This option is -4 as the short option and --ipv4 as the long, added in curl 7.10.8.
IP version
So why would anyone ever need this option?
Remember that when you ask curl to do a transfer with a host, that host name will typically be resolved to a list of IP addresses and that list will contain both IPv4 and IPv6 addresses. When curl then connects to the host, it will iterate over that list and it will attempt to connect to both IPv6 and IPv4 addresses, even at the same time in the style we call happy eyeballs.
The first connect attempt to succeed will be the one curl sticks to and will perform the transfer over.
When IPv6 acts up
In rare occasions or even in some setups, you may find yourself in a situation where you get back problematic IPv6 addresses in the name resolve, or the server’s IPv6 behavior seems erratic, your local config simply makes IPv6 flaky or things like that. Reasons you may want to ask curl to stick to IPv4-only to avoid a headache.
Then --ipv4 is here to help you.
--ipv4
First, this option will make the name resolving only ask for IPv4 addresses so there will be no IPv6 addresses returned to curl to try to connect to.
Then, due to the disabled IPv6, there won’t be any happy eyeballs procedure when connecting since there are now only addresses from a single family in the list.
It could perhaps be worth to stress that if the host name you target then doesn’t have any IPv4 addresses associated with it, the operation will instead fail when this option is used.
Example
curl --ipv4 https://example.org/
Related options
The reversed request, ask for IPv6 only is done with the --ipv6 option.
There are also options for specifying other protocol versions, in particular for example HTTP with --http1.0, --http1.1, --http2 and --http3 or for TLS with --tslv1, --tlsv1.2, --tlsv1.3 and more.
Neither a visa or a rejection yet, exactly two years since I completed my US visa application. Not a lot more to say that I haven’t already said before on this subject.
Of course I’m not surprised that I won’t get an approval in these travel-restricted Covid-19 times – as it would be a fine irony to get a visa and then not be allowed to travel anyway due to a general travel ban – but it also seems like the US immigration authorities haven’t yet used the pandemic as an excuse to (finally) just deny my application.
I was first prevented from traveling to the US on June 26 2017 (on ESTA) but it wasn’t until the following spring that I applied for a visa in an attempt to rectify the situation.
As so many other events in these mysterious times, the foss-north conference went online-only and on March 30, 2020 I was honored to be included among the champion speakers at this lovely conference and I talked about how to “curl better” there.
The talk is a condensed run-through of how curl works and why, and then a look into how some of the more important HTTP oriented command line options work and how they’re supposed to be used.
As someone pointed out: I don’t do a lot of presentations about the curl tool. Maybe I should do more of these.
curl is widely used but still most users only use a very small subset of options or even just copy their command line from somewhere else. I think more users could learn to curl better. Below is the video of this talk.
Doing a talk to a potentially large audience in front of your laptop in completely silence and not seeing a single audience member is a challenge. No “contact” with the audience and no feel for if they’re all going to sleep or seem interested etc. Still I have the feeling that this is the year we all are going to do this many times and hopefully get better at it over time…
Both browsers have paused or conditioned their efforts to not take the final steps during the Covid-19 outbreak, but they will continue and the outcome is given: FTP support in browsers is going away. Soon.
curl
curl supported both uploads and downloads with FTP already in its first release in March 1998. Which of course was many years before either of those browsers mentioned above even existed!
In the curl project, we work super hard and tirelessly to maintain backwards compatibility and not break existing scripts and behaviors.
For these reasons, curl will not drop FTP support. If you have legacy systems running FTP, curl will continue to have your back and perform as snappy and as reliably as ever.
FTP the protocol
FTP is a protocol that is quirky to use over the modern Internet mostly due to its use of two separate TCP connections. It is unencrypted in its default version and the secured version, FTPS, was never supported by browsers. Not to mention that the encrypted version has its own slew of issues when used through NATs etc.
To put it short: FTP has its issues and quirks.
FTP use in general is decreasing and that is also why the browsers feel that they can take this move: it will only negatively affect a very minuscule portion of their users.
Legacy
FTP is however still used in places. In the 2019 curl user survey, more than 29% of the users said they’d use curl to transfer FTP within the last two years. There’s clearly a long tail of legacy FTP systems out there. Maybe not so much on the public Internet anymore – but in use nevertheless.
Alternative protocols?
