Things did not work out the way we had planned. The 7.88.0 release that was supposed to be the last curl version 7 release contained a nasty bug that made us decide that we better ship an update once that is fixed. This is the update. The second final version 7 release.
Release presentation
Numbers
the 214th release 0 changes 5 days (total: 9,103) 25 bug-fixes (total: 8,690) 32 commits (total: 29,853) 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 0 new curl command line option (total: 250) 19 contributors, 7 new (total: 2,819) 10 authors, 1 new (total: 1,120) 0 security fixes (total: 135)
Bugfixes
As this is a rushed patch-release, there is only a small set of bugfixes merged in this cycle. The following notable bugs were fixed.
http2 multiplexed data corruption
The main bug that triggered the patch release. In some circumstances , when data was delivered as a HTTP/2 multiplexed stream, curl would get it wrong and cause the saved data to be corrupt. It would get the wrong data from the internal buffer.
This was not a new bug, but recent changes made it more likely to trigger.
make connect timeouts use full duration
In some cases curl would only allow half the given timeout period when doing connects.
runtests: fix “uninitialized value $port”
Running the test suite with verbose mode enabled, it would error out with this message. Since a short while back, we consider warnings in the test script fatal so this then aborts all the tests.
tests: make sure gnuserv-tls has SRP support before using it
The test suite uses gnuserv-tls to verify SRP authentication. It will only use this tool if found at startup, but due to recent changes in the GnuTLS project that ships this tool, it now builds with SRP disabled by default and thus can’t be used for this test. Now, the test script also checks that it actually supports SRP before trying to use it.
setopt: allow HTTP3 when HTTP2 is not defined
A regression made it impossible to ask for HTTP/3 if the build did not also support HTTP/2.
socketpair: allow EWOULDBLOCK when reading the pair check bytes
The fix in 7.88.0 turned out to cause occasional hiccups (on Windows at least) and this is a follow-up improvement for the verification of the socketpair emulation. When we create the pair and verify that it works, we must make sure that the code handles EWOULDBLOCK correctly.
Welcome to the final and last release in the series seven. The next release is planned and intended to become version 8.
Numbers
the 213th release 5 changes 56 days (total: 9,098) 173 bug-fixes (total: 8,665) 250 commits (total: 29,821) 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 1 new curl command line option (total: 250) 78 contributors, 41 new (total: 2,812) 42 authors, 18 new (total: 1,119) 3 security fixes (total: 135)
Release presentation
Security
This time we bring you three security fixes. All of them covering cases for which we have had problems reported and fixed before, but these are new subtle variations.
While we count over 140 individual bugfixes merged for this release, here follows a curated subset of some of the more interesting ones.
http/3 happy eyeballs
When asking for HTTP/3, curl will now also try older HTTP versions with a slight delay so that if HTTP/3 does not work, it might still succeed with and use an older version.
An application can now set drastically larger download buffers. For high speed/localhost transfers of some protocols this might sometimes make a difference.
curl: output warning at –verbose output for debug-enabled version
To help users realize when they use a debug build of curl, it now outputs a warning at the top of the --verbose output. We strongly discourage users to ship or use such builds in production.
websocket: multiple bugfixes
WebSocket support remains an experimental feature in curl but it is getting better. Several smaller and bigger bugs were squashed. Please continue to try it and report any problems and we can probably consider removing the experimental label soon.
dict: URL decode the entire path always
If you used a DICT URL it would sometimes do wrong as it previously only URL decoded parts of the path when using it. Now it correctly decodes the entire thing.
URL-encode/decode much faster
The libcurl functions for doing these conversions were sped up significantly. In the order of 3x and 7x.
haxproxy: send before TLS handhshake
The haproxy details are now properly sent before the TLS handshake takes place.
HTTP/[23]: continue upload when state.drain is set
Fixes a stalling problem when data is being uploaded and downloaded at the same time.
http2: aggregate small SETTINGS/PRIO/WIN_UPDATE frames
Optimizes outgoing frames for HTTP/2 into doing more in fewer sends.
openssl: store the CA after first send (ClientHello)
By changing the order of things, curl is better off spending CPU cycles while waiting for the server’s response and thereby making the entire handshake process complete faster.
curl: repair –rate
A regression in 7.87.0 made this feature completely broken. Now back on track again.
