When I (in spite of knowing better) talk to ordinary people about what I do for a living and the project I work on, one of the details about it that people have the hardest time to comprehend, is the fact that I really and truly don’t know a lot about who uses my code. (Or where. Or what particular features they use.)
I work on curl full-time and we ship releases frequently. Users download the curl source code from us, build curl and put it to use. Most of “my” users never tell me or anyone else in the curl project that they use curl or libcurl. This is of course perfectly fine and I probably could not even handle the flood if every user would tell me.
This not-knowing is a most common situation for Open Source authors and projects. It is not unique for me.
The not knowing your users is otherwise unusual in a world of products and software, and quite frankly, sometimes it is an obstacle for us as well since we lack a good way to communicate with users about plans, changes or ideas. It also makes it really hard to estimate our own success and the always-recurring question: how many users do you have?
To be fair: I do know quite a lot of users as well. But I don’t know how representative they are, nor how big fraction of the totals they consist of etc.
A user of my project runs into an issue and asks for help in a project forum – without hiding where they come from or what product they make.
While vanity-searching I find my project’s Open Source license mentioned for or bundled with a product or tool or device.
A user emails me asking funny questions about a product I never heard of, and then I realize they found my email because that product uses my code and the license has my email in it.
The REUSE project is an effort to make Open Source projects provide copyright and license information (for all files) in a machine readable way.
When a project is fully REUSE compliant, you can easily figure out the copyright and license situation for every single file it holds.
The easiest way to accomplish this is to make sure that all files have the correct header with the appropriate copyright info and SPDX-License-Identifier specified, but it also has ways to provide that meta data in adjacent files – for files where prepending that info isn’t sensible.
What we needed to do
We were already in a fairly good place before this push. We have a script that verifies the presence of copyright header in files (including checking the end year vs the latest git commit), with a list of files that were deliberately skipped.
The biggest things we needed to do were
Add the SPDX identifier all over
Make sure that the skipped files also have copyright and licensing info provided
Add a CI job that verifies that we remain compliant
I also ended up adjusting our own copyright scan script to use the REUSE metadata files instead of its own ignore filters which also made it even easier for us to make sure we are and remain compatible — that every single files in the curl git repository has a known and documented license and copyright situation.
As a bonus, the cleanup work helped us detect an example file that stood out which we got relicensed and we removed two older files that had their own unique licenses (without any good reason).
There are 3518 files in the curl git repository this exact moment.
Compliant!
Starting mid-June 2022, curl is 100% REUSE compliant. curl 7.84.0 will be the first release done in this status.
Motivation
I think it is a good idea to have perfect control over the copyright and license situation for every single file, and to make sure that the situation is documented enough and to a level that allows anyone and everyone to check it out and learn how things lie. No surprises.
Companies have obviously figured out this info before to a degree that they have been satisfied with since curl is widely used even commercial since a long time. But I believe that by providing the information in an even easier and more descriptive way makes things even better. For existing and future users.
I also think that the low threshold for us to reach this compliance was a factor. We were almost there already. We just need to polish up some small details and I think it made it worth it.
This cleanup also makes sure we have perfect control and knowledge of the license situation, now and going forward. I think this can be expected from a project aiming for gold standard.
The curl SPDX license identifier
Keen readers will notice that curl has its own license identifier. It is called the curl license. Not MIT, X or a BSD variation. curl.
The reason for this is good old stupidity. In January 2001 we adopted the MIT license for use in the project because we believed it better matches what we want compared to the previous license situation. We started out with a dual license situation together with the MPL license we used previously, but the MPL part was removed completely in October 2002.
For reasons that have since been forgotten, we thought it was a good idea to edit the license text. To trim it a little. Since August 2002, the license text that started out as an MIT/X license is no longer a perfect copy. It is a derivative . Very similar and almost identical. But it’s not the same.
When the SPDX project created their set of identifiers for well-used licenses out in the FOSS world they decided that the curl license is different enough from the MIT/X license to treat it separately and give it its own identifier. I know of no other project than curl that uses this particular edited version of the MIT license.
In hindsight, I believe the editing of the license text back in 2002 was dumb. I regret it, but I will not change it again. I think we can live with this situation pretty good.
Credits
Most of the heavy lifting necessary to make curl compliant was done by Max Mehl.