SFTP could have become a viable replacement for FTP in these cases, but in practice we’ve moved into a world where HTTPS replaces everything where browsers are used.
This is the 25th transfer protocol added to curl. The first new addition since we added SMB and SMBS back in November 2014.
Background
Back in early 2019, my brother Björn Stenberg brought a pull request to the curl project that added support for MQTT. I tweeted about it and it seemed people were interested in seeing this happen.
Time passed and Björn unfortunately didn’t manage to push his work forward and instead it grew stale and the PR eventually was closed due to that inactivity later the same year.
Roadmap 2020
In my work trying to go over and figure out what I want to see in curl the coming year and what we (wolfSSL) as a company would like to see being done, MQTT qualified as a contender for the list. See my curl roadmap 2020 video.
It’s happening again
I grabbed Björn’s old pull-request and rebased it onto git master, fixed a few minor conflicts and small cleanups necessary and then brought it further. I documented two of my early sessions on this, live-streamed on twitch. See MQTT in curl and MQTT part two below:
Polish
Björn’s code was an excellent start but didn’t take us all the way.
I wrote an MQTT test server, created a set of test cases, made sure the code worked for those test cases, made it more solid and more. It is still early days and the MQTT support is basic and comes with several caveats, but it’s slowly getting there.
MQTT – really?
When I say that MQTT almost fits the curl concepts and paradigms, I mean that you can consider what an MQTT client does to be “sending” and “receiving” and you can specify that with a URL.
Fetching an MQTT URL with curl means doing SUSCRIBE on a topic and waiting for that to arrive and get the payload sent to the output.
Doing the equivalent of a HTTP POST with curl, like with the command line’s -d option makes an MQTT PUBLISH and sends a payload to a topic.
Rough corners and wrong assumptions
I’m an MQTT rookie. I’m sure there will be mistakes and I will have misunderstood things. The MQTT will be considered experimental for a time forward so that people will get a chance to verify the functionality and we have a chance to change and correct the worst decisions and fatal mistakes. Remember that for experimental features in curl, we reserve ourselves the right to change behavior, API and ABI so nobody should ship such features enabled anywhere without first thinking it through very carefully!
If you’re a person who think MQTT in curl would be useful, good or just fun and you have use cases or ideas where you’d want to use this. Please join in and try and let us know how it works and what you think we should polish or fix to make it truly stellar!
The code is landed in the master branch since PR 5173 was merged. The code will be present in the coming 7.70.0 release, due to ship on April 29 2020.
TODO
As I write this, the MQTT support is still very basic. I want a first version out to users as early as possible as I want to get feedback and comments to help verify that we’re in the right direction and then work on making the support of the protocol more complete. TLS, authentication, QoS and more will come as we proceed. Of course, if you let me know what we must support for MQTT to make it interesting for you, I’ll listen! Preferably, you do the discussions on the curl-library mailing list.
We’ve only just started.
Credits
The initial MQTT patch that kicked us off was written by Björn Stenberg. I brought it forward from there, bug-fixed it, extended it, added a test server and test cases and landed the lot in the master branch.
--append is the long form option, -a is the short. The option has existed since at least May 1998 (present in curl 4.8). I think it is safe to say that if we would’ve created this option just a few years later, we would not have “wasted” a short option letter on it. It is not a very frequently used one.
Append remotely
The append in the option name is a require to the receiver to append to — rather than replace — a destination file. This option only has any effect when uploading using either FTP(S) or SFTP. It is a flag option and you use it together with the --upload option.
When you upload to a remote site with these protocols, the default behavior is to overwrite any file that happens to exist on the server using the name we’re uploading to. If you append this option to the command line, curl will instead instruct the server to append the newly uploaded data to the end of the remote file.
The reason this option is limited to just subset of protocols is of course that they are the only ones for which we can give that instruction to the server.
Example
Append the local file “trailer” to the remote file called “begin”:
Mar 31 2020, 11:13:38: I get a message from Frank in the #curl IRC channel over on Freenode. I’m always “hanging out” on IRC and Frank is a long time friend and fellow frequent IRCer in that channel. This time, Frank informs me that the curl web site is acting up:
“I’m getting 403s for some mailing list archive pages. They go away when I reload”
That’s weird and unexpected. An important detail here is that the curl web site is “CDNed” by Fastly. This means that every visitor of the web site is actually going to one of Fastly’s servers and in most cases they get cached content from those servers, and only infrequently do these servers come back to my “origin” server and ask for an updated file to send out to a web site visitor.
