

On September 25th 2017, I received the email that first explained to me that I had been awarded the Polhem Prize.
Du har genom ett omfattande arbete vaskats fram som en värdig mottagare av årets Polhemspris. Det har skett genom en nomineringskommitté och slutligen ett råd med bred sammansättning. Priset delas ut av Kungen den 19 oktober på Tekniska muséet.
My attempt of an English translation:
You have been selected as a worthy recipient of this year's Polhem prize through extensive work. It has been through a nomination committee and finally a council of broad composition. The prize is awarded by the King on October 19th at the Technical Museum.
A gold medal
 At the award ceremony in October 2017 I received the gold medal at the most fancy ceremony I could ever wish for, where I was given the most prestigious award I couldn’t have imagined myself even being qualified for, handed over by no other than the Swedish King.
At the award ceremony in October 2017 I received the gold medal at the most fancy ceremony I could ever wish for, where I was given the most prestigious award I couldn’t have imagined myself even being qualified for, handed over by no other than the Swedish King.
An entire evening with me in focus, where I was the final grand finale act and where my life’s work was the primary reason for all those people being dressed up in fancy clothes!
Things have settled down since. The gold medal has started to get a little dust on it where it lies here next to me on my work desk. I still glance at it every once in a while. It still feels surreal. It’s a fricking medal in pure gold with my name on it!
I almost forget the money part of the prize. I got a lot of money as well, but in retrospect it is really the honors, that evening and the gold medal that stick best in my memory. Money is just… well, money.
So did the award and prize make my life any different? Yes sure, a little, and I’ll tell you how.
What’s all that time spent on?
My closest surrounding of friends and family got a better understanding of what I’ve actually been doing all these long hours, all these years and more than one phrase in the style of “oh, so you actually did something useful?!” have been uttered.
Certainly I’ve tried to explain to them before, but nothing works as good as a gold medal from an award committee to say that what I do is actually appreciated “out there” and it has made a serious impact on the world.
I think I’m considered a little less weird now when I keep spending night hours in front of my computer when the house is otherwise dark and silent. Well, maybe still weird, but at least my weirdness has proven to result in something useful for mankind and that’s more than many other sorts of weird do… We all have hobbies.
What is curl?
Family and friends have gotten a rudimentary level of understanding of what curl is and what it does. I’m not suggesting they fully grasp it or know what an “internet protocol” is now, but at least a lot of people understand that it works with “internet transfers”. It’s not like people were totally uninterested before, but when I was given this prize – by a jury of engineers no less – that says this is a significant invention and accomplishment with a value that “can not be overestimated“, it made them more interested. The little video that was produced helped:
Some mysteries remain
People in general still have a hard time to grasp the reach of the project, how much time I’ve spent so far on it, how I can find motivation to keep up the work and not the least how this is all given away for free for everyone.
The simple fact that these are all questions that I’ve been asked I think is a small reward in itself. I think the fact that I was awarded this prize for my work on Open Source is awesome and I feel honored to be a person who introduces this way of thinking to some of the people who previously would think that you have to sell proprietary things or earn a lot of money for your products in order to impact and change society as a whole.
Not widely known
The Polhem prize is not widely known in Sweden among the general populace and thus neither is the fact that I won it. Only a very special subset of people know about this. Of course it is even less known outside of Sweden and in fact the information about the prize given in English is very sparse.
Next year’s winner
The other day I received my invitation to participate in this year’s award ceremony on November 14. Of course I’ll happily accept that and I will be there and celebrate the winner this year!
The curl project
How did the prize affect the project itself, the project that I was awarded for having cared for this long?
It hasn’t affected it much at all (as far as I can tell). The project has moved along like before and we’ve worked on fixing bugs and added features and cool things over time after my award just as we did before it. That’s how it has felt like. Business as usual.
If anything, I think I might have gotten some renewed energy and interest in the project and the commit author statistics actually show that my commit frequency has gone up since around the time I got the award. Our gitstats show that I’ve done more than half of the commits every single month the last year, most of this time even more than 70% of the commits.
I may have served twenty years here, but I’m not done yet!


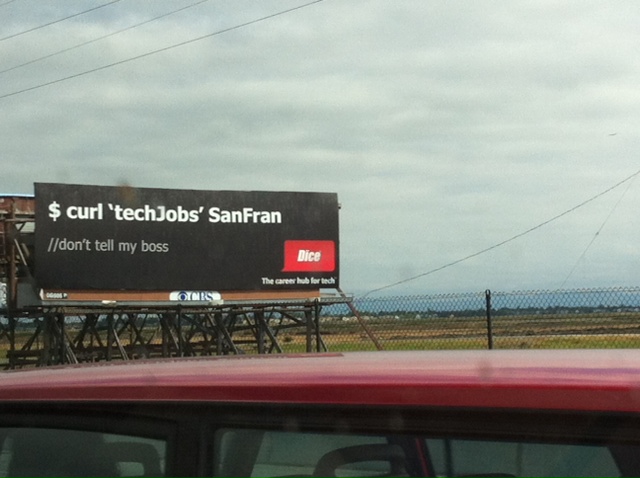
 servers on the Internet. curl and libcurl comes pre-installed on some Linux distributions and for those that it doesn’t, most users and sysadmins install it. My estimate says there are few such servers out there without curl on them.
servers on the Internet. curl and libcurl comes pre-installed on some Linux distributions and for those that it doesn’t, most users and sysadmins install it. My estimate says there are few such servers out there without curl on them. I wrote about this in a
I wrote about this in a  This game is made by Epic Games and credits curl in their
This game is made by Epic Games and credits curl in their  We know curl is used in television sets made by Sony, Philips, Toshiba, LG, Bang & Olufsen, JVC, Panasonic, Samsung and Sharp – at least.
We know curl is used in television sets made by Sony, Philips, Toshiba, LG, Bang & Olufsen, JVC, Panasonic, Samsung and Sharp – at least. I posit that there are almost no smart phones or tablets in the world that doesn’t run curl.
I posit that there are almost no smart phones or tablets in the world that doesn’t run curl.


 Old readers of this blog may remember my ramblings on
Old readers of this blog may remember my ramblings on 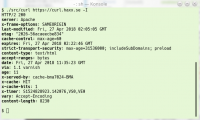


 Over time, we’ve slowly been adjusting the
Over time, we’ve slowly been adjusting the 


{kind=link}
{kind=link}
{kind=link}