Another curl version has been released into the world. curl 7.56.0 is available for download from the usual place. Here are some news I think are worthy to mention this time…
An FTP security issue
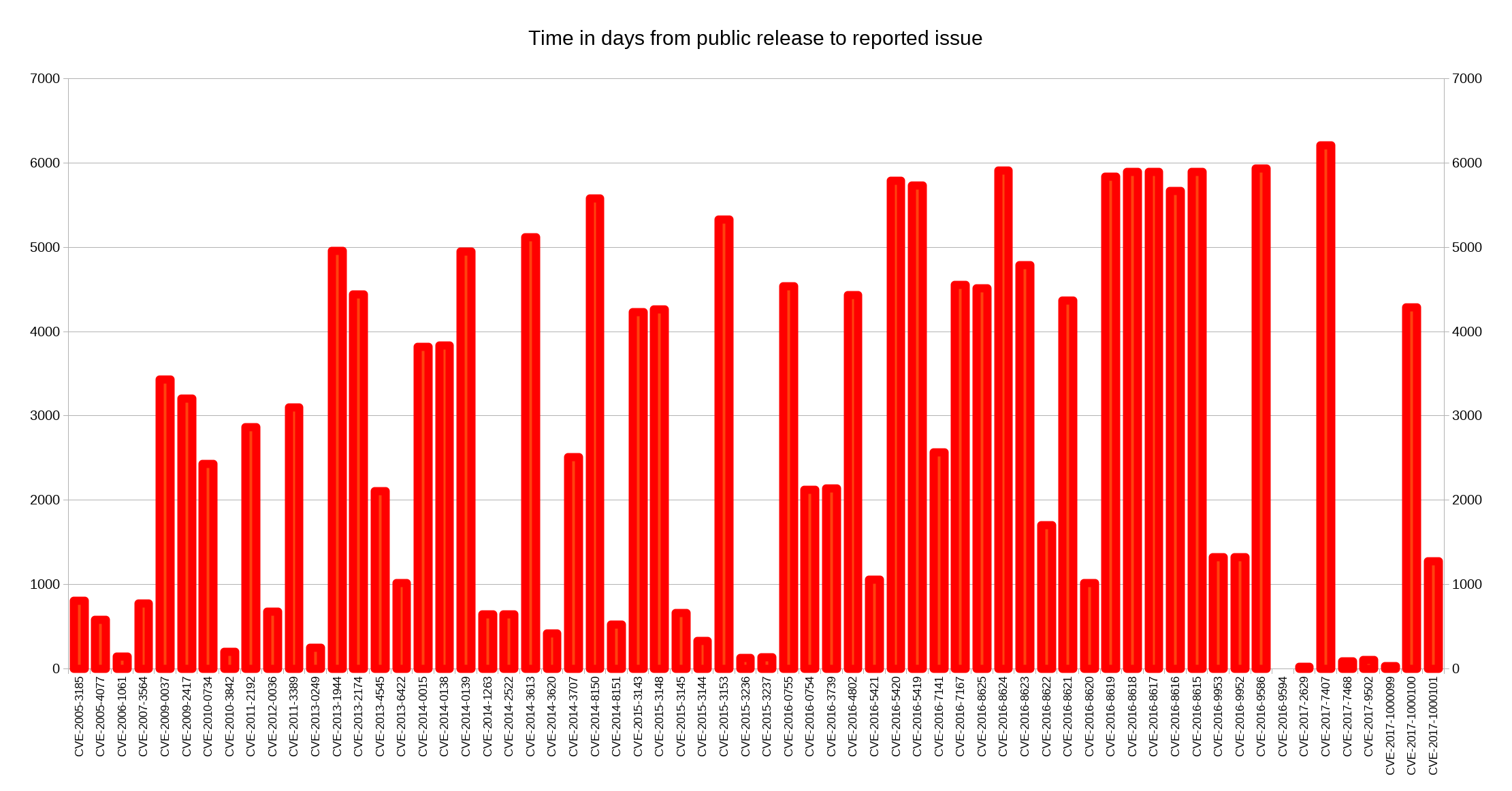
A mistake in the code that parses responses to the PWD command could make curl read beyond the end of a buffer, Max Dymond figured it out, and we’ve released a security advisory about it. Our 69th security vulnerability counted from the beginning and the 8th reported in 2017.
Multiple SSL backends
Since basically forever you’ve been able to build curl with a selected SSL backend to make it get a different feature set or behave slightly different – or use a different license or get a different footprint. curl supports eleven different TLS libraries!
Starting now, libcurl can be built to support more than one SSL backend! You specify all the SSL backends at build-time and then you can tell libcurl at run-time exactly which of the backends it should use.
