Recently I have received curious questions from users, customers and bystanders.
Can you explain the seemingly increased CVE activity in curl over like the last year or so?
(data and stats for this post comes mostly from the curl dashboard)
Frequency
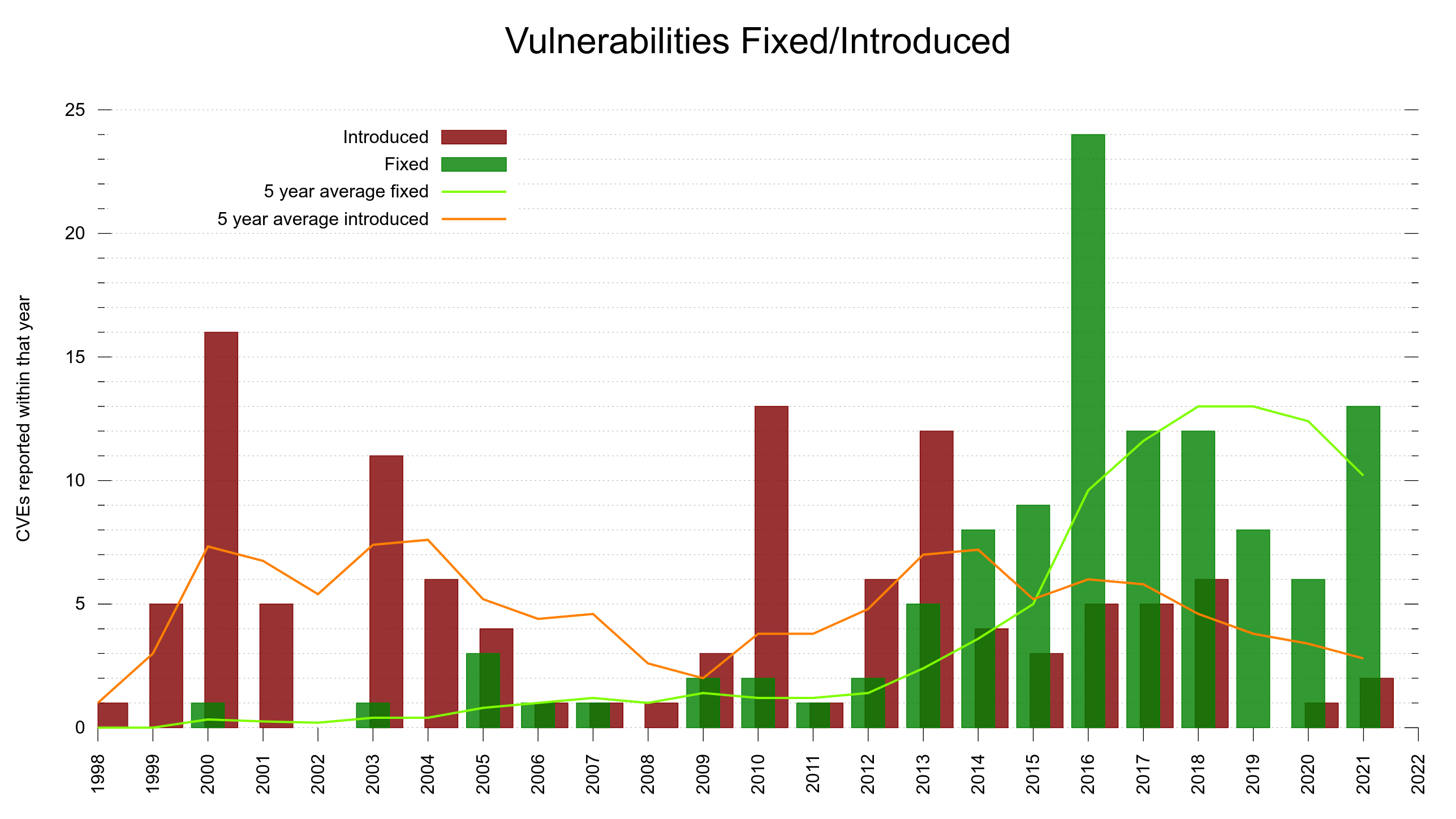
In 2022 we have already had 14 CVEs reported so far, and we will announce the 15th when we release curl 7.85.0 at the end of August. Going into September 2022, there have been a total of 18 reported CVEs in the last 12 months.
