One day in March 1998 I released a little file transfer tool I called curl. The first ever curl release. That was good.
10
By the end of July the same year, I released the 10th curl release. I’ve always believed in release early release often as a service to users and developers alike.
20
In December 1998 I released the 20th curl release. I started to get a hang of this.
50
In January 2001, not even three years in, we shipped the 50th curl release (version 7.5.2). We were really cramming them out back then!
200
Next week. 23 years, two months and six days after the first release, we will ship the 200th curl release. We call it curl 7.77.0.
Yes, there are exactly 200 stickers used in the photo. But the visual comparison with 50 is also apt: it isn’t that big difference seen from a distance.
I’ve personally done every release to date, but there’s nothing in the curl release procedure that says it has to be me, as long as the uploader has access to put the new packages on the correct server.
The fact that 200 is an HTTP status code that is indicating success is an awesome combination.
Release cadence
In 2014 we formally switched to an eight week release cycle. It was more or less what we already used at the time, but from then on we’ve had it documented and we’ve tried harder to stick to it.
Assuming no alarmingly bad bugs are found, we let 56 days pass until we ship the next release. We occasionally slip up and fail on this goal, and then we usually do a patch release and cut the next cycle short. We never let the cycle go longer than those eight weeks. This makes us typically manage somewhere between 6 and 10 releases per year.
Lessons learned
Make a release checklist, and stick to that when making releases
Update the checklist when needed
Script as much as possible of the procedure
Verify the release tarballs/builds too in CI
People never test your code properly until you actually release
No matter how hard you try, some releases will need quick follow-up patch releases
(This is a repost of a stackoverflow answer I once wrote on this topic. Slightly edited. Copied here to make sure I own and store my own content properly.)
curl knows the HTTP method
You normally use curl without explicitly saying which request method to use.
If you just pass in a HTTP URL like curl http://example.com, curl will use GET. If you use -d or -F curl will use POST, -I will cause a HEAD and -T will make it a PUT.
If for whatever reason you’re not happy with these default choices that curl does for you, you can override those request methods by specifying -X [WHATEVER]. This way you can for example send a DELETE by doing curl -X DELETE [URL].
It is thus pointless to do curl -X GET [URL] as GET would be used anyway. In the same vein it is pointless to do curl -X POST -d data [URL]... But you can make a fun and somewhat rare request that sends a request-body in a GET request with something like curl -X GET -d data [URL].
Digging deeper
curl -GET (using a single dash) is just wrong for this purpose. That’s the equivalent of specifying the -G, -E and -T options and that will do something completely different.
There’s also a curl option called --get to not confuse matters with either. It is the long form of -G, which is used to convert data specified with -d into a GET request instead of a POST.
Modern versions of curl will inform users about this unnecessary and potentially harmful use of -X when verbose mode is enabled (-v) – to make users aware. Further explained and motivated here.
-G converts a POST + body to a GET + query
You can ask curl to convert a set of -d options and instead of sending them in the request body with POST, put them at the end of the URL’s query string and issue a GET, with the use of `-G. Like this:
I’ve worked hard on making the presentation I ended up calling libcurl under the hood. A part of that presentation is spent on explaining the main libcurl transfer state machine and here I’ll try to document some of what, in a written form. Understanding the main transfer state machine in libcurl could be valuable and interesting for anyone who wants to work on libcurl internals and maybe improve it.
Background
The state is kept in easy handle in the struct field called mstate. The source file for this state machine is called multi.c.
An easy handle is always in exactly one of these states for as long as it exists.
This transfer state machine is designed to work for all protocols libcurl supports, but basically no protocol will transition through all states. As you can see in the drawing, there are many different possible transitions from a lot of the states.
libcurl transfer state machine
(click the image for a larger version)
Start
A transfer starts up there above the surface in the INIT state. That’s a yellow box next to the little start button. Basically the boat shows how it goes from INIT to the right over to MSGSENT with it’s finish flag, but the real path is all done under the surface.
The yellow boxes (states) are the ones that exist before or when a connection is setup. The striped background is for all states that has a single and specific connectdata struct associated with the transfer.
CONNECT
If there’s a connection limit, either in total or per host etc, the transfer can get sent to the PENDING state to wait for conditions to change. If not, the state probably moves on to one of the blue ones to resolve host name and connect to the server etc. If a connection could be reused, it can shortcut immediately over to the green DO state.
The green states are all about setting up the connection to a state of fully connected, authenticated and logged in. Ready to send the first request.
DO
The green DO states are all about sending the request with one or more commands so that the file transfer can begin. There are several such states to properly support all protocols but also for historical reasons. We could probably remove a state there by some clever reorgs if we wanted.
PERFORMING
When a request has been issued and the transfer starts, it transitions over to PERFORMING. In the white states data is flowing. Potentially a lot. Potentially in both or either direction. If during the transfer curl finds out that the transfer is faster than allowed, it will move into RATELIMITING until it has cooled down a bit.
DONE
All the post-transfer states are red in the picture. The DONE is the first of them and after having done what it needs to round up the transfer, it disassociates with the connection and moves to COMPLETED. There’s no stripes behind that state. Disassociate here means that the connection is returned back to the connection pool for later reuse, or in the worst case if deemed that it can’t be reused or if the application has instructed it so, closed.
As you’ll note, there’s no disconnect anywhere in the state machine. This is simply because the disconnect is not really a part of the transfer at all.
COMPLETED
This is the end of the road. In this state a message will be created and put in the outgoing queue for the application to read, and then as a final last step it moves over to MSGSENT where nothing more happens.
A typical handle remains in this state until the transfer is reused and restarted, in which it will be set back to the INIT state again and the journey begins again. Possibly with other transfer parameters and URL this time. Or perhaps not.
State machines within each state
What this state diagram and explanation doesn’t show is of course that in each of these states, there can be protocol specific handling and each of those functions might in themselves of course have their own state machines to control what to do and how to handle the protocol details.
