I write and prefer code that fits within 80 columns in curl and other projects – and there are reasons for it. I’m a little bored by the people who respond and say that they have 400 inch monitors already and they can use them.
I too have multiple large high resolution screens – but writing wide code is still a bad idea! So I decided I’ll write down my reasoning once and for all!
Narrower is easier to read
There’s a reason newspapers and magazines have used narrow texts for centuries and in fact even books aren’t using long lines. For most humans, it is simply easier on the eyes and brain to read texts that aren’t using really long lines. This has been known for a very long time.
Easy-to-read code is easier to follow and understand which leads to fewer bugs and faster debugging.
Side-by-side works better
I never run windows full sized on my screens for anything except watching movies. I frequently have two or more editor windows next to each other, sometimes also with one or two extra terminal/debugger windows next to those. To make this feasible and still have the code readable, it needs to fit “wrapless” in those windows.
Sometimes reading a code diff is easier side-by-side and then too it is important that the two can fit next to each other nicely.
Better diffs
Having code grow vertically rather than horizontally is beneficial for diff, git and other tools that work on changes to files. It reduces the risk of merge conflicts and it makes the merge conflicts that still happen easier to deal with.
It encourages shorter names
A side effect by strictly not allowing anything beyond column 80 is that it becomes really hard to use those terribly annoying 30+ letters java-style names on functions and identifiers. A function name, and especially local ones, should be short. Having long names make them really hard to read and makes it really hard to spot the difference between the other functions with similarly long names where just a sub-word within is changed.
I know especially Java people object to this as they’re trained in a different culture and say that a method name should rather include a lot of details of the functionality “to help the user”, but to me that’s a weak argument as all non-trivial functions will have more functionality than what can be expressed in the name and thus the user needs to know how the function works anyway.
I don’t mean 2-letter names. I mean long enough to make sense but not be ridiculous lengths. Usually within 15 letters or so.
Just a few spaces per indent level
To make this work, and yet allow a few indent levels, the code basically have to have small indent-levels, so I prefer to have it set to two spaces per level.
Many indent levels is wrong anyway
If you do a lot of indent levels it gets really hard to write code that still fits within the 80 column limit. That’s a subtle way to suggest that you should not write functions that needs or uses that many indent levels. It should then rather be split out into multiple smaller functions, where then each function won’t need that many levels!
Why exactly 80?
Once upon the time it was of course because terminals had that limit and these days the exact number 80 is not a must. I just happen to think that the limit has worked fine in the past and I haven’t found any compelling reason to change it since.
It also has to be a hard and fixed limit as if we allow a few places to go beyond the limit we end up on a slippery slope and code slowly grow wider over time – I’ve seen it happen in many projects with “soft enforcement” on code column limits.
Enforced by a tool
In curl, we have ‘checksrc’ which will yell errors at any user trying to build code with a too long line present. This is good because then we don’t have to “waste” human efforts to point this out to contributors who offer pull requests. The tool will point out such mistakes with ruthless accuracy.
The purpose of the curl web site is to inform the world about what curl and libcurl are and provide as much information as possible about the project, the products and everything related to that.
The web site has existed in some form for as long as the project has, but it has of course developed and changed over time.
Independent
The curl project is completely independent and stands free from influence from any parent or umbrella organization or company. It is not even a legal entity, just a bunch of random people cooperating over the Internet. And a bunch of awesome sponsors to help us.
This means that we have no one that provides the infrastructure or marketing for us. We need to provide, run and care for our own servers and anything else we think we should offer our users.
I still do a lot of the work in curl and the curl web site and I work full time on curl, for wolfSSL. This might of course “taint” my opinions and views on matters, but doesn’t imply ownership or control. I’m sure we’re all colored by where we work and where we are in our lives right now.
Contents
Most of the web site is static content: generated HTML pages. They are served super-fast and very lightweight by any web server software.
The web site source exists in the curl-www repository (hosted on GitHub) and the web site syncs itself with the latest repository changes several times per hour. The parts of the site that aren’t static are mostly consisting of smaller scripts that run either on demand at the time of a request or on an interval in a cronjob in the background. That is part of the reason why pushing an update to the web site’s repository can take a little while until it shows up on the live site.
There’s a deliberate effort at not duplicating information so a lot of the web pages you can find on the web site are files that are converted and “HTMLified” from the source code git repository.
“Design”
Some people say the curl web site is “retro”, others that it is plain ugly. My main focus with the site is to provide and offer all the info, and have it be accurate and accessible. The look and the design of the web site is a constant battle, as nobody who’s involved in editing or polishing the web site is really interested in or particularly good at design, looks or UX. I personally have done most of the editing of it, including CSS etc and I can tell you that I’m not good at it and I don’t enjoy it. I do it because I feel I have to.
I get occasional offers to “redesign” the web site, but the general problem is that those offers almost always involve rebuilding the entire thing using some current web framework, not just fixing the looks, layout or hierarchy. By replacing everything like that we’d get a lot of problems to get the existing information in there – and again, the information is more important than the looks.
The curl logo is designed by a proper designer however (Adrian Burcea).
If you want to help out designing and improving the web site, you’d be most welcome!
Who
I’ve already touched on it: the web site is mostly available in git so “anyone” can submit issues and pull-requests to improve it, and we are around twenty persons who have push rights that can then make a change on the live site. In reality of course we are not that many who work on the site any ordinary month, or even year. During the last twelve month period, 10 persons authored commits in the web repository and I did 90% of those.
How
Technically, we build the site with traditional makefiles and we generate the web contents mostly by preprocessing files using a C-like preprocessor called fcpp. This is an old and rather crude setup that we’ve used for over twenty years but it’s functional and it allows us to have a mostly static web site that is also fairly easy to build locally so that we can work out and check improvements before we push them to the git repository and then out to the world.
The web site is of course only available over HTTPS.
Hosting
The curl web site is hosted on an origin VPS server in Sweden. The machine is maintained by primarily by me and is paid for by Haxx. The exact hosting is not terribly important because users don’t really interact with our server directly… (Also, as they’re not sponsors we’re just ordinary customers so I won’t mention their name here.)
CDN
A few years ago we experienced repeated server outages simply because our own infrastructure did not handle the load very well, and in particular not the traffic spikes that could occur when I would post a blog post that would suddenly reach a wide audience.