During the whole of 2021 we had 13 CVEs reported – and already that was a large amount and the most CVEs in a single year since 2016.
There has clearly been an increased CVE issue rate in curl as of late.
Finding and fixing problems is good
While every reported security problem stings my ego and makes my soul hurt since it was yet another mistake I feel I should have found or not made in the first place, the key take away is still that it is good that they are found and reported so that they can be fixed properly. Ideally, we also learn something from each such report and make it less likely that we ever introduce that (kind of) problem again.
That might be the absolutely hardest task around each CVE. To figure out what went wrong, detect a pattern and then lock it down. It’s almost amusing how all bugs look a like a one-off mistake with nothing to learn from…
Ironically, the only way we know people are looking really hard at curl security is when someone reports security problems. If there was no reports at all, can we really be sure that people are scrutinizing the code the way we want?
Who is counting?
Counting the amount of CVEs and giving that a meaning, or even comparing the number between projects, is futile and a bad idea. The number does not say much and comparing two projects this way is impossible and will not tell you anything. Every project is unique.
Just counting CVEs disregards the fact that they all have severity levels. Are they a dozen “severity low” or are they a handful of critical ones? Even if you take severity into account, they might have gotten entirely different severity for virtually the same error, or vice versa.
Further, some projects attract more scrutinize and investigation because they are considered more worthwhile targets. Or perhaps they just pay researchers more for their findings. Projects that don’t get the same amount of focus will naturally get fewer security problems reported for them, which does not necessarily mean that they have fewer problems.
Incentives
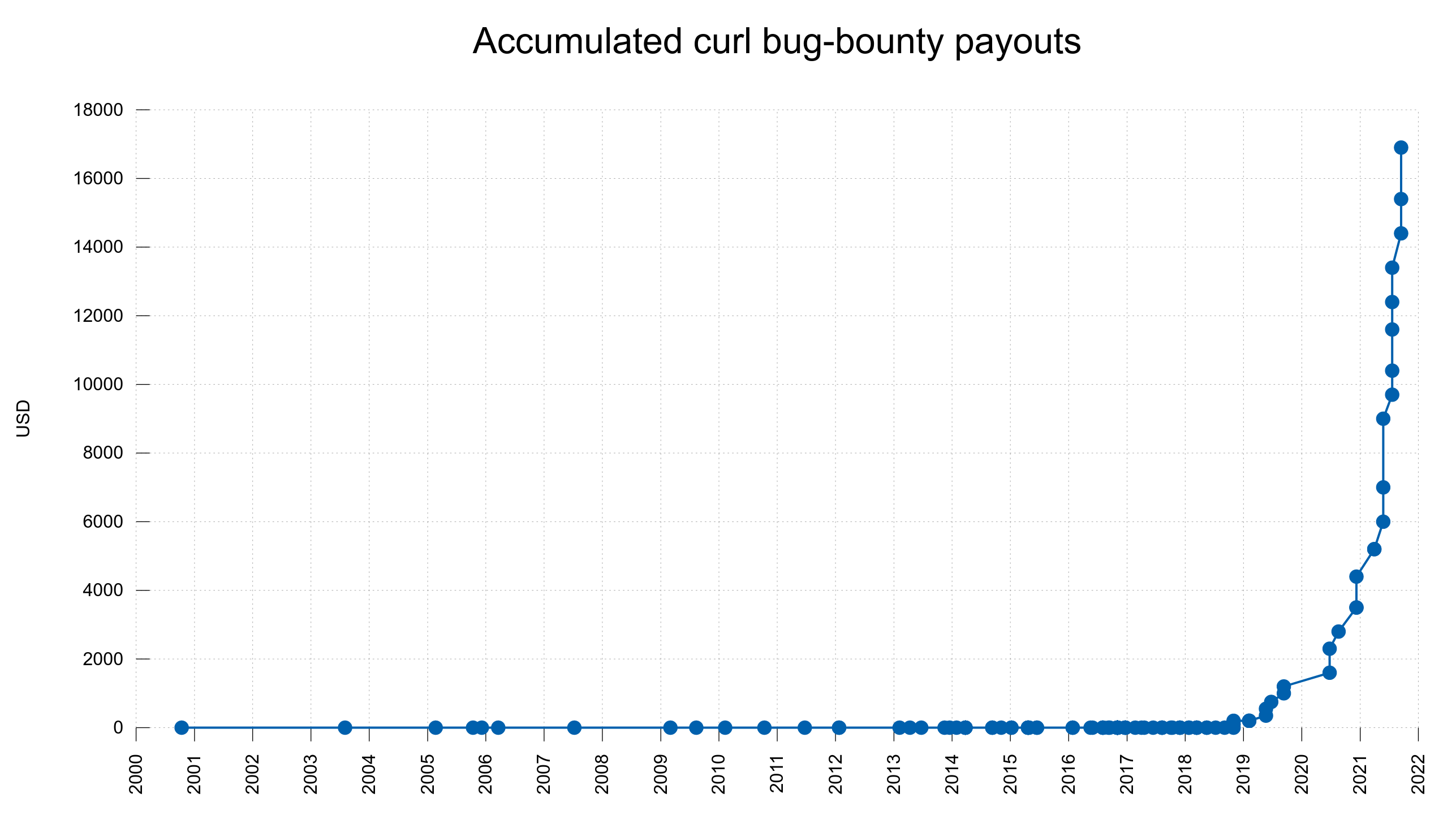
The curl bug-bounty really works as an incentive as we do reward security researchers a sizable amount of money for every confirmed security flaw they report. Recently, we have handed over 2,400 USD for each Medium-severity security problem.
