Let me tell you a story about how Windows users are deleting files from their installation and as a consequence end up in tears.
Background
The real and actual curl tool has been shipped as part of Windows 10 and Windows 11 for many years already. It is called curl.exe and is located in the System32 directory.
Microsoft ships this bundled with its Operating system. They get the code from the curl project but Microsoft builds, tests, ships and are in all ways responsible for their operating system.
In one particular case, CVE-2022-43552 was reported by the curl project in December 2022. It is a use-after-free flaw that we determined to be severity low and not higher mostly because of the very limited time window you need to make something happen for it to be exploited or abused. NVD set it to medium which admittedly was just one notch higher (this time).
This is not helpful.
“Security scanners”
Lots of Windows users everywhere runs security scanners on their systems with regular intervals in order to verify that their systems are fine. At some point after December 21, 2022, some of these scanners started to detect installations of curl that included the above mentioned CVE. Nessus apparently started this on February 23.
This is not helpful.
Panic
Lots of Windows users everywhere then started to panic when these security applications warned them about their vulnerable curl.exe. Many Windows users are even contractually “forced” to fix (all) such security warnings within a certain time period or risk bad consequences and penalties.
How do you fix this?
I have been asked numerous times about how to fix this problem. I have stressed at every opportunity that it is a horrible idea to remove the system curl or to replace it with another executable. It is very easy to download a fresh curl install for Windows from the curl site – but we still strongly discourage everyone from replacing system files.
But of course, far from everyone asked us. A seemingly large enough crowd has proceeded and done exactly what we would stress they should not: they deleted or replaced their C:\Windows\System32\curl.exe.
The real fix is of course to let Microsoft ship an update and make sure to update then. The exact update that upgrades curl to version 8.0.1 is called KB5025221 and shipped on April 11. (And yes, this is the first time you get the very latest curl release shipped in a Windows update)
The people who deleted or replaced the curl executable noticed that they cannot upgrade because the Windows update procedure detects that the Windows install has been tampered with and it refuses to continue.
I do not know how to restore this to a state that Windows update is happy with. Presumably if you bring back curl.exe to the exact state from before it could work, but I do not know exactly what tricks people have tested and ruled out.
Bad advice
I have been pointed to responses on the Microsoft site answers.microsoft.com done by “helpful volunteers” that specifically recommend removing the curl.exe executable as a fix.
This is not helpful.
I don’t want to help spreading that idea so I will not link to any such post. I have reported this to Microsoft contacts and I hope they can maybe edit or comment those posts soon.
We are not responsible
I just want to emphasize that if you install and run Windows, your friendly provider is Microsoft. You need to contact Microsoft for support and help with Windows related issues. The curl.exe you have in System32 is only provided indirectly by the curl project and we cannot fix this problem for you. We in fact fixed the problem in the source code already back in December 2022.
If you have removed curl.exe or otherwise tampered with your Windows installation, the curl project cannot help you.
trurl is a tool in a similar spirit of tr but for URLs. Here, tr stands for translate or transpose.
trurl is a small command line tool that parses and manipulates URLs, designed to help shell script authors everywhere.
URLs are tricky to parse and there are numerous security problems in software because of this. trurl wants to help soften this problem by taking away the need for script and command line authors everywhere to re-invent the wheel over and over.
trurl uses libcurl’s URL parser and will thus parse and understand URLs exactly the same as curl the command line tool does – making it the perfect companion tool.
I created trurl on March 31, 2023.
Some command line examples
Given just a URL (even without scheme), it will parse it and output a normalized version:
$ trurl ex%61mple.com/
http://example.com/
The above command will guess on a http:// scheme when none was provided. The guess has basic heuristics, like for example FTP server host names often starts with ftp:
$ trurl ftp.ex%61mple.com/
ftp://ftp.example.com/
A user can output selected components of a provided URL. Like if you only want to extract the path or the query components from it.:
trurl can read URLs to work on off a file or from stdin, and works on them in a streaming fashion suitable for filters etc.
$ cat many-urls.yxy | trurl --url-file -
...
More or different
trurl was born just a few days ago, this is what we have made it do so far. There is a high probability that it will change further going forward before it settles on exactly how things ideally should work.
It also means that we are extra open for and welcoming to feedback, ideas and pull-requests. With some luck, this could become a new everyday tool for all of us.
When a security vulnerability has been found and confirmed in curl, we request a CVE Id for the issue. This is a global unique identifier for this specific problem. We request the ID from our CVE Numbering Authority (CNA), Hackerone, which once we make the issue public will publish all details about it to MITRE, which hosts the central database.
In the curl project we have until today requested CVE Ids for and provided information about 135 vulnerabilities spread out over twenty-five years.
A CVE identifier affects a specific product (or set of products), and the problem affects the product from a version until a fixed version. And then there is a severity. How bad is the problem?
CVSS score
The Common Vulnerability Scoring System (CVSS) is a way to grade severity on a scale from zero to ten. You typically use a CVSS calculator, fill in the info as good as you can and voilá, out comes a score.
The ranges have corresponding names:
Name
Range
Low
lower 4
Medium
4.0-6.9
High
7.0-8.9
Critical
9 or higher
CVSS is a shitty system
Anyone who ever gets a problem reported for their project and tries to assess and set a CVSS score will immediately realize what an imperfect, simplified and one-dimensional concept this is.
The CVSS score leaves out several very important factors like how widespread the affected platform is, how common the affected configuration is and yet it is still very subjective as you need to assess as and mark different things as None, Low, Medium or High.
The same bug is therefore likely to end up with different CVSS scores depending on who fills in the form – even when the persons are familiar with the product and the error in question.
curl severity
In the curl project we decided to abandon CVSS years ago because of its inherent problems. Instead we use only the four severity names: Low, Medium, High, and Critical and we work out the severity together in the curl security team as we work on the vulnerability. We make sure we understand the problem, the risks, its prevalence and more. We take all factors into account and then we set a severity level we think helps the world understand it.
All security vulnerabilities are vulnerabilities and therefore security risks, even the ones set to severity Low, but having the correct severity is still important in messaging and for the rest of the world to get a better picture of howserious the issue is. Getting the right severity is important.
NVD
Let me introduce yet another player in this game. The National Vulnerability Database (NVD). (And no, it’s not “national” really).
NVD hosts a database of vulnerabilities. All CVEs that are submitted to MITRE are sucked in into NVD’s database. NVD says it “performs analysis on CVEs that have been published to the CVE Dictionary“.
That last sentence is probably important.
NVD imports CVEs into their database and they in turn offer other databases to import vulnerabilities from them. One large and known user of the NVD database is this I mentioned in a recent blog post: GitHub Security Advisory Database (GHSA DB) .
GHSA DB
This GitHub thing an ambitious database that subsequently hosts a lot of vulnerabilities that people and projects reported themselves in addition to them importing information about all vulnerabilities ever published with CVE Ids.
This creates a huge database that in theory should contain just about every software vulnerability ever reported in the public. Pretty cool.
Enter reality
NVD, in their great wisdom, rescores the CVSS score for CVE Ids they import into their database! (It’s not clear how or why, but they seem to not do it for all issues).
NVD decides they know better than the project that set the severity level for the issue, enters their own answers in the CVSS calculator and eventually sets that new score on the CVEs they import.
NVD clearly thinks they need to do this and that they improve the state of the CVEs by this practice, but the end result is close to scaremongering.
Result
Because NVD sets their own severity level and they have some sort of “worst case” approach, virtually all issues that NVD sets severity for is graded worse or much worse when they do it than how we set the severity levels.