I’m not in the US and I’m not a US citizen but I felt I should help out when asked and I was able to.
On April 21 2022, I joined the video meeting together with an OpenSSL and a Tomcat contributor and several members of the board. (I am not naming any names of participants in this post because I have not asked for permission nor do I think the names are important here.)
For about an hour we talked to the board how we develop Open Source, how we take on security problems and how we work on making sure we do things as securely as we can. It was striking how similarly the three of us looked at the issues and how we work in our project, despite our projects all being different and having our own specifics.
As projects, we believe we have pretty well-established and working procedures for getting problems reported and we think we fix the issues fairly swiftly. We ship fixes, advisories and updates not long after the issues get known. The CVE system where we register and publish security vulnerabilities in a global registry is working adequately. (I’m not saying things are perfect.)
The main problem
It was pretty clear to me that we agreed that the biggest problem in the Open Source supply chain today is the slow uptake in patching vulnerable software.
Lots of vendors and products have not been made or have any plans for how to handle upgrades when vulnerabilities are found. Many of those that do act, do that with such glacier like speeds that users of such products remain exposed for attackers for a long period after the flaws are already fixed and have become known.
My own analysis of this is that such vendors of course do this because its the cheapest way. Plain capitalistic reasons.
Addressing this is hard
If we had any easy fixes for this, we would already have them in progress. We were also asked by the board what kind of systems that we would not like to see.
Will Software Bill Of Materials (SBOM) fix this? Maybe it can help, by exposing to the world what software and versions are used in products, but it will certainly depend on how it is used and enforced. If done too heavy-handed, it risks causing overhead and added complications but in the other end it might end up too wishy-washy.
Ended there
This was just an hour of conversation with a few follow-up clarifying emails. I hope that we were able to provide insights into how Open Source is made but I have no illusions of us changing anything in drastic ways.
I felt honored to represent “my kind” and help sharing knowledge of Open Source to areas of the world that might not always get informed about it.
– Everything I know and learned about running and maintaining Open Source projects for three decades.
For several years now, I have had a blog post series in mind to describe something about what people could expect to happen in Open Source projects. I had a few already half-started blog post drafts for some sub topics.
I couldn’t really make up my mind how to craft a series of blog posts about this wide topic in a sensible way so I kept postponing it for later. I did this for years.
A book, it has to be a book
It just dawned on my one day: the only way to get all this into a comprehensible way that also can hold all the thoughts I would like it to have, is to put it into a book. By book, I mean a document. An essay. A collection of pages. A booklet maybe. I don’t know how many words it might end up to become and I have no illusions of it ever ending up in print.
I mean to write the document in the open and provide it for free, online. Open Source style.
Day one
I grabbed my original draft for my blog series “You can expect this in your Open Source project”. I had worked on that document in the background for a long time, adding some little thing here and there over years – and it now had maybe twenty-five “lessons” listed with a short paragraph of text next to each.
I also had started three blog posts based on such lessons that were in pending state here on daniel.haxx.se in my queue of drafts.
I first copied the blog post content back into the text file from those potential blog posts, before I deleted them, and converted the entire file to markdown.
I then grouped the “lessons” I had listed in the markdown file and moved them into a few different sections. Like what to expect, code, money, people and project. I put subtitles into separate files for those five main areas.
How hard can it be?
I didn’t want to do a lot of work before I put the thing into git, and I didn’t want to run any private git repository so I had to make a new repo with a name. I went with “How hard can it be” as a working title and created the repo on GitHub. On April 6 I made the first git push with initial contents to that repository.
The first external contributor appeared after just a few minutes with the first pull-request fixing typos. Clearly people are following me on GitHub and spotted the creating of the repository and checked out what it was. I hadn’t told anyone or given any pointers.
I started expanding on subjects in the book.
Let’s get a real title
In the evening of April 7 I posted this question on Twitter:
I got a flood of replies. Lots of good ones and also lots of fun and sarcastic ones. The one that I think really talked to me the best was also the shortest: Uncurled.
It’s short and sweet
It includes a reference to curl without saying it is “a curl book” (it isn’t)
The topic is a bit about “untangling” and curl is a project that probably has taught me the most of what I include here
It sounds a little like “debriefed” from the curl project, and it is…
I can put it up on the domain name un.curl.dev
I figured I could possibly go with a longer subtitle that could explain the book more: “Everything I know and learned about running and maintaining Open Source projects”.