In addition to that, finding and getting credited for finding a flaw in a widespread product such as curl is also seen as an extra “feather in the hat” for a lot of security-minded bug hunters.
Over the last year alone, we have paid about 30,000 USD in bug bounty rewards to security researchers, summing up a total of over 40,000 USD since the program started.

Who’s looking?
We have been fortunate to have received the attention of some very skilled, patient and knowledgeable individuals. To find security problems in modern curl, the best bug hunters both know the ins and outs of the curl project source code itself while at the same time they know the protocols curl speaks to a deep level. That’s how you can find mismatches that shouldn’t be there and that could lead to security problems.
The 15 reports we have received in 2022 so far (including the pending one) have been reported by just four individuals. Two of them did one each, the other two did 87% of the reporting. Harry Sintonen alone reported 60% of them.
Hardly any curl security problems are found with source code analyzers or even fuzzers these days. Those low hanging fruits have already been picked.
We care, we act
Our average response time for security reports sent to the curl project has been less than two hours during 2022, for the 56 reports received so far.
We give each report a thorough investigation and we spend a serious amount of time and effort to really make sure we understand all the angles of the claim, that it really is a security problem, that we produce the best possible fix for it and not the least: that we produce a mighty fine advisory for the issue that explains it to the world with detail and accuracy.
Less than 8% of the submissions we get are eventually confirmed actual security problems.
As a general rule all security problems we confirm, are fixed in the pending next release. The only acceptable exception would be if the report arrives just a day or two from the next release date.
We work hard to make curl more secure and to use more ways of writing secure code and tools to detect mistakes than ever, to minimize the risk for introducing security flaws.
Judge a project on how it acts
Since you cannot judge a project by the number of CVEs that come out of it, what you should instead pay more focus on when you assess the health of a software project is how it acts when security problems are reported.
Most problems are still very old
In the curl project we make a habit of tracing back and figuring out exactly in which release each and every security problem was once introduced. Often the exact commit. (Usually that commit was authored by me, but let’s not linger on that fact now.)
One fun thing this allows us to do, is to see how long time the offending code has been present in releases. The period during which all the eyeballs that presumably glanced over the code missed the fact that there was a security bug in there.
On average, curl security problems have been present an extended period of time before there are found and reported.
On average for all CVEs: 2,867 days
The average time bugs were present for CVEs reported during the last 12 months is a whopping 3,245 days. This is very close to nine years.
How many people read the code in those nine years?
The people who find security bugs do not know nor do they care about the age of a source code line when they dig up the problems. The fact that the bugs are usually old could be an indication that we introduced more security bugs in the past than we do now.
Finding vs introducing
Enough about finding issues for a moment. Let’s talk about introducing security problems. I already mentioned we track down exactly when security flaws were introduced. We know.