Let’s take an example: CVE-2022-42915: HTTP proxy double-free. We deemed this a medium severity. It was not made higher partly because of the very limited time-window between the two frees, making it harder to take advantage of.
Yes, it makes you wonder what magic insights and knowledge the person/bots on NVD possessed when they did this.
Scaremongering
The different severity levels should not matter too much but people find those inflated ones and they believe them. Users also find the discrepancies, get confused and won’t know what to believe or whom to trust. After all, NVD is trust-inducing brand. People think they know their stuff and if they say critical and the curl project says medium, what are we expected to think?
I claim that NVD overstate their severity levels and there unnecessarily scares readers and make them think issues are worse and more dangerous than they actually are.
The fact that GitHub now imports all CVE data from NVD makes these severity levels get transported, shown and believed as they are now also shown in the GHSA DB.
Look how many critical issues there are!
Not exactly GitHub’s fault
This NVD habit of re-scoring is an old existing habit and I just recently learned it. GitHub’s displaying the severity levels highlighted it for me, especially since users out there seem to trust and use this GitHub database.
I have talked to humans on the GitHub database team and I push for them to ignore or filter out the severity levels as set by NVD, if possible. But me being just a single complaining maintainer I do not expect this to have much of an effect. I would urge NVD to stop this insanity if I had any way to.
Hackerone glitches?
(Updated after first post). It turns out that some CVEs that we have filed from the curl project that uses our CNA hackerone have been submitted to MITRE without any severity level or CVSS score at all. For such issues, I of course understand why someone would put their own score on the issue because then our originally set score/severity is not passed on. Then the “blame” is instead shifted to Hackerone. I have contacted them about it.
Dispute a CVSS
NVD provides a way to dispute their rescores, but that’s just an open free-text form. I have use that form to request that NVD stop rescoring all curl issues. Although I honestly think they should rather stop all rescoring and only do that in the rare occasions where the original score or severity is obviously wrong.
I cannot dispute the severity levels at GitHub. They show the NVD levels.
tldr: several hundred hours of dedicated scrutinizing of curl by a team of security experts resulted in two CVEs and a set of less serious remarks. The link to the reports is at the bottom of this article.
Thanks to an OpenSSF grant, OSTIF helped us set up a curl security audit, which the excellent Trail of Bits was selected to perform in September 2022. We are most grateful to OpenSSF for doing this for us, and I hope all users who use and rely on curl recognize this extraordinary gift. OSTIF and Trail of Bits both posted articles about this audit separately.
We previously had an audit performed on curl back in 2016 by Cure53 (sponsored by Mozilla) but I like to think that we (curl) have traveled quite far and matured a lot since those days. The fixes from the discoveries reported in that old previous audit were all merged and shipped in the 7.51.0 release, in November 2016. Now over six years ago.
Changes since previous audit
We have done a lot in the project that have improved our general security situation over the last six years. I believe we are in a much better place than the last time around. But we have also grown and developed a lot more features since then.
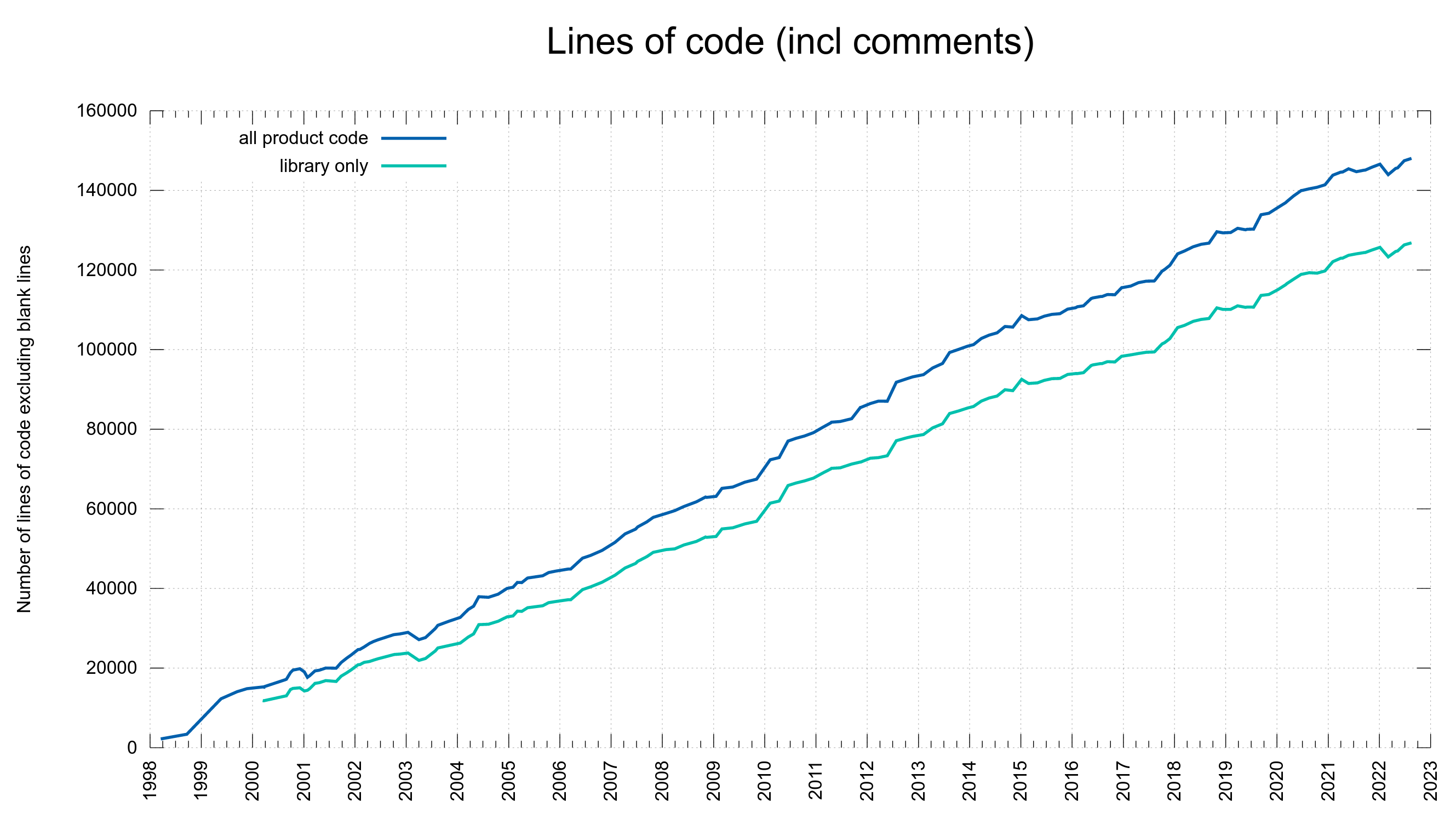
curl is now at150,000 lines of C code. This count is for “product code” only and excludes blank lines but includes 19% comments.