Each protocol in libcurl has its own “protocol handler” and most of the protocol specific stuff in libcurl is then done by calls from the generic parts to the protocol specific parts with calls like protocol_handler->proto_connect() that calls the protocol specific connection procedure.
This allows the generic state machine described in this blog post to not really know the protocol specifics and yet all the currently support 26 transfer protocols can be supported.
libcurl under the hood – the video
Here’s the full video of libcurl under the hood.
If you want to skip directly to the state machine diagram and the following explanation, go here.
We had five presentations done, all prerecorded and made available before the event. At the Sunday afternoon we gathered to discuss the presentations and everything around those topics.
We were not very many who actually joined the meeting, and out of the people in the meeting a majority decided to be spectators only and remained muted with their cameras off.
It turned out as a two hour long mostly casual talk among me, Stefan Eissing and Emil Engler about the presentations and related topics. Toward the end, Kamil Dudka appeared.
The three of us get to talk about roadmap items, tests, security, writing code that interfaces modules written in rust and what more details in the libcurl internals that could use further descriptions and documentation.
The video
The agenda in the video is roughly following the agenda order in the 2021 wiki page and the discussion topics mentioned there.
Sponsored
Thanks to wolfSSL for sponsoring the video meeting account used!
“Memes” or other fun images involving curl. Please send or direct me to other ones you think belong in this collection! Kept here solely to boost my ego.
All modern digital infrastructure
This is the famous xkcd strip number 2347, modified to say Sweden and 1997 by @tsjost. I’ve seen this picture taking some “extra rounds” in various places, somehow also being claimed to be xkcd 2347 when people haven’t paid attention to the “patch” in the text.
This image originally comes from cowbirdsinlove.com but sadly it seems the page that once showed it is no longer there. I saved it from that site already back in 2015, but I cannot recall the exact URL it used. The image is still available at https://cowbirdsinlove.com/comics/base10[1].png.
Since I consider this picture such an iconic classic and masterpiece, I decided I better host it here in a small attempt to preserve it for everyone to enjoy.
In the curl project we make great efforts to store a lot of meta data about each and every vulnerability that we have fixed over the years – and curl is over 23 years old. This data set includes CVE id, first vulnerable version, last vulnerable version, name, announce date, report to the project date, CWE, reward amount, code area and “C mistake kind”.
We also keep detailed data about releases, making it easy to look up for example release dates for specific versions.
Dashboard
All this, combined with my fascination (some would call it obsession) of graphs is what pushed me into creating the curl project dashboard, with an ever-growing number of daily updated graphs showing various data about the curl projects in visual ways. (All scripts for that are of course also freely available.)
What to show is interesting but of course it is sometimes even more important how to show particular data. I don’t want the graphs just to show off the project. I want the graphs to help us view the data and make it possible for us to draw conclusions based on what the data tells us.
Vulnerabilities
The worst bugs possible in a project are the ones that are found to be security vulnerabilities. Those are the kind we want to work really hard to never introduce – but we basically cannot reach that point. This special status makes us focus a lot on these particular flaws and we of course treat them special.
For a while we’ve had two particular vulnerability graphs in the dashboard. One showed the number of fixed issues over time and another one showed how long each reported vulnerability had existed in released source code until a fix for it shipped.
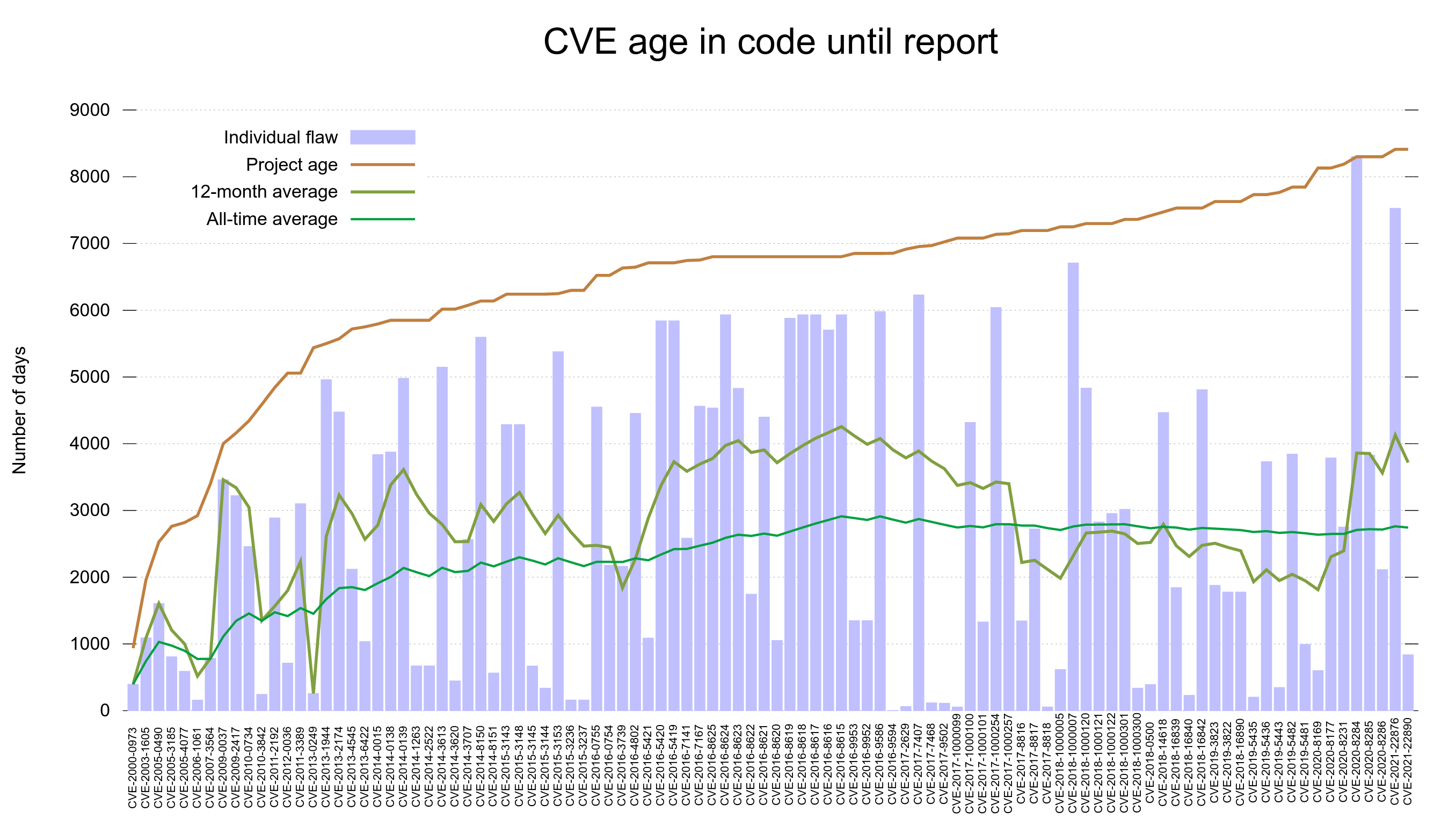
CVE age in code until report
The CVE age in code until report graph shows that in general, reported vulnerabilities were introduced into the code base many years before they are found and fixed. In fact, the all time average time suggests they are present for more than 2,700 – more than seven years. Looking at the reports from the last 12 months, the average is even almost 1000 days more!
