Only 6 days since the previous release we are again here with a curl release. It turned out 8.1.0 had some rather nasty regressions that we felt were urgent enough to warrant another round on the dance floor. So here goes curl 8.1.1. A bugfix release.
Release presentation
Numbers
the 218th release 0 changes 6 days (total: 9,195) 25 bug-fixes (total: 9,031) 40 commits (total: 30,407 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 0 new curl command line option (total: 251) 19 contributors, 10 new (total: 2,885) 13 authors, 6 new (total: 1,148) 0 security fixes (total: 145)
Bugfixes
Some of the highlights of this release include…
cmake: avoid list(PREPEND)
This use of a too new cmake feature snuck itself into the build in the last release which caused trouble for people using older cmake versions.
cmake: repair cross compiling
A recently added cmake check did not have the correct precautions added for cross-compiling which broke such builds.
configure: generate a script to run the compiler
The configure script has an elaborate check that verifies provided if libraries can be used at run-time. This turned out complicated when the compiler itself uses libraries that configure checks for by setting the LD_LIBRARY_PATH since that path also affects the compiler!
http2: double http request parser max line length
The last word is probably not said about this logic, but capping the max request header line size to 4KB was too narrow and caused application breakages. Now the limit is at 8KB.
http2: increase stream window size to 10 MB
It turned out that even though we have a flexible HTTP/2 window concept, download performance could suffer and now we have bumped the window size again significantly.
http2: upload improvements
In particular doing uploads that are aborted prematurely by a reset when for example a 404 is returned before the entire upload was done could cause issues.
rename struct ‘http_req’ to ‘httpreq’
The development branch of FreeBSD (14) introduced a struct in one of the public headers that name-collided an internal struct libcurl uses. The bug exists in FreeBSD’s header, but we renamed ours anyway to work around the problem while the FreeBSD team fixes their end.
better error message when URLs fail to parse
Since we have a fairly elaborate identification of exactly what fails when the URL parser rejects a URL, this now helps users to better understand what curl does not like.
urlapi: allow numerical parts in the host name
The URL parser was far too strict in rejecting host names because they were “invalid IPv4” when in fact they should be treated as host names instead. Probably the worst regression added in 8.1.0. In fact, the URL parser basically cannot refuse a host name for not being a valid IPv4 since then it can get passed through to the name resolver which can then still find it in /etc/hosts etc.
We are back with the first release since that crazy March day when we did two releases on the same day. First 8.0.0 shipped that bumped the major version for the first time in decades. Then curl 8.0.1 followed just hours after, due to a serious mess-up in the factory lines.
Release video presentation
Numbers
the 217th release 3 changes 58 days (total: 9,189) 185 bug-fixes (total: 9,006) 322 commits (total: 30,367 0 new public libcurl function (total: 91) 0 new curl_easy_setopt() option (total: 302) 1 new curl command line option (total: 251) 64 contributors, 35 new (total: 2,875) 37 authors, 17 new (total: 1,142) 4 security fixes (total: 145)
Security
We disclose four new curl security vulnerabilities today, three of them at severity Low and one of them at Medium. This also means that 3,840 USD was awarded as bug bounties in this release cycle.
UAF in SSH sha256 fingerprint check
[CVE-2023-28319] libcurl offers a feature to verify an SSH server’s public key using a SHA 256 hash. When this check fails, libcurl would free the memory for the fingerprint before it returns an error message containing the (now freed) hash.
siglongjmp race condition
[CVE-2023-28320] libcurl provides several different backends for resolving host names, selected at build time. If it is built to use the synchronous resolver, it allows name resolves to time-out slow operations using alarm() and siglongjmp().
When doing this, libcurl used a global buffer that was not mutex protected and a multi-threaded application might therefore crash or otherwise misbehave.
IDN wildcard match
[CVE-2023-28321] curl supports matching of wildcard patterns when listed as “Subject Alternative Name” in TLS server certificates. curl can be built to use its own name matching function for TLS rather than one provided by a TLS library. This private wildcard matching function would match IDN (International Domain Name) hosts incorrectly and could as a result accept patterns that otherwise should mismatch.
more POST-after-PUT confusion
[CVE-2023-28322] When doing HTTP(S) transfers, libcurl might erroneously use the read callback (CURLOPT_READFUNCTION) to ask for data to send, even when the CURLOPT_POSTFIELDS option has been set, if the same handle previously was used to issue a PUT request which used that callback.
This flaw may surprise the application and cause it to misbehave and either send off the wrong data or use memory after free or similar in the second transfer.