71 additional vulnerabilities have been reported and fixed since then. (42 of those even existed in the version that was audited in 2016 but were obviously not detected)
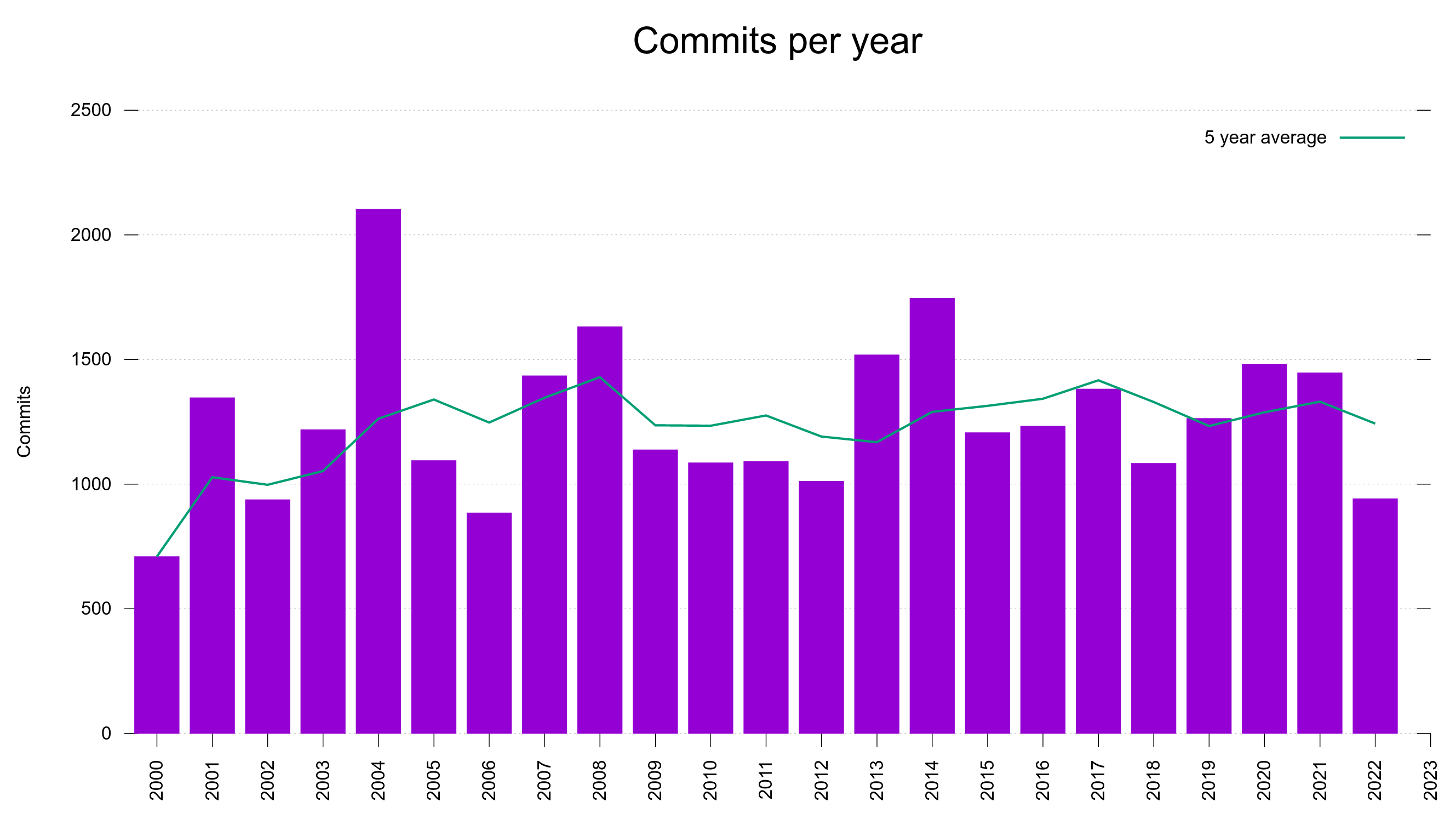
We have 30,000 additional lines of code today (+27%), and we have done over 8,000 commits since.
We have 50% more test cases (now 1550).
We have done 47 releases featuring more than 4,200 documented bugfixes and 150 changes/new features.
We have 25 times the number of CI jobs: up from 5 in 2016 to 127 today.
The OSS-Fuzz project started fuzzing curl in 2017, and it has been fuzzing curl non-stop since.
We introduced our “dynbuf” system internally in 2020 for managing growing buffers to maybe avoid common C mistakes around those.
Audit
The Trail of Bits team was assigned this as a three-part project:
Create a Threat Model document
Testing Analysis and Improvements
Secure code Review
The project was setup to use a total of 380 man hours and most of the time two Trail of Bits engineers worked in parallel on the different tasks. The Trail of Bits team themselves eventually also voluntarily extended the program with about a week. They had no problems finding people who wanted to join in and look into curl. We can safely say that they spent a significant amount of time and effort scrutinizing curl.
The curl security team members had frequent status meetings and assisted with details and could help answer questions. We would also get updates and reports on how they progressed.
The second vulnerability was found after Trail of Bits had actually ended their work and their report, while they were still running a fuzzer that triggered a separate flaw. This second vulnerability is not covered in the report but was disclosed earlier today in sync with the curl 7.87.0 release announcement: CVE-2022-43552: HTTP Proxy deny use-after-free.
Minor frictions detected
Discoveries and remarks highlighted through their work that were not consider security sensitive we could handle on the fly. Some examples include:
Using --ssl now outputs a warning saying it is unsafe and instead recommending --ssl-reqd to be used.
The Alt-svc: header parser did not deal with illegal port numbers correctly
The URL parser accepted “illegal” characters in the host name part.
Harmless memory leaks
You should of course read the full reports to learn about all the twenty something issues with all details, including feedback from the curl security team.
Actions
The curl team acted on all reported issues that we think we could act on. We disagree with the Trail of Bits team on a few issues and there are some that are “good ideas” that we should probably work on getting addressed going forward but that can’t be fixed immediately – but also don’t leave any immediate problem or danger in the code.
Conclusions
Security is not something that can be checked off as done once and for all nor can it ever be considered complete. It is a process that needs to blend in and affect everything we do when we develop software. Now and forever going forward.
This team of security professionals spent more time and effort in this security auditing and poking on curl with fuzzers than probably anyone else has ever done before. Personally, I am thrilled that they only managed to uncovered two actual security problems. I think this shows that a lot of curl code has been written the right way. The CVEs they found were not even that terrible.
Lessons
Twenty something issues were detected, and while the report includes advice from the auditors on how we should improve things going forward, they are of the kind we all already know we should do and paths we should follow. I could not really find any real lessons as in obvious things or patterns we should stop or new paradigms och styles to adapt.
I think we learned or more correctly we got these things reconfirmed:
we seem to be doing things mostly correct
we can and should do more and better fuzzing
adding more tests to increase coverage is good
Security is hard
To show how hard security can be, we received no less than three additional security reports to the project during the actual life-time when this audit was being done. Those additional security reports of course came from other people and identified security problems this team of experts did not find.
My comments on the reports
The term Unresolved is used for a few issues in the report and I have a minor qualm with the use of that particular word in this context for all cases. While it is correct that we in several cases did not act on the advice in the report, we saw some cases where we distinctly disagree with the recommendations and some issues that mentioned things we might work on and address in the future. They are all just marked as unresolved in the reports, but they are not all unresolved to us in the curl project.
In particular I am not overly pleased with how the issue called TOB-CURLTM-6 is labeled severity high and status unresolved as I believe this wrongly gives the impression that curl has issues with high severity left unresolved in the code.
If you want to read the specific responses for each and every reported issue from the curl project, they are stored in this separate GitHub gist.
The reports
You find the two reports linked to from the curl security page. A total of almost 100 pages in two PDF documents.
Recently I have received curious questions from users, customers and bystanders.
