At the AIxCC competition at DEF CON 33 earlier this year, teams competed against each other to find vulnerabilities in provided Open Source projects by using (their own) AI powered tools.
An added challenge was that the teams were also tasked to have their tooling generate patches for the found problems, and the competitors could have a go to try to poke holes on the patches which if they were successful would lead to a reduced score for the patching team.
Injected vulnerabilities
In order to give the team actual and perhaps even realistic flaws to find, the organizers injected flaws into existing source code. I was curious about how exactly this was done as curl was one of the projects they used for this in the finals, so I had a look and I figured I would let you know. Should you also perhaps be curious.
Would your tools find these vulnerabilities?
Other C based projects used for this in the finals included OpenSSL, little-cms, libexif, libxml2, libavif, freerdp, dav1d and wireshark.
The curl intro
First, let’s paste their description of the curl project here to enjoy their heart-warming words.
curl is a command-line tool and library for transferring data with URLs, supporting a vast array of protocols including HTTP, HTTPS, FTP, SFTP, and dozens of others. Written primarily in C, this Swiss Army knife of data transfer has been a cornerstone of internet infrastructure since 1998, powering everything from simple web requests to complex API integrations across virtually every operating system. What makes curl particularly noteworthy is its incredible protocol support–over 25 different protocols–and its dual nature as both a standalone command-line utility and a powerful library (libcurl) that developers can embed in their applications. The project is renowned for its exceptional stability, security focus, and backward compatibility, making it one of the most widely deployed pieces of software in the world. From IoT devices to major web services, curl quietly handles billions of data transfers daily, earning it a reputation as one of the most successful and enduring open source projects ever created.
Five curl “tasks”
There is this website providing (partial) information about all the challenges in the final, or as they call them: tasks. Their site for this is very flashy and cyber I’m sure, but I find it super annoying. It doesn’t provide all the details but enough to give us some basic insights of what the teams were up against.
Task 9
The organizers wrote a new protocol handler into curl for supporting the “totallyfineprotocl” (yes, with a typo) and within that handler code they injected a rather crude NULL pointer assignment shown below. The result variable is an integer containing zero at that point in the code.
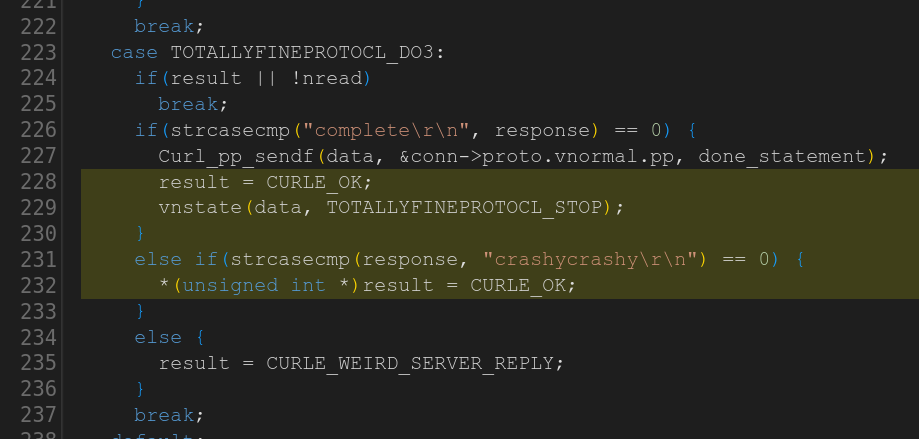
Task 10
This task had two vulnerabilities injected.
The first one is an added parser in the HTTP code for the response header X-Powered-by: where the code copies the header field value to a fixed-size 64 bytes buffer, so that if the contents is larger than so it is a heap buffer overflow.
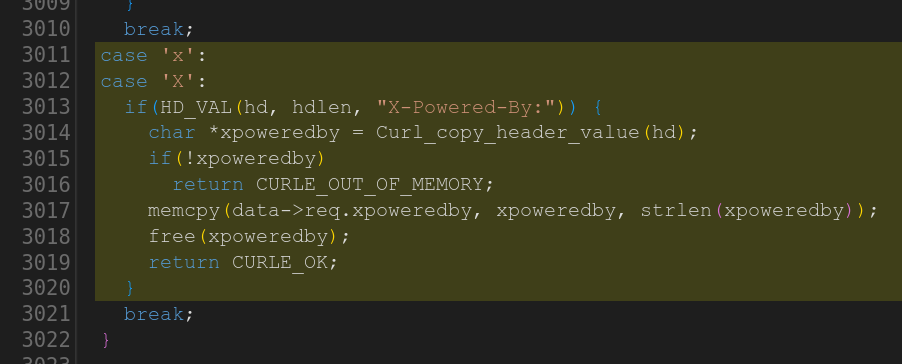
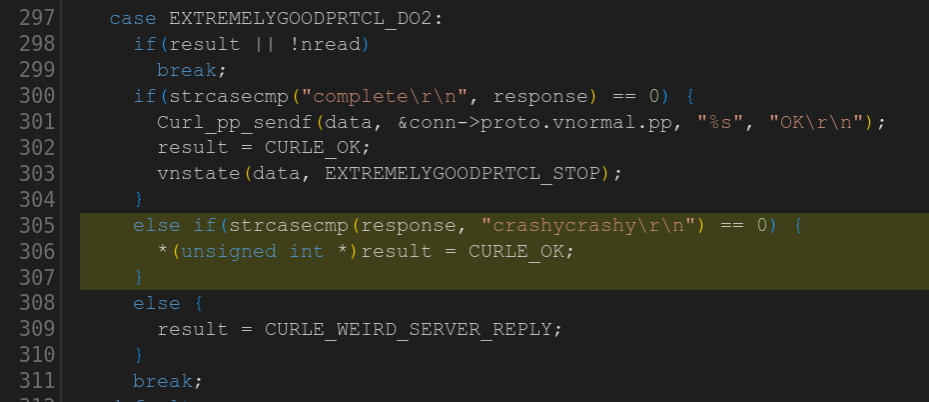
The second one is curiously almost a duplicate of task 9 using code for a new protocol:
Task 20
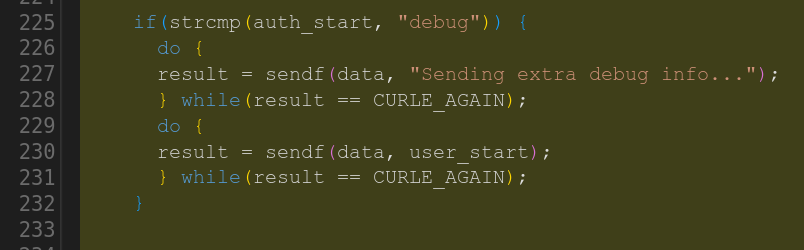
Two vulnerabilities. The first one inserts a new authentication method to the DICT protocol code, where it contains a debug handler/message with string format vulnerability. The curl internal sendf() function takes printf() formatting options.