Changes
This release has only three real changes. One bigger and two smaller:
HTTP/2 over proxy
libcurl can now negotiate and use HTTP/2 when it is told to use a HTTPS proxy (details in the CURLOPT_PROXYTYPE man page), and the command line tool can of course switch it on using the --proxy-http2 option. Explained more in this blog post.
refuse to resolve the .onion TLD
When a host name ending with .onion is passed on to the name resolver functions, they will cause an error and will not be resolved. Like RFC 7686 tells us.
The official counter says we did more than 180 bugfixes in his release cycle. Here follows some of my favorites:
checksrc fixes
We made it better at checking the code style for three distinct code situations – and then updated the source code accordingly.
cmake fixes
bring in the network library on Haiku
do not add zlib headers for OpenSSL
make config version 8 compatible with 7
set SONAME for SunOS too
only do transfer-encoding compression if asked to
Transfer encodings other than “chunked” are rarely used. Up until now libcurl would still activate automatic decompression if such was used, even if it was not asked for by the application.
bring back support for SFTP path ending in /~
A regression made a URL that ends with /~ no longer make a directory listing because the URL does not end with a slash. Now we bring back that behavior, even if it goes a little against the standard behavior.
never allocate dynbufs larger than “too big”
The general dynamic buffer system no longer allocates more memory than what the specific buffer is allowed to grow to. An optimization.
various gskit compile errors in OS400
Makes curl build fine there again.
enforce a maximum DNS cache size independent of timeout value
The DNS cache entries are purged on age only (default 60 seconds). With this new code, libcurl limits caps the maximum total amount of DNS cache entries to 30,000.
remove PENDING + MSGSENT handles from the main linked list
Not yet activated transfers and the transfers that are already completed, are now moved away off the main linked list. For performance.
runtests: prepare for parallel
Lots of cleanups and smaller fixes have been merged during this cycle in preparation for the pending introduction of parallel tests.
verify socketpair with a random value
The custom socketpair implementation used for platforms without a native one, was changed to use truly random values when verifying that the pipe works.
Fix ‘Location:’ formatting for early VTE terminals
The special terminal highlighting of the URL that is shown in the Location: header is now disabled for some terminals that can’t display it properly.
urlapi polish
Several different bugs and improvements were made. Including:
cleanups and performance improvements
detect and error on illegal IPv4 addresses
prevent setting invalid schemes
URL encoding for the URL missed the fragment
enhanced WebSocket en-/decoding
Parts of the websocket parser code was rewritten to fix bugs.
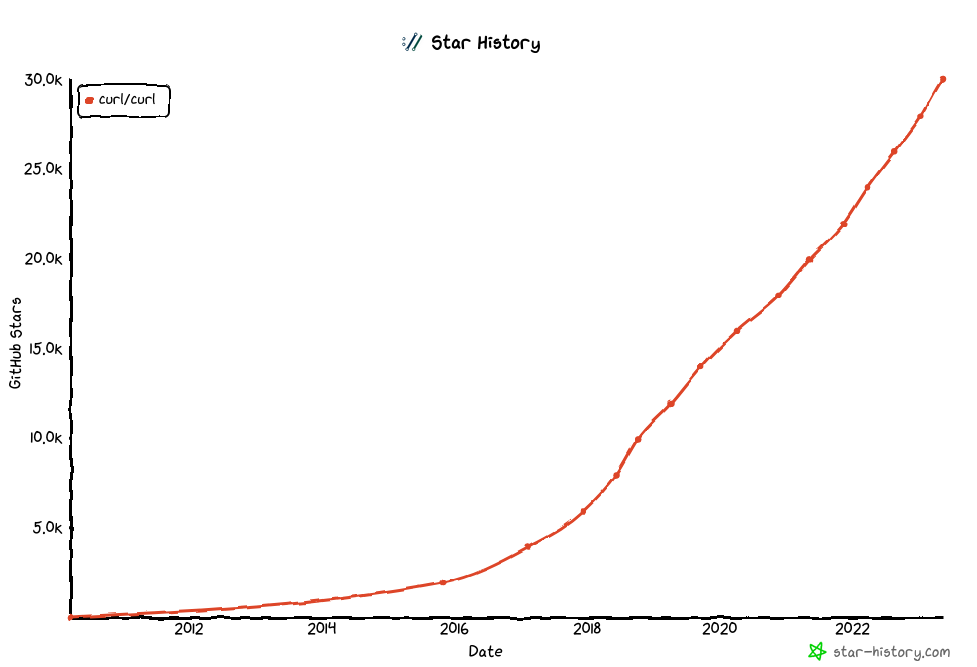
This post is slightly delayed just because I happened to be traveling when I realized we had climbed above this mark, so it took me an extra day to get an appropriate photograph made. The kind of photograph a moment like this calls for. Unfortunately without a beer this time.