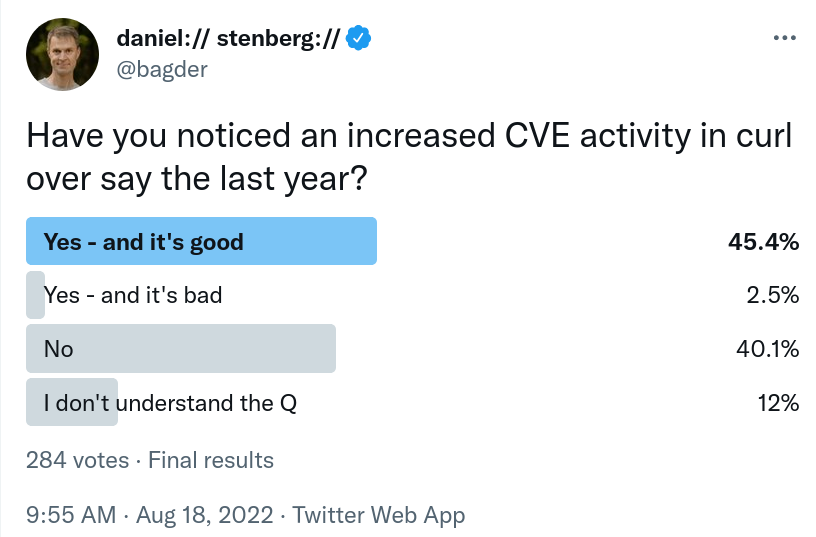
Can you explain the seemingly increased CVE activity in curl over like the last year or so?
(data and stats for this post comes mostly from the curl dashboard)
Pointless but related poll I ran on Twitter
Frequency
In 2022 we have already had 14 CVEs reported so far, and we will announce the 15th when we release curl 7.85.0 at the end of August. Going into September 2022, there have been a total of 18 reported CVEs in the last 12 months.
During the whole of 2021 we had 13 CVEs reported – and already that was a large amount and the most CVEs in a single year since 2016.
There has clearly been an increased CVE issue rate in curl as of late.
Finding and fixing problems is good
While every reported security problem stings my ego and makes my soul hurt since it was yet another mistake I feel I should have found or not made in the first place, the key take away is still that it is good that they are found and reported so that they can be fixed properly. Ideally, we also learn something from each such report and make it less likely that we ever introduce that (kind of) problem again.
That might be the absolutely hardest task around each CVE. To figure out what went wrong, detect a pattern and then lock it down. It’s almost amusing how all bugs look a like a one-off mistake with nothing to learn from…
Ironically, the only way we know people are looking really hard at curl security is when someone reports security problems. If there was no reports at all, can we really be sure that people are scrutinizing the code the way we want?
Who is counting?
Counting the amount of CVEs and giving that a meaning, or even comparing the number between projects, is futile and a bad idea. The number does not say much and comparing two projects this way is impossible and will not tell you anything. Every project is unique.
Just counting CVEs disregards the fact that they all have severity levels. Are they a dozen “severity low” or are they a handful of critical ones? Even if you take severity into account, they might have gotten entirely different severity for virtually the same error, or vice versa.
Further, some projects attract more scrutinize and investigation because they are considered more worthwhile targets. Or perhaps they just pay researchers more for their findings. Projects that don’t get the same amount of focus will naturally get fewer security problems reported for them, which does not necessarily mean that they have fewer problems.
Incentives
The curl bug-bounty really works as an incentive as we do reward security researchers a sizable amount of money for every confirmed security flaw they report. Recently, we have handed over 2,400 USD for each Medium-severity security problem.
In addition to that, finding and getting credited for finding a flaw in a widespread product such as curl is also seen as an extra “feather in the hat” for a lot of security-minded bug hunters.
Over the last year alone, we have paid about 30,000 USD in bug bounty rewards to security researchers, summing up a total of over 40,000 USD since the program started.
Accumulated bug-bounty rewards for curl CVEs over time
Who’s looking?
We have been fortunate to have received the attention of some very skilled, patient and knowledgeable individuals. To find security problems in modern curl, the best bug hunters both know the ins and outs of the curl project source code itself while at the same time they know the protocols curl speaks to a deep level. That’s how you can find mismatches that shouldn’t be there and that could lead to security problems.
The 15 reports we have received in 2022 so far (including the pending one) have been reported by just four individuals. Two of them did one each, the other two did 87% of the reporting. Harry Sintonen alone reported 60% of them.
Hardly any curl security problems are found with source code analyzers or even fuzzers these days. Those low hanging fruits have already been picked.
We care, we act
Our average response time for security reports sent to the curl project has been less than two hours during 2022, for the 56 reports received so far.
We give each report a thorough investigation and we spend a serious amount of time and effort to really make sure we understand all the angles of the claim, that it really is a security problem, that we produce the best possible fix for it and not the least: that we produce a mighty fine advisory for the issue that explains it to the world with detail and accuracy.
Less than 8% of the submissions we get are eventually confirmed actual security problems.
As a general rule all security problems we confirm, are fixed in the pending next release. The only acceptable exception would be if the report arrives just a day or two from the next release date.
We work hard to make curl more secure and to use more ways of writing secure code and tools to detect mistakes than ever, to minimize the risk for introducing security flaws.
Judge a project on how it acts
Since you cannot judge a project by the number of CVEs that come out of it, what you should instead pay more focus on when you assess the health of a software project is how it acts when security problems are reported.
Most problems are still very old
In the curl project we make a habit of tracing back and figuring out exactly in which release each and every security problem was once introduced. Often the exact commit. (Usually that commit was authored by me, but let’s not linger on that fact now.)
One fun thing this allows us to do, is to see how long time the offending code has been present in releases. The period during which all the eyeballs that presumably glanced over the code missed the fact that there was a security bug in there.
On average, curl security problems have been present an extended period of time before there are found and reported.
On average for all CVEs: 2,867 days
The average time bugs were present for CVEs reported during the last 12 months is a whopping 3,245 days. This is very close to nine years.
How many people read the code in those nine years?
The people who find security bugs do not know nor do they care about the age of a source code line when they dig up the problems. The fact that the bugs are usually old could be an indication that we introduced more security bugs in the past than we do now.
