bus factor: the minimum number of team members that have to suddenly disappear from a project before the project stalls due to lack of knowledgeable or competent personnel.

Projects should strive to survive
If a project is worth using and deploying today and if it is a project worth sending patches to right now, it is also a project that should position itself to survive a loss of key individuals. However unlikely or unfortunate such an event would be.
Tools to calculate bus factor
All the available tools that determine the bus factor for a given project only run on code and check for commits, code churn or check how many files each person has done a significant share of changes in etc.
This number is really impossible to figure out without tools and tools really cannot take “general knowledge” into account, or “this person answers a lot of email on the list”, or this person has 48k in reputation on stack overflow already for responding to questions about the project.
The bus factor as evaluated by a tool pretty much has to be about amount of code, size of code or number of code changes, which may or may not be a good indicator of who knows what about the code. Those who author and commit changes probably have a good idea but a real problem is that you can’t reverse that view and say that just because you didn’t commit or change something, you don’t know. Do you know more about the code if you did many commits? Do you know more about the code if you changed more lines of code?
We can’t prove or assume lack of knowledge or interest by an absence of commits, edits or changes. And yet we can’t calculate bus factor if there’s no tool or way to calculate it.
A look at curl
curl is  soon 20 years old and boasts 22k something commits. I’m the author of about 57% of them, and the second-most committer (who’s not involved anymore) has about 12%. That makes two committers having done 15.3k commits out of the 22k. If we for simplicity calculate bus factor based on commit numbers, we’d need 8580 commits from others and I would stop completely, to reach bus factor >2 (when the 2 top committers have less than 50% of the commits), which at the current commit rate equals in about 5 years. And it would take about 3 years to just push the factor above 1. So even when new people joins the project, they have a really hard time to significantly change the bus factor…
soon 20 years old and boasts 22k something commits. I’m the author of about 57% of them, and the second-most committer (who’s not involved anymore) has about 12%. That makes two committers having done 15.3k commits out of the 22k. If we for simplicity calculate bus factor based on commit numbers, we’d need 8580 commits from others and I would stop completely, to reach bus factor >2 (when the 2 top committers have less than 50% of the commits), which at the current commit rate equals in about 5 years. And it would take about 3 years to just push the factor above 1. So even when new people joins the project, they have a really hard time to significantly change the bus factor…
