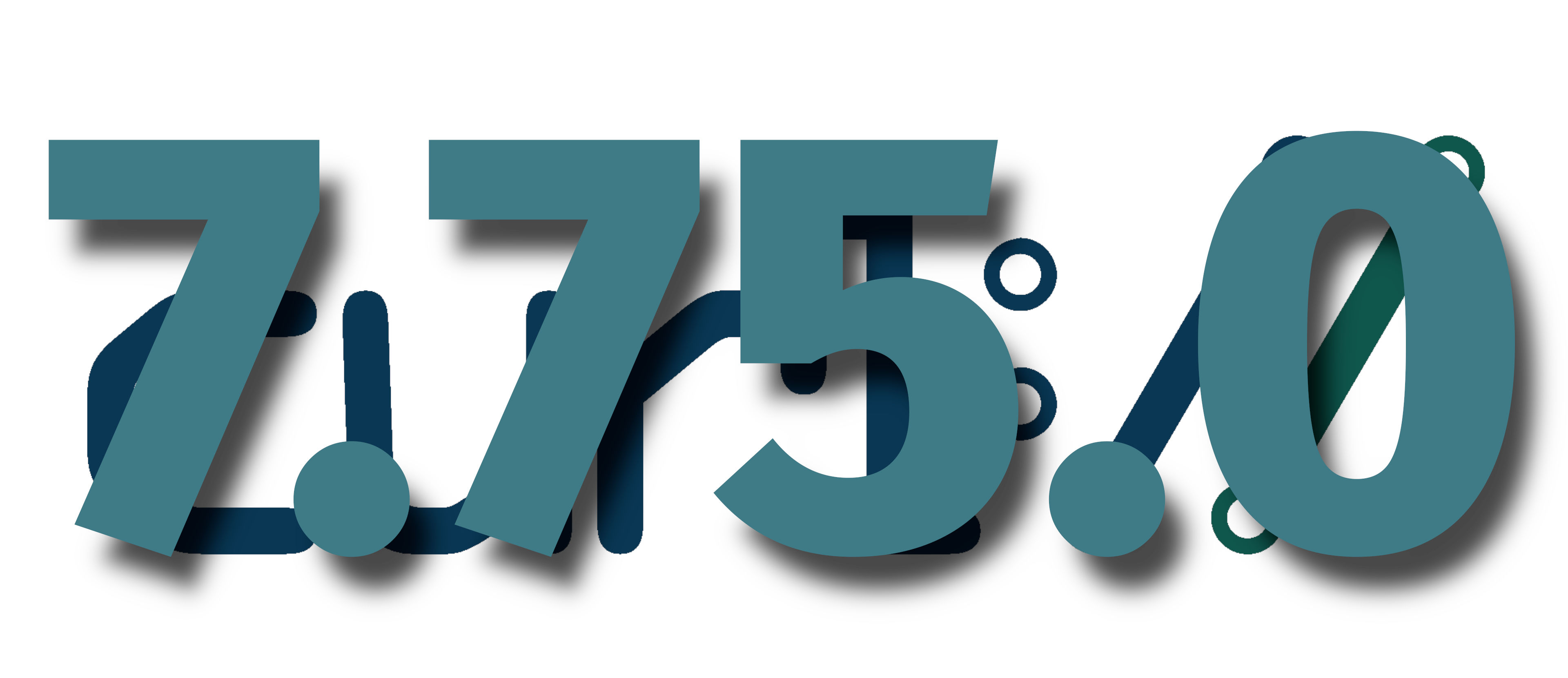
There’s been another 56 day release cycle and here’s another curl release to chew on!
Release presentation
Numbers
the 197th release
6 changes
56 days (total: 8,357)
113 bug fixes (total: 6,682)
268 commits (total: 26,752)
0 new public libcurl function (total: 85)
1 new curl_easy_setopt() option (total: 285)
2 new curl command line option (total: 237)
58 contributors, 30 new (total: 2,322)
31 authors, 17 new (total: 860)
0 security fixes (total: 98)
0 USD paid in Bug Bounties (total: 4,400 USD)
Security
No new security advisories this time!
Changes
We added --create-file-mode to the command line tool. To be used for the protocols where curl needs to tell the remote server what “mode” to use for the file when created. libcurl already supported this, but now we expose the functionality to the tool users as well.
The --write-out option got five new “variables” to use. Detailed in this separate blog post.
The CURLOPT_RESOLVE option got an extended format that now allows entries to be inserted to get timed-out after the standard DNS cache expiry time-out.
gophers:// – the protocol GOPHER done over TLS – is now supported by curl.
As a new experimentally supported HTTP backend, you can now build curl to use Hyper. It is not quite up to 100% parity in features just yet.
AWS HTTP v4 Signature support. This is an authentication method for HTTP used by AWS and some other services. See CURLOPT_AWS_SIGV4 for libcurl and --aws-sigv4 for the curl tool.