The selection can only happen once per invocation so there’s no switching back and forth among them, but still. It also of course requires that you actually build curl with more than one TLS library, which you do by telling configure all the libs to use.
The first user of this feature that I’m aware of is git for windows that can select between using the schannel and OpenSSL backends.
curl_global_sslset() is the new libcurl call to do this with.
This feature was brought by Johannes Schindelin.
New MIME API
The currently provided API for creating multipart formposts, curl_formadd, has always been considered a bit quirky and complicated to work with. Its extensive use of varargs is to blame for a significant part of that.
Now, we finally introduce a replacement API to accomplish basically the same features but also with a few additional ones, using a new API that is supposed to be easier to use and easier to wrap for bindings etc.
Introducing the mime API: curl_mime_init, curl_mime_addpart, curl_mime_name and more. See the postit2.c and multi-post.c examples for some easy to grasp examples.
This work was done by Patrick Monnerat.
SSH compression
The SSH protocol allows clients and servers to negotiate to use of compression when communicating, and now curl can too. curl has the new –compressed-ssh option and libcurl has a new setopt called CURLOPT_SSH_COMPRESSION using the familiar style.
Feature worked on by Viktor Szakats.
SSLKEYLOGFILE
Peter Wu and Jay Satiro have worked on this feature that allows curl to store SSL session secrets in a file if this environment variable is set. This is normally the way you tell Chrome and Firefox to do this, and is extremely helpful when you want to wireshark and analyze a TLS stream.
This is still disabled by default due to its early days. Enable it by defining ENABLE_SSLKEYLOGFILE when building libcurl and set environment variable SSLKEYLOGFILE to a pathname that will receive the keys.
Numbers
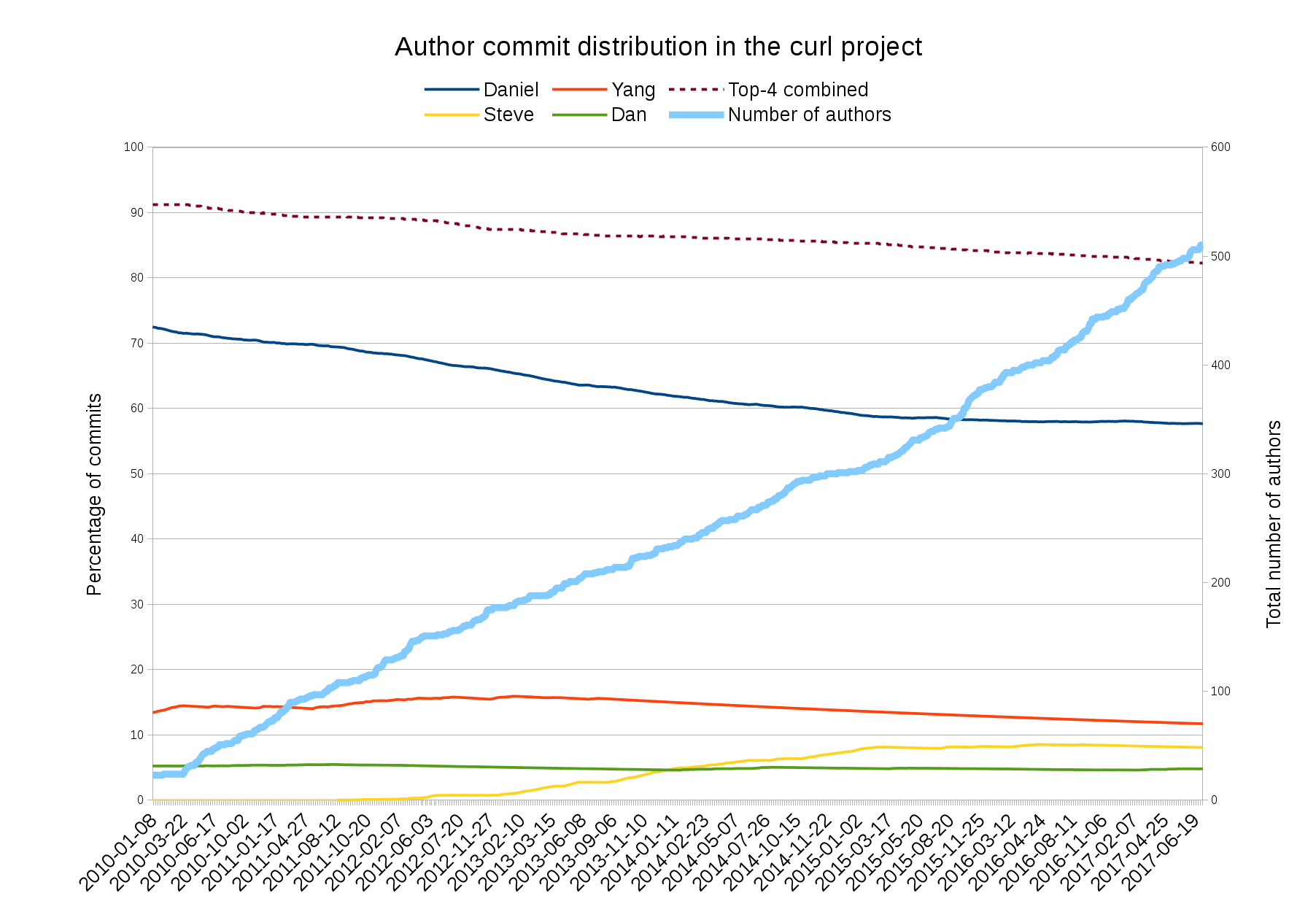
This, the 169th curl release, contains 89 bug fixes done during the 51 days since the previous release.
