

Every now and then I get questions on how to work with git in a smooth way when developing, bug-fixing or extending curl – or how I do it. After all, I work on open source full time which means I have very frequent interactions with git (and GitHub). Simply put, I work with git all day long. Ordinary days, I issue git commands several hundred times.
I have a very simple approach and way of working with git in curl. This is how it works.
command line
I use git almost exclusively from the command line in a terminal. To help me see which branch I’m working in, I have this little bash helper script.
brname () {
a=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
if [ -n "$a" ]; then
echo " [$a]"
else
echo ""
fi
}
PS1="\u@\h:\w\$(brname)$ "
That gives me a prompt that shows username, host name, the current working directory and the current checked out git branch.
In addition: I use Debian’s bash command line completion for git which is also really handy. It allows me to use tab to complete things like git commands and branch names.
git config
I of course also have my customized ~/.gitconfig file to provide me with some convenient aliases and settings. My most commonly used git aliases are:
st = status --short -uno
ci = commit
ca = commit --amend
caa = commit -a --amend
br = branch
co = checkout
df = diff
lg = log -p --pretty=fuller --abbrev-commit
lgg = log --pretty=fuller --abbrev-commit --stat
up = pull --rebase
latest = log @^{/RELEASE-NOTES:.synced}..
The ‘latest’ one is for listing all changes done to curl since the most recent RELEASE-NOTES “sync”. The others should hopefully be rather self-explanatory.
The config also sets gpgsign = true, enables mailmap and a few other things.
master is clean and working
The main curl development is done in the single curl/curl git repository (primarily hosted on GitHub). We keep the master branch the bleeding edge development tree and we work hard to always keep that working and functional. We do our releases off the master branch when that day comes (every eight weeks) and we provide “daily snapshots” from that branch, put together – yeah – daily.
When merging fixes and features into master, we avoid merge commits and use rebases and fast-forward as much as possible. This makes the branch very easy to browse, understand and work with – as it is 100% linear.
Work on a fix or feature
When I start something new, like work on a bug or trying out someone’s patch or similar, I first create a local branch off master and work in that. That is, I don’t work directly in the master branch. Branches are easy and quick to do and there’s no reason to shy away from having loads of them!
I typically name the branch prefixed with my GitHub user name, so that when I push them to the server it is noticeable who is the creator (and I can use the same branch name locally as I do remotely).
$ git checkout -b bagder/my-new-stuff-or-bugfix
Once I’ve reached somewhere, I commit to the branch. It can then end up one or more commits before I consider myself “done for now” with what I was set out to do.
I try not to leave the tree with any uncommitted changes – like if I take off for the day or even just leave for food or an extended break. This puts the repository in a state that allows me to easily switch over to another branch when I get back – should I feel the need to. Plus, it’s better to commit and explain the change before the break rather than having to recall the details again when coming back.
Never stash
“git stash” is therefore not a command I ever use. I rather create a new branch and commit the (temporary?) work in there as a potential new line of work.
Show it off and get reviews
Yes I am the lead developer of the project but I still maintain the same work flow as everyone else. All changes, except the most minuscule ones, are done as pull requests on GitHub.
When I’m happy with the functionality in my local branch. When the bug seems to be fixed or the feature seems to be doing what it’s supposed to do and the test suite runs fine locally.
I then clean up the commit series with “git rebase -i” (or if it is a single commit I can instead use just “git commit --amend“).
The commit series should be a set of logical changes that are related to this change and not any more than necessary, but kept separate if they are separate. Each commit also gets its own proper commit message. Unrelated changes should be split out into its own separate branch and subsequent separate pull request.
git push origin bagder/my-new-stuff-or-bugfix
Make the push a pull request
On GitHub, I then make the newly pushed branch into a pull request (aka “a PR”). It will then become visible in the list of pull requests on the site for the curl source repository, it will be announced in the #curl IRC channel and everyone who follows the repository on GitHub will be notified accordingly.
