The official publication date of the relevant QUIC specifications is: May 27, 2021.
I’ve done many presentations about HTTP and related technologies over the years. HTTP/2 had only just shipped when the QUIC working group had been formed in the IETF and I started to mention and describe what was being done there.
I’ve explained HTTP/3
I started writing the document HTTP/3 explained in February 2018 before the protocol was even called HTTP/3 (and yeah the document itself was also called something else at first). The HTTP protocol for QUIC was just called “HTTP over QUIC” in the beginning and it took until November 2018 before it got the name HTTP/3. I did my first presentation using HTTP/3 in the title and on slides in early December 2018, My first recorded HTTP/3 presentation was in January 2019 (in Stockholm, Sweden).
In that talk I mentioned that the protocol would be “live” by the summer of 2019, which was an optimistic estimate based on the then current milestones set out by the IETF working group.
I think my optimism regarding the release schedule has kept up but as time progressed I’ve updated that estimation many times…
HTTP/3 – not yet
The first four RFC documentations to be ratified and published only concern QUIC, the transport protocol, and not the HTTP/3 parts. The two HTTP/3 documents are also in queue but are slightly delayed as they await some other prerequisite (“generic” HTTP update) documents to ship first, then the HTTP/3 ones can ship and refer to those other documents.
QUIC
QUIC is a new transport protocol. It is done over UDP and can be described as being something of a TCP + TLS replacement, merged into a single protocol.
Okay, the title of this blog is misleading. QUIC is actually documented in four different RFCs:
RFC 9002 – QUIC Loss Detection and Congestion Control
My role: I’m just a bystander
I initially wanted to keep up closely with the working group and follow what happened and participate on the meetings and interims etc. It turned out to be too difficult for me to do that so I had to lower my ambitions and I’ve mostly had a casual observing role. I just couldn’t muster the energy and spend the time necessary to do it properly.
I’ve participated in many of the meetings, I’ve been present in the QUIC implementers slack, I’ve followed lots of design and architectural discussions on the mailing list and in GitHub issues. I’ve worked on implementing support for QUIC and h3 in curl and thanks to that helped out iron issues and glitches in various implementations, but the now published RFCs have virtually no traces of me or my feedback in them.
In the curl project we make great efforts to store a lot of meta data about each and every vulnerability that we have fixed over the years – and curl is over 23 years old. This data set includes CVE id, first vulnerable version, last vulnerable version, name, announce date, report to the project date, CWE, reward amount, code area and “C mistake kind”.
We also keep detailed data about releases, making it easy to look up for example release dates for specific versions.
Dashboard
All this, combined with my fascination (some would call it obsession) of graphs is what pushed me into creating the curl project dashboard, with an ever-growing number of daily updated graphs showing various data about the curl projects in visual ways. (All scripts for that are of course also freely available.)
What to show is interesting but of course it is sometimes even more important how to show particular data. I don’t want the graphs just to show off the project. I want the graphs to help us view the data and make it possible for us to draw conclusions based on what the data tells us.
Vulnerabilities
The worst bugs possible in a project are the ones that are found to be security vulnerabilities. Those are the kind we want to work really hard to never introduce – but we basically cannot reach that point. This special status makes us focus a lot on these particular flaws and we of course treat them special.
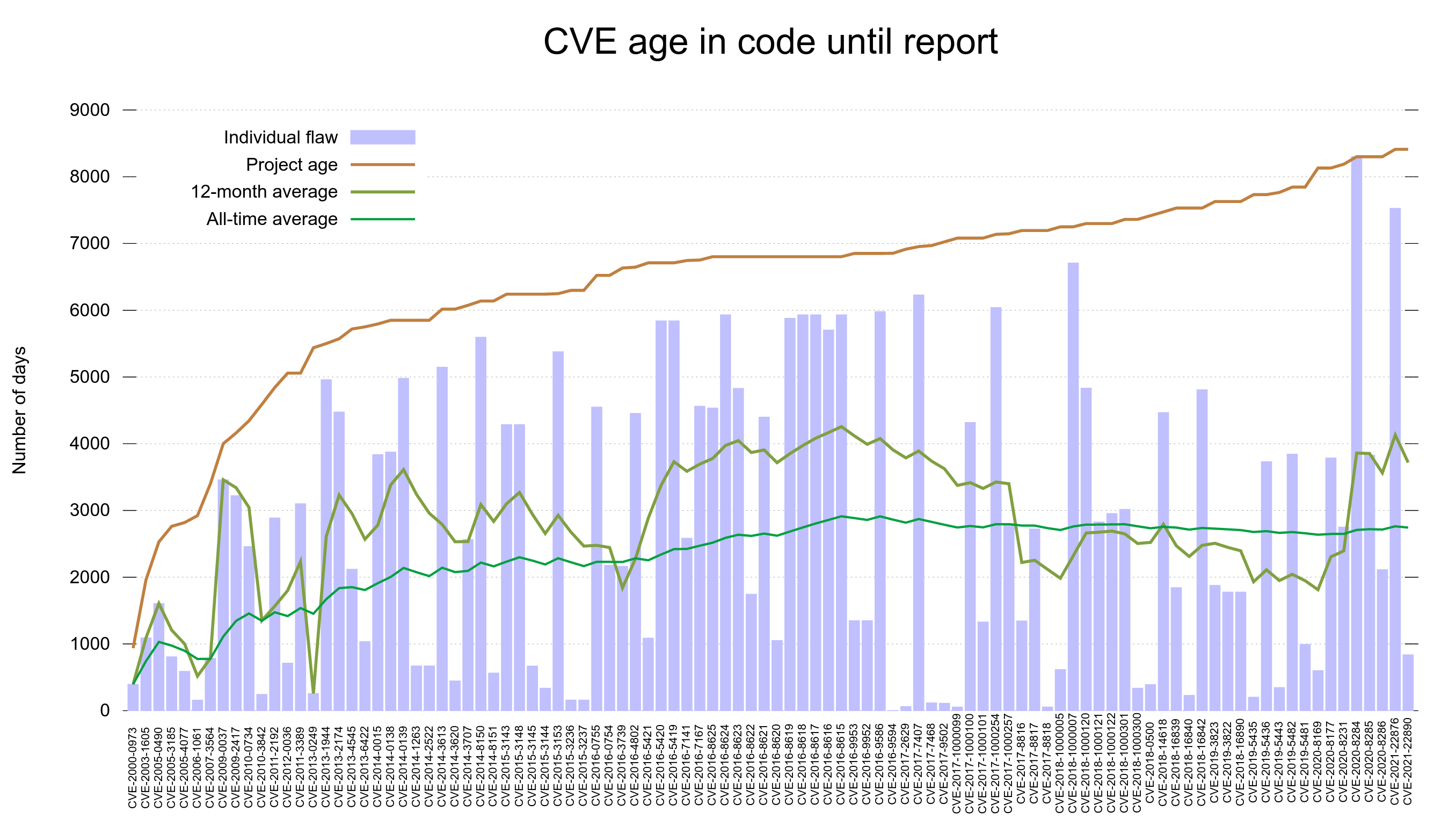
For a while we’ve had two particular vulnerability graphs in the dashboard. One showed the number of fixed issues over time and another one showed how long each reported vulnerability had existed in released source code until a fix for it shipped.