A 403 error for a valid page is not a good thing. I started checking out some of my logs – which then only are for the origin as I don’t do any logging at all at CDN level (more about that later) – and I could verify the 403 errors. So they’re in my log meaning it isn’t caused by (a misconfiguration of) the CDN. Why would a perfectly legitimate URL suddenly return 403 to have it go away again after a reload?
Why does he get a 403?
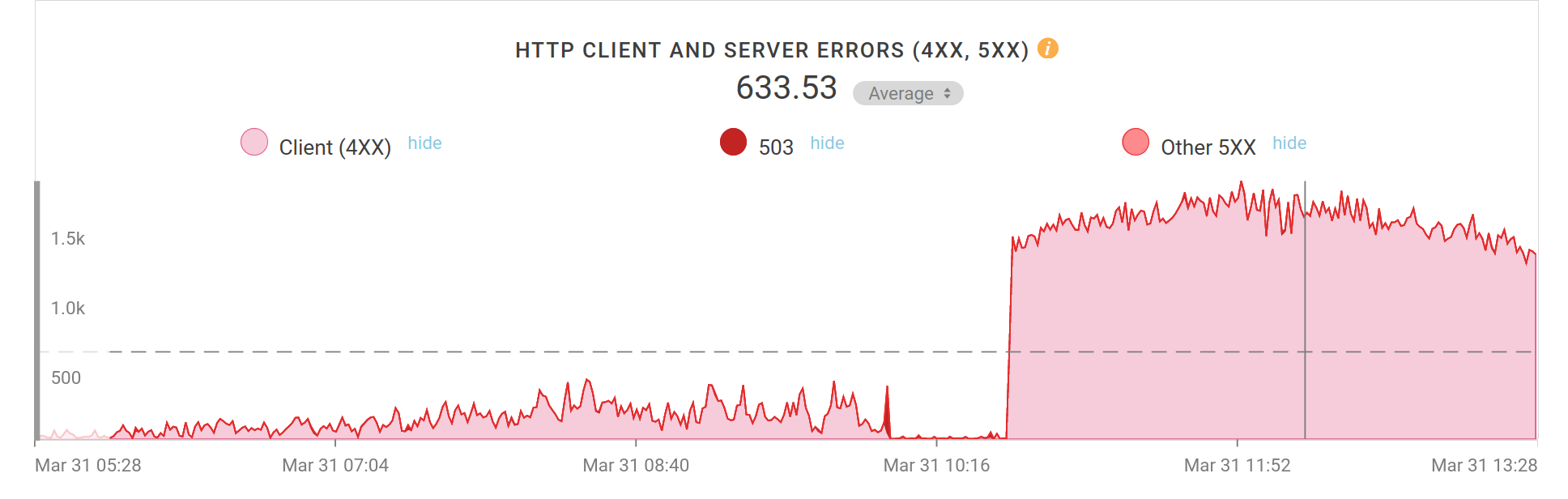
I took a look at Fastly’s management web interface and I spotted that the curl web site was sending out data at an unusual high speed at the moment. An average speed of around 50mbps, while we typically average at below 20. Hm… something is going on.
While I continued to look for the answers to these things I noted that my logs were growing really rapidly. There were POSTs being sent to the same single URL at a high frequency (10-20 reqs/second) and each of those would get some 225Kbytes of data returned. And they all used the same User-agent: QQGameHall. It seems this started within the last 24 hours or so. They’re POSTs so Fastly basically always pass them through to my server.
Before I could figure out Franks’s 403s, I decided to slow down this madness by temporarily forbidding this user-agent access so that the bot or program or whatever would notice it starts to fail, and it would of course then stop bombarding the site.
Deny
Ok, a quick deny of the user-agent made my server start responding with 403s to all those requests and instead of a 225K response it now sent back 465 bytes per request. The average bandwidth on the site immediately dropped down to below 20Mbps again. Back to looking for Frank’s 403-problem
First the 403s seen due to the ratelimiting, then I removed the ratelmiting and finally I added a block of the user-agent. Screenshotted error rates from Fastly’s admin interface. This is errors per minute.