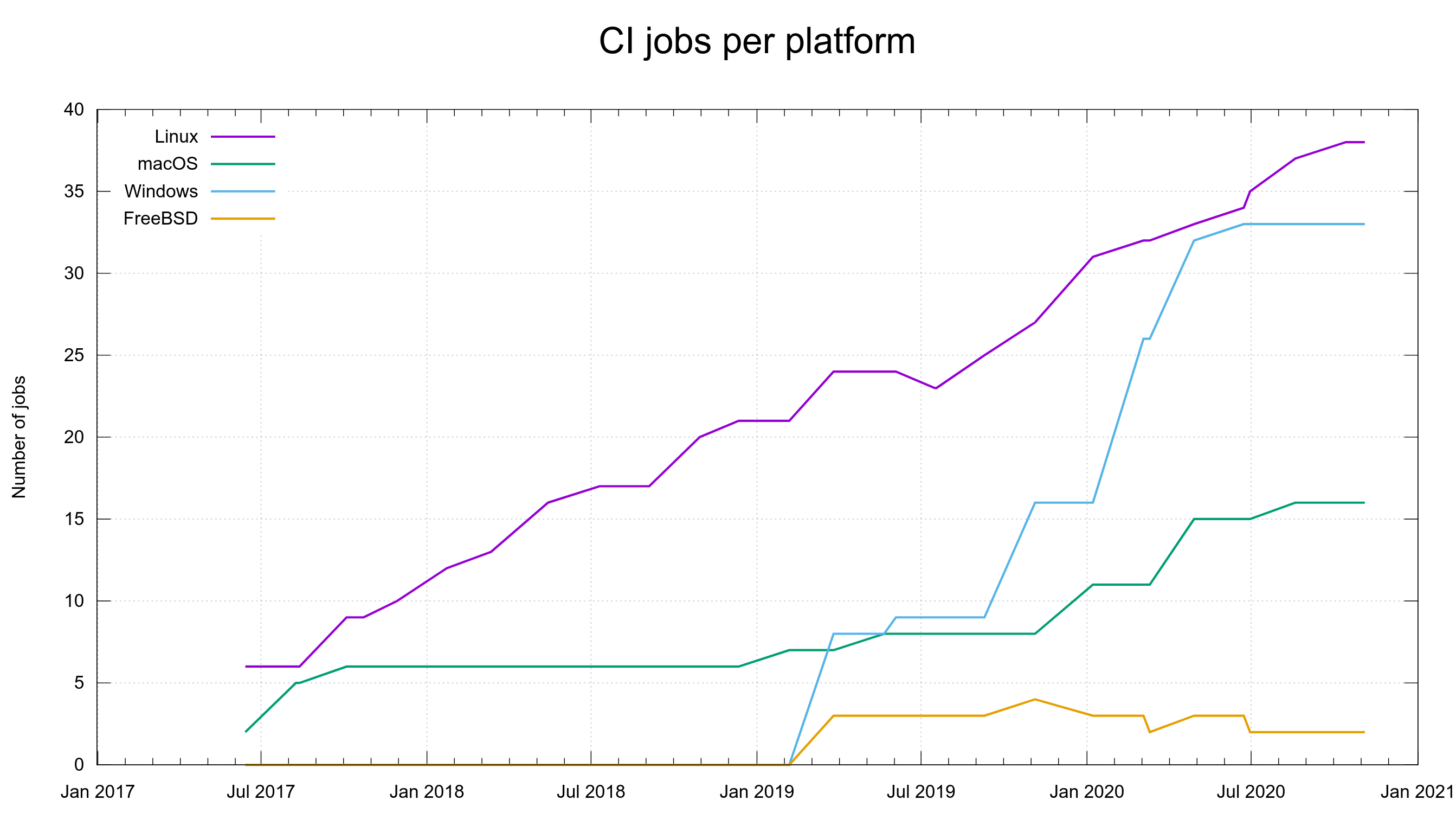
Perhaps most importantly, a pull request kicks of a flood of CI jobs that will build and test the code in numerous different combinations and on several platforms, and the results of those tests will trickle in over the coming hours. When I write this, we have around 90 different CI jobs – per pull request – and something like 8 different code analyzers will scrutinize the change to see if there’s any obvious flaws in there.
A branch in the actual curl/curl repo
Most contributors who would work on curl would not do like me and make the branch in the curl repository itself, but would rather do them in their own forked version instead. The difference isn’t that big and I could of course also do it that way.
After push, switch branch
As it will take some time to get the full CI results from the PR to come in (generally a few hours), I switch over to the next branch with work on my agenda. On a normal work-day I can easily move over ten different branches, polish them and submit updates in their respective pull-requests.