It takes a very long time for vulnerabilities to get found and reported.
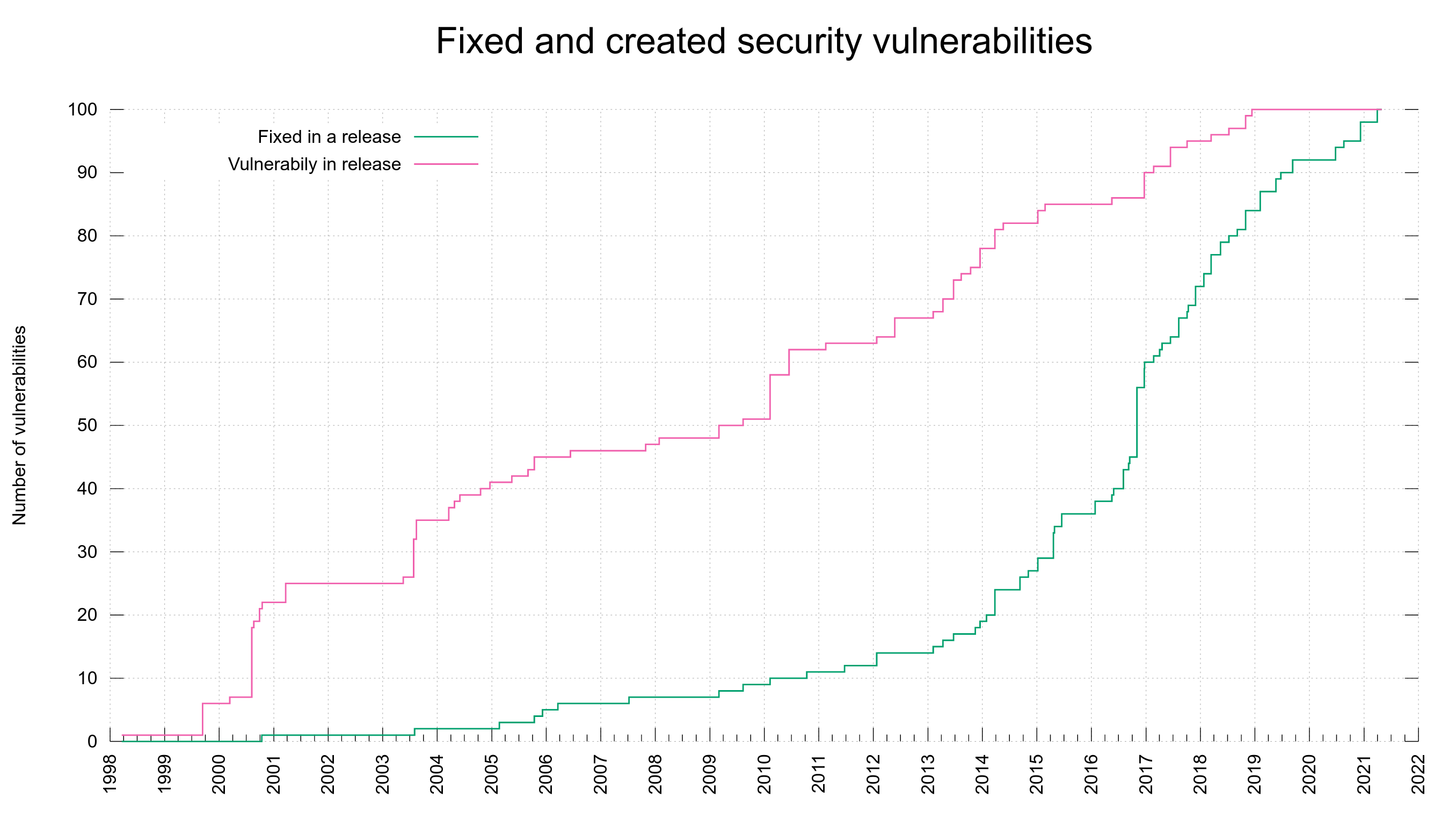
When were the vulnerabilities introduced
Just the other day it struck me that even though I had a lot of graphs already showing in the dashboard, there was none that actually showed me in any nice way at what dates we created the vulnerabilities we spent so much time and effort hunting down, documenting and talking about.
I decided to use the meta data we already have and add a second plot line to the already existing graph. Now we have the previous line (shown in green) that shows the number of fixed vulnerabilities bumped at the date when a fix was released.
Added is the new line (in red) that instead is bumped for every date we know a vulnerability was first shipped in a release. We know the version number from the vulnerability meta data, we know the release date of that version from the release meta data.
This all new graph helps us see that out of the current 100 reported vulnerabilities, half of them were introduced into the code before 2010.