47 contributors helped making this release, out of whom 18 are new.
254 commits were done since the previous release, by 26 authors.
The top-5 commit authors this release are:
- Daniel Stenberg (116)
- Johannes Schindelin (37)
- Patrick Monnerat (28)
- Jay Satiro (12)
- Dan Fandrich (10)
Thanks a lot everyone!
(picture from pixabay)


 I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you.
I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you. Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.
Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.

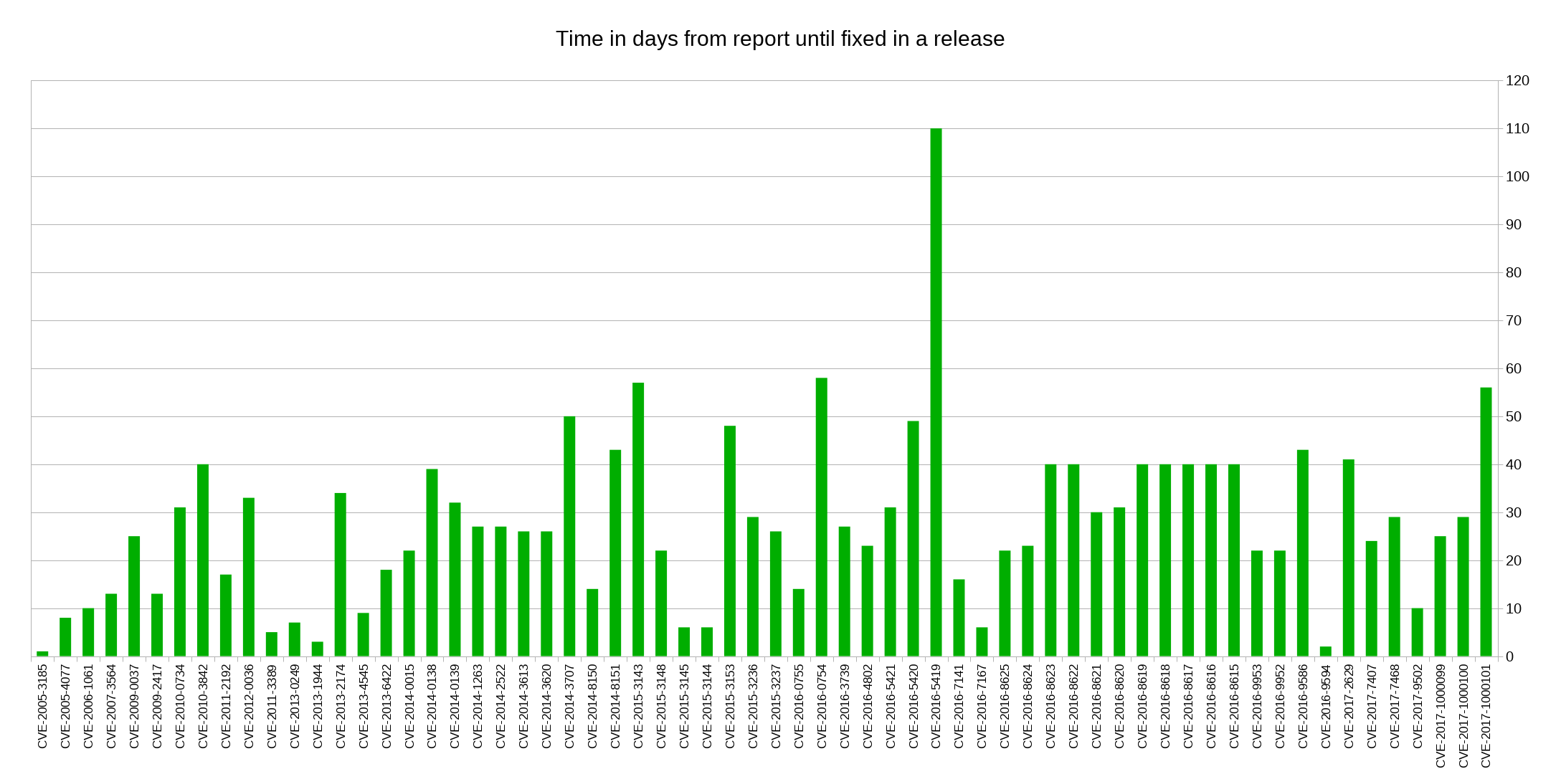
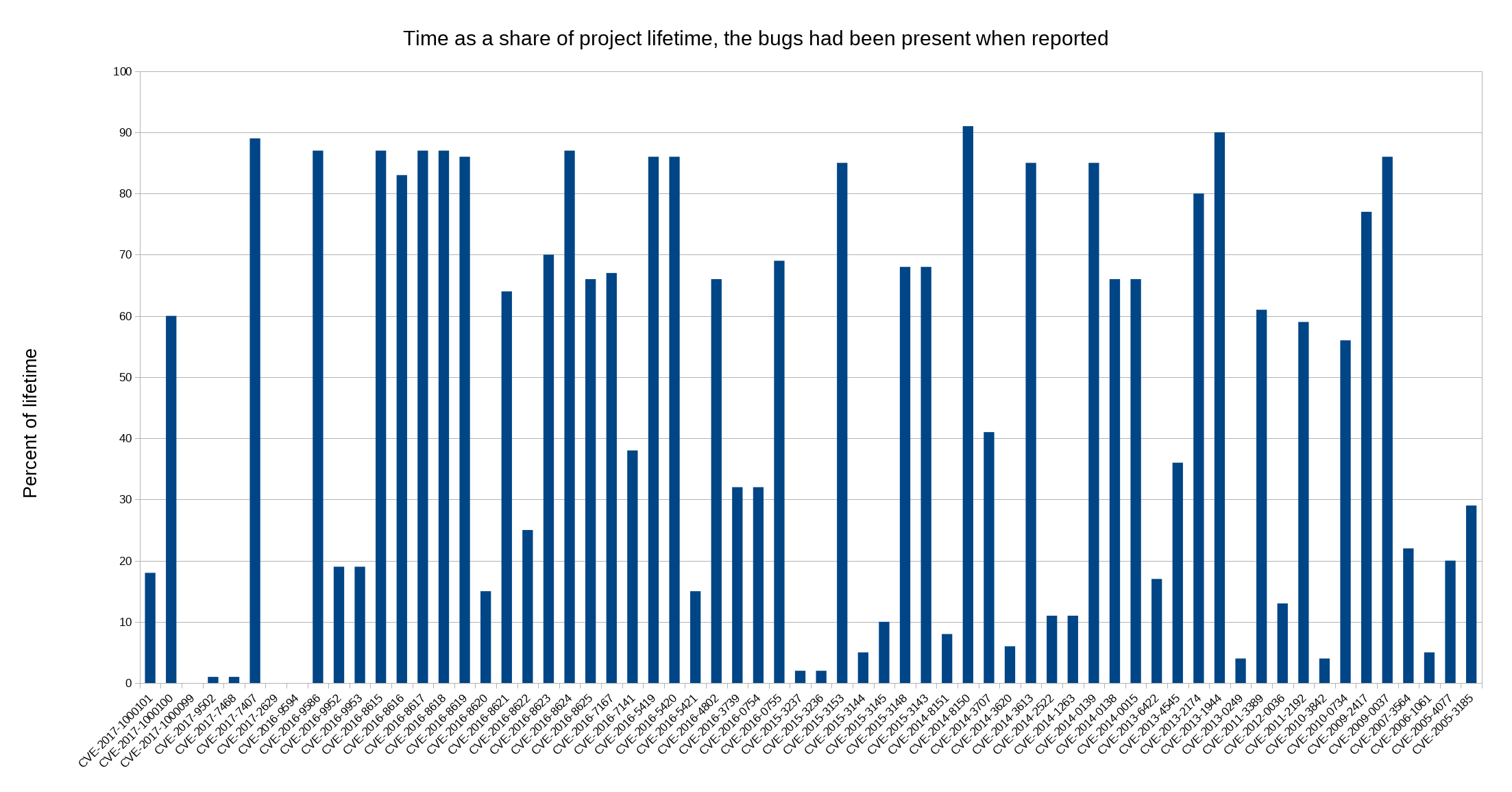
 I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in