I’m awarded the Swedish Polhem Prize 2017. (Link to a Swedish-speaking site.)
The Polhem Prize (Polhemspriset in Swedish), is awarded “for a high-level technological innovation or an ingenious solution to a technical problem.” The Swedish innovation must be available and shown competitive on the open market.
This award has been handed out in the name of the scientist and inventor Christopher Polhem, sometimes called the father of Swedish engineering, since 1878. It is Sweden’s oldest and most prestigious award for technological innovation.
I first got the news on the afternoon on September 24th and I don’t think I exaggerate much if I say that I got a mild shock. Me? A prize? How did they even find me or figure out what I’ve done?
 I get this award for having worked on curl for a very long time, and by doing this having provided an Internet infrastructure of significant value to the world. I’ve never sold it nor earned much of commercial income from this hobby of mine, but my code now helps to power an almost unimaginable amount of devices, machines and other connected things in the world.
I get this award for having worked on curl for a very long time, and by doing this having provided an Internet infrastructure of significant value to the world. I’ve never sold it nor earned much of commercial income from this hobby of mine, but my code now helps to power an almost unimaginable amount of devices, machines and other connected things in the world.
I’m not used to getting noticed or getting awards. I’m used to sitting by myself working on bugs, merging patches and responding to user emails. I don’t expect outsiders to notice what I do much and I always have a hard time to explain to friends and “mortals” what it is I actually do.
I accept this prize, not as a single inventor or brilliant mind of anything, but like the captain of a boat with a large and varying crew without whom I would never have reached this far. I’m excited that the nominee board found me and our merry project and that they were open-minded enough to see and realize the value and position of an open source project that is used literally everywhere. I feel deeply honored.
I’m fascinated the award nominee group found me and I think it is super cool that an open source project gets this attention and acknowledgement.
Apart from the honor, the prize comes in form of a monetary part (250K SEK, about 31,000 USD) and a gold medal with Polhem’s image on. See this blog post’s featured image. The official award ceremony will take place in a few days at the Technical Museum in Stockholm. I’m then supposed to get the medal handed to me by his royal highness Carl XVI Gustav , the king of Sweden. An honor very few people get to experience. Especially very few open source hackers.
Thank you
While I have so many people to thank for having contributed to my (and curl’s) success, there are some that have been fundamental.
I’d like to specifically highlight my wife Anja and my kids Agnes and Rex who are the ones I routinely steal time away from to instead spend on curl. They’re the ones who I drift away from when I respond to issues on the phones or run off to the computer to “just respond to something quickly”. They’re the best.
I’d like to thank Björn, my brother, who chipped in half the amount of money for that first Commodore 64 we purchased back in 1985 and which was the first stepping stone to me being here.
I’d like to thank all my friends and team mates in the curl project without whom curl would’ve died as an infant already in the 1990s. It is with honest communication, hard work and good will that good software is crafted. (Well, there might be some more components necessary too, but let’s keep it simple here.)
I’d like to thank everyone who ever said thanks to me for curl and told me that what I did or brought to the world actually made a difference or served a purpose. Positive feedback is what drives me. It is the fuel that keeps me going.
How will this award affect me and the curl project going forward?
I hope the award will strengthen my spine even more in knowing that we’re going down the right path here. Not necessarily with every single decision or choice we do, but the general one: we do things open source, we do things together and we work long-term.
I hope the award puts a little more light and attention on the world of open source and how this development model can produce the most stellar and robust software components you can think of – without a “best before” stamp.
I would like the award to make one or two more people find and take a closer look at the curl project. To dive in and contribute, in one way or another. We always need more eyes and hands!
Further, I realize that this award might bring some additional eyes on me who will watch how I act and behave. I intend to keep trying to do the right thing and act properly in every situation and I know my friends and community will help me stand straight – no matter how the winds blow.
What will I do with the money?
I intend to take my family with me on an extended vacation trip to New Zealand!
Hopefully there will be some money left afterward, that I hope to at least in part spend on curl related activities such as birthday cakes on the pending curl 20th birthday celebrations in spring 2018…
But really, how many use curl?
Virtually every smart phone has one or more curl installs. Most modern cars and television sets do as well. Probably just about all Linux servers on the Internet run it. Almost all PHP sites on the Internet do. Portable devices and internet-connected machines use it extensively. curl sends crash-reports when your Chrome or Firefox browser fail. It is the underlying data transfer engine for countless systems, languages, programs, games and environments.