Daniel celebrating
Steady growth
The star growth rate for curl seems to have been fairly linear over many years now.
Meaningless
Yes GitHub stars is a totally meaning less metric that does not say anything real about a project like curl. It does not reflect usage, it does not reflect popularity and it does not reflect the number of installs out in the real world. It’s just a vanity number.
It started as just a test to see if I could use the existing advisory data we have for all curl CVEs to date and provide that as JSON. Maybe, I thought, if we provide it good enough it can be used to populate other databases automatically or even get queried easier by tools.
Information
In the curl project we have published 141 vulnerability advisories so far, each with its own registered CVE Id. We make an effort to provide all the details about all the flaws as good and thorough as possible, but also with easy overviews and tables etc so that users can quickly detect for example which curl versions are vulnerable to which flaws etc. It is our going the extra meticulous mile that makes it extra annoying when others override what we conclude.
More machine friendly
In a recent push I decided that all the info we have and provide could and should be offered in a more machine friendly format for whoever wants it.
After a first few test shots, fellow curl team mates pointed out to me that there is an existing effort called the Open Source Vulnerability format, an openly developed JSON schema designed for pretty much exactly what I was set out to do. I agreed that it made sense to follow something existing rather to make up my own format.
Can be improved
Of course we ran into some minor snags with this schema and there are still details in it that I think can be improved and we are discussing with the OSV team to see if there is merit to our ideas or not. Still, even without any changes we can now offer our data using this established format.
The two primary things I want to improve is how we provide project identification (whose issue is this) and how we convey the severity level of the issue.
Different sets
As of now, we offer a set of different ways to get the CVE data as JSON.
1. Everything all at once
On the fixed URL https://curl.se/docs/vuln.json, we provide a JSON array holding a number of JSON objects. One object per existing CVE. Right now, this is 349KB of data. (If you ask for it compressed it will be smaller!)
This URL will always contain the entire set and it will automatically update in the future as we published new CVEs. It also automatically updates when we correct or change any of the previously published advisories.
2. Single object per issue
If you prefer to get the exact metadata for a single specific curl CVE, you can get the JSON for an issue by replacing the .html extension to .json for any CVE documented on the website. You will also find a menu option the “related box” for each documented CVE that links to it.
