I write and prefer code that fits within 80 columns in curl and other projects – and there are reasons for it. I’m a little bored by the people who respond and say that they have 400 inch monitors already and they can use them.
I too have multiple large high resolution screens – but writing wide code is still a bad idea! So I decided I’ll write down my reasoning once and for all!
Narrower is easier to read
There’s a reason newspapers and magazines have used narrow texts for centuries and in fact even books aren’t using long lines. For most humans, it is simply easier on the eyes and brain to read texts that aren’t using really long lines. This has been known for a very long time.
Easy-to-read code is easier to follow and understand which leads to fewer bugs and faster debugging.
Side-by-side works better
I never run windows full sized on my screens for anything except watching movies. I frequently have two or more editor windows next to each other, sometimes also with one or two extra terminal/debugger windows next to those. To make this feasible and still have the code readable, it needs to fit “wrapless” in those windows.
Sometimes reading a code diff is easier side-by-side and then too it is important that the two can fit next to each other nicely.
Better diffs
Having code grow vertically rather than horizontally is beneficial for diff, git and other tools that work on changes to files. It reduces the risk of merge conflicts and it makes the merge conflicts that still happen easier to deal with.
It encourages shorter names
A side effect by strictly not allowing anything beyond column 80 is that it becomes really hard to use those terribly annoying 30+ letters java-style names on functions and identifiers. A function name, and especially local ones, should be short. Having long names make them really hard to read and makes it really hard to spot the difference between the other functions with similarly long names where just a sub-word within is changed.
I know especially Java people object to this as they’re trained in a different culture and say that a method name should rather include a lot of details of the functionality “to help the user”, but to me that’s a weak argument as all non-trivial functions will have more functionality than what can be expressed in the name and thus the user needs to know how the function works anyway.
I don’t mean 2-letter names. I mean long enough to make sense but not be ridiculous lengths. Usually within 15 letters or so.
Just a few spaces per indent level
To make this work, and yet allow a few indent levels, the code basically have to have small indent-levels, so I prefer to have it set to two spaces per level.
Many indent levels is wrong anyway
If you do a lot of indent levels it gets really hard to write code that still fits within the 80 column limit. That’s a subtle way to suggest that you should not write functions that needs or uses that many indent levels. It should then rather be split out into multiple smaller functions, where then each function won’t need that many levels!
Why exactly 80?
Once upon the time it was of course because terminals had that limit and these days the exact number 80 is not a must. I just happen to think that the limit has worked fine in the past and I haven’t found any compelling reason to change it since.
It also has to be a hard and fixed limit as if we allow a few places to go beyond the limit we end up on a slippery slope and code slowly grow wider over time – I’ve seen it happen in many projects with “soft enforcement” on code column limits.
Enforced by a tool
In curl, we have ‘checksrc’ which will yell errors at any user trying to build code with a too long line present. This is good because then we don’t have to “waste” human efforts to point this out to contributors who offer pull requests. The tool will point out such mistakes with ruthless accuracy.
Every now and then I get questions on how to work with git in a smooth way when developing, bug-fixing or extending curl – or how I do it. After all, I work on open source full time which means I have very frequent interactions with git (and GitHub). Simply put, I work with git all day long. Ordinary days, I issue git commands several hundred times.
I have a very simple approach and way of working with git in curl. This is how it works.
command line
I use git almost exclusively from the command line in a terminal. To help me see which branch I’m working in, I have this little bash helper script.
brname () {
a=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
if [ -n "$a" ]; then
echo " [$a]"
else
echo ""
fi
}
PS1="\u@\h:\w\$(brname)$ "
That gives me a prompt that shows username, host name, the current working directory and the current checked out git branch.
In addition: I use Debian’s bash command line completion for git which is also really handy. It allows me to use tab to complete things like git commands and branch names.
git config
I of course also have my customized ~/.gitconfig file to provide me with some convenient aliases and settings. My most commonly used git aliases are:
st = status --short -uno
ci = commit
ca = commit --amend
caa = commit -a --amend
br = branch
co = checkout
df = diff
lg = log -p --pretty=fuller --abbrev-commit
lgg = log --pretty=fuller --abbrev-commit --stat
up = pull --rebase
latest = log @^{/RELEASE-NOTES:.synced}..
The ‘latest’ one is for listing all changes done to curl since the most recent RELEASE-NOTES “sync”. The others should hopefully be rather self-explanatory.
The config also sets gpgsign = true, enables mailmap and a few other things.
master is clean and working
The main curl development is done in the single curl/curl git repository (primarily hosted on GitHub). We keep the master branch the bleeding edge development tree and we work hard to always keep that working and functional. We do our releases off the master branch when that day comes (every eight weeks) and we provide “daily snapshots” from that branch, put together – yeah – daily.
When merging fixes and features into master, we avoid merge commits and use rebases and fast-forward as much as possible. This makes the branch very easy to browse, understand and work with – as it is 100% linear.