Using this graph it also very clear to me that the increased CVE reporting that we can spot in the green line started to accelerate in the project in 2016 was not because the bugs were introduced then. The creation of vulnerabilities rather seem to be fairly evenly distributed over time – with occasional bumps but I think that’s more related to those being particular releases that introduced a larger amount of features and code.
As the average vulnerability takes 2700 days to get reported, it could indicate that flaws landed since 2014 are too young to have gotten reported yet. Or it could mean that we’ve improved over time so that new code is better than old and thus when we find flaws, they’re more likely to be in old code paths… I don’t think the red graph suggests any particular notable improvement over time though. Possibly it does if we take into account the massive code growth we’ve also had over this time.
The green “fixed” line at least has a much better trend and growth angle.
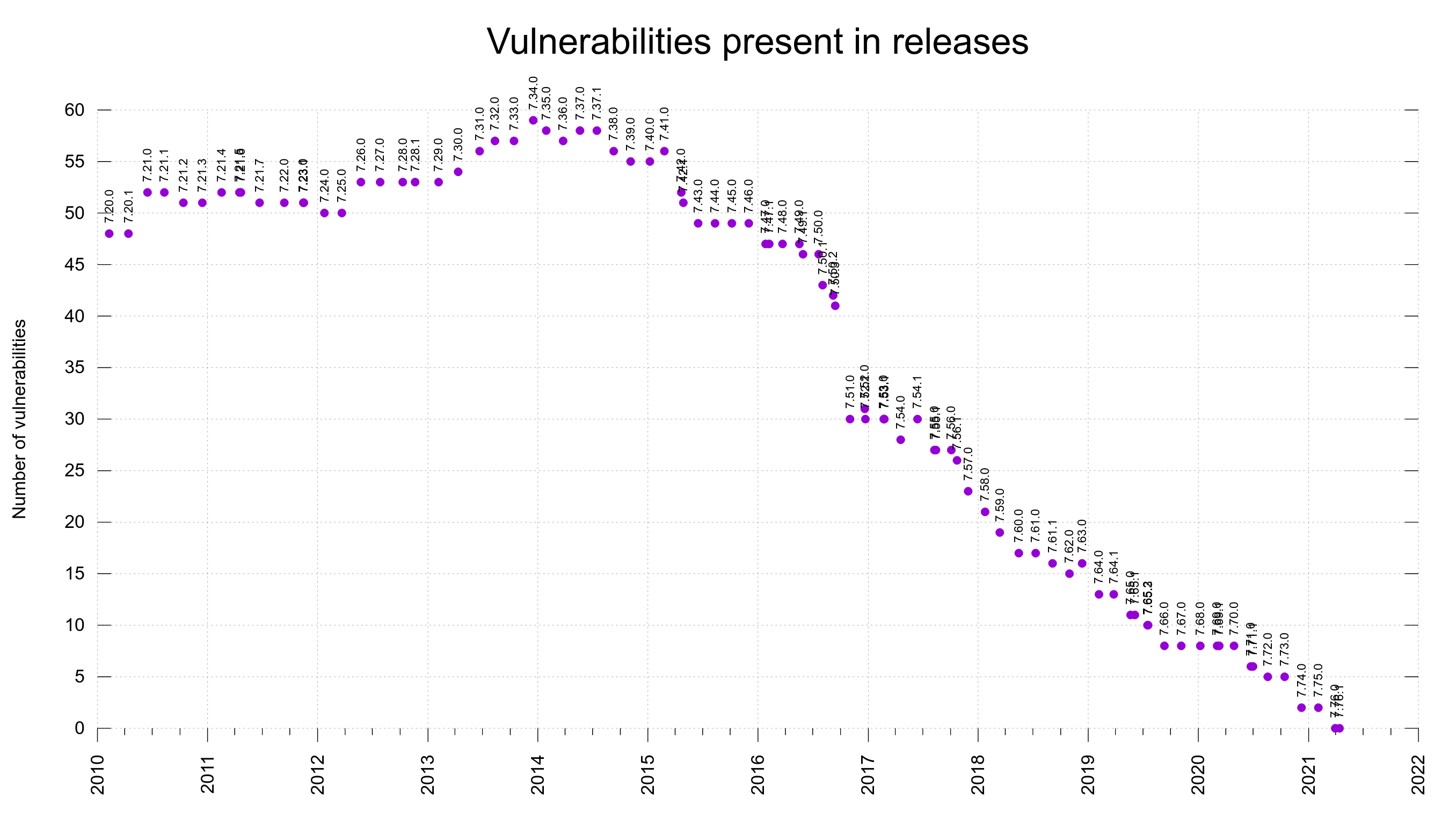
Present in which releases
As we have the range of vulnerable releases stored in the meta data file for each CVE, we can then add up the number of the flaws that are present in every past release.
Together with the release dates of the versions, we can make a graph that shows the number of reported vulnerabilities that are present in each past release over time, in a graph.
You can see that some labels end up overwriting each other somewhat for the occasions when we’ve done two releases very close in time.