Every single human in the connected world use something that runs curl every day. Probably more than once per day. Most have it installed in devices they carry around with them.
It is installed and runs in tens of billions of instances, as most modern-life rich people have numerous installations in their phones, with their web browsers, in their tablets, their cars, their TVs, their kitchen appliances etc.
Most humans, of course, don’t know this. They use devices and apps that just work and are fine with that. curl is just a little piece in the engines of those systems.
![]()


 Unless the issue is critical, we prefer to schedule a fix and announcement of the issue in association with the pending next release, and as we do releases every 8 weeks like clockwork, that’s never very far away.
Unless the issue is critical, we prefer to schedule a fix and announcement of the issue in association with the pending next release, and as we do releases every 8 weeks like clockwork, that’s never very far away. we should introduce processes, tests and checks to make sure we detect other similar mistakes now and in the future.
we should introduce processes, tests and checks to make sure we detect other similar mistakes now and in the future. Unfortunately we don’t have any bug bounties on our own in the curl project. We simply have no money for that. We actually don’t have money at all for anything.
Unfortunately we don’t have any bug bounties on our own in the curl project. We simply have no money for that. We actually don’t have money at all for anything.


 I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you.
I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you. Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.
Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.

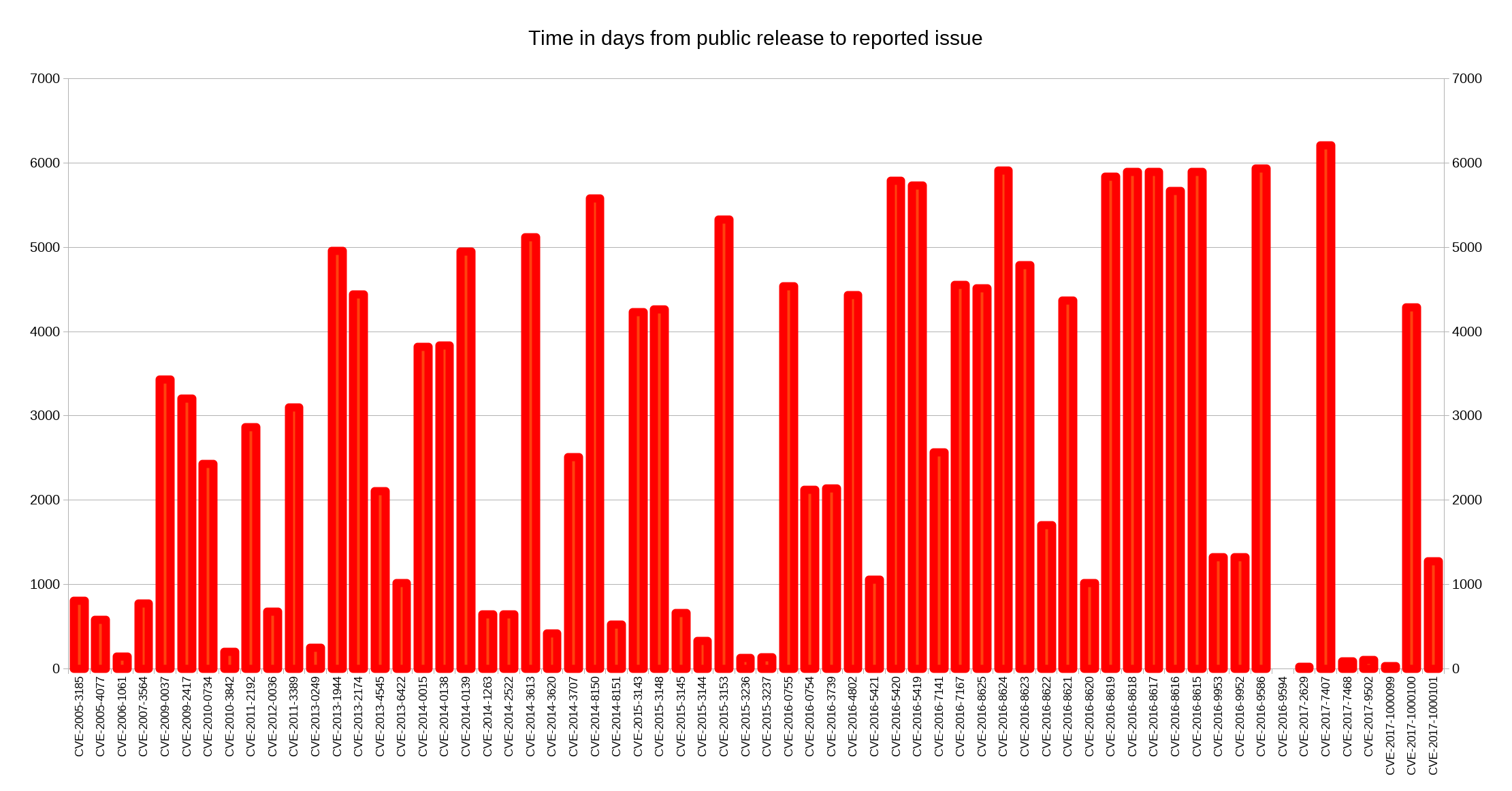
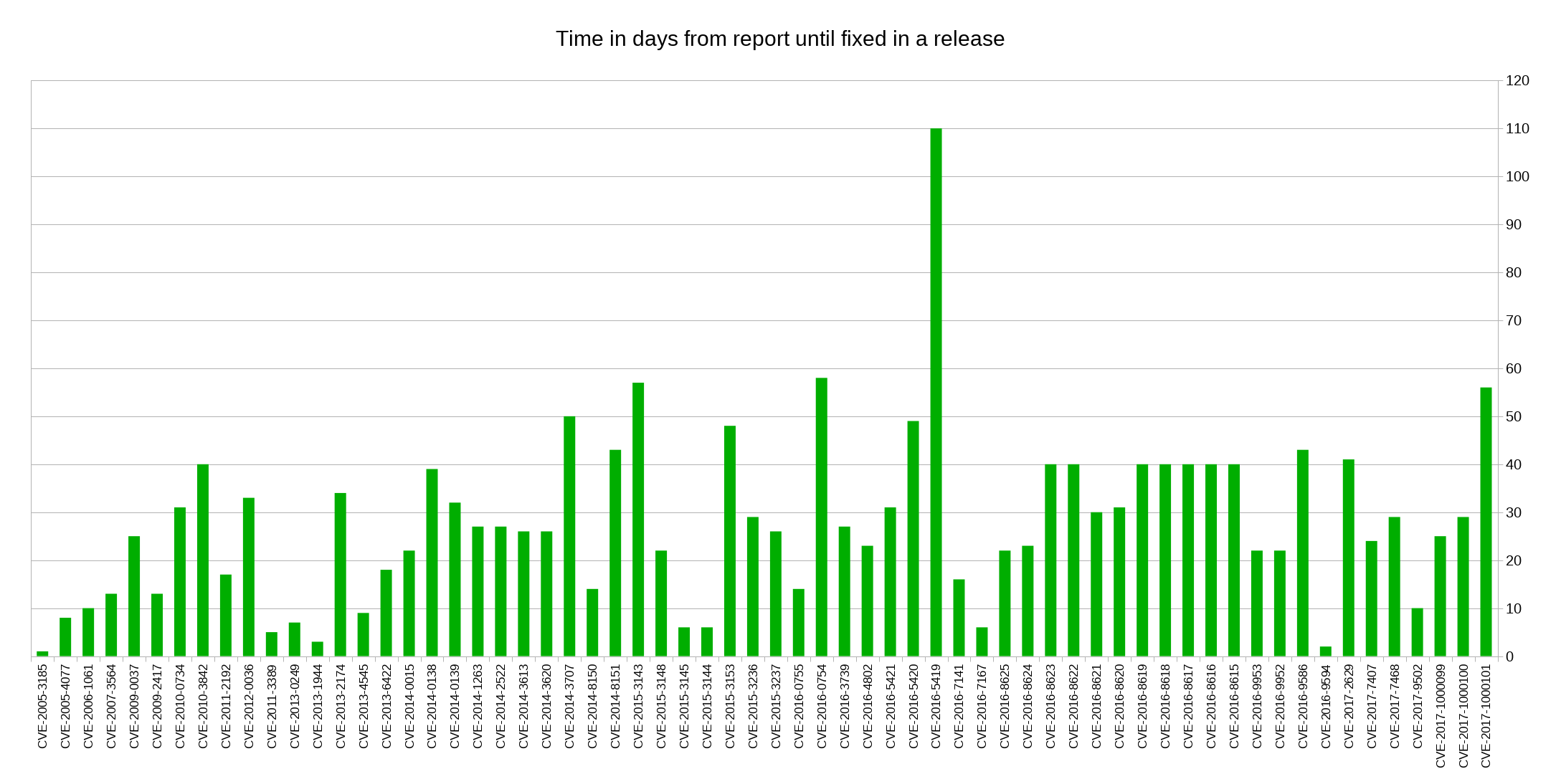
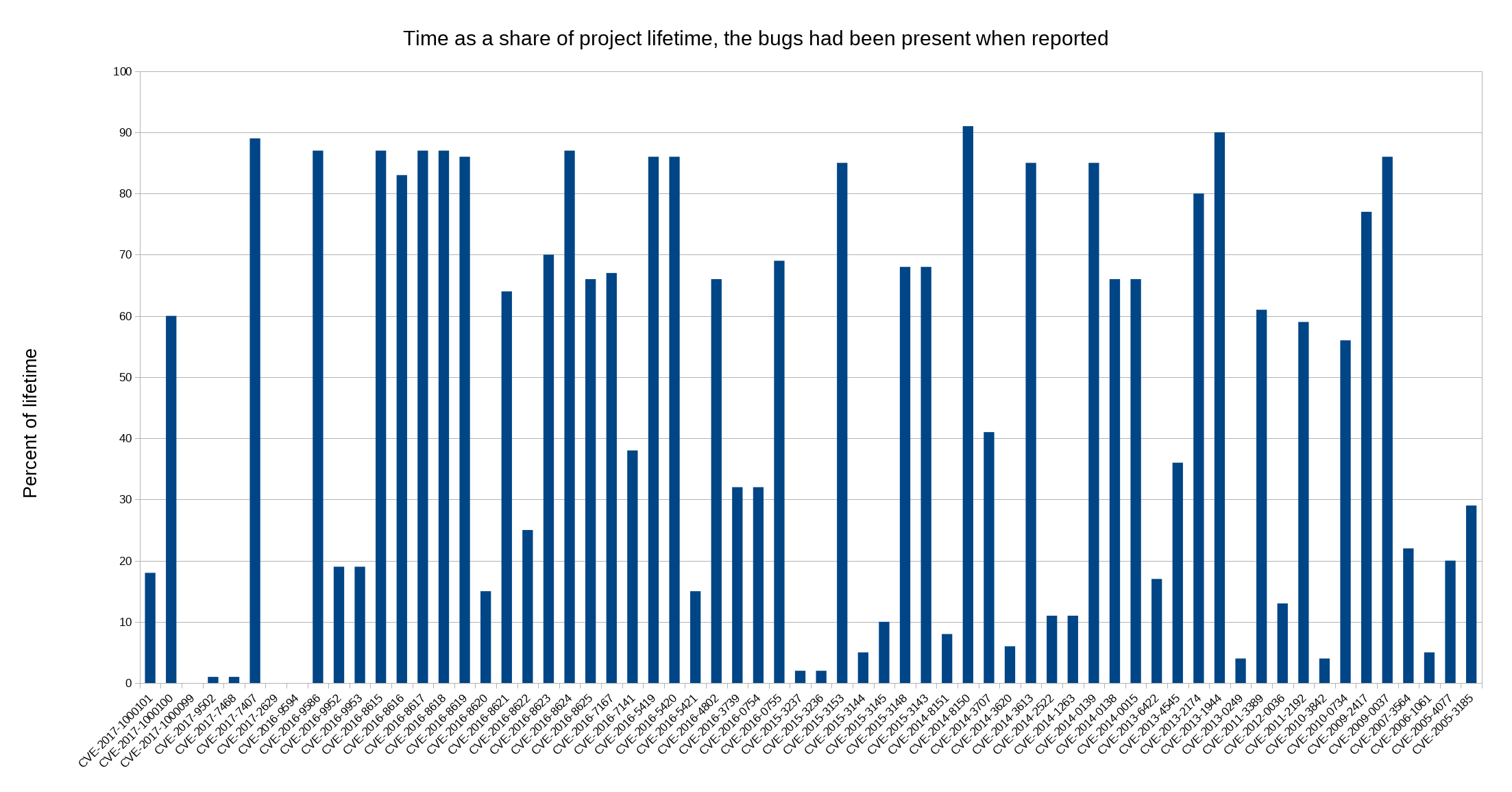
 I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in