tldr: the curl bug-bounty has been an astounding success so far.
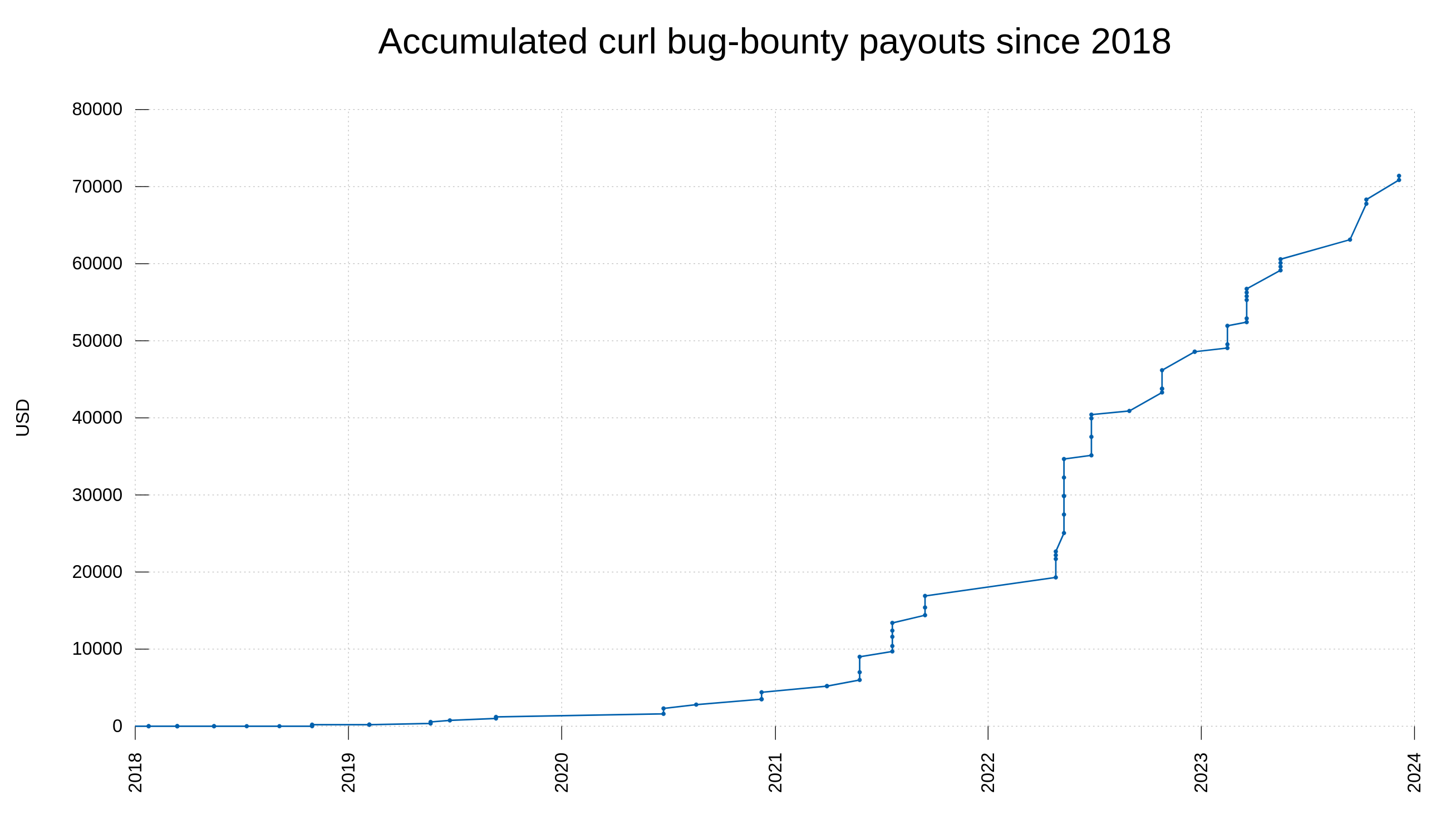
We started the current curl bug-bounty setup in April 2019. We have thus run it for five and a half years give or take.
In the beginning we awarded researchers just a few hundred USD per issue because we did not know where it would go and as we used money from the curl fund (donated money) we wanted to make sure we could afford it.
Since a few years back, the money part of the bug-bounty is sponsored by the Internet Bug Bounty, meaning that the curl project actually earns money for every flaw as we get 20% of the IBB money for each bounty paid.