HTTP/2 much faster multiplexed transfers
By improving the handling of multiple concurrent streams over a single connection, curl now performs such transfers much faster than before. Sometimes an almost 3x speedup.
noproxy: support for space-separated names is deprecated
The parser that parses the “noproxy” string accepts plain space (without comma) as separators, while hardly any other tool or library does. This matters because it can be set in an environment variable. This accepted space-only separation is now marked as deprecated.
nss: implement data_pending method
The NSS backend was improved to work better for cases when the socket has been drained of data and only the NSS internal buffers has it, which could lead to curl getting stalled or losing data. Note: NSS support is marked for removal later in 2023.
socketpair: allow localhost MITM sniffers
curl has an internal socketpair emulation function for Windows. The way it worked did not allow MITM sniffers, but instead return error if such a thing was detected. It turns out too many users run tools on Windows that do this, so we have changed the logic to accept their presence and use.
tests-httpd: infra to run curl against an apache httpd
An entirely new line of tests that opens up new ways to test and verify our HTTP implementations in ways we could not do before. It uses pytest and an apache httpd server with special test modules.
curl: fix hiding of command line secrets
A regression.
curl: fix error code on bad URL
If you would use an invalid URL for upload, curl would erroneously report the problem as “out of memory” which unsurprisingly greatly confused users.
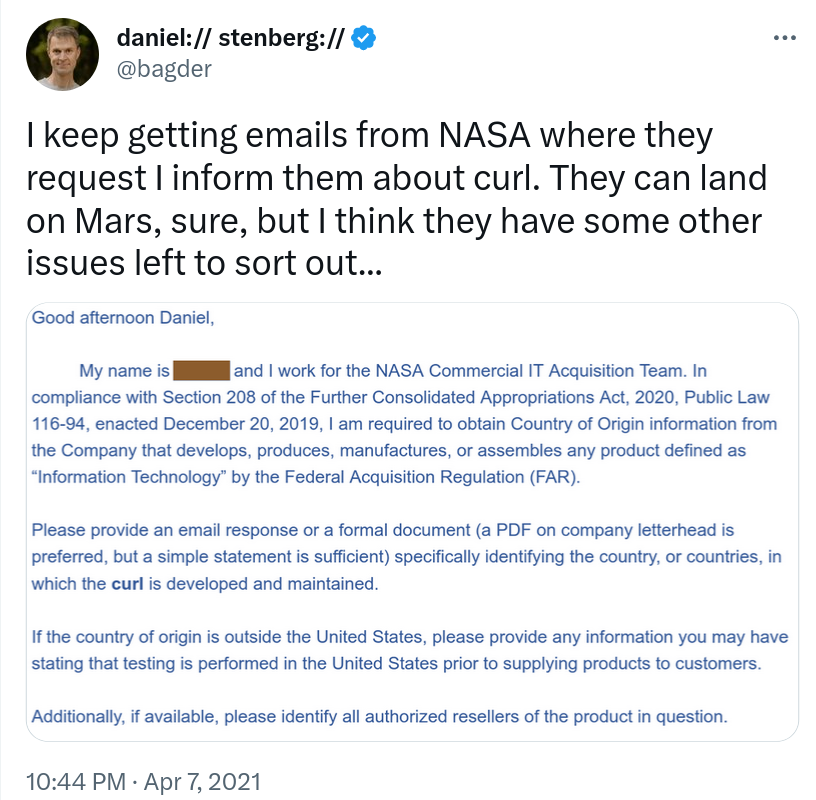
curl is actually something which is critical, especially to our data management system. It is being used very widely across NASA.
Dr Steve Crawford
2020
Back in 2020 I started getting emails from NASA asking for details and specifics about curl’s origins and in particular about where contributors to the project works, and I first replied eagerly trying to be helpful, but over time I kept receiving very similar emails from other NASA departments.
2021
It puzzled me, and out of frustration I posted this tweet in April 2021. A tweet that received a lot of attention and more than 3,000 likes.
2023
In a closing keynote at the FOSDEM 2023 conference, Dr. Steve Crawford did a talk titled NASA and Open Source Software (video, slides).
Some 24 minutes in, on slide 28, Dr Crawford shows a screenshot of the above tweet and talks about NASA’s use of curl, and says that piece I quoted at the top.
I was at the FOSDEM 2023 conference, but unfortunately I had to skip the last hour of presentations so I had just left the campus when this talk was held.
It would have been a blast to have been present in the room at that time. Now I instead got an avalanche of messages from friends and acquaintances who notified me about this talk and mention of me, which was of course also fun.