Enter Fastly. Now, when you go to curl.se (or daniel.haxx.se) you don’t actually reach the origin server we admin, you will instead reach one of Fastly’s servers that are distributed across the world. They then fetch the web contents from our origin, cache it on their edge servers and send it to you when you browse the site. This way, your client speaks to a server that is likely (much) closer to you than the origin server is and you’ll get the content faster and experience a “snappier” web site. And our server only gets a tiny fraction of the load.
Technically, this is achieved by the name curl.se resolving to a number of IP addresses that are anycasted. Right now, that’s 4 IPv4 addresses and 4 IPv6 addresses.
The fact that the CDN servers cache content “a while” is another explanation to why updated contents take a little while to “take effect” for all visitors.
DNS
When we just recently switched the site over to curl.se, we also adjusted how we handle DNS.
I run our own main DNS server where I control and admin the zone and the contents of it. We then have four secondary servers to help us really up our reliability. Out of those four secondaries, three are sponsored by Kirei and are anycasted. They should be both fast and reliable for most of the world.
With the help of fabulous friends like Fastly and Kirei, we hope that the curl web site and services shall remain stable and available.
DNS enthusiasts have remarked that we don’t do DNSSEC or registry-lock on the curl.se domain. I think we have reason to consider and possibly remedy that going forward.
Traffic
The curl web site is just the home of our little open source project. Most users out there in the world who run and use curl or libcurl will not download it from us. Most curl users get their software installation from their Linux distribution or operating system provider. The git repository and all issues and pull-requests are done on GitHub.
Relevant here is that we have no logging and we run no ads or any analytics. We do this for maximum user privacy and partly because of laziness, since handling logging from the CDN system is work. Therefore, I only have aggregated statistics.
In this autumn of 2020, over a normal 30 day period, the web site serves almost 11 TB of data to 360 million HTTP requests. The traffic volume is up from 3.5 TB the same time last year. 11 terabytes per 30 days equals about 4 megabytes per second on average.
Without logs we cannot know what people are downloading – but we can guess! We know that the CA cert bundle is popular and we also know that in today’s world of containers and CI systems, a lot of things out there will download the same packages repeatedly. Otherwise the web site is mostly consisting of text and very small images.
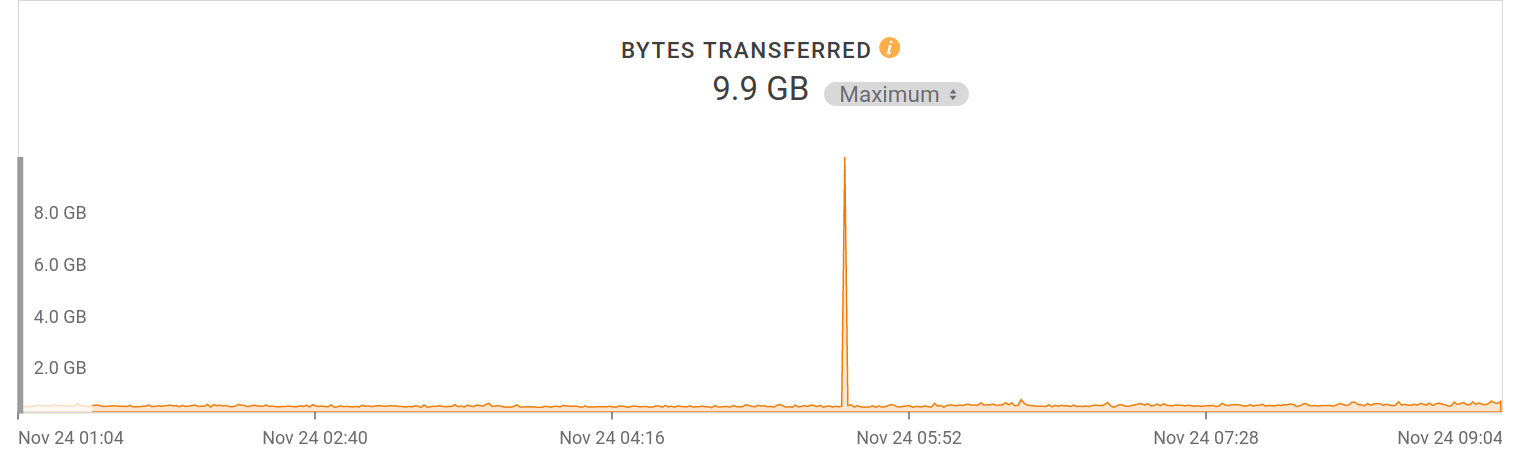
One interesting specific pattern on the server load that’s been going on for months: every morning at 05:30 UTC, the site gets over 50,000 requests within that single minute, during which 10 gigabytes of data is downloaded. The clients are distributed world wide as I see the same pattern on access points all over. The minute before and the minute after, the average traffic rate remains at 200MB/minute. It makes for a fun graph:
An eight hour zoomed in window of bytes transferred from the web site. UTC times.
Our servers suffer somewhat from being the target of weird clients like qqgamehall that continuously “hammer” the site with requests at a high frequency many months after we started always returning error to them. An effect they have is that they make the admin dashboard to constantly show a very high error rate.
Software
The origin server runs Debian Linux and Apache httpd. It has a reverse proxy based on nginx. The DNS server is bind. The entire web site is built with free and open source. Primarily: fcpp, make, roffit, perl, curl, hypermail and enscript.
If you curl the curl site, you can see in response headers that Fastly uses Varnish.
At 00:42 in the early morning of November 16 (my time, Central European Time), I received an email saying that “someone” logged into my twitter account @bagder from a new device. The email said it was done from Stockholm, Sweden and it was “Chrome on Windows”. (I live Stockholm)
I didn’t do it. I don’t normally use Windows and I typically don’t run Chrome. I didn’t react immediately on the email however, as I was debugging curl code at the moment it arrived. Just a few moments later I was forcibly logged out from my twitter sessions (using tweetdeck in my Firefox on Linux and on my phone).
Whoa! What was that? I tried to login again in the browser tab, but Twitter claimed my password was invalid. Huh? Did I perhaps have the wrong password? I selected “restore my password” and then learned that Twitter doesn’t even know about my email anymore (in spite of having emailed me on it just minutes ago).
At 00:50 I reported the issue to Twitter. At 00:51 I replied to their confirmation email and provided them with additional information, such as my phone number I have (had?) associated with my account.
I’ve since followed up with two additional emails to Twitter with further details about this but I have yet to hear something from them. I cannot access my account.
November 17: (30 hours since it happened). The name of my account changed to Elon Musk (with a few funny unicode letters that only look similar to the Latin letters) and pushed for bitcoin scams.
