

Yet again we say hello to a new curl release that has been uploaded to the servers and sent off into the world. Version 7.61.0 (full changelog). It has been exactly eight weeks since 7.60.0 shipped.
Numbers
the 175th release
7 changes
56 days (total: 7,419)
88 bug fixes (total: 4,538)
158 commits (total: 23,288)
3 new curl_easy_setopt() options (total: 258)
4 new curl command line option (total: 218)
55 contributors, 25 new (total: 1,766)
42 authors, 18 new (total: 596)
1 security fix (total: 81)
Security fixes
SMTP send heap buffer overflow (CVE-2018-0500)
A stupid heap buffer overflow that can be triggered when the application asks curl to use a smaller download buffer than default and then sends a larger file – over SMTP. Details.
New features
The trailing dot zero in the version number reveals that we added some news this time around – again.
More microsecond timers
Over several recent releases we’ve introduced ways to extract timer information from libcurl that uses integers to return time information with microsecond resolution, as a complement to the ones we already offer using doubles. This gives a better precision and avoids forcing applications to use floating point math.
Bold headers
The curl tool now outputs header names using a bold typeface!
Bearer tokens
The auth support now allows applications to set the specific bearer tokens to pass on.
TLS 1.3 cipher suites
As TLS 1.3 has a different set of suites, using different names, than previous TLS versions, an application that doesn’t know if the server supports TLS 1.2 or TLS 1.3 can’t set the ciphers in the single existing option since that would use names for 1.2 and not work for 1.3 . The new option for libcurl is called CURLOPT_TLS13_CIPHERS.
Disallow user name in URL
There’s now a new option that can tell curl to not acknowledge and support user names in the URL. User names in URLs can brings some security issues since they’re often sent or stored in plain text, plus if .netrc support is enabled a script accepting externally set URLs could risk getting exposing the privately set password.
Awesome bug-fixes this time
Some of my favorites include…
Resolver local host names faster
When curl is built to use the threaded resolver, which is the default choice, it will now resolve locally available host names faster. Locally as present in /etc/hosts or in the OS cache etc.
Use latest PSL and refresh it periodically
curl can now be built to use an external PSL (Public Suffix List) file so that it can get updated independently of the curl executable and thus better keep in sync with the list and the reality of the Internet.
Rumors say there are Linux distros that might start providing and updating the PSL file in separate package, much like they provide CA certificates already.
fnmatch: use the system one if available
The somewhat rare FTP wildcard matching feature always had its own internal fnmatch implementation, but now we’ve finally ditched that in favour of the system fnmatch() function for platforms that have such a one. It shrinks footprint and removes an attack surface – we’ve had a fair share of tiresome fuzzing issues in the custom fnmatch code.
axTLS: not considered fit for use
In an effort to slowly increase our requirement on third party code that we might tell users to build curl to use, we’ve made curl fail to build if asked to use the axTLS backend. This since we have serious doubts about the quality and commitment of the code and that project. This is just step one. If no one yells and fights for axTLS’ future in curl going forward, we will remove all traces of axTLS support from curl exactly six months after step one was merged. There are plenty of other and better TLS backends to use!
Detailed in our new DEPRECATE document.
TLS 1.3 used by default
When negotiating TLS version in the TLS handshake, curl will now allow TLS 1.3 by default. Previously you needed to explicitly allow that. TLS 1.3 support is not yet present everywhere so it will depend on the TLS library and its version that your curl is using.
Coming up?
We have several changes and new features lined up for next release. Stay tuned!
First, we will however most probably schedule a patch release, as we have two rather nasty HTTP/2 bugs filed that we want fixed. Once we have them fixed in a way we like, I think we’d like to see those go out in a patch release before the next pending feature release.







 Unless the issue is critical, we prefer to schedule a fix and announcement of the issue in association with the pending next release, and as we do releases every 8 weeks like clockwork, that’s never very far away.