While the exact award amounts per report vary over time, they are roughly 500 USD for a low severity issue, 2,500 USD for a Medium and almost 5,000 USD for a High severity one.
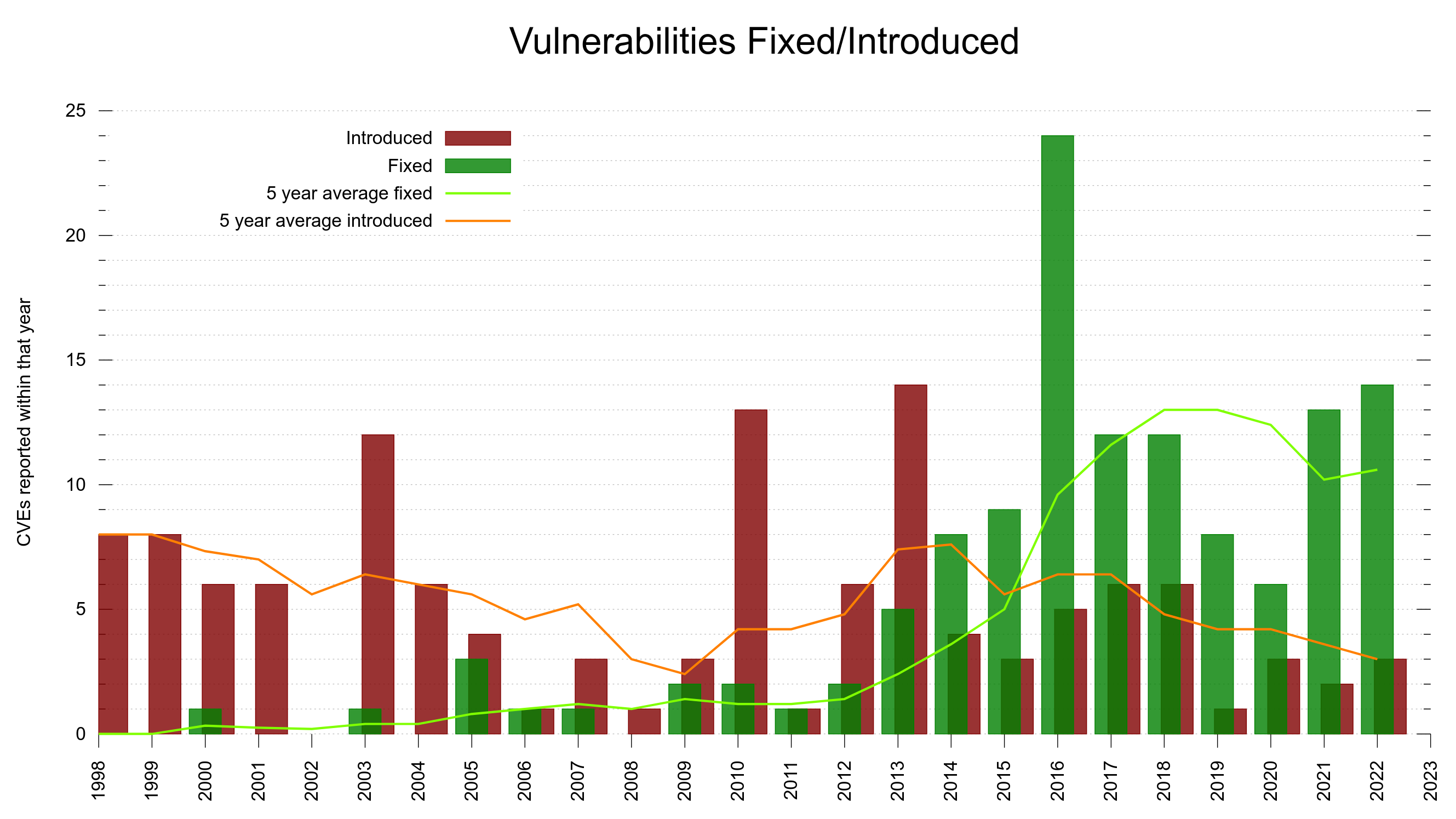
To this day, we have paid out 84,260 USD to security researchers as rewards for their findings, distributed over 69 separate CVEs. 1,220 USD on average.