Work on a fix or feature
When I start something new, like work on a bug or trying out someone’s patch or similar, I first create a local branch off master and work in that. That is, I don’t work directly in the master branch. Branches are easy and quick to do and there’s no reason to shy away from having loads of them!
I typically name the branch prefixed with my GitHub user name, so that when I push them to the server it is noticeable who is the creator (and I can use the same branch name locally as I do remotely).
$ git checkout -b bagder/my-new-stuff-or-bugfix
Once I’ve reached somewhere, I commit to the branch. It can then end up one or more commits before I consider myself “done for now” with what I was set out to do.
I try not to leave the tree with any uncommitted changes – like if I take off for the day or even just leave for food or an extended break. This puts the repository in a state that allows me to easily switch over to another branch when I get back – should I feel the need to. Plus, it’s better to commit and explain the change before the break rather than having to recall the details again when coming back.
Never stash
“git stash” is therefore not a command I ever use. I rather create a new branch and commit the (temporary?) work in there as a potential new line of work.
Show it off and get reviews
Yes I am the lead developer of the project but I still maintain the same work flow as everyone else. All changes, except the most minuscule ones, are done as pull requests on GitHub.
When I’m happy with the functionality in my local branch. When the bug seems to be fixed or the feature seems to be doing what it’s supposed to do and the test suite runs fine locally.
I then clean up the commit series with “git rebase -i” (or if it is a single commit I can instead use just “git commit --amend“).
The commit series should be a set of logical changes that are related to this change and not any more than necessary, but kept separate if they are separate. Each commit also gets its own proper commit message. Unrelated changes should be split out into its own separate branch and subsequent separate pull request.
git push origin bagder/my-new-stuff-or-bugfix
Make the push a pull request
On GitHub, I then make the newly pushed branch into a pull request (aka “a PR”). It will then become visible in the list of pull requests on the site for the curl source repository, it will be announced in the #curl IRC channel and everyone who follows the repository on GitHub will be notified accordingly.
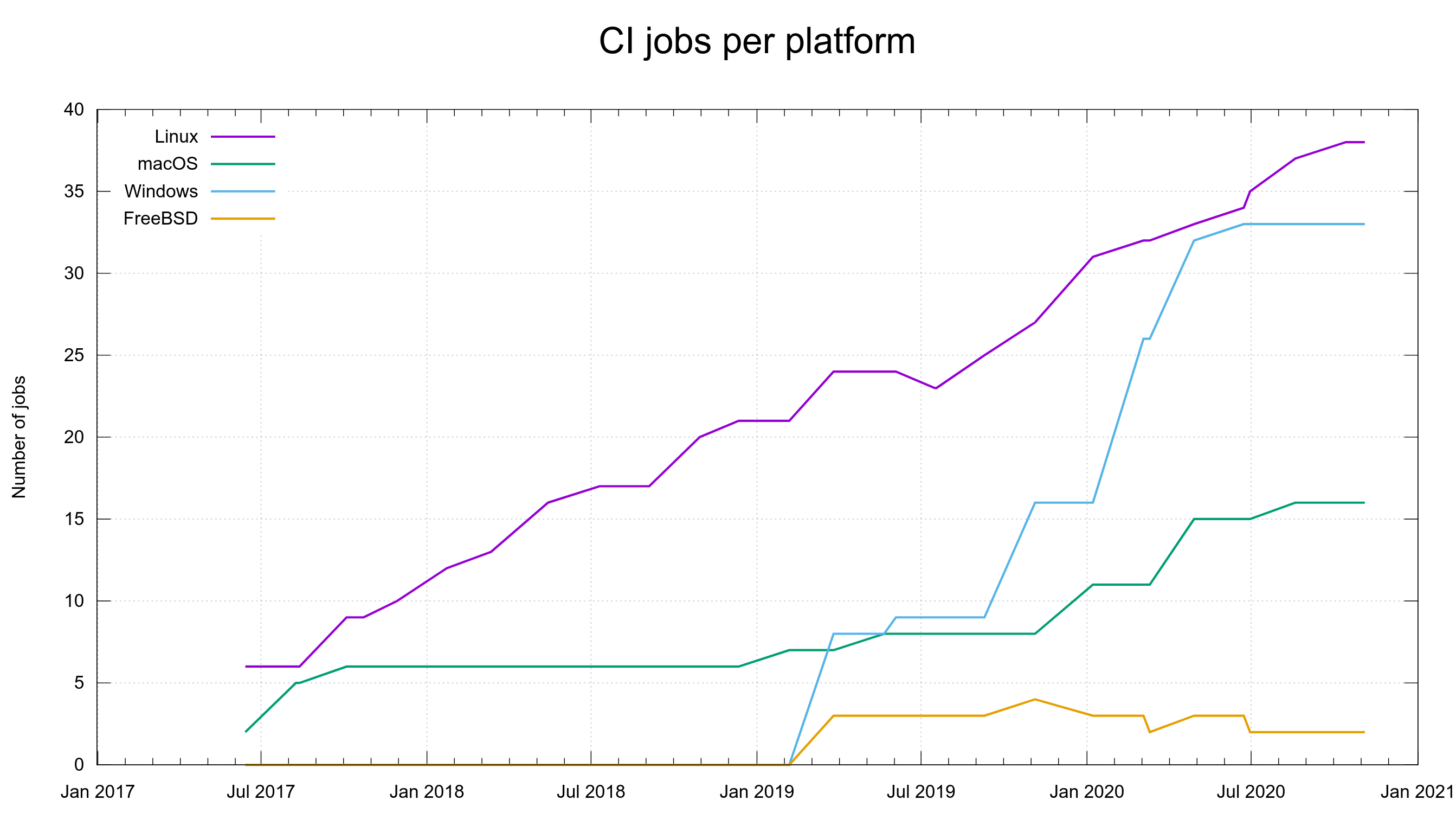
Perhaps most importantly, a pull request kicks of a flood of CI jobs that will build and test the code in numerous different combinations and on several platforms, and the results of those tests will trickle in over the coming hours. When I write this, we have around 90 different CI jobs – per pull request – and something like 8 different code analyzers will scrutinize the change to see if there’s any obvious flaws in there.