Unless the issue is critical, we prefer to schedule a fix and announcement of the issue in association with the pending next release, and as we do releases every 8 weeks like clockwork, that’s never very far away. we should introduce processes, tests and checks to make sure we detect other similar mistakes now and in the future.
we should introduce processes, tests and checks to make sure we detect other similar mistakes now and in the future. Unfortunately we don’t have any bug bounties on our own in the curl project. We simply have no money for that. We actually don’t have money at all for anything.
Unfortunately we don’t have any bug bounties on our own in the curl project. We simply have no money for that. We actually don’t have money at all for anything.

 I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you.
I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you. Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.
Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong. I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in 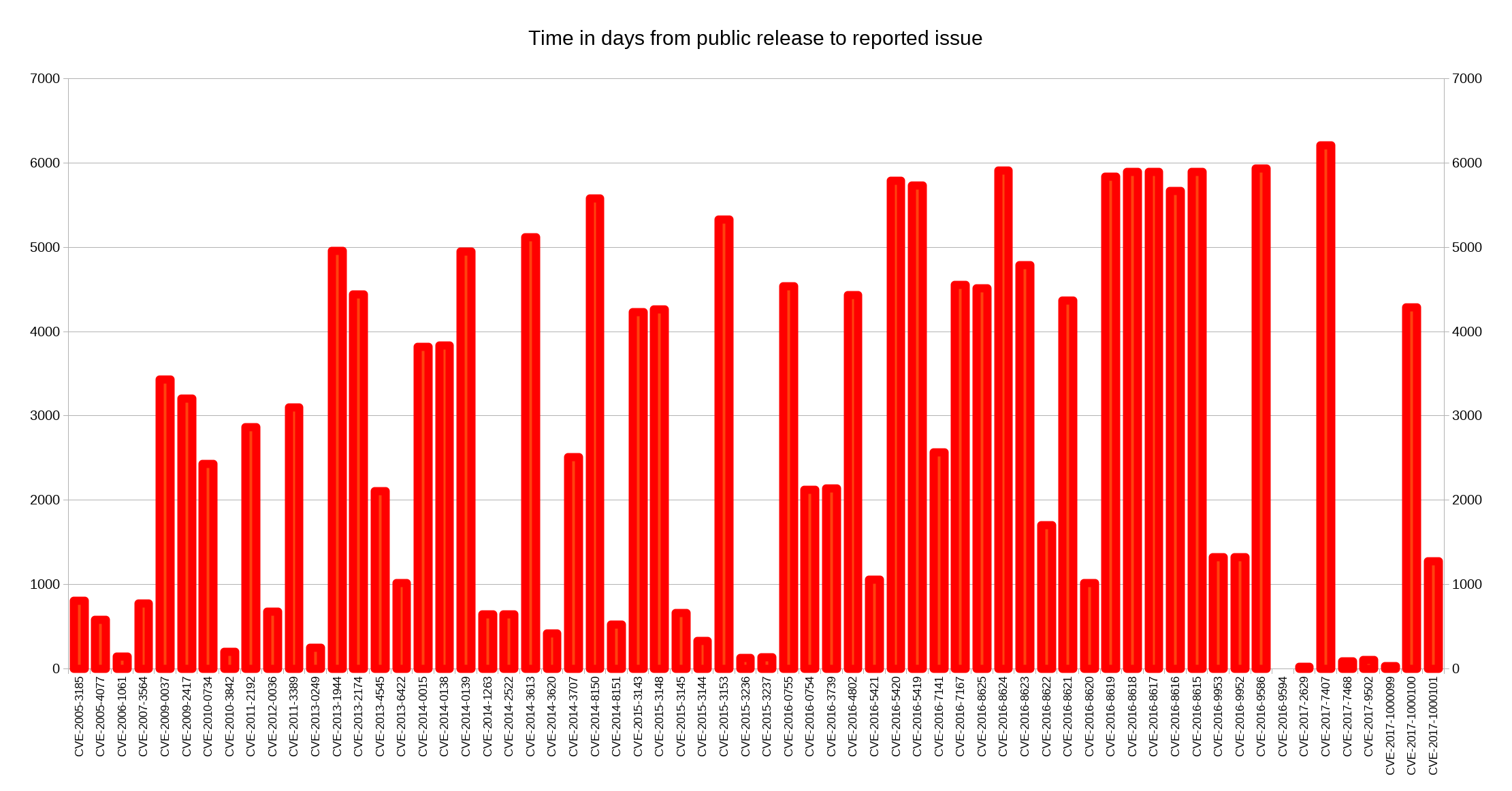
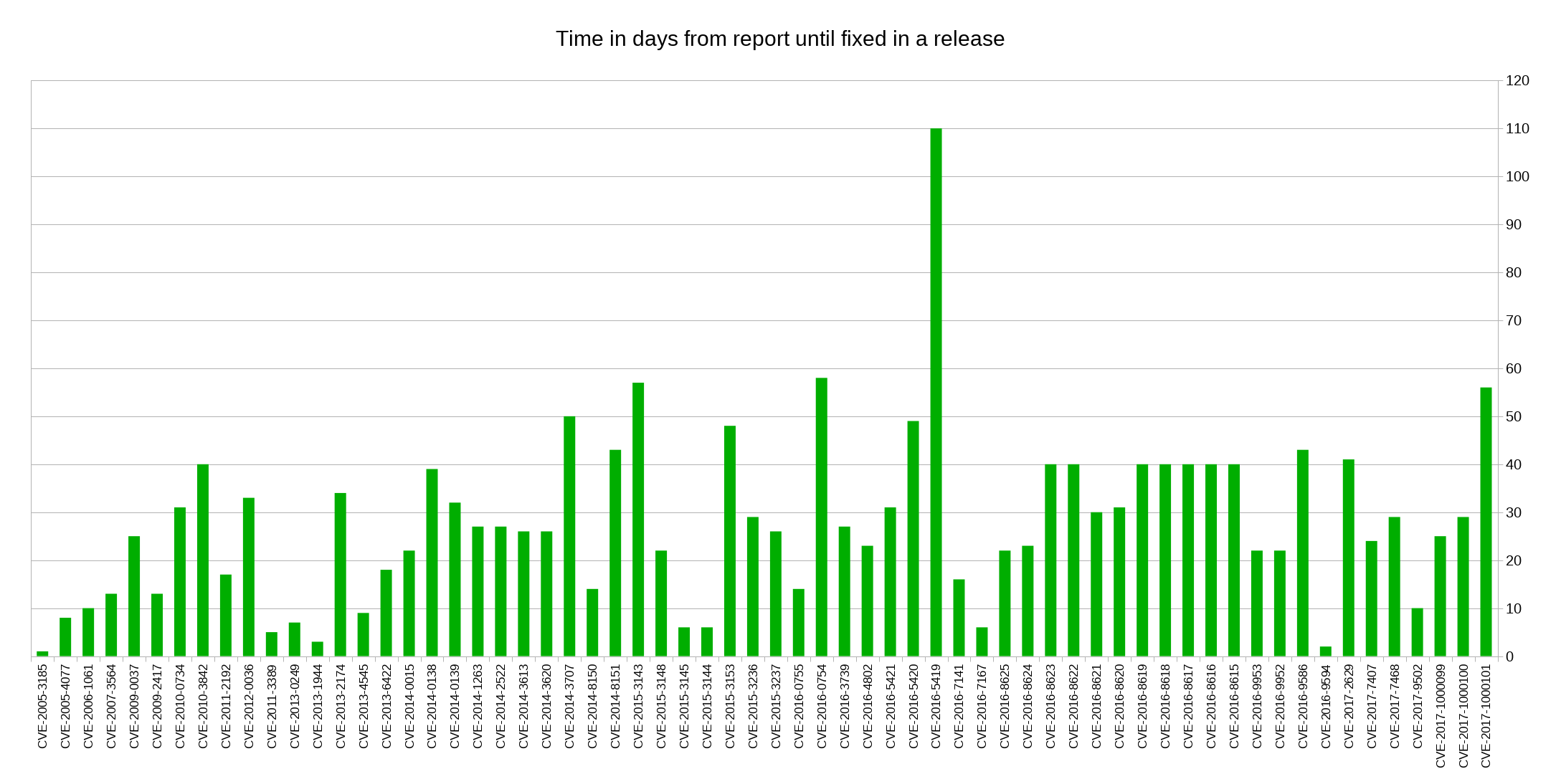
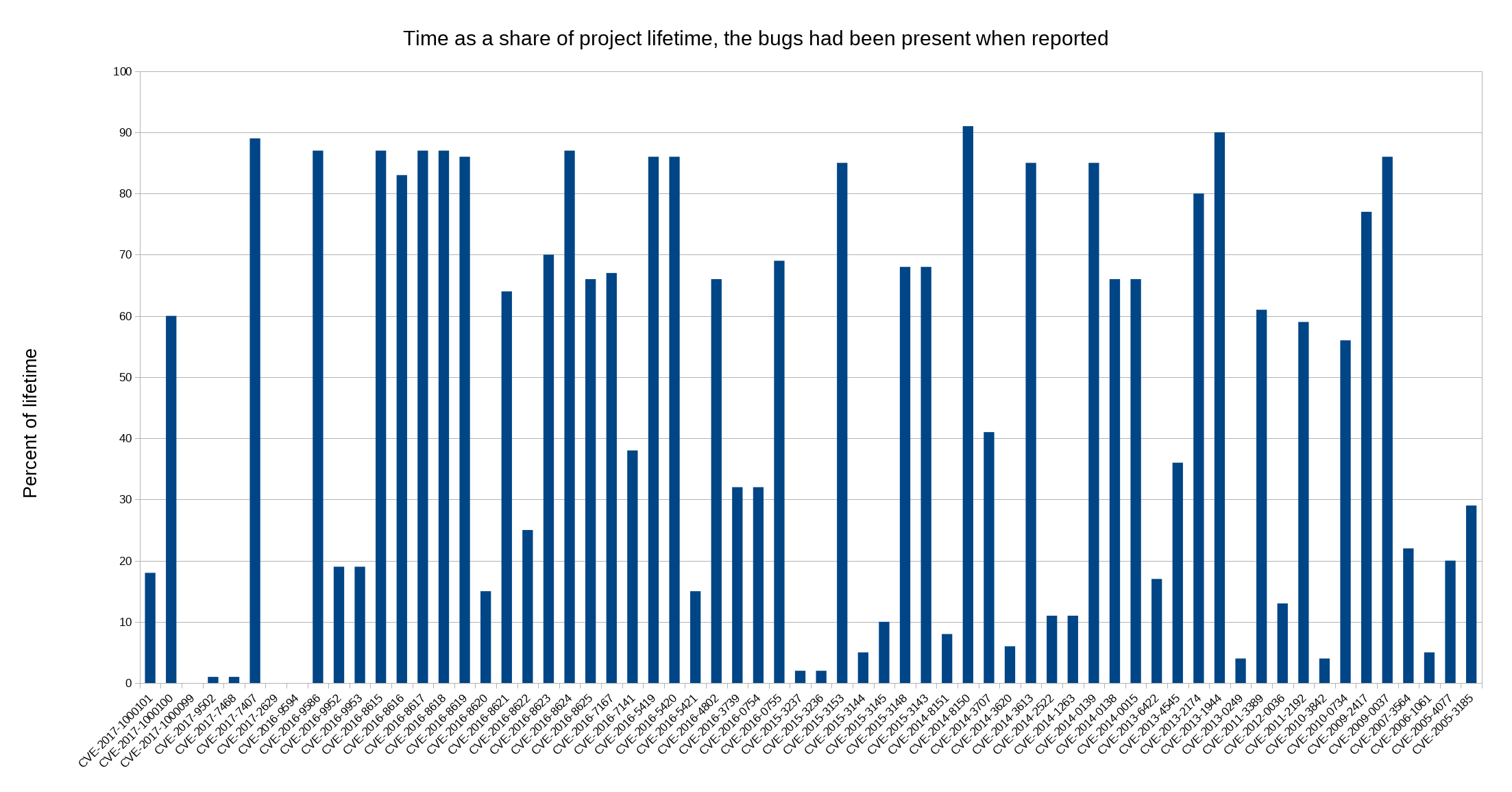
 I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.
I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.