CVE age in code until report
The CVE age in code until report graph shows that in general, reported vulnerabilities were introduced into the code base many years before they are found and fixed. In fact, the all time average time suggests they are present for more than 2,700 – more than seven years. Looking at the reports from the last 12 months, the average is even almost 1000 days more!
It takes a very long time for vulnerabilities to get found and reported.
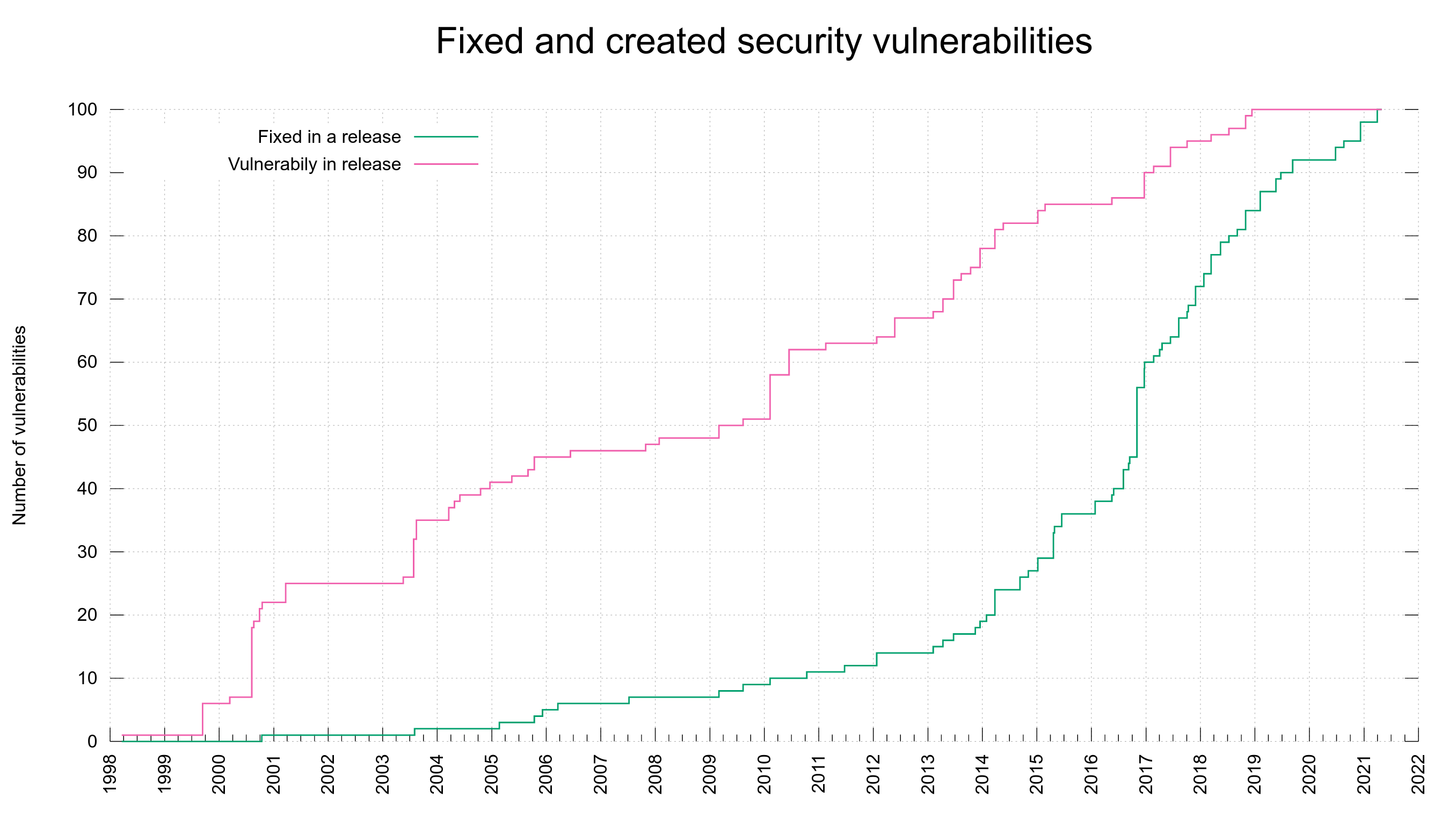
When were the vulnerabilities introduced
Just the other day it struck me that even though I had a lot of graphs already showing in the dashboard, there was none that actually showed me in any nice way at what dates we created the vulnerabilities we spent so much time and effort hunting down, documenting and talking about.
I decided to use the meta data we already have and add a second plot line to the already existing graph. Now we have the previous line (shown in green) that shows the number of fixed vulnerabilities bumped at the date when a fix was released.
Added is the new line (in red) that instead is bumped for every date we know a vulnerability was first shipped in a release. We know the version number from the vulnerability meta data, we know the release date of that version from the release meta data.
This all new graph helps us see that out of the current 100 reported vulnerabilities, half of them were introduced into the code before 2010.
Using this graph it also very clear to me that the increased CVE reporting that we can spot in the green line started to accelerate in the project in 2016 was not because the bugs were introduced then. The creation of vulnerabilities rather seem to be fairly evenly distributed over time – with occasional bumps but I think that’s more related to those being particular releases that introduced a larger amount of features and code.
As the average vulnerability takes 2700 days to get reported, it could indicate that flaws landed since 2014 are too young to have gotten reported yet. Or it could mean that we’ve improved over time so that new code is better than old and thus when we find flaws, they’re more likely to be in old code paths… I don’t think the red graph suggests any particular notable improvement over time though. Possibly it does if we take into account the massive code growth we’ve also had over this time.
The green “fixed” line at least has a much better trend and growth angle.