A name
I renamed the GitHub repository and added a description there. I created the URL (by adding the “un” CNAME entry in the “curl.dev” domain) and I setup gitbook.com to render the content to appear on un.curl.dev.
With a little more thoughts and then spilling some beans about my plans in my weekly report on April 8 (but not leaking the URL or repo to anyone yet) that made people provide some more ideas, I added more content.
10,000 words
By the evening of April 9, I surpassed 10,000 words of contents. Still having the contents and the order of everything pretty much in flux and not yet sorted out.
20,000 words
On April 25, I surpassed 20,000 words. It starts to look like something I can announce soon.
Getting there, but not done
The uncurled book is now in a state I think I can show off without feeling embarrassed. I believe I will still need to work on it more going forward to add and polish content and make it more coherent and less of a collection of snippets. I hope that I over time can settle down and gradually slow down the change pace. It will of course also depend a lot on the feedback I get.
Cover
Since it doesn’t exist physically and probably never will, I don’t think it actually needs a cover image, but it would probably be cool to still have one to use as an image and symbol for the book. If someone has a good idea or feels artistically inclined to make one, let me know!
I didn’t expect this, and this year I wasn’t asked ahead of time if I wanted to receive this gift. It is however something of a collector’s item that I find very enjoyable.
I received my GitHub contribution matrix printed in steel. This is my 2021 contribution skyline. (Click the images for higher resolution.)
The thing is surprisingly heavy and sturdy. If I had papers lying around, this would an awesome paper press.
You might remember that I got a similar gift last year, so it felt natural to do a comparison shot of 2021 and 2020.
For 2020, GitHub counted 2,466 contributions, while I reached 2,543 in 2021. Very similar numbers, but clearly distributed very differently. The two matrix images look like this.
2020
2021
Letter
Enclosed with this gift was also a friendly and encouraging letter.
It was a while since I last spoke Swedish on a podcast. I joined the friendly hosts Sebastian and Alex of the Trevlig Mjukvara (translates to something like “Nice Software”) podcast and we talked software development, open source, curl, Mozilla and a few other topics for an hour. I had a great time. (We had Jitsi act up on us more than once so we had to switch away from it mid-recording!)
On Friday January 21, 2022 I received this email. I tweeted about it and it took off like crazy.
The email comes from a fortune-500 multi-billion dollar company that apparently might be using a product that contains my code, or maybe they have customers who do. Who knows?
My guess is that they do this for some compliance reasons and they “forgot” that their open source components are not automatically provided by “partners” they can just demand this information from.
I answered the email very briefly and said I will be happy to answer with details as soon as we have a support contract signed.
I think maybe this serves as a good example of the open source pyramid and users in the upper layers not at all thinking of how the lower layers are maintained. Building a house without a care about the ground the house stands on.
In my tweet and here in my blog post I redact the name of the company. I most probably have the right to tell you who they are, but I still prefer to not. (Especially if I manage to land a profitable business contract with them.) I suspect we can find this level of entitlement in many companies.
The level of ignorance and incompetence shown in this single email is mind-boggling.
While they don’t even specifically say which product they are using, no code I’ve ever been involved with or have my copyright use log4j and any rookie or better engineer could easily verify that.
In the picture version of the email I padded the name fields to better anonymize the sender, and in the text below I replaced them with NNNN.
(And yes, it is very curious that they send queries about log4j now, seemingly very late.)
Continue down for the reply.
The email
Dear Haxx Team Partner,
You are receiving this message because NNNN uses a product you developed. We request you review and respond within 24 hours of receiving this email. If you are not the right person, please forward this message to the appropriate contact.
As you may already be aware, a newly discovered zero-day vulnerability is currently impacting Java logging library Apache Log4j globally, potentially allowing attackers to gain full control of affected servers.
The security and protection of our customers' confidential information is our top priority. As a key partner in serving our customers, we need to understand your risk and mitigation plans for this vulnerability.
Please respond to the following questions using the template provided below.