Counters
In this period we have received 477 reports, which is about 6 per month on average.
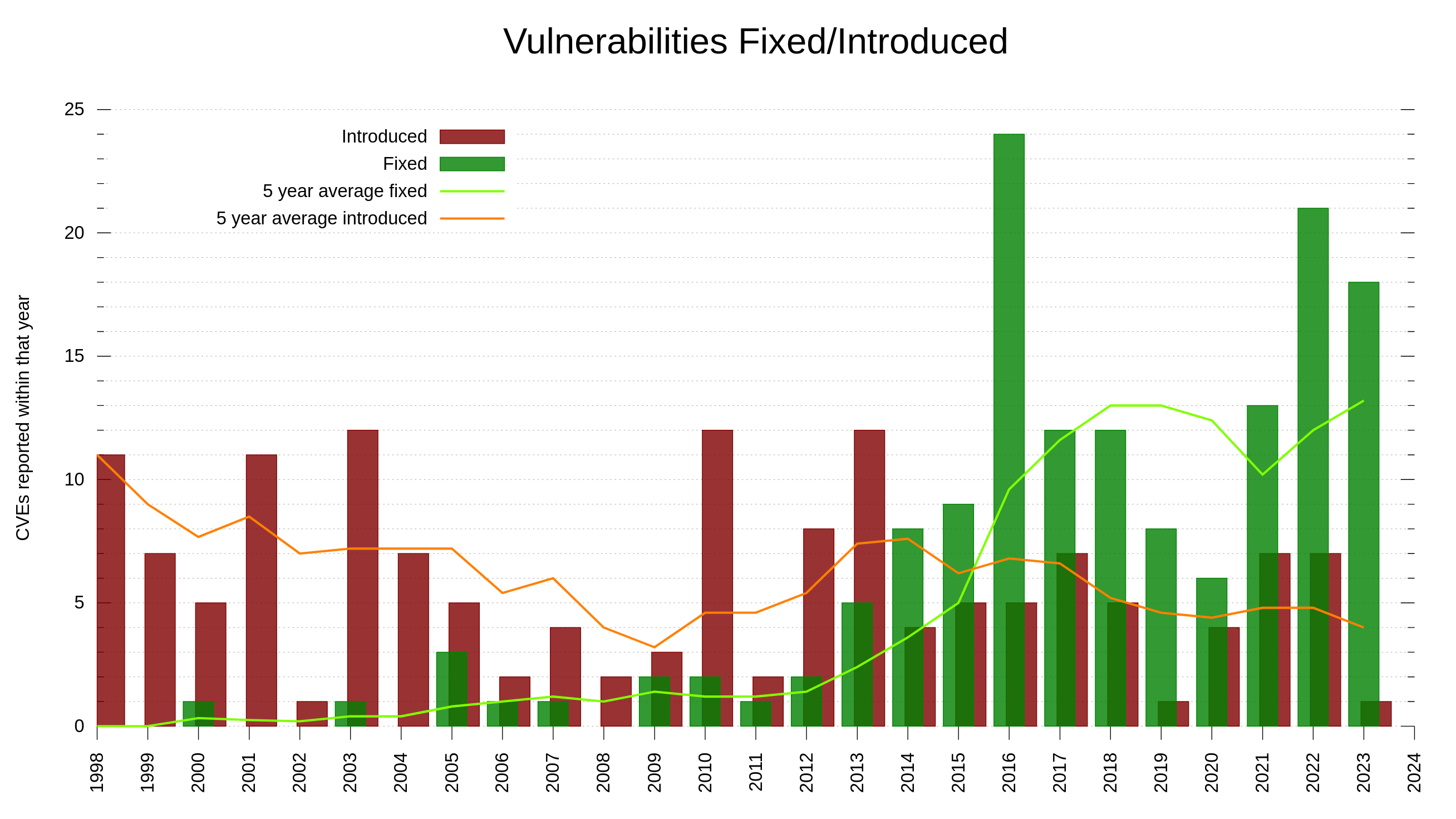
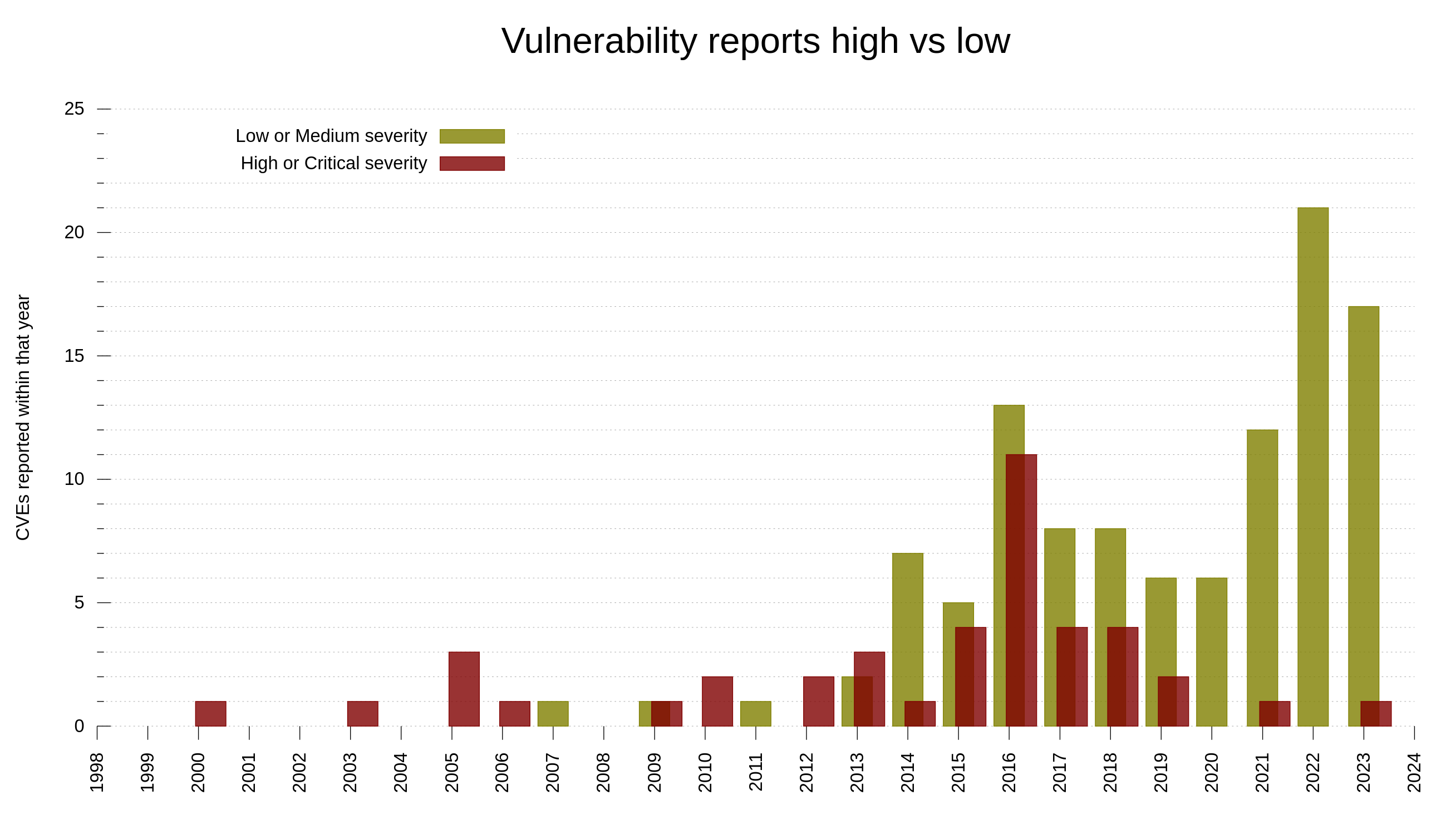
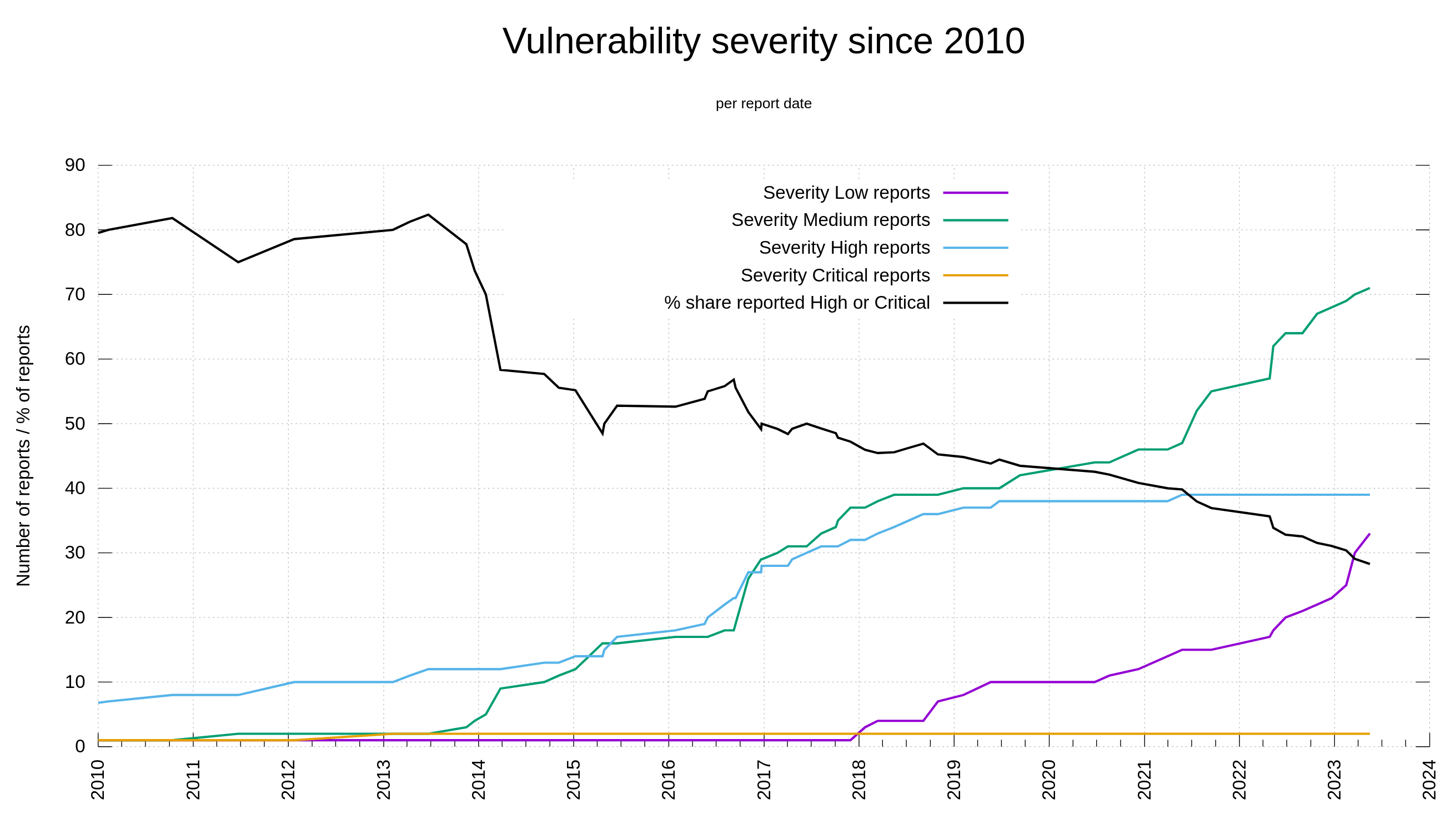
73 of the reports (15.4%) were confirmed and treated as valid security vulnerabilities that ended up CVEs. This also means that we get roughly one valid security report per month on average. Only 3 of these security problems were rated severity High, the rest were Low or Medium. None of them reached the worst level: Critical.
92 of of the reports (19.4%) were confirmed legitimate bugs but not security problems.
311 of the reports (65.3%) were Not Applicable. They were not bugs and not security problems. See below for more on this category.
1 of the reports is still being assessed as I write this.
Tightening the screws
Security is top priority for us but we also continue to develop curl at a high pace. We merge code into the repository at a frequency of more than four bugfixes per day on average over the last couple of years. When we tighten the screws in this project in order to avoid future problems and to mitigate the risks that we add new ones, we need to do it using policies and concepts that still allow us to move fast and be agile.
First response
We have an ambition to always have a first response posted within 24 hours. Over these first 477 reports, we have had a medium response time on under one hour and we have never missed our 24 hour goal. I am personally a little amazed by this feat.
Time to triage
The medium time from filed report until the curl security team has determined and concluded with some confidence that the problem is a security problem is 36 hours.