At 20:56 on November 17 I received the email with the notice the account had been restored back to my email address and ownership.
Left now are the very sad DM responses in my account from desperate and ruined people who cry out for help and mercy from the scammers after they’ve fallen for the scam and lost large sums of money.
How?
A lot of people ask me how this was done. The simple answer is that I don’t know. At. All. Maybe I will later on but right now, it all went down as described above and it does not tell how the attacker managed to perform this. Maybe I messed up somewhere? I don’t know and I refuse to speculate without having more information.
I’m convinced I had 2fa enabled on the account, but I’m starting to doubt if perhaps I am mistaking myself?
Why me?
Probably because I have a “verified” account (with a blue check-mark) with almost 24.000 followers.
Other accounts
I have not found any attacks, take-overs or breaches in any other online accounts and I have no traces of anyone attacking my local computer or other accounts of mine with value. I don’t see any reason to be alarmed to suspect that source code or github project I’m involved with should be “in danger”.
Here’s the complete timeline of events. From my first denial to travel to the US until I eventually received a tourist visa. And then I can’t go anyway.
December 5-11, 2016
I spent a week on Hawaii with Mozilla – my employer at the time. This was my 12th visit to the US over a period of 19 years. I went there on ESTA, the visa waiver program Swedish citizens can use. I’ve used it many times, there was nothing special this time. The typical procedure with ESTA is that we apply online: fill in a form, pay a 14 USD fee and get a confirmation within a few days that we’re good to go.
I took this photo at the hotel we stayed at during the Mozilla all-hands on Hawaii 2016.
June 26, 2017
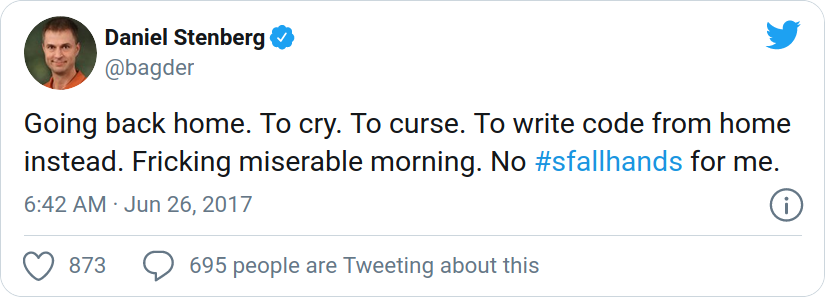
In the early morning one day by the check-in counter at Arlanda airport in Sweden, I was refused to board my flight. Completely unexpected and out of the blue! I thought I was going to San Francisco via London with British Airways, but instead I had to turn around and go back home – slightly shocked. According to the lady behind the counter there was “something wrong with my ESTA”. I used the same ESTA and passport as I used just fine back in December 2016. They’re made to last two years and it had not expired.
Tweeted by me, minutes after being stopped at Arlanda.
People engaged by Mozilla to help us out could not figure out or get answers about what the problem was (questions and investigations were attempted both in the US and in Sweden), so we put our hopes on that it was a human mistake somewhere and decided to just try again next time.
April 3, 2018
I missed the following meeting (in December 2017) for other reasons but in the summer of 2018 another Mozilla all-hands meeting was coming up (in Texas, USA this time) so I went ahead and applied for a new ESTA in good time before the event – as I was a bit afraid there was going to be problems. I was right and I got denied ESTA very quickly. “Travel Not Authorized”.
Rejected from the ESTA program.
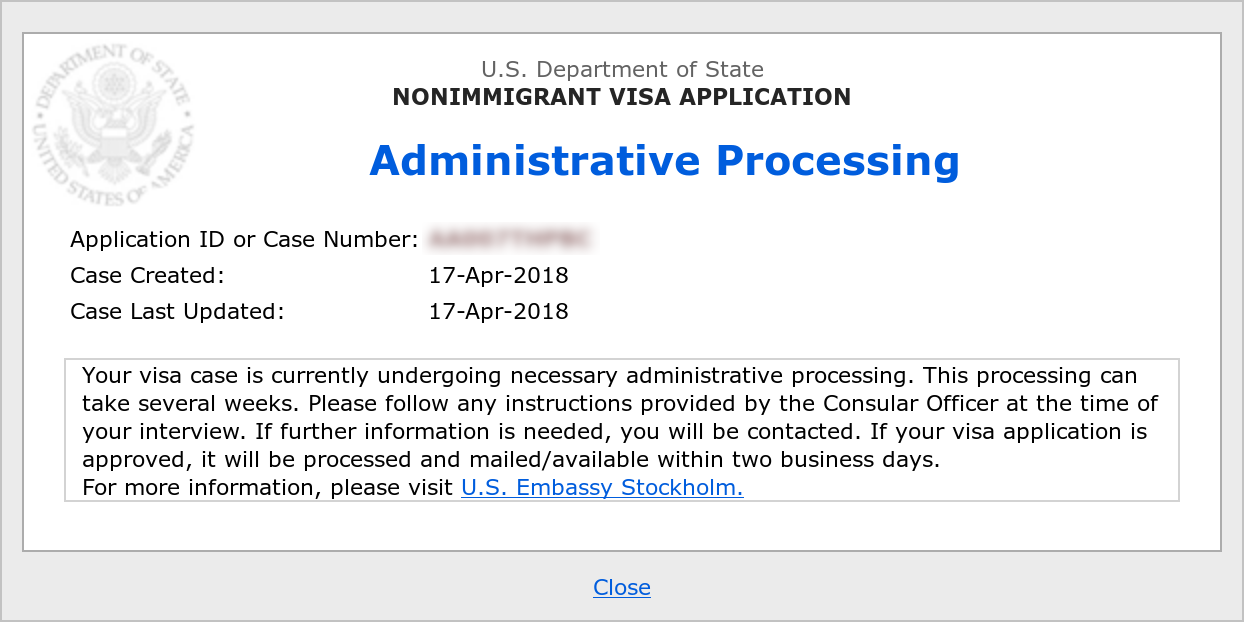
Day 0 – April 17, 2018
Gaaah. It meant it was no mistake last year, they actually mean this. I switched approach and instead applied for a tourist visa. I paid 160 USD, filled in a ridiculous amount of information about me and my past travels over the last 15 years and I visited the US embassy for an in-person interview and fingerprinting.
This is day 0 in the visa process, 296 days after I was first stopped at Arlanda.
Day 90 – July 2018
I missed the all-hands meeting in San Francisco when I didn’t get the visa in time.