Takeaway
I’m glad NASA is aware of some of their problems and that they listen. It is a comfort that my text was taken with the right attitude. It also feels good that I used the correct tone in that Tweet: I figure it is rarely someone’s actual desire to appear clumsy or bureaucratic, but organizations and companies can easily get trapped in processes that still make them act that way.
Credit
As a celebration of NASA, the top image is taken by NASA’s James Webb Space Telescope’s Near-Infrared Camera (NIRCam) and features the central region of the Chamaeleon I dark molecular cloud, which resides 630 light years away.
In the beginning and for many years, the curl project used no CI services at all. It instead used a distributed build and test systems where volunteers ran machines that pulled the latest code repeatedly, built curl, ran the tests and reported back the results to a central server.
One
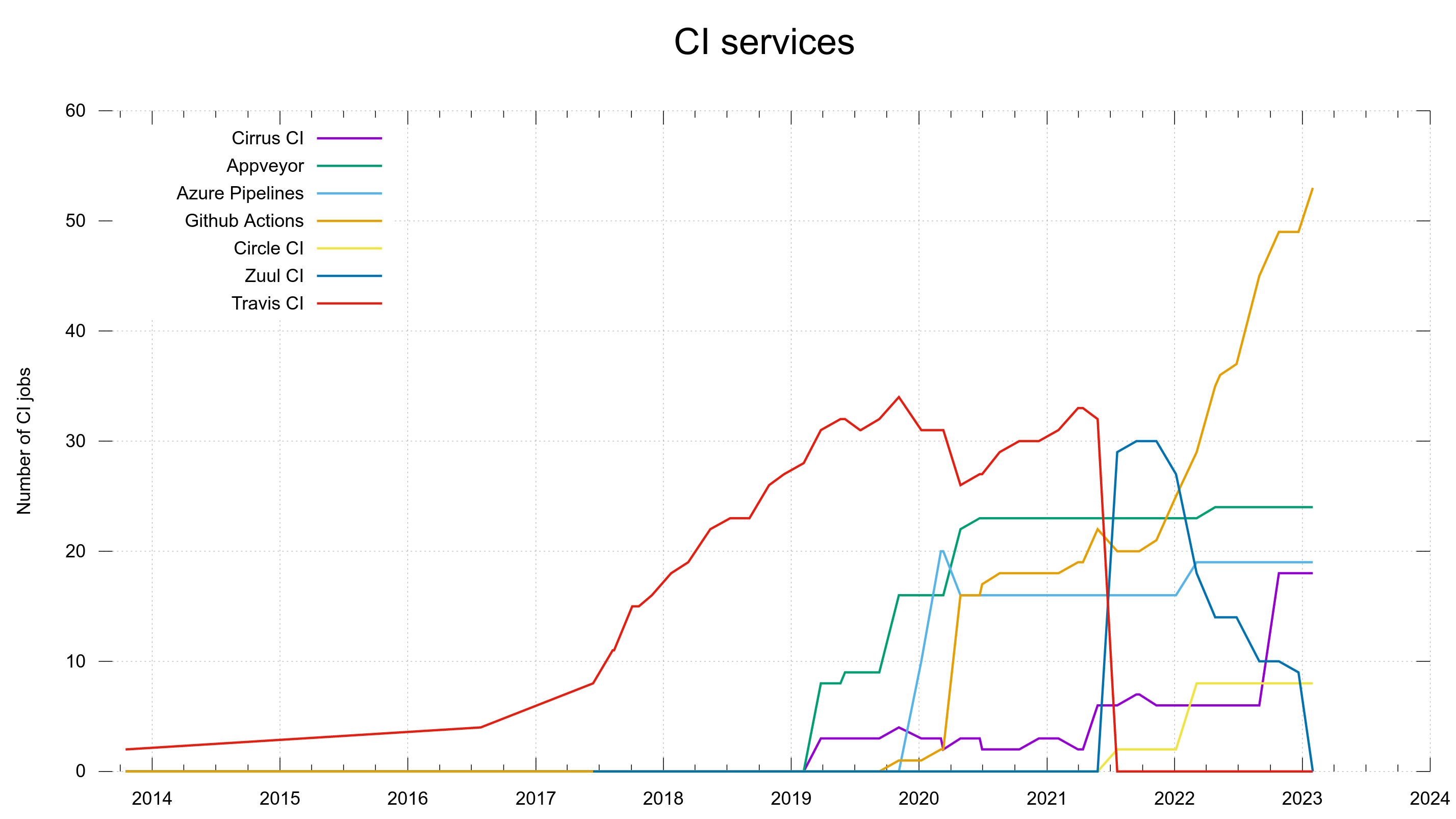
In 2013, the year curl turned 15, we created our first CI jobs on Travis CI. With only a single CI service life was easy for a few years.