CI jobs per platform over time. Graph snapped on November 5, 2020
A branch in the actual curl/curl repo
Most contributors who would work on curl would not do like me and make the branch in the curl repository itself, but would rather do them in their own forked version instead. The difference isn’t that big and I could of course also do it that way.
After push, switch branch
As it will take some time to get the full CI results from the PR to come in (generally a few hours), I switch over to the next branch with work on my agenda. On a normal work-day I can easily move over ten different branches, polish them and submit updates in their respective pull-requests.
I can go back to the master branch again with ‘git checkout master‘ and there I can “git pull” to get everything from upstream – like when my fellow developers have pushed stuff in the mean time.
PR comments or CI alerts
If a reviewer or a CI job find a mistake in one of my PRs, that becomes visible on GitHub and I get to work to handle it. To either fix the bug or discuss with the reviewer what the better approach might be.
Unfortunately, flaky CI jobs is a part of life so very often there ends up one or two red markers in the list of CI jobs that can be ignored as the test failures in them are there due to problems in the setup and not because of actual mistakes in the PR…
To get back to my branch for that PR again, I “git checkout bagder/my-new-stuff-or-bugfix“, and fix the issues.
I normally start out by doing follow-up commits that repair the immediate mistake and push them on the branch:
git push origin bagder/my-new-stuff-or-bugfix
If the number of fixup commits gets large, or if the follow-up fixes aren’t small, I usually end up doing a squash to reduce the number of commits into a smaller, simpler set, and then force-push them to the branch.
The reason for that is to make the patch series easy to review, read and understand. When a commit series has too many commits that changes the previous commits, it becomes hard to review.
Ripe to merge?
When the pull request is ripe for merging (independently of who authored it), I switch over to the master branch again and I merge the pull request’s commits into it. In special cases I cherry-pick specific commits from the branch instead. When all the stuff has been yanked into master properly that should be there, I push the changes to the remote.
Usually, and especially if the pull request wasn’t done by me, I also go over the commit messages and polish them somewhat before I push everything. Commit messages should follow our style and mention not only which PR that it closes but also which issue it fixes and properly give credit to the bug reporter and all the helpers – using the right syntax so that our automatic tools can pick them up correctly!
As already mentioned above, I merge fast-forward or rebased into master. No merge commits.
Never merge with GitHub!
There’s a button GitHub that says “rebase and merge” that could theoretically be used for merging pull requests. I never use that (and if I could, I’d disable/hide it). The reasons are simply:
I don’t feel that I have the proper control of the commit message(s)
I can’t select to squash a subset of the commits, only all or nothing
I often want to cleanup the author parts too before push, which the UI doesn’t allow
The downside with not using the merge button is that the message in the PR says “closed by [hash]” instead of “merged in…” which causes confusion to a fair amount of users who don’t realize it means that it actually means the same thing! I consider this is a (long-standing) GitHub UX flaw.
Post merge
If the branch has nothing to be kept around more, I delete the local branch again with “git branch -d [name]” and I remove it remotely too since it was completely merged there’s no reason to keep the work version left.
At any given point in time, I have some 20-30 different local branches alive using this approach so things I work on over time all live in their own branches and also submissions from various people that haven’t been merged into master yet exist in branches of various maturity levels. Out of those local branches, the number of concurrent pull requests I have in progress can be somewhere between just a few up to ten, twelve something.
RELEASE-NOTES
Not strictly related, but in order to keep interested people informed about what’s happening in the tree, we sync the RELEASE-NOTES file every once in a while. Maybe every 5-7 days or so. It thus becomes a file that explains what we’ve worked on since the previous release and it makes it well-maintained and ready by the time the release day comes.