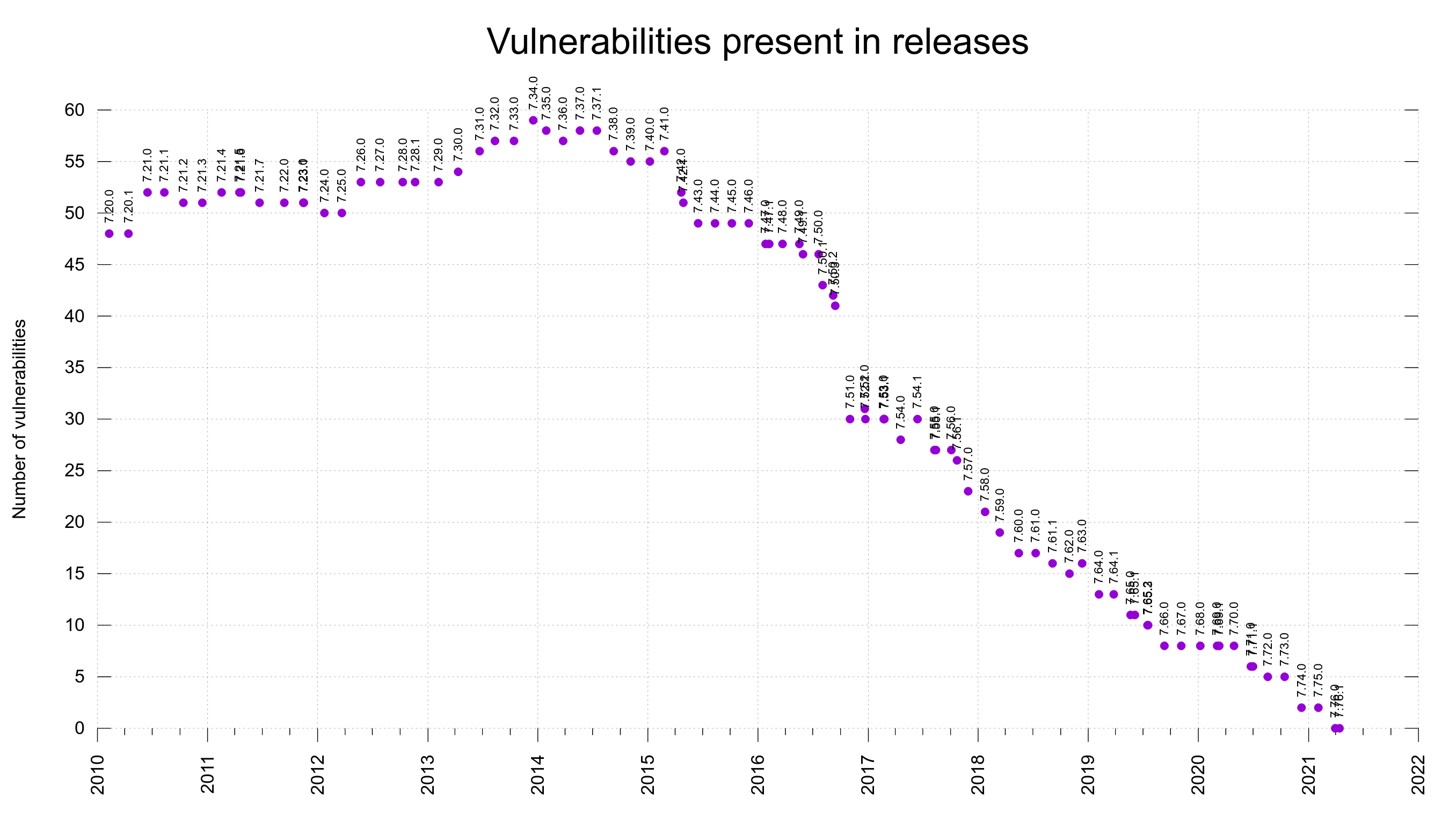
Present in which releases
As we have the range of vulnerable releases stored in the meta data file for each CVE, we can then add up the number of the flaws that are present in every past release.
Together with the release dates of the versions, we can make a graph that shows the number of reported vulnerabilities that are present in each past release over time, in a graph.
You can see that some labels end up overwriting each other somewhat for the occasions when we’ve done two releases very close in time.
tldr: the level of HTTP/3 support in servers is surprisingly high.
The specs
The specifications are all done. They’re now waiting in queues to get their final edits and approvals before they will get assigned RFC numbers and get published as such – they will not change any further. That’s a set of RFCs (six I believe) for various aspects of this new stack. The HTTP/3 spec is just one of those. Remember: HTTP/3 is the application protocol done over the new transport QUIC. (See http3 explained for a high-level description.)
The HTTP/3 spec was written to refer to, and thus depend on, two other HTTP specs that are in the works: httpbis-cache and https-semantics. Those two are mostly clarifications and cleanups of older HTTP specs, but this forces the HTTP/3 spec to have to get published after the other two, which might introduce a small delay compared to the other QUIC documents.
The working group has started to take on work on new specifications for extensions and improvements beyond QUIC version 1.
HTTP/3 Usage
In early April 2021, the usage of QUIC and HTTP/3 in the world is measured by a few different companies.
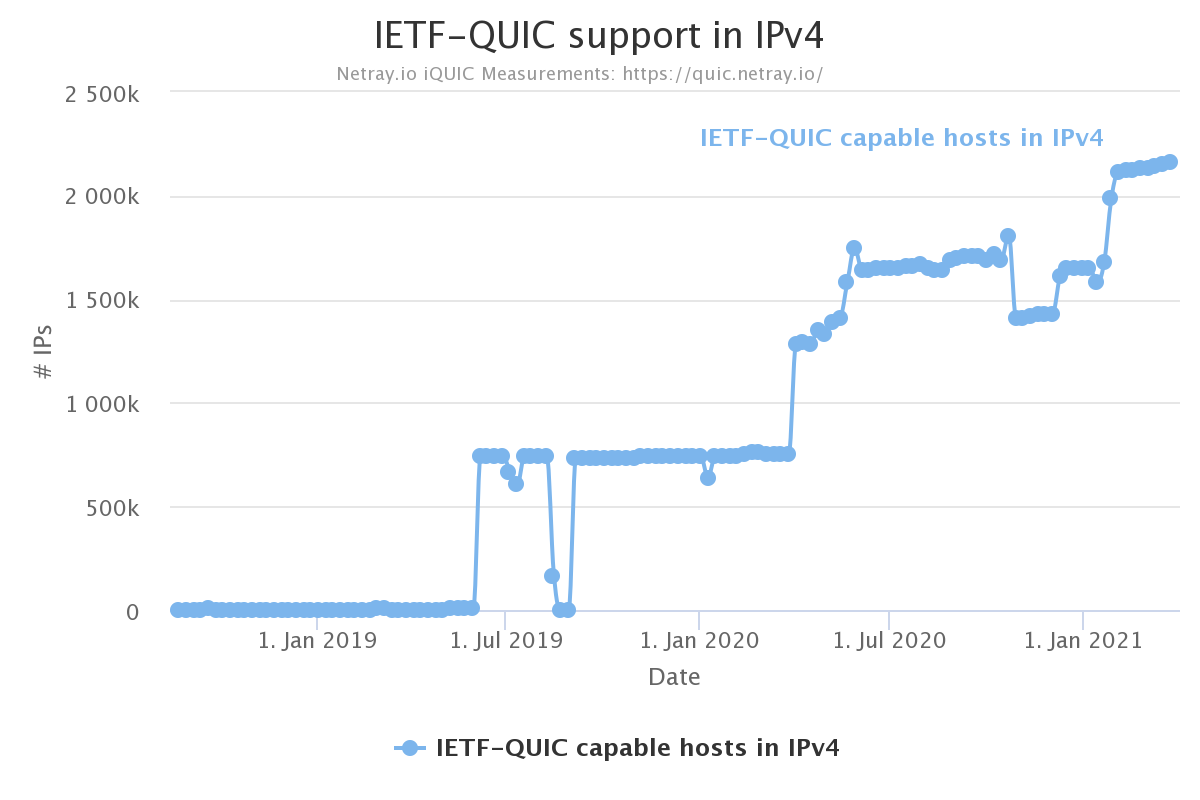
QUIC support
netray.io scans the IPv4 address space weekly and checks how many hosts that speak QUIC. Their latest scan found 2.1 million such hosts.