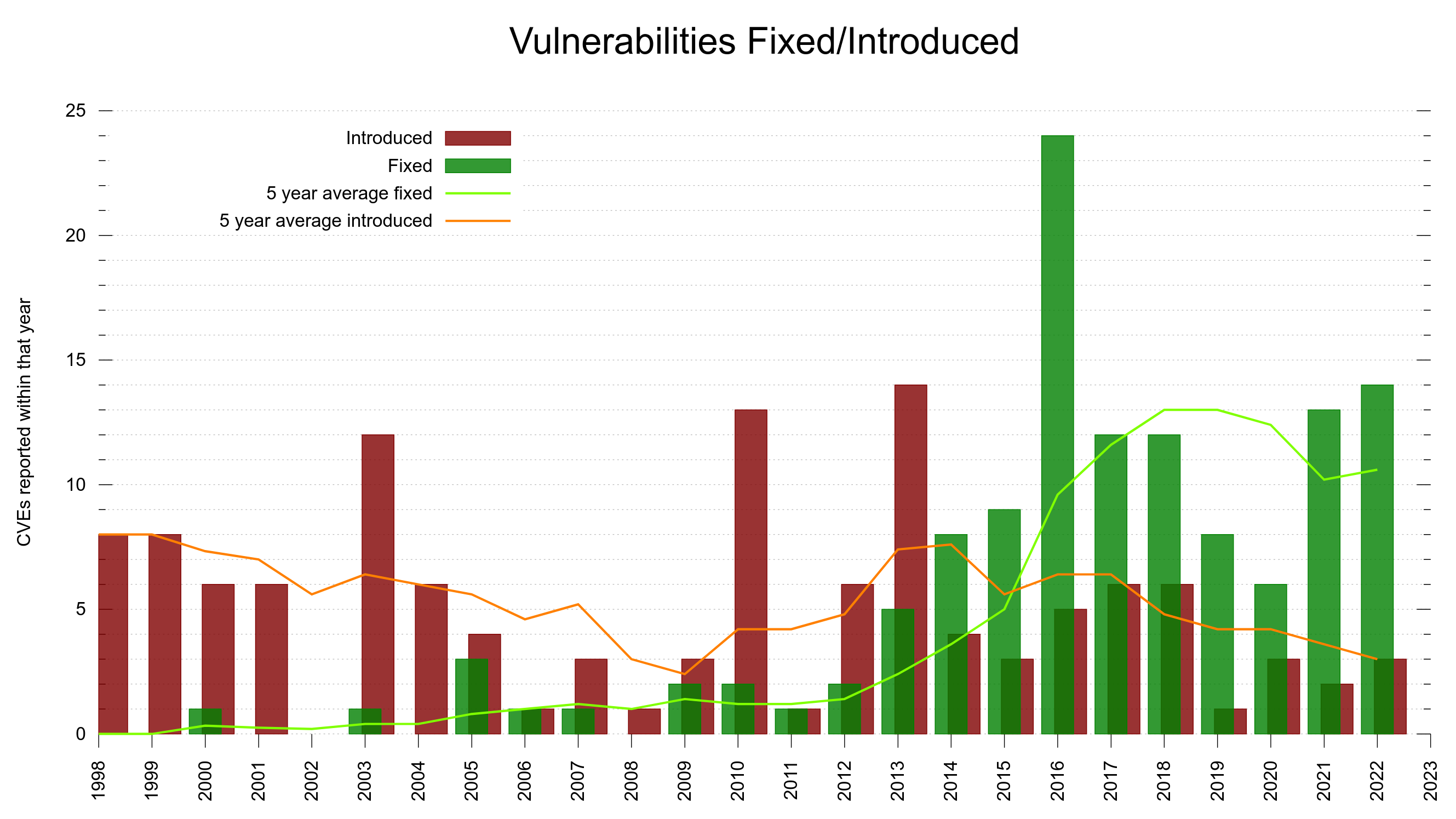
With this, we can look at the trend and see if we are improving over time.
The project has existed for almost 25 years, which means that if we introduce problems spread out evenly over time, we would have added 4% of them every year. About 5 CVE problems are introduced per year on average. So, being above or below 5 introduced makes us above or below an average year.