To sync it, all I need to do is:
$ ./scripts/release-notes.pl
Which makes the script add suggested updates to it, so I then load the file into my editor, remove the separation marker and all entries that don’t actually belong there (as the script adds all commits as entries as it can’t judge the importance).
When it looks okay, I run a cleanup round to make it sort it and remove unused references from the file…
$ ./scripts/release-notes.pl cleanup
Then I make sure to get a fresh list of contributors…
$ ./scripts/contributors.sh
… and paste that updated list into the RELEASE-NOTES. Finally, I get refreshed counters for the numbers at the top of the file by running
$ ./scripts/delta
Then I commit the update (which needs to have the commit message RELEASE-NOTES: synced“) and push it to master. Done!
For a long time, the curl changelog on the web site showed the history of changes in the curl project all the way back to curl 6.0. Released on September 13 1999. Older changes were not displayed.
The reason for this was always basically laziness. The page in its current form was initially created back in 2001 and then I just went back a little in history and filled up with a set of previous releases. Since we don’t have pre-1999 code in our git tree (because of a sloppy CVS import), everything before 1999 is a bit of manual procedure to extract so we left it like that.
Until now.
I decided to once and for all fix this oversight and make sure that we get a complete changelog from the first curl release all the way up until today. The first curl release was called 4.0 and was shipped on March 20, 1998.
Before 6.0 we weren’t doing very careful release notes and they were very chatty. I got the CHANGES file from the curl 6.0 tarball and converted them over to the style of the current changelog.
Notes on the restoration work
The versions noted as “beta” releases in the old changelog are not counted or mentioned as real releases.
For the released versions between 4.0 and 4.9 there are no release dates recorded, so I’ve “estimated” the release dates based on the knowledge that we did them fairly regularly and that they probably were rather spread out over that 200 day time span. They won’t be exact, but close enough.
Complete!
The complete changelog is now showing on the site, and in the process I realized that I have at some point made a mistake and miscounted the total number of curl releases. Off-by one actually. The official count now says that the next release will become the 188th.
As a bonus from this work, the “releaselog” page is now complete and shows details for all curl releases ever. (Also, note that we provide all that info in a CSV file too if you feel like playing with the data.)
There’s a little caveat on the updated vulnerability information there: when we note how far vulnerabilities go, we have made it a habit to sometimes mark the first vulnerable version as “6.0” if the bad code exists in the first ever git imported code – simply because going back further and checking isn’t easy and usually isn’t worth the effort because that old versions are not used anymore.
Therefore, we will not have accurate vulnerability information for versions before 6.0. The vulnerability table will only show versions back to 6.0 for that reason.
Many bug-fixes
With the complete data, we also get complete numbers. Since the birth of curl until version 7.67.0 we have fixed exactly 5,664 bugs shipped in releases, and there were exactly 7,901 days between the 4.0 the 7.67.0 releases.
The Internet Museum translated to Swedish becomes “internetmuseum“. It is a digital, online-only, museum that collects Internet- and Web related historical information, especially focused on the Swedish angle to all of this. It collects stories from people who did the things. The pioneers, the ground breakers, the leaders, the early visionaries. Most of their documentation is done in the form of video interviews.
I was approached and asked to be part of this – as an Internet Pioneer. Me? Internet Pioneer, really?
I’m humbled and honored to be considered and I certainly had a lot of fun doing this interview. To all my friends not (yet) fluent in Swedish: here’s your grand opportunity to practice, because this is done entirely in this language of curl founders and muppet chefs.
Back in the morning of October 18th 2019, two guys showed up as planned at my door and I let them in. One of my guests was a photographer who set up his gear in my living room for the interview, and then me and and guest number two, interviewer Jörgen, sat down and talked for almost an hour straight while being recorded.
The result can be seen here below.
The Science museum was first
This is in fact the second Swedish museum to feature me.
I have already been honored with a display about me, at the Tekniska Museet in Stockholm, the “Science museum” which has an exhibition about past Polhem Prize award winners.
Information displayed about me at the Swedish Science museum in Stockholm. I have a private copy of the cardboard posters.
It’s just another meaningless number, but today there are 3,000 forks done of the curl GitHub repository.
This pops up just a little over three years since we reached our first 1,000 forks. Also, 10,000 stars no too long ago.
Why fork?
A typical reason why people fork a project on GitHub, is so that they can make a change in their own copy of the source code and then suggest that change to the project in the form of a pull-request.
The curl project has almost 700 individual commit authors, which makes at least 2,300 forks done who still haven’t had their pull-requests accepted! Of course those are 700 contributors who actually managed to work all the way through to inclusion. We can imagine that there is a huge number of people who only ever thought about doing a change, some who only ever just started to do it, many who ditched the idea before it was completed, some who didn’t actually manage to implement it properly, some who got their idea and suggestion shut down by the project and of course, lots of people still have their half-finished change sitting there waiting for inspiration.