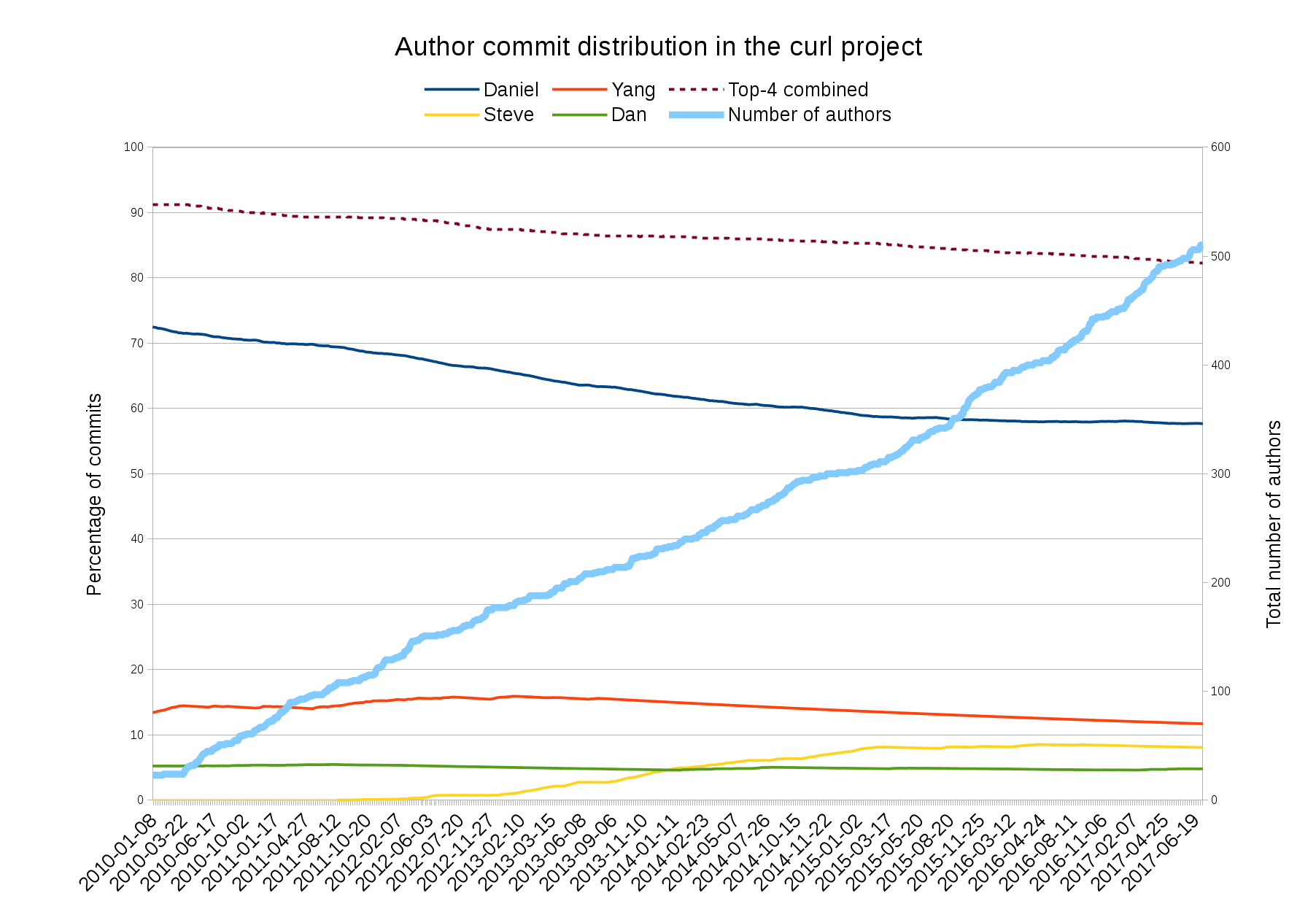
The image above shows the relative share of commits done in the curl project’s git source code repository (as a share of the total amount) by the top 4 commiters from January 1 2010 to July 5 2017 (click for higher resolution). The top dotted line shows the combined share of all four (at 82% right now) and the dark blue line is my share. You can see how my commit share has shrunk from 72% down to 57% over these last 7.5 years. If this trend holds, I’ll have less than 50% of the total commits done in curl in 3-4 years.
At the same time, the thicker light blue line that climbs up into the right is the total number of authors in the git repository, which recently surpassed 500 as you can see. (The line uses the right Y-axes)
We’re approaching 1600 individually named contributors thanked in the project and every release we do (we ship one every 8 weeks) has around 40 contributors, out of which typically around half are newcomers. The long tail is very long and the amount of drive-by just-once contributors is high. Also note how the number 1600 is way higher than the 500 something that has authored commits. Lots of people contribute in other ways.
When we ask our users “why don’t you contribute (more) to the project?” (which we do annually) what do they answer? They say its because 1) everything works, 2) I don’t have time 3) things get fixed fast enough 4) I don’t know the programming language 5) I don’t have the energy.
First as the 6th answer (at 5% 2017) comes “other” where some people actually say they wouldn’t know where to start and so on.
All of this taken together: there are no visible signs of us suffering from having a low bus factor. Lots of signs that people can do things when they want to if I don’t do it. Lots of signs that the code and concepts are understood.
Lots of signs that a low bus factor is not a big problem here. Or perhaps rather that the bus factor isn’t really as low as any tool would calculate it.
What if I…
Do I know who would pick up the project and move on if I die today? No. We’re a 100% volunteer-driven project. We create one of the world’s most widely used software components (easily more than three billion instances and counting) but we don’t know who’ll be around tomorrow to work on it. I can’t know because that’s not how the project works.
Given the extremely wide use of our stuff, given the huge contributor base, given the vast amounts of documentation and tests I think it’ll work out.
Just because you have a large bus factor doesn’t necessarily make the project a better place to ask questions. We’ve seen projects in the past where N persons involved are all from the same company and when that company removes its support for that project those people all go away. High bus factor, no people to ask.
Finally, let me just add that I would of course love to have many more committers and contributors in the curl project, and I think we would be an even better project if we did. But that’s a separate issue.








 (Season three, episode two)
(Season three, episode two)