Two, three
This single service had a limited feature set and in particular a limited set of supported platforms. To also do automatic testing on FreeBSD and Windows we had to use two additional services because Travis did not support them. Now they were three, early 2019. Cirrus CI and AppVeyor.
Four
When we use free services, we need to live with the limitations of what the good providers offer for free or at low cost. In the case of CI services, they tend to reduce CPU time and parallelisms for users of the free tier and so did Travis.
When the number of CI jobs on Travis surpassed 30, and we had already gotten a small performance boost just because of their good will, we created the next few new CI jobs on GitHub Actions instead to increase the parallelism for no extra money. If I recall things correctly, the macOS support was also much better on GitHub since it was rather limited on Travis.
GitHub later graciously bumped our service level for even more power and parallelism. Increased parallelism, not the least thanks to the use of several independent CI services, made sure that the complete set of CI jobs would still complete within a reasonable time.
Five
When working on extending and improving our Windows CI testing in late 2019, our previous Windows CI provider AppVeyor was not good enough so we opted to add jobs on Azure Pipelines. This was also because GitHub Actions could not run the images we have and wanted to use for this purpose.
Redundancy
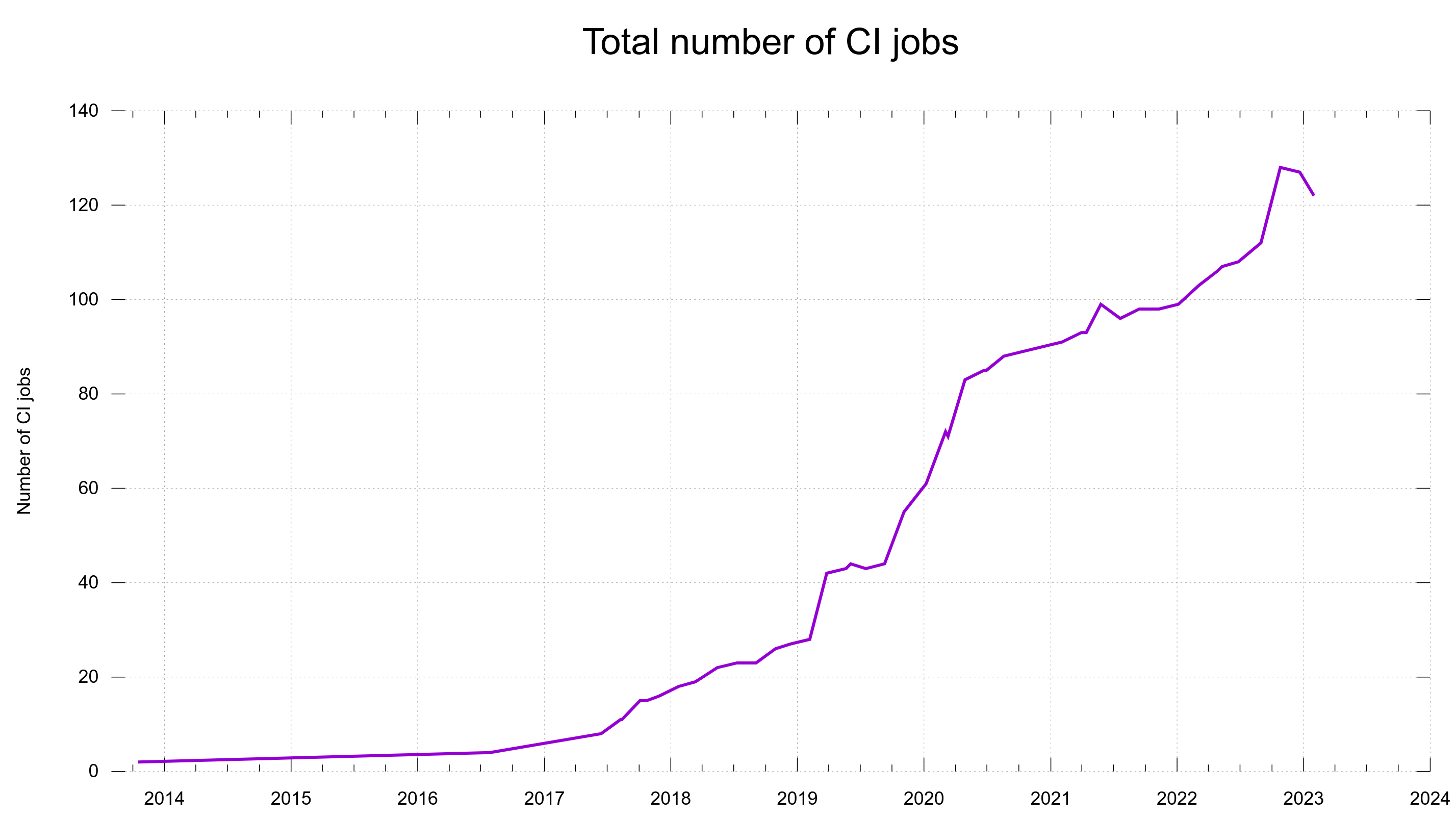
When we entered the year 2020 we were at 60 CI jobs and having them run on several different CI services often turned out useful when one of them acted up: at least a lot of other jobs would still work and help us assess and verify proposed changes. No all eggs in the same basket problem.