1. If you utilize a Java logging library for any of your application, what Log4j versions are running?
2. Have there been any confirmed security incidents to your company?
3. If yes, what applications, products, services, and associated versions are impacted?
4. Were any NNNN product and services impacted?
5. Has NNNN non-public or personal information been affected?
6. If yes, please provide details of affected information NNNN immediately.
7. What is the timeline (MM/DD/YY) for completing remediation? List the NNNN steps, including dates for each.
8. What action is required from NNNN to complete this remediation?
In an effort to maintain the integrity of this inquiry, we request that you do not share information relating to NNNN outside of your company and to keep this request to pertinent personnel only.
Thank you in advance for your prompt attention to this inquiry and your partnership!
Sincerely,
NNNN Information Security
The information contained in this message may be CONFIDENTIAL and is for the intended addressee only. Any unauthorized use, dissemination of the information, or copying of this message is prohibited. If you are not the intended addressee, please notify the sender immediately and delete this message.
Their reply
On January 24th I received this response, from the same address and it quotes my reply so I know they got it fine.
Hi David,
Thank you for your reply. Are you saying that we are not a customer of your organization?
/ [a first name]
My second reply
I replied again (22:29 CET on Jan 24) to this mail that identified me as “David”. Now there’s this great story about a David and some giant so I couldn’t help myself…
Hi Goliath,
No, you have no established contract with me or anyone else at Haxx whom you addressed this email to, asking for a lot of information. You are not our customer, we are not your customer. Also, you didn't detail what product it was regarding.
So, we can either establish such a relationship or you are free to search for answers to your questions yourself.
I can only presume that you got our email address and contact information into your systems because we produce a lot of open source software that are used widely.
Best wishes,
Daniel
The image version of the initial email
The company
Update on February 9: The email came from MetLife.
The well-known log4j security vulnerability of December 2021 triggered a lot of renewed discussions around software supply chain security, and sometimes it has also been said to be an Open Source related issue.
This was not the first software component to have a serious security flaw, and it will not be the last.
What can we do about it?