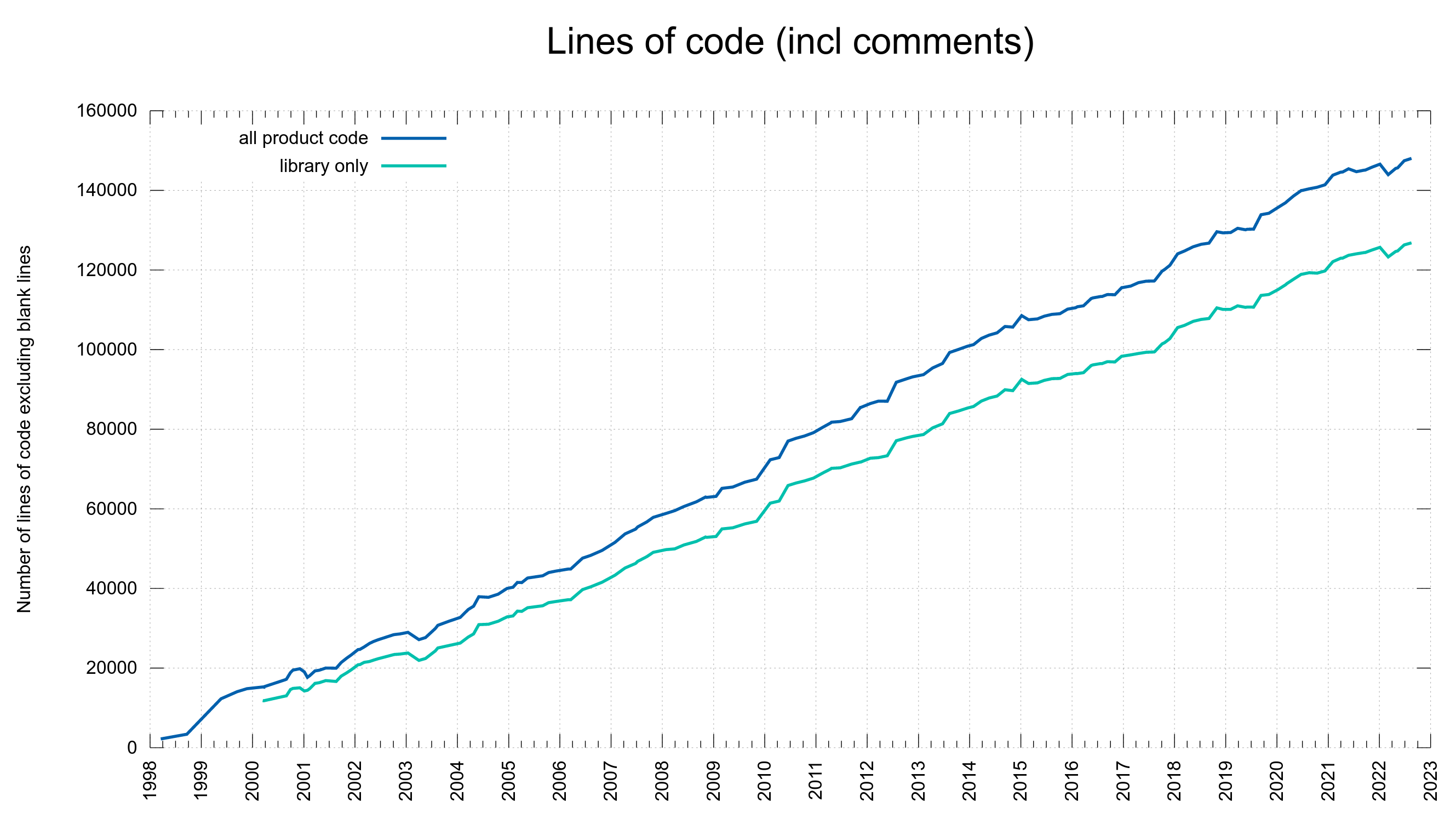
Bugs are probably not introduced as a product of time, but more as a product of number of lines of code or perhaps as a ratio of the commits.