Day 240 – December 2018
I quit Mozilla, so I then had no more reasons to go to their company all-hands…
Day 365 – April 2019
A year passed. “someone is working on it” the embassy email person claimed when I asked about progress.
Day 651- January 28, 2020
I emailed the embassy to query about the process
Screenshotted email
The reply came back quickly:
Dear Sir,
All applications are processed in the most expeditious manner possible. While we understand your frustration, we are required to follow immigration law regarding visa issuances. This process cannot be expedited or circumvented. Rest assured that we will contact you as soon as the administrative processing is concluded.
Day 730 – April 2020
Another year had passed and I had given up all hope. Now it turned into a betting game and science project. How long can they actually drag out this process without saying either yes or no?
Day 871 – September 3, 2020
A friend of mine, a US citizen, contacted his Congressman – Gerry Connolly – about my situation and asked for help. His office then subsequently sent a question to the US embassy in Stockholm asking about my case. While the response that arrived on September 17 was rather negative…
your case is currently undergoing necessary administrative processing and regrettably it is not possible to predict when this processing will be completed.
… I think the following turn of events indicates it had an effect. It unclogged something.
Day 889 – September 22, 2020
After 889 days since my interview on the embassy (only five days after the answer to the congressman), the embassy contacted me over email. For the first time since that April day in 2018.
Your visa application is still in administrative processing. However, we regret to inform you that because you have missed your travel plans, we will require updated travel plans from you.
My travel plans – that had been out of date for the last 800 days or so – suddenly needed to be updated! As I was already so long into this process and since I feared that giving up now would force me back to square one if I would stop now and re-attempt this again at a later time, I decided to arrange myself some updated travel plans. After all, I work for an American company and I have a friend or two there.
Day 900 – October 2, 2020
I replied to the call for travel plan details with an official invitation letter attached, inviting me to go visit my colleagues at wolfSSL signed by our CEO, Larry. I really want to do this at some point, as I’ve never met most of them so it wasn’t a made up reason. I could possibly even get some other friends to invite me to get the process going but I figured this invite should be enough to keep the ball rolling.
Day 910 – October 13, 2020
I got another email. Now at 910 days since the interview. The embassy asked for my passport “for further processing”.
Day 913 – October 16, 2020
I posted my passport to the US embassy in Stockholm. I also ordered and paid for “return postage” as instructed so that they would ship it back to me in a safe way.
Day 934 – November 6, 2020
At 10:30 in the morning my phone lit up and showed me a text telling me that there’s an incoming parcel being delivered to me, shipped from “the Embassy of the United State” (bonus points for the typo).
Day 937 – November 9, 2020
I received my passport. Inside, there’s a US visa that is valid for ten years, until November 2030.
The upper left corner of the visa page in my passport…
As a bonus, the visa also comes with a NIE (National Interest Exception) that allows me a single entry to the US during the PP (Presidential Proclamations) – which is restricting travels to the US from the European Schengen zone. In other words: I am actually allowed to travel right away!
The timing is fascinating. The last time I was in the US, Trump hadn’t taken office yet and I get the approved visa in my hands just days after Biden has been announced as the next president of the US.
Will I travel?
Covid-19 is still over us and there’s no end in sight of the pandemic. I will of course not travel to the US or any other country until it can be deemed safe and sensible.
When the pandemic is under control and traveling becomes viable, I am sure there will be opportunities. Hopefully the situation will improve before the visa expires.
Thanks to
All my family and friends, in the US and elsewhere who have supported me and cheered me up through this entire process. Thanks for keeping inviting me to fun things in the US even though I’ve not been able to participate. Thanks for pushing for events to get organized outside of the US! I’m sorry I’ve missed social gatherings, a friend’s marriage and several conference speaking opportunities. Thanks for all the moral support throughout this long journey of madness.
A special thanks go to David (you know who you are) for contacting Gerry Connolly’s office. I honestly think this was the key event that finally made things move in this process.
Every now and then I get questions on how to work with git in a smooth way when developing, bug-fixing or extending curl – or how I do it. After all, I work on open source full time which means I have very frequent interactions with git (and GitHub). Simply put, I work with git all day long. Ordinary days, I issue git commands several hundred times.
I have a very simple approach and way of working with git in curl. This is how it works.
command line
I use git almost exclusively from the command line in a terminal. To help me see which branch I’m working in, I have this little bash helper script.
brname () {
a=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
if [ -n "$a" ]; then
echo " [$a]"
else
echo ""
fi
}
PS1="\u@\h:\w\$(brname)$ "
That gives me a prompt that shows username, host name, the current working directory and the current checked out git branch.
In addition: I use Debian’s bash command line completion for git which is also really handy. It allows me to use tab to complete things like git commands and branch names.
git config
I of course also have my customized ~/.gitconfig file to provide me with some convenient aliases and settings. My most commonly used git aliases are:
st = status --short -uno
ci = commit
ca = commit --amend
caa = commit -a --amend
br = branch
co = checkout
df = diff
lg = log -p --pretty=fuller --abbrev-commit
lgg = log --pretty=fuller --abbrev-commit --stat
up = pull --rebase
latest = log @^{/RELEASE-NOTES:.synced}..
The ‘latest’ one is for listing all changes done to curl since the most recent RELEASE-NOTES “sync”. The others should hopefully be rather self-explanatory.
The config also sets gpgsign = true, enables mailmap and a few other things.
master is clean and working
The main curl development is done in the single curl/curl git repository (primarily hosted on GitHub). We keep the master branch the bleeding edge development tree and we work hard to always keep that working and functional. We do our releases off the master branch when that day comes (every eight weeks) and we provide “daily snapshots” from that branch, put together – yeah – daily.
When merging fixes and features into master, we avoid merge commits and use rebases and fast-forward as much as possible. This makes the branch very easy to browse, understand and work with – as it is 100% linear.
Work on a fix or feature
When I start something new, like work on a bug or trying out someone’s patch or similar, I first create a local branch off master and work in that. That is, I don’t work directly in the master branch. Branches are easy and quick to do and there’s no reason to shy away from having loads of them!
I typically name the branch prefixed with my GitHub user name, so that when I push them to the server it is noticeable who is the creator (and I can use the same branch name locally as I do remotely).
$ git checkout -b bagder/my-new-stuff-or-bugfix
Once I’ve reached somewhere, I commit to the branch. It can then end up one or more commits before I consider myself “done for now” with what I was set out to do.