I can go back to the master branch again with ‘git checkout master‘ and there I can “git pull” to get everything from upstream – like when my fellow developers have pushed stuff in the mean time.
PR comments or CI alerts
If a reviewer or a CI job find a mistake in one of my PRs, that becomes visible on GitHub and I get to work to handle it. To either fix the bug or discuss with the reviewer what the better approach might be.
Unfortunately, flaky CI jobs is a part of life so very often there ends up one or two red markers in the list of CI jobs that can be ignored as the test failures in them are there due to problems in the setup and not because of actual mistakes in the PR…
To get back to my branch for that PR again, I “git checkout bagder/my-new-stuff-or-bugfix“, and fix the issues.
I normally start out by doing follow-up commits that repair the immediate mistake and push them on the branch:
git push origin bagder/my-new-stuff-or-bugfix
If the number of fixup commits gets large, or if the follow-up fixes aren’t small, I usually end up doing a squash to reduce the number of commits into a smaller, simpler set, and then force-push them to the branch.
The reason for that is to make the patch series easy to review, read and understand. When a commit series has too many commits that changes the previous commits, it becomes hard to review.
Ripe to merge?
When the pull request is ripe for merging (independently of who authored it), I switch over to the master branch again and I merge the pull request’s commits into it. In special cases I cherry-pick specific commits from the branch instead. When all the stuff has been yanked into master properly that should be there, I push the changes to the remote.
Usually, and especially if the pull request wasn’t done by me, I also go over the commit messages and polish them somewhat before I push everything. Commit messages should follow our style and mention not only which PR that it closes but also which issue it fixes and properly give credit to the bug reporter and all the helpers – using the right syntax so that our automatic tools can pick them up correctly!
As already mentioned above, I merge fast-forward or rebased into master. No merge commits.
Never merge with GitHub!
There’s a button GitHub that says “rebase and merge” that could theoretically be used for merging pull requests. I never use that (and if I could, I’d disable/hide it). The reasons are simply:
- I don’t feel that I have the proper control of the commit message(s)
- I can’t select to squash a subset of the commits, only all or nothing
- I often want to cleanup the author parts too before push, which the UI doesn’t allow
The downside with not using the merge button is that the message in the PR says “closed by [hash]” instead of “merged in…” which causes confusion to a fair amount of users who don’t realize it means that it actually means the same thing! I consider this is a (long-standing) GitHub UX flaw.
Post merge
If the branch has nothing to be kept around more, I delete the local branch again with “git branch -d [name]” and I remove it remotely too since it was completely merged there’s no reason to keep the work version left.
At any given point in time, I have some 20-30 different local branches alive using this approach so things I work on over time all live in their own branches and also submissions from various people that haven’t been merged into master yet exist in branches of various maturity levels. Out of those local branches, the number of concurrent pull requests I have in progress can be somewhere between just a few up to ten, twelve something.
RELEASE-NOTES
Not strictly related, but in order to keep interested people informed about what’s happening in the tree, we sync the RELEASE-NOTES file every once in a while. Maybe every 5-7 days or so. It thus becomes a file that explains what we’ve worked on since the previous release and it makes it well-maintained and ready by the time the release day comes.
To sync it, all I need to do is:
$ ./scripts/release-notes.pl
Which makes the script add suggested updates to it, so I then load the file into my editor, remove the separation marker and all entries that don’t actually belong there (as the script adds all commits as entries as it can’t judge the importance).
When it looks okay, I run a cleanup round to make it sort it and remove unused references from the file…
$ ./scripts/release-notes.pl cleanup
Then I make sure to get a fresh list of contributors…
$ ./scripts/contributors.sh
… and paste that updated list into the RELEASE-NOTES. Finally, I get refreshed counters for the numbers at the top of the file by running
$ ./scripts/delta
Then I commit the update (which needs to have the commit message RELEASE-NOTES: synced“) and push it to master. Done!
The most up-to-date version of RELEASE-NOTES is then always made available on https://curl.se/dev/release-notes.html
Credits
Picture by me, taken from the passenger seat on a helicopter tour in 2011.













 I’ve tried to imagine of what kind of person that would not have or use any piece of
I’ve tried to imagine of what kind of person that would not have or use any piece of 