Arguably, the netray number doesn’t say much. Those two million hosts could be very well used or barely used machines.
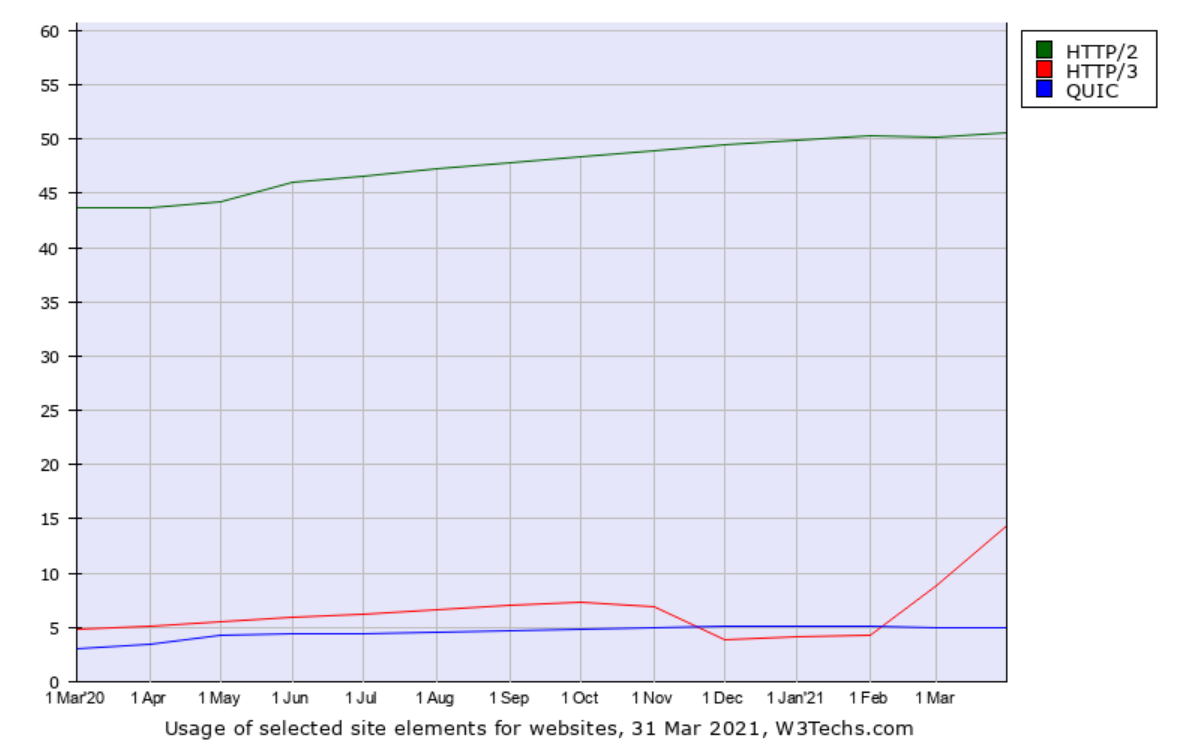
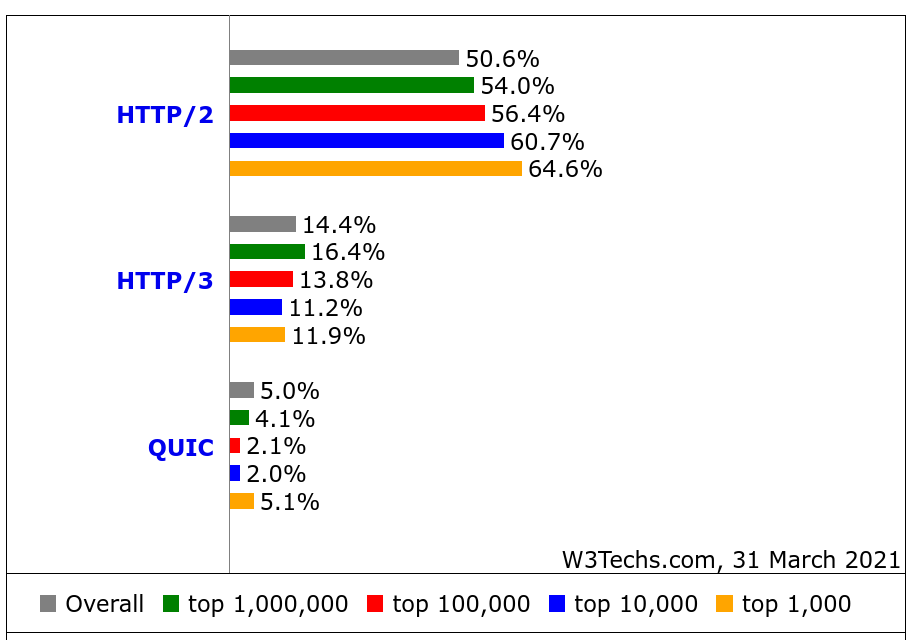
HTTP/3 by w3techs
w3techs.com has been in the game of scanning web sites for stats purposes for a long time. They scan the top ten million sites and count how large share that runs/supports what technologies and they also check for HTTP/3. In their data they call the old Google QUIC for just “QUIC” which is confusing but that should be seen as the precursor to HTTP/3.
What stands out to me in this data except that the HTTP/3 usage seems very high: the top one-million sites are claimed to have a higher share of HTTP/3 support (16.4%) than the top one-thousand (11.9%)! That’s the reversed for HTTP/2 and not how stats like this tend to look.
It has been suggested that the growth starting at Feb 2021 might be explained by Cloudflare’s enabling of HTTP/3 for users also in their free plan.