Services come and go
Redundancy also helps soften the blow when a service goes away. If you are in the race long enough, all services will go away or go sour eventually. This includes CI services.
In 2021, Travis CI changed their policies and suddenly we could not keep using them unless we paid up a few K USD per year and we would rather avoid that.
We had to move the 30+ CI jobs from Travis to something else. Thanks to a generous offer, volunteers showed up and helped transition the Travis jobs over to a new service: Zuul CI. It softened the repercussions from the “jump” and the CI jobs kept helping us ship quality code.
Five, Six
To manage the Travis CI eviction, Zuul took over most of the curl CI jobs and a few of them were added on Circle CI, which then appeared as CI service number six. Primarily because of their at the time early and convenient support for arm.
Zuul CI
We were grateful for the help we got to move over to Zuul from Travis, but soon it became apparent to us that Zuul CI is more “crude” than some of the other services and it left us wanting more. It’s UI is way less sophisticated, to the level that it is almost difficult for a casual PR submitted to read and understand build errors. Also, it was slightly buggy, which could result in Zuul jobs not showing up in the GitHub UI at all or simply failing to trigger the new jobs. When the responses from the Zuul side to our problems were somewhere between slow to non-existent I felt with had no other choice but to transition away from this service as well.
The change took its time. At the end of 2021 we had 30 CI jobs on Zuul, and just days ago in late January 2023, we removed the final curl jobs from it.
Five
We use five services now and we could possibly consolidate down to four if we really wanted to, but I see no reason to do that now when things are working and huffing along.
GitHub Actions have really taken off as our primary CI service and now runs almost half of the entire set. Thanks to it being convenient, well integrated, well documented and us having good parallelism on it.
We do what we need
Whatever is good for the project we will consider doing. We have gotten to this point with this set of CI services because they help the project. If someone proposes a change that improve things and that change reduces the number of CI services, then we might go that way next. Or maybe we add one? We have not planned what comes next.
What we run in CI
We build curl and run tests with numerous different build configurations on several architectures on different operating systems. With and without debug enabled. With and without using valgrind. Most builds also run checksrc , which verifies source code style.
We run dedicated jobs that do “deeper” testing, such as building with address and undefined behavior-analyzers and running the complete curl test suite in “torture mode”.
We run markdown and man page spell checkers
We run English prose checking (using proselint) of markdown files
We run static code analyzers and fuzzers
We confirm the copyright and license situation of all files in git
We verify links within markdowns
We have a few “bot services” that can set the “hacktoberfest-accepted” label, and a labeler service that tries to automatically set proper categories for pull requests.
We verify that the release tarball looks right and works when generated from the current set of files in git
… and probably a few other things I have forgot now
Of course we have graphs
These graphs were screenshotted from the dashboard on February 1st, 2023.
The total number of CI jobs done for each PR and commit, over time
Number of CI jobs running on which CI service, over time
CI job distribution over platforms
Future
Whatever helps the project and whatever someone offers to help us make that happen, we might do. That may mean using more services, it might mean using less.
The important part is that these services are used to improve and strengthen the curl project and the products we ship.
The latest HTTP version is called HTTP/3 and is being transferred over QUIC instead of the old classic TCP+TLS duo.