This is the 10,000 dollar question that is really hard to answer. In this post I hope to help putting some light on to why it is such a hard problem. This comes from my view as an Open Source author and contributor since almost three decades now.
In this post I’m going to talk about security as in how we make our products have less bugs in the code we write and land on purpose. There is also a lot to be said about infrastructure problems such as consumers not verifying dependencies so that when malicious actors purposely destroy a component, users of that don’t notice the problem or supply chain security issues that risk letting bad actors insert malicious code into components. But those are not covered in this blog post!
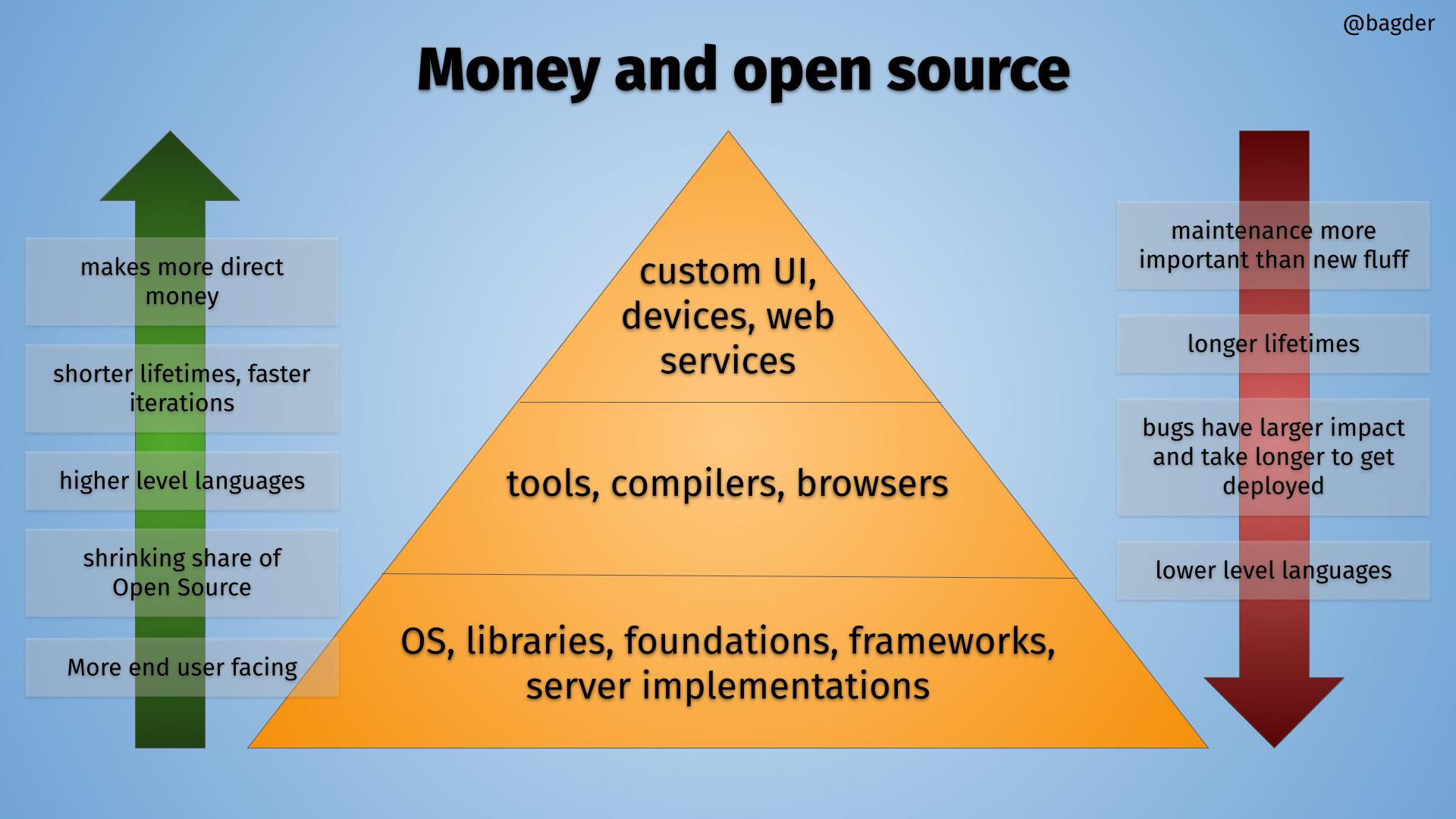
The OSS Pyramid
I think we can view the world of software and open source as a pyramid, and I made this drawing to illustrate.
The OSS pyramid, click for bigger version.
Inside the pyramid there is a hierarchy where things using software are build on top of others, in layers. The higher up you go, the more you stand on the shoulders of open source components below you.
At the very bottom of the pyramid are the foundational components. Operating systems and libraries. The stuff virtually everything runs or depends upon. The components you really don’t want to have serious security vulnerabilities.
Going upwards
In the left green arrow, I describe the trend if you look at software when climbing upwards the pyramid.
Makes more direct money
Shorter lifetimes, faster iterations
Higher level languages
Shrinking share of Open Source
More end user facing
At the top, there are a lot of things that are not Open Source. Proprietary shiny fronts with Open Source machines in the basement.
Going downwards
In the red arrow on the right, I describe the trend if you look at software when going downwards in the pyramid.
Maintenance is more important than new fluff
Longer lifetimes
Bugs have larger impact, fixes take longer to get deployed
Lower level languages
At the bottom, almost everything is Open Source. Each component in the bottom has countless users depending on them.
It is in the bottom of the pyramid each serious bug has a risk of impacting the world in really vast and earth-shattering ways. That is where tightening things up may have the most positive outcomes. (Even if avoiding problems is mostly invisible unsexy work.)
Zoom out to see the greater picture
We can argue about specific details and placements within the pyramid, but I think largely people can agree with the greater picture.
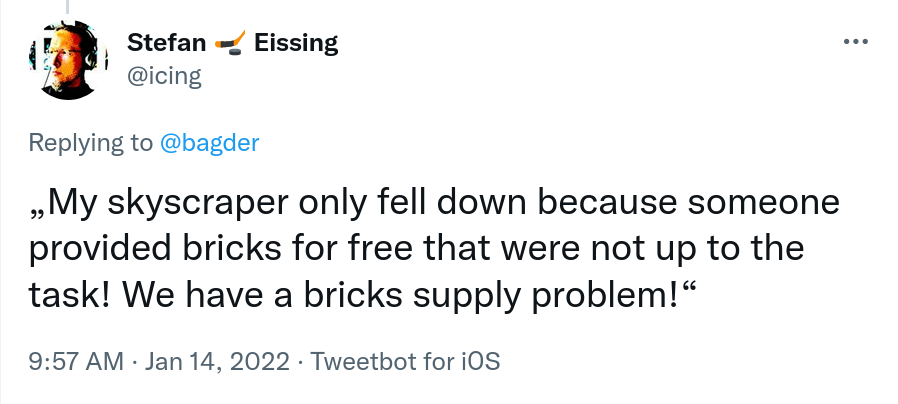
Skyscrapers using free bricks
A little quote from my friend Stefan Eissing:
As a manufacturer of skyscrapers, we decided to use the free bricks made available and then maybe something bad happened with them. Where is the problem in this scenario?