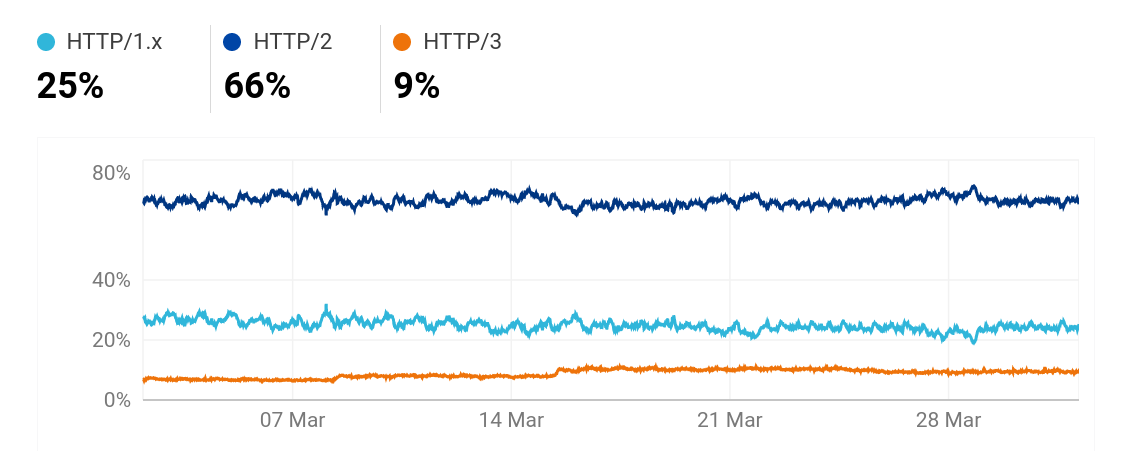
HTTP/3 by Cloudflare
On radar.cloudflare.com we can see Cloudflare’s view of a lot of Internet and protocol trends over the world.
The last 30 days according to radar.cloudflare.com
This HTTP/3 number is significantly lower than w3techs’. Presumably because of the differences in how they measure.
Clients
The browsers
All the major browsers have HTTP/3 implementations and most of them allow you to manually enable it if it isn’t already done so. Chrome and Edge have it enabled by default and Firefox will so very soon. The caniuse.com site shows it like this (updated on April 4):
(Earlier versions of this blog post showed the previous and inaccurate data from caniuse.com. Not anymore.)
curl
curl supports HTTP/3 since a while back, but you need to explicitly enable it at build-time. It needs to use third party libraries for the HTTP/3 layer and it needs a QUIC capable TLS library. The QUIC/h3 libraries are still beta versions. See below for the TLS library situation.
curl’s HTTP/3 support is not even complete. There are still unsupported areas and it’s not considered stable yet.
curl supports 14 different TLS libraries at this time. Two of them have QUIC support landed: BoringSSL and GnuTLS. And a third would be the quictls OpenSSL fork. (There are also a few other smaller TLS libraries that support QUIC.)
OpenSSL
The by far most popular TLS library to use with curl, OpenSSL, has postponed their QUIC work:
At the same time they have delayed the OpenSSL 3.0 release significantly. Their release schedule page still today speaks of a planned release of 3.0.0 in “early Q4 2020”. That plan expects a few months from the beta to final release and we have not yet seen a beta release, only alphas.
Realistically, this makes QUIC in OpenSSL many months off until it can appear even in a first alpha. Maybe even 2022 material?
BoringSSL
The Google powered OpenSSL fork BoringSSL has supported QUIC for a long time and provides the OpenSSL API, but they don’t do releases and mostly focus on getting a library done for Google. People outside the company are generally reluctant to use and depend on this library for those reasons.
The quiche QUIC/h3 library from Cloudflare uses BoringSSL and curl can be built to use quiche (as well as BoringSSL).
quictls
Microsoft and Akamai have made a fork of OpenSSL available that is based on OpenSSL 1.1.1 and has the QUIC pull-request applied in order to offer a QUIC capable OpenSSL flavor to the world before the official OpenSSL gets their act together. This fork is called quictls. This should be compatible with OpenSSL in all other regards and provide QUIC with an API that is similar to BoringSSL’s.
The ngtcp2 QUIC library uses quictls. curl can be built to use ngtcp2 as well as with quictls,
Is HTTP/3 faster?
I realize I can’t blog about this topic without at least touching this question. The main reason for adding support for HTTP/3 on your site is probably that it makes it faster for users, so does it?
According to cloudflare’s tests, it does, but the difference is not huge.
We’ve seen other numbers say h3 is faster shown before but it’s hard to find up-to-date performance measurements published for the current version of HTTP/3 vs HTTP/2 in real world scenarios. Partly of course because people have hesitated to compare before there are proper implementations to compare with, and not just development versions not really made and tweaked to perform optimally.
I think there are reasons to expect h3 to be faster in several situations, but for people with high bandwidth low latency connections in the western world, maybe the difference won’t be noticeable?
Future
I’ve previously shown the slide below to illustrate what needs to be done for curl to ship with HTTP/3 support enabled in distros and “widely” and I think the same works for a lot of other projects and clients who don’t control their TLS implementation and don’t write their own QUIC/h3 layer code.
This house of cards of h3 is slowly getting some stable components, but there are still too many moving parts for most of us to ship.
I assume that the rest of the browsers will also enable HTTP/3 by default soon, and the specs will be released not too long into the future. That will make HTTP/3 traffic on the web increase significantly.
The QUIC and h3 libraries will ship their first non-beta versions once the specs are out.
The TLS library situation will continue to hamper wider adoption among non-browsers and smaller players.
The big players already deploy HTTP/3.
Updates
I’ve updated this post after the initial publication, and the biggest corrections are in the Chrome/Edge details. Thanks to immediate feedback from Eric Lawrence. Remaining errors are still all mine! Thanks also to Barry Pollard who filed the PR to update the previously flawed caniuse.com data.
curl is an internet transfer engine. A rather modular one too. Parts of curl’s functionality is provided by selectable alternative implementations that we call backends. You select what backends to enable at build-time and in many cases the backends are enabled and powered by different 3rd party libraries.
Many backends
curl has a range of such alternative backends for various features:
International Domain Names
Name resolving
TLS
SSH
HTTP/3
HTTP content encoding
HTTP
Stable API and ABI
Maintaining a stable API and ABI is key to libcurl. As long as those promises are kept, changing internals such as switching between backends is perfectly fine.
The API is the armored front door that we don’t change. The backends is the garden on the back of the house that we can dig up and replant every year if we want, without us having to change the front door.