An attempt of an architectural drawing could look like this:
HTTP network stacks
Remember: experimental
HTTP/3 support in curl is still experimental so we do reserve the right to change names, behavior and functionality during development.
We aim to remove this experimental label from HTTP/3 support during the spring of 2023.
HTTP/3 is for HTTPS only
Before we dig into the details of this, remember that HTTP/3 can and will only be used for HTTPS:// URLs. It is always encrypted and there is no way to do HTTP/3 over clear text. Asking to do HTTP/3 with a HTTP:// URL is therefor a non-starter. An error.
Cannot upgrade a connection
When HTTP/2 was introduced to the world, there was a companion TLS extension created called ALPN that allows a client to ask for HTTP/2 to be used. This is a very convenient and slick way for a client to mostly transparently upgrade from HTTP/1.1 to HTTP/2 over the same connection. No penalty or extra time wasted even.
With HTTP/3, the procedure cannot be done in the same easy way. As my fancy picture above shows, HTTP/3 requires a separate QUIC connection done to the host. A connection that uses HTTP/1 or HTTP/2 cannot be upgraded to HTTP/3. The client needs to make a separate, dedicated connection for HTTP/3.
(Since QUIC is done over UDP, HTTP/3 also uses a different port number space than the earlier HTTP versions.)
If the QUIC connection fails, it means there can be no HTTP/3 and then a client might instead select to try an older HTTP version over another connection.
Alt-Svc
The original and official (according to the HTTP/3 RFC) way of bootstrapping a transfer into HTTP/3 is done like this:
A client makes a request using HTTP/1 or HTTP/2 to a server and in its response headers, the server indicates that it supports HTTP/3 by including an Alt-Svc: header with details on where and how to connect to the HTTP/3 server – and also for how long into the future this information is valid.
The client can then make its next HTTP operation against that server with HTTP/3 to the above mentioned host name and port number. So unless this info was already cached, a client needs an initial “upgrade” round-trip before it can use HTTP/3. Also, many clients/browsers will rather prefer to reuse the existing initial (HTTP/2 or HTTP/1-using) connection for subsequent requests rather than creating a new one since that might be faster.
Thus, the upgrading to HTTP/3 might not happen until some time has passed that allow the initial connection to close.
curl supports alt-svc and can upgrade to HTTP/3 using it.
Alt-Svc replacement
There are some inherent problems with this header and server operators do not like it. A working group set out to fix its problems have rather suggested a new header, alt-svcb, to replace it. This header looks simpler, partly because it is made to lean on another newcomer in the game: the HTTPS DNS records.
HTTPS records
This is a proposed new DNS record which can contain information about a server’s support for (among other things) HTTP/3, called HTTPS. Called a DNS RR, where RR is Resource Record. A field of information stored in DNS.
Yes, the name of this DNS record makes discussions a little confusing as HTTPS is otherwise generally a URL scheme or perhaps even a “protocol”.
A client can use DNS to figure out if and where it should try HTTP/3 or an older HTTP version when speaking to a particular host by using this HTTPS record. This is not yet an official standard and the RFC is not finalized, but there are servers out there deploying it already and there are clients/browsers taking advantage of it.
curl does not support HTTPS records yet, but we have a rough plan for how to do it.
Just try it
During curl’s several years of having offered experimental HTTP/3 support, we have provided an option for the user to ask it to use HTTP/3 directly against the host mentioned in the URL. Known as --http3 for the command line tool.
Going forward, this option is going to remain an option to ask curl to speak HTTP/3 with the server in the URL but it will also allow curl to fallback to an earlier HTTP version in case of QUIC problems. See below for details on exactly how.
Starting now, we also introduce a new separate option to ask for exactly and only HTTP/3 without any fallback. We expect this to be less commonly used by users. This option for the command line is currently called --http3-only.
Happy eyeballs everything!
We want users to be able to ask for HTTP/3 with a fallback to an earlier HTTP version if needed. The option should start as an opt-in but with the expectation that maybe in a future it can become a default.
Challenges involve:
A not insignificant share of QUIC attempts are blocked when the company/organization from which the attempt is made does not allow them.
Sometimes UDP is just slowed down (a lot)
HTTP/3 is still only deployed in a fraction of all servers
This is how we envision to do it:
Start an HTTP/3 attempt
If it has not connected successfully within N milliseconds, start an HTTP/2 attempt in parallel. (That can become an HTTP/1 transfer depending what the server supports.)