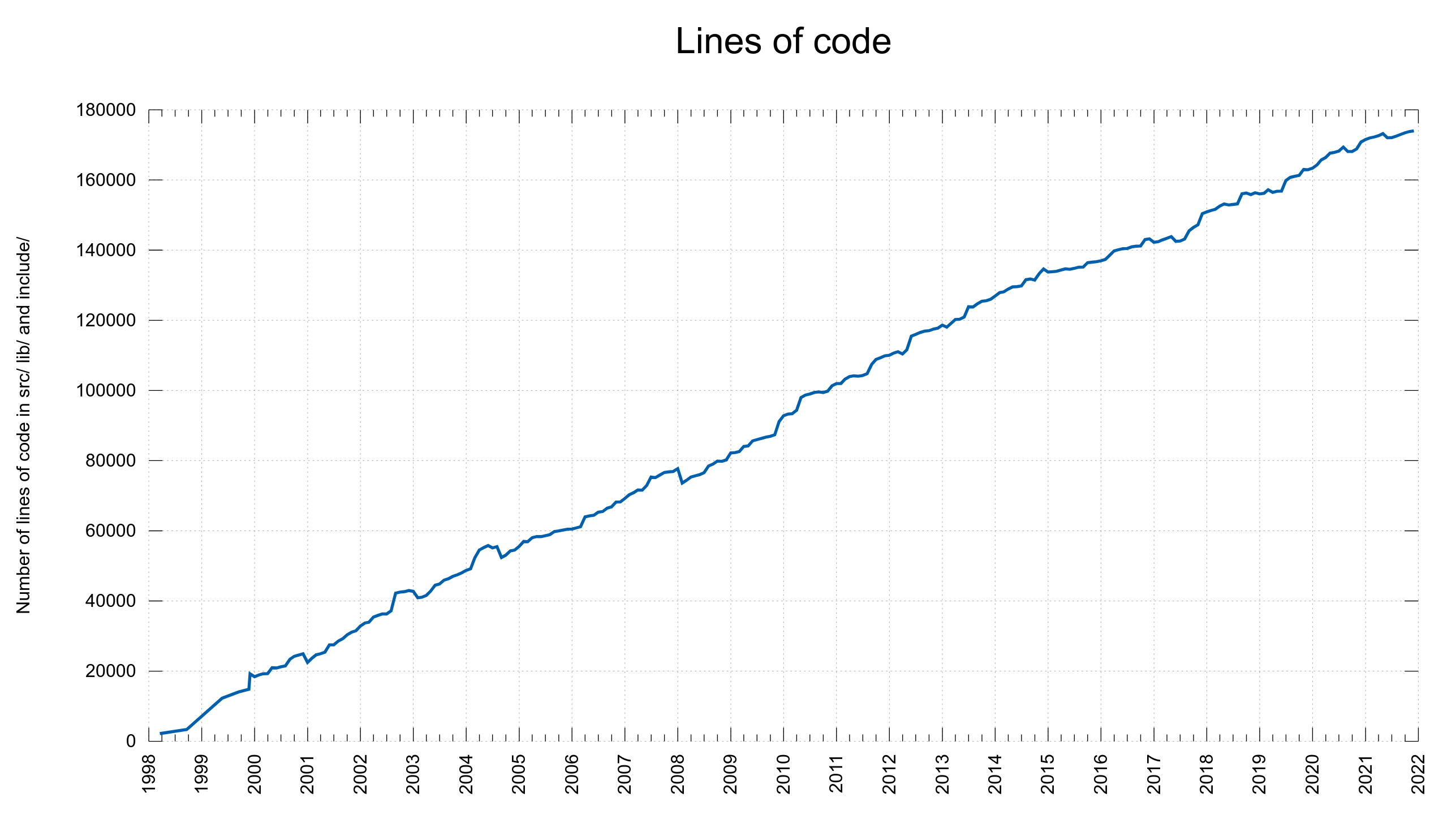
75% of the CVE errors were introduced before March 2014 – and yet the code base “only” had 102,000 lines of code at the end of that period. At that time, we had done 61% of the git commits (17684). One CVE per 189 commits.