Then there are people who just never had the intention of sending any change back. Maybe they just wanted to tinker with the code and have fun. Some want to do private changes they don’t want to offer or perhaps they already know the upstream project won’t accept.
We just can’t tell.
Many?
Is 3,000 forks a lot or a little? Both. It is certainly more forks than we’ve ever had before in this project. But compared to some of the most popular projects on GitHub, even comparing to some other C projects (on GitHub the most popular projects are never written in C) our numbers are dwarfed by the really popular ones. You can probably guess which ones they are.
In the end, this number is next to totally meaningless as it doesn’t say anything about the project nor about what contributions we get or will get in the future. It tells us we have (or had) the attention of a lot of users and that’s about it.
I will continue to try to make sure we’re worth the attention, both now and going forward!
As some of you already found out, I’ve tried live-streaming curl development recently. If you want to catch previous and upcoming episodes subscribe on my twitch page.
Why stream
For the fun of it. I work alone from home most of the time and this is a way for me to interact with others.
To show what’s going on in curl right now. By streaming some of my development I also show what kind of work that’s being done, showing that a lot of development and work are being put into curl and I can share my thoughts and plans with a wider community. Perhaps this will help getting more people to help out or to tickle their imagination.
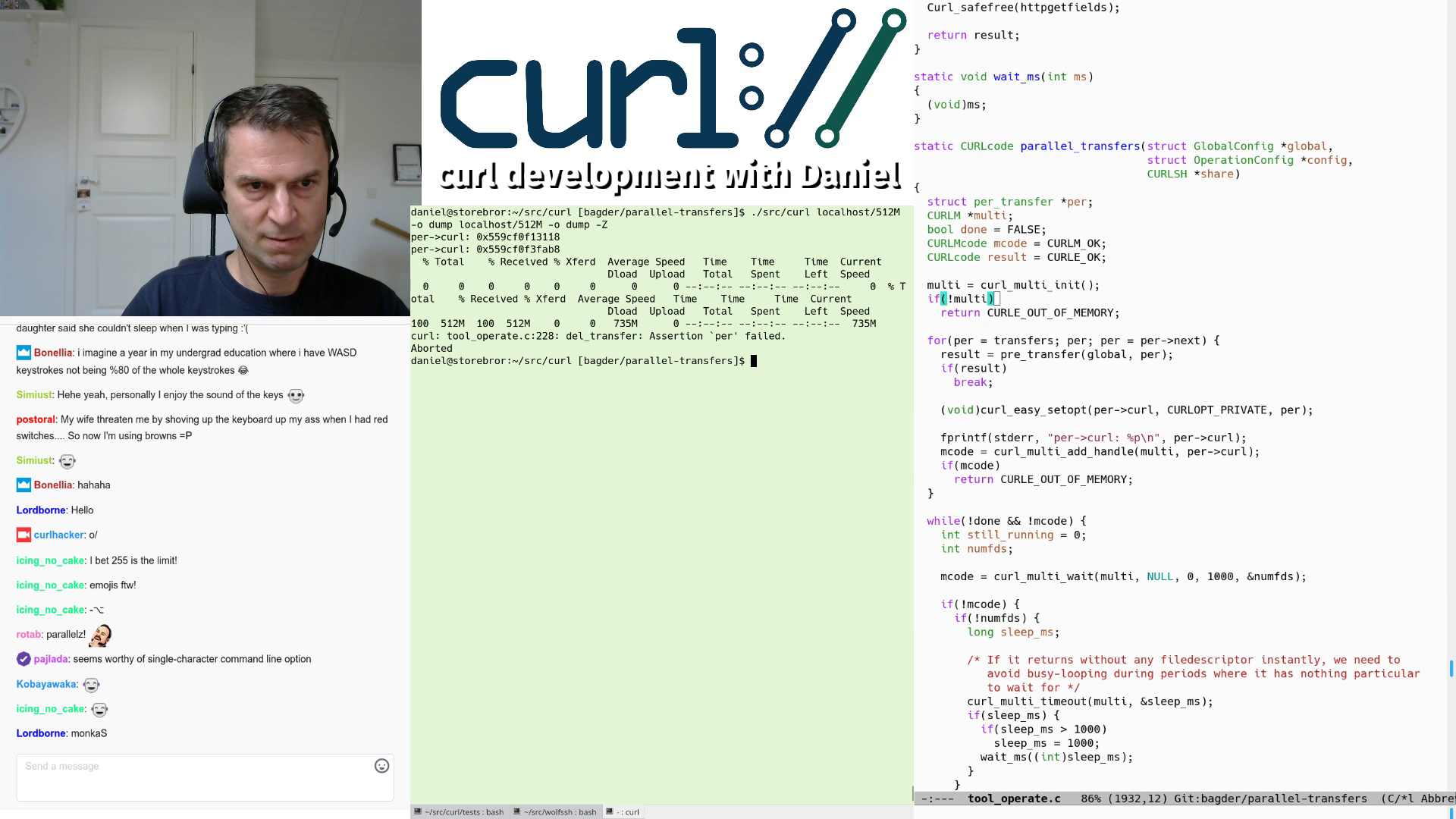
A screenshot from live stream #11 when parallel transfers with curl was shown off for the first time ever!