The answer was pretty simple and I didn’t have to search a lot. The clues existed in the error logs and it turned out we had “mod_evasive” enabled since another heavy bot load “attack” a while back. It is a module for “rate limiting” incoming requests and since a lot of requests to our server now comes from Fastly’s limited set of IP addresses and we had this crazy QQ thing hitting us, my server would return a 403 every now and then when it considered the rate too high.
I whitelisted Fastly’s requests and Frank’s 403 problems were solved.
Deny a level up
The bot traffic showed no sign of slowing down. Easily 20 requests per second, to the same URL and they all get an error back and obviously they don’t care. I decided to up my game a little so with help, I moved my blocking of this service to Fastly. I now block their user-agent already there so the traffic doesn’t ever reach my server. Phew, my server was finally back to its regular calm state. They way it should be.
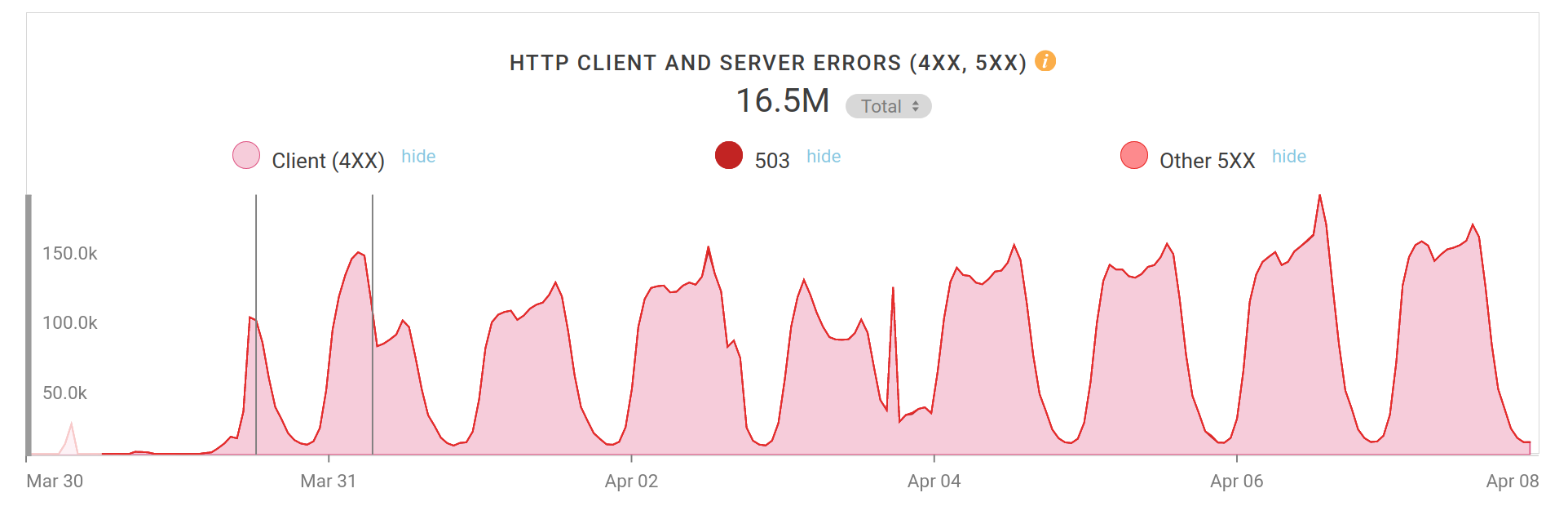
It doesn’t stop there. Here’s a follow-up graph I just grabbed, a little over a week since I started the blocking. 16.5 million blocked requests (and counting). This graph here shows number of requests/hour on the Y axis, peeking at almost 190k; around 50 requests/second. The load is of course not actually a problem, just a nuisance now. QQGameHall keeps on going.
Errors per hour over the period of several days.
QQGameHall
What we know about this.
Friends on Twitter and googling for this name informs us that this is a “game launcher” done by Tencent. I’ve tried to contact them via Twitter (as I have no means of contacting them otherwise that seems even remotely likely to work).
I have not checked what these user-agent POSTs, because I didn’t log that. I suspect it was just a zero byte POST.
The URL they post to is the CA cert bundle file with provide on the curl CA extract web page. The one we convert from the Mozilla version into a PEM for users of the world to enjoy. (Someone seems to enjoy this maybe just a little too much.)