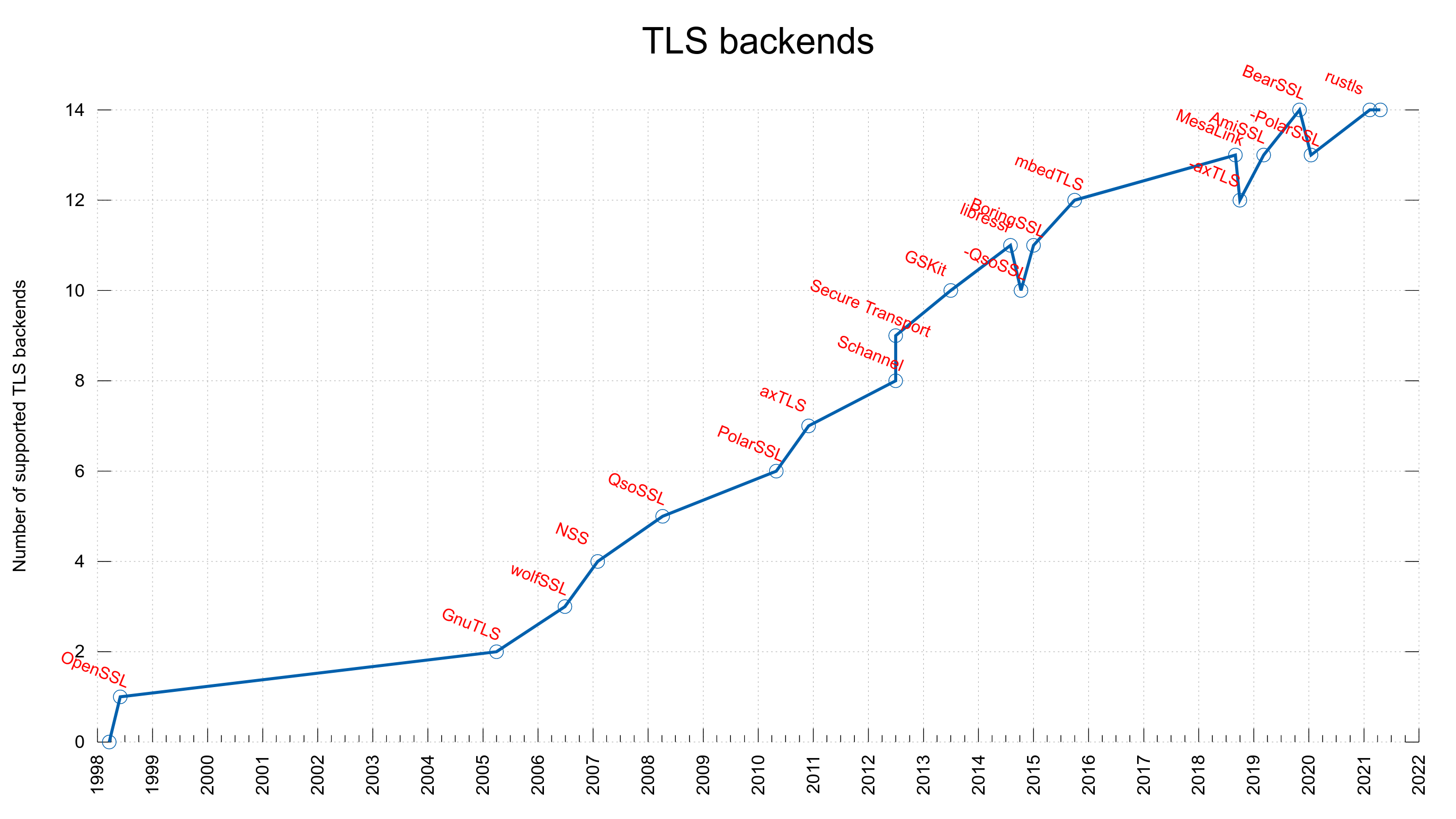
tldr: starting now, you need to select which TLS to use when you run curl’s configure script.
How it started
In June 1998, three months after the first release of curl, we added support for HTTPS. We decided that we would use an external library for this purpose – for providing SSL support – and therefore the first dependency was added. The build would optionally use SSLeay. If you wanted HTTPS support enabled, we would use that external library.
SSLeay ended development at the end of that same year, and OpenSSL rose as a new project and library from its ashes. Of course, even later the term “SSL” would also be replaced by “TLS” but the entire world has kept using them interchangeably.
Building curl
The initial configure script we wrote and provided back then (it appeared for the first time in November 1998) would look for OpenSSL and use it if found present.
In the spring of 2005, we merged support for an alternative TLS library, GnuTLS, and now you would have to tell the configure script to not use OpenSSL but instead use GnuTLS if you wanted that in your build. That was the humble beginning of the explosion of TLS libraries supported by curl.
As time went on we added support for more and more TLS libraries, giving the users the choice to select exactly which particular one they wanted their curl build to use. At the time of this writing, we support 14 different TLS libraries.
TLS backends supported in curl, over time
OpenSSL was still default
The original logic from when we added GnuTLS back in 2005 was however still kept so whatever library you wanted to use, you would have to tell configure to not use OpenSSL and instead use your preferred library.
Also, as the default configure script would try to find and use OpenSSL it would result in some surprises to users who maybe didn’t want TLS in their build or even when something was just not correctly setup and configure unexpectedly didn’t find OpenSSL and the build then went on and was made completely without TLS support! Sometimes even without getting noticed for a long time.
Not doing it anymore
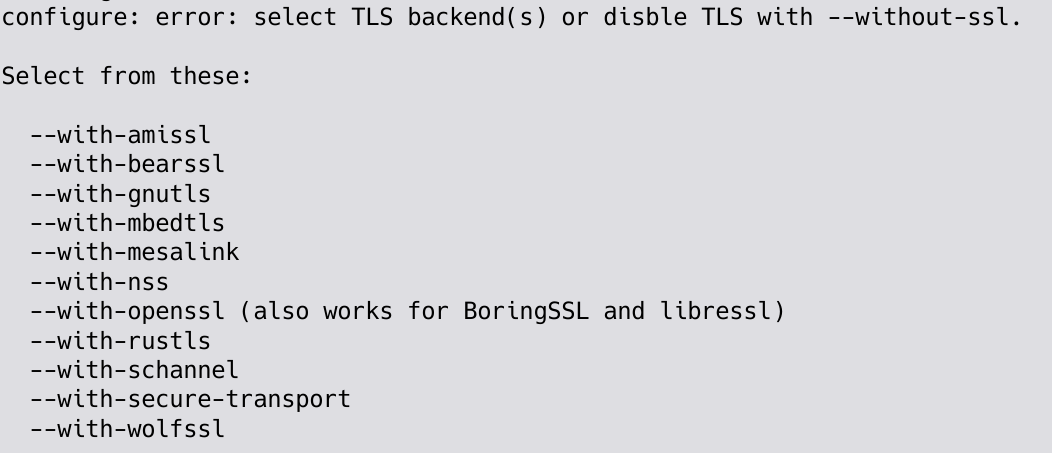
Starting now, curl’s configure will not select TLS backend by default.
