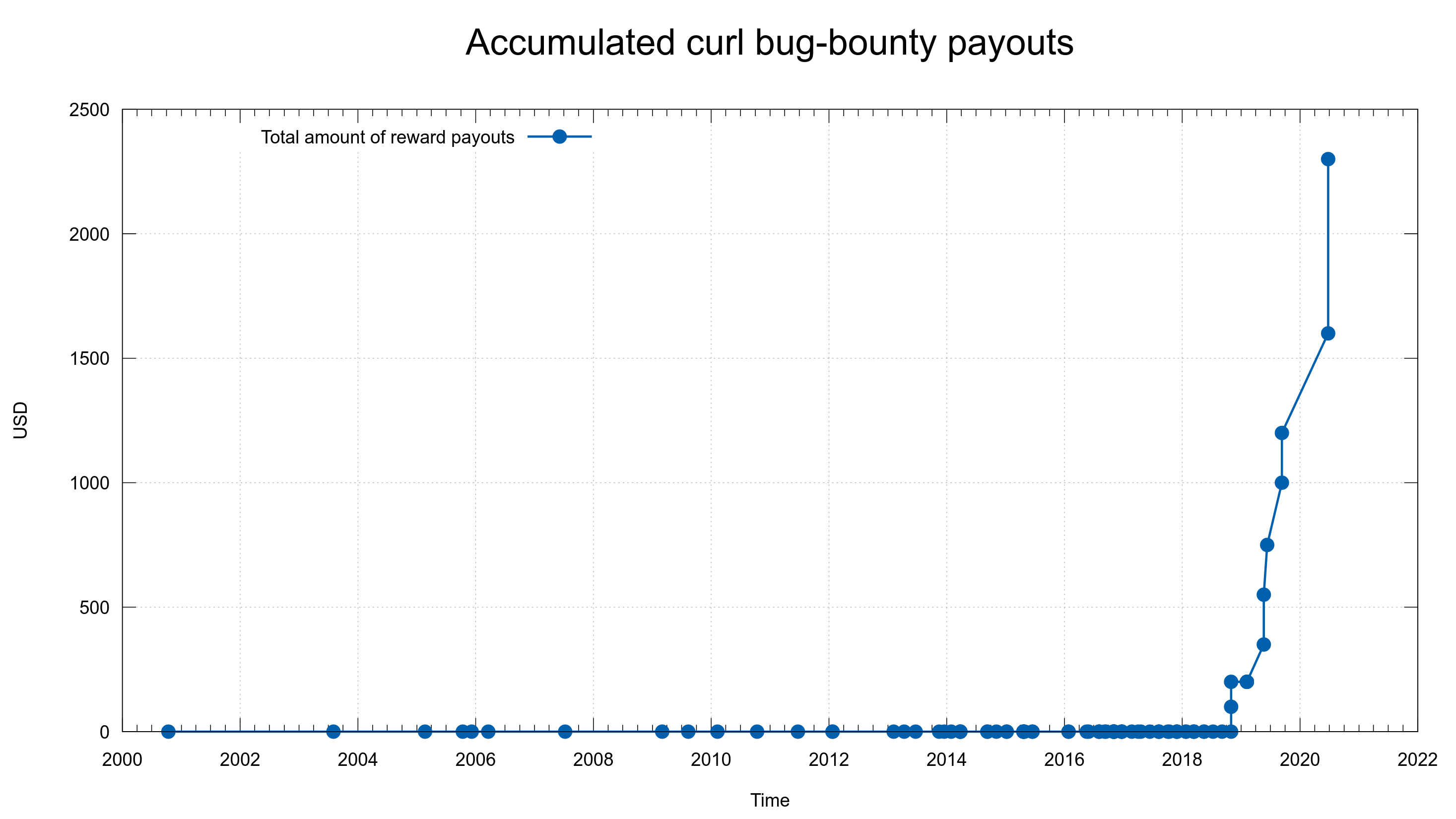
Previous options of the week.
--silent (-s) existed in curl already in the first ever version released: 4.0.
Silent by default
I’ve always enjoyed the principles of Unix command line tool philosophy and I’ve tried to stay true to them in the design and implementation of the curl command line tool: everything is a pipe, don’t “speak” more than necessary by default.
As a result of the latter guideline, curl features the --verbose option if you prefer it to talk and explain more about what’s going on. By default – when everything is fine – it doesn’t speak much extra.
Initially: two things were “spoken”
To show users that something is happening during a command line invoke that takes a long time, we added a “progress meter” display. But since you can also ask curl to output text or data in the terminal, curl has logic to automatically switch off the progress meter display to avoid content output to get mixed with it.
Of course we very quickly figured out that there are also other use cases where the progress meter was annoying so we needed to offer a way to shut it off. To keep silent! --silent was the obvious choice for option name and -s was conveniently still available.
The other thing that curl “speaks” by default is the error message. If curl fails to perform the transfer or operation as asked to, it will output a single line message about it when it is done, and then return an error code.
When we added an option called --silent to make curl be truly silent, we also made it hush the error message. curl still returns an error code, so shell scripts and similar environments that invoke curl can still detect errors perfectly fine. Just possibly slightly less human friendly.
But I want my errors?
In May 1999, the tool was just fourteen months old, we added --show-error (-S) for users that wanted to curl to be quiet in general but still wanted to see the error message in case it failed. The -Ss combination has been commonly used ever since.
More information added
Over time we’ve made the tool more complex and we’ve felt that it needs some more informational output in some cases. For example, when you use --retry, curl will say something that it will try again etc. The reason is of course that --verbose is really verbose so its not really the way to ask for such little extra helpful info.
Only shut off the progress meter
Not too long ago, we ended up with a new situation where the --silent option is a bit too silent since it also disables the text for retry etc so what if you just want to shut off the progress meter?
--no-progress-meter was added for that, which thus is a modern replacement for --silent in many cases.