Assessing
Assessing a (good) report is hard and usually involves a lot of work: reading up on protocols details, reading code, trying different reproducer builds/scripts and bouncing back and forth with the reporters and the security team.
Acknowledging that it is a security problem is only one step. The adjacent one that is at least equally difficult is to then figuring out the severity. How serious is this flaw? A normal pattern is of course that the researcher considers the problem to be several degrees worse than the curl security team does so it can take a great deal of reasoning to reach an agreement. Sometimes we even decree a certain severity against the will of the researcher.
The team
There is a curl security team that works on and with security reports. The awesome people in this group are:
Max Dymond, Dan Fandrich, Daniel Gustafsson, James Fuller, Viktor Szakats, Stefan Eissing and myself.
They are all long-time curl maintainers. Knowledgeable, skilled, trusted.
Report quality
65.3% of the incoming reports are deemed not even a bug.
These reports can be all sorts of different things of course. When promising people money for their reports, there is no surprise that we get a fair share of luck-seekers trying to earn a few bucks the easy route.
Some reporters run scanners against the code, the mail server or the curl website and insist some findings are bounty worthy. The curl bug-bounty does not cover infrastructure, only the products, so they are not covered no matter what.
A surprisingly large amount of the bad reports are on various kinds of “information exposure” on the website – which is often ironic since the entire website already is available in a public git repository and the information exposed is hardly secret.
Reporting scanner results on code without applying your own thinking and confirming that the findings are indeed correct – and actual security problems – is rarely a good idea. That also goes for when asking AIs for finding problems.
Dismissing
Typically, the worse the report is, the quicker it is to dismiss. That is also why having this large share of rubbish is usually not a problem: we normally get rid of them with just a few minutes work spent.
The better crap we get, the worse the problem gets. An AI or a person that writes a long and good-looking report arguing for their sake can take a long time to analyze, asses and eventually debunk.
Since security problems are top priority in the project, getting too much good crap can to some degree cause a denial of service in the project as we need to halt other activities while we take care of the incoming reports.
We run our bug-bounty program on Hackerone, which has a reputation system for reporters. When we close reports as N/A, they get a reputation cut. This works as a mild deterrence for submitting low quality reports. Of course it also sometimes gives the reporter a reason to argue with us and insist we should rather close it as informative which does not come with a reputation penalty.
The good findings
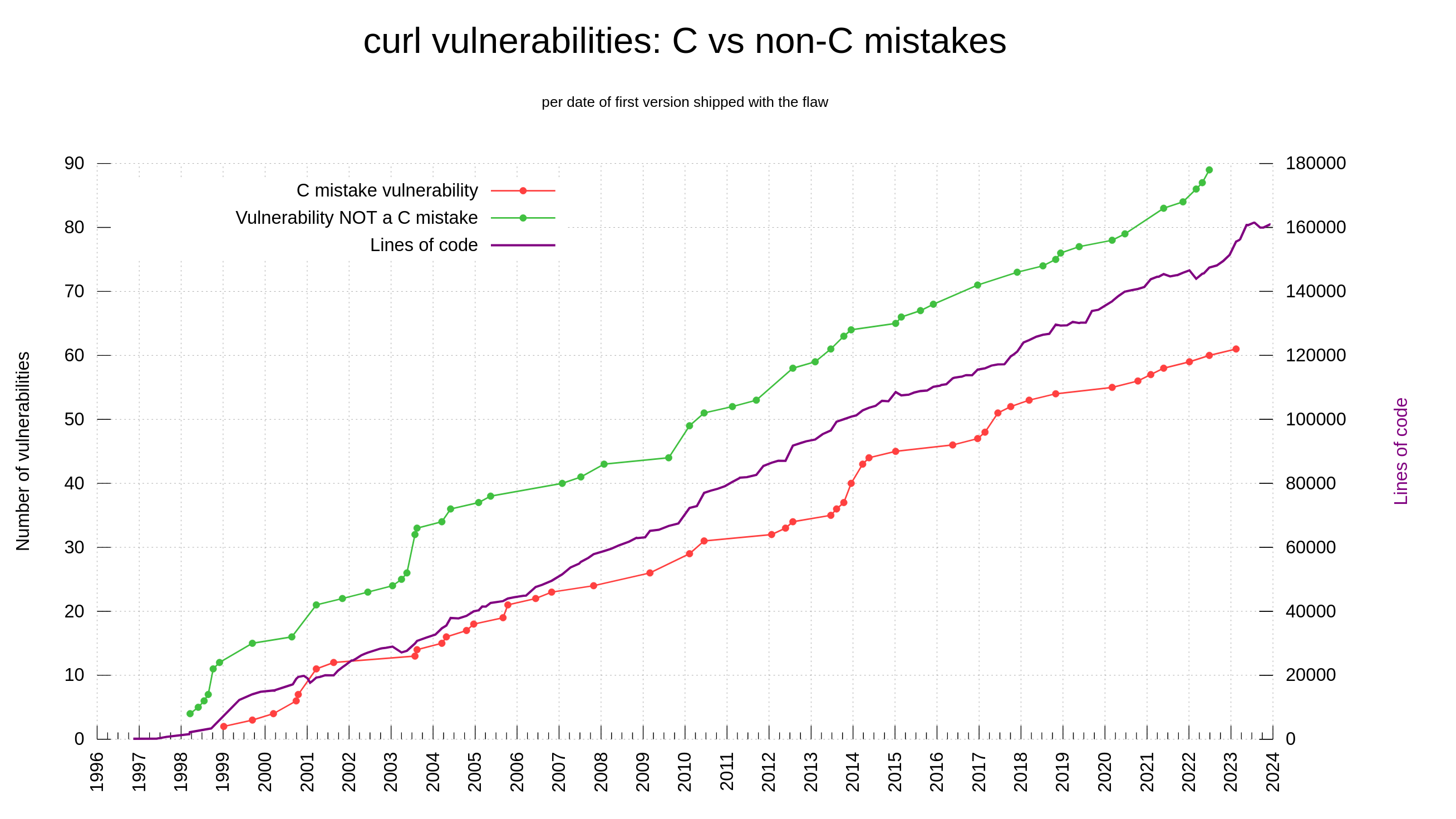