It will not decide for you which one you use, as there are many decisions involved when selecting TLS backend and there are many users who prefer something else than OpenSSL. We will no longer give any special treatment to that library at build time. We will not impose our bias onto others anymore.
Not selecting any TLS backend at all will just make configure exit quickly with a help message prompting you to make a decision, as shown below. Notice that going completely without a TLS library is still fine but similarly also requires an active decision (--without-ssl).
The list of available TLS backends is sorted alphabetically.
Effect on configure users
With this change, every configure invoke needs to clearly state which TLS library or even libraries (in plural since curl supports building with support for more than one library) to use.
The biggest change is of course for everyone who invokes configure and wants to build with OpenSSL since they now need to add an option and say that explicitly. For virtually everyone else life can just go on like before.
Everyone who builds curl automatically from source code might need to update their build scripts.
The first release shipping with this change will be curl 7.77.0.
You know that question you can get asked casually by a person you’ve never met before or even by someone you’ve known for a long time but haven’t really talked to about this before. Perhaps at a social event. Perhaps at a family dinner.
– So what do you do?
The implication is of course what you work with. Or as. Perhaps a title.
Software Engineer
In my case I typically start out by saying I’m a software engineer. (And no, I don’t use a title.)
If the person who asked the question is a non-techie, this can then take off in basically any direction. From questions about the Internet, how their printer acts up sometimes to finicky details about Wifi installations or their parents’ problems to install anti-virus. In other words: into areas that have virtually nothing to do with software engineering but is related to computers.
If the person is somewhat knowledgeable or interested in technology or computers they know both what software and engineering are. Then the question can get deepened.
What kind of software?
Alternatively they ask for what company I work for, but it usually ends up on the same point anyway, just via this extra step.
I work on curl. (Saying I work for wolfSSL rarely helps.)
Business cards of mine
So what is curl?
curl is a command line tool used but a small set of people (possibly several thousands or even millions), and the library libcurl that is installed in billions of places.
I often try to compare libcurl with how companies build for example cars out of many components from different manufacturers and companies. They use different pieces from many separate sources put together into a single machine to produce the end product.
libcurl is like one of those little components that a car manufacturer needs. It isn’t the only choice, but it is a well known, well tested and familiar one. It’s a safe choice.
Internet what?
Lots of people, even many with experience, knowledge or even jobs in the IT industry I’ve realized don’t know what an Internet transfer is. Me describing curl as doing such, doesn’t really help in those cases.
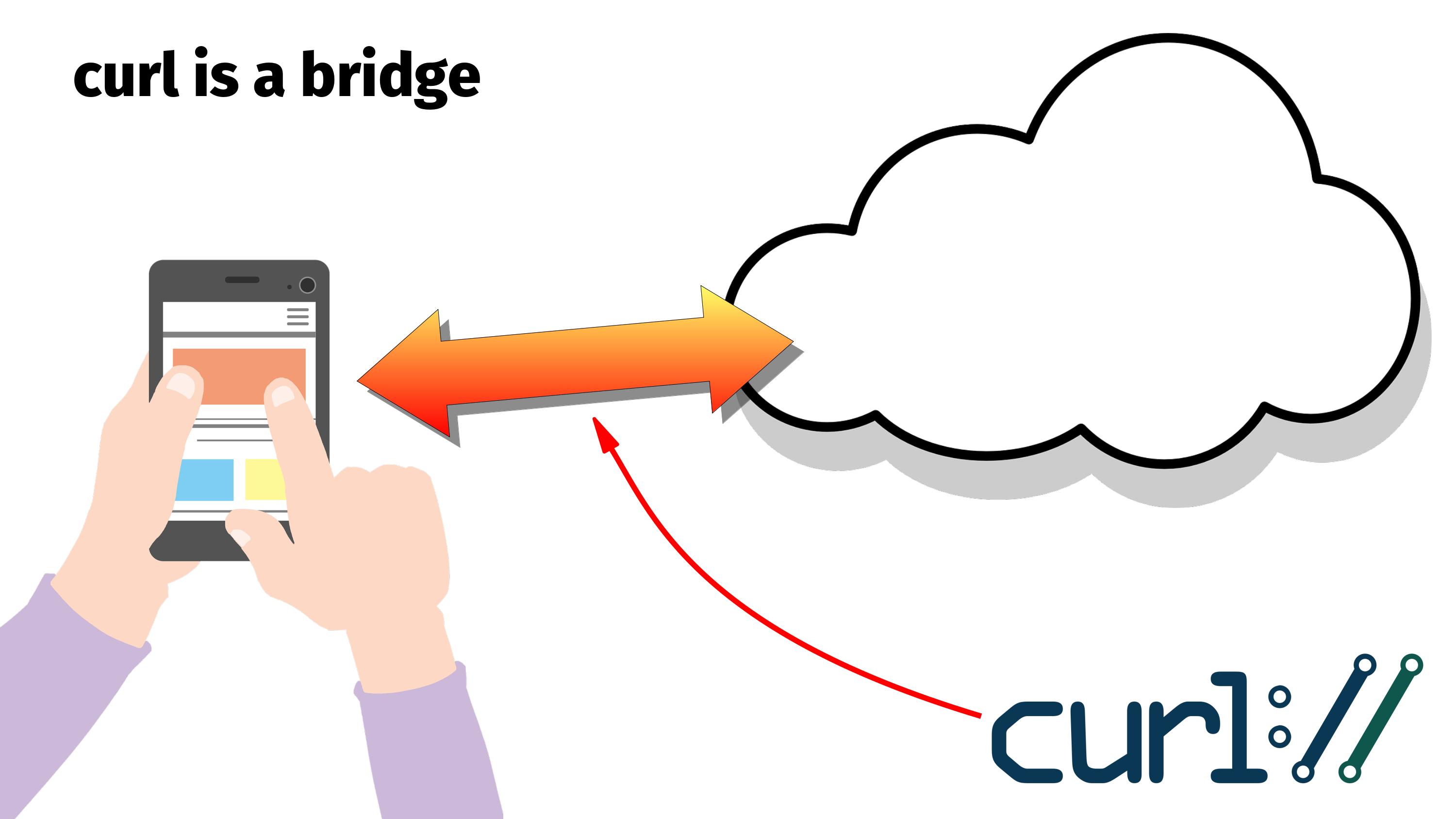
An internet transfer is the bridge between “the cloud” and your devices or applications. curl is a bridge.