I try not to leave the tree with any uncommitted changes – like if I take off for the day or even just leave for food or an extended break. This puts the repository in a state that allows me to easily switch over to another branch when I get back – should I feel the need to. Plus, it’s better to commit and explain the change before the break rather than having to recall the details again when coming back.
Never stash
“git stash” is therefore not a command I ever use. I rather create a new branch and commit the (temporary?) work in there as a potential new line of work.
Show it off and get reviews
Yes I am the lead developer of the project but I still maintain the same work flow as everyone else. All changes, except the most minuscule ones, are done as pull requests on GitHub.
When I’m happy with the functionality in my local branch. When the bug seems to be fixed or the feature seems to be doing what it’s supposed to do and the test suite runs fine locally.
I then clean up the commit series with “git rebase -i” (or if it is a single commit I can instead use just “git commit --amend“).
The commit series should be a set of logical changes that are related to this change and not any more than necessary, but kept separate if they are separate. Each commit also gets its own proper commit message. Unrelated changes should be split out into its own separate branch and subsequent separate pull request.
git push origin bagder/my-new-stuff-or-bugfix
Make the push a pull request
On GitHub, I then make the newly pushed branch into a pull request (aka “a PR”). It will then become visible in the list of pull requests on the site for the curl source repository, it will be announced in the #curl IRC channel and everyone who follows the repository on GitHub will be notified accordingly.
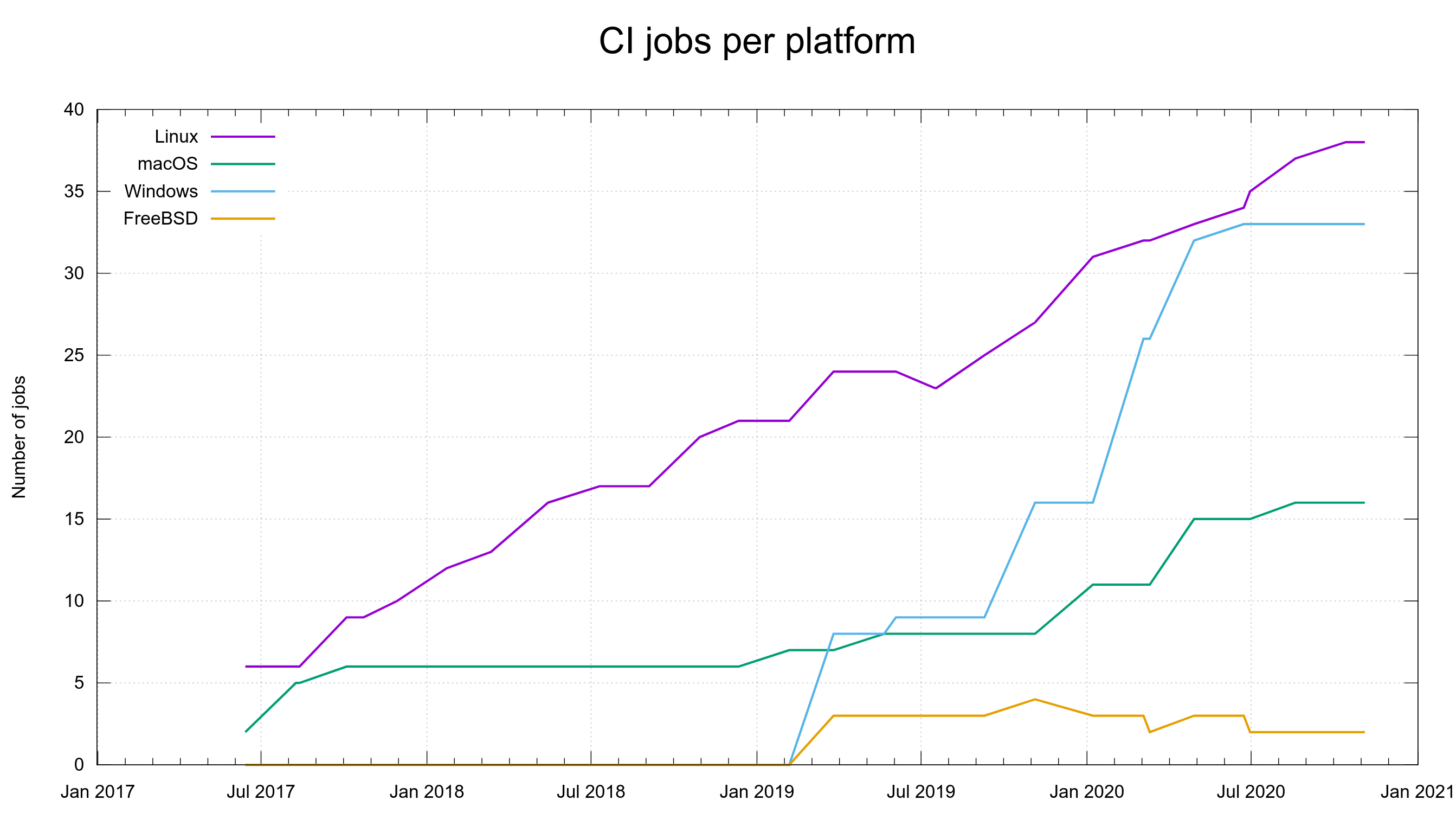
Perhaps most importantly, a pull request kicks of a flood of CI jobs that will build and test the code in numerous different combinations and on several platforms, and the results of those tests will trickle in over the coming hours. When I write this, we have around 90 different CI jobs – per pull request – and something like 8 different code analyzers will scrutinize the change to see if there’s any obvious flaws in there.
CI jobs per platform over time. Graph snapped on November 5, 2020
A branch in the actual curl/curl repo
Most contributors who would work on curl would not do like me and make the branch in the curl repository itself, but would rather do them in their own forked version instead. The difference isn’t that big and I could of course also do it that way.
After push, switch branch
As it will take some time to get the full CI results from the PR to come in (generally a few hours), I switch over to the next branch with work on my agenda. On a normal work-day I can easily move over ten different branches, polish them and submit updates in their respective pull-requests.
I can go back to the master branch again with ‘git checkout master‘ and there I can “git pull” to get everything from upstream – like when my fellow developers have pushed stuff in the mean time.
PR comments or CI alerts
If a reviewer or a CI job find a mistake in one of my PRs, that becomes visible on GitHub and I get to work to handle it. To either fix the bug or discuss with the reviewer what the better approach might be.
Unfortunately, flaky CI jobs is a part of life so very often there ends up one or two red markers in the list of CI jobs that can be ignored as the test failures in them are there due to problems in the setup and not because of actual mistakes in the PR…
To get back to my branch for that PR again, I “git checkout bagder/my-new-stuff-or-bugfix“, and fix the issues.