The second is hard to understand based on the incomplete code they provide, but the gist of it that the code uses an array for number of seconds in text format that it indexes with the given “current second” without taking leap seconds into account which then would access the stack out of bounds if tm->tm_sec is ever larger than 59:
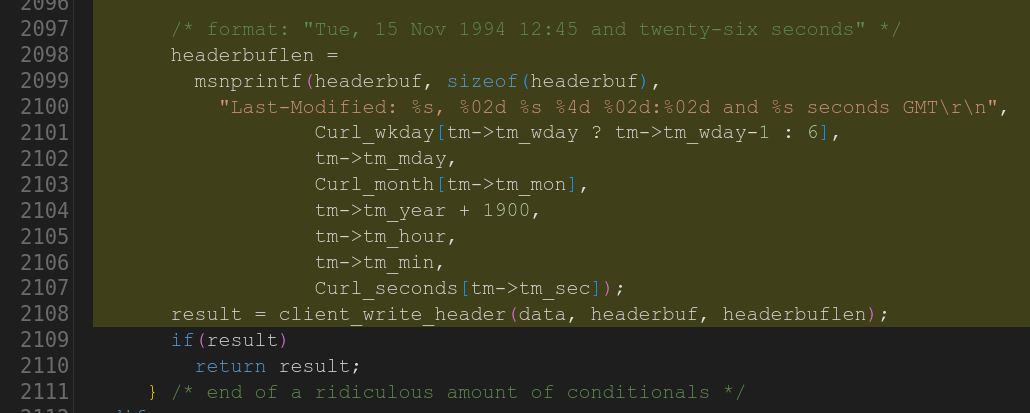
Task 24
Third time’s the charm? Here’s the maybe not so sneaky NULL pointer dereference in a third made up protocol handler quite similar to the previous two:
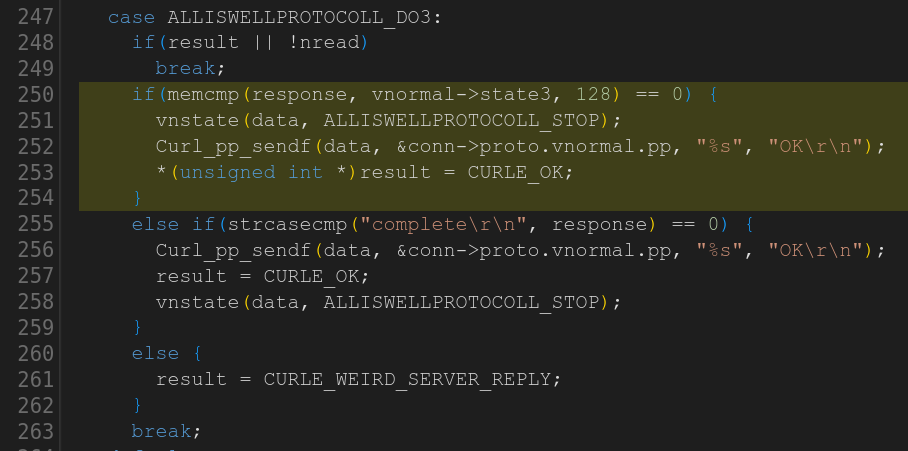
Task 44
This task is puzzling to me because it is listed as “0 vulnerabilities” and there is no vulnerability details listed or provided. Is this a challenge no one cracked? A flaw on the site? A trick question?
Modern tools find these
Given what I recently have seen what modern tools from Aisle and ZeroPath etc can deliver, I suspect lots of tools can find these flaws now. As seen above here, they were all rather straight forward and not hidden or deeply layered very much. I think for future competitions they need to up their game. Caveat of course that I didn’t look much at the tasks related to other projects; maybe they were harder?
Of course making the problems harder to find will also make more work for the organizers.
I suspect a real obstacle for the teams to find these issues had to be the amount of other potential issues the tools also found and reported; some rightfully and some not quite as correctly. Remember how ZeroPath gave us over 600 potential issues on curl’s master repository just recently. I have no particular reason to think that other projects would have fewer, at least if at a comparable size.
[Addition after first post] I was told that a general idea for how to inject proper and sensible bugs for the competition, was to re-insert flaws from old CVEs, as they are genuine problems in the project that existed in the past. I don’t know why they ended up not doing this (for curl).
Reports?
I have unfortunately not seen much written in terms of reports and details from the competition from the competing teams. I am still waiting for details on some of their scans on curl.