On the curl website we already offer a way for users to get a list of all known vulnerabilities a certain specific release is known to be vulnerable to. Of course always updated with the latest publications.
For example, curl version 7.87.0 has all its vulnerability information detailed on https://curl.se/docs/vuln-7.87.0.html. When I write this, there are eight known vulnerabilities for this version.
Screenshot of the website displaying vulnerability information for curl 7.87.0
Again, either by clicking the JSON link there on the page under the table, or simply by replacing html by json in the URL, the user can get a listing of all the CVEs this version is vulnerable to, as a JSON array with a number of JSON objects inside. In this case, eight objects as of now.
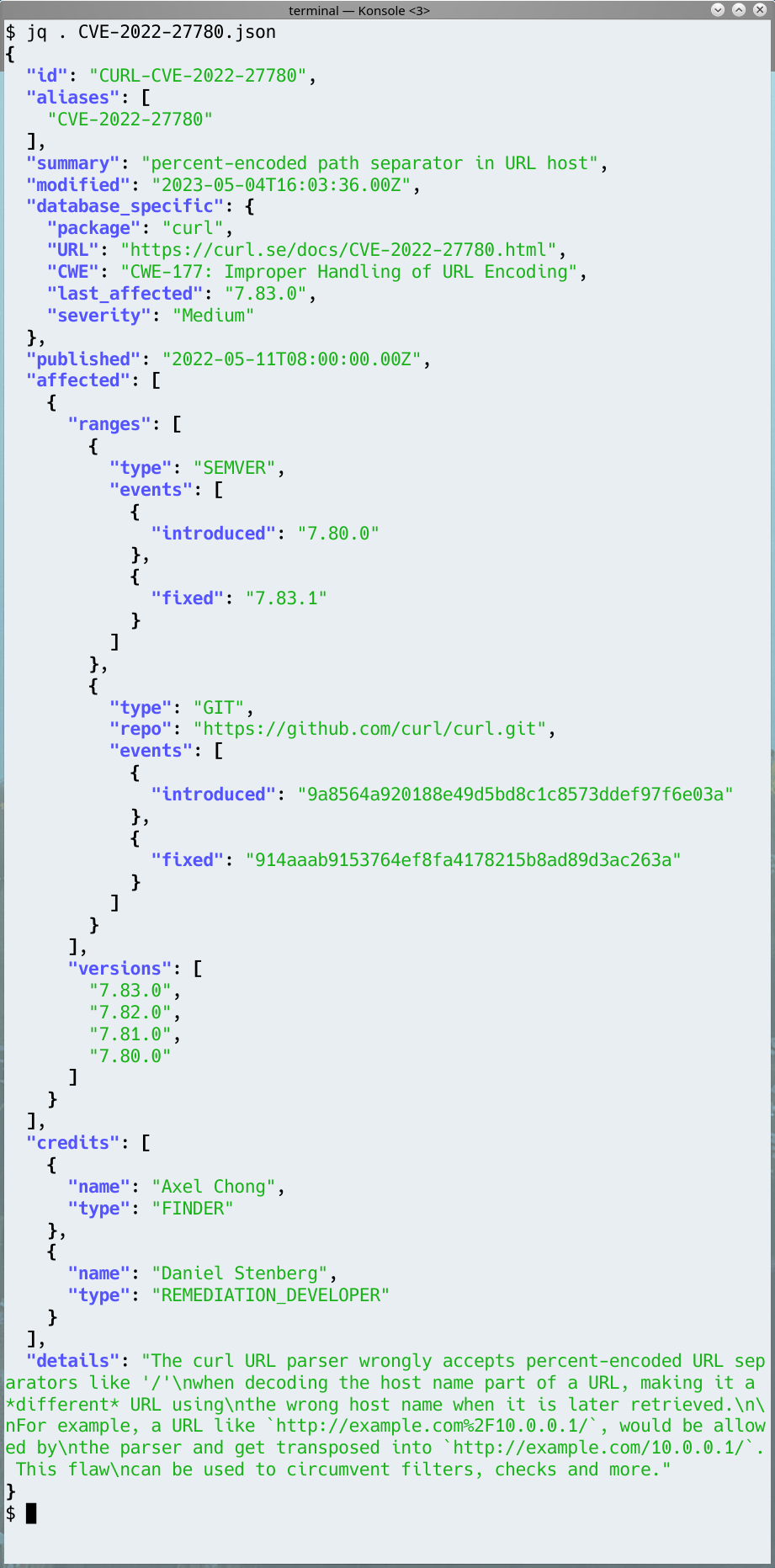
While I expect the format might still change a little bit going forward, and not all issues have all the metadata provided just yet (for example, the git commit ranges are still lacking on a number of issues from before 2017), here is an illustration screenshot of jq displaying the JSON object for CVE-2022-27780.
Object details
The database_specific object near the top is metadata that we have and believe belongs with the issue but that has no defined established field in the JSON schema. Since I think the data still adds value to users, I decided to put them into this section that is designed and meant exactly for this kind of extensions.
You can see that we set an “id” that is the CVE ID with a CURL- prefix. This is just us catering to the conditions of OSV and the JSON schema. We apparently need our own ID and provide the actual CVE ID as an alias, so we “fake” this by simply prepending curl to the CVE ID. We don’t use any private ID when we work with vulnerabilities: we only deal with public issues and we only deal with issues that are CVE worthy so it seems unnecessary to involve anything else.
First: performance is tricky and bechmarking even more so. I will talk some numbers in this post but of course they are what I have measured for my specific tests on my machine. Your numbers for your test cases will be different.
Over the last six months or so, curl has undergone a number of refactors and architectural cleanups. The primary motivations for this have been to improve the HTTP/3 support and to offer HTTP/2 over proxy, but also to generally improve the code, its maintainability and its readability.
A main change is the connection filters I already blogged about, but while working on this a lot of other optimizations and “quirk removals” have been performed. Most of this work done by Stefan Eissing.
So how do all these changes reflect on raw transfer metrics?