I normally start out by doing follow-up commits that repair the immediate mistake and push them on the branch:
git push origin bagder/my-new-stuff-or-bugfix
If the number of fixup commits gets large, or if the follow-up fixes aren’t small, I usually end up doing a squash to reduce the number of commits into a smaller, simpler set, and then force-push them to the branch.
The reason for that is to make the patch series easy to review, read and understand. When a commit series has too many commits that changes the previous commits, it becomes hard to review.
Ripe to merge?
When the pull request is ripe for merging (independently of who authored it), I switch over to the master branch again and I merge the pull request’s commits into it. In special cases I cherry-pick specific commits from the branch instead. When all the stuff has been yanked into master properly that should be there, I push the changes to the remote.
Usually, and especially if the pull request wasn’t done by me, I also go over the commit messages and polish them somewhat before I push everything. Commit messages should follow our style and mention not only which PR that it closes but also which issue it fixes and properly give credit to the bug reporter and all the helpers – using the right syntax so that our automatic tools can pick them up correctly!
As already mentioned above, I merge fast-forward or rebased into master. No merge commits.
Never merge with GitHub!
There’s a button GitHub that says “rebase and merge” that could theoretically be used for merging pull requests. I never use that (and if I could, I’d disable/hide it). The reasons are simply:
I don’t feel that I have the proper control of the commit message(s)
I can’t select to squash a subset of the commits, only all or nothing
I often want to cleanup the author parts too before push, which the UI doesn’t allow
The downside with not using the merge button is that the message in the PR says “closed by [hash]” instead of “merged in…” which causes confusion to a fair amount of users who don’t realize it means that it actually means the same thing! I consider this is a (long-standing) GitHub UX flaw.
Post merge
If the branch has nothing to be kept around more, I delete the local branch again with “git branch -d [name]” and I remove it remotely too since it was completely merged there’s no reason to keep the work version left.
At any given point in time, I have some 20-30 different local branches alive using this approach so things I work on over time all live in their own branches and also submissions from various people that haven’t been merged into master yet exist in branches of various maturity levels. Out of those local branches, the number of concurrent pull requests I have in progress can be somewhere between just a few up to ten, twelve something.
RELEASE-NOTES
Not strictly related, but in order to keep interested people informed about what’s happening in the tree, we sync the RELEASE-NOTES file every once in a while. Maybe every 5-7 days or so. It thus becomes a file that explains what we’ve worked on since the previous release and it makes it well-maintained and ready by the time the release day comes.
To sync it, all I need to do is:
$ ./scripts/release-notes.pl
Which makes the script add suggested updates to it, so I then load the file into my editor, remove the separation marker and all entries that don’t actually belong there (as the script adds all commits as entries as it can’t judge the importance).
When it looks okay, I run a cleanup round to make it sort it and remove unused references from the file…
$ ./scripts/release-notes.pl cleanup
Then I make sure to get a fresh list of contributors…
$ ./scripts/contributors.sh
… and paste that updated list into the RELEASE-NOTES. Finally, I get refreshed counters for the numbers at the top of the file by running
$ ./scripts/delta
Then I commit the update (which needs to have the commit message RELEASE-NOTES: synced“) and push it to master. Done!
When I created and started hosting the first websites for curl I didn’t care about the URL or domain names used for them, but after a few years I started to think that maybe it would be cool to register a curl domain for its home. By then it was too late to find an available name under a “sensible” top-level domain and since then I’ve been on the lookout for one.
Yeah, I host it
So yes, I’ve administrated every machine that has ever hosted the curl web site going all the way back to the time before we called the tool curl. I’m also doing most of the edits and polish of the web content, even though I’m crap at web stuff like CSS and design. So yeah, I consider it my job to care for the site and make sure it runs smooth and that it has a proper (domain) name.
www.fts.frontec.se
The first ever curl web page was hosted on “www.fts.frontec.se/~dast/curl” in the late 1990s (snapshot). I worked for the company with that domain name at the time and ~dast was the location for my own personal web content.
curl.haxx.nu
The curl website moved to its first “own home”, with curl.haxx.nu in August 1999 (snapshot) when we registered our first domain and the .nu top-level domain was available to us when .se wasn’t.
curl.haxx.se
We switched from curl.haxx.nu to curl.haxx.se in the summer of 2000 (when finally were allowed to register our name in the .se TLD) (snapshot).
The name “haxx” in the domain has been the reason for many discussions and occasional concerns from users and overzealous blocking-scripts over the years. I’ve kept the curl site on that domain since it is the name of one of the primary curl sponsors and partly because I want to teach the world that a particular word in a domain is not a marker for badness or something like that. And of course because we have not bought or been provided a better alternative.
Haxx is still the name of the company I co-founded back in 1997 so I’m also the admin of the domain.
curl.se
I’ve looked for and contacted owners of curl under many different TLDs over the years but most have never responded and none has been open for giving up their domains. I’ve always had an extra attention put on curl.se because it is in the Swedish TLD, the same one we have for Haxx and where I live.
The curling background
The first record on archive.org of anyone using the domain curl.se for web content is dated August 2003 when the Swedish curling team “Härnösands CK” used it. They used the domain and website for a few years under this name. It can be noted that it was team Anette Norberg, which subsequently won two Olympic gold medals in the sport.
In September 2007 the site was renamed, still being about the sport curling but with the name “the curling girls” in Swedish (curlingtjejerna) which remained there for just 1.5 years until it changed again. “curling team Folksam” then populated the site with contents about the sport and that team until they let the domain expire in 2012. (Out of these three different curling oriented sites, the first one is the only one that still seems to be around but now of course on another domain.)
Ads
In early August 2012 the domain was registered to a new owner. I can’t remember why, but I missed the chance to get the domain then.
August 28 2012 marks the first date when curl.se is recorded to suddenly host a bunch of links to casino, bingo and gambling sites. It seems that whoever bought the domain wanted to surf on the good name and possible incoming links built up from the previous owners. For several years this crap was what the website showed. I doubt very many users ever were charmed by the content nor clicked on many links. It was ugly and over-packed with no real content but links and ads.
The last archive.org capture of the ad-filled site was done on October 2nd 2016. Since then, there’s been no web content on the domain that I’ve found. But the domain registration kept getting renewed.