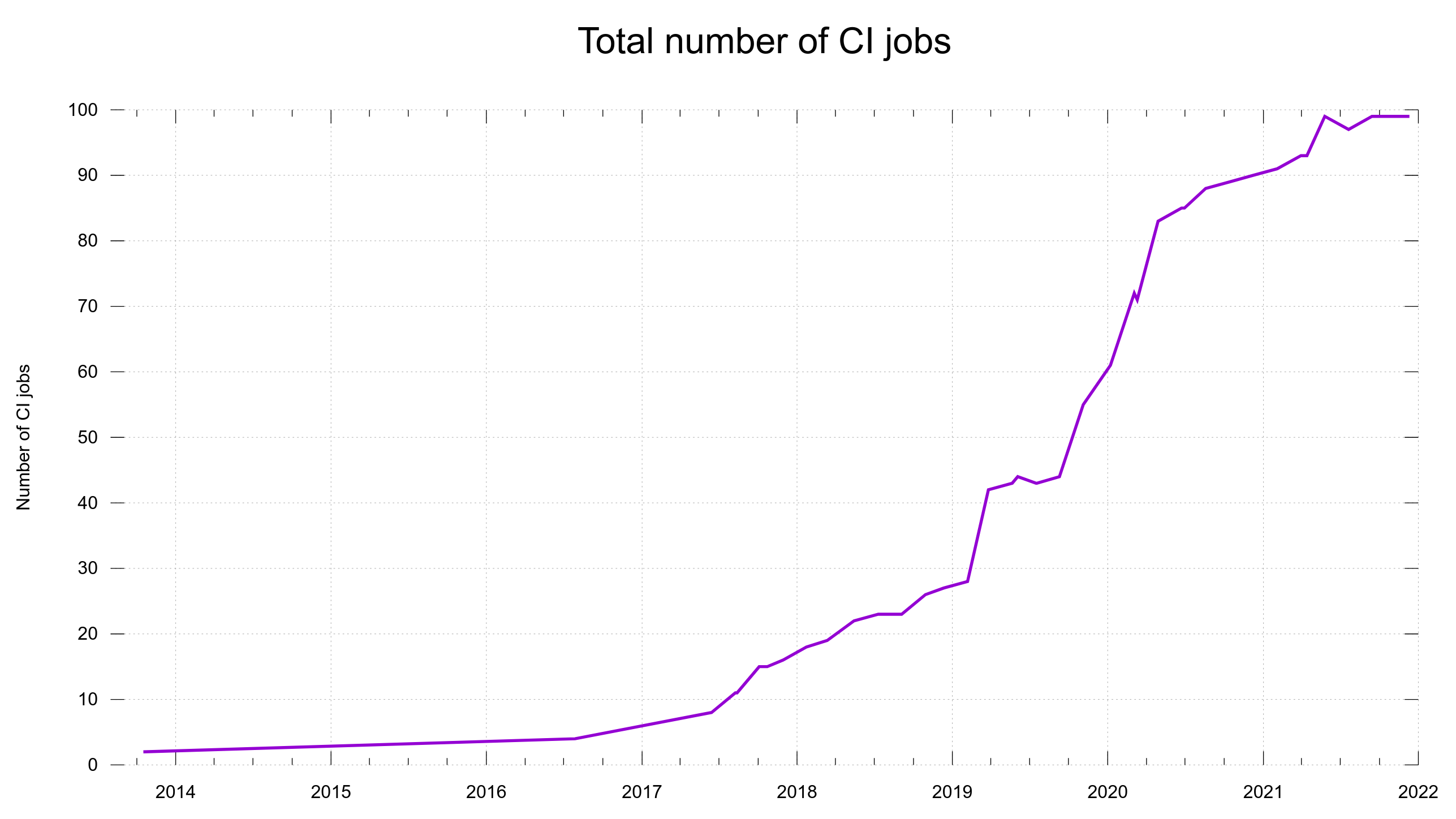
15% of the security problems were introduced during the last five years and now we are at 148,000 lines of code. Finding needles in a growing haystack. With more code than ever before, we introduce bugs at a lower-than average rate. One CVE per 352 commits. This probably is also related to the ever-growing number of tests and CI jobs that help us detect more problems before we merge them.