The first successful connect wins and the other one is discarded.
For each of these separate attempts, IPv6/IPv4 is also selected in the same kind of race against each other to pick the one that connects first. Potentially making up to four parallel connect attempts going on at the same time: QUIC-IPv6, QUIC-IPv4, TCP-IPv6 and TCP-IPv4!
I made a little drawing to visualize how the different connect attempts then might get initiated:
Multi-layered happy eyeballs
This is planned
I just want to be clear: this is what we plan to make work going forward. The code does not actually work like this just yet.
Update
In a slightly longer plan, before this feature is removed from its experimental state, we will probably remove both --http3 and --http3-only from the command line tool and instead create a more generic --http-versions options to maybe replace a lot of HTTP selection options. The exact functionality and syntax for this is yet to be worked out.
The underlying libcurl options might still remain as described in this blog post though.
Starting this week, you can subscribe to my weekly report and receive it as an email. This is the brief weekly summary of my past week that I have been writing and making available for over a year already. It sums up what I have been doing recently and what I plan to do next.
Topics in the reports typically involve a lot of curl, libcurl, HTTP, protocols, standards, networking and related open source stuff.
By subscribing to this by email, you will receive a ping and get it in your inbox as soon as it it exists. This saves you from reloading the weekly report web page or risk missing my updates on social media.
Follow what happens in the projects I run and participate in. Keep up with the latest developments in all the open source and network related stuff that occupy my every day life.
Why email?
I was already sending this report over email to some receivers, so I figured I could just invite everyone who wants to receive it the same way. Depending on how people take this, I might decide to rather only do this over email going forward.
Your feedback will help me decide on how this plays out.
The weekly report emails are archived, so you can go back and check them after the fact as well.
Like so many other software projects the curl project has copyright mentions at the top of almost every file in the source code repository. Like
Copyright (C) 1998 - 2022, Daniel Stenberg ...
Over the years we have used a combination of scripts and manual edits to update the ending year in that copyright line to match the year of the latest update of that file.
As soon as we started a new year and someone updated a file, the copyright range needed update. Scripts and tools made it less uncomfortable, but it was always somewhat of a pain to remember and fix.
In 2023 this changed
When the year was again bumped and the first changes of the year were done to curl, we should then consequentially start updating years again to make ranges end with 2023.
Only this time someone asked me why? and it made me decide that what the heck, let’s completely rip them out instead! Doing it at the beginning of the year is also a very good moment.
Do we need the years?
The Berne Convention states that copyright “must be automatic; it is prohibited to require formal registration”.
The often-used copyright lines are not necessary to protect our rights. According to the Wikipedia page mentioned above, the Berne Convention has been ratified by 181 states out of 195 countries in the world.
They can still serve a purpose as they are informational and make the ownership question quite clear. The year ranges add questionable value though.
I have tried to find resources that argue for the importance of the copyright years to be stated and present, but I have not found any credible sources. Possibly because I haven’t figured out where to look.
Not alone
It turns out quite a few projects run by many different organizations or even huge companies have already dropped the years from their source code header copyright statements. Presumably at least some of those giant corporations have had their legal departments give a green light to the idea before they went ahead and published source code that way to the world.
Low risk
We own the copyrights no matter if the years are stated or not. The exact years the files were created or edited can still easily be figured out since we use version control, should anyone ever actually care about it. And we give away curl for free, under an extremely liberal license.
I don’t think we risk much by doing this move.
January 3, 2023
On this day I merged commit 2bc1d775f510, which updated 1856 files and removed copyright years from almost everywhere in the source code repository.
I decided to leave them in the main license file. Partly because this is a file that lots of companies include in their products and I have had some use of seeing the year ranges in there in the past!
Bliss
Now we can forget about copyright years in the project. It’s a relief!
A generous member of the wider curl community stepped up and donated an unused Mac mini m1 model to me to be used for curl development. Today it arrived at my home. An 8C CPU/16GB/1TB/8C GPU/1GbE model as per the sticker on the box.
The m1 mac mini, still wrapped in plastic.
Apple is not helping
Apple has shipped and used curl in their products for twenty years but they never assist, help or otherwise contribute to the development. They also don’t sponsor us in any way, like with hardware.
Yet, there are many curl users on the different Apple platforms and sometimes these users run into issues that are unique to those platforms and are challenging to address without direct access to such.