Everything wants Internet these days
In general, anything today that has power goes towards becoming networked. Everything that can, will connect to the Internet sooner or later. Maybe not always because it’s a good idea, but because it gives your thing a (perceived) advantage to your competitors.
Things that a while ago you wouldn’t dream would do that, now do Internet transfers. Tooth brushes, ovens, washing machines etc.
If you want to build a new device or application today and you want it to be successful and more popular than your competitors, you will probably have to make it Internet-connected.
You need a “bridge”.
Making things today is like doing a puzzle
Everyone who makes devices or applications today have a wide variety of different components and pieces of the big “puzzle” to select from.
You can opt to write many pieces yourself, but virtually nobody today creates anything digital entirely on their own. We lean on others. We stand on other’s shoulders. In particular open source software has grown up to become or maybe provide a vast ocean of puzzle pieces to use and leverage.
One of the little pieces in your device puzzle is probably Internet transfers, because you want your thing to get updates, upload telemetry and who knows what else.
The picture then needs a piece inserted in the right spot to get complete. The Internet transfers piece. That piece can be curl. We’ve made curl to be a good such piece.
This perfect picture is just missing one little piece…
Relying on pieces provided by others
Lots have been said about the fact that companies, organizations and entire ecosystems rely on pieces and components written, maintained and provided by someone else. Some of them are open source components written by developers on their spare time, but are still used by thousands of companies shipping commercial products.
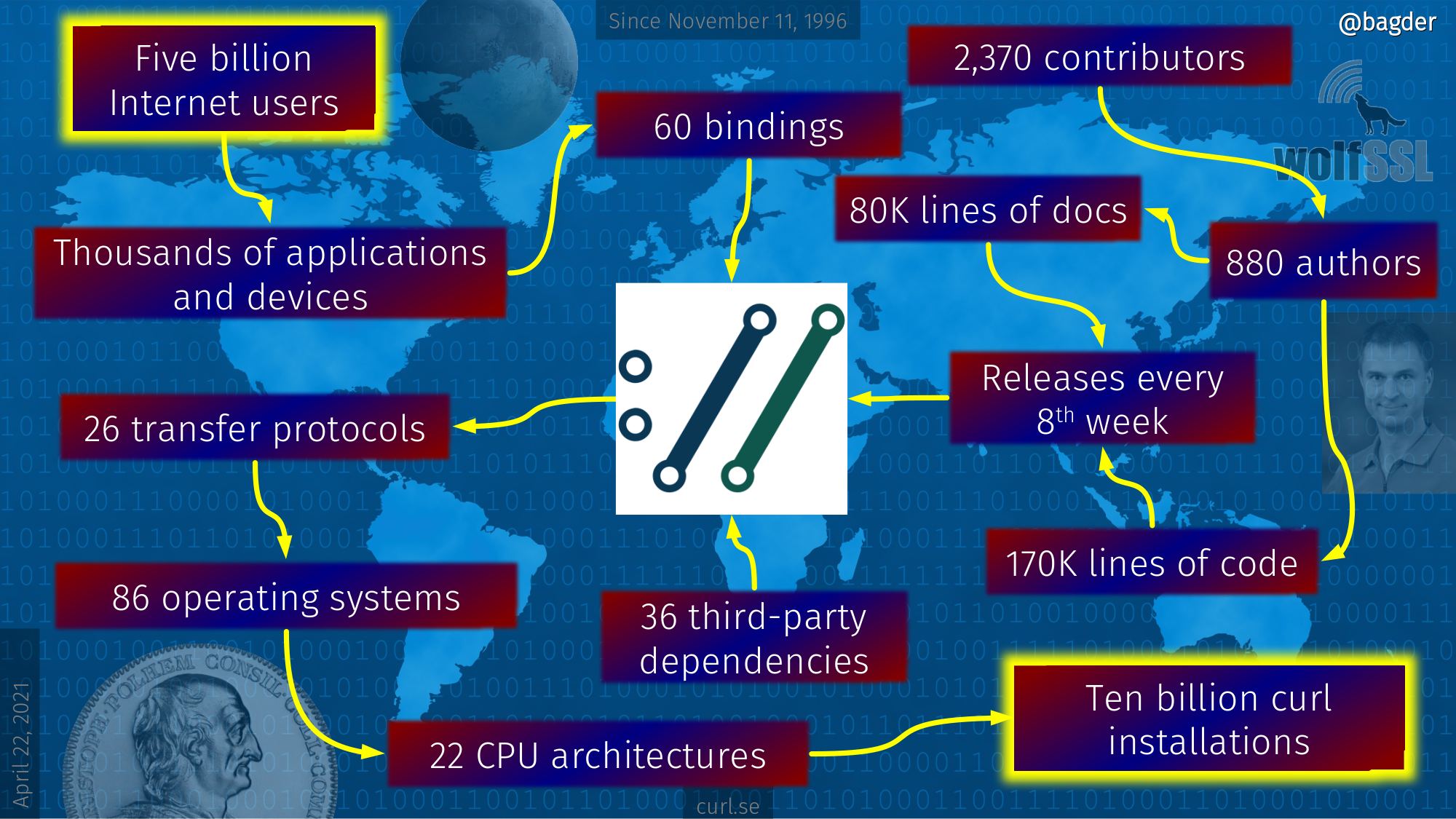
curl is one such component. It’s not “just” a spare time project anymore of course, but the point remains. We estimate that curl runs in some ten billion installations these days, so quite a lot of current Internet infrastructure uses our little puzzle piece in their pictures.