Market economy drives “good enough”
As long as it is possible to earn a lot of money without paying much for the “communal foundation” you stand on, there is very little incentive to invest in or pay for maintenance of something – that also incidentally benefits your competitors. As long as you make (a lot of) money, it is fine if it is “good enough”.
Good enough software components will continue to have the occasional slip-ups (= horrible security flaws) and as long as those mistakes don’t truly hurt the moneymakers in this scenario, this world picture remains hard to change.
However, if those flaws would have a notable negative impact on the mountains of cash in the vaults, then something could change. It would of course require something extraordinary for that to happen.
What can bottom-dwellers do
Our job, as makers of bricks in the very bottom of the pyramid, is to remind the top brass of the importance of a solid foundation.
Our work is to convince a large enough share of software users higher up the stack that are relying on our functionality, that they are better off and can sleep better at night if they buy support and let us help them not fall into any hidden pitfalls going forward. Even if this also in fact indirectly helps their competitors who might rely on the very same components. Having support will at least put them in a better position than the ones who don’t have it, if something bad happens. Perhaps even make them avoid badness completely. Paying for maintenance of your dependencies help reduce the risk for future alarm calls far too early on a weekend morning.
This convincing part is often much easier said than done. It is only human to not anticipate the problem ahead of time and rather react after the fact when the problem already occurred. “We have used this free product for years without problems, why would we pay for it now?”
Software projects with sufficient funding to have engineer time spent on the code should be able to at least make serious software glitches rare. Remember that even the world’s most valuable company managed to ship the most ridiculous security flaw. Security is hard.
All producers of code should make sure dependencies of theirs are of high quality. High quality here, does not only mean that the code as of right now is working, but they should also make sure that the dependencies are run in ways that are likely to continue to produce good output.
This may require that you help out. Add resources. Provide funding. Run infrastructure. Whatever those projects may need to improve – if anything.
The smallest are better off with helping hands
I participate in a few small open source projects outside of curl. Small projects that produce libraries that are used widely. Not as widely as curl perhaps, but still millions and millions of users. Pyramid-bottom projects providing infrastructure for free for the moneymakers in the top. (I’m not naming them here because it doesn’t matter exactly which ones it is. As a reader I’m sure you know of several of this kind of projects.)
This kind of projects don’t have anyone working on the project full-time and everyone participates out of personal interest. All-volunteer projects.
Imagine that a company decides they want to help avoiding “the next log4j flaw” in such a project. How would that be done?
In the slightly larger projects there might be a company involved to pay for support or an individual working on the project that you can hire or contract to do work. (In this aspect, curl would for example count as a “slightly larger” kind.)
In these volunteers-only projects, all the main contributors work somewhere (else) and there is no established project related entity to throw money at to fix issues. In these projects, it is not necessarily easy for a contributor to take on a side project for a month or two – because they are employed to do something else during the days. Day-jobs have a habit of making it difficult to take a few weeks or months off for a side project.
Helping hands would, eh… help
Even the smallest projects tend to appreciate a good bug-fix and getting things from the TODO list worked on and landed. It also doesn’t add too much work load or requirements on the volunteers involved and it doesn’t introduce any money-problems (who would receive it, taxation, reporting, etc).
For projects without any existing way setup or available method to pay for support or contract work, providing man power is for sure a good alternative to help out. In many cases the very best way.
This of course then also moves the this is difficult part to the company that wants the improvement done (the user of it), as then they need to find that engineer with the correct skills and pay them for the allotted time for the job etc.
The entity providing such helping hands to smaller projects could of course also be an organization or something dedicated for this, that is sponsored/funded by several companies.