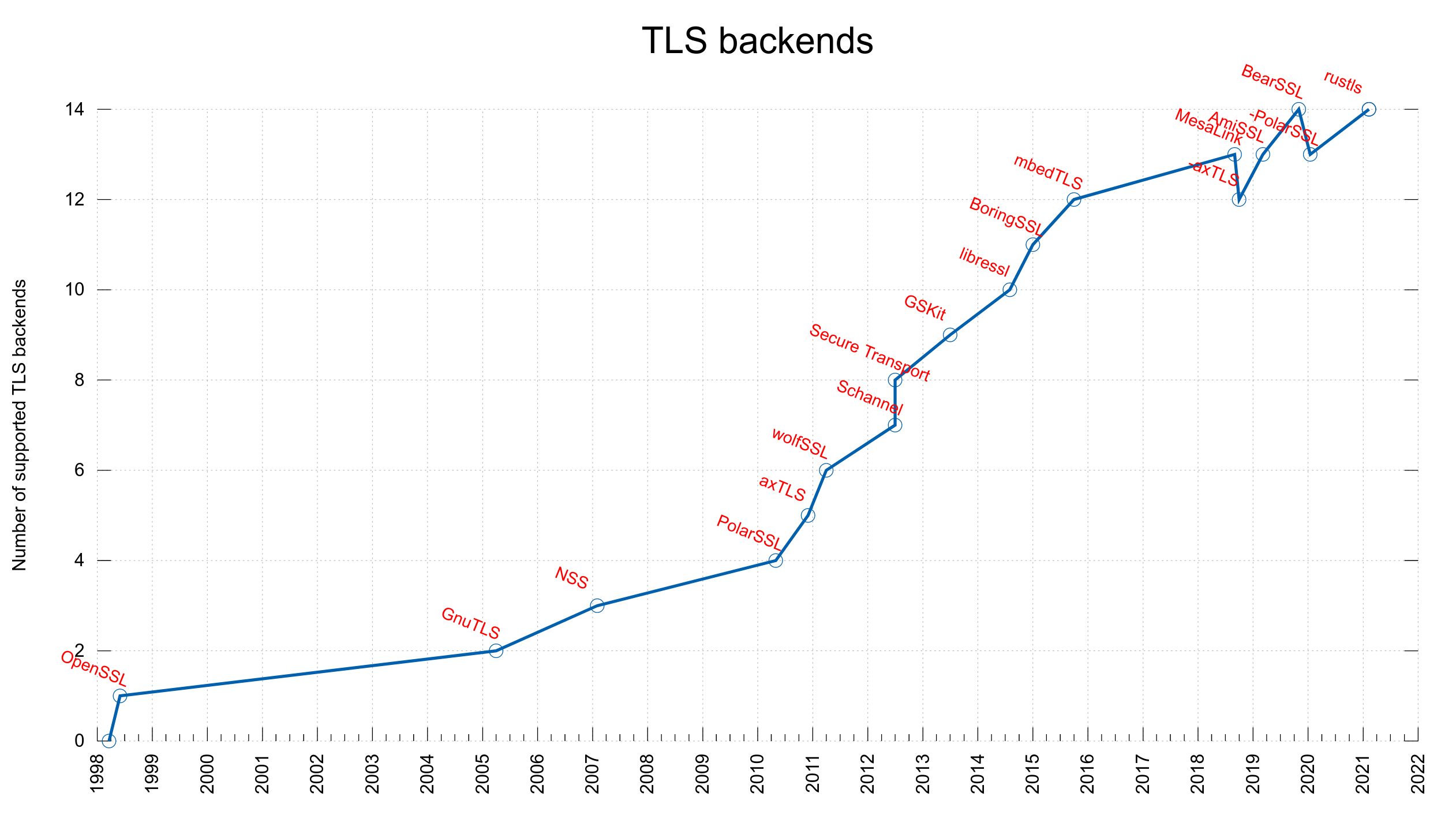
TLS backends
Already back in 2005 we added support for using an alternative TLS library in curl when we added support for GnuTLS in addition to OpenSSL, and since then we’ve added many more. We do this by having an internal API through which we do all the TLS related things and for each third party library we support we have code that does the necessary logic to connect the internal API with the corresponding TLS library.
rustls
Today, we merged support for yet another TLS library: rustls. This is a TLS library written in rust and it has a C API provided in a separate project called crustls. Strictly speaking, curl is built to use crustls.
This is still early days for the rustls backend and it is not yet feature complete. There’s more work to do and polish to apply before we can think of it as a proper competitor to the already established and well-used TLS backends, but with this merge it makes it much easier for more people to help out and test it out. Feel free and encouraged to join in!
We count this addition as the 14th concurrently supported TLS library in curl. I’m not aware of any other project, anywhere, that supports more or even this many TLS libraries.
rustls again!
The TLS library named mesalink is actually already using rustls, but under an OpenSSL API disguise and we support that since a few years back…
Credits
The TLS backend code for rustls was written and contributed by Jacob Hoffman-Andrews.
On February 11th, 2021 18:00 UTC (10am Pacific time, 19:00 Central Europe) we invite you to participate in a webinar we call “curl, Hyper and Rust”. To join us at the live event, please register via the link below:
https://www.wolfssl.com/isrg-partner-webinar/
What is the project about, how will this improve curl and Hyper, how was it done, what lessons can be learned, what more can we expect in the future and how can newcomers join in and help?
Participating speakers in this webinar are:
Daniel Stenberg. Founder of and lead developer of curl.
Josh Aas, Executive Director at ISRG / Let’s Encrypt.
The event went on for 60 minutes, including the Q&A session at the end.
Recording
Questions?
If you already have a question you want to ask, please let us know ahead of time. Either in a reply here on the blog, or as a reply on one of the many tweets that you will see about about this event from me and my fellow “webinarees”.
You might recall that my Twitter account was hijacked and then again just two weeks later.
The first: brute-force
The first take-over was most likely a case of brute-forcing my weak password while not having 2FA enabled. I have no excuse for either of those lapses. I had convinced myself I had 2fa enabled which made me take a (too) lax attitude to my short 8-character password that was possible to remember. Clearly, 2fa was not enabled and then the only remaining wall against the evil world was that weak password.
The second time
After that first hijack, I immediately changed password to a strong many-character one and I made really sure I enabled 2fa with an authenticator app and I felt safe again. Yet it would only take seventeen days until I again was locked out from my account. This second time, I could see how someone had managed to change the email address associated with my account (displayed when I wanted to reset my password). With the password not working and the account not having the correct email address anymore, I could not reset the password, and my 2fa status had no effect. I was locked out. Again.
It felt related to the first case because I’ve had my Twitter account since May 2008. I had never lost it before and then suddenly after 12+ years, within a period of three weeks, it happens twice?
Why and how
How this happened was a complete mystery to me. The account was restored fairly swiftly but I learned nothing from that.
Then someone at Twitter contacted me. After they investigated what had happened and how, I had a chat with a responsible person there and he explained for me exactly how this went down.
Had Twitter been hacked? Is there a way to circumvent 2FA? Were my local computer or phone compromised? No, no and no.
Apparently, an agent at Twitter who were going through the backlog of issues, where my previous hijack issue was still present, accidentally changed the email on my account by mistake, probably confusing it with another account in another browser tab.
There was no outside intruder, it was just a user error.
Okay, the cynics will say, this is what he told me and there is no evidence to back it up. That’s right, I’m taking his words as truth here but I also think the description matches my observations. There’s just no way for me or any outsider to verify or fact-check this.