For the feedback and interaction. It is immediately notable that one of the biggest reasons I enjoy live-streaming is the chat with the audience and the instant feedback on mistakes I do or thoughts and plans I express. It becomes a back-and-forth and it is not at all just a one-way broadcast. The more my audience interact with me, the more fun I have! That’s also the reason I show the chat within the stream most of the time since parts of what I say and do are reactions and follow-ups to what happens there.
I can only hope I get even more feedback and comments as I get better at this and that people find out about what I’m doing here.
And really, by now I also think of it as a really concentrated and devoted hacking time. I can get a lot of things done during these streaming sessions! I’ll try to keep them going a while.
Twitch
I decided to go with twitch simply because it is an established and known live-streaming platform. I didn’t do any deeper analyses or comparisons, but it seems to work fine for my purposes. I get a stream out with video and sound and people seem to be able to enjoy it.
As of this writing, there are 1645 people following me on twitch. Typical recent live-streams of mine have been watched by over a hundred simultaneous viewers. I also archive all past streams on Youtube, so you can get almost the same experience my watching back issues there.
I announce my upcoming streaming sessions as “events” on Twitch, and I announce them on twitter (@bagder you know). I try to stick to streaming on European day time hours basically because then I’m all alone at home and risk fewer interruptions or distractions from family members or similar.
Challenges
It’s not as easy as it may look trying to write code or debug an issue while at the same time explaining what I do. I learnt that the sessions get better if I have real and meaty issues to deal with or features to add, rather than to just have a few light-weight things to polish.
I also quickly learned that it is better to now not show an actual screen of mine in the stream, but instead I show a crafted set of windows placed on the output to look like it is a screen. This way there’s a much smaller risk that I actually show off private stuff or other content that wasn’t meant for the audience to see. It also makes it easier to show a tidy, consistent and clear “desktop”.
Streaming makes me have to stay focused on the development and prevents me from drifting off and watching cats or reading amusing tweets for a while
Trolls
So far we’ve been spared from the worst kind of behavior and people. We’ve only had some mild weirdos showing up in the chat and nothing that we couldn’t handle.
Equipment and software
I do all development on Linux so things have to work fine on Linux. Luckily, OBS Studio is a fine streaming app. With this, I can setup different “scenes” and I can change between them easily. Some of the scenes I have created are “emacs + term”, “browser” and “coffee break”.
When I want to show off me fiddling with the issues on github, I switch to the “browser” scene that primarily shows a big browser window (and the chat and the webcam in smaller windows).
When I want to show code, I switch to “emacs + term” that instead shows a terminal and an emacs window (and again the chat and the webcam in smaller windows), and so on.
OBS has built-in support for some of the major streaming services, including twitch, so it’s just a matter of pasting in a key in an input field, press ‘start streaming’ and go!
The rest of the software is the stuff I normally use anyway for developing. I don’t fake anything and I don’t make anything up. I use emacs, make, terminals, gdb etc. Everything this runs on my primary desktop Debian Linux machine that has 32GB of ram, an older i7-3770K CPU at 3.50GHz with a dual screen setup. The video of me is captured with a basic Logitech C270 webcam and the sound of my voice and the keyboard is picked up with my Sennheiser PC8 headset.
How else am I supposed to have my coffee while developing?
This is my home office standard setup. On the left is my video conference laptop and on the right is my regular work laptop. The two screens in the middle are connected to the desktop computer.
curl supports some twenty-three protocols (depending on exactly how you count).
In order to properly test and verify curl’s implementations of each of these protocols, we have a test suite. In the test suite we have a set of handcrafted servers that speak the server-side of these protocols. The more used a protocol is, the more important it is to have it thoroughly tested.
We believe in having test servers that are “stupid” and that offer buttons, levers and thresholds for us to control and manipulate how they act and how they respond for testing purposes. The control of what to send should be dictated as much as possible by the test case description file. If we want a server to send back a slightly broken protocol sequence to check how curl supports that, the server must be open for this.
In order to do this with a large degree of freedom and without restrictions, we’ve found that using “real” server software for this purpose is usually not good enough. Testing the broken and bad cases are typically not easily done then. Actual server software tries hard to do the right thing and obey standards and protocols, while we rather don’t want the server to make any decisions by itself at all but just send exactly the bytes we ask it to. Simply put.
Of course we don’t always get what we want and some of these protocols are fairly complicated which offer challenges in sticking to this policy all the way. Then we need to be pragmatic and go with what’s available and what we can make work. Having test cases run against a real server is still better than no test cases at all.
Now SOCKS
“SOCKS is an Internet protocol that exchanges network packets between a client and server through a proxy server. Practically, a SOCKS server proxies TCP connections to an arbitrary IP address, and provides a means for UDP packets to be forwarded.
Recently we fixed a bug in how curl sends credentials to a SOCKS5 proxy as it turned out the protocol itself only supports user name and password length of 255 bytes each, while curl normally has no such limits and could pass on credentials with virtually infinite lengths. OK, that was silly and we fixed the bug. Now curl will properly return an error if you try such long credentials with your SOCKS5 proxy.
As a general rule, fixing a bug should mean adding at least one new test case, right? Up to this time we had been testing the curl SOCKS support by firing up an ssh client and having that setup a SOCKS proxy that connects to the other test servers.
curl -> ssh with SOCKS proxy -> test server
Since this setup doesn’t support SOCKS5 authentication, it turned out complicated to add a test case to verify that this bug was actually fixed.
This test problem was fixed by the introduction of a newly written SOCKS proxy server dedicated for the curl test suite (which I simply named socksd). It does the basic SOCKS4 and SOCKS5 protocol logic and also supports a range of commands to control how it behaves and what it allows so that we can now write test cases against this server and ask the server to misbehave or otherwise require fun things so that we can make really sure curl supports those cases as well.
It also has the additional bonus that it works without ssh being present so it will be able to run on more systems and thus the SOCKS code in curl will now be tested more widely than before.
curl -> socksd -> test server
Going forward, we should also be able to create even more SOCKS tests with this and make sure to get even better SOCKS test coverage.
In order to ship a quality product – once every eight weeks – we need lots of testing. This is what we do to test curl and libcurl.
checksrc
We have basic script that verifies that the source code adheres to our code standard. It doesn’t catch all possible mistakes, but usually it complains with enough details to help contributors to write their code to match the style we already use. Consistent code style makes the code easier to read. Easier reading makes less bugs and quicker debugging.
By doing this check with a script (that can be run automatically when building curl), it makes it easier for everyone to ship properly formatted code.
We have not (yet) managed to convince clang-format or other tools to reformat code to correctly match our style, and we don’t feel like changing it just for the sake of such a tool. I consider this a decent work-around.
make test
The test suite that we bundle with the source code in the git repository has a large number of tests that test…
curl – it runs the command line tool against test servers for a large range of protocols and verifies error code, the output, the protocol details and that there are no memory leaks
libcurl – we then build many small test programs that use the libcurl API and perform tests against test servers and verifies that they behave correctly and don’t leak memory etc.
unit tests – we build small test programs that use libcurl internal functions that aren’t exposed in the API and verify that they behave correctly and generate the presumed output.
valgrind – all the tests above can be run with and without valgrind to better detect memory issues
“torture” – a special mode that can run the tests above in a way that first runs the entire test, counts the number of memory related functions (malloc, strdup, fopen, etc) that are called and then runs the test again that number of times and for each run it makes one of the memory related functions fail – and makes sure that no memory is leaked in any of those situations and no crash occurs etc. It runs the test over and over until all memory related functions have been made to fail once each.
Right now, a single “make test” runs over 1100 test cases, varying a little depending on exactly what features that are enabled in the build. Without valgrind, running those tests takes about 8 minutes on a reasonably fast machine but still over 25 minutes with valgrind.
Then we of course want to run all tests with different build options…
CI
For every pull request and for every source code commit done, the curl source is built for Linux, mac and windows. With a large set of different build options and TLS libraries selected, and all the tests mentioned above are run for most of these build combinations. Running ‘checksrc’ on the pull requests is of course awesome so that humans don’t have to remark on code style mistakes much. There are around 30 different builds done and verified for each commit.
If any CI build fails, the pull request on github gets a red X to signal that something was not OK.
We also run test case coverage analyses in the CI so that we can quickly detect if we for some reason significantly decrease test coverage or similar.
We use Travis CI, Appveyor and Coveralls.io for this.
Autobuilds
Independently of the CI builds, volunteers run machines that regularly update from git, build and run the entire test suite and then finally email the results back to a central server. These setups help us cover even more platforms, architectures and build combinations. Just with a little longer turn around time.
With millions of build combinations and support for virtually every operating system and CPU architecture under the sun, we have to accept that not everything can be fully tested. But since almost all code is shared for many platforms, we can still be reasonably sure about the code even for targets we don’t test regularly.
Static code analyzing
We run the clang scan-build on the source code daily and we run Coverity scans on the code “regularly”, about once a week.
We always address defects detected by these analyzers immediately when notified.
Fuzzing
We’re happy to be part of Google’s OSS-fuzz effort, which with a little help with integration from us keeps hammering our code with fuzz to make sure we’re solid.
OSS-fuzz has so far resulted in two security advisories for curl and a range of other bug fixes. It hasn’t been going on for very long and based on the number it has detected so far, I expect it to keep finding flaws – at least for a while more into the future.