A general caution though: this creates the weird situation where the people running and maintaining the projects are still unpaid volunteers but people who show up contributing are getting paid to do it. It causes unbalances and might be cause for friction. Be aware. This needs to be done in close cooperating with the maintainers and existing contributors in these projects.
Not the mythical man month
Someone might object and ask what about this notion that adding manpower to a late software project makes it later? Sure, that’s often entirely correct for a project that already is staffed properly and has manpower to do its job. It is not valid for understaffed projects that most of all lack manpower.
Grants are hard for small projects
Doing grants is a popular (and easy from the giver’s perspective) way for some companies and organizations who want to help out. But for these all-volunteer projects, applying for grants and doing occasional short-term jobs is onerous and complicated. Again, the contributors work full-time somewhere, and landing and working short term on a project for a grant is then a very complicated thing to mix into your life. (And many employers actively would forbid employees to do it.)
Should you be able to take time off your job, applying for grants is hard and time consuming work and you might not even get the grant. Estimating time and amount of work to complete the job is super hard. How much do you apply for and how long will it take?
Some grant-givers even assume that you also will contribute so to speak, so the amount of money paid by the grant will not even cover your full-time wage. You are then, in effect, expected to improve the project by paying parts of the job yourself. I’m not saying this is always bad. If you are young, a student or early in your career that might still be perfect. If you are a family provider with a big mortgage, maybe less so.
In Nebraska since 2003
A more chaotic, more illustrative and probably more realistic way to show “the pyramid”, was done by Randall Munroe in his famous xkcd 2347 image, which, when applied onto my image looks like this:
Me shamelessly stealing image parts from xkcd 2347 to further make my point
Generalizing
Of course lots of projects in the bottom make money and are sufficiently staffed and conversely not all projects in the top are proprietary money printing business. This is a simplified image showing trends and the big picture. There will always be exceptions.
I’ve previously said that curl is one of the most widely used software components in the world with its estimated over ten billion installations, and I’m getting questions about it every now and then.
— Is curl the most widely used software component in the world? If not, which one is?
We can’t know for sure which products are on the top list of the most widely deployed software components. There’s no method for us to count or estimate these numbers with a decent degree of certainty. We can only guess and make rough estimates – and it also depends on exactly what we count. And quite probably also depending on who‘s doing the counting.
First, let’s acknowledge that SQLite already hosts a page for mostly deployed software module, where they speculate on this topic (and which doesn’t even mention curl). Also, does this count number of devices running the code or number of installs? If we count devices, does virtual machines count? Is it the number of currently used installations or total number of installations done over the years?
Choices
The SQLite page suggests four contenders for the top-5 list and I think it is pretty good:
zlib (the original implementation)
libpng
libjpeg
sqlite
I will go out on a limb and say that the two image libraries in the list, while of course very widely used, are not typically used on devices without screens and in the IoT world of today, such devices are fairly common. Light bulbs, power switches, networking gear etc. I think it might imply that they are slightly less used than the others in the list. Secondarily, libjpeg seems to not actually be around, but there are a few other successors that are used? Ie not a single implementation.
All top components are Open Source (sqlite’s situation is special but they still call it open source), and I don’t think it is a coincidence.
Are there other contenders not mentioned here? I figure maybe some of the operating systems for the tiniest devices that ship in the billions could be there. But I’m not sure there’s any such obvious market dominant player. There are other compression libraries too, but I doubt they reach the levels of zlib at this moment.
Someone brings up the Linux kernel, which certainly is very well used, but all Android devices, servers, windows 10 etc probably don’t make the unit count go over 7 billion and I believe that in virtually all Linux these kernel installs, curl, zlib and sqlite also run…
Similarly to how SQLite forgot to mention curl, I might of course also have a blind eye for some other really well-used code block.
The finalists
We end up with three finalists:
zlib
sqlite
libcurl
I think it is impossible for us to rank these three in an order with any good certainty. If we look at that sqlite list of where it is used, we quickly recognize that zlib and libcurl are deployed in pretty much all of them as well. The three modules have a huge overlap and will all be installed in billions of devices, while of course there are also plenty that only install one or two of them.
I just can’t figure out the numbers that would rank these modules in the top-list.