Failed to purchase
In August 2019, I noticed that the domain was about to expire, and I figured it could be a sign that the owner was not too interested in keeping it anymore. I contacted the owner via a registrar and offered to buy it. The single only response I ever got was that my monetary offer was “too low”. I tried to up my bid, but I never got any further responses from the owner and then after a while I noticed that the domain registration was again renewed for another year. I went back to waiting.
Expired again
In September 2020 the domain was again up for expiration and I contacted the owner again, this time asking for a price for which they would be willing to sell the domain. Again no response, but this time the domain actually went all the way to expiry and deletion, which eventually made it available “on the market” for everyone interested to compete for the purchase.
I entered the race with the help of a registrar that would attempt to buy the name when it got released. When this happens, when a domain name is “released”, it becomes a race between all the potential buyers who want the domain. It is a 4-letter domain that is an English word and easy pronounceable. I knew there was a big risk others would also be trying to get it.
In the early morning of October 19th 2020, the curl.se domain was released and in the race of getting the purchase… I lost. Someone else got the domain before me. I was sad. For a while, until I got the good news…
Donated!
It turned out my friend Bartek Tatkowski had snatched the domain! After getting all the administrative things in order, Bartek graciously donated the domain to me and 15:00 on October 30 2020 I could enter my own name servers into the dedicated inputs fields for the domain, and configure it properly in our master and secondary DNS servers.
curl.se is the new home
Starting on November 4, 2020 curl.se is the new official home site for the curl project. The curl.haxx.se name will of course remain working for a long time more and I figure we can basically never shut it down as there are so many references to it spread out over the world. I intend to eventually provide redirects for most things from the old name to the new.
What about a www prefix? The jury is still out how or if we should use that or not. The initial update of the site (November 4) uses a www.curl.se host name in links but I’ve not done any automatic redirects to or from that. As the site is CDNed, and we can’t use CNAMEs on the apex domain (curl.se), we instead use anycast IPs for it – the net difference to users should be zero. (Fastly is a generous sponsor of the curl project.)
I also happen to own libcurl.se since a few years back and I’ll make sure using this name also takes you to the right place.
Why not curl.dev?
People repeatedly ask me. Names in the .dev domains are expensive. Registering curl.dev goes for 400 USD right now. curl.se costs 10 USD/year. I see little to no reason to participate in that business and I don’t think spending donated money on such a venture is a responsible use of our funds.
HTTP Strict Transport Security (HSTS) is a standard HTTP response header for sites to tell the client that for a specified period of time into the future, that host is not to be accessed with plain HTTP but only using HTTPS. Documented in RFC 6797 from 2012.
The idea is of course to reduce the risk for man-in-the-middle attacks when the server resources might be accessible via both HTTP and HTTPS, perhaps due to legacy or just as an upgrade path. Every access to the HTTP version is then a risk that you get back tampered content.
Browsers preload
These headers have been supported by the popular browsers for years already, and they also have a system setup for preloading a set of sites. Sites that exist in their preload list then never get accessed over HTTP since they know of their HSTS state already when the browser is fired up for the first time.
The entire .dev top-level domain is even in that preload list so you can in fact never access a web site on that top-level domain over HTTP with the major browsers.
With the curl tool
Starting in curl 7.74.0, curl has experimental support for HSTS. Experimental means it isn’t enabled by default and we discourage use of it in production. (Scheduled to be released in December 2020.)
You instruct curl to understand HSTS and to load/save a cache with HSTS information using --hsts <filename>. The HSTS cache saved into that file is then updated on exit and if you do repeated invokes with the same cache file, it will effectively avoid clear text HTTP accesses for as long as the HSTS headers tell it.
I envision that users will simply use a small hsts cache file for specific use cases rather than anyone ever really want to have or use a “complete” preload list of domains such as the one the browsers use, as that’s a huge list of sites and for most use cases just completely unnecessary to load and handle.
With libcurl
Possibly, this feature is more useful and appreciated by applications that use libcurl for HTTP(S) transfers. With libcurl the application can set a file name to use for loading and saving the cache but it also gets some added options for more flexibility and powers. Here’s a quick overview:
CURLOPT_HSTS – lets you set a file name to read/write the HSTS cache from/to.
CURLOPT_HSTSREADFUNCTION – this callback gets called by libcurl when it is about to start a transfer and lets the application preload HSTS entries – as if they had been read over the wire and been added to the cache.
CURLOPT_HSTSWRITEFUNCTION – this callback gets called repeatedly when libcurl flushes its in-memory cache and allows the application to save the cache somewhere and similar things.
Feedback?
I trust you understand that I’m very very keen on getting feedback on how this works, on the API and your use cases. Both negative and positive. Whatever your thoughts are really!
The other day we celebrated everything curlturning 5 years old, and not too long after that I got myself this printed copy of the Chinese translation in my hands!
If you would be interested in starting a translation of the book into another language, let me know and I’ll help you get started. Currently the English version consists of 72,798 words so it’s by no means an easy feat to translate! My other two other smaller books, http2 explained and HTTP/3 explained have been translated into twelve(!) and ten languages this way (and there might be more languages coming!).
A collection of printed works authored by yours truly!Inside the Chinese version – yes I can understand some headlines!
Unfortunately I don’t read Chinese so I can’t tell you how good the translation is!
I started learning how to program in my teens, well over thirty years ago and I’ve worked as a software engineer and developer since the early 1990s. My first employment as a developer was in 1993. I’ve since worked for and with lots of companies and I’ve worked on a huge amount of (proprietary) software products and devices over many years. Meaning: I certainly didn’t start my life open source. I had to earn it.
When I was 20 years old I did my (then mandatory) military service in Sweden. After having endured that, I applied to the university while at the same time I was offered a job at IBM. I hesitated, but took the job. I figured I could always go to university later – but life took other turns and I never did. I didn’t do a single day of university. I haven’t regretted it.
I learned to code in the mid 80s on a Commodore 64 and software development has been one of my primary hobbies ever since. One thing it taught me well, that I still carry with me, is to spend a few hours per day in front of my home computer.
And then I shipped curl
In the spring of 1998 I renamed my little pet project of the time again and I released the first ever curl release. I have told this story many times, but since then I have spent two hours or so of my spare time on that project – every day for over twenty years. While still working as a software engineer by day.
Over time, curl gradually grew popular and attracted more users. There was no sudden moment in time where I struck gold and everything took off. It was just slowly gaining ground while me and my fellow project members kept improving and polishing curl. At some point in time I happened to notice that curl and libcurl would appear in more and more acknowledgements and in open source license collections in products and devices.
It was still just a spare time project.