Fuzzing is really the best way to hammer out bugs. When we’re down to zero detected static analyzer detects and thousands of test cases that all do good, the fuzzers can still continue to find holes in the net.
External
Independently of what we test, there are a large amount of external testing going on, for each curl release we do.
In a presentation by Google at curl up 2017, they mentioned their use of curl in “hundreds of applications” and how each curl release they adopt gets tested more than 400,000 times. We also know a lot of other users also have curl as a core component in their systems and test their installations extensively.
We have a large set of security interested developers who run tests and fuzzers on curl at their own will.
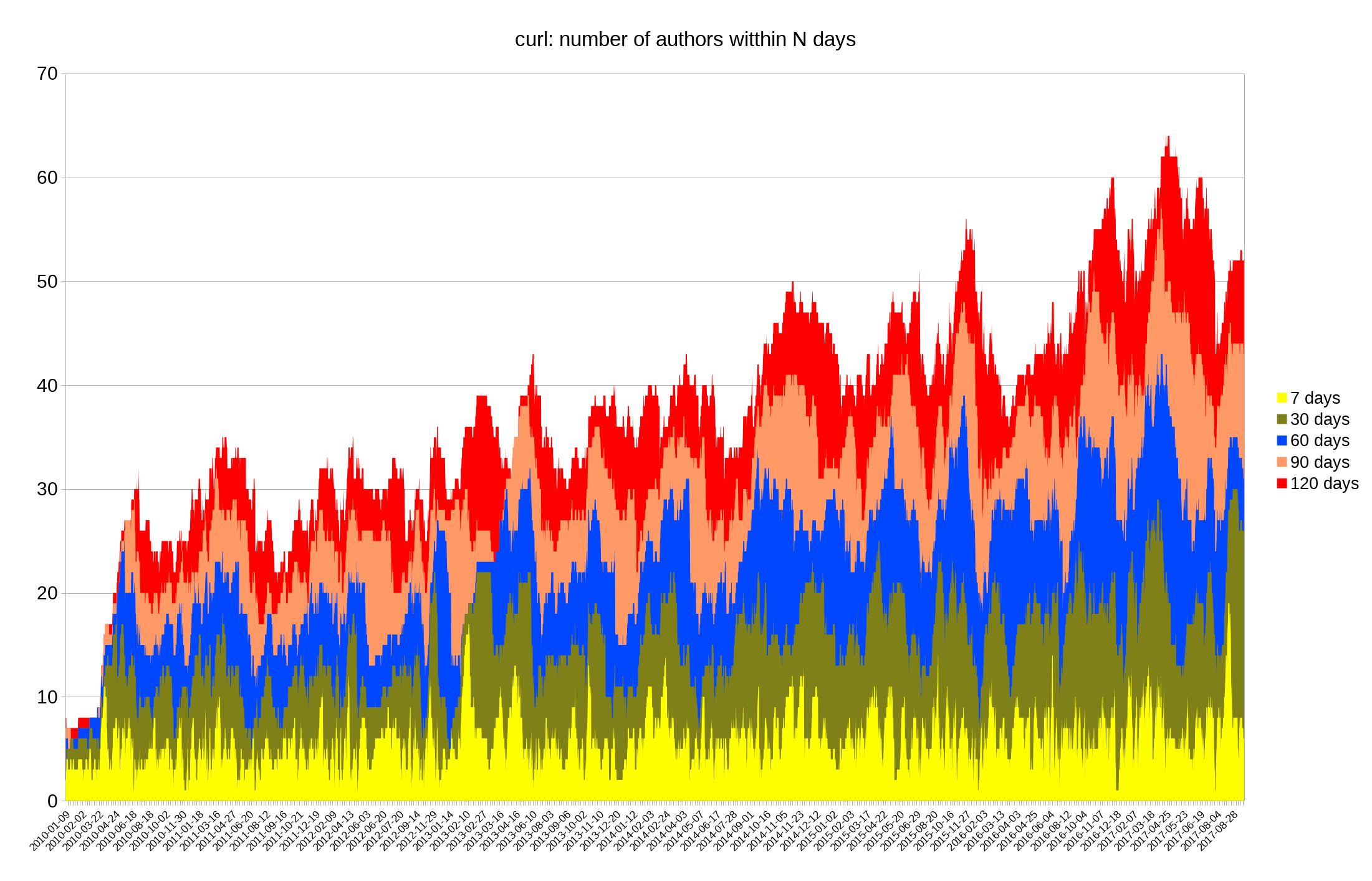
At the time of each commit, check how many unique authors that had a change committed within the previous 120, 90, 60, 30 and 7 days. Run the script on the curl git repository and then plot a graph of the data, ranging from 2010 until today. This is just under 10,000 commits.
(click for the full resolution version)
git-authors-active.pl is the little stand-alone script I wrote and used for this – should work fine for any git repository. I then made the graph from that using libreoffice.