A brighter future
They seem to already have identified things to improve to reduce the risk of this happening again and Michael also mentioned a few other items on their agenda that should make hijacks harder to do and help them detect suspicious behavior earlier and faster going forward. I was also happy to provide my feedback on how I think they could’ve made my lost-account experience a little better.
I’m relieved that the second time at least wasn’t my fault and neither of my systems are breached or hacked (as far as I know).
I’ve also now properly and thoroughly gone over all my accounts on practically all online services I use and made really sure that I have 2fa enabled on them. On some of them I’ve also changed my registered email address to one with 30 random letters to make it truly impossible for any outsider to guess what I use.
(I’m also positively surprised by this extra level of customer care Twitter showed for me and my case.)
Am I a target?
I don’t think I am. I think maybe my Twitter account could be interesting to scammers since I have almost 25K followers and I have a verified account. Me personally, I work primarily with open source and most of my works is already made public. I don’t deal in business secrets. I don’t think my personal stuff attracts attackers more than anyone else does.
What about the risk or the temptation for bad guys in trying to backdoor curl? It is after all installed in some 10 billion systems world-wide. I’ve elaborated on that before. Summary: I think it is terribly hard for someone to actually manage to do it. Not because of the security of my personal systems perhaps, but because of the entire setup and all processes, signings, reviews, testing and scanning that are involved.
So no. I don’t think my personal systems are a valued singled out target to attackers.
Status: 00:27 in the morning of December 4 my account was restored again. No words or explanations on how it happened – yet.
This morning (December 3rd, 2020) I woke up to find myself logged out from my Twitter account on the devices where I was previously logged in. Due to “suspicious activity” on my account. I don’t know the exact time this happened. I checked my phone at around 07:30 and then it has obviously already happened. So at time time over night.
Trying to log back in, I get prompted saying I need to update my password first. Trying that, it wants to send a confirmation email to an email address that isn’t mine! Someone has managed to modify the email address associated with my account.
It has only been two weeks since someone hijacked my account the last time and abused it for scams. When I got the account back, I made very sure I both set a good, long, password and activated 2FA on my account. 2FA with auth-app, not SMS.
The last time I wasn’t really sure about how good my account security was. This time I know I did it by the book. And yet this is what happened.
Excuse the Swedish version, but it wasn’t my choice. Still, it shows the option to send the email confirmation to an email address that isn’t mine and I didn’t set it there.
Communication
I was in touch with someone at Twitter security and provided lots of details of my systems , software, IP address etc while they researched their end about what happened. I was totally transparent and gave them all info I had that could shed some light.
I was contacted by a Sr. Director from Twitter (late Dec 4 my time). We have a communication established and I’ve been promised more details and information at some point next week. Stay tuned.
Was I breached?
Many people have proposed that the attacker must have come through my local machine to pull this off. If someone did, it has been a very polished job as there is no trace at all of that left anywhere on my machine. Also, to reset my password I would imagine the attacker would need to somehow hijack my twitter session, need the 2FA or trigger a password reset and intercept the email. I don’t receive emails on my machine so the attacker would then have had to (also?) manage to get into my email machine and removed that email – and not too many others because I receive a lot of email and I’ve kept on receiving a lot of email during this period.
I’m not ruling it out. I’m just thinking it seems unlikely.
If the attacker would’ve breached my phone and installed something nefarious on that, it would not have removed any reset emails and it seems like a pretty touch challenge to hijack a “live” session from the Twitter client or get the 2FA code from the authenticator app. Not unthinkable either, just unlikely.
Most likely?
As I have no insights into the other end I cannot really say which way I think is the most likely that the perpetrator used for this attack, but I will maintain that I have no traces of a local attack or breach and I know of no malicious browser add-ons or twitter apps on my devices.
Details
Firefox version 83.0 on Debian Linux with Tweetdeck in a tab – a long-lived session started over a week ago (ie no recent 2FA codes used),
Browser extensions: Cisco Webex, Facebook container, multi-account containers, HTTPS Everywhere, test pilot and ublock origin.
I only use one “authorized app” with Twitter and that’s Tweetdeck.
On the Android phone, I run an updated Android with an auto-updated Twitter client. That session also started over a week ago. I used Google Authenticator for 2fa.
While this hijack took place I was asleep at home (I don’t know the exact time of it), on my WiFi, so all my most relevant machines would’ve been seen as originating from the same “NATed” IP address. This info was also relayed to Twitter security.
Restored
The actual restoration happens like this (and it was the exact same the last time): I just suddenly receive an email on how to reset my password for my account.
The email is a standard one without any specifics for this case. Just a template press the big button and it takes you to the Twitter site where I can set a new password for my account. There is nothing in the mail that indicates a human was involved in sending it. There is no text explaining what happened. Oh, right, the mail also include a bunch of standard security advice like “use a strong password”, “don’t share your password with others” and “activate two factor” etc as if I hadn’t done all that already…
It would be prudent of Twitter to explain how this happened, at least roughly and without revealing sensitive details. If it was my fault somehow, or if I just made it easier because of something in my end, I would really like to know so that I can do better in the future.
What was done to it?
No tweets were sent. The name and profile picture remained intact. I’ve not seen any DMs sent or received from while the account was “kidnapped”. Given this, it seems possible that the attacker actually only managed to change the associated account email address.
At 00:42 in the early morning of November 16 (my time, Central European Time), I received an email saying that “someone” logged into my twitter account @bagder from a new device. The email said it was done from Stockholm, Sweden and it was “Chrome on Windows”. (I live Stockholm)
I didn’t do it. I don’t normally use Windows and I typically don’t run Chrome. I didn’t react immediately on the email however, as I was debugging curl code at the moment it arrived. Just a few moments later I was forcibly logged out from my twitter sessions (using tweetdeck in my Firefox on Linux and on my phone).
Whoa! What was that? I tried to login again in the browser tab, but Twitter claimed my password was invalid. Huh? Did I perhaps have the wrong password? I selected “restore my password” and then learned that Twitter doesn’t even know about my email anymore (in spite of having emailed me on it just minutes ago).
At 00:50 I reported the issue to Twitter. At 00:51 I replied to their confirmation email and provided them with additional information, such as my phone number I have (had?) associated with my account.
I’ve since followed up with two additional emails to Twitter with further details about this but I have yet to hear something from them. I cannot access my account.
November 17: (30 hours since it happened). The name of my account changed to Elon Musk (with a few funny unicode letters that only look similar to the Latin letters) and pushed for bitcoin scams.
At 20:56 on November 17 I received the email with the notice the account had been restored back to my email address and ownership.
Left now are the very sad DM responses in my account from desperate and ruined people who cry out for help and mercy from the scammers after they’ve fallen for the scam and lost large sums of money.
How?
A lot of people ask me how this was done. The simple answer is that I don’t know. At. All. Maybe I will later on but right now, it all went down as described above and it does not tell how the attacker managed to perform this. Maybe I messed up somewhere? I don’t know and I refuse to speculate without having more information.