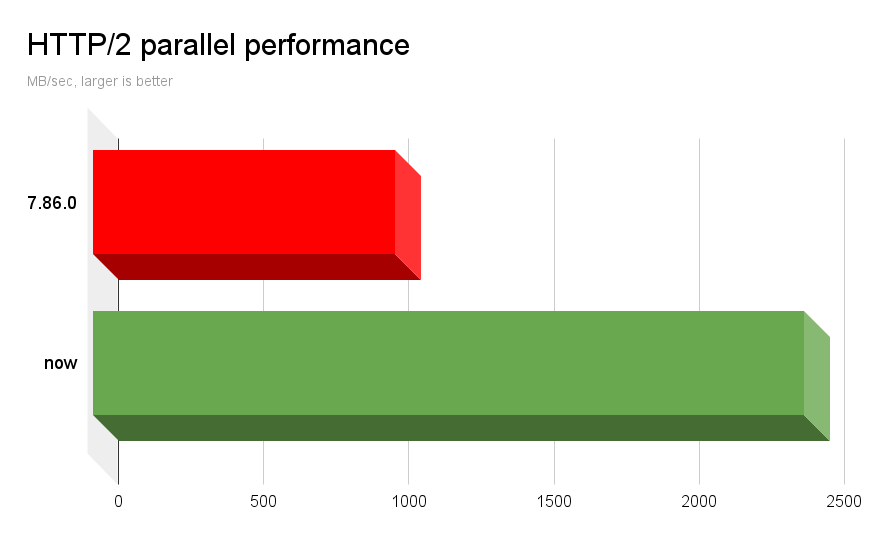
Parallelism with TLS
This test case uses a single TCP connection and makes 50 parallel transfers, each being 100 megabytes. The transfer uses HTTP/2 and TLS to a server running on the same host. All done in a single thread in the client.
As a baseline version, I selected curl 7.86.0, which was released in October 2022. The last curl release we shipped before Stefan’s refactor work started. Should work as a suitable before/after comparison.
For this test I built curl and made it use OpenSSL 3.0.8 for TLS and nghttp2 1.52.0 for HTTP/2. The server side is apache2 2.4.57-2, a plain standard installation in my Debian unstable.
Running the exact same parallel test, built with the same OpenSSL version (and cipher config) and the same nghttp2 version, 7.86.0 transfers those 50 streams at 1040 MB/sec. A 2.36 times speedup!
We still have further ideas on how we can streamline the receiving of data on multiplexed transfers. Future versions might be able to squeeze out even more.
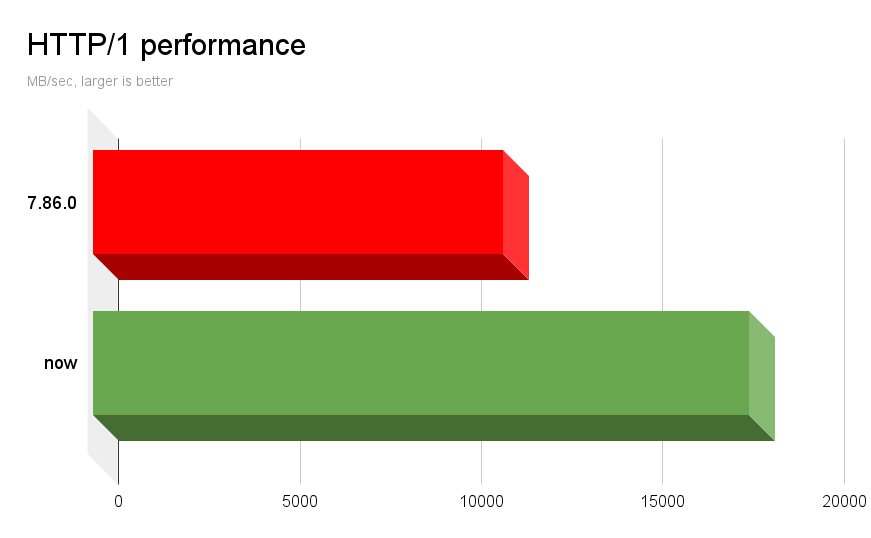
Raw unencrypted HTTP/1
This test simply uses the libcurl multi API to do 5 parallel HTTP/1 transfers – in the same thread. They will then use one connection each and again download from the local apache2 installation. Each file is 100GB so it transfers 500GB and measures how fast it can complete the entire operation.
Running this test program linking with curl 7.86.0 reaches 11320 MB/sec on the same host as before.
Running the exact same program, just pointing out to my 8.1.0-DEV library, the program reports a rather amazing 18104 MB/sec. An 1.6 times improvement.
This difference actually surprised us, because we knew we had some leeway in the HTTP/2 department to “clean up” but I was not aware that we had this much margin to further enhance plain HTTP/1 transfers. We are also not entirely sure what change that made this significant bump possible.
It should probably also be noted that this big gain is in particular when doing them in parallel. If I do a single file transfer with the same program, current libcurl does 3900 MB/sec vs the old at 3700 MB/sec. Clearly the bigger enhancements lie in doing multiple transfers and internal transfer-switching.
Does it matter?
I believe it does. By doing transfers faster, we are more effective and therefor libcurl uses less energy for the same thing than previously. In a world with 20+ billion libcurl installations, every little performance tweak has the opportunity to make a huge dent at scale.
If there are 100 million internet transfers done with curl every day, and we make each transfer take 0.1 second less we save 10 million CPU seconds. That equals 115 days of CPU time saved.