Finding vs introducing
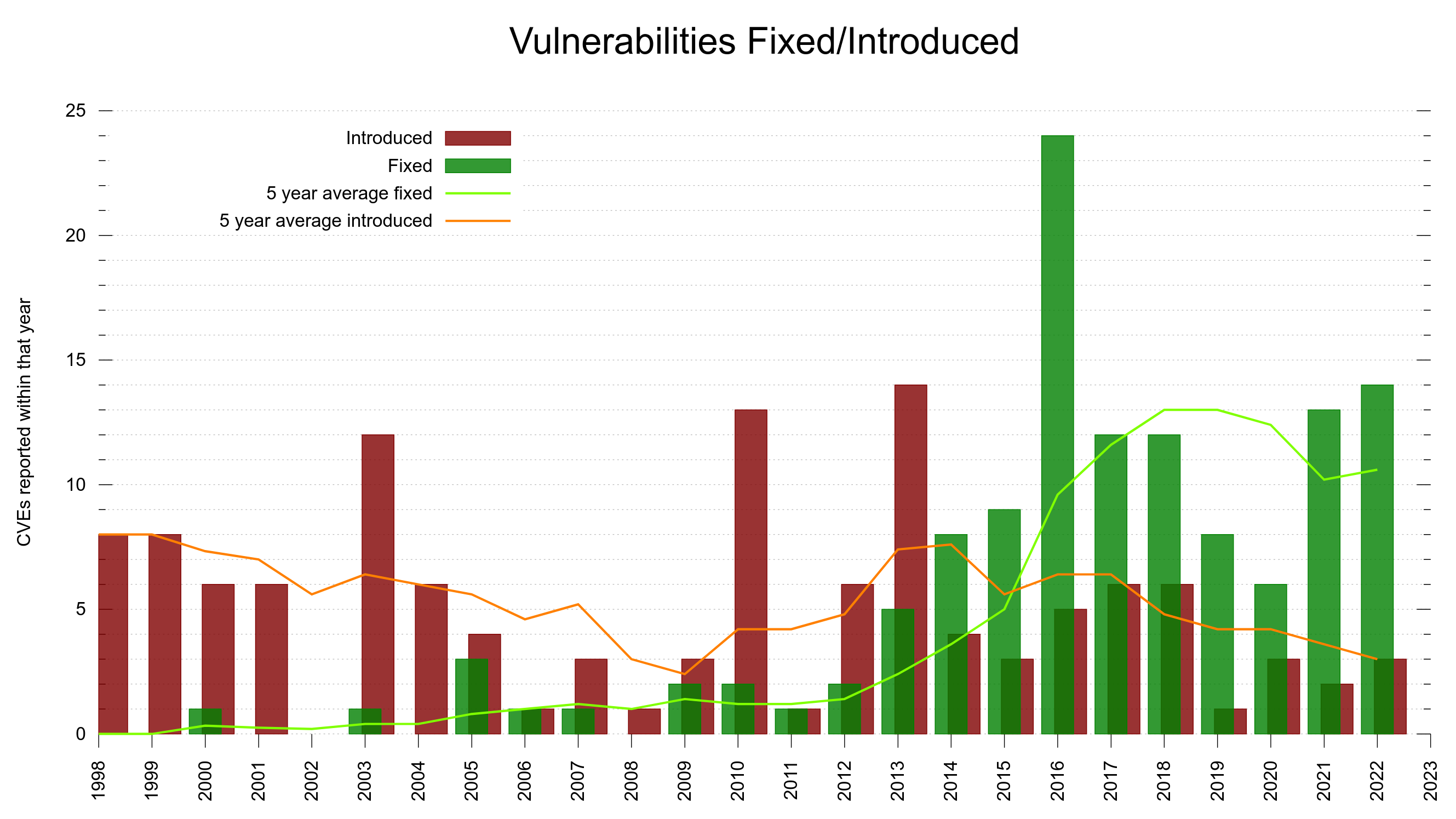
Enough about finding issues for a moment. Let’s talk about introducing security problems. I already mentioned we track down exactly when security flaws were introduced. We know.
All CVEs in curl, green are found, red are introduced
With this, we can look at the trend and see if we are improving over time.
The project has existed for almost 25 years, which means that if we introduce problems spread out evenly over time, we would have added 4% of them every year. About 5 CVE problems are introduced per year on average. So, being above or below 5 introduced makes us above or below an average year.
Bugs are probably not introduced as a product of time, but more as a product of number of lines of code or perhaps as a ratio of the commits.
75% of the CVE errors were introduced before March 2014 – and yet the code base “only” had 102,000 lines of code at the end of that period. At that time, we had done 61% of the git commits (17684). One CVE per 189 commits.
15% of the security problems were introduced during the last five years and now we are at 148,000 lines of code. Finding needles in a growing haystack. With more code than ever before, we introduce bugs at a lower-than average rate. One CVE per 352 commits. This probably is also related to the ever-growing number of tests and CI jobs that help us detect more problems before we merge them.
Number of lines of code. Includes comments, excludes blank lines
The commit rate has remained between 1,100 and 1,700 commits per year since 2007 with ups and downs but no obvious growing or declining trend.
Number of commits per year
Harry Sintonen
Harry reported a large amount of the recent curl CVEs as mentioned above, and is credited for a total of 17 reported curl CVEs – no one else is even close to that track record. I figured it is apt to ask him about the curl situation of today, to make sure this is not just me hallucinating things up. What do you think is the reason for the increased number of CVEs in curl in 2022?
Harry replied:
The news of good bounties being paid likely has been attracting more researchers to look at curl.
I did put considerable effort in doing code reviews. I’m sure some other people put in a lot of effort too.
When a certain before unseen type of vulnerability is found, it will attract people to look at the code as a whole for similar or surrounding issues. This quite often results in new, similar CVEs bundling up. This is kind of a clustering effect.
It’s worth mentioning, I think, that even though there has been more CVEs found recently, they have been found (well most of them at least) as part of the bug bounty program and get handled in a controlled manner. While it would be even better to have no vulnerabilities at all, finding and handling them in controlled manner is the 2nd best option.
This might be escaping a random observer who just looks at the recent amount of CVEs and goes “oh this is really bad – something must have gone wrong!”. Some of the issues are rather old and were only found now due to the increased attention.
Conclusion
We introduce CVE problems at a slower rate now than we did in the past even though we have gotten problems reported at a higher than usual frequency recently.
The way I see it, we are good. I suppose the future will tell if I am right.
Disclaimer: I work for wolfSSL but I don’t speak for wolfSSL. I state my own opinions and I try to be as honest and transparent as possible. As always.
QUIC API
Back in the summer of 2020 I blogged about QUIC support coming in wolfSSL. That work never actually took off, primarily I believe because the team kept busy with other projects and tasks that had more customer focus and interest and yeah, there was not really any noticeable customer demand for QUIC with wolfSSL.
Time passed.
On July 21 2022, Stefan Eissing submitted his work on introducing a QUIC API and after reviews and updates, it was merged into the wolfSSL master branch on August 9th.
The QUIC API is planned to appear “for real” in a coming wolfSSL release version. Until then, we can play with what is available in git.
Let me be clear here: the good people at wolfSSL has not decided to write a full QUIC implementation, because that would be insane when so many good alternatives are already being worked on. This is just a set of new functions to allow wolfSSL to be used as TLS component when a QUIC stack is created.
Having QUIC support in wolfSSL is just one (but important) step along the way as it makes it possible to use wolfSSL to build a QUIC implementation but there are some more steps needed to turn this baby into full HTTP/3.
ngtcp2
Luckily, ngtcp2 exists and it is an established QUIC implementation that was written to be TLS agnostic from the beginning. This “only” needs adaptions provided to make sure it can be built and used with wolSSL as the TLS provider.
Stefan brought wolfSSL support to ngtcp2 in this PR. Merged on August 13th.
nghttp3
nghttp3 is the HTTP/3 library that uses ngtcp2 for QUIC, so once ngtcp2 supports wolfSSL we can use nghttp3 to do HTTP/3.
curl
curl can (as one of the available options) get built to use nghttp3 for HTTP/3, and if we just make sure we use an underlying ngtcp2 built to use a wolfSSL version with QUIC support, we can now do proper curl HTTP/3 transfers powered by wolfSSL.
Stefan made it possible to build curl with the wolfSSL+ngtcp2 combo in this PR. Merged on August 15th.