I’m convinced I had 2fa enabled on the account, but I’m starting to doubt if perhaps I am mistaking myself?
Why me?
Probably because I have a “verified” account (with a blue check-mark) with almost 24.000 followers.
Other accounts
I have not found any attacks, take-overs or breaches in any other online accounts and I have no traces of anyone attacking my local computer or other accounts of mine with value. I don’t see any reason to be alarmed to suspect that source code or github project I’m involved with should be “in danger”.
HTTP Strict Transport Security (HSTS) is a standard HTTP response header for sites to tell the client that for a specified period of time into the future, that host is not to be accessed with plain HTTP but only using HTTPS. Documented in RFC 6797 from 2012.
The idea is of course to reduce the risk for man-in-the-middle attacks when the server resources might be accessible via both HTTP and HTTPS, perhaps due to legacy or just as an upgrade path. Every access to the HTTP version is then a risk that you get back tampered content.
Browsers preload
These headers have been supported by the popular browsers for years already, and they also have a system setup for preloading a set of sites. Sites that exist in their preload list then never get accessed over HTTP since they know of their HSTS state already when the browser is fired up for the first time.
The entire .dev top-level domain is even in that preload list so you can in fact never access a web site on that top-level domain over HTTP with the major browsers.
With the curl tool
Starting in curl 7.74.0, curl has experimental support for HSTS. Experimental means it isn’t enabled by default and we discourage use of it in production. (Scheduled to be released in December 2020.)
You instruct curl to understand HSTS and to load/save a cache with HSTS information using --hsts <filename>. The HSTS cache saved into that file is then updated on exit and if you do repeated invokes with the same cache file, it will effectively avoid clear text HTTP accesses for as long as the HSTS headers tell it.
I envision that users will simply use a small hsts cache file for specific use cases rather than anyone ever really want to have or use a “complete” preload list of domains such as the one the browsers use, as that’s a huge list of sites and for most use cases just completely unnecessary to load and handle.
With libcurl
Possibly, this feature is more useful and appreciated by applications that use libcurl for HTTP(S) transfers. With libcurl the application can set a file name to use for loading and saving the cache but it also gets some added options for more flexibility and powers. Here’s a quick overview:
CURLOPT_HSTS – lets you set a file name to read/write the HSTS cache from/to.
CURLOPT_HSTSREADFUNCTION – this callback gets called by libcurl when it is about to start a transfer and lets the application preload HSTS entries – as if they had been read over the wire and been added to the cache.
CURLOPT_HSTSWRITEFUNCTION – this callback gets called repeatedly when libcurl flushes its in-memory cache and allows the application to save the cache somewhere and similar things.
Feedback?
I trust you understand that I’m very very keen on getting feedback on how this works, on the API and your use cases. Both negative and positive. Whatever your thoughts are really!
Earlier this year I was the recipient of a monetary Google patch grant with the expressed purpose of improving security in libcurl.
This was an upfront payout under this Google program describing itself as “an experimental program that rewards proactive security improvements to select open-source projects”.
I accepted this grant for the curl project and I intend to keep working fiercely on securing curl. I recognize the importance of curl security as curl remains one of the most widely used software components in the world, and even one that is doing network data transfers which typically is a risky business. curl is responsible for a measurable share of all Internet transfers done over the Internet an average day. My job is to make sure those transfers are done as safe and secure as possible. It isn’t my only responsibility of course, as I have other tasks to attend to as well, but still.
Do more
Security is already and always a top priority in the curl project and for myself personally. This grant will of course further my efforts to strengthen curl and by association, all the many users of it.
What I will not do
When security comes up in relation to curl, some people like to mention and propagate for other programming languages, But curl will not be rewritten in another language. Instead we will increase our efforts in writing good C and detecting problems in our code earlier and better.
Proactive counter-measures
Things we have done lately and working on to enforce everywhere:
String and buffer size limits – all string inputs and all buffers in libcurl that are allowed to grow now have a maximum allowed size, that makes sense. This stops malicious uses that could make things grow out of control and it helps detecting programming mistakes that would lead to the same problems. Also, by making sure strings and buffers are never ridiculously large, we avoid a whole class of integer overflow risks better.
Unified dynamic buffer functions – by reducing the number of different implementations that handle “growing buffers” we reduce the risk of a bug in one of them, even if it is used rarely or the spot is hard to reach with and “exercise” by the fuzzers. The “dynbuf” internal API first shipped in curl 7.71.0 (June 2020).
Realloc buffer growth unification – pretty much the same point as the previous, but we have earlier in our history had several issues when we had silly realloc() treatment that could lead to bad things. By limiting string sizes and unifying the buffer functions, we have reduced the number of places we use realloc and thus we reduce the number of places risking new realloc mistakes. The realloc mistakes were usually in combination with integer overflows.
Code style – we’ve gradually improved our code style checker (checksrc.pl) over time and we’ve also gradually made our code style more strict, leading to less variations in code, in white spacing and in naming. I’m a firm believer this makes the code look more coherent and therefore become more readable which leads to fewer bugs and easier to debug code. It also makes it easier to grep and search for code as you have fewer variations to scan for.
More code analyzers – we run every commit and PR through a large number of code analyzers to help us catch mistakes early, and we always remove detected problems. Analyzers used at the time of this writing: lgtm.com, Codacy, Deepcode AI, Monocle AI, clang tidy, scan-build, CodeQL, Muse and Coverity. That’s of course in addition to the regular run-time tools such as valgrind and sanitizer builds that run the entire test suite.
Memory-safe components – curl already supports getting built with a plethora of different libraries and “backends” to cater for users’ needs and desires. By properly supporting and offering users to build with components that are written in for example rust – or other languages that help developers avoid pitfalls – future curl and libcurl builds could potentially avoid a whole section of risks. (Stay tuned for more on this topic in a near future.)
Reactive measures
Recognizing that whatever we do and however tight ship we run, we will continue to slip every once in a while, is important and we should make sure we find and fix such slip-ups as good and early as possible.
Raising bounty rewards. While not directly fixing things, offering more money in our bug-bounty program helps us get more attention from security researchers. Our ambition is to gently drive up the reward amounts progressively to perhaps multi-thousand dollars per flaw, as long as we have funds to pay for them and we mange keep the security vulnerabilities at a reasonably low frequency.
More fuzzing. I’ve said it before but let me say it again: fuzzing is really the top method to find problems in curl once we’ve fixed all flaws that the static analyzers we use have pointed out. The primary fuzzing for curl is done by OSS-Fuzz, that tirelessly keeps hammering on the most recent curl code.
Good fuzzing needs a certain degree of “hand-holding” to allow it to really test all the APIs and dig into the dustiest corners, and we should work on adding more “probes” and entry-points into libcurl for the fuzzer to make it exercise more code paths to potentially detect more mistakes.