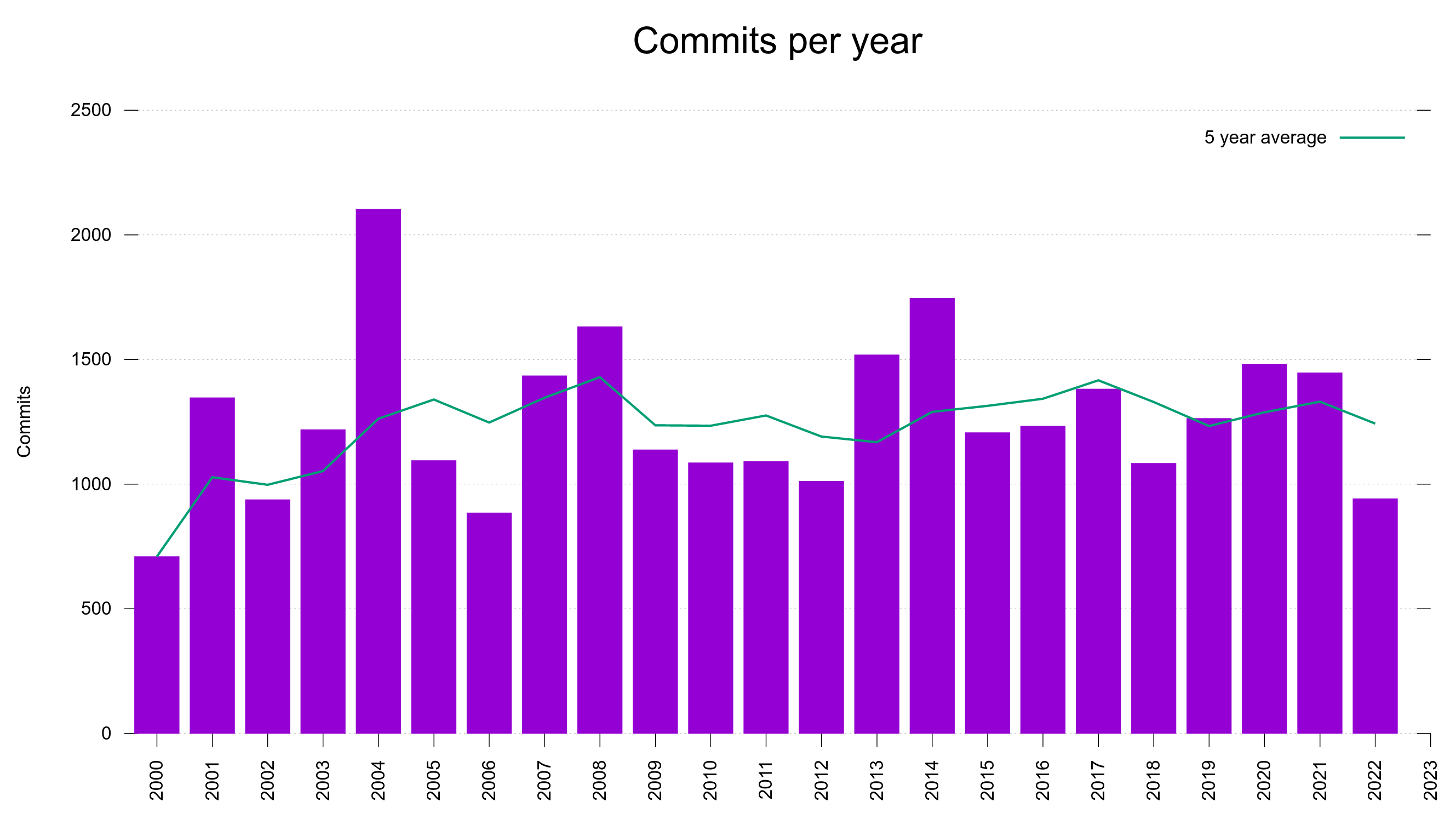
The commit rate has remained between 1,100 and 1,700 commits per year since 2007 with ups and downs but no obvious growing or declining trend.
Harry Sintonen
Harry reported a large amount of the recent curl CVEs as mentioned above, and is credited for a total of 17 reported curl CVEs – no one else is even close to that track record. I figured it is apt to ask him about the curl situation of today, to make sure this is not just me hallucinating things up. What do you think is the reason for the increased number of CVEs in curl in 2022?
Harry replied:
- The news of good bounties being paid likely has been attracting more researchers to look at curl.
- I did put considerable effort in doing code reviews. I’m sure some other people put in a lot of effort too.
- When a certain before unseen type of vulnerability is found, it will attract people to look at the code as a whole for similar or surrounding issues. This quite often results in new, similar CVEs bundling up. This is kind of a clustering effect.
It’s worth mentioning, I think, that even though there has been more CVEs found recently, they have been found (well most of them at least) as part of the bug bounty program and get handled in a controlled manner. While it would be even better to have no vulnerabilities at all, finding and handling them in controlled manner is the 2nd best option.
This might be escaping a random observer who just looks at the recent amount of CVEs and goes “oh this is really bad – something must have gone wrong!”. Some of the issues are rather old and were only found now due to the increased attention.
Conclusion
We introduce CVE problems at a slower rate now than we did in the past even though we have gotten problems reported at a higher than usual frequency recently.
The way I see it, we are good. I suppose the future will tell if I am right.