Available HTTP/3 components
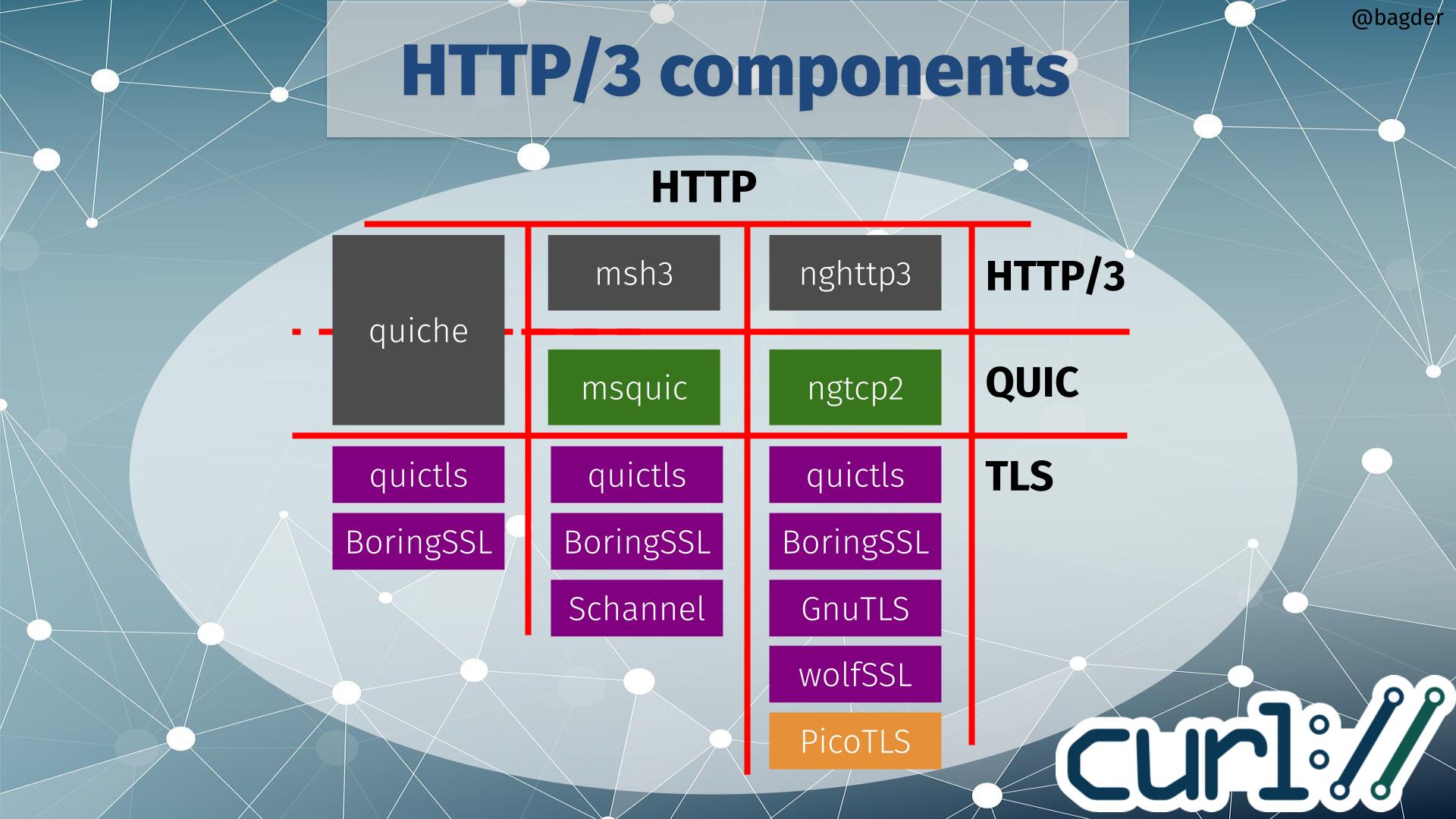
With this new ecosystem addition, the chart of HTTP/3 components for curl did not get any easier to parse!
If you start by selecting which HTTP/3 library (or maybe I should call it HTTP/3 vertical) to use when building, there are three available options to go with: quiche, msh3 or nghttp3. Depending on that choice, the QUIC library is given. quiche does QUIC as well, but the two other HTTP/3 libraries use dedicated QUIC libraries (msquic and ngtcp2 respectively).
Depending on which QUIC solution you use, there is a limited selection of TLS libraries to use. The image above shows TLS libraries that curl also supports for other protocols, meaning that if you pick one of those you can still use that curl build to for example do HTTPS for HTTP version 1 or 2.
TLS options
If you instead rather pick TLS library first, only quictls and BoringSSL are supported by all QUIC libraries (quictls is an OpenSSL fork with a BoringSSL-like QUIC API patched in). If you rather build curl to use Schannel (that’s the native Windows TLS API), GnuTLS or wolfSSL you have also indirectly chosen which QUIC and HTTP/3 libraries to use.
Picotls
ngtcp2 supports Picotls shown in orange in the image above because that is a TLS 1.3-only library that is not supported for other TLS operations within curl. If you build curl and opt to go with a ngtcp2 build using Picotls for QUIC, you would need to have use an second TLS library for other TLS-using protocols. This is possible, but is rarely what users prefer.
No OpenSSL option
It should probably be especially highlighted that the plain vanilla OpenSSL is not an available option. Primarily because they decided that the already created API was not good enough for them so they will instead work on implementing their own QUIC library to be released at some point in the future. That also implies that if we want to build curl to do HTTP/3 with OpenSSL in the future, we probably need to add support for a forth QUIC library – and someone would also have to write a HTTP/3 library to use OpenSSL for QUIC.
Why wolfSSL adding QUIC is good for HTTP/3
People in general want to build applications and infrastructure using released, official and supported libraries and the sad truth is that there is a clear shortage in such TLS libraries with QUIC support.
In your typical current Linux distribution, quictls and BoringSSL are usually not viable options. The first since it is an OpenSSL fork not many even ship as a package and the second because it is done by Google for Google and they don’t do releases and generally care little for outside-Google users.
For the situations where those two TLS options are out of the game, the image above shows you the grim reality: your HTTP/3 options are limited. On Windows you can go with msh3 since it can use Schannel there, but on non-Windows you can only use ngtcp2/nghttp3 and before this wolfSSL support the only TLS option was GnuTLS.
For many embedded solutions, or even FIPS requirements, wolfSSL is now the only viable option for doing HTTP/3 with curl.
curl, along with every other Internet tool with aspirations, supports proxies. A proxy is a (usually known) middle-man in a network operation; instead of going directly to the remote end server, the client goes via a proxy.
curl has supported proxies since the day it was born.
Which proxy?
Applications that do Internet transfers often would like to automatically be able to do their transfers even when users are trapped in an environment where they use a proxy. To figure out the proxy situation automatically.
Many proxy users have to use their proxy to do Internet transfers.
A library to detect which proxy?
The challenge to figure out the proxy situation is of course even bigger if your applications can run on multiple platforms. macOS, Windows and Linux have completely different ways of storing and accessing the necessary information.
libproxy
libproxy is a well-known library used for exactly this purpose. The first feature request to add support for this into libcurl that I can find, was filed in December 2007 (I also blogged about it) and it has been popping up occasionally over the years since then.
In August 2016, David Woodhouse submitted a patch for curl that implemented support for libproxy (the PR version is here). I was skeptical then primarily because of the lack of tests and docs in libproxy (and that the project seemed totally unresponsive to bug reports). Subsequently we did not merge that pull request.
Almost six years later, in June 2022, Jan Brummer revived David’s previous work and submitted a fresh pull request to add libproxy support in curl. Another try.
The proxy library dream is clearly still very much alive. There are also a fair amount of applications and systems today that are built to use libproxy to figure out the proxy and then tell curl about it.
What is unfortunately also still present, is the unsatisfying state of libproxy. It seems to have changed and improved somewhat since the last time I looked at it (6 years ago), but there several warning signs remaining that make me hesitate.
This is not a dependency I want to encourage curl users to lean and depend upon.
I greatly appreciate the idea of a libproxy but I do not like the (state of the) implementation.
My responsibility
Or rather, the responsibility I think we have as curl maintainers. We ship a product that is used and depended upon by an almost unfathomable amount of users, tools, products and devices.
Our job is to help guide our users so that the entire product, including third party dependencies, become an as safe and secure solution as possible. I am not saying that we can take full responsibility for the security of code outside of our own domain, but I think we should recognize that what we condone and recommend will be used. People read our support for library X as some level of approval.
We should only add support for third party libraries that meets a certain quality threshold. This threshold or bar maybe is (unfortunately) not written down anywhere but is still mostly a soft “gut feeling” based on human reviews of the situation.
What to do
I think the sensible thing to do first, before trying to get curl to use libproxy, is to make sure that there is a library for proxies that we can and want to lean on. That library can be the libproxy of today but it could also be something else.
Some areas in need of attention in libproxy that I recently also highlighted in the curl PR, that would take it closer to meeting the requirements we can ask of a dependency:
Improve the project with docs. We cannot safely rely on a library and its APIs if we don’t know exactly what to expect.
There needs to be at least basic tests that verify its functionality. We cannot fix and improve the library safely if we cannot check that it still works and behaves as expected. Tests is the only reliable way to make sure of this.
Add CI jobs that build the project and run those tests. To help the project better verify that things don’t break along the way.
Consider improving the API. To be fair, it is extremely simple now, but it’s also so simple that that it becomes ineffective and quirky in some use cases.
Allow for external URL parser and URL retrieving etc to avoid blocking, double-parsing and to reuse caches properly. It would be ridiculous for curl to use a library that has its own separate (semi-broken) HTTP transfer and its own (synchronous) name resolving process.
A solid proxy library?
The current libproxy is not even a lot of code, it could perhaps make more sense to just plainly write a new library based on how you would want a library like this to work – and use all the knowledge, magic and experience from libproxy to get the technical parts done correctly. A libproxy-next-generation.
But
This would require that someone really wanted to see this development take place and happen. It would take someone to take lead in the project and push for changes (like perhaps the 5 bullets I listed above). The best would be if someone who would like to use this kind of setup could sponsor a developer half/full time for a while to get a good head start on this.
Based on history, seeing we have had this known use case and this library around for well over a decade and this is the best we have accomplished so far, I am not optimistic that we can turn this ship around. Until then, we simply cannot allow curl to use this dependency.
The InterPlanetary File System (IPFS) is according to the Wikipedia description: “a protocol, hypermedia and file sharing peer-to-peer network for storing and sharing data in a distributed file system.”. It works a little like bittorrent and you typically access content on it using a very long hash in an ipfs:// URL. Like this:
I guess partly because IPFS is a rather new protocol not widely supported by many clients yet, people came up with the concept of IPFS “gateways”. (Others might have called it a proxy, because that is what it really is.)
This gateway is an HTTP server that runs on a machine that also knows how to speak and access IPFS. By sending the right HTTP request to the gateway, that includes the IPFS hash you are interested in, the gateway can respond with the contents from the IPFS hash.
This way, you just need an ordinary HTTP client to access IPFS. I think it is pretty clever. But as always, the devil is in the details.
Rewrite ipfs:// into https://
The quest for IPFS aficionados have seemingly become to add support for IPFS using this gateway approach to multiple widely used applications that know how to speak HTTP(S). Just rewrite the URL internally from IPFS to HTTPS.
The IPFS “URL rewrite” is done in such so that the example IPFS URL is converted into “https://$gateway/$hash”. The transfer is done by the client as if it was a plain old HTTPS transfer.
What if the gateway is not local?
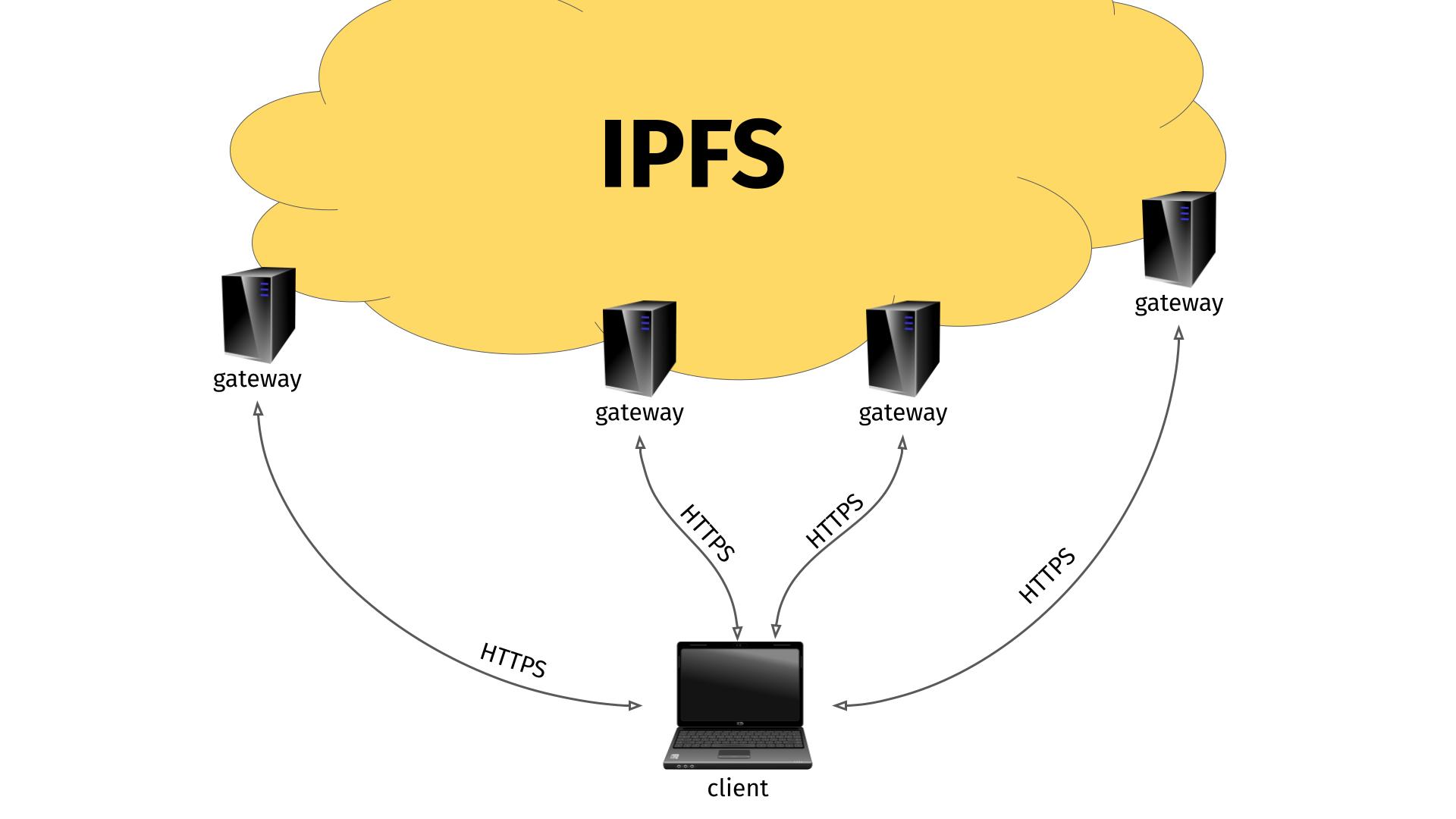
This approach has its biggest benefit of course when you can actually use a remote IPFS gateway. I presume most random ordinary users who want to access IPFS does not actually want to download, install and run an IPFS gateway on their machine to use this new power. They might very well appreciate the idea and convenience of accessing a remote IPFS gateway.
Remote IPFS gateways illustration
After all, the gateways are using HTTPS so at least the transfers are secure, right?
Leading people behind IPFS are even running public IPFS gateways for anyone to use. Both dweb.link and ipfs.io have been mentioned and suggested for default use. Possibly they are the same physical host as they appear to have the same IP addresses (owned by Protocol Labs, one of the big proponents behind IPFS).
In an attempt to make this even easier for users, ffmpeg is made to use a built-in default gateway if none is set by the user.
I would expect very few users to actually have an IPFS gateway set. And even fewer to actually specify a local one.
So, when users want to watch a video using ffmpeg and an ipfs:// URL what happens?
The gateway sees it all
The remote gateway, that is administered by someone, somewhere, gets to see the full incoming request, and all traffic (video, whatever) that is sent back to the client (ffmpeg in this example) goes via the gateway. Sure, the client accesses the gateway via HTTPS so nobody can tamper with the traffic along the way, but the gateway is in full control and can inspect and tamper with the data as much as it likes. And there is no way for the client to know or detect if it is happening.
I am not involved in ffmpeg, nor do I have any insights into how the discussions evolved and were done around this subject, but for curl I have put my foot down and said that we must not blindly use and trust any default remote gateway like this. I believe it is our responsibility to not lure users into this traffic-monitoring setup.
Make sure you trust the gateway you use.
The curl way
curl will probably output an error message if there was no gateway set when an ipfs:// URL is used, and inform the user that it needs a gateway set to function and probably also show a URL for a page that contains more information about what this means and how to specify a gateway.
Bouncing gateways!
During the work of making the IPFS support for curl (which I review and comment on, not written or authored myself) I have also learned that some of the IPFS gateways even do regular HTTP 30x redirects to bounce over the client to another gateway.
Meaning: not only do you use and rely a total rando’s gateway on the Internet for your traffic. That gateway might even, on its own discretion, redirect you over to another host. Possibly run somewhere else, monitored by a separate team.
I have insisted, in the PR for ipfs support to curl, that the IPFS URL handling code should not automatically follow such gateway redirects, as I believe that adds even more risk to the user so if a user wants to allow this operation, it should be opt-in.
Imagine rising use of this
I would imagine that the ones hosting a popular default gateway either becomes overloaded and slow, or they need to scale up. If they scale up, they risk to leak traffic even wider. Scaling up also makes the operation more expensive, leading to incentives to make money somehow to finance it. Will the cookie car in the form of a massive data trove perhaps then be used/sold?
Users of these gateways get no promises, no rights, no contracts.
Other IPFS privacy concerns
Brave, the browser, has actual native IPFS support (not using any gateway) and they have an informative page called How does IPFS Impact my Privacy?
Final verdict
I am not dissing the idea nor implementation of IPFS itself. I think using HTTP gateways to access IPFS is a good idea in general as it makes the network more accessible. It is just a fragile solution that easily misleads users to do things they maybe shouldn’t. So maybe a little too accessible?
I poked the ffmpeg project over Twitter, there was immediate reaction and there is already a proposed patch for ffmpeg that removes the use of a default IPFS gateway. “it’s a security risk”
The .netrc file is used to hold user names and passwords for specific host names and allows tools to login to those systems automatically without having to prompt the user for the credentials while avoiding having to use them in command lines. The .netrc file is typically set without group or world read permissions (0600) to reduce the risk of leaking those secrets.
History
Allegedly, the .netrc file format was invented and first used for Berknet in 1978 and it has been used continuously since by various tools and libraries. Incidentally, this was the same year Intel introduced the 8086 and DNS didn’t exist yet.
.netrc has been supported by curl (since the summer of 1998), wget, fetchmail, and a busload of other tools and networking libraries for decades. In many cases it is the only cross-tool way to provide credentials to remote systems.
The .netrc file use is perhaps most widely known from the “standard” ftp command line client. I remember learning to use this file when I wanted to do automatic transfers without any user interaction using the ftp command line tool on unix systems in the early 1990s.
Example
A .netrc file where we tell the tool to use the user name daniel and password 123456 for the host user.example.com is as simple as this:
machine user.example.com
login daniel
password 123456
Those different instructions can also be written on the same single line, they don’t need to be separated by newlines like above.
Specification
There is no and has never been any standard or specification for the file format. If you google .netrc now, the best you get is a few different takes on man pages describing the format in a high level. In general this covers our needs and for most simple use cases this is good enough, but as always the devil is in the details.
The lack of detailed descriptions on how long lines or fields to accept, how to handle special character or white space for example have left the implementers of the different code basis to decide by themselves how to handle those things.
The horse left the barn
Since numerous different implementations have been done and have been running in systems for several decades already, it might be too late to do a spec now.
This is also why you will find man pages out there with conflicting information about the support for space in passwords for example. Some of them explicitly say that the file format does not support space in passwords.
Passwords
Most fields in the .netrc work fine even when not supporting special characters or white space, but in this age we have hopefully learned that we need long and complicated passwords and thus having “special characters” in there is now probably more common than back in the 1970s.
Writing a .netrc file with for example a double-quote or a white space in the password unfortunately breaks tools and is not portable.
I have found at least three different ways existing tools do the parsing, and they are all incompatible with each other.
curl parser (before 7.84.0)
curl did not support spaces in passwords, period. The parser split all fields at the following space or newline and accepted whatever is in between. curl thus supported any characters you want, except spaceand newlines . It also did not “unquote” anything so if you wanted to provide a password like ""llo (with two leading double-quotes), you would use those five bytes verbatim in the file.
wget parser
This parser allows a space in the password if you provide it quoted within double-quotes and use a backslash in front of the space. To specify the same ""llo password mentioned above, you would have to write it as "\"\"llo".
fetchmail parser
Also supports spaces in passwords. Here the double-quote is a quote character itself so in order to provide a verbatim double-quote, it needs to be doubled. To specify the same ""llo password mentioned above, you would have to write it as """"llo – that is with four double-quotes.
What is the best way?
Changing any of these parsers in an effort to unify risk breaking existing use cases and scripts out in the wild with outraged users as a result. But a change could also generate a few happy users too who then could better share the same .netrc file between tools.
In my personal view, the wget parser approach seems to be the most user friendly one that works perhaps most closely to what I as a user would expect. So that’s how I went ahead and made curl work.
What to do
Users will of course be stuck with ancient versions for a long time and this incompatibility situation will remain for the foreseeable future. I can think of a few work-arounds users can do to cope:
Avoid space, tabs, newline and various quotes in passwords
Use separate .netrc files for separate tools
Provide passwords using other means than .netrc – with curl you can for example explore using –config instead
Future curl supports quoting
We are changing the curl parser somewhat in the name of compatibility with other tools (read wget) and curl will allow quoted strings in the way wget does it, starting in curl 7.84.0. While this change risks breaking a few command lines out there (for users who have leading double-quotes in their existing passwords), I think the change is worth doing in the name of compatibility and the new ability to use spaces in passwords.
A little polish after twenty-four years of not supporting spaces in user names or passwords.
The first mention of QUIC on this blog was back when I posted about the HTTP workshop of July 2015. Today, this blog is readable over the protocol QUIC subsequently would turn into. (Strictly speaking, it turned into QUIC + HTTP/3 but let’s not be too literal now.)
The other day Fastly announced that all their customers now can enable HTTP/3, and since this blog and the curl site are graciously running on the Fastly network I went ahead and enabled the protocol.
Within minutes and with almost no mistakes, I could load content over HTTP/3 using curl or browsers. Wooosh.
The name HTTP/3 wasn’t adopted until late 2018, and the RFC has still not been published yet. Some of the specifications for QUIC have however.