I would claim that it is pretty hard to find a security problem in curl these days, but since we still average in maybe twelve per year recently they certainly still exist.
The valid reports today tend to happen because either a user accidentally did something that made them look, research and unveil something troublesome, or in the more common case: they have put in some real effort into research.
In the latter cases, we see researchers run their own custom fuzzers on parts of the code that our own fuzzers have not exercised as well, we see them check for code patterns that have led to problems before or in other projects and we also see researchers get inspiration by previous reports and fixes to see if perhaps there were gaps left.
The best curl security problem finders today understand the underlying involved protocols, the curl architecture, the source code and they look for inconsistencies between them all, as such might cause security problems.
Bounty hunters
The 69 bug bounty payouts so far have been done to 27 separate individuals. Five reporters have been rewarded for more than two issues each. The true curl security researcher heroes:
| Reports | Name | Rewarded |
| 25 | Harry Sintonen | 29,620 USD |
| 8 | Hiroki Kurosawa | 9,800 USD |
| 4 | Axel Chong | 7,680 USD |
| 4 | Patrick Monnerat | 7,300 USD |
| 3 | z2_ | 4,080 USD |
We are extremely fortunate to have this skilled set of people tracking down and highlighting our worst mistakes.
Harry of course sticks out in the top with his 25 rewarded curl security reports. More than three times the amount the number two has.
(Before you think the math is wrong: a few reports have been filed that ended up as valid CVEs but for which the reporters have declined getting a monetary reward.)
My advice
I think the curl bug-bounty is an absolute and undisputed success. I believe it is a key part in our mission to keep our users safe and secure.
If you consider kicking off a bug-bounty for your project here’s my little checklist:
- Do your software engineering proper. Run all the tools, tests, checks, analyzers, scanners, fuzzers you can and make sure they are at zero reported defects. To avoid a raging herd of reports when you open the gates.
- Start out with conservative bounty amounts to get a lay of the land, then raise them as you go.
- Own all security problems for your project. Whoever reports them and however they appear, you assess, evaluate, research and fix them. You write and publish the complete and original security advisory.
- Make sure you have a team. Even the best maintainers need sleep and occasional vacation days. Security is hard and having good people around to bounce problems with is priceless.
- Close/reject crap reports as quickly as possible to prevent them from wasting team time and energy.
- Always fix security problems with haste. Never let them linger around.
- Transparency. Make as much as possible open and public once the CVEs are out, so that your processes, communications, methods are visible. This builds trust and allows for feedback and iterative improvements of the process.