Proprietary Software for years
I’d like to emphasize that I worked as a contract and consultant developer for many years (over 20!), primarily on proprietary software and custom solutions, before I managed to land myself a position where I could primarily write open source as part of my job.
Mozilla
In 2014 I joined Mozilla and got the opportunity to work on the open source project Firefox for a living – and doing it entirely from my home. This was the first time in my career I actually spent most of my days on code that was made public and available to the world. They even allowed me to spend a part of my work hours on curl, even if that didn’t really help them and curl was not a fundamental part of any Mozilla work or products. It was still great.
I landed that job for Mozilla a lot thanks to my many years and long experience with portable network coding and running a successful open source project at this level.
My work setup with Mozilla made it possible for me to spend even more time on curl, apart from the (still going) two daily spare time hours. Nobody at Mozilla cared much about (my work with) curl and no one there even asked me about it. I worked on Firefox for a living.
For anyone wanting to do open source as part of their work, getting a job at a company that already does a lot of open source is probably the best path forward. Even if that might not be easy either, and it might also mean that you would have to accept working on some open source projects that you might not yourself be completely sold on.
In late 2018 I quit Mozilla, in part because I wanted to try to work with curl “for real” (and part other reasons that I’ll leave out here). curl was then already over twenty years old and was used more than ever before.
wolfSSL
I now work for wolfSSL. We sell curl support and related services to companies. Companies pay wolfSSL, wolfSSL pays me a salary and I get food on the table. This works as long as we can convince enough companies that this is a good idea.
The vast majority of curl users out there of course don’t pay anything and will never pay anything. We just need a small number of companies to do it – and it seems to be working. We help customers use curl better, we make curl better for them and we make them ship better products this way. It’s a win win. And I can work on open source all day long thanks to this.
My open source life-style
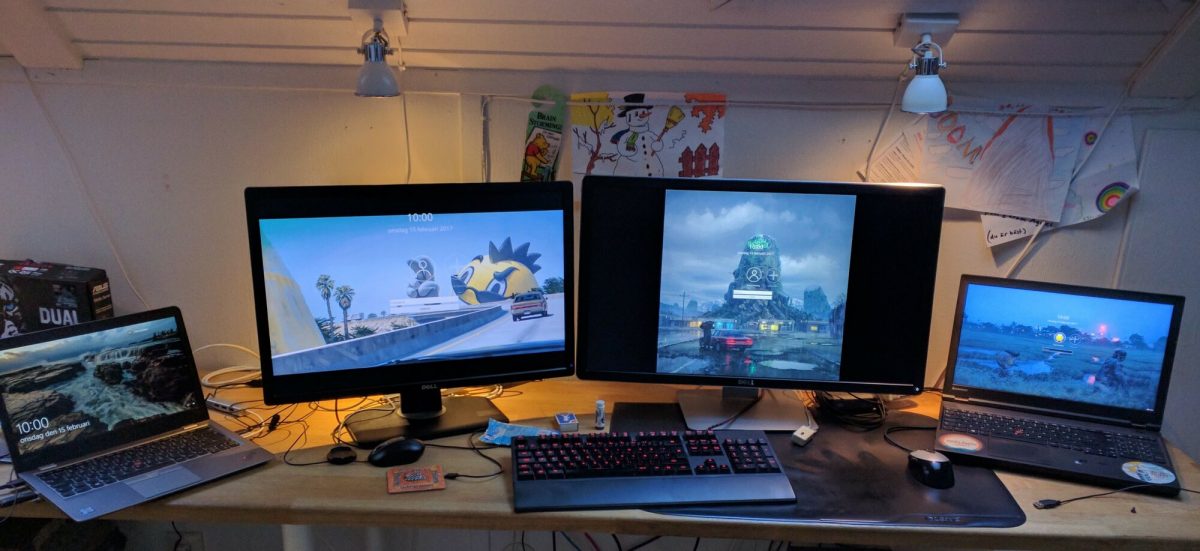
A normal day in the work week, I get up before 7 in the morning and I have breakfast with my family members: my wife and my two kids. Then I grab my first cup of coffee for the day and take the thirteen steps up the stairs to my “office”.
I sit down in front of my main development (Linux) machine with two 27″ screens and get to work.
Photo of my work desk from a few years ago but it looks very similar still today.
What work and in what order?
I lead the curl project. It means many questions and decisions fall down to me to have an opinion about or say on, and it’s a priority for me to make sure that I unblock such situations as soon as possible so that developers wanting to do things with curl can continue doing that.
Thus, I read and respond to email about curl all hours I’m awake and have network access. Of course incoming messages actually rarely require immediate responses and then I can queue them up and instead do them later. I also try to read and assess all new incoming curl issues as soon as possible to see if there’s something urgent I should deal with immediately, or otherwise figure out how to deal with them going forward.
I usually have a set of bugs or features to work on so when there’s no alarming email or GitHub issue left, I context-switch over to the curl source code tree and the particular branch in which I work on right now. I typically have 20-30 different branches of development of various stages and maturity going on. If I get stuck on something, or if I create a pull-request for one of them that needs time to get all the CI jobs done, I switch over to one of the others.
Customers and their needs of course have priority when I decide what to work on. The exception would perhaps be security vulnerabilities or other really serious bugs being reported, but thankfully they are rare. But after that, I go by ear and work on what I think is fun and what I think users might appreciate.
If I want to go forward with something, for my own sake or for a customer’s, and that entails touching or improving other software in other projects, then I don’t shy away from submitting pull requests for them – or at least filing an issue.
Spare time open source
Yes, I still spend my spare time hours on open source, mostly curl. This means I often end up spending 50-55 hours per week on curl and curl related activities. But I don’t count or measure work hours and I rarely have to report any to anyone. This is a work of love.
Lots of people will say that they don’t have time because of life, family, kids etc. I have of course been very fortunate over the years to have had the opportunity and ability to spend all this time on what I want to do, but let’s not forget that people in general spend lots of time on their hobbies; on watching TV, on playing computer games and on socializing with friends and why not: to sleep. If you cut down on all of those things (yes, including the sleeping) there could very well be opportunities. It’s often a question of priorities. I’ve made spare time development a priority in my life.
curl support?
Any company that uses curl or libcurl – and they are plenty – could benefit from buying support from us instead of wasting their own time and resources. We at wolfSSL are probably much better at curl already and we can find and fix the issues much faster, which ends up cheaper and better long-term.
Credits
The top photo is taken by Anja Stenberg, my wife. It’s me in a local forest, summer 2020.