The competition
I have not tried to find out how competitors and alternative Internet transfers libraries perform for the same kind of work loads. Primarily because I don’t think it matters too much, but also because doing fair performance comparisons is really hard and no matter how hard I would try I would be severely biased anyway. I leave that exercise to someone else.
Let me tell you a story about how Windows users are deleting files from their installation and as a consequence end up in tears.
Background
The real and actual curl tool has been shipped as part of Windows 10 and Windows 11 for many years already. It is called curl.exe and is located in the System32 directory.
Microsoft ships this bundled with its Operating system. They get the code from the curl project but Microsoft builds, tests, ships and are in all ways responsible for their operating system.
In one particular case, CVE-2022-43552 was reported by the curl project in December 2022. It is a use-after-free flaw that we determined to be severity low and not higher mostly because of the very limited time window you need to make something happen for it to be exploited or abused. NVD set it to medium which admittedly was just one notch higher (this time).
This is not helpful.
“Security scanners”
Lots of Windows users everywhere runs security scanners on their systems with regular intervals in order to verify that their systems are fine. At some point after December 21, 2022, some of these scanners started to detect installations of curl that included the above mentioned CVE. Nessus apparently started this on February 23.
This is not helpful.
Panic
Lots of Windows users everywhere then started to panic when these security applications warned them about their vulnerable curl.exe. Many Windows users are even contractually “forced” to fix (all) such security warnings within a certain time period or risk bad consequences and penalties.
How do you fix this?
I have been asked numerous times about how to fix this problem. I have stressed at every opportunity that it is a horrible idea to remove the system curl or to replace it with another executable. It is very easy to download a fresh curl install for Windows from the curl site – but we still strongly discourage everyone from replacing system files.
But of course, far from everyone asked us. A seemingly large enough crowd has proceeded and done exactly what we would stress they should not: they deleted or replaced their C:\Windows\System32\curl.exe.
The real fix is of course to let Microsoft ship an update and make sure to update then. The exact update that upgrades curl to version 8.0.1 is called KB5025221 and shipped on April 11. (And yes, this is the first time you get the very latest curl release shipped in a Windows update)
The people who deleted or replaced the curl executable noticed that they cannot upgrade because the Windows update procedure detects that the Windows install has been tampered with and it refuses to continue.
I do not know how to restore this to a state that Windows update is happy with. Presumably if you bring back curl.exe to the exact state from before it could work, but I do not know exactly what tricks people have tested and ruled out.
Bad advice
I have been pointed to responses on the Microsoft site answers.microsoft.com done by “helpful volunteers” that specifically recommend removing the curl.exe executable as a fix.
This is not helpful.
I don’t want to help spreading that idea so I will not link to any such post. I have reported this to Microsoft contacts and I hope they can maybe edit or comment those posts soon.
We are not responsible
I just want to emphasize that if you install and run Windows, your friendly provider is Microsoft. You need to contact Microsoft for support and help with Windows related issues. The curl.exe you have in System32 is only provided indirectly by the curl project and we cannot fix this problem for you. We in fact fixed the problem in the source code already back in December 2022.
If you have removed curl.exe or otherwise tampered with your Windows installation, the curl project cannot help you.
I am honored to yet again receive a peer bonus award from Google. This is a Google program for which persons like me can be nominated by Googlers and as a result receive grants.
A few people noticed and have commented on the fact that this letter is signed by Chris DiBona and dated April 19th 2023, while sources say he was let go from Google back in January. Which means one or two of those things are wrong.
In September 2013 we merged the first code into curl that made it capable of using HTTP/2: HTTP version 2.
This version of HTTP changed a lot of previous presumptions when it comes to transfers, which introduced quite a few challenges to HTTP stack authors all of the world. One of them being that with version 2 there can be more than one transfer using the same connection where as up to that point we had always just had one transfer per connection.