Future
I think we will continue to receive valid security reports going forward, simply because we keep developing at a high pace and we change and add a lot of source code every year.
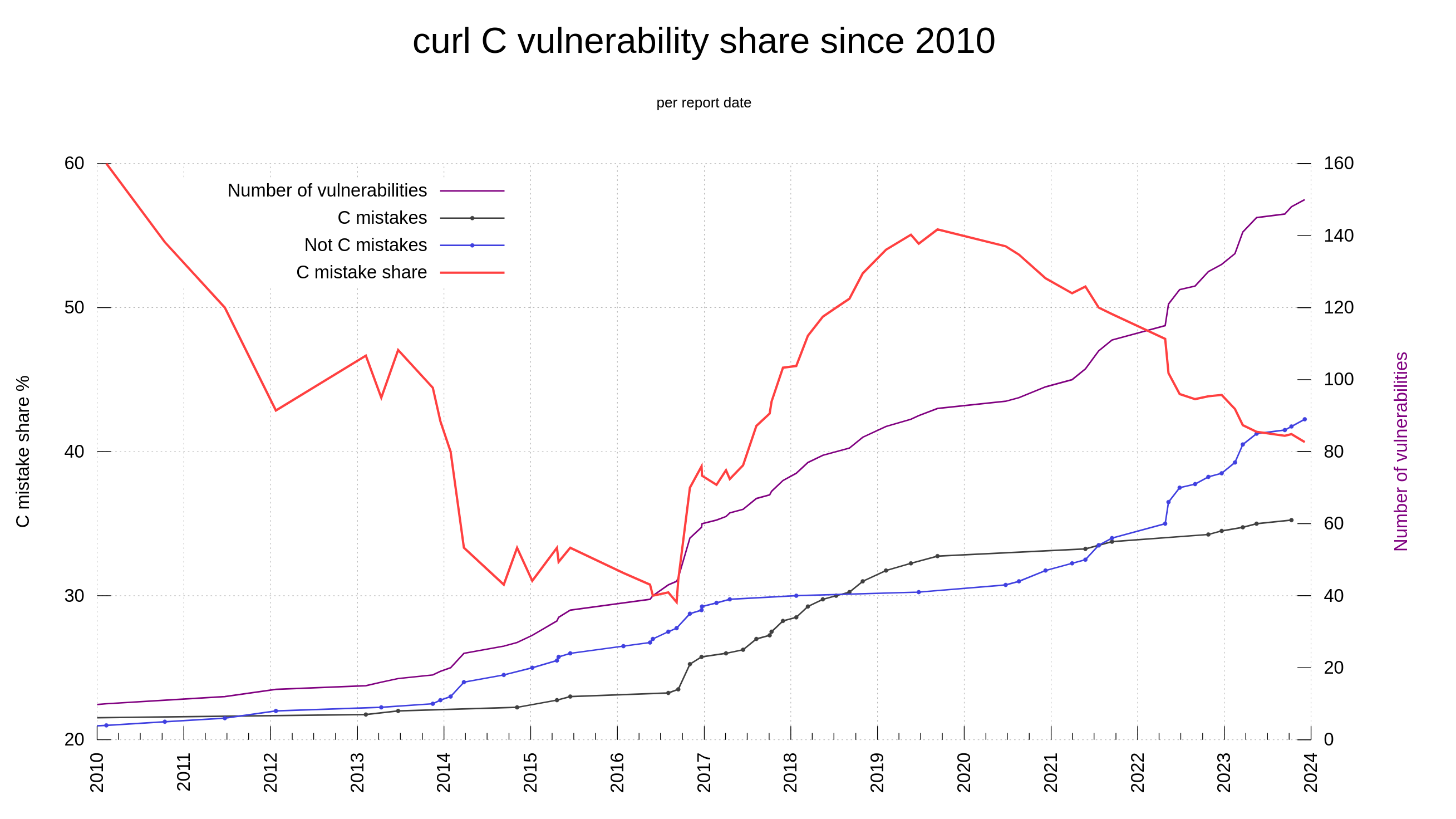
The trend in recent years have been more security reports, but the ratio of low/medium vs high/critical has sky-rocketed. The issues reported these days tend to be less sever than they were in the past.
My explanation for this is primarily that we have more people looking harder for problems now than in the past. Due to mitigations and past reports we introduce really bad security problems at a lower frequency than before.