Bug-fixes
Some of the notable things we’ve fixed this time around…
Reduced struct sizes
In my ongoing struggles to remove “dead weight” and ensure that curl can run on as small devices as possible, I’ve trimmed down the size of several key structs in curl. The memory foot-print of libcurl is now smaller than it has been for a very long time.
Reduced conn->data references
While itself not exactly a bug-fix, this is a step in a larger refactor of libcurl where we work on removing all references back from connections to the transfer. The grand idea is that transfers can point to connections, but since a connection can be owned and used by many transfers, we should remove all code that reference back to a transfer from the connection. To simplify internals. We’re not quite there yet.
Silly writeout time units bug
Many users found out that when asking the curl tool to output timing information with -w, I accidentally made it show microseconds instead of seconds in 7.74.0! This is fixed and we’re back to the way it always was now…
CURLOPT_REQUEST_TARGET works with HTTP proxy
The option that lets the user set the “request target” of a HTTP request to something custom (like for example “*” when you want to issue a request using the OPTIONS method) didn’t work over proxy!
CURLOPT_FAILONERROR fails after all headers
Often used with the tools --fail flag, this is feature that makes libcurl stop and return error if the HTTP response code is 400 or larger. Starting in this version, curl will still read and parse all the response headers before it stops and exists. This then allows curl to act on and store contents from the other headers that can be used for features in combination with --fail.
Proxy-Connection duplicated headers
In some circumstances, providing a custom “Proxy-Connection:” header for a HTTP request would still get curl’s own added header in the request as well, making the request get sent with a duplicate set!
CONNECT chunked encoding race condition
There was a bug in the code that handles proxy responses, when the body of the CONNECT responses was using chunked-encoding. curl could end up thinking the response had ended before it actually had…
proper User-Agent header setup
Back in 7.71.0 we fixed a problem with the user-agent header and made it get stored correctly in the transfer struct, from previously having been stored in the connection struct.
That cause a regression that we fixed now. The previous code had a mistake that caused the user-agent header to not get used when a connection was re-used or multiplexed, which from an outside perspective made it appear go missing in a random fashion…
add support for %if [feature] conditions in tests
Thanks to the new preprocessor we added for test cases some releases ago, we could now take the next step and offer conditionals in the test cases so that we can now better allow tests to run and behave differently depending on features and parameters. Previously, we have resorted to only make tests require a certain feature set to be able to run and otherwise skip the tests completely if the feature set could be satisfied, but with this new ability we can make tests more flexible and thus work with a wider variety of features.
if IDNA conversion fails, fallback to Transitional
A user reported that that curl failed to get the data when given a funny URL, while it worked fine in browsers (and wget):

The host name consists of a heart and a fox emoji in the .ws top-level domain. This is yet another URLs-are-weird issue and how to do International Domain Names with them is indeed a complicated matter, but starting now curl falls back and tries a more conservative approach if the first take fails and voilá, now curl too can get the heart-fox URL just fine… Regular readers of my blog might remember the smiley URLs of 2015, which were similar.
urldata: make magic first struct field
We provide types for the most commonly used handles in the libcurl API as typedef’ed void pointers. The handles are typically declared like this:
CURL *easy;
CURLM *multi;
CURLSH *shared;
… but since they’re typedefed void-pointers, the compiler cannot helpfully point out if a user passes in the wrong handle to the wrong libcurl function and havoc can ensue.
Starting now, all these three handles have a “magic” struct field in the same relative place within their structs so that libcurl can much better detect when the wrong kind of handle is passed to a function and instead of going bananas or even crash, libcurl can more properly and friendly return an error code saying the input was wrong.
Since you’d ask: using void-pointers like that was a mistake and we regret it. There are better ways to accomplish the same thing, but the train has left. When we’ve tried to correct this situation there have been cracks in the universe and complaints have been shouted through the ether.
SECURE_RENEGOTIATION support for wolfSSL
Turned out we didn’t support this before and it wasn’t hard to add…
openssl: lowercase the host name before using it for SNI
The SNI (Server Name Indication) field is data set in TLS that tells the remote server which host name we want to connect to, so that it can present the client with the correct certificate etc since the server might serve multiple host names.
The spec clearly says that this field should contain the DNS name and that it is case insensitive – like DNS names are. Turns out it wasn’t even hard to find multiple servers which misbehave and return the wrong cert if the given SNI name is not sent lowercase! The popular browsers typically always send the SNI names like that… In curl we keep the host name internally exactly as it was given to us in the URL.
With a silent protest that nobody cares about, we went ahead and made curl also lowercase the host name in the SNI field when using OpenSSL.
I did not research how all the other TLS libraries curl can use behaves when setting SNI. This same change is probably going to have to be done on more places, or perhaps we need to surrender and do the lowercasing once and for all at a central place… Time will tell!
Future!
We have several pull requests in the queue suggesting changes, which means the next release is likely to be named 7.76.0 and the plan is to ship that on March 31st, 2021.
Send us your bug reports and pull requests!