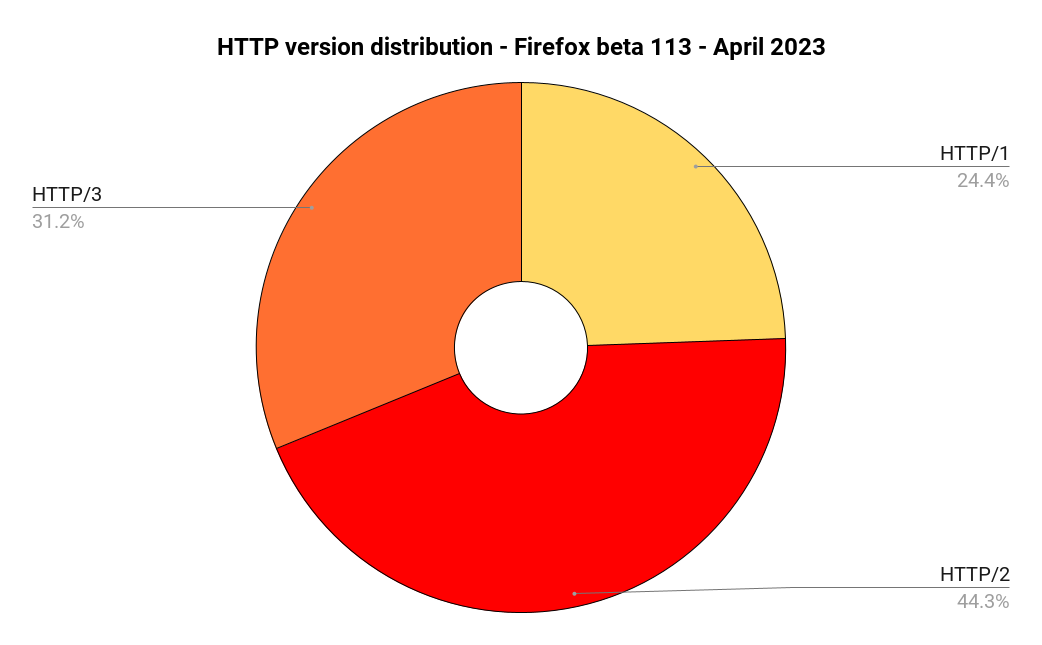
Now almost eight years since the RFC was published, HTTP/2 is the version seen most frequently in browser responses if we ask the Firefox telemetry data. 44.4% of the responses are HTTP/2.
curl
This year, the curl project has been sponsored by the Sovereign Tech Fund, and one of the projects this funding has covered is what I am here to talk about:
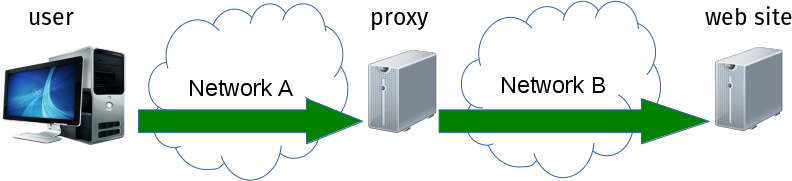
Speaking HTTP/2 with a proxy. More specifically with what is commonly referred to as a “forward proxy.”
Many organizations and companies have setups like the one illustrated in this image below. The user on the left is inside the organization network A and the website they want to reach is on the outside on network B.
HTTP/2 to the proxy
When this is an HTTPS proxy, meaning that the communication to and with the proxy is itself protected with TLS, curl and libcurl are now capable of negotiating HTTP/2 with it.
It might not seem like a big deal to most people, and maybe it is not, but the introduction of this feature comes after some rather heavy lifting and internal refactors over the recent months that have enabled the rearrangement of networking components for this purpose.
Enable
To enable this feature in your libcurl-using application, you first need to make sure you use libcurl 8.1.0 when it ships in mid May and then you need to set the proxy type to CURLPROXY_HTTPS2.
This allows HTTP/2 but will proceed with plain old HTTP/1 if it can’t negotiate the higher protocol version using ALPN.
The old proxy type called just CURLPROXY_HTTPS remains for asking libcurl to stick to HTTP/1 when talking to the proxy. We decided to introduce a new option for this simply because we anticipate that there will be proxies out there that will not work correctly so we cannot throw this feature at users without them asking for it.
command line tool
Using the command line tool, you use a HTTPS proxy exactly like before and then you add this flag to tell the tool that it may try HTTP/2 with the proxy: --proxy-http2.
This also happens to be curl’s 251st command line option.
Shipping and credits
This implementation has been done by Stefan Eissing.
These features have already landed in the master branch and will be part of the pending curl 8.1.0 release, scheduled for release on May 17, 2023.
trurl is a tool in a similar spirit of tr but for URLs. Here, tr stands for translate or transpose.
trurl is a small command line tool that parses and manipulates URLs, designed to help shell script authors everywhere.
URLs are tricky to parse and there are numerous security problems in software because of this. trurl wants to help soften this problem by taking away the need for script and command line authors everywhere to re-invent the wheel over and over.
trurl uses libcurl’s URL parser and will thus parse and understand URLs exactly the same as curl the command line tool does – making it the perfect companion tool.
I created trurl on March 31, 2023.