The user-agents seemed to come (mostly) from China which seems to add up. Also, the look of the graph when it goes up and down could indicate an eastern time zone.
This program uses libcurl. Harry in the #curl channel found files in Virus Total and had a look. It is, I think, therefore highly likely that this “storm” is caused by an application using curl!
My theory: this is some sort of service that was deployed, or an upgrade shipped, that wants to get an updated CA store and they get that from our site with this request. Either they get it far too often or maybe there are just a very large amount them or similar. I cannot understand why they issue a POST though. If they would just have done a GET I would never have noticed and they would’ve fetched perfectly fine cached versions from the CDN…
Feel free to speculate further!
Logging, privacy, analytics
I don’t have any logging of the CDN traffic to the curl site. Primarily because I haven’t had to, but also because I appreciate the privacy gain for our users and finally because handling logs at this volume pretty much requires a separate service and they all seem to be fairly pricey – for something I really don’t want. So therefore I don’t see the source IP addresses these things. (But yes, I can ask Fastly to check and tell me if I really really wanted to know.)
Also: I don’t run any analytics (Google or otherwise) on the site, primarily for privacy reasons. So that won’t give me that data or other clues either.
Update: it has been proposed I could see the IP address in the X-Forwarded-For: headers and it seems accurate. Of course I didn’t log that header during this period but I will consider starting doing it for better control and info in the future.
Update 2: As of May 18 2020, this flood has not diminished. Logs show that we still block about 5 million requests/day from this service, peaking at over 100 requests/minute.
This is one of the original 24 command line options that existed already in the first ever curl release in the spring of 1998. The -v option’s long version is --verbose.
Note that this uses the lowercase ‘v’. The uppercase -V option shows detailed version information.
So use it!
In a blog post series of curl command line options you’d think that this option would basically be unnecessary to include since it seems to basic, so obvious and of course people know of it and use it immediately to understand why curl invokes don’t behave as expected!
Time and time again the first response to users with problems is to please add –verbose to the command line. Many of those times, the problem is then figured out, understood and sorted out without any need of further help.
--verbose should be the first action to try for everyone who runs a curl command that fails unexplainably.
What verbose shows
First: there’s only one verbosity level in curl. There’s normal and there’s verbose. Pure binary; on or off. Adding more -v flags on the same line won’t bring you more details. In fact, adding more won’t change anything at all other than making your command line longer. (And yes, you have my permission to gently taunt anyone you see online who uses more than one -v with curl.)
Verbose mode shows outgoing and incoming headers (or protocol commands/responses) as well as “extra” details that we’ve deemed sensible in the code.
For example you will get to see which IP addresses curl attempts to connect to (that the host name resolved to), it will show details from the server’s TLS certificate and it will tell you what TLS cipher that was negotiated etc.
-v shows details from the protocol engine. Of course you will also see different outputs depending on what protocol that’s being used.
What verbose doesn’t show
This option is meant to help you understand the protocol parts but it doesn’t show you everything that’s going on – for example it doesn’t show you the outgoing protocol data (like the HTTP request body). If -v isn’t enough for you, then the --trace and --trace-ascii options are there for you.
If you are in the rare situation where the trace options aren’t detailed enough, you can go all-in with full SSLKEYLOGFILE mode and inspect curl’s network traffic with Wireshark.
Less verbose?
It’s not exactly “verbose level” but curl does by default for example show a progress meter and some other things. You can silence curl completely by using -s (--silent) or use the recently introduced option --no-progress-meter.
I’m honored to – once again – be a recipient of this award Google hands out to open source contributors, annually. I was previously awarded this in 2011.
I don’t get a lot of awards. Getting this token of appreciation feels awesome and I’m humbled and grateful I was not only nominated but also actually selected as recipient. Thank you, Google!
Nine years ago I got 350 USD credits in the Google store and I got my family a set of jackets using them – my kids have grown significantly since then, so to them those black beauties are now just a distant memory, but I still actually wear mine from time to time!
curl beers and curl stickers!
This time, the reward comes with a 250 USD “payout” (that’s the gift mentioned in the mail above), as a real money transfer that can be spent on other things than just Google merchandise!
I’ve decided to accept the reward and the money and I intend to spend it on beer and curl stickers for my friends and fans. As I prefer to view it: