I’m about to take an extended vacation for the rest of the year and into the beginning of the next, so I decided I’d sum up the year from a curl angle already now, a few weeks early. (So some numbers will grow a bit more after this post.)
2017
So what did we do this year in the project, how did curl change?
The first curl release of the year was version 7.53.0 and the last one was 7.57.0. In the separate blog posts on 7.55.0, 7.56.0 and 7.57.0 you’ll note that we kept up adding new goodies and useful features. We produced a total of 9 releases containing 683 bug fixes. We announced twelve security problems. (Down from 24 last year.)
At least 125 different authors wrote code that was merged into curl this year, in the 1500 commits that were made. We never had this many different authors during a single year before in the project’s entire life time! (The 114 authors during 2016 was the previous all-time high.)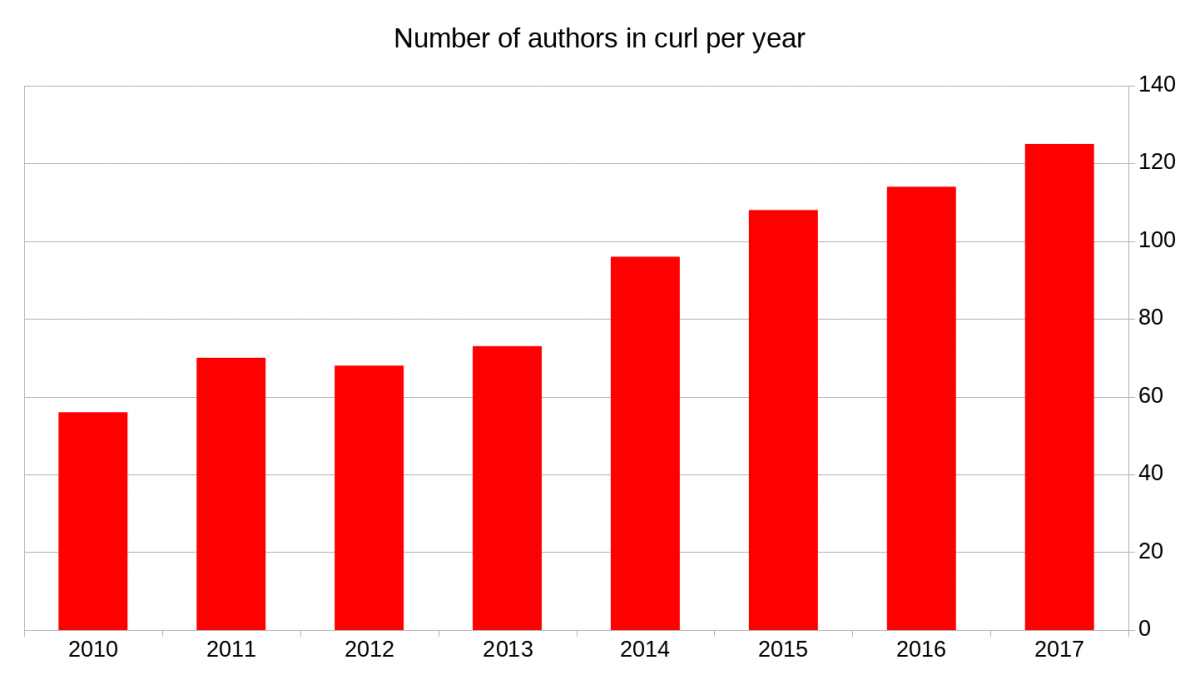
We added more than 160 new names to the THANKS document for their help in improving curl. The total amount of contributors is now over 1660.
This year we truly started to use travis for CI builds and grew from a mere two builds per commit and PR up to nineteen (with additional ones run on appveyor and elsewhere). The current build set is a very good verification that that most things still compile and work after a PR is merged. (see also the testing curl article).
Mozilla announced that they too will use colon-slash-slash in their logo. Of course we all know who had it that in their logo first… =)
In March 2017, we had our first ever curl get-together as we arranged curl up 2017 a weekend in Nuremberg, Germany. It was very inspiring and meeting parts of the team in real life was truly a blast. This was so good we  intend to do it again: curl up 2018 will happen.
intend to do it again: curl up 2018 will happen.
curl turned 19 years old in March. In May it surpassed 5,000 stars on github.
 Also in May, we moved over the official curl site (and my personal site) to get hosted by Fastly. We were beginning to get problems to handle the bandwidth and load, and in one single step all our worries were graciously taken care of!
Also in May, we moved over the official curl site (and my personal site) to get hosted by Fastly. We were beginning to get problems to handle the bandwidth and load, and in one single step all our worries were graciously taken care of!
We got curl entered into the OSS-fuzz project, and Max Dymond even got a reward from Google for his curl-fuzzing integration work and thanks to that project throwing heaps of junk at libcurl’s APIs we’ve found and fixed many issues.
The source code (for the tool and library only) is now at about 143,378 lines of code. It grew around 7,057 lines during the year. The primary reasons for the code growth were:
- the new libssh-powered SSH backend (not yet released)
- the new mime API (in 7.56.0) and
- the new multi-SSL backend support (also in 7.56.0).
Your maintainer’s view
Oh what an eventful year it has been for me personally.
The first interim meeting for QUIC took place in Japan, and I participated from remote. After all, I’m all set on having curl support QUIC and I’ll keep track of where the protocol is going! I’ve participated in more interim meetings after that, all from remote so far.
I talked curl on the main track at FOSDEM in early February (and about HTTP/2 in the Mozilla devroom). I’ve then followed that up and have also had the pleasure to talk in front of audiences in Stockholm, Budapest, Jönköping and Prague through-out the year.
 I went to London and “represented curl” in the third edition of the HTTP workshop, where HTTP protocol details were discussed and disassembled, and new plans for the future of HTTP were laid out.
I went to London and “represented curl” in the third edition of the HTTP workshop, where HTTP protocol details were discussed and disassembled, and new plans for the future of HTTP were laid out.
In late June I meant to go to San Francisco to a Mozilla “all hands” conference but instead I was denied to board the flight. That event got a crazy amount of attention and I received massive amounts of love from new and old friends. I have not yet tried to enter the US again, but my plan is to try again in 2018…
I wrote and published my h2c tool, meant to help developers convert a set of HTTP headers into a working curl command line.

The single occasion that overshadows all other events and happenings for me this year by far, was without doubt when I was awarded the Polhem Prize and got a gold medal medal from no other than his majesty the King of Sweden himself. For all my work and years spent on curl no less.
Not really curl related, but in November I was also glad to be part of the huge Firefox Quantum release. The biggest Firefox release ever, and one that has been received really well.
I’ve managed to commit over 800 changes to curl through the year, which is 54% of the totals and more commits than I’ve done in curl during a single year since 2005 (in which I did 855 commits). I explain this increase mostly on inspiration from curl up and the prize, but I think it also happened thanks to excellent feedback and motivation brought by my fellow curl hackers.
We’re running towards the end of 2017 with me being the individual who did most commits in curl every single month for the last 28 months.
2018?
More things to come!