The SQLite page says: our best guess is that SQLite is the second mostly widely deployed software library, after libz. They might of course be right. Or wrong. They also don’t specify or explain how they do that guess.
libc
Whenever I’ve mentioned widely used components in the past, someone has brought up “libc” as a contender. But since there are many different libc implementations and they are typically done for specific platforms/operating systems, I don’t think any single of the libc implementations actually reach the top-5 list.
zlib in curl/sqlite
Many people says zlib, partly because curl uses it, but then I have to add that zlib is an optional dependency for curl and I know many, including large volume, users that ship products with libcurl that doesn’t use zlib at all. One very obvious and public example, is the curl.exeshipped in Windows 10 – that’s maybe one billion installs of curl that don’t bundle zlib.
If I understand things correctly, the situation is similar in sqlite: it doesn’t always ship with a zlib dependency.
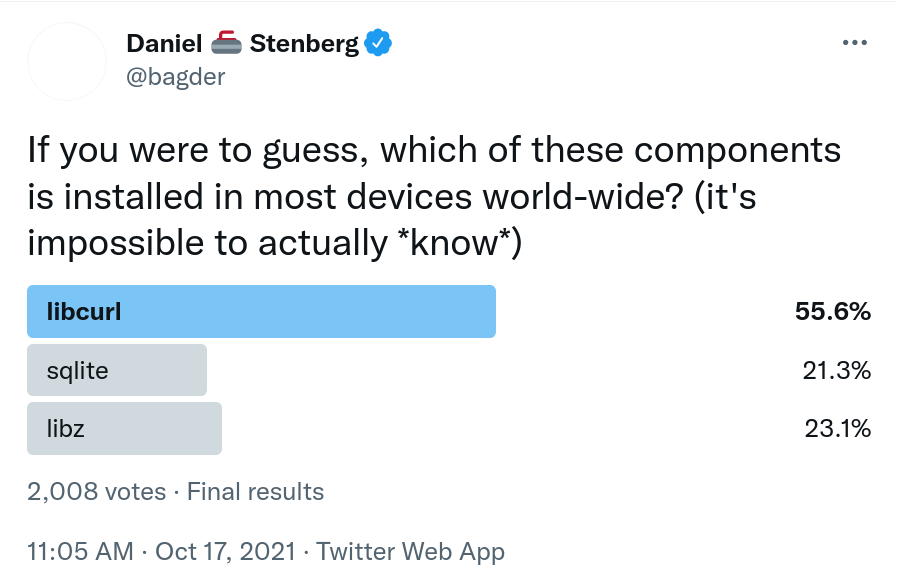
The poll
I asked my twitter followers which one of these three components they guess is the most widely used one. Very unscientifically and of course skewed towards libcurl (since I asked and I have a curl bias),
The over 2,000 respondents voted libcurl with a fairly high margin.
The datestamp shown in the image is when the poll went up and it was online for 24 hours.
What did I miss?
Did I miss a contender?
Have I overlooked some stats that make one of these win?
Updates: Since this was originally posted, I have had OpenSSL, expat and the Linux kernel proposed to me as additional finalists and possibly most-used components.
On May 17, I joined the Kathy and Brian, the hosts of the GitHub ReadMe podcast on a video meeting from my home and we had a chat. Mostly about my work on curl. Today the episode “aired”.
curl is one of the most widely used software component in the world. It is over twenty years old and I am the founder and I still work as lead developer and head honcho. It works!
We talked about how I got into computers and open source in general. How curl started and about how it works to drive such a project, do releases and how to work on it as a full-time job. I am far from alone in this project – I’m just the captain of this ship with a large about of contributors onboard!
Photographs
As a part of the promotion for this episode, I was photographed by a professional outside of my house and nearby on a very lovely summer’s evening. In a southern suburb of Stockholm, Sweden. So, not only does the GitHub material feature not previously seen images of me, since I’ve been given the photos I can now use them for various things going forward. Like for when I do presentations and organizers ask for photos etc.
The photos I’ve used most commonly up until this point are the ones a professional photographer took of me when I spoke at the Velocity conference in New York in 2015. Of course I’m eternally young, but for some reason those past six years are visible on me…
Podcasts
I’ve participated in some podcasts before. If my count is correct, this is the 19th time. See the whole list.
Credits
The new set of photos of me were shot by Evia Photos. One of them is used on the top of this page.