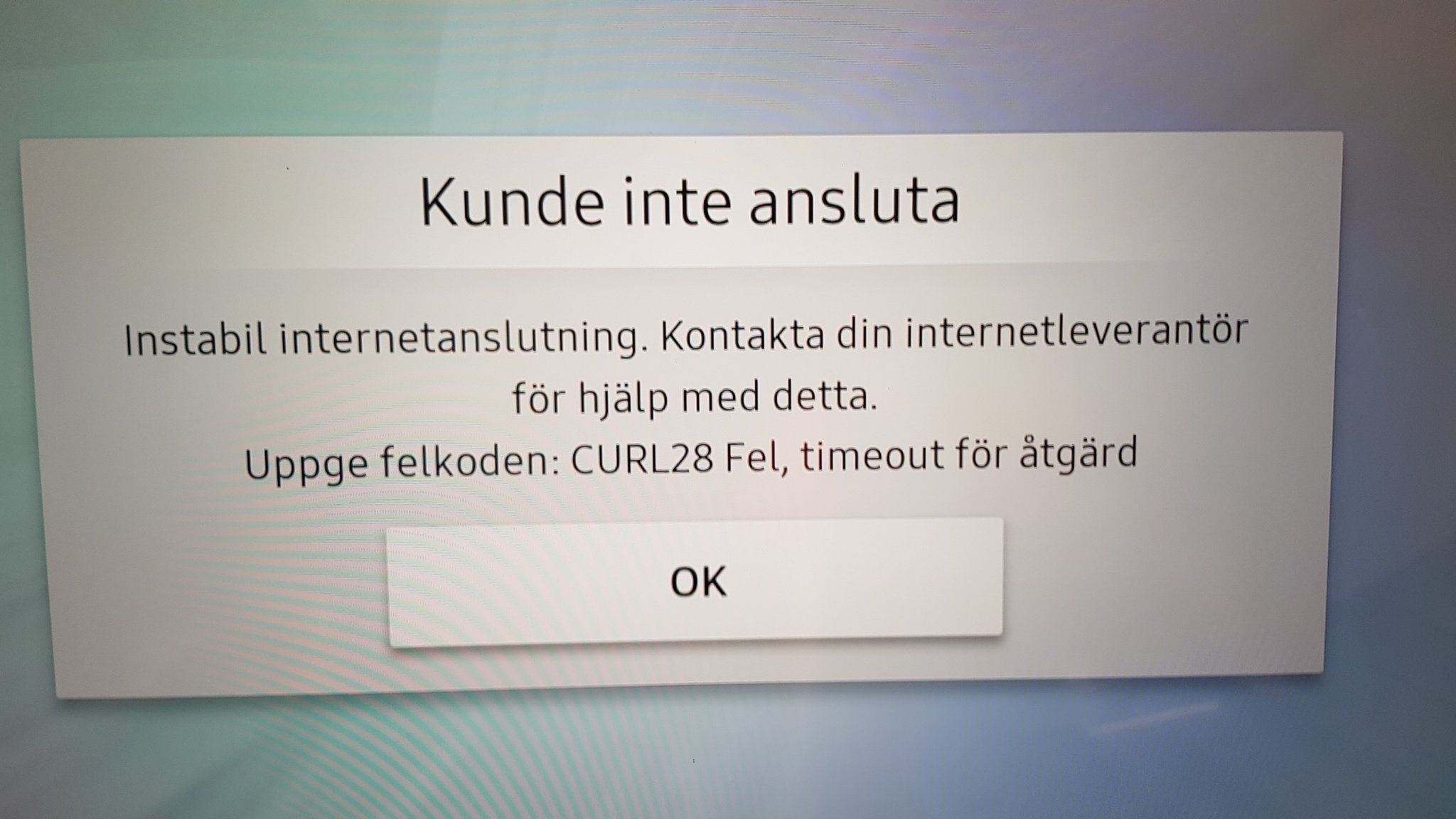
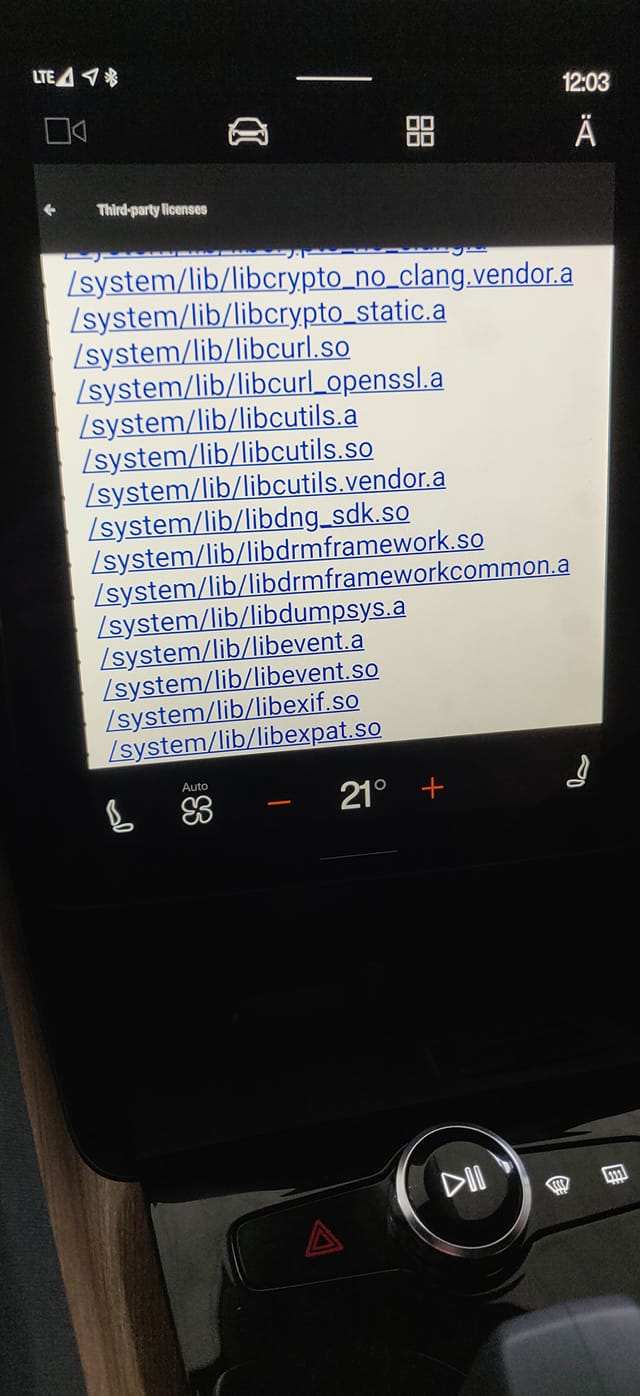
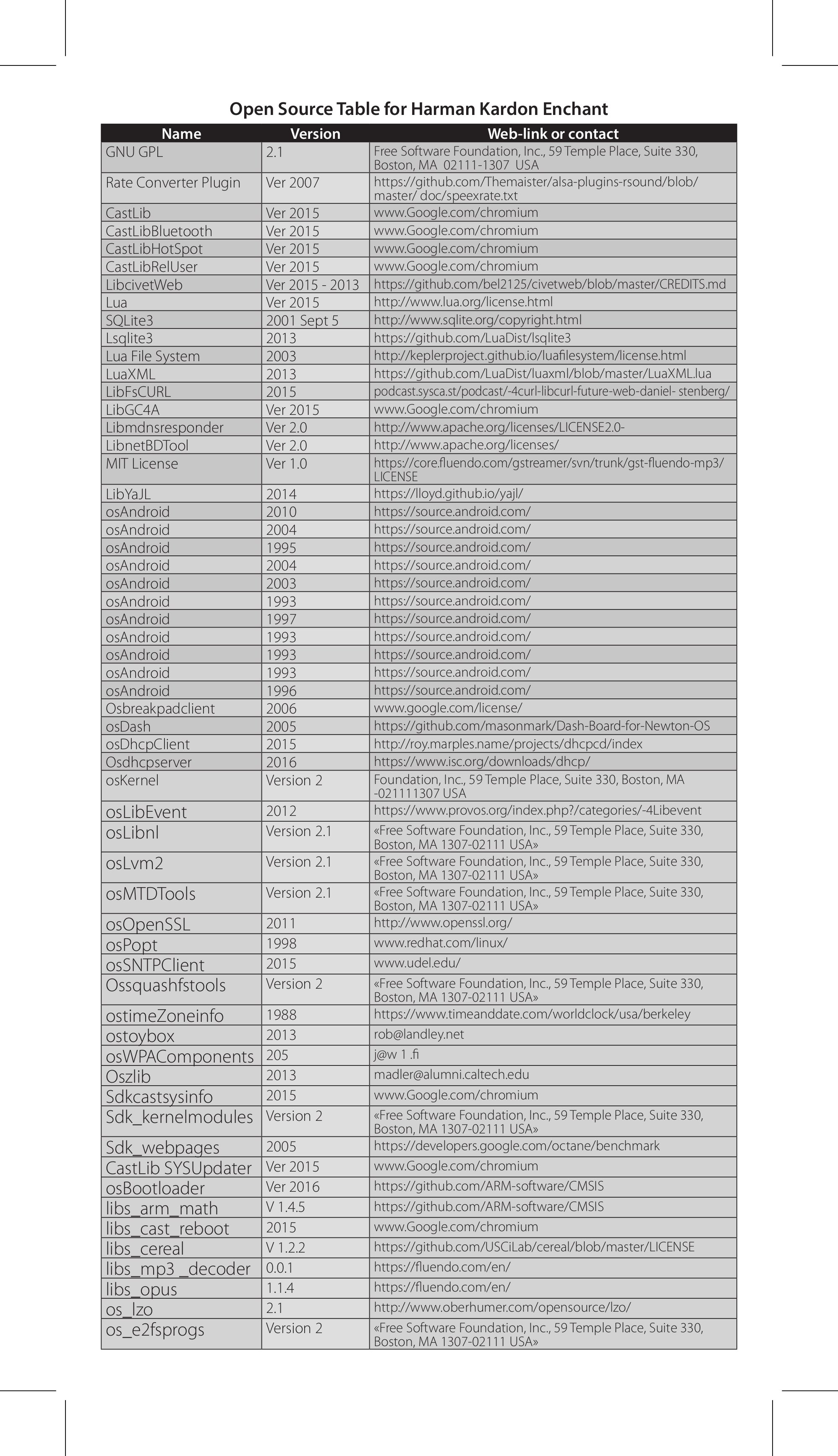
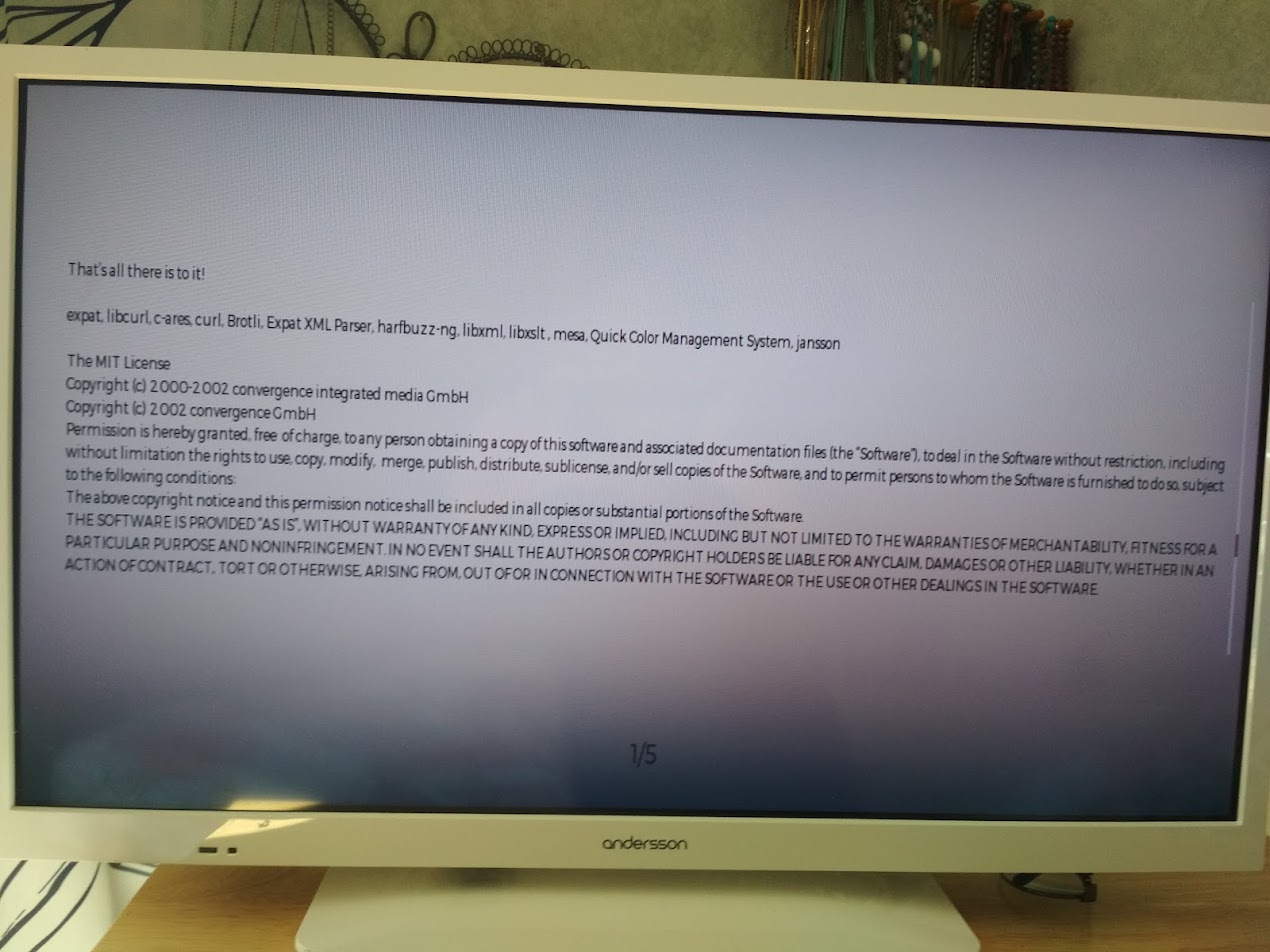
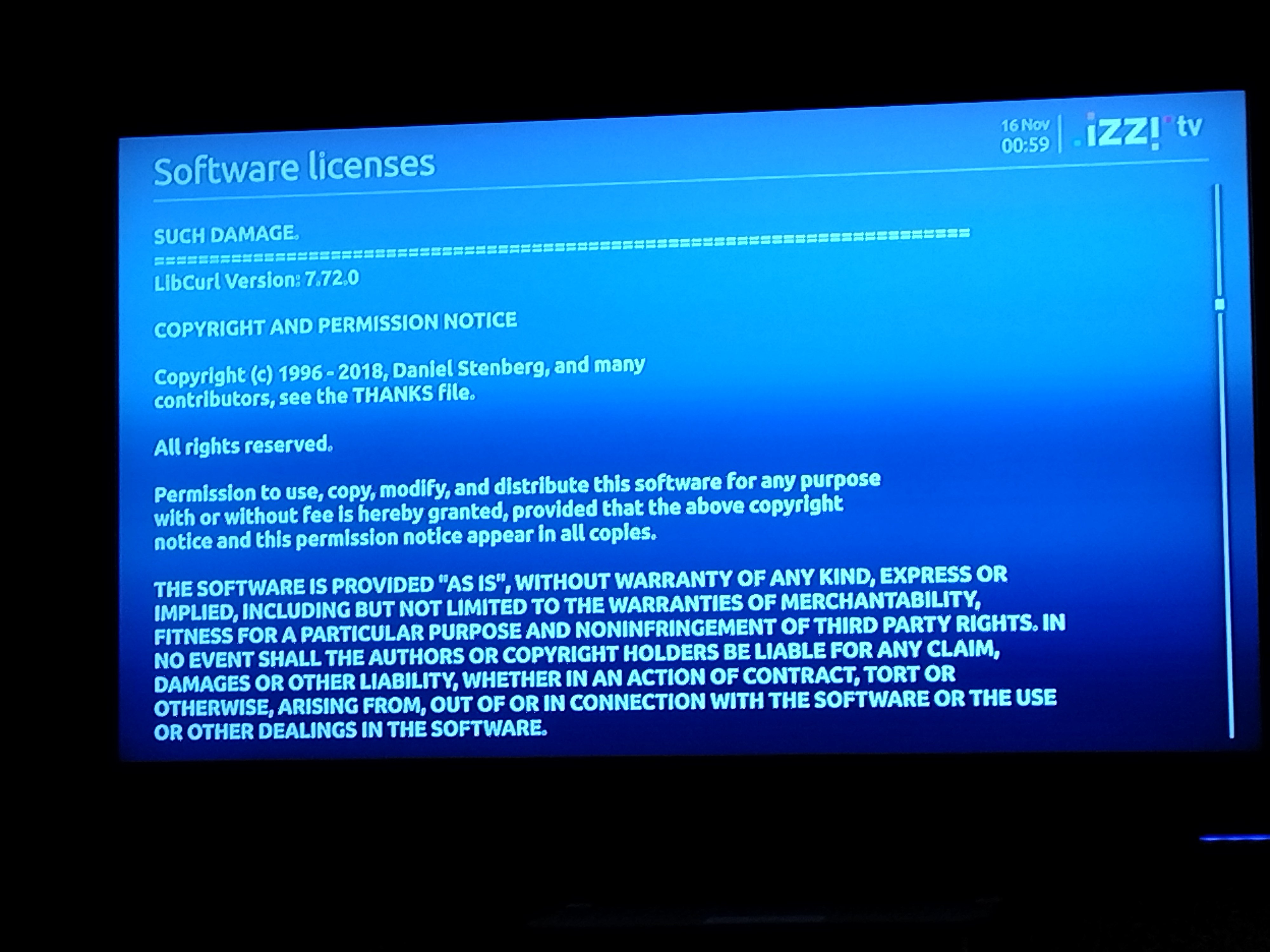
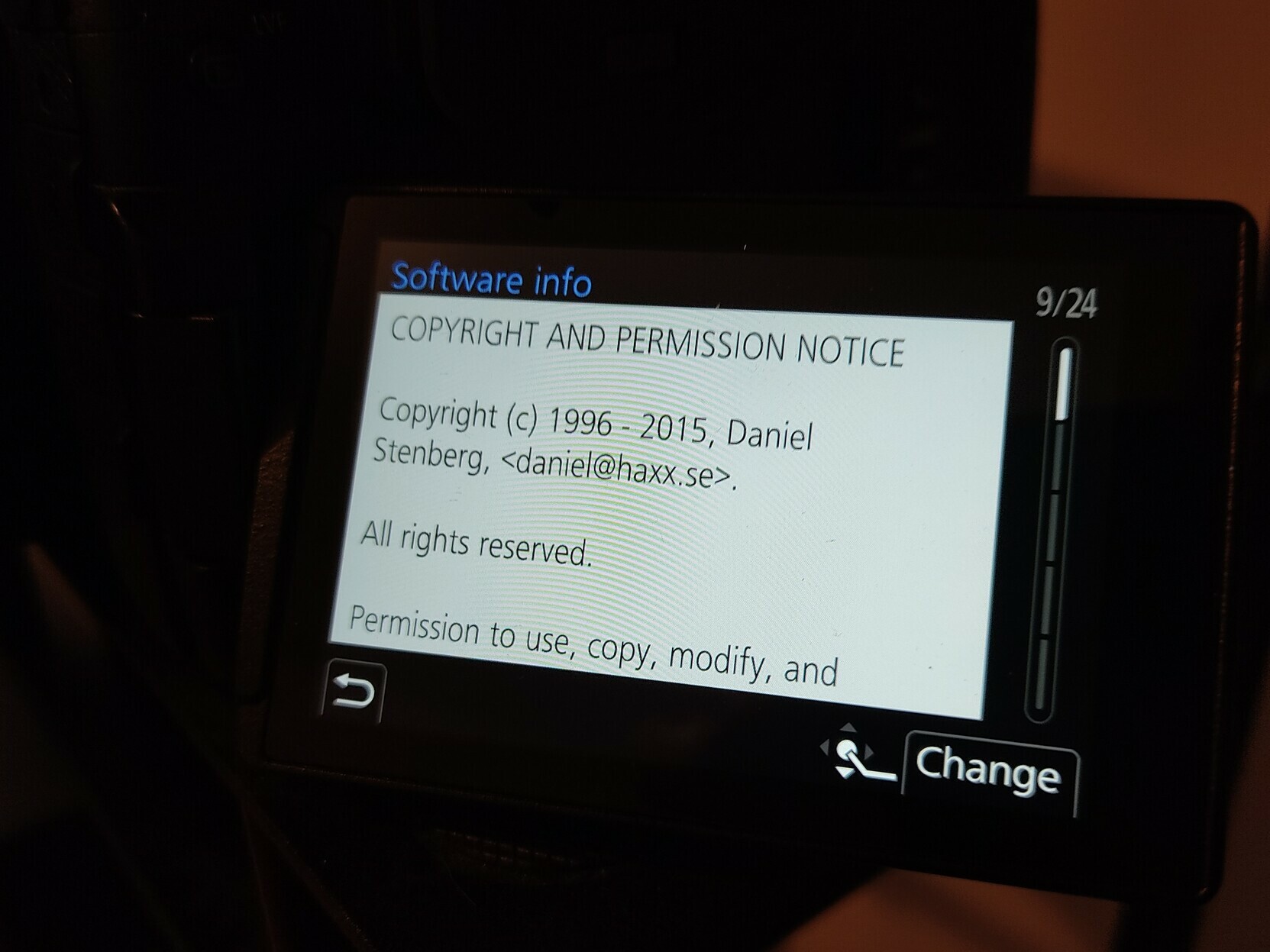
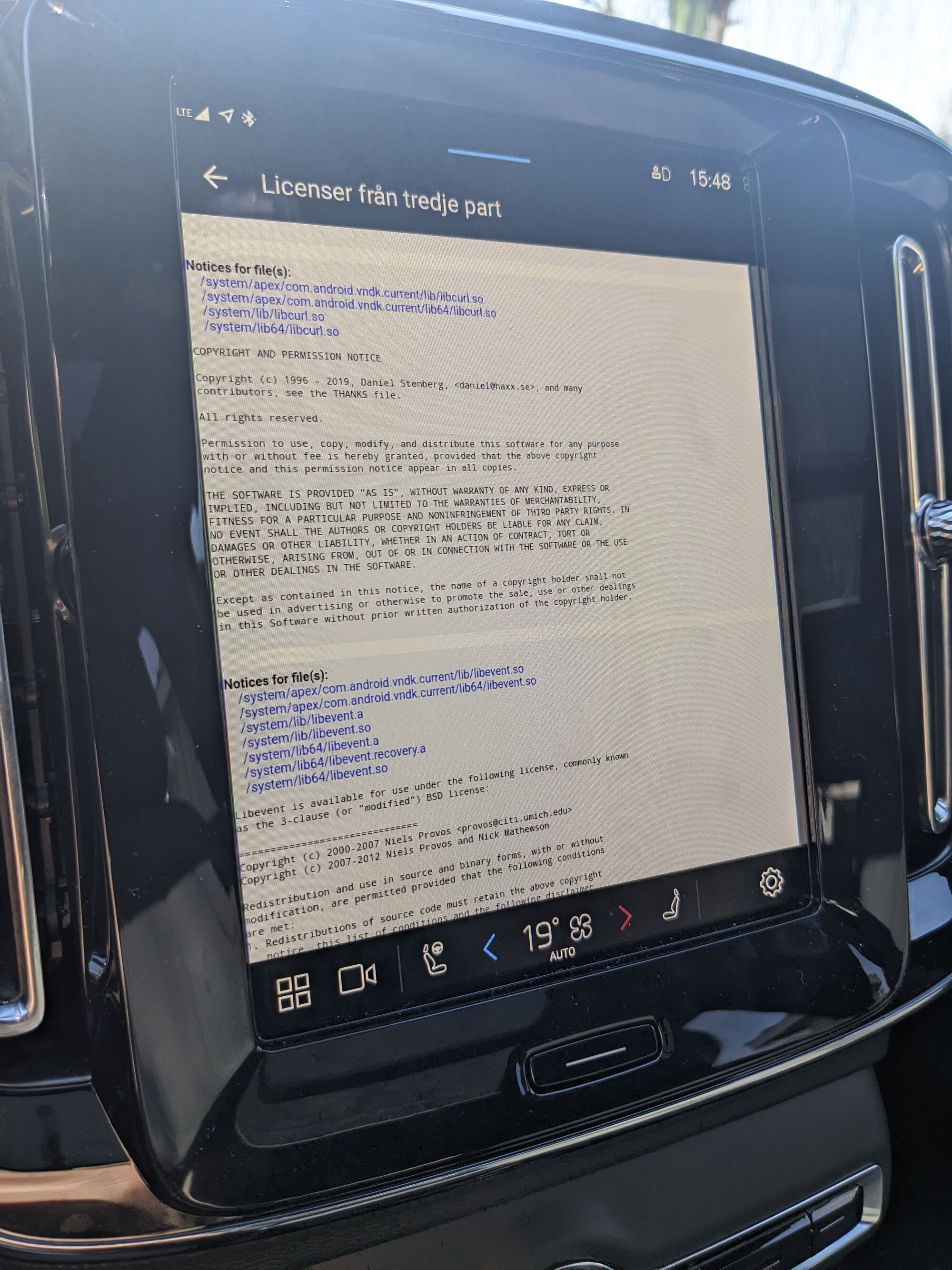
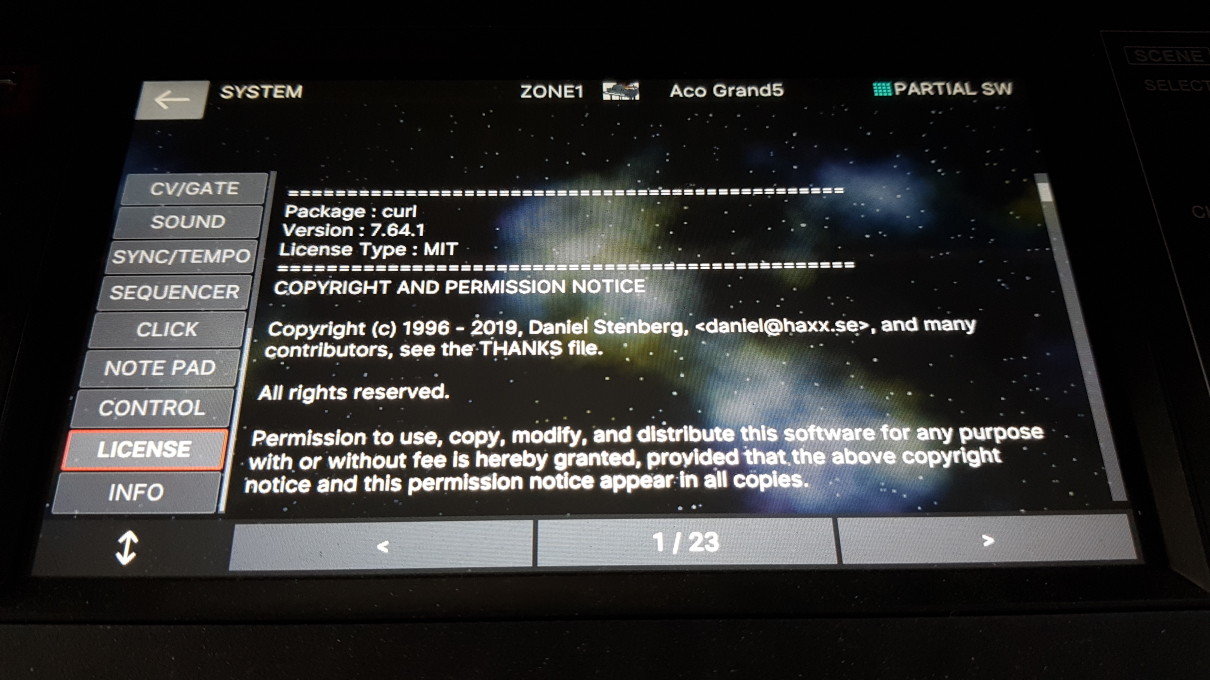
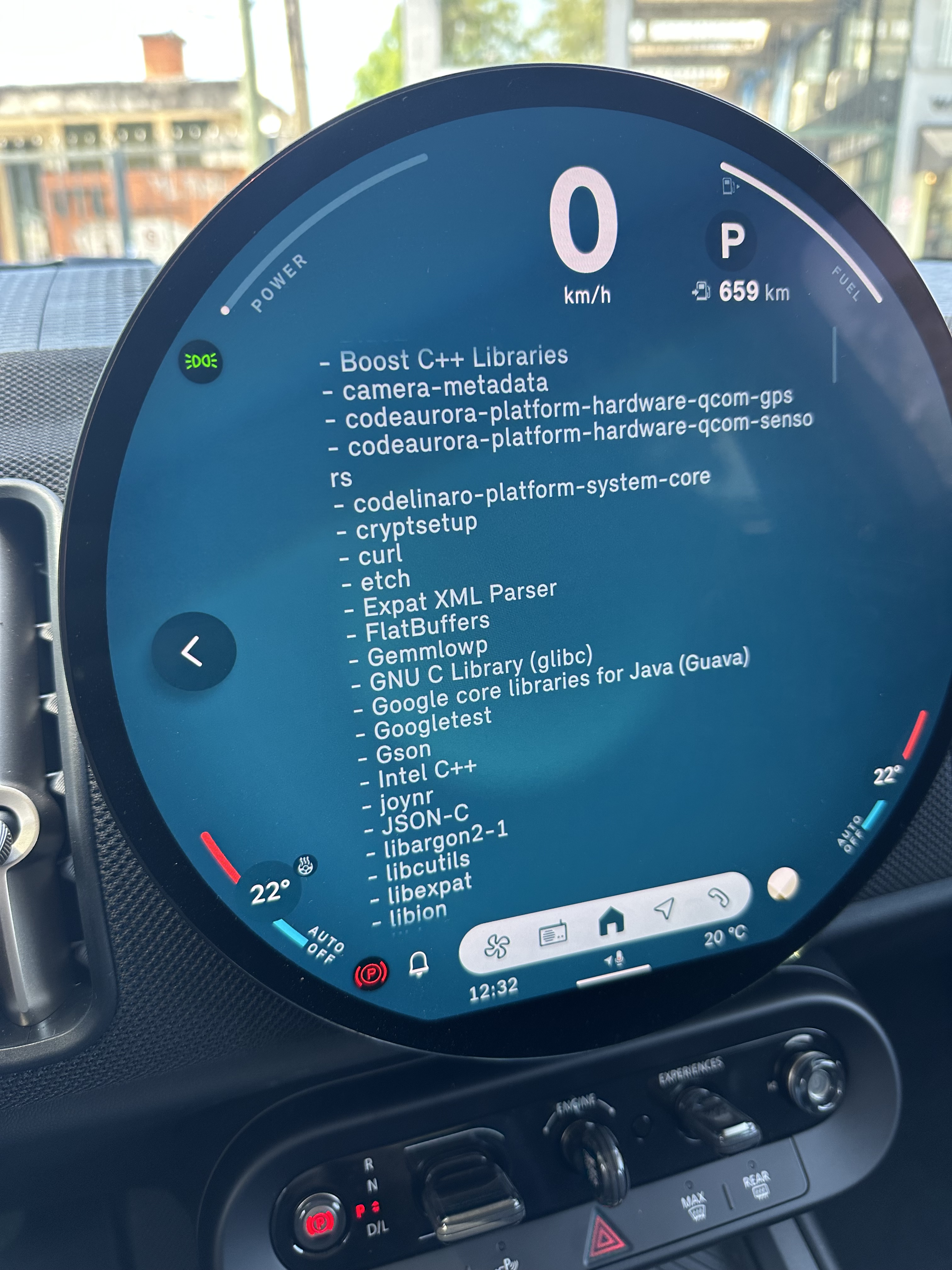
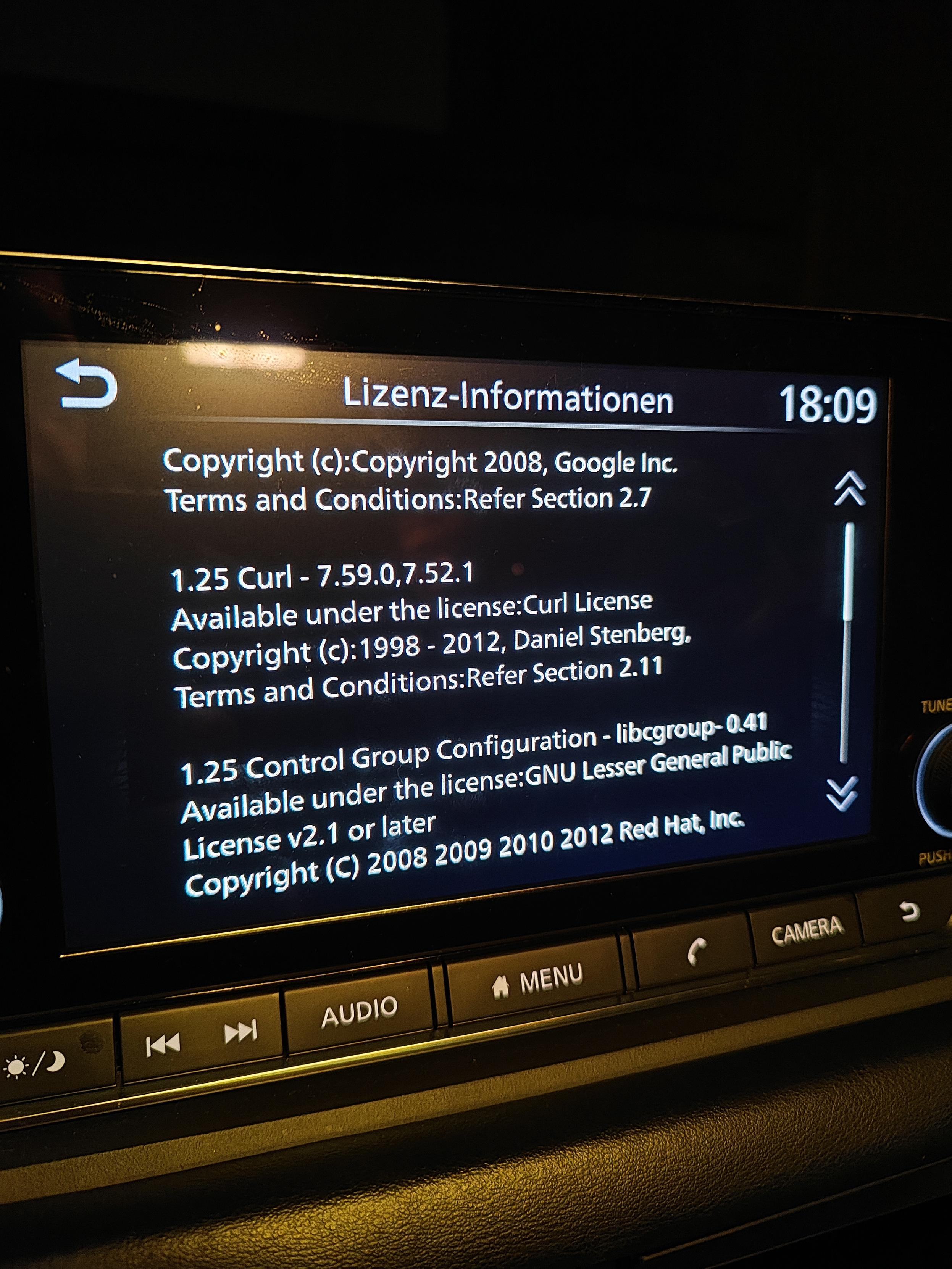
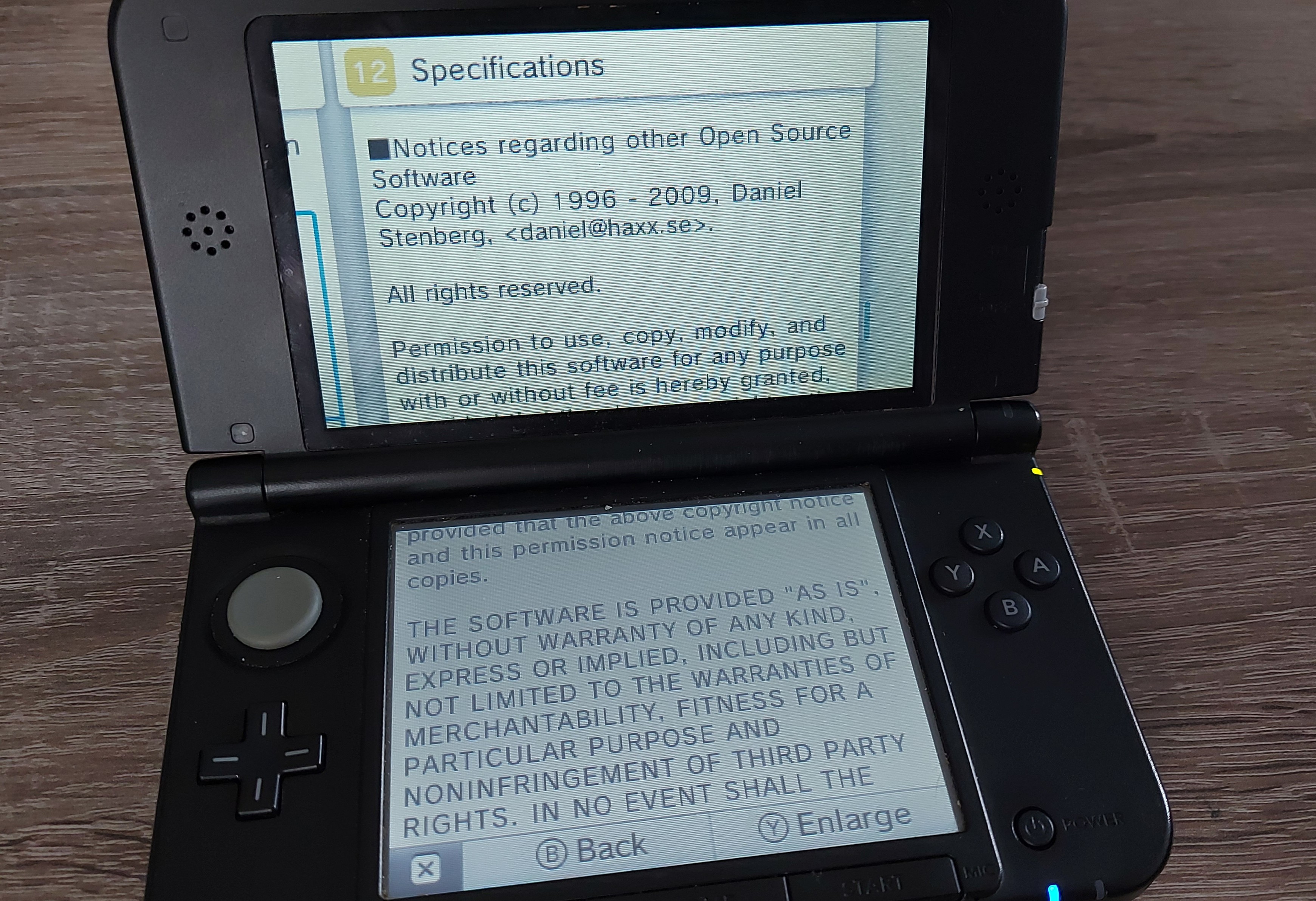
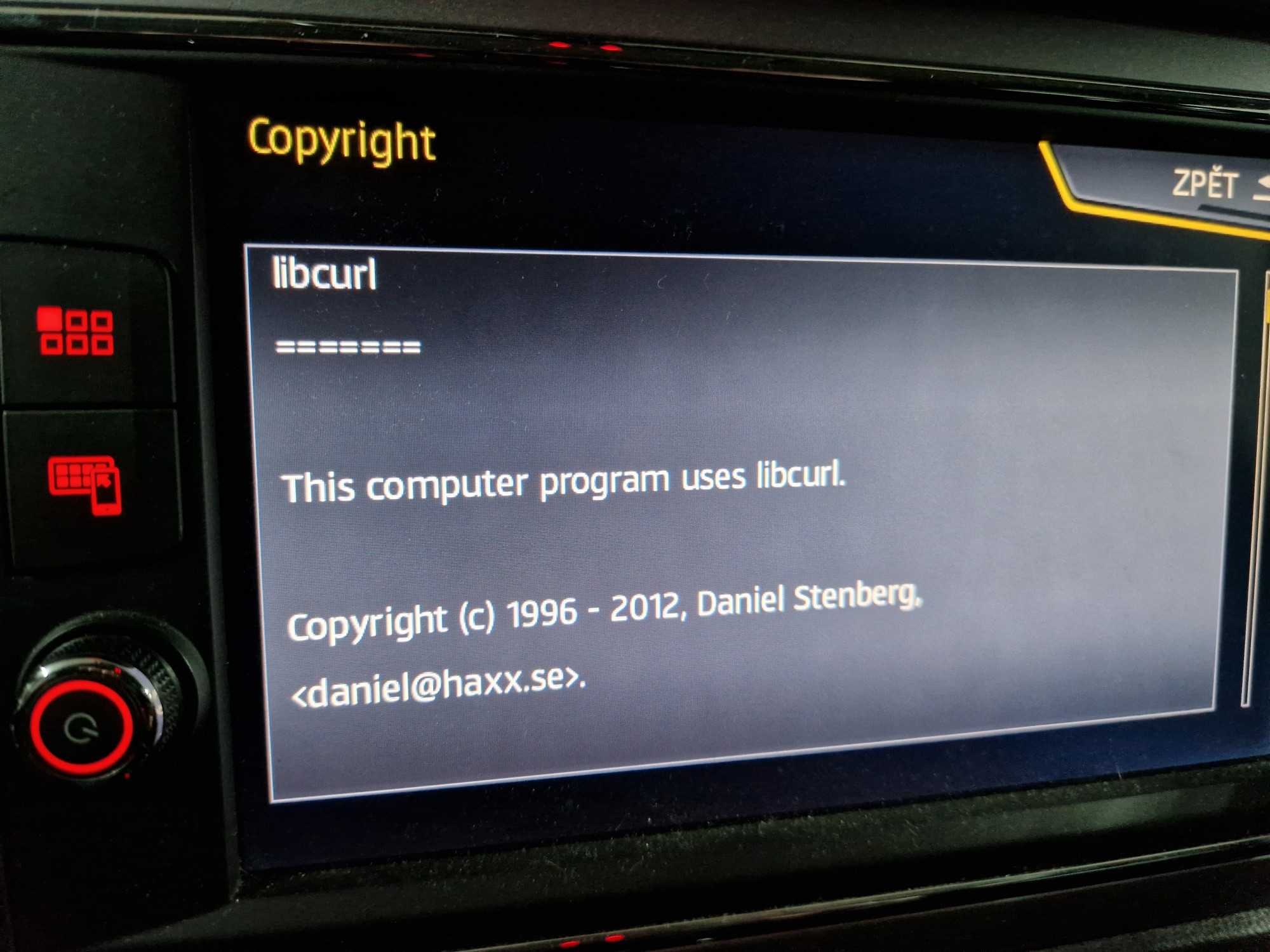
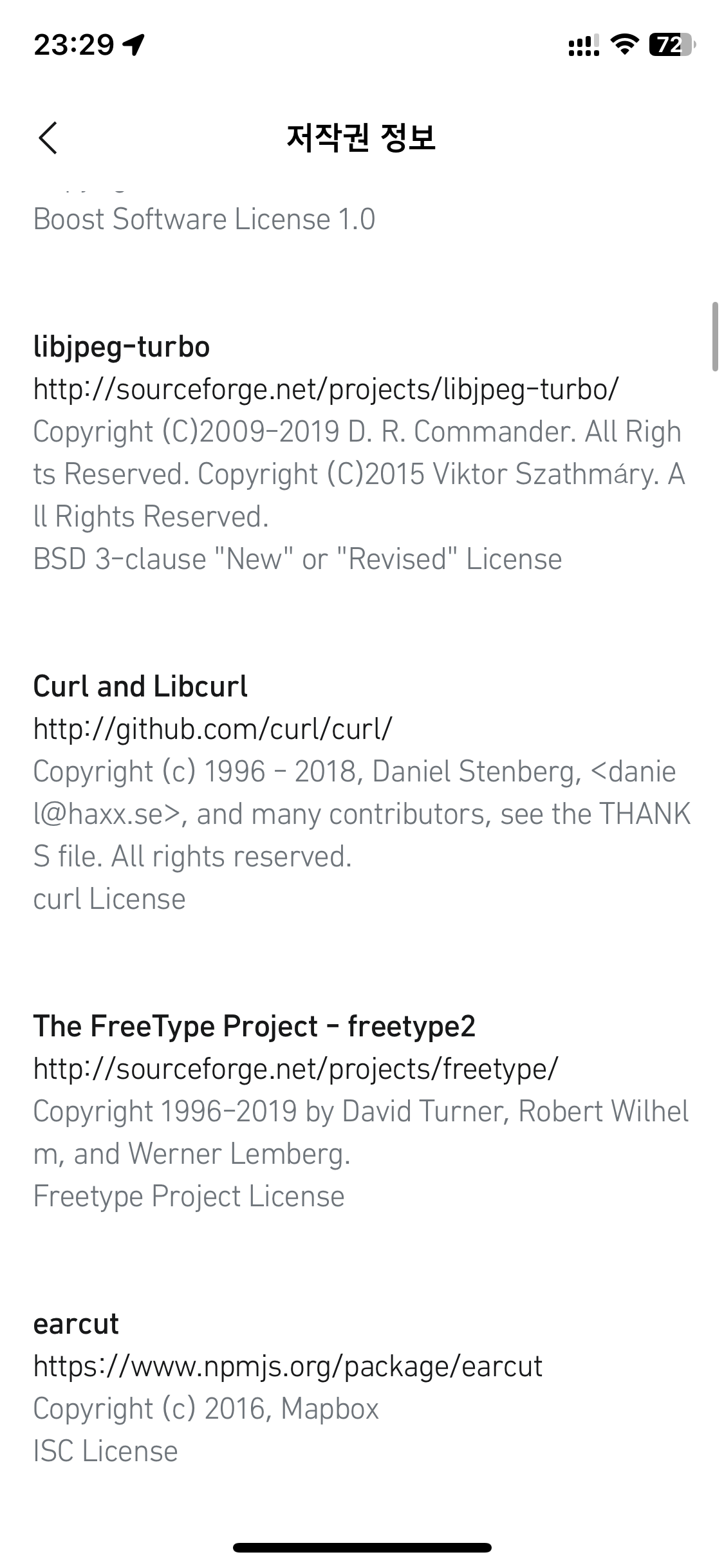
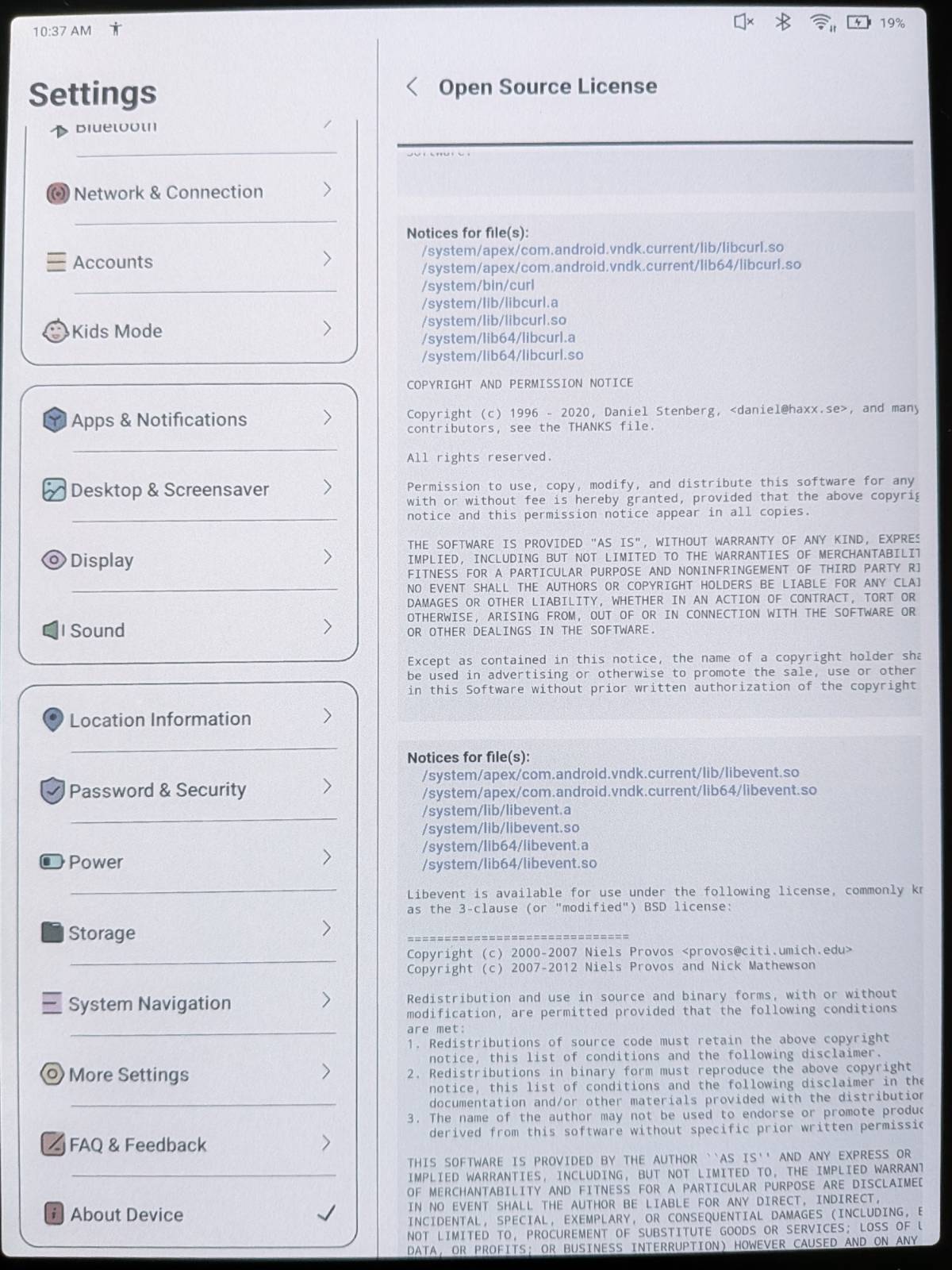
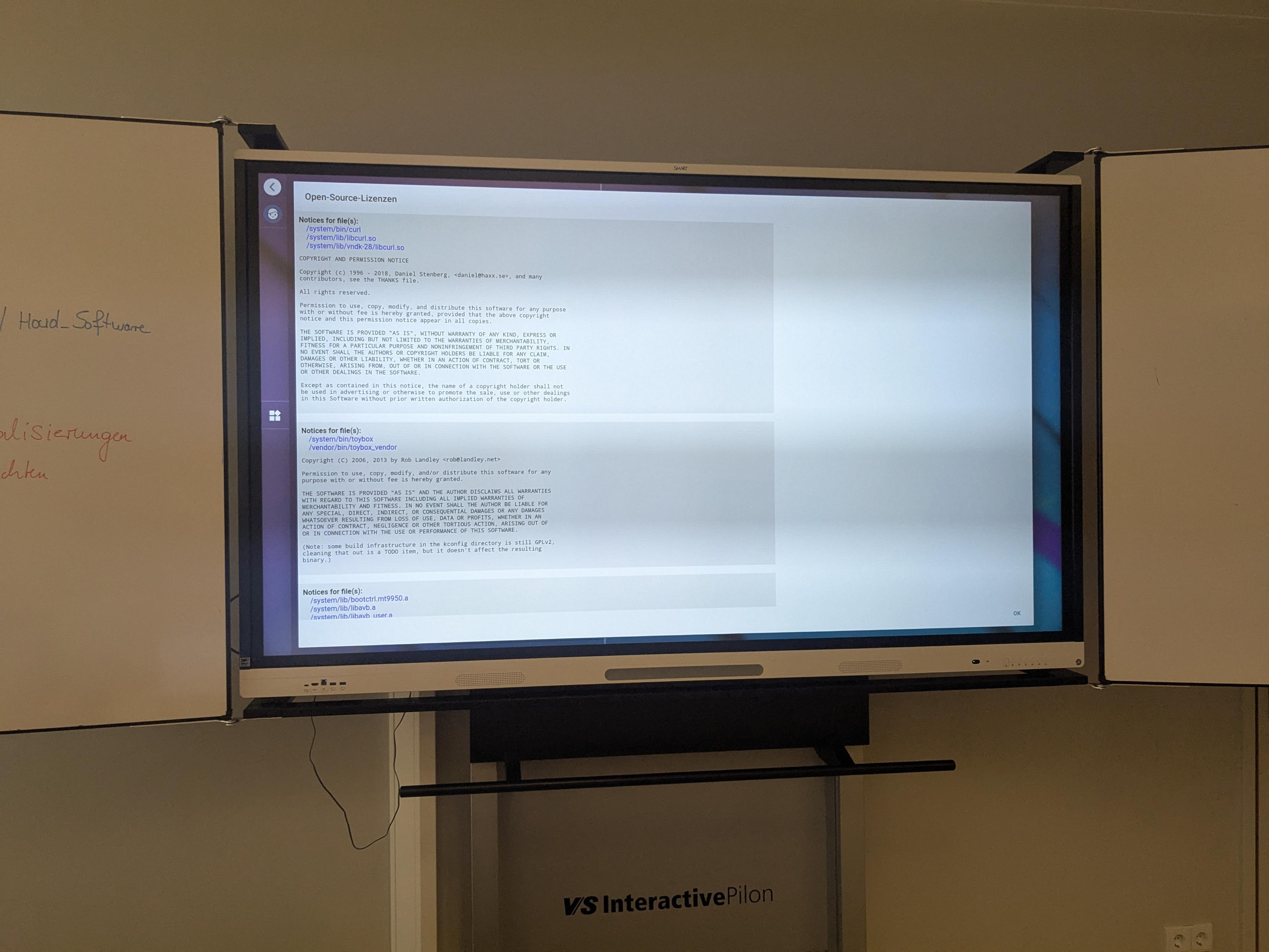
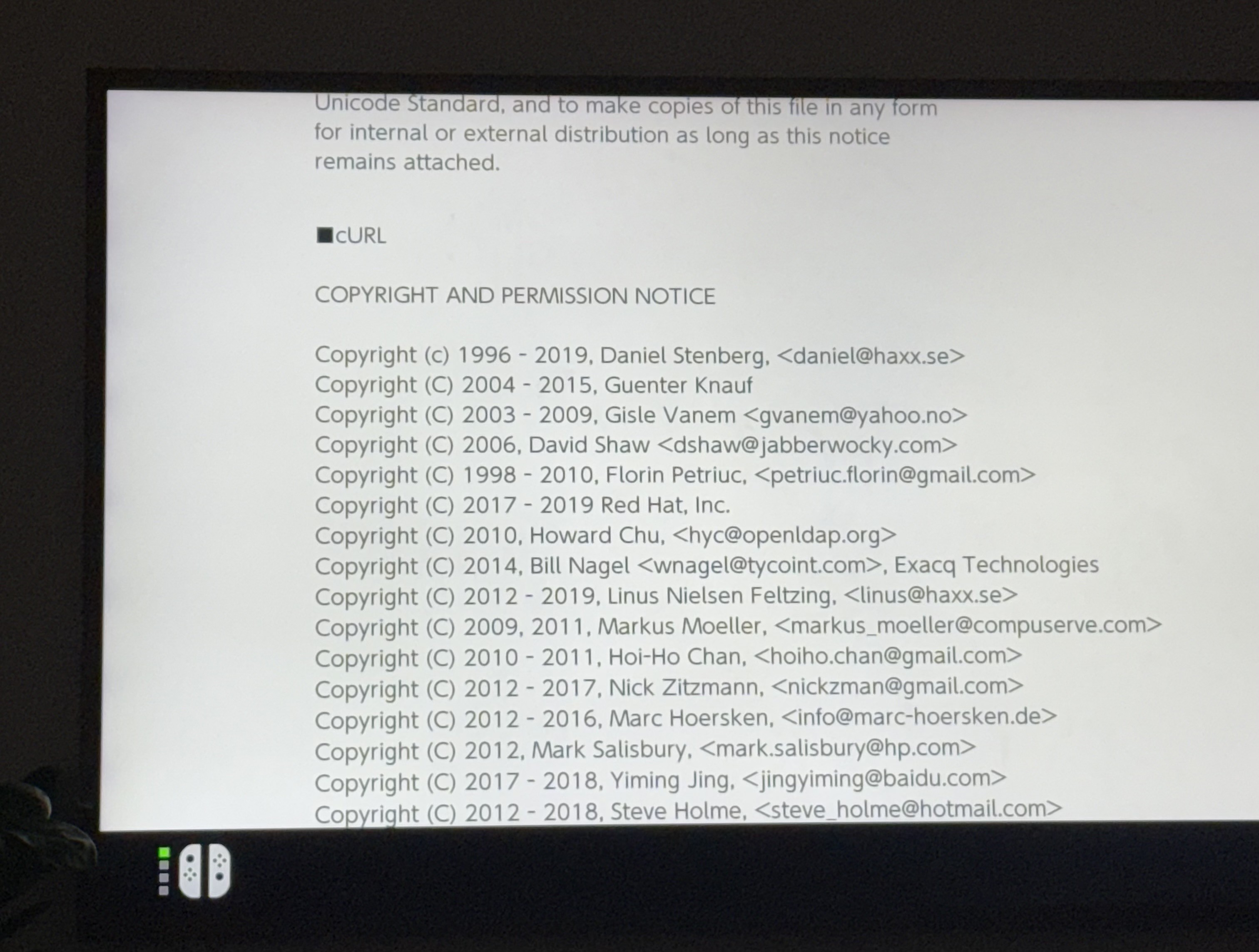
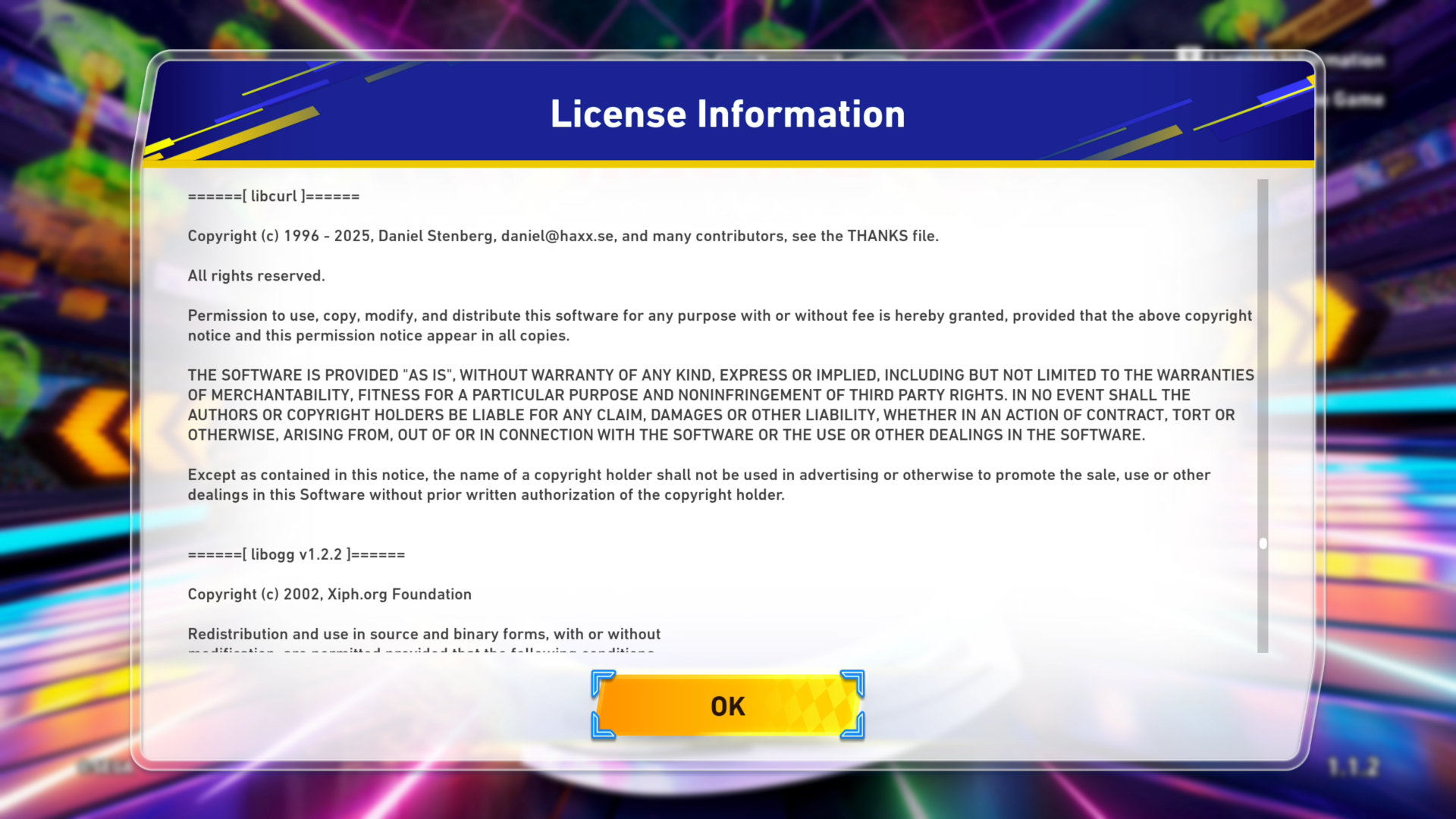
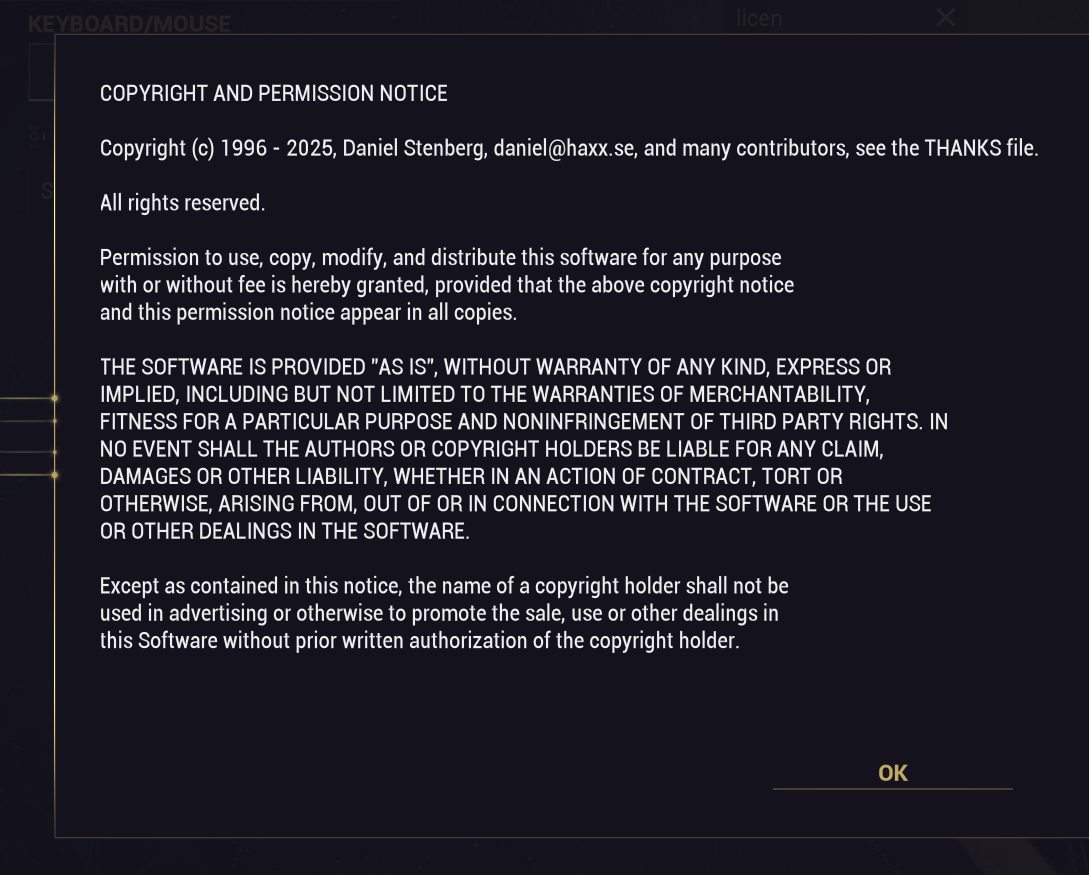
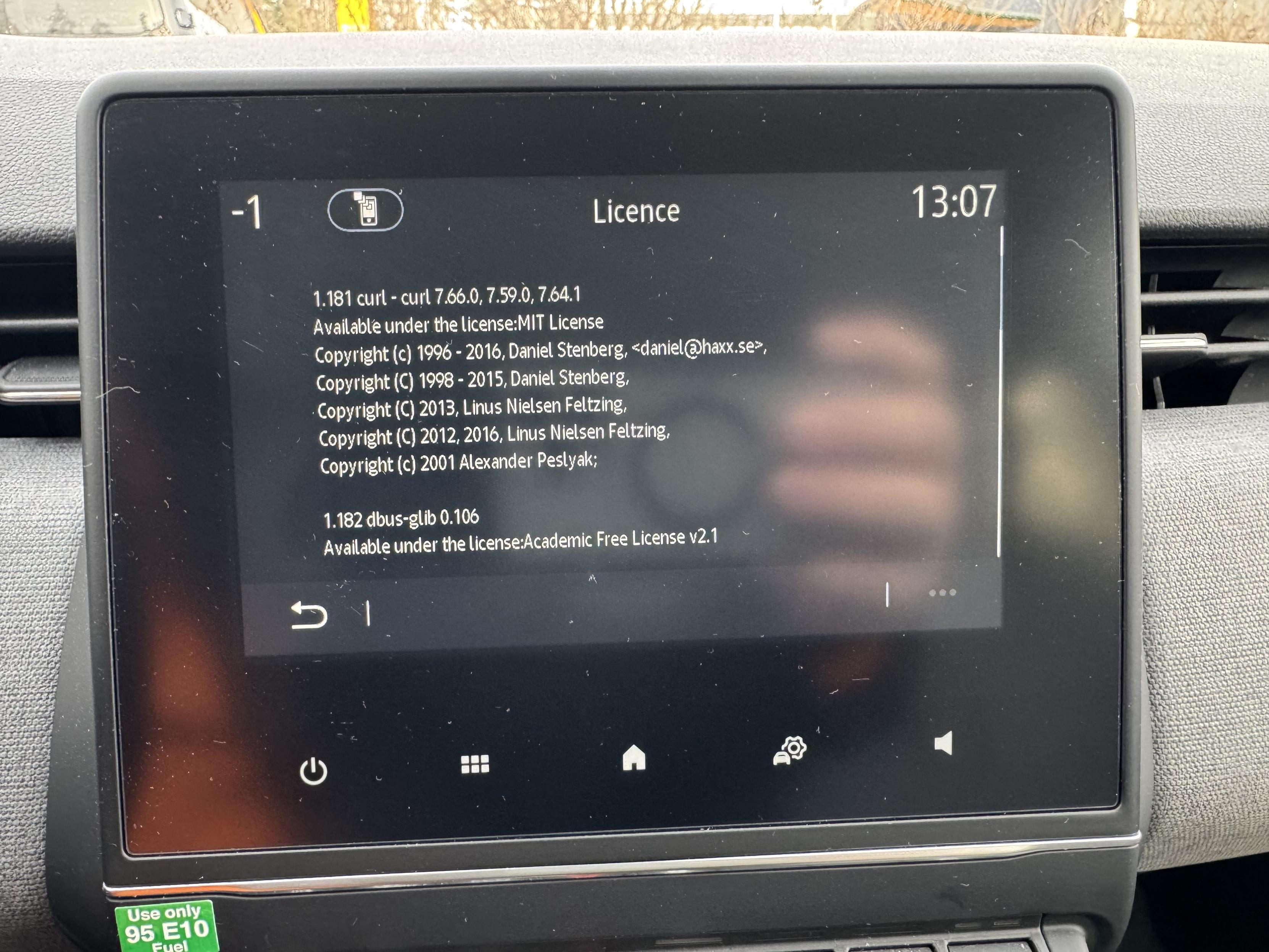
Modern cars have fancy infotainment setups, big screens and all sorts of computers with networked functionality built-in. Part of that fanciness is increasingly often a curl install. curl is a part of the standard GenIVI and Tizen offers for cars and is used in lots of other independent software installs too.
This usually affects my every day very little. Sure I’m thrilled over hundreds of millions of more curl installations in the world but the companies that ship them don’t normally contact me and curl is a really stable product by now so not a lot of them speak up on the issue trackers or mailing lists either (or if they do, they don’t tell us where they come from or what they’re working on).
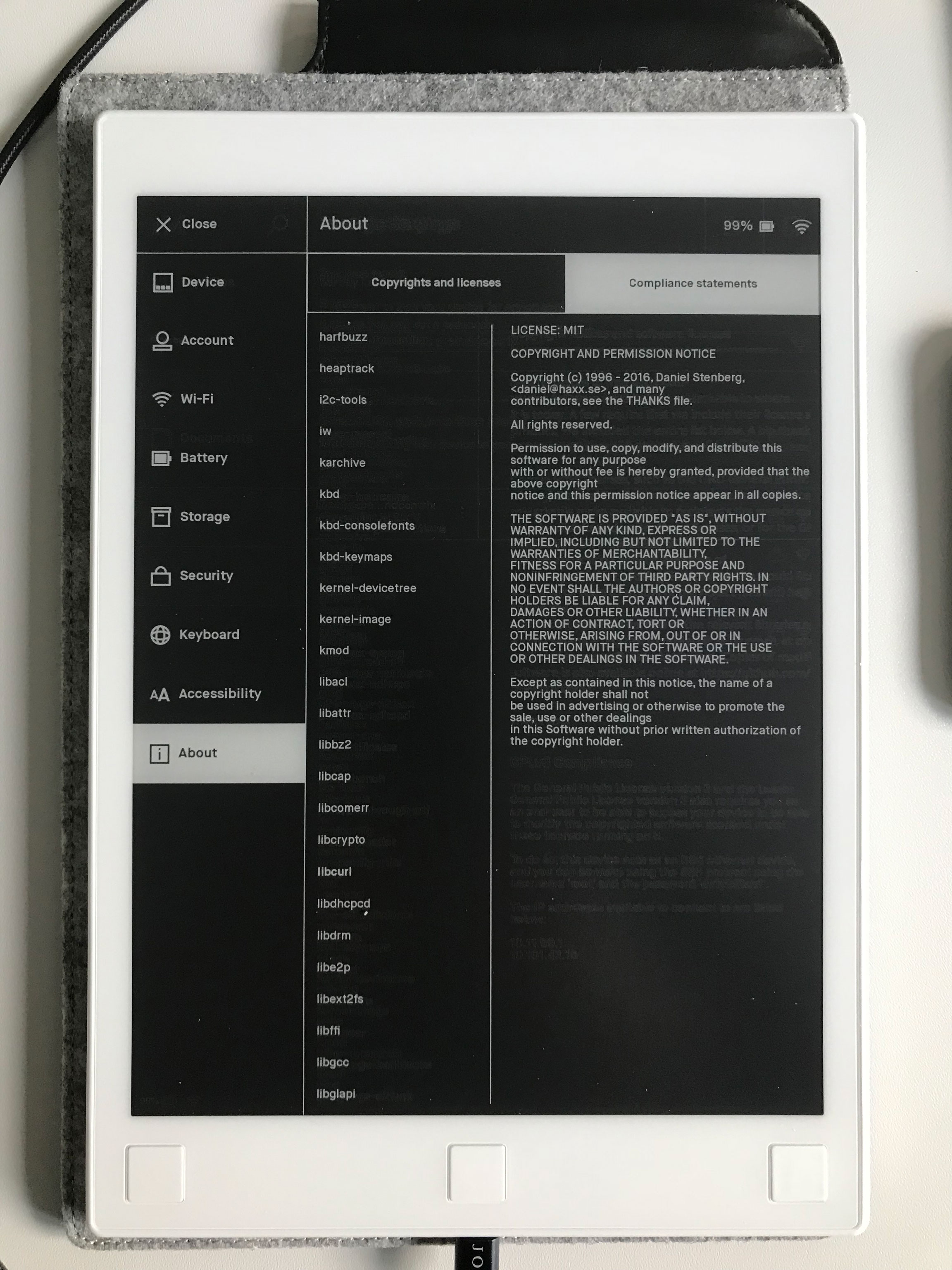
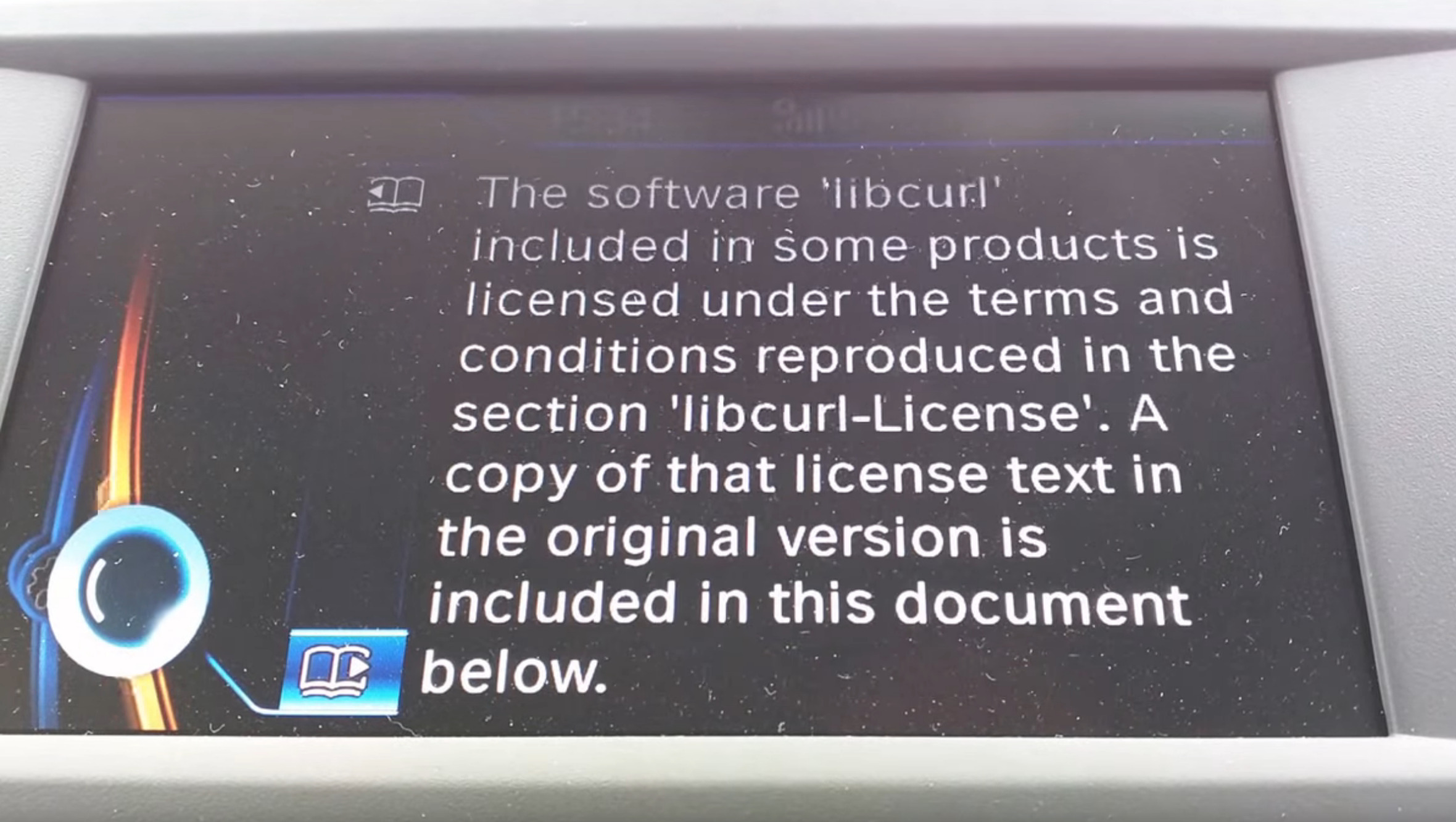
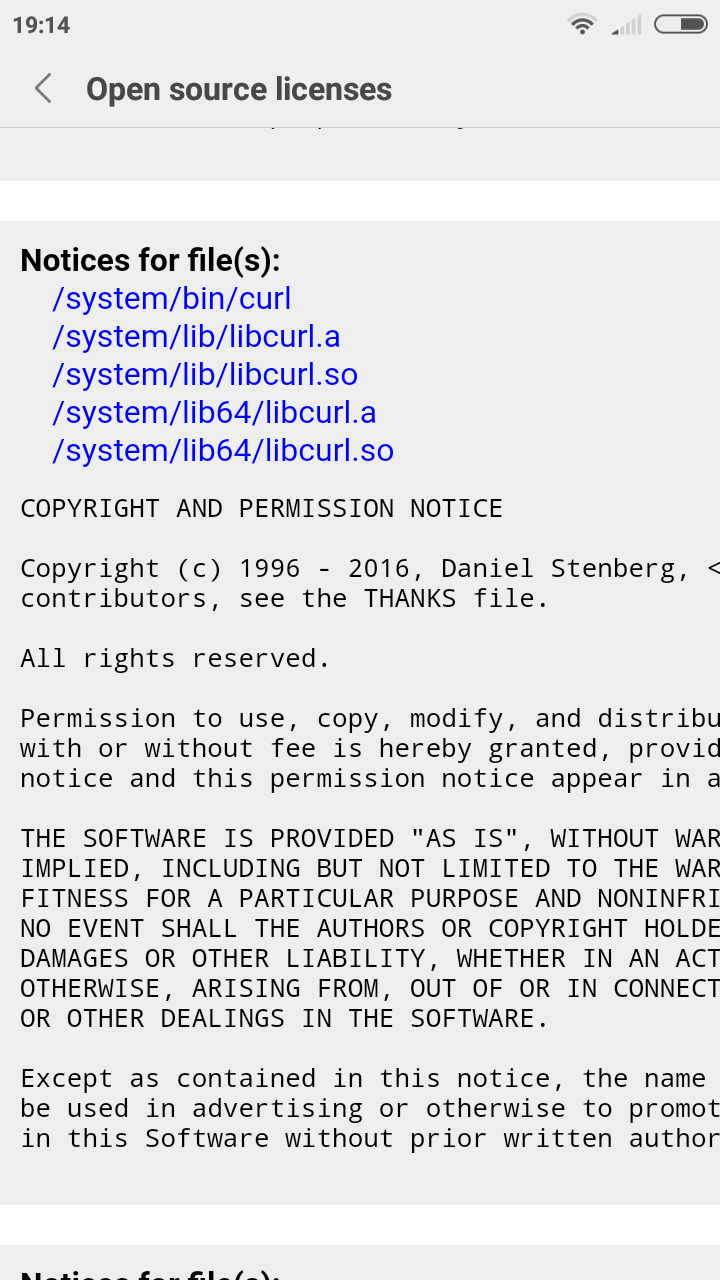
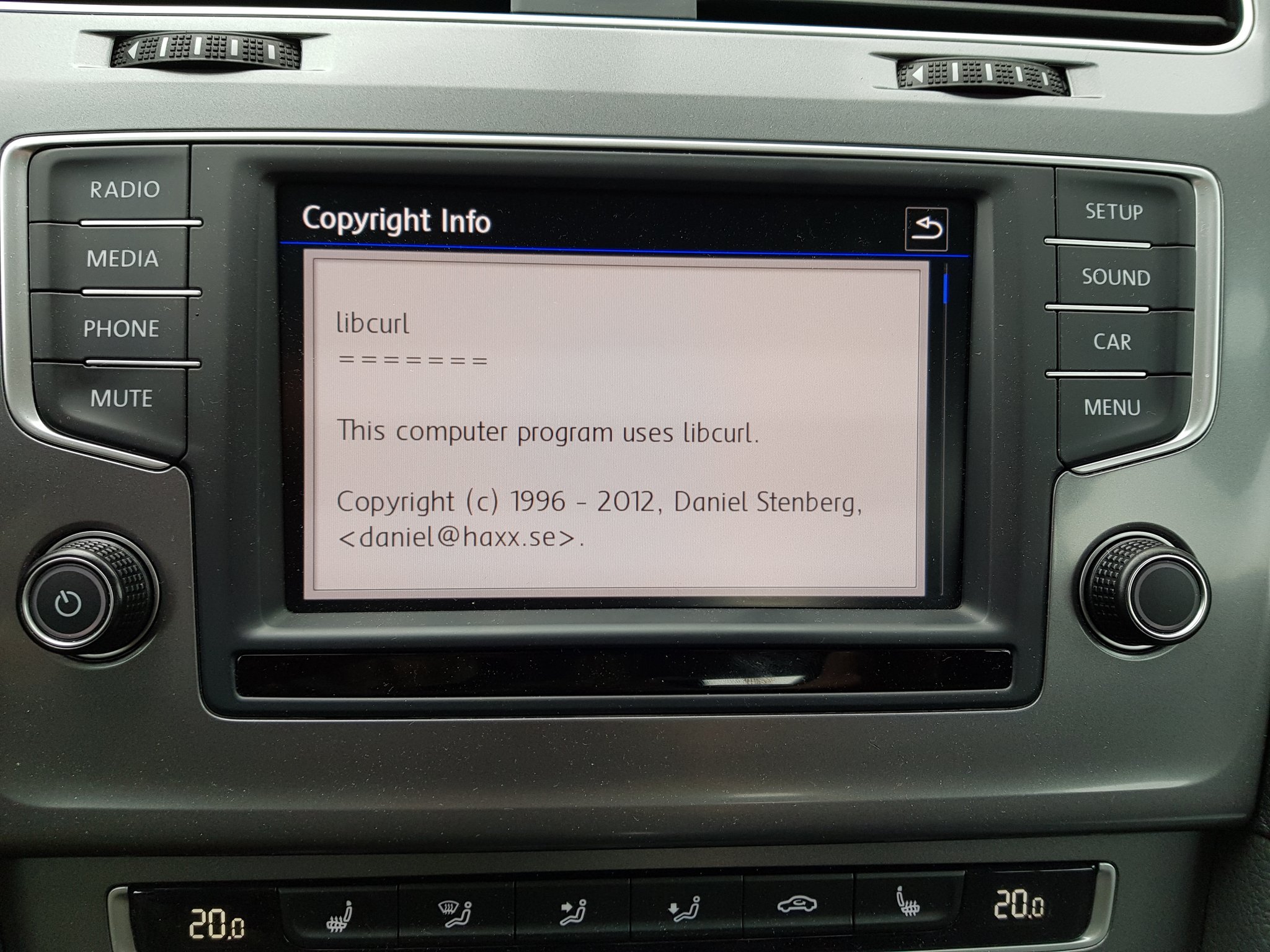
The main effect is that normal end users find my email address via the curl license text in products in cars to a higher degree. They usually find it in the about window or an open source license listing or similar. Often I suspect my email address is just about the only address listed.
This occasionally makes desperate users who have tried everything to eventually reach out to me. They can’t fix their problem but since my email exists in their car, surely I can!
Here are three of my favorite samples that I saved.
November 13, 2016
Hello sir
I have Avalon 2016
Regarding the audio player, why there delay between audio and video when connect throw Bluetooth and how to fix it.
November 5, 2015
Hello,
I am using in a new Ford Mondeo the navigation system with SD Card FM5T-19H449-FC Europe F4.
I can read the card but not write on it. I want to add to the card some POI´s. Can you help me to do it?
June 8, 2015
Hello
I have toyota corola with multimedya system that you have its copyright.
I need a advice to know how to use the gps .
Now i cant use or see maps.
And i want to know how to add hebrew leng.
How do I respond?
I’m sad to say that I rarely respond at all. I can’t help them and I’ve learned over the years that just trying to explain how I have nothing to do with the product they’re using is often just too time consuming and energy draining to be worth it. I hope these people found the answers to the problems via other means.
The hacker news discussions on this post took off. I just want to emphasize that this post is not a complaint. I’m not whining over this. I’m just showing some interesting side-effects of my email in the license text. I actually find these emails interesting, sometimes charming and they help me connect to the reality many people experience out there.
Already now, both Firefox and Chrome have test versions out with TLS 1.3 enabled. Firefox 52 will have it by default, and while Chrome will ship it, I couldn’t figure out exactly when we can expect it to be there by default.
Over the last few days we’ve merged TLS 1.3 support to curl, primarily in this commit by Kamil Dudka. Both the command line tool and libcurl will negotiate TLS 1.3 in the next version (7.52.0 – planned release date at the end of December 2016) if built with a TLS library that supports it and told to do it by the user.
The two current TLS libraries that will speak TLS 1.3 when built with curl right now is NSS and BoringSSL. The plan is to gradually adjust curl over time as the other libraries start to support 1.3 as well. As always we will appreciate your help in making this happen!
Right now, there’s also the minor flux in that servers and clients may end up running implementations of different draft versions of the TLS spec which contributes to a layer of extra fun!
TLS 1.3 offers a few new features that allow clients such as curl to do subsequent TLS connections much faster, with only 1 or even 0 RTTs, but curl has no code for any of those features yet.
I talked with Ed Hoover on the between screens podcast a while ago and that episode has now been published. It is a dense 12 minutes as the good Ed edited it massively.
Weirdly enough, it was hard to find a high resolution version of that image today but I’m showing you a version of it on the right side here.
In the 2016 movie Jason Bourne, Swedish actress Alicia Vikander is seen working on her laptop at around 1:16:30 into the movie and there’s a single visible sticker on that laptop. Yeps, it is for sure the same EFF sticker. There’s even a very brief glimpse of the top of the red EFF dot below the “crime” word.
Everyone interested in curl, libcurl and related matters is invited to participate. We only ask of you to register and pay the small fee. The fee will be used for food and more at the event.
You’ll find the full and detailed description of the event and the specific location in the curl wiki.
The agenda for the weekend is purposely kept loose to allow for flexibility and unconference-style adding things and topics while there. You will thus have the chance to present what you like and affect what others present. Do tell us what you’d like to talk about or hear others talk about! The sign-up for the event isn’t open yet, as we first need to work out some more details.
We have a dedicated mailing list for discussing the meeting, called curl-meet, so please consider yourself invited to join in there as well!
Thanks a lot to SUSE for hosting!
Feel free to help us make a cool logo for the event!
(The 19th birthday of curl is suitably enough the day after, on March 20.)
Thursday, September 22nd 2016. An email popped up in my inbox.
Subject: ares_create_query OOB write
As one of the maintainers of the c-ares project I’m receiving mails for suspected security problems in c-ares and this was such a one. In this case, the email with said subject came from an individual who had reported a ChromeOS exploit to Google.
It turned out that this particular c-ares flaw was one important step in a sequence of necessary procedures that when followed could let the user execute code on ChromeOS from JavaScript – as the root user. I suspect that is pretty much the worst possible exploit of ChromeOS that can be done. I presume the reporter will get a fair amount of bug bounty reward for this. (Update: he got 100,000 USD for it.)
The setup and explanation on how this was accomplished is very complicated and I am deeply impressed by how this was figured out, tracked down and eventually exploited in a repeatable fashion. But bear with me. Here comes a very simplified explanation on how a single byte buffer overwrite with a fixed value could end up aiding running exploit code as root.
The main Google bug for this problem is still not open since they still have pending mitigations to perform, but since the c-ares issue has been fixed I’ve been told that it is fine to talk about this publicly.
c-ares writes a 1 outside its buffer
c-ares has a function called ares_create_query. It was added in 1.10 (released in May 2013) as an updated version of the older function ares_mkquery. This detail is mostly interesting because Google uses an older version than 1.10 of c-ares so in their case the flaw is in the old function. This is the two functions that contain the problem we’re discussing today. It used to be in the ares_mkquery function but was moved over to ares_create_query a few years ago (and the new function got an additional argument). The code was mostly unchanged in the move so the bug was just carried over. This bug was actually already present in the original ares project that I forked and created c-ares from, back in October 2003. It just took this long for someone to figure it out and report it!
I won’t bore you with exactly what these functions do, but we can stick to the simple fact that they take a name string as input, allocate a memory area for the outgoing packet with DNS protocol data and return that newly allocated memory area and its length.
Due to a logic mistake in the function, you could trick the function to allocate a too short buffer by passing in a string with an escaped trailing dot. An input string like “one.two.three\.” would then cause the allocated memory area to be one byte too small and the last byte would be written outside of the allocated memory area. A buffer overflow if you want. The single byte written outside of the memory area is most commonly a 1 due to how the DNS protocol data is laid out in that packet.
This flaw was given the name CVE-2016-5180 and was fixed and announced to the world in the end of September 2016 when c-ares 1.12.0 shipped. The actual commit that fixed it is here.
What to do with a 1?
Ok, so a function can be made to write a single byte to the value of 1 outside of its allocated buffer. How do you turn that into your advantage?
The Redhat security team deemed this problem to be of “Moderate security impact” so they clearly do not think you can do a lot of harm with it. But behold, with the right amount of imagination and luck you certainly can!
Back to ChromeOS we go.
First, we need to know that ChromeOS runs an internal HTTP proxy which is very liberal in what it accepts – this is the software that uses c-ares. This proxy is a key component that the attacker needed to tickle really badly. So by figuring out how you can send the correctly crafted request to the proxy, it would send the right string to c-ares and write a 1 outside its heap buffer.
ChromeOS uses dlmalloc for managing the heap memory. Each time the program allocates memory, it will get a pointer back to the request memory region, and dlmalloc will put a small header of its own just before that memory region for its own purpose. If you ask for N bytes with malloc, dlmalloc will use ( header size + N ) and return the pointer to the N bytes the application asked for. Like this:
With a series of cleverly crafted HTTP requests of various sizes to the proxy, the attacker managed to create a hole of freed memory where he then reliably makes the c-ares allocated memory to end up. He knows exactly how the ChromeOS dlmalloc system works and its best-fit allocator, how big the c-ares malloc will be and thus where the overwritten 1 will end up. When the byte 1 is written after the memory, it is written into the header of the next memory chunk handled by dlmalloc:
The specific byte of that following dlmalloc header that it writes to, is used for flags and the lowest bits of size of that allocated chunk of memory.
Writing 1 to that byte clears 2 flags, sets one flag and clears the lowest bits of the chunk size. The important flag it sets is called prev_inuse and is used by dlmalloc to tell if it can merge adjacent areas on free. (so, if the value 1 simply had been a 2 instead, this flaw could not have been exploited this way!)
When the c-ares buffer that had overflowed is then freed again, dlmalloc gets fooled into consolidating that buffer with the subsequent one in memory (since it had toggled that bit) and thus the larger piece of assumed-to-be-free memory is partly still being in use. Open for manipulations!
Using that memory buffer mess
This freed memory area whose end part is actually still being used opened up the play-field for more “fun”. With doing another creative HTTP request, that memory block would be allocated and used to store new data into.
The attacker managed to insert the right data in that further end of the data block, the one that was still used by another part of the program, mostly since the proxy pretty much allowed anything to get crammed into the request. The attacker managed to put his own code to execute in there and after a few more steps he ran whatever he wanted as root. Well, the user would have to get tricked into running a particular JavaScript but still…
I cannot even imagine how long time it must have taken to make this exploit and how much work and sweat that were spent. The report I read on this was 37 very detailed pages. And it was one of the best things I’ve read in a long while! When this goes public in the future, I hope at least parts of that description will become available for you as well.
A lesson to take away from this?
No matter how limited or harmless a flaw may appear at a first glance, it can serve a malicious purpose and serve as one little step in a long chain of events to attack a system. And there are skilled people out there, ready to figure out all the necessary steps.
Update: A detailed write-up about this flaw (pretty much the report I refer to above) by the researcher who found it was posted on Google’s Project Zero blog on December 14: Chrome OS exploit: one byte overflow and symlinks.
When Mac OS X first launched they did so without an existing poll function. They later added poll() in Mac OS X 10.3, but we quickly discovered that it was broken (it returned a non-zero value when asked to wait for nothing) so in the curl project we added a check in configure for that and subsequently avoided using poll() in all OS X versions to and including Mac OS 10.8 (Darwin 12). The code would instead switch to the alternative solution based on select() for these platforms.
With the release of Mac OS X 10.9 “Mavericks” in October 2013, Apple had fixed their poll() implementation and we’ve built libcurl to use it since with no issues at all. The configure script picks the correct underlying function to use.
Enter macOS 10.12 (yeah, its not called OS X anymore) “Sierra”, released in September 2016. Quickly we discovered that poll() once against did not act like it should and we are back to disabling the use of it in preference to the backup solution using select().
The new error looks similar to the old problem: when there’s nothing to wait for and we ask poll() to wait N milliseconds, the 10.12 version of poll() returns immediately without waiting. Causing busy-loops. The problem has been reported to Apple and its Radar number is 28372390. (There has been no news from them on how they plan to act on this.)
If none of the defined events have occurred on any selected file descriptor, poll() waits at least timeout milliseconds for an event to occur on any of the selected file descriptors.
We pushed a configure check for this in curl, to be part of the upcoming 7.51.0 release. I’ll also show you a small snippet you can use stand-alone below.
Apple is hardly alone in the broken-poll department. Remember how Windows’ WSApoll is broken?
Here’s a little code snippet that can detect the 10.12 breakage:
This poll bug has been confirmed fixed in the macOS 10.12.2 update (released on December 13, 2016), but I’ve found no official mention or statement about this fact.
Chevrolet Traverse 2018 uses curl according to its owners manual on page 403. It is mentioned almost identically in other Chevrolet model manuals such as for the Corvette, the 2018 Camaro, the 2018 TRAX, the 2013 VOLT, the 2014 Express and the 2017 BOLT.
The curl license is also in owner manuals for other brands and models such as in the GMC Savana, Cadillac CT6 2016, Opel Zafira, Opel Insignia, Opel Astra, Opel Karl, Opel Cascada, Opel Mokka, Opel Ampera, Vauxhall Astra … (See 100 million cars run curl).
The Onkyo TX-NR609 AV-Receiver uses libcurl as shown by the license in its manual. (Thanks to Marc Hörsken)
Over time, I’ve reluctantly come to terms with the fact that a lot of questions and answers about curl is not done on the mailing lists we have setup in the project itself.
A primary such external site with curl related questions is of course stackoverflow – hardly news to programmers of today. The questions tagged with curl is of course only a very tiny fraction of the vast amount of questions and answers that accumulate on that busy site.
The pile of questions tagged with curl on stackoverflow has just surpassed the staggering number of 25,000. Of course, these questions involve persons who ask about particular curl behaviors (and a large portion is about PHP/CURL) but there’s also a significant amount of tags for questions where curl is only used to do something and that other something is actually what the question is about. And ‘libcurl’ is used as a separate tag and is often used independently of the ‘curl’ one. libcurl is tagged on almost 2,000 questions.
But still. 25,000 questions. Wow.
I visit that site every so often and answer to some questions but I often end up feeling a great “distance” between me and questions there, and I have a hard time to bridge that gap. Also, stackoverflow the site and the format isn’t really suitable for debugging or solving problems within curl so I often end up trying to get the user move over to file an issue on curl’s github page or discuss the curl problem on a mailing list instead. Forums more suitable for plenty of back-and-forth before the solution or fix is figured out.
Now, any bets for how long it takes until we reach 100K questions?



 The main effect is that normal end users find my email address via the
The main effect is that normal end users find my email address via the  shed at the end of October 2016.
shed at the end of October 2016. Back in 2013, it came to light that
Back in 2013, it came to light that