For curl
I decided to accept this gift as I believe it might help the project, but this is not a guarantee or promise that I will run around and become the mac support guy in the project. It will just allow me to sometimes get a better grip and ability to help out.
I will also offer other curl committers access to the machine in case of need. For development and debugging and whatnot. Talk to me about it.
A tiny speed comparison
My Intel-based development machine runs Linux, is ten years old and is equipped with an i7-3770K CPU at 3.5GHz. The source code is stored on an OCZ-VERTEX4 SSD on the Intel, the mac has SSD storage only.
Here’s a rough and not very scientific test of some of my most common build activities on the m1+macOS vs the old Intel+Linux machines. This is using the bleeding edge curl source code with roughly the same build config. Both used clang for compiling, a debug build.
People mention that the Intel CPU uses much more power, runs at higher temperature and that the m1 is “just first generation” and all sorts of other excuses for the results presented above. Others insist that the Makefiles must be bad or that I’m not using the mac to its best advantage etc.
None of those excuses change the fact that my ten year old machine builds curl and related code at roughly the same speed as this m1 box while I expected it to be a more noticeable speed difference in the m1’s favor. Yes, it was probably bad expectations.
When a client connects to a TLS server it gets sent one or more certificates during the handshake.
Those certificates are verified by the client, to make sure that the server is indeed the right one: the server the client expects it to be; no impostor and no man in the middle etc.
When such a server certificate is signed by a Certificate Authority (CA), that CA’s certificate is normally not sent by the server but the client is expected to have it already in its CA store.
What certs?
Ever since the day SSL and TLS first showed up in the 1990s user have occasionally wanted to be able to save the certificates provided by the server in a TLS handshake.
This is of course most convenient when that server is using a self-signed certificate or something otherwise unusual.
(WARNING: The above shown example is an insecure way of reaching the host, as it does not detect if the host is already MITMed at the time when the first command runs. Trust On First Use.)
OpenSSL
A downside with the approach above is that it requires the openssl tool. Albeit, not a big downside for most people.
There are also alternative tools provided by wolfSSL and GnuTLS etc that offer the same functionality.
QUIC
Over the last few years we have seen a huge increase in number of servers that run QUIC and HTTP/3, and tools like curl and all the popular browsers can communicate using this modern set of protocols.
OpenSSL cannot. They decided to act against what everyone wanted, and as a result the openssl tool also does not support QUIC and therefore it cannot show the certificates used for a HTTP/3 site!
This is an inconvenience to users, including many curl users. I decided I could do something about it.
CURLOPT_CERTINFO
Already back in 2016 we added a feature to libcurl that enables it to return a list of certificate information back to the application, including the certificate themselves in PEM format. We call the option CURLOPT_CERTINFO.
We never exposed this feature in the command line tool and we did not really see the need as everyone could use the openssl tool etc fine already.
Until now.
curl -w is your friend
curl supports QUIC and HTTP/3 since a few years back, even if still marked as experimental. Because of this, the above mentioned CURLOPT_CERTINFO option works fine for that protocol version as well.
Using the –write-out (-w) option and the new variables %{certs} and %{num_certs} curl can now do what you want. Get the certificates from a server in PEM format:
You can of course also add --http3 to the command line if you want, and if you like to get the certificates from a server with a self-signed one you may want to use --insecure. You might consider adding --head to avoid the response body. This command line uses -o to write the content to /dev/null because it does not care about that data.
The %{num_certs} variable shows the number of certificates returned in the handshake. Typically one or two but can be more.
%{certs} outputs the certificates in PEM format together with a number of other details and meta data about the certificates in a “name: value” format.
Availability
These new -w variables are only supported if curl is built with a supported TLS backend: OpenSSL/libressl/BoringSSL/quictls, GnuTLS, Schannel, NSS, GSKit and Secure Transport.
Support for these new -w variables has been merged into curl’s master branch and is scheduled to be part of the coming release of curl version 7.88.0 on February 15th, 2023.
Today, another 1,000 commits have been recorded as done by me in the curl source code git repository since November 2021. Out of a total of 29,608 commits to the curl source code repository, I have made 17,001. 57.42%.
In 2022, I have done 56% of all the commits in the curl source repository. I am also the only developer who works full time on curl all the time.
In 2022, 179 individuals authored commits that were merged into curl. 115 of them did that for the first time this year. Over curl’s life time, a total of 1104 persons have authored code merged into curl.
Do I ever get bored? Not yet. I will let you know if I do.