I rarely get to this point in any conversation because I would have already bored my company into a coma by now.
The concept of giving away a component like this as open source under a liberal license is a very weird concept to general people. Maybe also because I say that I work on this and I created it, but I’m not at all the only contributor and we wouldn’t have gotten to this point without the help of several hundred other developers.
“- No, I give it away for free. Yes really, entirely and totally free for anyone and everyone to use. Correct, even the largest and richest mega-corporations of the world.”
The ten billion installations work as marketing for getting companies to understand that curl is a solid puzzle piece so that more will use it and some of those will end up discovering they need help or assistance and they purchase support for curl from me!
I’m not rich, but I do perfectly fine. I consider myself very lucky and fortunate who get to work on curl for a living.
A curl world
There are about 5 billion Internet using humans in the world. There are about 10 billion curl installations.
The puzzle piece curl is there in the middle.
This is how they’re connected. This is the curl world map 2021.
Or put briefly
libcurl is a library for doing transfers specified with a URL, using one of the supported protocols. It is fast, reliable, very portable, well documented and feature rich. A de-facto standard API available for everyone.
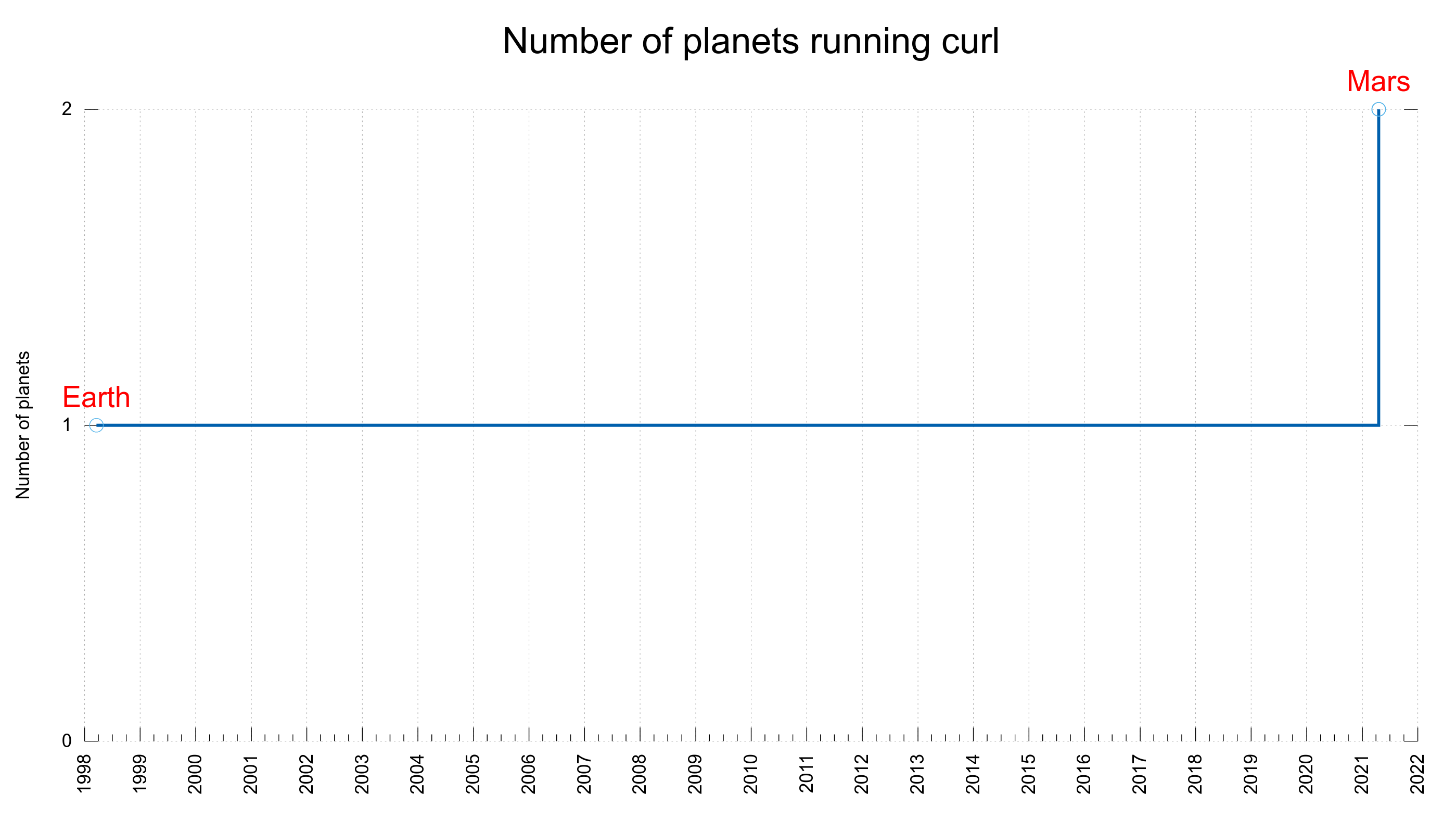
Friends of mine know that I’ve tried for a long time to get confirmation that curl is used in space. We’ve believed it to be likely but I’ve wanted to get a clear confirmation that this is indeed the fact.
Today GitHub posted their article about open source in the Mars mission, and they now provide a badge on their site for contributors of projects that are used in that mission.
I have one of those badges now. Only a few other of the current 879 recorded curl authors got it. Which seems to be due to them using a very old curl release (curl 7.19, released in September 2008) and they couldn’t match all contributors with emails or the authors didn’t have their emails verified on GitHub etc.
According to that GitHub blog post, we are “almost 12,000” developers who got it.
While this strictly speaking doesn’t say that curl is actually used in space, I think it can probably be assumed to be.
Here’s the interplanetary curl development displayed in a single graph:





























![https://cowbirdsinlove.com/comics/base10[1].png](https://cowbirdsinlove.com/comics/base10[1].png){kind=link}