Some command line examples
Given just a URL (even without scheme), it will parse it and output a normalized version:
$ trurl ex%61mple.com/
http://example.com/
The above command will guess on a http:// scheme when none was provided. The guess has basic heuristics, like for example FTP server host names often starts with ftp:
$ trurl ftp.ex%61mple.com/
ftp://ftp.example.com/
A user can output selected components of a provided URL. Like if you only want to extract the path or the query components from it.:
trurl can read URLs to work on off a file or from stdin, and works on them in a streaming fashion suitable for filters etc.
$ cat many-urls.yxy | trurl --url-file -
...
More or different
trurl was born just a few days ago, this is what we have made it do so far. There is a high probability that it will change further going forward before it settles on exactly how things ideally should work.
It also means that we are extra open for and welcoming to feedback, ideas and pull-requests. With some luck, this could become a new everyday tool for all of us.
In 2011 I started to send “pre-notifications” about pending curl security vulnerabilities to the distros mailing list (back then it was still called linux-distros).
For several years we also asked them for CVE IDs for the new vulnerabilities that we were about to publish to the world. By notifying the distros ahead of time, the idea is that they get a little head-start to fix their curl packages so that at the day when we publish the vulnerabilities to the world, they can already provide curl upgrades.
The gap from us announcing a flaw until they offer curl upgrades could ideally be made a minimum.
The distros list’s rules forbid us to tell them more than 10 days before the planned release day. They call this an embargo as they are expected to not tell anyone who is not a mailing list member about these flaws.
During the last twelve plus years, I have told them about almost 130 pending curl vulnerabilities like this up until today.
Secrets are hard
For an open source project that has all its processes and test infrastructure public and open there are several challenges with how to deal with secrets, such as vulnerabilities and their corresponding fixes.
We recently updated our security process in the curl project: we have noticed that we have previously – several times – landed fixes to security problems that were defective and in some cases did not even fix the reported problem correctly. I believe one reason for this is that we had this policy to make the fix into a (public) pull-request no earlier than 48 hours before the pending release. 48 hours is enough to make all the tests and CI verify the fix, but it is a very short time window for the community to react or be able to test and find any problems with the fixes before the release goes out.
As an attempt to do better we have tweaked our policy. If a reported security problem is deemed to be of severity low or severity medium, we will instead allow and rather push for turning the fix into a public pull-request much earlier. We will however not mention the security aspect of the fix in the public communication about the pull-request, but only talk about the bugfix aspect.
This will allow us to merge fixes earlier in the release cycle. To give the bugfixes more time to mature and ripe in the repository before the pending release. It should increase the chances that we can do follow-up fixes and truly make it a good correction by the time we do the next release. Hopefully it leads to better releases with fewer regressions.
Of course the risk with this is that a malicious user somewhere finds out about a vulnerability this way, earlier than 48 hours before a release, and therefore gets an extended time window to perform nefarious actions. That is also why we limit this method to severity low and medium issues, as the ones rated more serious are deemed too dangerous to risk.
Policy vs policy
The week before we were about to ship the curl 8.0.0 release, I emailed the distros mailing list again like I have done so many times before and told them about the upcoming six(!) vulnerabilities we were about to reveal to the world.
This time turned out to be different.
Because of our updated policy where the fixes were already committed in a public git repository, the distros mailing list’s policy says that if there is a public commit they consider the issue to be public and thus they refuse to accept any embargo.
What they call embargo I of course call heads-up time.
I argue that while the fixes are public, the actual vulnerabilities and the security issues those fixes rectify are not. It takes a serious effort and pretty good insights to just detect that one or more of the commits for the pending release are done because of a security problem and then even more so if you want to convert that suspicion into an actual attack vector.
They maintain that while they could make an exception for me/us this time, this is an exception and their policy says this is not acceptable for embargos.
If we make commits public before telling distros, we may not “ask for an embargo”.
So we won’t tell
I thought we were doing this for their benefit. I was under the impression that we actually helped distributors of open source operating systems by telling them ahead of time what was going to ship very soon that they might want to get a head-start on so that their users stay protected.
I have been told in very clear terms that they do not want to be notified about vulnerabilities ahead of time if the commits are public.
I have informed them that I will not tell them anymore until they change their minds because I think our updated security process can make our releases better and I think improving curl and making better releases is more important than telling distros ahead of time.
I cannot understand how this stubbornness makes anything better for them. For me, it takes away some amount of work so I will manage just fine. For curl users “in the wild”, this will probably mean that they will get security-patched curl releases from their distros a little slower in the future.
We rarely see curl vulnerabilities rated higher than medium so this means we will effectively stop emailing distros about pending flaws. We are still allowed to tell them about more criticality scored vulnerabilities but I must confess I feel less inclined to do that than I used to.